
Long-Distance Multi-Vehicle Detection at Night Based on Gm-APD Lidar

Abstract
:1. Introduction
- To solve the problem of dim and small objects not being detected at a long distance, the method of local contrast enhancement is adopted to effectively improve the brightness information of weak and small objects, which can improve the accuracy of object detection;
- We propose a two-level detection network, which combines the two-dimensional intensity information and three-dimensional range information of lidar, effectively reducing the missed detection rate and improving the detection accuracy;
- We propose an improved first-level object detection network. The backbone network introduces the lightweight neural network of MobilNetv3, which solves the problem of increasing the computational complexity of two-level networks without reducing the detection accuracy of the network.
2. Related Work
3. Method
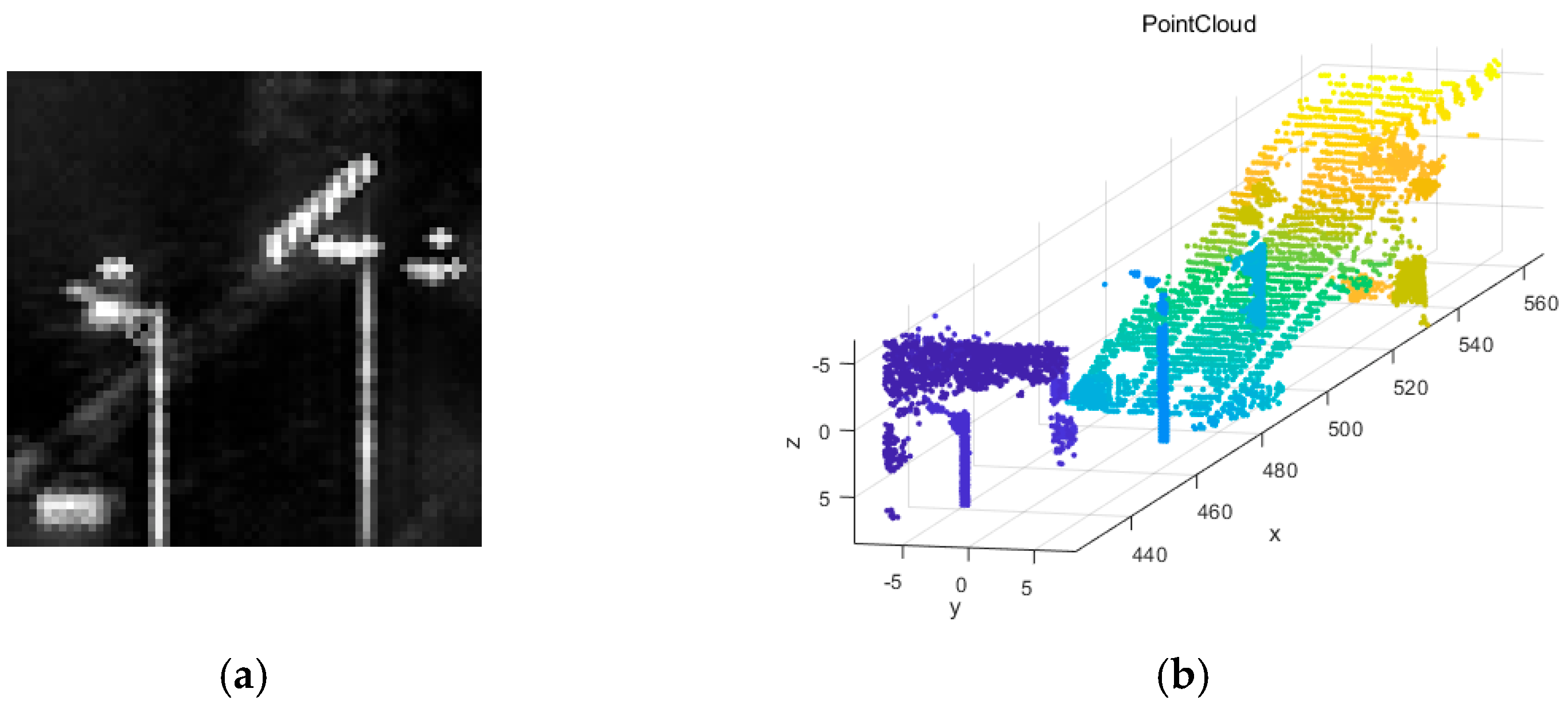
3.1. Data
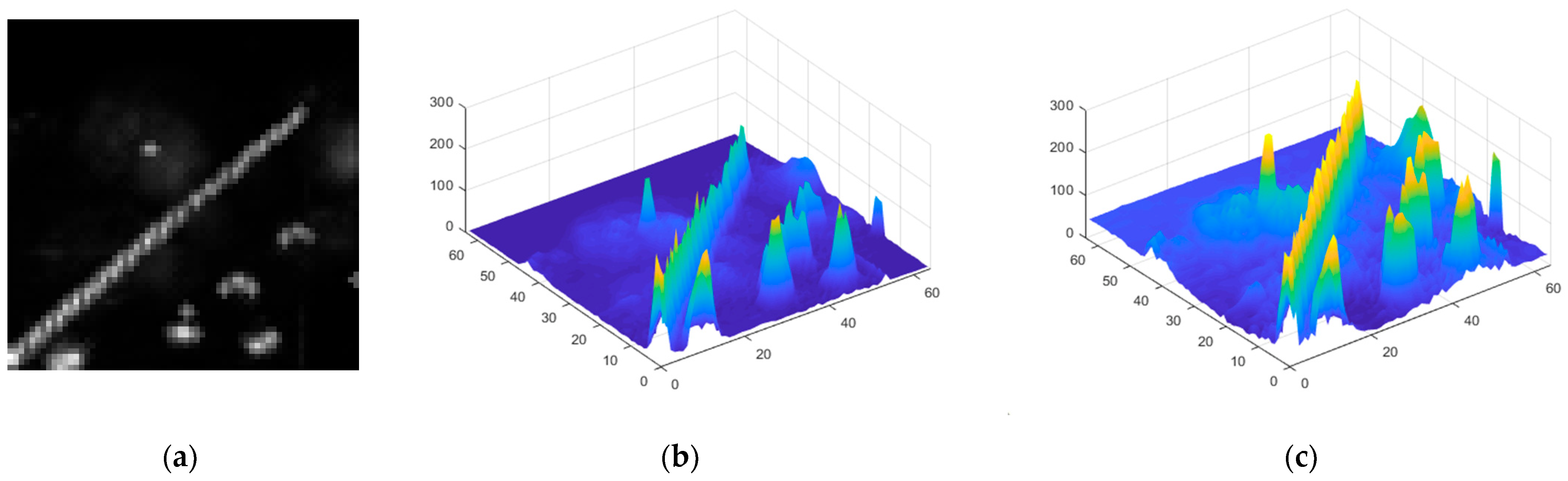
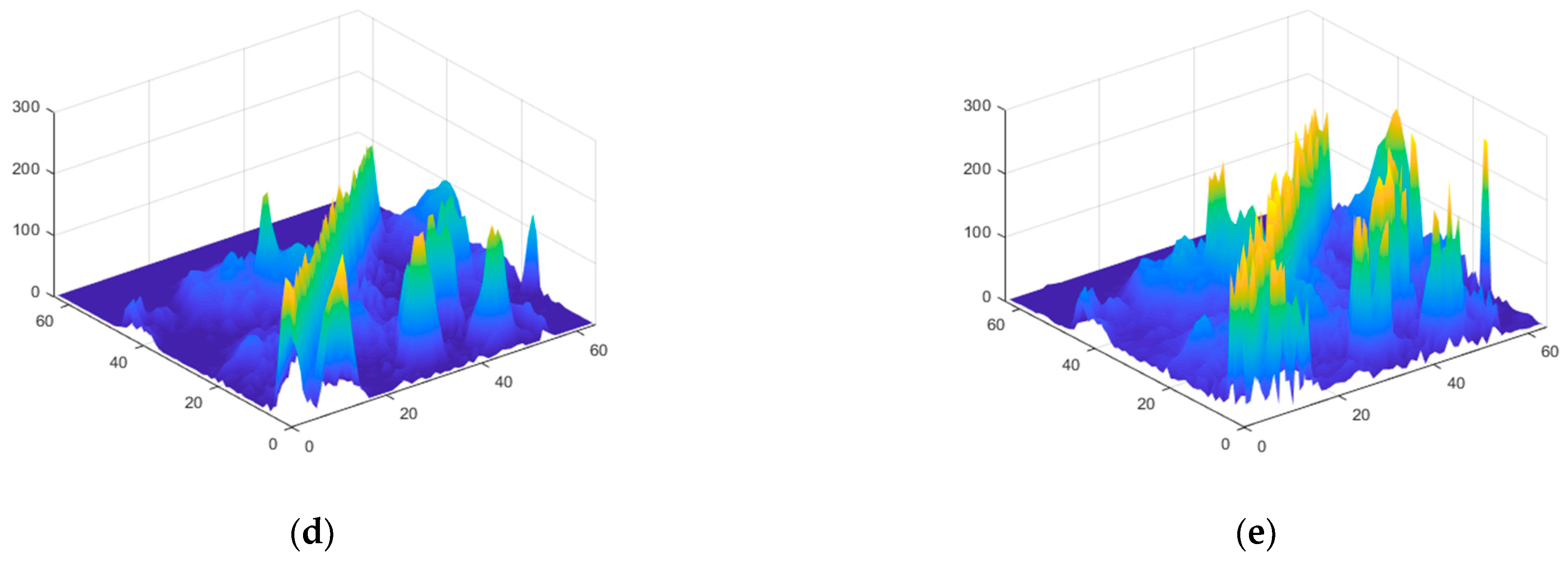
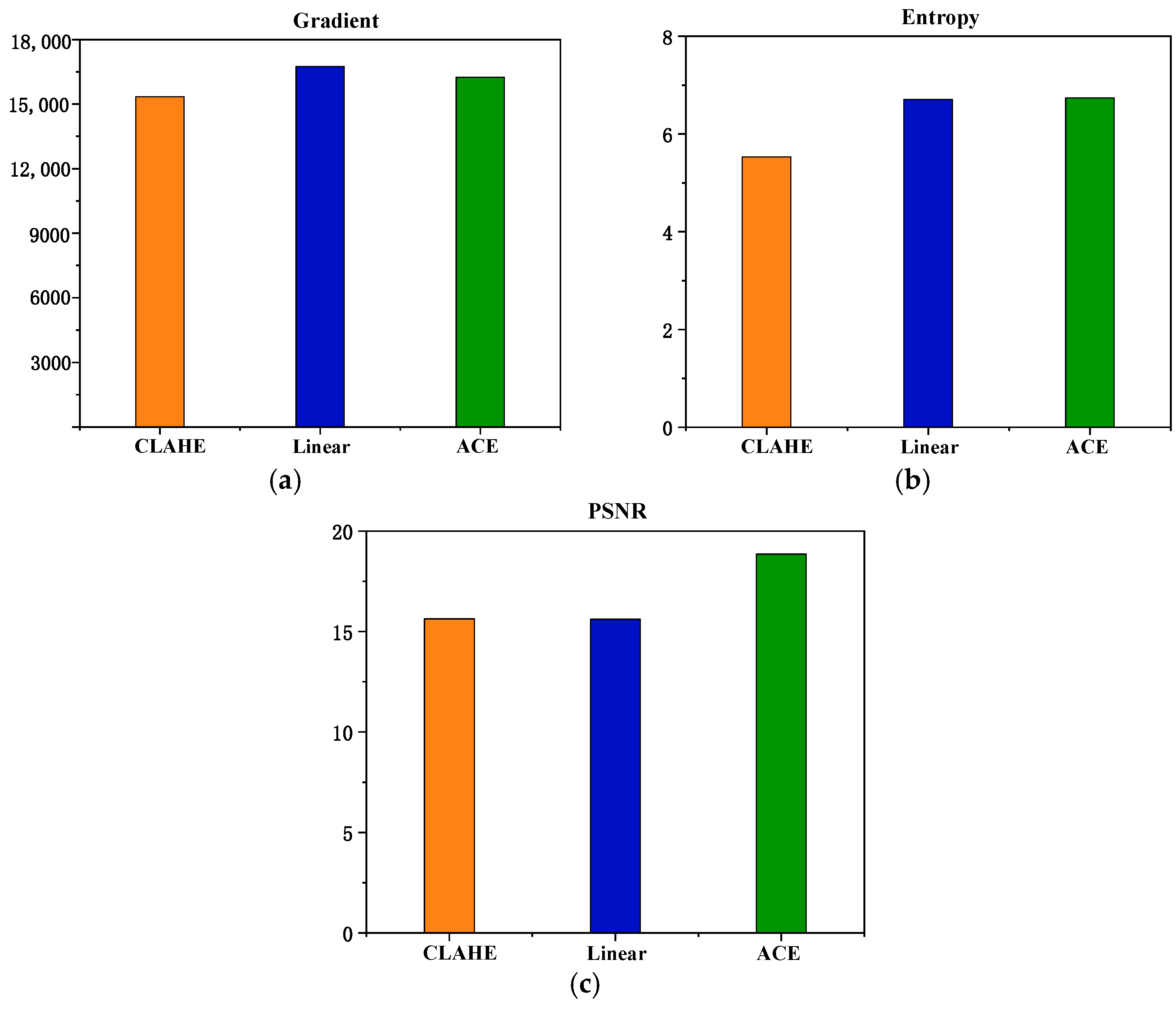
3.2. Adaptive Contrast Enhancement (ACE) Algorithm
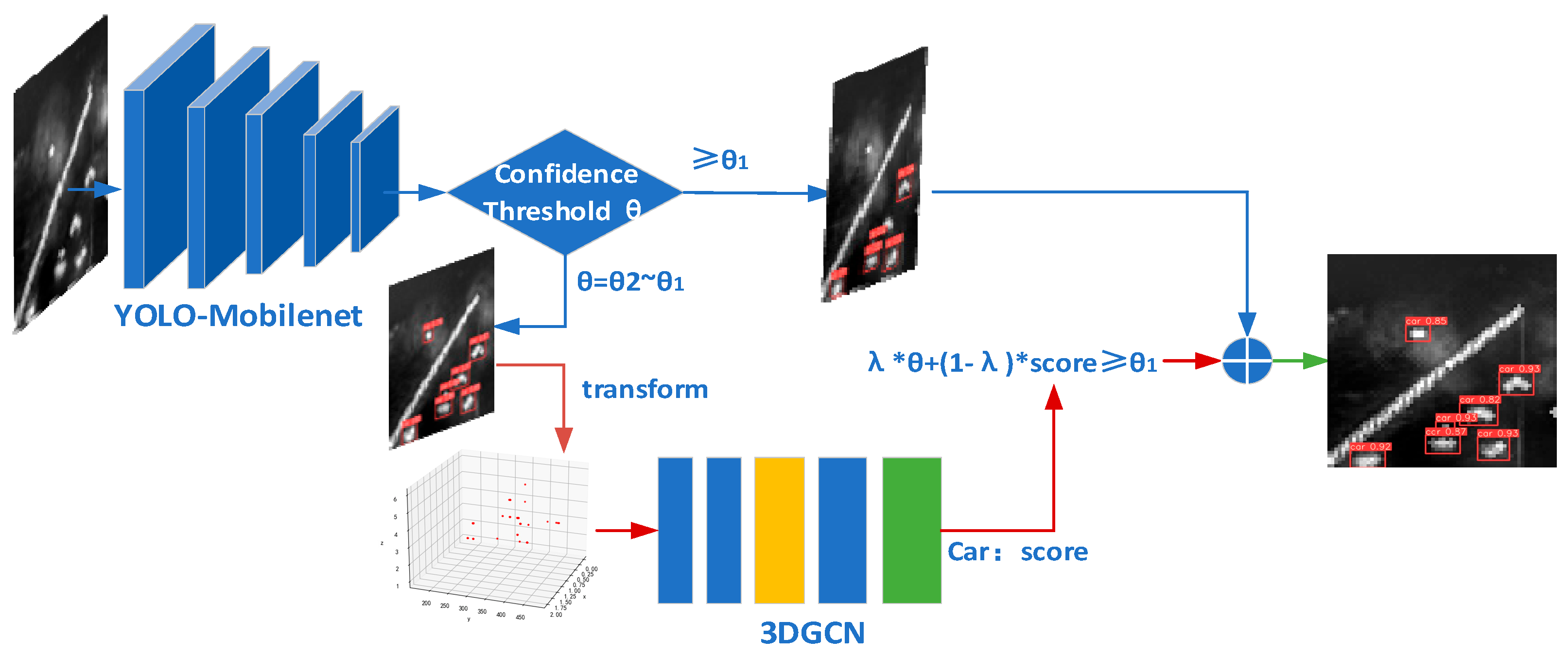
3.3. Two-Level Multi-Vehicle Detection Network
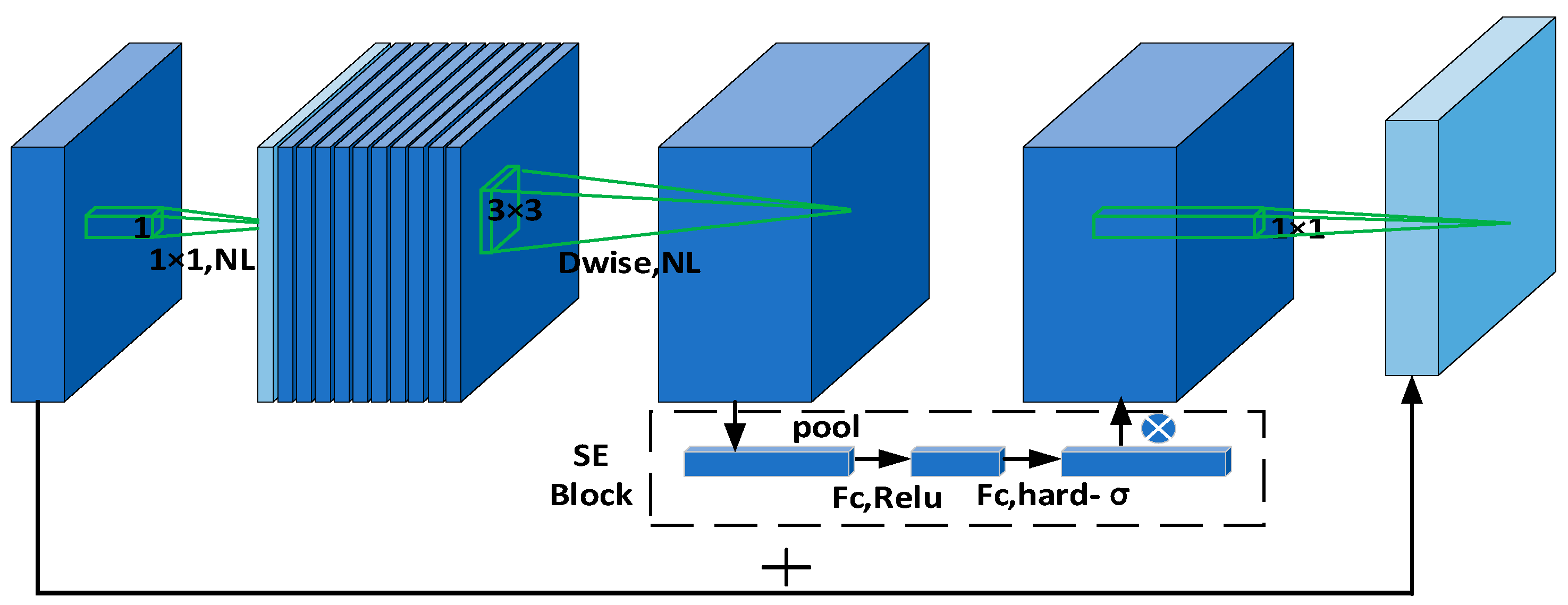
3.3.1. Improved First-Level YOLO Network
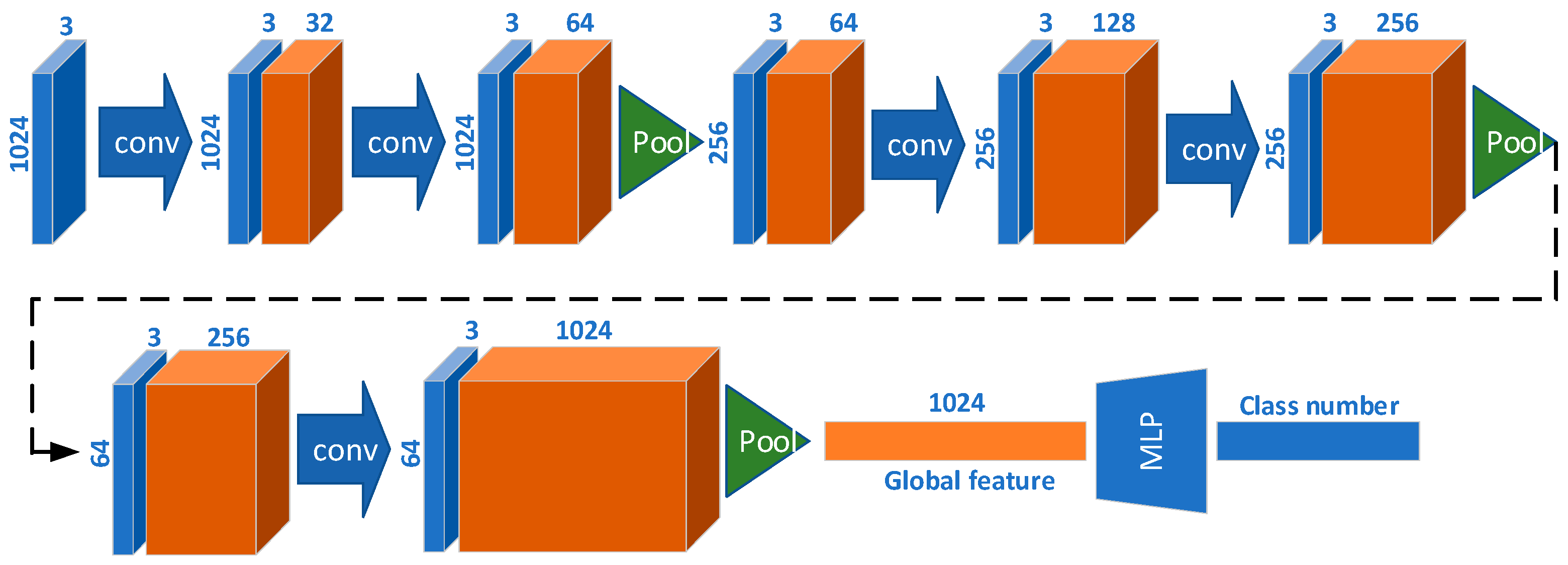
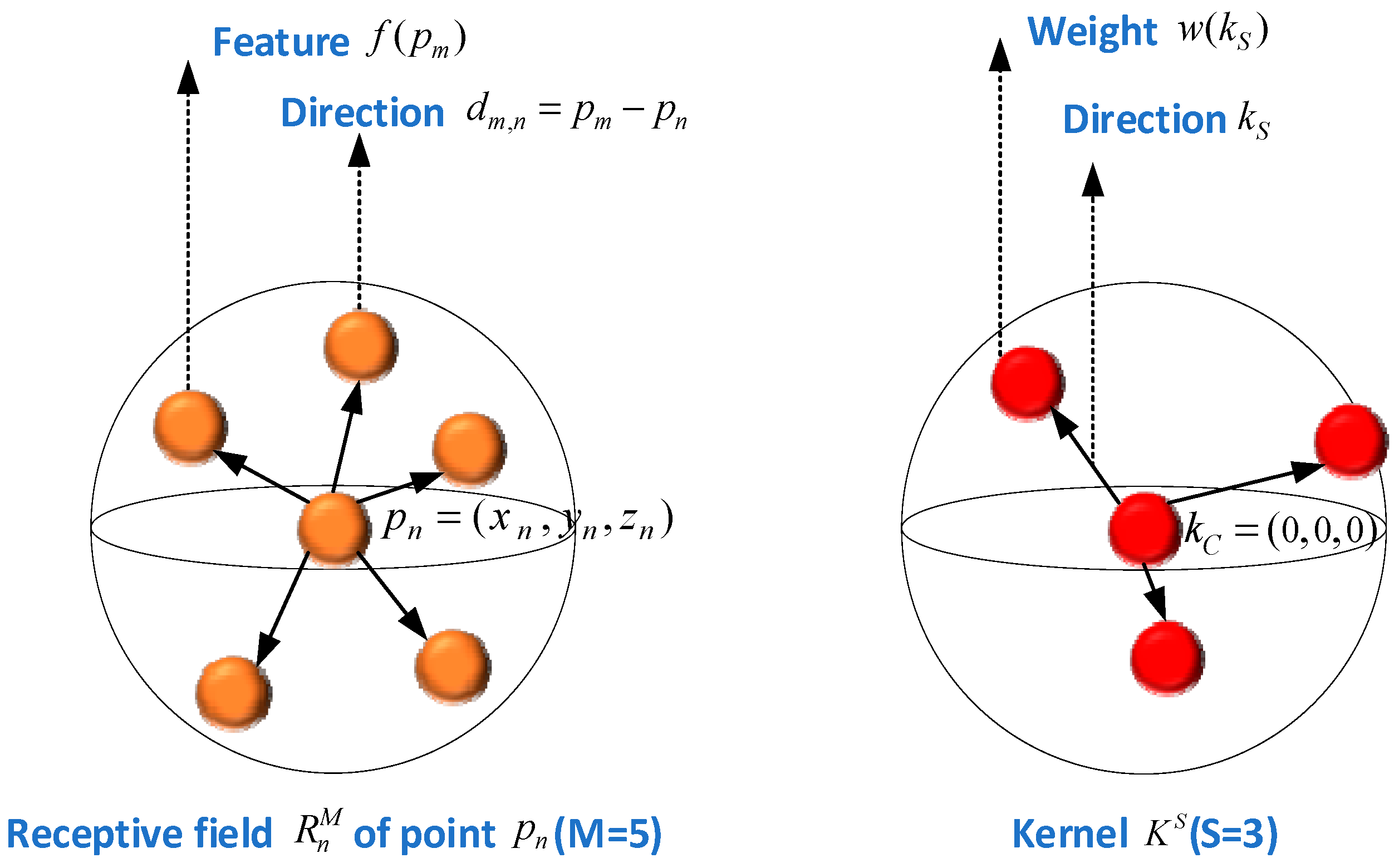
3.3.2. Second-Level 3DGCN Network
- (1)
- Learnable kernel
- (2)
- 3DGCN calculation
3.3.3. Confidence Threshold Processing Method
4. Experimental Results and Analysis
4.1. Experimental Operating Environment
4.2. Evaluation Indicators
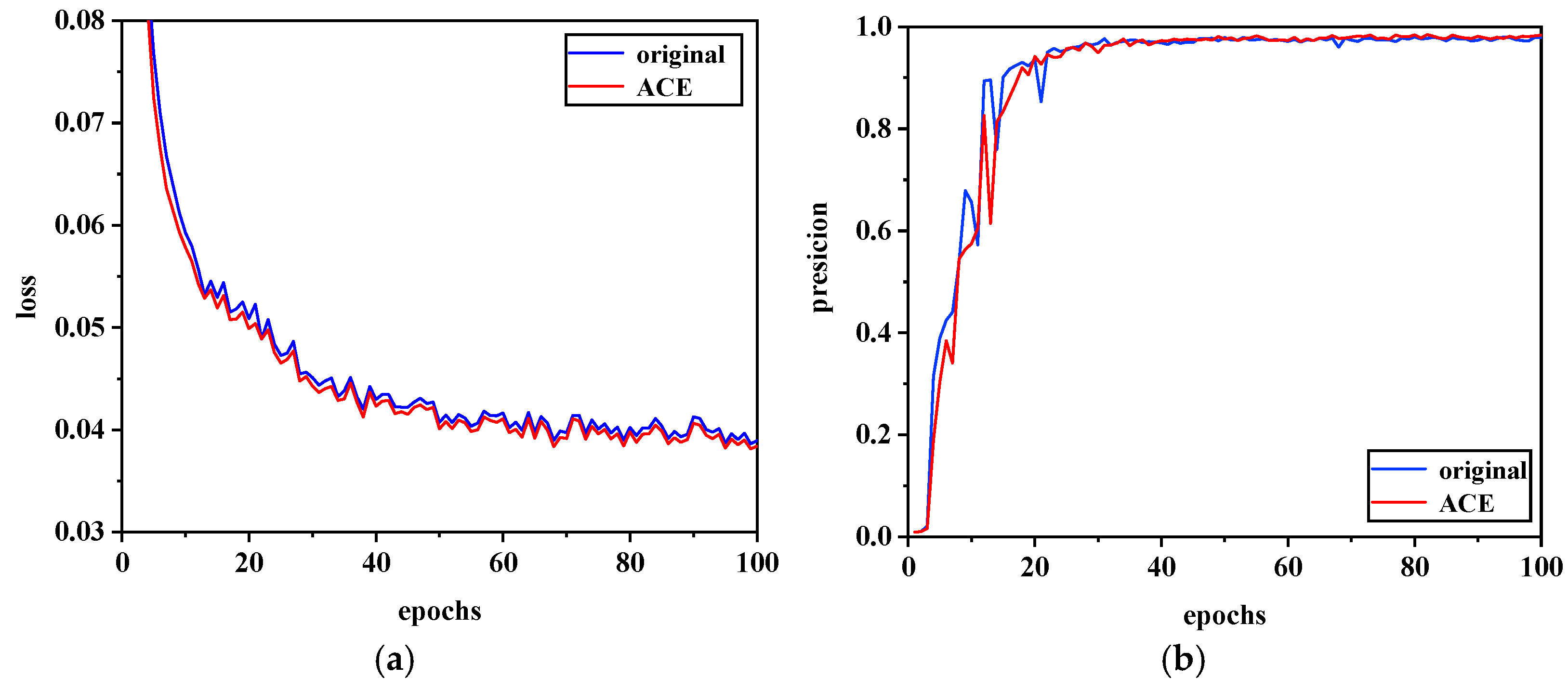
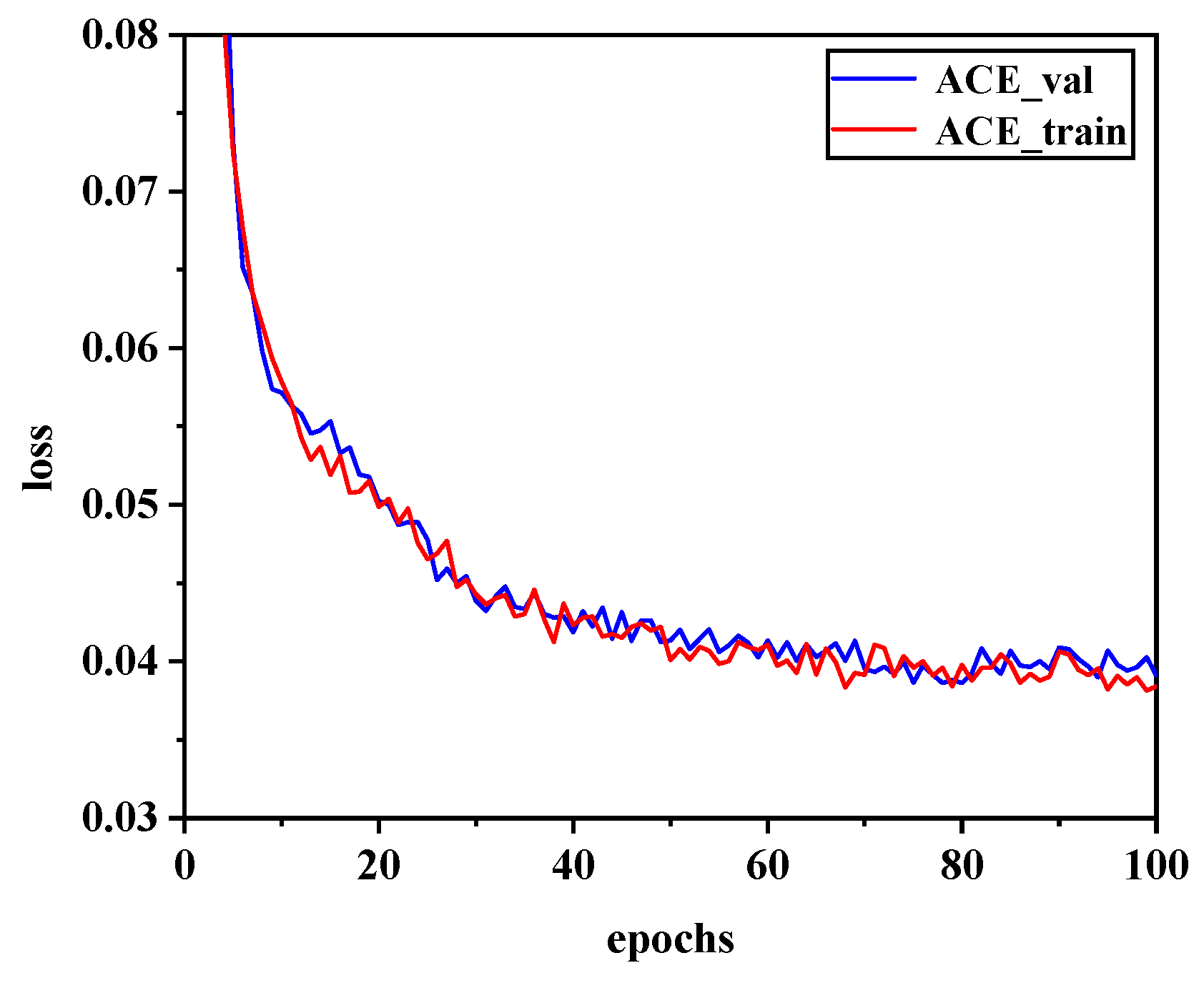
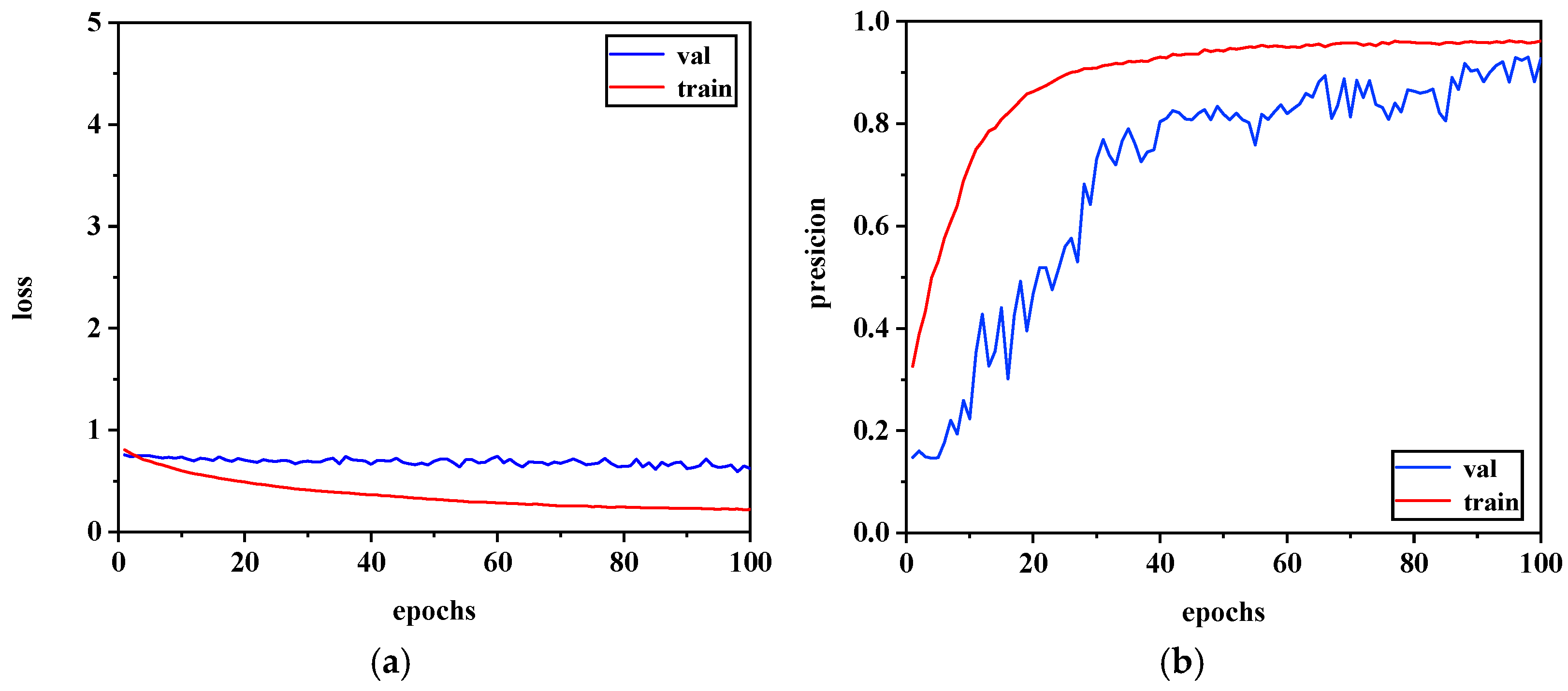
4.3. Network Training
4.4. Test Results and Analysis
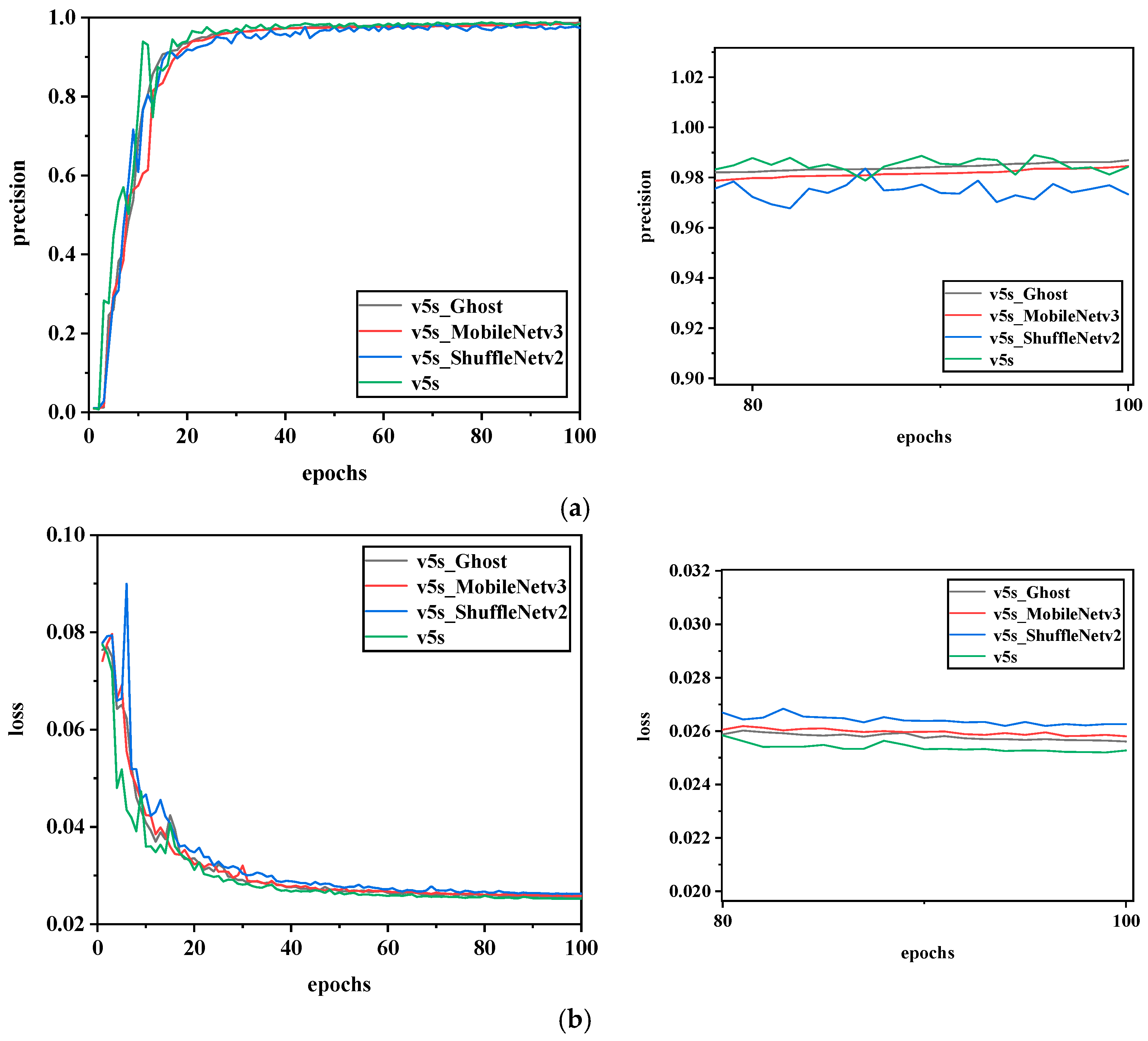
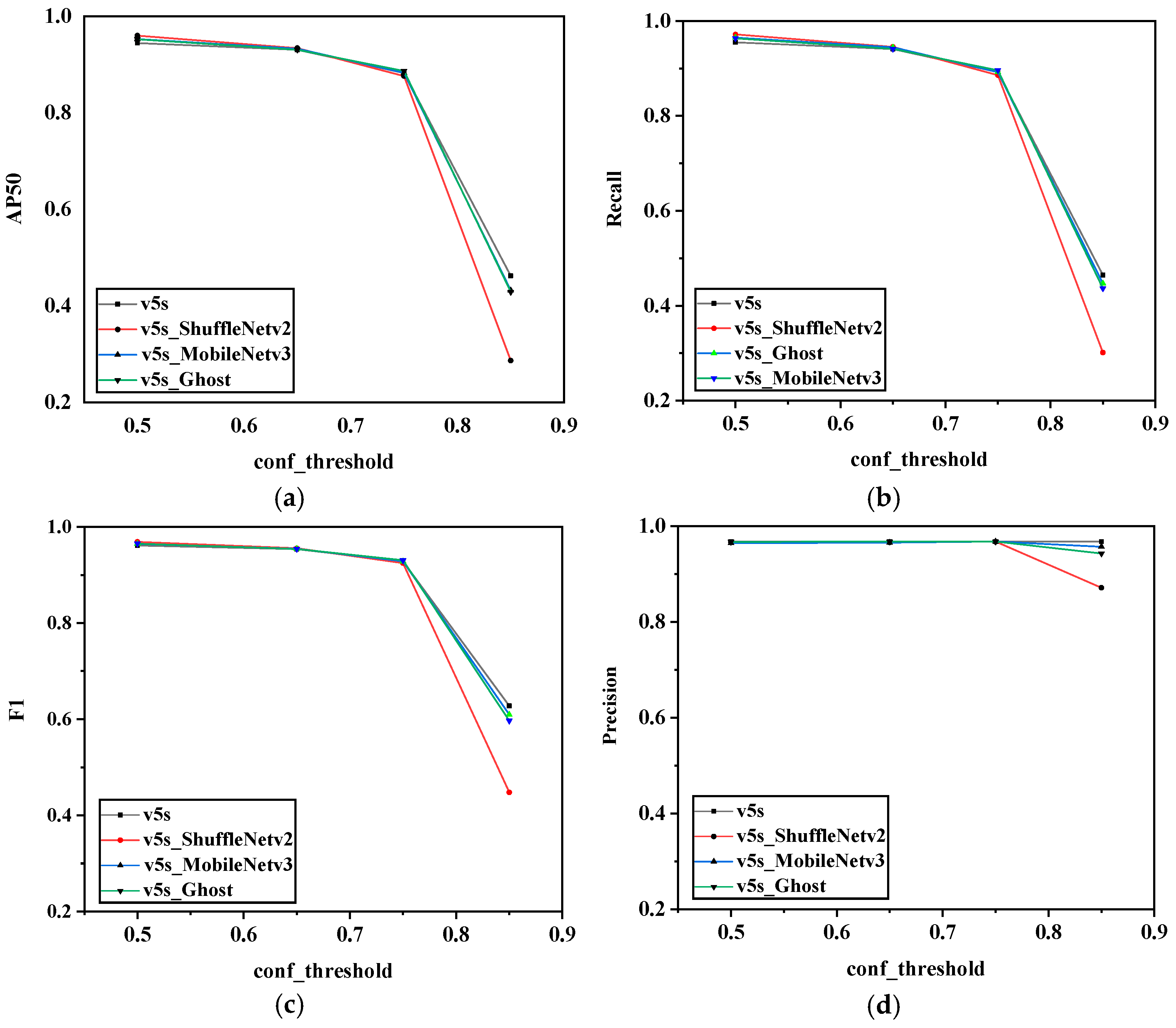
4.4.1. Comparison of First-Level Networks
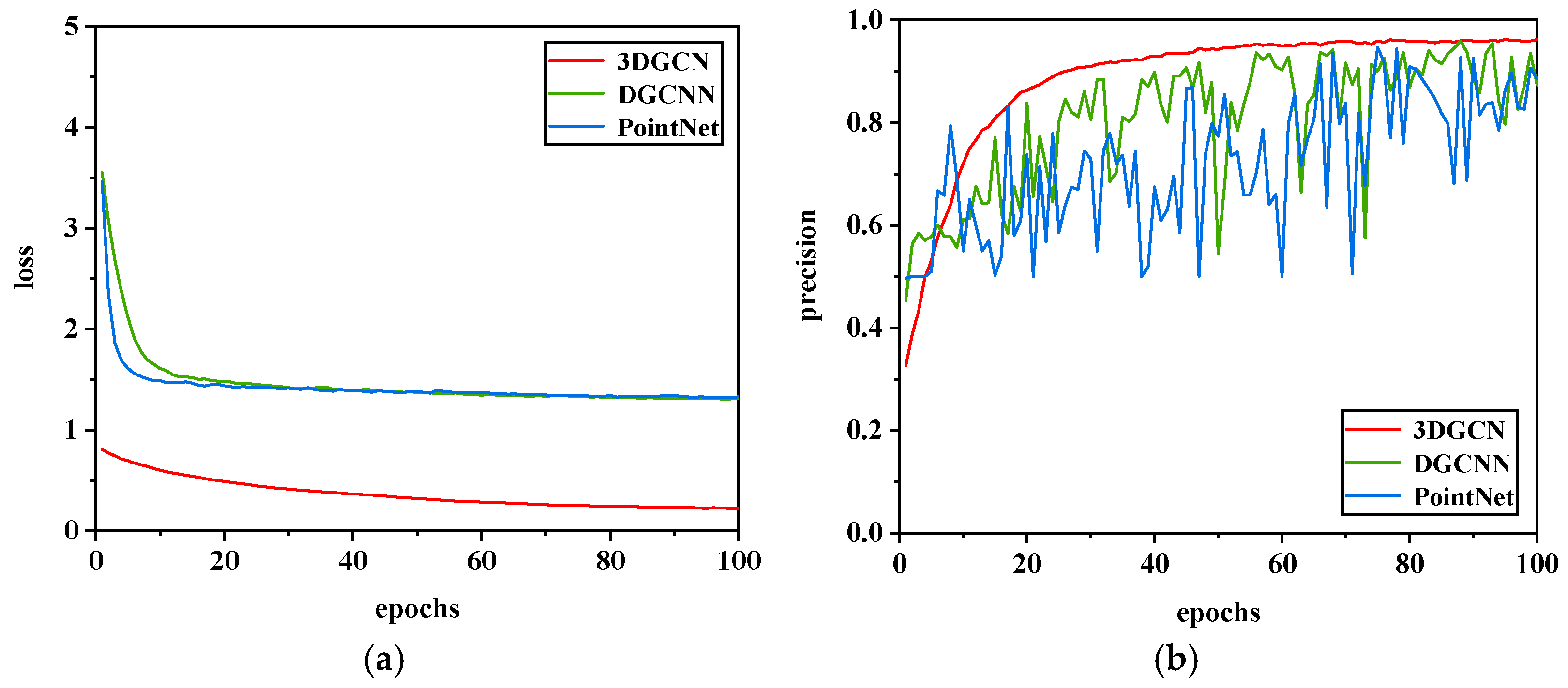
4.4.2. Comparison of Second-Level Networks
4.4.3. Comparison of Results between Single-Level Networks and Two-Level Networks
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qin, P.; Cai, Y.L.; Liu, J.; Fan, P.R.; Sun, M.H. Multilayer Feature Extraction Network for Military Ship Detection From High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11058–11069. [Google Scholar] [CrossRef]
- Janakiramaiah, B.; Kalyani, G.; Karuna, A.; Prasad, L.V.N.; Krishna, M. Military object detection in defense using multi-level capsule networks. Soft Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Fu, X.H.; Li, W. The intelligent vehicle object recognition algorithm based on object infrared features combined with lidar. Comput. Commun. 2020, 155, 158–165. [Google Scholar] [CrossRef]
- Cossio, T.K.; Slatton, K.C.; Carter, W.E.; Shrestha, K.Y.; Harding, D. Predicting Small Object Detection Performance of Low-SNR Airborne Lidar. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 3, 672–688. [Google Scholar] [CrossRef]
- Kechagias-Stamatis, O.; Aouf, N.; Richardson, M.A. 3D automatic object recognition for future LIDAR missiles. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2662–2675. [Google Scholar] [CrossRef] [Green Version]
- Silva, L.G.D.; Cerqueira, S., Jr. A LiDAR Architecture Based on Indirect ToF for Autonomous Cars. J. Microw. Optoelectron. Electromagn. Appl. 2021, 20, 504–512. [Google Scholar] [CrossRef]
- Sheu, M.H.; Morsalin SM, S.; Zheng, J.X.; Hsia, S.C.; Lin, C.J.; Chang, C.Y. FGSC: Fuzzy guided scale choice SSD model for edge AI design on real-time vehicle detection and class counting. Sensors 2021, 21, 7399. [Google Scholar] [CrossRef]
- De-Las-Heras, G.; Sánchez-Soriano, J.; Puertas, E. Advanced driver assistance systems (ADAS) based on machine learning techniques for the detection and transcription of variable message signs on roads. Sensors 2021, 21, 5866. [Google Scholar] [CrossRef]
- Caban, J.; Nieoczym, A.; Dudziak, A.; Krajka, T.; Stopková, M. The Planning Process of Transport Tasks for Autonomous Vans—Case Study. Appl. Sci. 2022, 12, 2993. [Google Scholar] [CrossRef]
- Ma, Y.; Anderson, J.; Crouch, S.; Shan, J. Moving object detection and tracking with doppler LiDAR. Remote Sens. 2019, 11, 1154. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Sun, J.F.; Gao, S.; Ma, L.; Jiang, P.; Guo, S.H.; Zhou, X. Single-parameter estimation construction algorithm for Gm-APD ladar imaging through fog. Opt. Commun. 2021, 482, 126558. [Google Scholar] [CrossRef]
- Qiu, C.R.; Sun, J.F.; Zhou, X.; Jiang, P.; Li, C.C.; Wang, Q. Experimental research on polarized LIDAR imaging based on GM-APD. In Optics Frontier Online 2020: Optics Imaging and Display; SPIE: Bellingham, WA, USA 2020, 11571, 40–50. [Google Scholar]
- Wang, P.; Fan, E.; Wang, P. Night vehicle object recognition based on fuzzy particle filter. J. Intell. Fuzzy Syst. 2020, 38, 3707–3716. [Google Scholar] [CrossRef]
- Hu, H.N.; Zhu, M.; Li, M.Y.; Chan, K.L. Deep Learning-Based Monocular 3D Object Detection with Refinement of Depth Information. Sensors 2022, 22, 2576. [Google Scholar] [CrossRef] [PubMed]
- Mendez, J.; Molina, M.; Rodriguez, N.; Cuellar, M.P.; Morales, D.P. Camera-LiDAR Multi-Level Sensor Fusion for Object Detection at the Network Edge. Sensors 2021, 21, 3992. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Kim, C.; Jang, C.; Sunwoo, M.; Jo, K. Deep learning-based dynamic object classification using LiDAR point cloud augmented by layer-based accumulation for intelligent vehicles. Expert Syst. Appl. 2021, 167, 113861. [Google Scholar] [CrossRef]
- Huang, D.Y.; Zhou, Z.H.; Deng, M.; Li, Z.H. Nighttime vehicle detection based on direction attention network and bayes corner localization. J. Intell. Fuzzy Syst. 2021, 41, 783–801. [Google Scholar] [CrossRef]
- Kuang, H.L.; Zhang, X.S.; Li, Y.J.; Chan, L.L.H.; Yan, H. Nighttime vehicle detection based on bio-inspired image enhancement and weighted score-level feature fusion. IEEE Trans. Intell. Transp. 2016, 18, 927–936. [Google Scholar] [CrossRef]
- Mo, Y.Y.; Han, G.Q.; Zhang, H.D.; Xu, X.M.; Qu, W. Highlight-assisted nighttime vehicle detection using a multi-level fusion network and label hierarchy. Neurocomputing 2019, 355, 13–23. [Google Scholar] [CrossRef]
- Chen, L.; Hu, X.M.; Xu, T.; Kuang, H.L.; Li, Q.Q. Turn signal detection during nighttime by cnn detector and perceptual hashing tracking. IEEE Trans. Intell. Transp. 2017, 18, 3303–3314. [Google Scholar] [CrossRef]
- Li, S.X.; Bai, P.F.; Qin, Y.F. Dynamic Adjustment and Distinguishing Method for Vehicle Headlight Based on Data Access of a Thermal Camera. Front. Phys. 2020, 8, 354. [Google Scholar] [CrossRef]
- Cai, Y.F.; Zhang, T.T.; Wang, H.; Li, Y.C.; Liu, Q.C.; Chen, X.B. 3D vehicle detection based on lidar and camera fusion. Automot. Innov. 2019, 2, 276–283. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, X.D. Real-time vehicle detection and tracking using 3D LiDAR. Asian J. Control 2021, 24, 1459–1469. [Google Scholar] [CrossRef]
- Tian, Y.F.; Song, W.; Chen, L.; Fong, S.; Sung, Y.; Kwak, J. A 3D Object Recognition Method from LiDAR Point Cloud Based on USAE-BLS. IEEE Trans. Intell. Transp. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- McCulloch, J.; Green, R. Conductor Reconstruction for Dynamic Line Rating Using Vehicle-Mounted LiDAR. Remote Sens. 2020, 12, 3718. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Tan, Z.W.; Yang, C.C. Theoretical limit evaluation of ranging accuracy and power for LiDAR systems in autonomous cars. Opt. Eng. 2018, 57, 096104. [Google Scholar] [CrossRef]
- Ma, L.; Sun, J.F.; Jiang, P.; Liu, D.; Zhou, X. Signal extraction algorithm of Gm-APD lidar with low SNR return. Optik 2020, 206, 164340. [Google Scholar] [CrossRef]
- Du, H.C. Image Denoising Algorithm Based on Nonlocal Regularization Sparse Representation. IEEE Sens. J. 2019, 20, 11943–11950. [Google Scholar] [CrossRef]
- Xiang, Q.; Peng, L.K.; Pang, X.L. Image DAEs based on residual entropy maximum. IET Image Processing 2020, 14, 1164–1169. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.X.; Wang, W.J.; Zhu, Y.K.; Pang, R.M.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018. [Google Scholar]
- Lin, Z.H.; Huang, S.Y.; Wang, Y.C.F. Convolution in the Cloud: Learning Deformable Kernels in 3D Graph Convolution Networks for Point Cloud Analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1800–1809. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graphic. 2018, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Doll´ar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [Green Version]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Number of Image Frames | Maximum Number of Objects per Frame | Minimum Object Ratio | Image Minimum Object Pixel Count |
|---|---|---|---|---|
| 20:37:19 | 500 | 15 | 3.052 × 10−5 | 8 |
| 20:37:58 | 500 | 11 | 3.052 × 10−5 | 8 |
| 20:38:11 | 500 | 12 | 1.907 × 10−5 | 5 |
| 20:38:24 | 500 | 6 | 1.907 × 10−5 | 5 |
| 20:52:09 | 500 | 11 | 1.907 × 10−5 | 5 |
| 20:52:22 | 500 | 9 | 3.052 × 10−5 | 8 |
| 20:52:37 | 500 | 17 | 3.052 × 10−5 | 8 |
| 20:52:51 | 500 | 16 | 1.907 × 10−5 | 5 |
| 21:22:48 | 500 | 8 | 3.052 × 10−5 | 8 |
| 21:23:05 | 500 | 8 | 2.670 × 10−5 | 7 |
| 21:23:24 | 500 | 7 | 3.052 × 10−5 | 8 |
| 21:23:50 | 500 | 7 | 2.670 × 10−5 | 7 |
| Input | Operator | Exp Size | Out | SE | NL | s |
|---|---|---|---|---|---|---|
| 6402 × 3 | bneck, 3 × 3 | - | 16 | - | HS | 2 |
| 3202 × 24 | bneck, 3 × 3 | 16 | 16 | √ | RE | 2 |
| 1602 × 24 | bneck, 3 × 3 | 72 | 24 | - | RE | 2 |
| 802 × 24 | bneck, 3 × 3 | 88 | 24 | - | RE | 1 |
| 802 × 40 | bneck, 5 × 5 | 96 | 40 | √ | HS | 1 |
| 402 × 40 | bneck, 5 × 5 | 240 | 40 | √ | HS | 1 |
| 402 × 40 | bneck, 5 × 5 | 240 | 40 | √ | HS | 1 |
| 402 × 40 | bneck, 5 × 5 | 120 | 48 | √ | HS | 1 |
| 402 × 48 | bneck, 5 × 5 | 144 | 48 | √ | HS | 1 |
| 402 × 96 | bneck, 5 × 5 | 288 | 96 | √ | HS | 2 |
| 202 × 96 | bneck, 5 × 5 | 576 | 96 | √ | HS | 1 |
| 202 × 96 | bneck, 5 × 5 | 576 | 96 | √ | HS | 1 |
| Model | Layers | Parameters | GFLOPs | Weight Size |
|---|---|---|---|---|
| YOLOv5s | 270 | 7,235,389 | 16.5 | 13.7 MB |
| YOLOv5s_Shufflenetv2 | 308 | 3,844,193 | 8.1 | 7.68 MB |
| YOLOv5s_Ghost | 453 | 3,897,605 | 8.8 | 7.50 MB |
| Ours | 340 | 3,542,756 | 6.3 | 7.17 MB |
| AP | v5s | v5s_ShuffeNetv2 | v5s_Ghost | Ours | |
|---|---|---|---|---|---|
| Conf = 0.5 | |||||
| AP50 | 0.9682 | 0.9749 | 0.9722 | 0.9751 | |
| AP75 | 0.9682 | 0.9748 | 0.9718 | 0.9749 | |
| AP85 | 0.9682 | 0.9740 | 0.9692 | 0.9744 | |
| AP@50:5:95 | 0.9546 | 0.9596 | 0.9532 | 0.9540 | |
| Conf = 0.75 | |||||
| AP50 | 0.9047 | 0.8963 | 0.9143 | 0.9116 | |
| AP75 | 0.9047 | 0.8963 | 0.9141 | 0.9115 | |
| AP85 | 0.9047 | 0.8963 | 0.9127 | 0.9115 | |
| AP@50:5:95 | 0.8938 | 0.8857 | 0.8991 | 0.8944 | |
| Conf = 0.85 | |||||
| AP50 | 0.4544 | 0.2997 | 0.4323 | 0.4488 | |
| AP75 | 0.4544 | 0.2997 | 0.4323 | 0.4488 | |
| AP85 | 0.4544 | 0.2997 | 0.4323 | 0.4488 | |
| AP@50:5:95 | 0.4510 | 0.2983 | 0.4282 | 0.4432 |
| Epochs_2D | Epochs_3D | conf_thresd | AP50 | AP75 | AP85 | AP@50:5:95 | |
|---|---|---|---|---|---|---|---|
| Ours | 100 | 100 | 0.85 | 0.9738 | 0.9736 | 0.9542 | 0.9638 |
| Epochs_All | AP50 | AP75 | AP85 | AP@50:5:95 | Train Time | |
|---|---|---|---|---|---|---|
| Faster R-CNN | 200 | 0.9204 | 0.8044 | 0.7239 | 0.7639 | 6.5 h |
| SSD | 200 | 0.9590 | 0.8770 | 0.8630 | 0.7950 | 5.4 h |
| RetinaNet | 200 | 0.9675 | 0.8130 | 0.8114 | 0.7700 | 5.2 h |
| CenterNet | 200 | 0.9680 | 0.803 | 0.7910 | 0.7681 | 3.2 h |
| YOLOX | 200 | 0.9791 | 0.886 | 0.7700 | 0.7176 | 2.8 h |
| Ours | 200 | 0.9738 | 0.9736 | 0.9542 | 0.9638 | 3.8 h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Qu, Y.; Sun, J.; Du, D.; Jiang, Y.; Zhang, H. Long-Distance Multi-Vehicle Detection at Night Based on Gm-APD Lidar. Remote Sens. 2022, 14, 3553. https://doi.org/10.3390/rs14153553
Ding Y, Qu Y, Sun J, Du D, Jiang Y, Zhang H. Long-Distance Multi-Vehicle Detection at Night Based on Gm-APD Lidar. Remote Sensing. 2022; 14(15):3553. https://doi.org/10.3390/rs14153553
Chicago/Turabian StyleDing, Yuanxue, Yanchen Qu, Jianfeng Sun, Dakuan Du, Yanze Jiang, and Hailong Zhang. 2022. "Long-Distance Multi-Vehicle Detection at Night Based on Gm-APD Lidar" Remote Sensing 14, no. 15: 3553. https://doi.org/10.3390/rs14153553
APA StyleDing, Y., Qu, Y., Sun, J., Du, D., Jiang, Y., & Zhang, H. (2022). Long-Distance Multi-Vehicle Detection at Night Based on Gm-APD Lidar. Remote Sensing, 14(15), 3553. https://doi.org/10.3390/rs14153553