
A Cascade Defense Method for Multidomain Adversarial Attacks under Remote Sensing Detection


Abstract
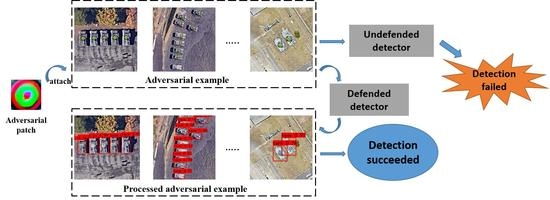
:
1. Introduction
- To the best of our knowledge, we are the first to propose an effective defense method against adversarial attacks on optical remote sensing detection including but not limited to earth observation satellite detection of ground targets, aerial target detection of drones to the ground, etc. Our method can effectively defend against vanishing attacks of adversarial patches attached to or near the detection target.
- We propose a framework for defense against adversarial patches, including adversarial patch positioning, image inpainting, and feature learning enhancement methods for adversarial patches. This makes our defense framework robust against adversarial attacks.
- A series of experiments demonstrate the effectiveness of our algorithm, including the defense capabilities of different models with multiple types of adversarial patches. Our experiments show that our framework can provide strong robustness to object detection models under different detectors and different adversarial attacks.
2. Related Work
2.1. Adversarial Attack
2.2. Adversarial Attack for Aerial Image Detection
2.3. Physical Domain Adversarial Defense
3. Problem Definition
3.1. The Purpose of the Attacker
3.2. The Purpose of the Defender
- 1.
- The detector should try to restore the detection ability of the detection image under the adversarial attack;
- 2.
- When not attacked by adversarial examples, it is necessary to ensure that the performance of the detector on the clean detection image does not degrade;
3.3. Adversarial Patch
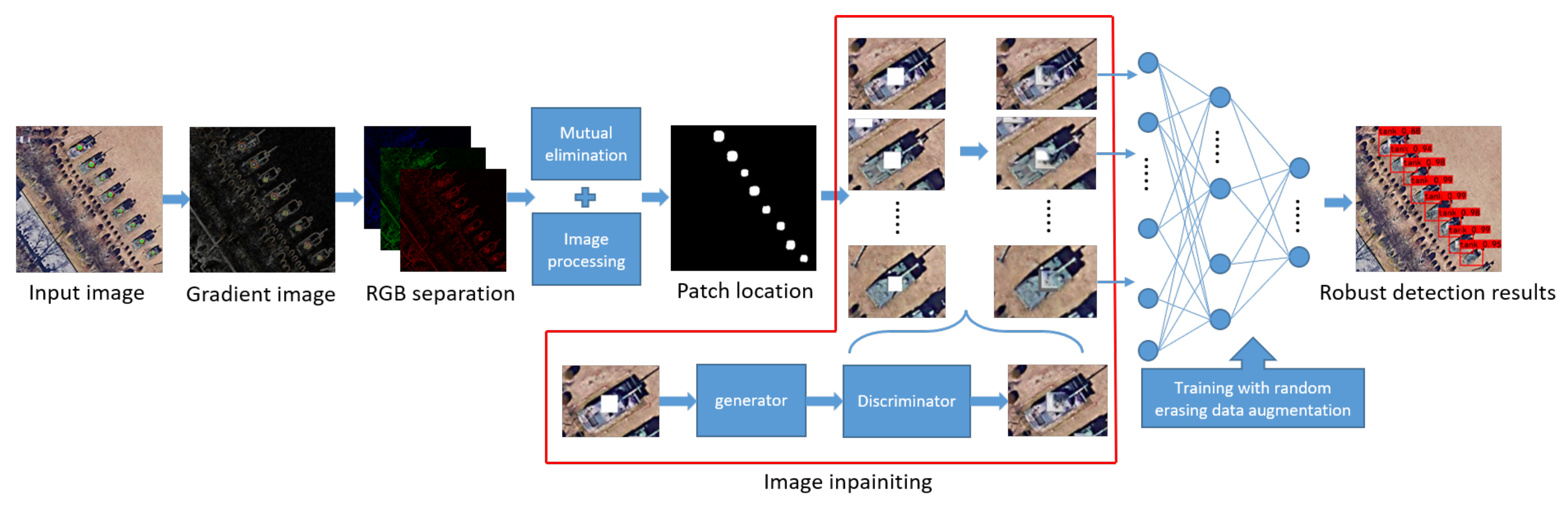
4. Defense Method
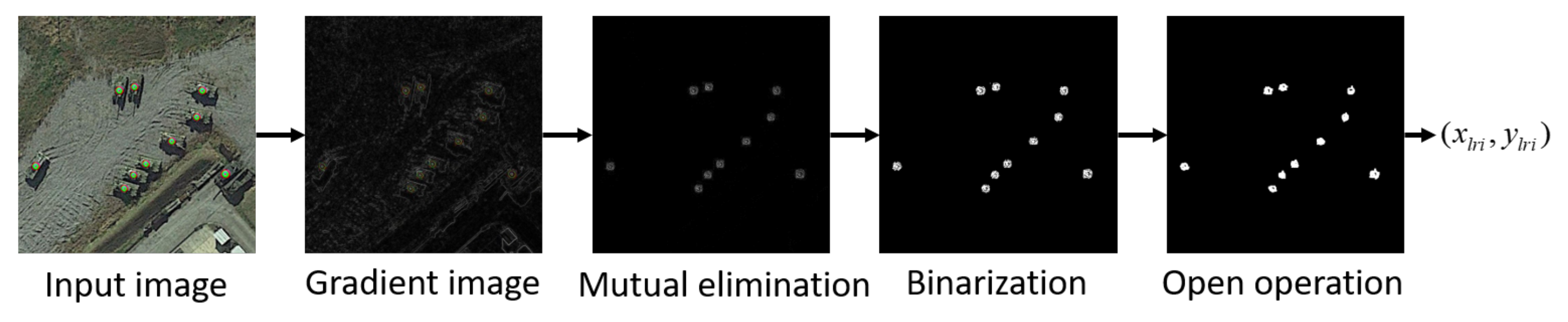
4.1. Locating Adversarial Patch
4.2. Image Inpainting and Data Augmentation
5. Experimental Results
5.1. Datasets and Adversarial Patch
5.1.1. Tank Dataset
5.1.2. Adversarial Patch
5.2. Defense Algorithm Details and Defense Performance
5.2.1. Adversarial Patch Positioning
5.2.2. Image Inpainting
5.2.3. Random Erasing Data Augmentation
5.2.4. Defense Performance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Conf1 | Conf10 | Conf20 | Conf40 | Conf60 | Conf75 | Conf90 |
|---|---|---|---|---|---|---|---|
| Recall(nat) | 76.87 | 76.87 | 76.87 | 76.87 | 69.86 | 56.54 | 32.72 |
| Recall(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Recall | 75.70(↓1.17) | 75.70(↓1.17) | 75.70(↓1.17) | 75.70(↓1.17) | 67.99(↓1.87) | 50.23(↓6.31) | 26.64(↓6.08) |
| Precision(nat) | 91.64 | 91.64 | 91.64 | 91.64 | 93.44 | 96.80 | 98.59 |
| Precision(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Precision | 90.00(↓1.64) | 90.00(↓1.64) | 90.00(↓1.64) | 90.00(↓1.64) | 93.57(↓0.13) | 96.41(↓0.39) | 98.28(↓0.31) |
| F1(nat) | 0.84 | 0.84 | 0.84 | 0.84 | 0.80 | 0.71 | 0.49 |
| F1(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| F1 | 0.82(↓0.02) | 0.82(↓0.02) | 0.82(↓0.02) | 0.82(↓0.02) | 0.79(↓0.1) | 0.66(↓0.05) | 0.42(↓0.07) |
| AP(nat) | 92.40 | 90.36 | 87.03 | 78.65 | 68.59 | 55.93 | 32.67 |
| AP(adv) | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| AP | 91.47(↓0.93) | 89.30(↓1.06) | 86.08(↓0.95) | 78.87(↑0.22) | 66.48(↓2.11) | 52.52(↓3.41) | 26.39(↓6.28) |
| Index | Conf1 | Conf10 | Conf20 | Conf40 | Conf60 | Conf75 | Conf90 |
|---|---|---|---|---|---|---|---|
| Recall(nat) | 98.13 | 98.13 | 98.13 | 98.13 | 98.13 | 97.66 | 96.26 |
| Recall(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Recall | 96.26(↓1.87) | 96.26(↓1.87) | 96.26(↓1.87) | 96.26(↓1.87) | 96.03(↓2.10) | 94.84(↓2.82) | 92.76(↓3.50) |
| Precision(nat) | 76.64 | 76.64 | 76.64 | 76.64 | 81.40 | 86.72 | 93.64 |
| Precision(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Precision | 79.23(↑2.59) | 79.23(↑2.59) | 79.23(↑2.59) | 79.23(↑2.59) | 81.55(↑0.15) | 85.00(↓1.72) | 93.19(↓0.45) |
| F1(nat) | 0.86 | 0.86 | 0.86 | 0.86 | 0.89 | 0.92 | 0.95 |
| F1(adv) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| F1 | 0.87(↑0.01) | 0.87(↑0.01) | 0.87(↑0.01) | 0.87(↑0.01) | 0.88(↓0.01) | 0.90(↓0.02) | 0.93(↓0.02) |
| AP(nat) | 98.09 | 98.09 | 98.09 | 97.77 | 97.59 | 97.19 | 95.91 |
| AP(adv) | 0.11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| AP | 97.27(↓0.82) | 96.84(↓1.25) | 96.68(↓1.41) | 95.79(↓1.98) | 95.42(↓2.17) | 94.84(↓2.35) | 92.51(↓3.40) |
- 1.
- Since adversarial patch is not directly attached to the detection target, the accuracy of the adversarial patch position method can be simulated, so the localization method has high localization accuracy. Therefore, it can also be seen that image inpainting and training data augmentation can almost restore the detection performance of the detector.
- 2.
- When the adversarial patch is close to the detection target, some target features will be lost due to the pooling operation, so the detection performance in this case is not completely the same as the performance before the attack;
5.3. Ablation Studies
5.3.1. Why Does the Mutual Elimination Operation in the Gradient Domain Work?
5.3.2. Improvement of Detection Robustness by Random Erasing Algorithm
5.3.3. Defense against Weakly Saliency Adversarial Patch
5.3.4. Influence of Adversarial Patch Size on Image Inpainting and Adversarial Patch Positioning
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial object detection in high resolution satellite images based on multi-scale convolutional neural network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Ji, H.; Gao, Z.; Mei, T.; Ramesh, B. Vehicle detection in remote sensing images leveraging on simultaneous super-resolution. IEEE Geosci. Remote Sens. Lett. 2019, 17, 676–680. [Google Scholar] [CrossRef]
- Shermeyer, J.; Van Etten, A. The effects of super-resolution on object detection performance in satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kim, J.; Cho, J. RGDiNet: Efficient Onboard Object Detection with Faster R-CNN for Air-to-Ground Surveillance. Sensors 2021, 21, 1677. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Tramèr, F.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. The space of transferable adversarial examples. arXiv 2017, arXiv:1704.03453. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 284–293. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Li, H.; Chen, Y. Dpatch: An adversarial patch attack on object detectors. arXiv 2018, arXiv:1806.02299. [Google Scholar]
- Den Hollander, R.; Adhikari, A.; Tolios, I.; van Bekkum, M.; Bal, A.; Hendriks, S.; Kruithof, M.; Gross, D.; Jansen, N.; Perez, G.; et al. Adversarial patch camouflage against aerial detection. In Proceedings of the Artificial Intelligence and Machine Learning in Defense Applications II, Online, 21–25 September 2020; Volume 11543, p. 115430F. [Google Scholar]
- Duan, R.; Mao, X.; Qin, A.K.; Chen, Y.; Ye, S.; He, Y.; Yang, Y. Adversarial laser beam: Effective physical-world attack to DNNs in a blink. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16062–16071. [Google Scholar]
- Kaziakhmedov, E.; Kireev, K.; Melnikov, G.; Pautov, M.; Petiushko, A. Real-world attack on MTCNN face detection system. In Proceedings of the 2019 International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Academpark, Russia, 21–22 October 2019; pp. 0422–0427. [Google Scholar]
- Wu, Z.; Lim, S.N.; Davis, L.S.; Goldstein, T. Making an invisibility cloak: Real world adversarial attacks on object detectors. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 1–17. [Google Scholar]
- Huang, L.; Gao, C.; Zhou, Y.; Xie, C.; Yuille, A.L.; Zou, C.; Liu, N. Universal physical camouflage attacks on object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 720–729. [Google Scholar]
- Wang, J.; Liu, A.; Yin, Z.; Liu, S.; Tang, S.; Liu, X. Dual attention suppression attack: Generate adversarial camouflage in physical world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8565–8574. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedemé, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Hoory, S.; Shapira, T.; Shabtai, A.; Elovici, Y. Dynamic adversarial patch for evading object detection models. arXiv 2020, arXiv:2010.13070. [Google Scholar]
- Chen, S.T.; Cornelius, C.; Martin, J.; Chau, D.H.P. Shapeshifter: Robust physical adversarial attack on faster r-cnn object detector. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 52–68. [Google Scholar]
- Dziugaite, G.K.; Ghahramani, Z.; Roy, D.M. A study of the effect of jpg compression on adversarial images. arXiv 2016, arXiv:1608.00853. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Chen, L.; Kounavis, M.E.; Chau, D.H. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv 2017, arXiv:1705.02900. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against adversarial attacks using high-level representation guided denoiser. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1778–1787. [Google Scholar]
- Osadchy, M.; Hernandez-Castro, J.; Gibson, S.; Dunkelman, O.; Pérez-Cabo, D. No bot expects the DeepCAPTCHA! Introducing immutable adversarial examples, with applications to CAPTCHA generation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2640–2653. [Google Scholar] [CrossRef] [Green Version]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Lee, H.; Han, S.; Lee, J. Generative adversarial trainer: Defense to adversarial perturbations with gan. arXiv 2017, arXiv:1705.03387. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Zhang, H.; Wang, J. Towards adversarially robust object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 421–430. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. No need to worry about adversarial examples in object detection in autonomous vehicles. arXiv 2017, arXiv:1707.03501. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM Sigsac Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1528–1540. [Google Scholar]
- Du, A.; Chen, B.; Chin, T.J.; Law, Y.W.; Sasdelli, M.; Rajasegaran, R.; Campbell, D. Physical adversarial attacks on an aerial imagery object detector. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 1796–1806. [Google Scholar]
- Naseer, M.; Khan, S.; Porikli, F. Local gradients smoothing: Defense against localized adversarial attacks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1300–1307. [Google Scholar]
- Hayes, J. On visible adversarial perturbations & digital watermarking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1597–1604. [Google Scholar]
- Chiang, P.Y.; Ni, R.; Abdelkader, A.; Zhu, C.; Studer, C.; Goldstein, T. Certified defenses for adversarial patches. arXiv 2020, arXiv:2003.06693. [Google Scholar]
- Xiang, C.; Bhagoji, A.N.; Sehwag, V.; Mittal, P. {PatchGuard}: A Provably Robust Defense against Adversarial Patches via Small Receptive Fields and Masking. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 2237–2254. [Google Scholar]
- Bao, J.; Chen, J.; Ma, H.; Ma, H.; Yu, C.; Huang, Y. Improving Adversarial Robustness of Detector via Objectness Regularization. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Beijing, China, 29 October–1 November 2021; pp. 252–262. [Google Scholar]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]











| Index | AP(average) | AP35 | AP50 | AP75 | AP90 |
|---|---|---|---|---|---|
| Recall(nat) | 76.87 | 76.87 | 76.87 | 76.87 | 76.87 |
| Recall | 75.70(↓1.17) | 75.70(↓1.17) | 75.70(↓1.17) | 75.70(↓1.17) | 75.70(↓1.17) |
| Precision(nat) | 71.64 | 90.98 | 89.60 | 59.44 | 46.55 |
| Precision | 72.31(↑0.67) | 91.27(↑0.29) | 88.77(↓0.83) | 59.59(↑0.15) | 49.62(↑0.07) |
| AP(nat) | 69.85 | 75.44 | 75.92 | 67.00 | 61.04 |
| AP | 68.70(↓1.15) | 74.16(↓1.28) | 73.84(↓2.08) | 65.71(↓1.29) | 61.12(↑0.08) |
| Index | Conf1 | Conf10 | Conf20 | Conf40 | Conf60 | Conf75 | Conf90 |
|---|---|---|---|---|---|---|---|
| Recall(adv) | 0.70 | 0.70 | 0.70 | 0.70 | 0.70 | 0.47 | 0.00 |
| Recall | 68.69 | 68.69 | 68.69 | 68.69 | 58.88 | 42.99 | 20.56 |
| Precision(adv) | 17.65 | 17.65 | 17.65 | 17.65 | 25.00 | 33.33 | 0.00 |
| Precision | 88.55 | 88.55 | 88.55 | 88.55 | 92.31 | 96.34 | 97.78 |
| AP(adv) | 1.19 | 0.60 | 0.01 | 0.01 | 0.01 | 0.01 | 0.00 |
| AP | 87.86 | 83.94 | 80.04 | 70.49 | 57.36 | 42.28 | 20.45 |
| Blur Pixel Radius | Conf1 | Conf20 | Conf60 | Conf90 | ||||
|---|---|---|---|---|---|---|---|---|
| Attack | Robust | Attack | Robust | Attack | Robust | Attack | Robust | |
| 1(Recall) | 15.42 | 69.63 | 15.42 | 69.63 | 10.28 | 60.28 | 1.87 | 20.09 |
| 1(AP) | 52.09 | 89.75 | 24.49 | 82.38 | 9.60 | 59.27 | 1.87 | 20.09 |
| 2(Recall) | 17.52 | 73.60 | 17.52 | 73.60 | 12.38 | 67.76 | 2.57 | 23.83 |
| 2(AP) | 54.99 | 90.52 | 27.04 | 83.92 | 11.69 | 66.71 | 2.57 | 23.83 |
| 4(Recall) | 18.22 | 73.83 | 18.22 | 73.83 | 14.02 | 66.12 | 2.80 | 27.10 |
| 4(AP) | 57.89 | 90.72 | 29.53 | 84.37 | 13.29 | 65.00 | 2.80 | 27.09 |
| 8(Recall) | 21.50 | 70.33 | 21.50 | 70.33 | 17.99 | 64.49 | 4.21 | 25.23 |
| 8(AP) | 63.84 | 88.53 | 37.24 | 82.46 | 17.09 | 63.12 | 4.21 | 25.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, W.; Chen, Z.; Tian, W.; Wu, Y.; Hua, B. A Cascade Defense Method for Multidomain Adversarial Attacks under Remote Sensing Detection. Remote Sens. 2022, 14, 3559. https://doi.org/10.3390/rs14153559
Xue W, Chen Z, Tian W, Wu Y, Hua B. A Cascade Defense Method for Multidomain Adversarial Attacks under Remote Sensing Detection. Remote Sensing. 2022; 14(15):3559. https://doi.org/10.3390/rs14153559
Chicago/Turabian StyleXue, Wei, Zhiming Chen, Weiwei Tian, Yunhua Wu, and Bing Hua. 2022. "A Cascade Defense Method for Multidomain Adversarial Attacks under Remote Sensing Detection" Remote Sensing 14, no. 15: 3559. https://doi.org/10.3390/rs14153559
APA StyleXue, W., Chen, Z., Tian, W., Wu, Y., & Hua, B. (2022). A Cascade Defense Method for Multidomain Adversarial Attacks under Remote Sensing Detection. Remote Sensing, 14(15), 3559. https://doi.org/10.3390/rs14153559