
Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility




Abstract
:1. Introduction
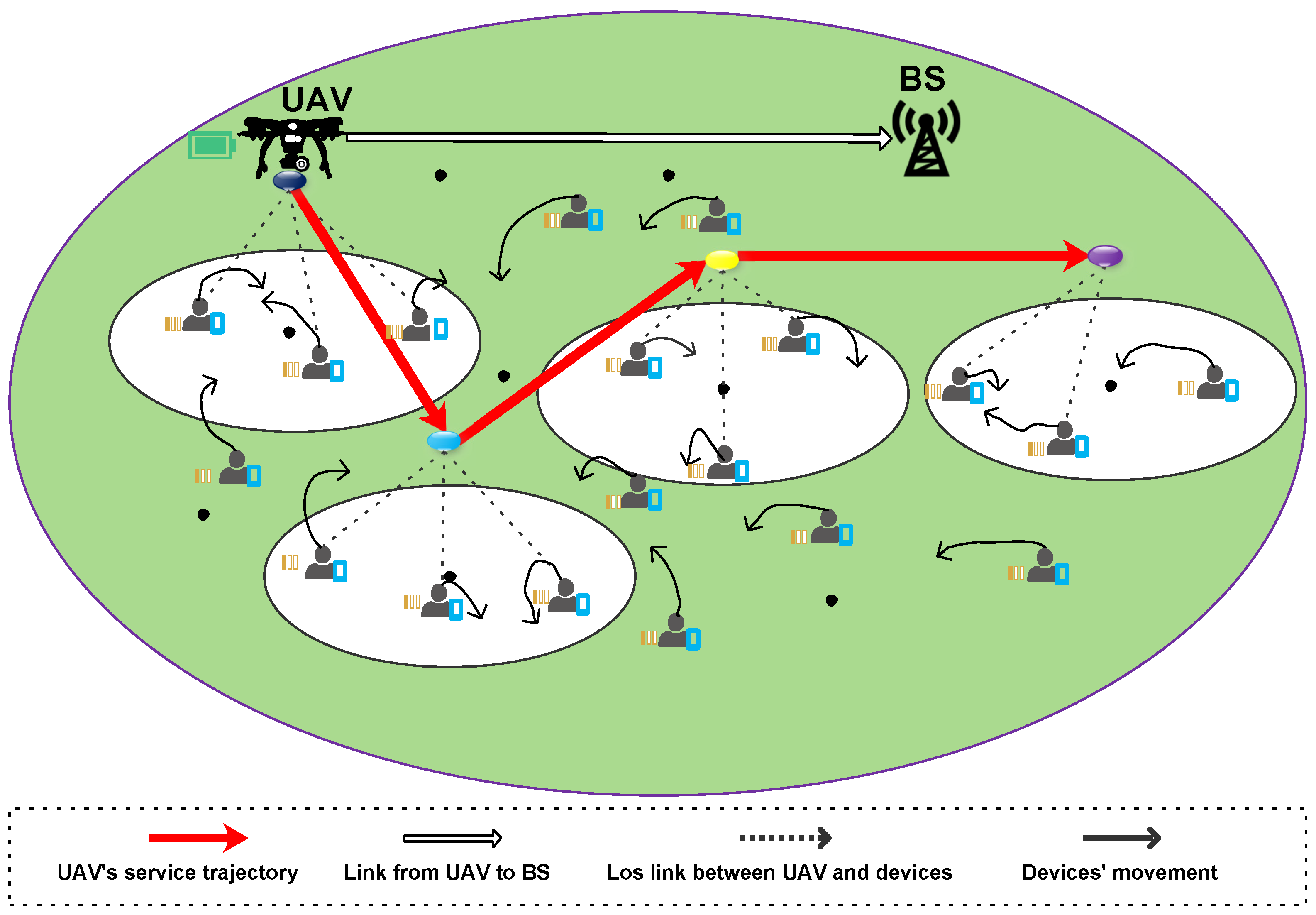
- We study a UAV-assisted MEC network with device mobility, in which an energy-constrained UAV as a relay station collects and forwards the computing task of mobile devices within its serviceable area to a faraway base station to be remotely executed.
- The path planning problem is formulated to simultaneously minimize the energy consumption of the UAV and the averaged AoI by optimizing the service path of the UAV. Considering the dimension explosion issue caused by the enormous state space, a freshness-aware path planning scheme based on double deep Q-learning network (DDQN) algorithm is proposed to optimize the trajectory of the UAV intelligently.
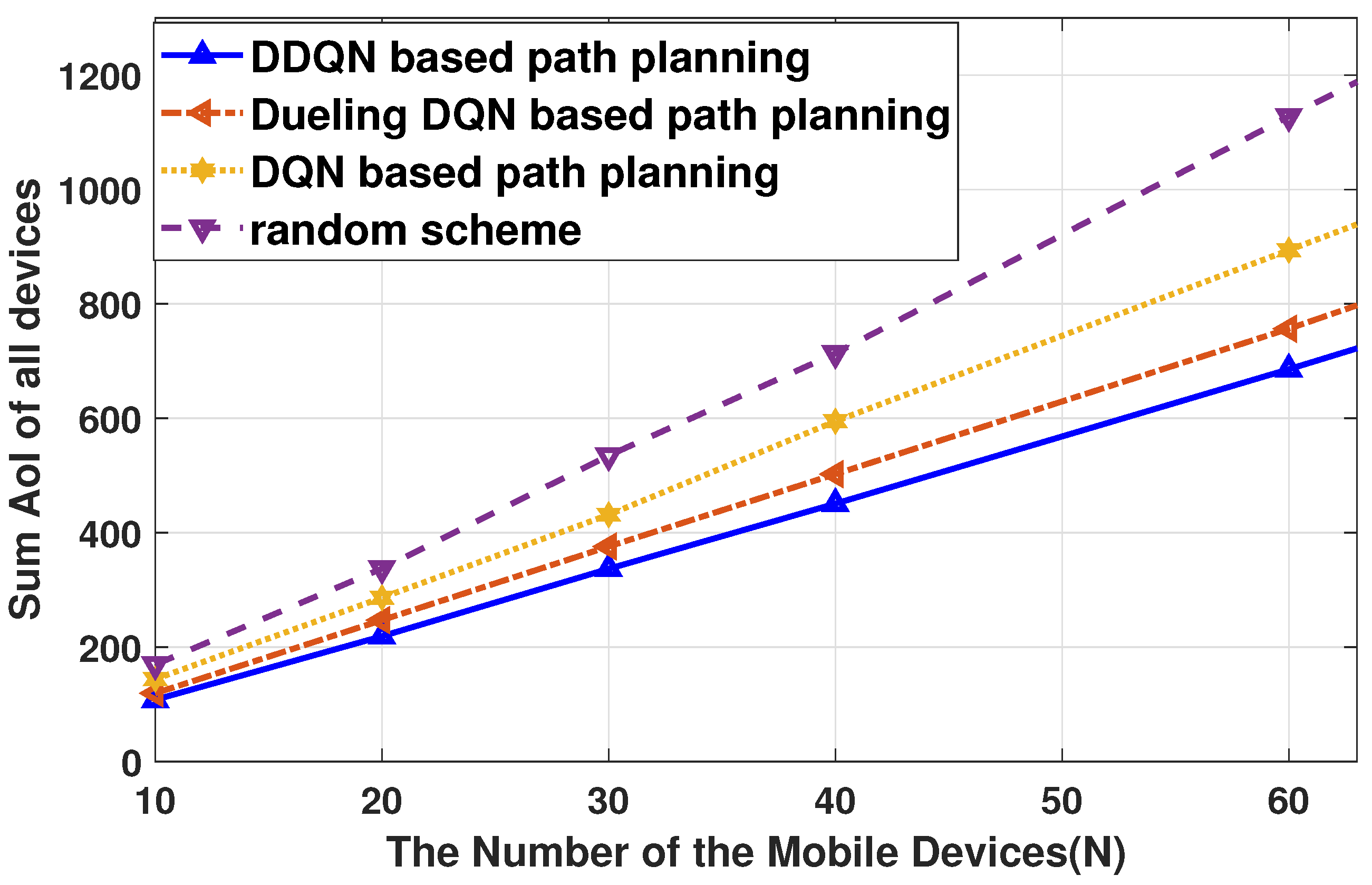
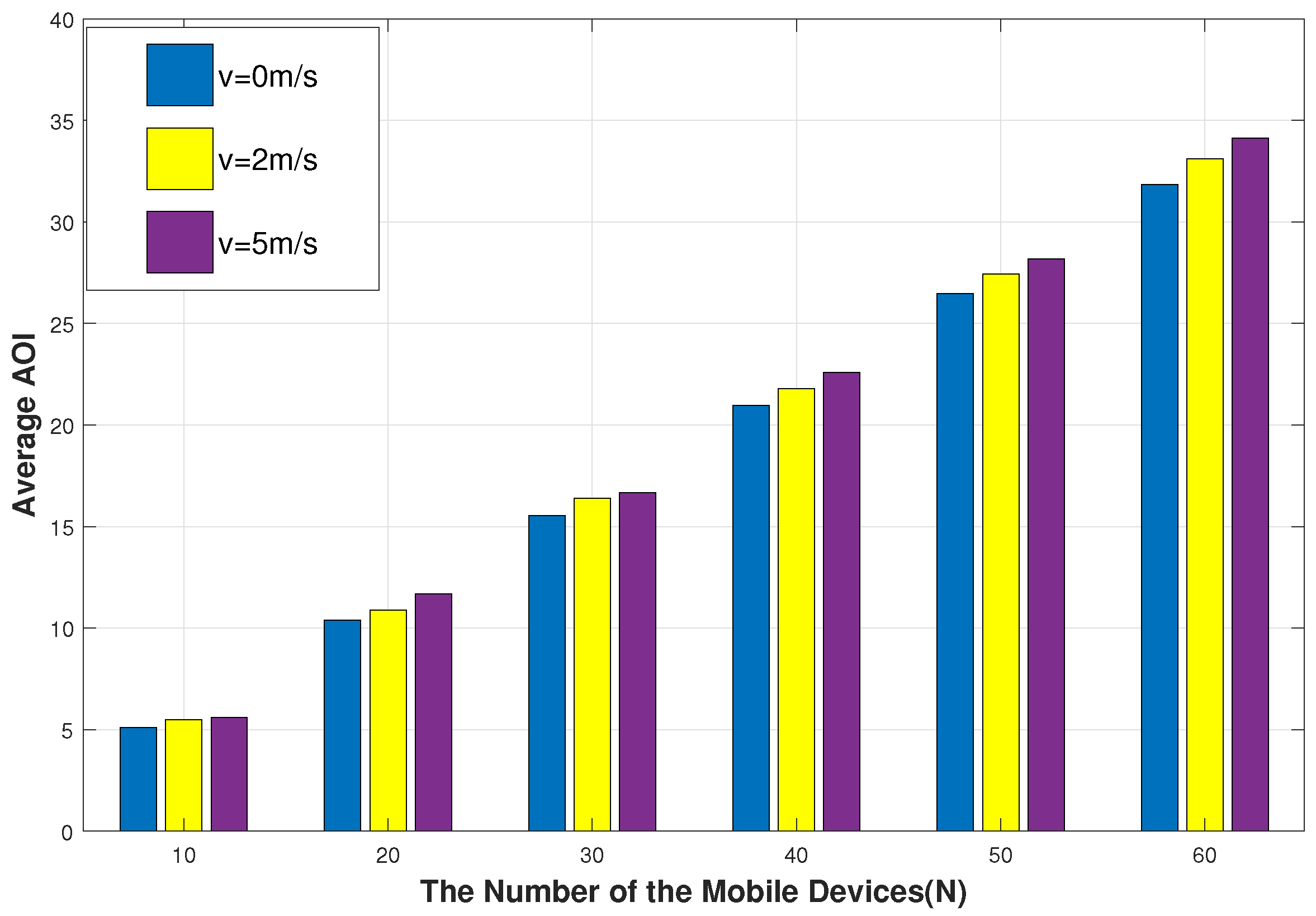
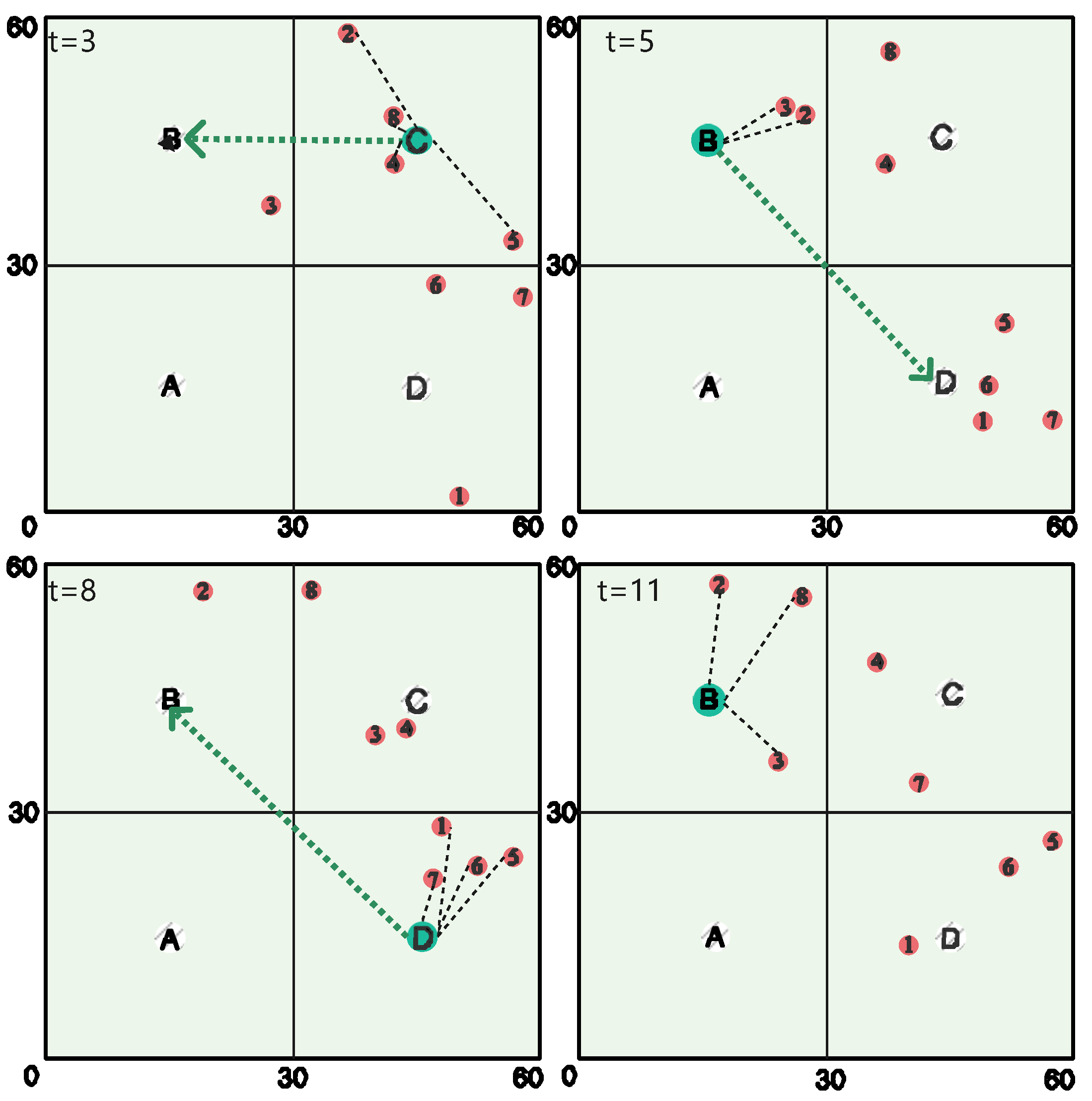
- Extensive experiments are conducted to validate that the proposed freshness-aware path planning scheme performs better than the conventional schemes. Meanwhile, the effects of the moving speed of the UAV and mobile devices on the achieved AoI are unveiled. We further present the example of devices’ AoI evolution and the UAV’s service trajectory.
2. Related Works
3. System Model and Problem Formulation
3.1. System Model
3.2. Movement Model
3.3. Communication Model
3.4. Energy Consumption
3.4.1. Flying Energy Consumption
3.4.2. Hovering Energy Consumption
3.4.3. Relaying Energy Consumption
3.5. Age of Information
3.6. Problem Formulation
4. Deep Reinforcement Learning Dased Freshness-Aware Path Planning
4.1. Reinforcement Learning Reformulation
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward Function
4.2. Double Deep Q Learning Network
4.3. Training Process
| Algorithm 1 DDQN-based freshness-aware path planning |
|
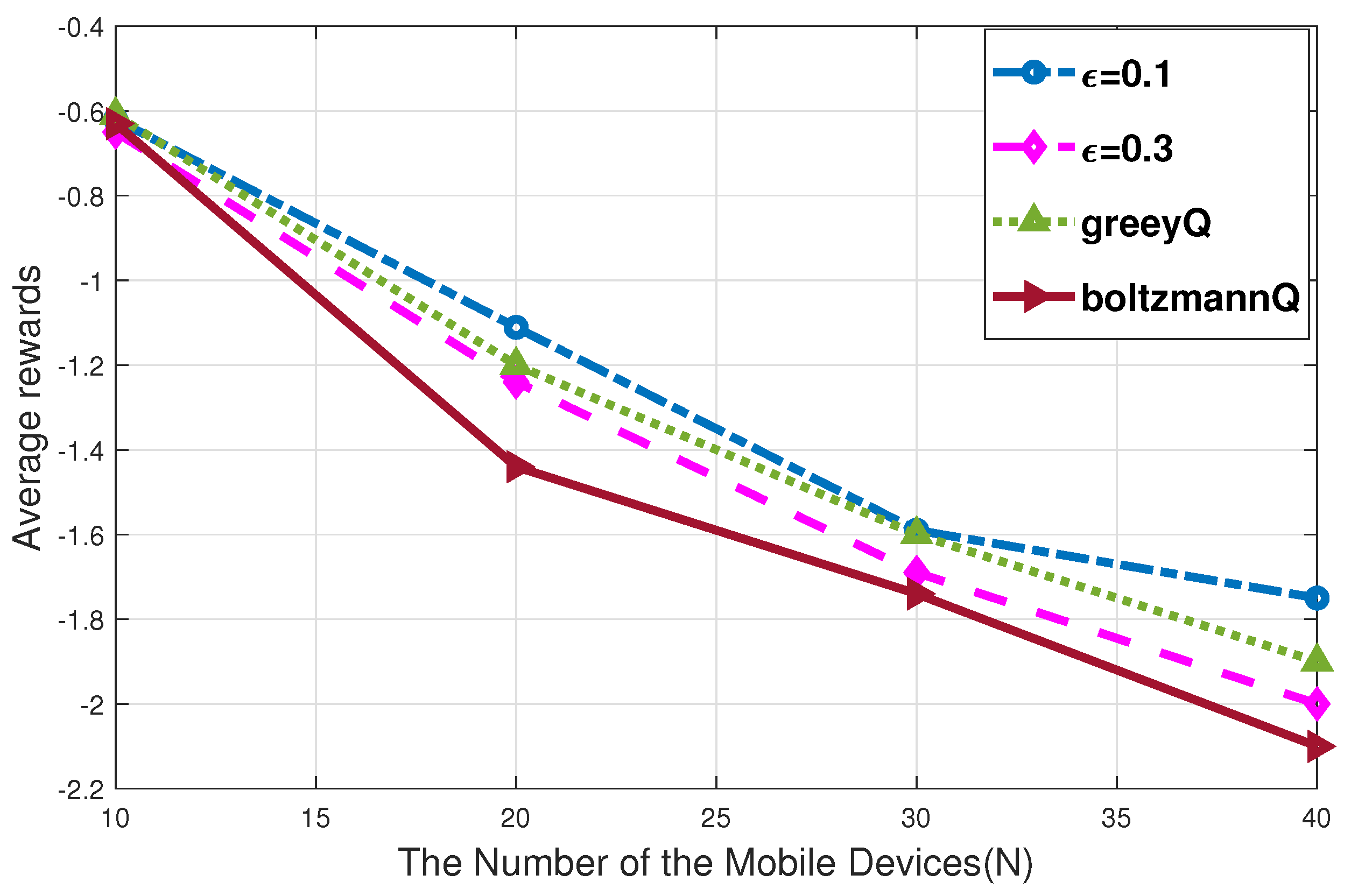
5. Experiments and Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Barbarossa, S.; Sardellitti, S.; Di Lorenzo, P. Communicating While Computing: Distributed mobile cloud computing over 5G heterogeneous networks. IEEE Signal Process. Mag. 2014, 31, 45–55. [Google Scholar] [CrossRef]
- Mahmood, A.; Hong, Y.; Ehsan, M.K.; Mumtaz, S. Optimal Resource Allocation and Task Segmentation in IoT Enabled Mobile Edge Cloud. IEEE Trans. Vehicular Technol. 2021, 70, 13294–13303. [Google Scholar] [CrossRef]
- Liu, J.; Ahmed, M.; Mirza, M.A.; Khan, W.U.; Xu, D.; Li, J.; Han, Z. RL/DRL meets vehicular task offloading using edge and vehicular cloudlet: A survey. IEEE Internet Things J. 2022, 9, 8315–8338. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Wan, S.; Lu, J.; Fan, P.; Letaief, K.B. Toward Big Data Processing in IoT: Path Planning and Resource Management of UAV Base Stations in Mobile-Edge Computing System. IEEE Internet Things J. 2020, 7, 5995–6009. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Bagaa, M.; Taleb, T. UAV-Based IoT Platform: A Crowd Surveillance Use Case. IEEE Commun. Mag. 2017, 55, 128–134. [Google Scholar] [CrossRef]
- Tun, Y.K.; Park, Y.M.; Tran, N.H.; Saad, W.; Pandey, S.R.; Hong, C.S. Energy-Efficient Resource Management in UAV-Assisted Mobile Edge Computing. IEEE Commun. Lett. 2021, 25, 249–253. [Google Scholar] [CrossRef]
- Zhou, Y.; Pan, C.; Yeoh, P.L.; Wang, K.; Elkashlan, M.; Vucetic, B.; Li, Y. Secure Communications for UAV-Enabled Mobile Edge Computing Systems. IEEE Trans. Commun. 2020, 68, 376–388. [Google Scholar] [CrossRef]
- Jeong, S.; Simeone, O.; Kang, J. Mobile Edge Computing via a UAV-Mounted Cloudlet: Optimization of Bit Allocation and Path Planning. IEEE Trans. Veh. Technol. 2018, 67, 2049–2063. [Google Scholar] [CrossRef]
- Liu, Q.; Shi, L.; Sun, L.; Li, J.; Ding, M.; Shu, F. Path Planning for UAV-Mounted Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 5723–5728. [Google Scholar] [CrossRef]
- Ma, X.; Zhou, A.; Sun, Q.; Wang, S. Freshness-Aware Information Update and Computation Offloading in Mobile-Edge Computing. IEEE Internet Things J. 2021, 8, 13115–13125. [Google Scholar] [CrossRef]
- Zhou, B.; Saad, W. Minimum Age of Information in the Internet of Things with Non-Uniform Status Packet Sizes. IEEE Trans. Wirel. Commun. 2020, 19, 1933–1947. [Google Scholar] [CrossRef]
- Corneo, L.; Rohner, C.; Gunningberg, P. Age of Information-Aware Scheduling for Timely and Scalable Internet of Things Applications. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2476–2484. [Google Scholar]
- Zhou, C.; He, H.; Yang, P.; Lyu, F.; Wu, W.; Cheng, N.; Shen, X. Deep RL-based Trajectory Planning for AoI Minimization in UAV-assisted IoT. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Li, W.; Wang, L.; Fei, A. Minimizing Packet Expiration Loss with Path Planning in UAV-Assisted Data Sensing. IEEE Wirel. Commun. Lett. 2019, 8, 1520–1523. [Google Scholar] [CrossRef]
- Hu, H.; Xiong, K.; Qu, G.; Ni, Q.; Fan, P.; Letaief, K.B. AoI-Minimal Trajectory Planning and Data Collection in UAV-Assisted Wireless Powered IoT Networks. IEEE Internet Things J. 2021, 8, 1211–1223. [Google Scholar] [CrossRef]
- Tong, P.; Liu, J.; Wang, X.; Bai, B.; Dai, H. Deep Reinforcement Learning for Efficient Data Collection in UAV-Aided Internet of Things. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Han, R.; Wang, J.; Bai, L.; Liu, J.; Choi, J. Age of Information and Performance Analysis for UAV-Aided IoT Systems. IEEE Internet Things J. 2021, 8, 14447–14457. [Google Scholar] [CrossRef]
- Kumar, K.; Liu, J.; Lu, Y.H.; Bhargava, B. A survey of computation offloading for mobile systems. Mob. Netw. Appl. 2013, 18, 129–140. [Google Scholar] [CrossRef]
- Wang, J.; Amos, B.; Das, A.; Pillai, P.; Sadeh, N.; Satyanarayanan, M. A scalable and privacy-aware IoT service for live video analytics. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; pp. 38–49. [Google Scholar] [CrossRef]
- Billinghurst, M.; Clark, A.; Lee, G. A survey of augmented reality. Found. Trends Hum. Comput. Interact. 2015, 8, 73–272. [Google Scholar] [CrossRef]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Liu, Y.; Li, D.; Du, B.; Shu, L.; Han, G. Rethinking Sustainable Sensing in Agricultural Internet of Things: From Power Supply Perspective. IEEE Wirel. Commun. 2022, 1–8. [Google Scholar] [CrossRef]
- Cao, X.; Yang, P.; Alzenad, M.; Xi, X.; Wu, D.; Yanikomeroglu, H. Airborne Communication Networks: A Survey. IEEE J. Sel. Areas Commun. 2018, 36, 1907–1926. [Google Scholar] [CrossRef]
- Mozaffari, M.; Saad, W.; Bennis, M.; Nam, Y.H.; Debbah, M. A Tutorial on UAVs for Wireless Networks: Applications, Challenges, and Open Problems. IEEE Commun. Surv. Tutor. 2019, 21, 2334–2360. [Google Scholar] [CrossRef]
- Haider, S.K.; Jiang, A.; Almogren, A.; Rehman, A.U.; Ahmed, A.; Khan, W.U. Hamam, H. Energy efficient UAV flight path model for cluster head selection in next-generation wireless sensor networks. Sensors 2021, 21, 8445. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Gong, Y.; Gong, S.; Guo, Y. Joint Task Offloading and Resource Allocation in UAV-Enabled Mobile Edge Computing. IEEE Internet Things J. 2020, 7, 3147–3159. [Google Scholar] [CrossRef]
- Jameel, F.; Javaid, U.; Khan, W.U.; Aman, M.N.; Pervaiz, H.; Jäntti, R. Reinforcement learning in blockchain-enabled IIoT networks: A survey of recent advances and open challenges. Sustainability 2020, 12, 5161. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Wu, C.; Mao, S.; Ji, Y.; Bennis, M. Optimized Computation Offloading Performance in Virtual Edge Computing Systems Via Deep Reinforcement Learning. IEEE Internet Things J. 2019, 6, 4005–4018. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep reinforcement learning for dynamic computation offloading and resource allocation in cache-assisted mobile edge computing systems. Intell. Converged Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef]
- Kosta, A.; Pappas, N.; Angelakis, V. Age of information: A new concept, metric, and tool. Found. Trends Netw. 2017, 12, 162–259. [Google Scholar] [CrossRef]
- Sun, Y.; Kadota, I.; Talak, R.; Modiano, E. Age of information: A new metric for information freshness. Synth. Lect. Commun. Netw. 2019, 12, 1–224. [Google Scholar]
- Tripathi, V.; Talak, R.; Modiano, E. Age optimal information gathering and dissemination on graphs. IEEE Trans. Mob. Comput. 2021, 1–14. [Google Scholar] [CrossRef]
- Abd-Elmagid, M.A.; Ferdowsi, A.; Dhillon, H.S.; Saad, W. Deep Reinforcement Learning for Minimizing Age-of-Information in UAV-Assisted Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Abd-Elmagid, M.A.; Dhillon, H.S. Average Peak Age-of-Information Minimization in UAV- Assisted IoT Networks. IEEE Trans. Veh. Technol. 2019, 68, 2003–2008. [Google Scholar] [CrossRef]
- Jia, Z.; Qin, X.; Wang, Z.; Liu, B. Age-Based Path Planning and Data Acquisition in UAV-Assisted IoT Networks. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Kuang, Q.; Gong, J.; Chen, X.; Ma, X. Analysis on Computation-Intensive Status Update in Mobile Edge Computing. IEEE Trans. Veh. Technol. 2020, 69, 4353–4366. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Hu, X.; Guo, L.; Hu, B.; Guo, Y.; Qiu, T.; Kwok, R.Y.K. Mobile Edge Computing Enabled 5G Health Monitoring for Internet of Medical Things: A Decentralized Game Theoretic Approach. IEEE J. Sel. Areas Commun. 2021, 39, 463–478. [Google Scholar] [CrossRef]
- Jung, H.; Ko, S.-W. Performance Analysis of UAV-Enabled Over-the-Air Computation Under Imperfect Channel Estimation. IEEE Wirel. Commun. Lett. 2022, 11, 438–442. [Google Scholar] [CrossRef]
- Khan, W.U.; Jamshed, M.A.; Lagunas, E.; Chatzinotas, S.; Li, X.; Ottersten, B. Energy Efficiency Optimization for Backscatter Enhanced NOMA Cooperative V2X Communications Under Imperfect CSI. IEEE Trans. Intell. Transp. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Ihsan, A.; Chen, W.; Khan, W.U.; Wu, Q.; Wang, K. Energy-Efficient Backscatter Aided Uplink NOMA Roadside Sensor Communications under Channel Estimation Errors. arXiv 2021, arXiv:2109.05341. [Google Scholar]
- Batabyal, S.; Bhaumik, P. Mobility models, traces and impact of mobility on opportunistic routing algorithms: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 1679–1707. [Google Scholar] [CrossRef]
- Yang, Z.; Pan, C.; Wang, K.; Shikh-Bahaei, M. Energy efficient resource allocation in UAV-enabled mobile edge computing networks. IEEE Trans. Wirel. Commun. 2019, 18, 4576–4589. [Google Scholar] [CrossRef]
- Mozaffari, M.; Saad, W.; Bennis, M.; Debbah, M. Mobile Unmanned Aerial Vehicles (UAVs) for Energy-Efficient Internet of Things Communications. IEEE Trans. Wirel. Commun. 2017, 16, 7574–7589. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Omidshafiei, S.; Pazis, J.; Amato, C.; How, J.P.; Vian, J. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2681–2690. [Google Scholar]
- Foerster, J.; Nardelli, N.; Farquhar, G.; Afouras, T.; Torr, P.H.; Kohli, P.; Whiteson, S. Stabilising experience replay for deep multi-agent reinforcement learning. International conference on machine learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1146–1155. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1995–2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| N | Number of IoT devices |
| Communication time of the UAV | |
| Number of bits in a task | |
| p | Probability of task generation |
| Indicate whether the UAV is flying or hovering | |
| Position of device n in the time slot t | |
| Position of the UAV in the time slot t | |
| The distance between device n and UAV in the time slot t | |
| H | The height of the UAV from the ground |
| The maximum angle from the UAV and the edge of its coverage area | |
| Indicate whether device n is in the association area in the time slot t | |
| Indicate the active status of device n in the time slot t | |
| The amount of unloaded task at the time slot t | |
| Flight power of UAV | |
| L | The flying distance of the UAV |
| V | The flying speed of a UAV |
| Hovering power of UAV | |
| B | System bandwidth |
| Noise power spectral density | |
| Path loss per meter | |
| The position of the BS | |
| Relay forwarding time | |
| The energy status of the UAV in The time slot t | |
| The AoI of device n in the time slot t | |
| Initial energy of UAV | |
| The time interval of two successive computing tasks generated |
| Symbol Notations | Parameter |
|---|---|
| Number of access points | |
| Initial energy of UAV | J |
| Flying speed of UAV | m/s |
| Reference Path loss | dB |
| Hovering power consumption | W |
| Flying power consumption | W |
| Relay forwarding time | s |
| System bandwidth | MHz |
| Noise power spectral density | W/Hz |
| Communication time of the UAV | s |
| Maximum angle from UAV and the edge of its coverage area | |
| Probability of task generation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Liu, Y.; Li, D.; Zhang, H. Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sens. 2022, 14, 4016. https://doi.org/10.3390/rs14164016
Peng Y, Liu Y, Li D, Zhang H. Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sensing. 2022; 14(16):4016. https://doi.org/10.3390/rs14164016
Chicago/Turabian StylePeng, Yingsheng, Yong Liu, Dong Li, and Han Zhang. 2022. "Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility" Remote Sensing 14, no. 16: 4016. https://doi.org/10.3390/rs14164016
APA StylePeng, Y., Liu, Y., Li, D., & Zhang, H. (2022). Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sensing, 14(16), 4016. https://doi.org/10.3390/rs14164016