
RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation




Abstract
:
1. Introduction
- A random graph module is proposed which randomly constructs adjacency graphs for data augmentation.
- A feature extraction module is proposed which can learn local significant features of a point cloud by aggregating point spatial information and multidimensional features.
- A graph-based network (RG-GCN) is proposed for 3D point cloud semantic segmentation which achieves excellent performance in S3DIS and Toronto3D regardless of whether training samples are sufficient or insufficient.
2. Related Works
2.1. Projection-Based and Voxel-Based Methods
2.2. Point-Based Method
2.3. Graph-Based Method
2.4. Data Augmentation Method
3. Method
3.1. Random Graph Module
3.2. Feature Extraction Module
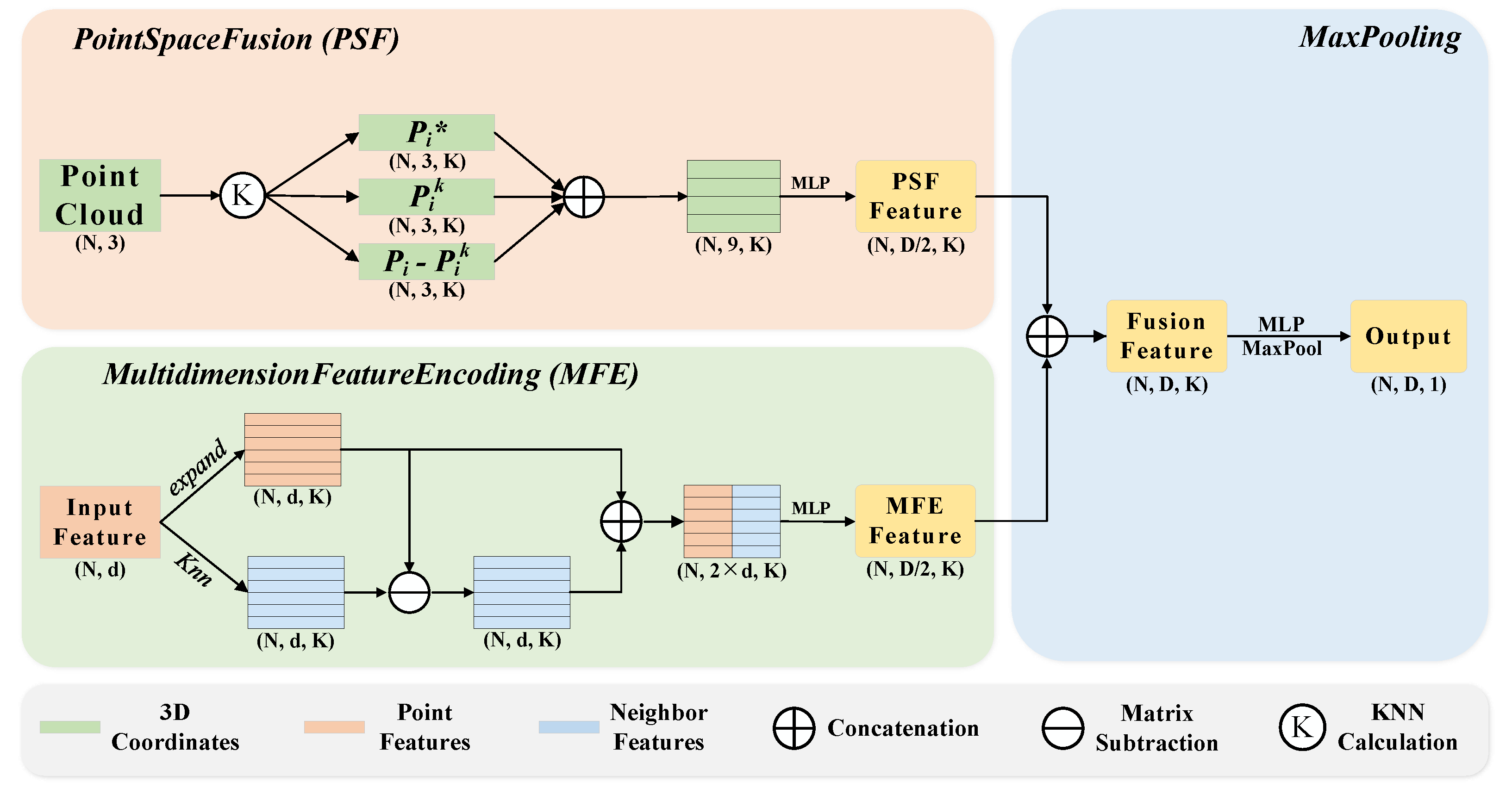
3.2.1. Point Space Fusion
3.2.2. Multidimension Feature Encoding
3.2.3. Max Pooling
3.3. Network Architecture
4. Experiments and Discussion
4.1. Experimental Setting
4.2. Indoor Scene Segmentation
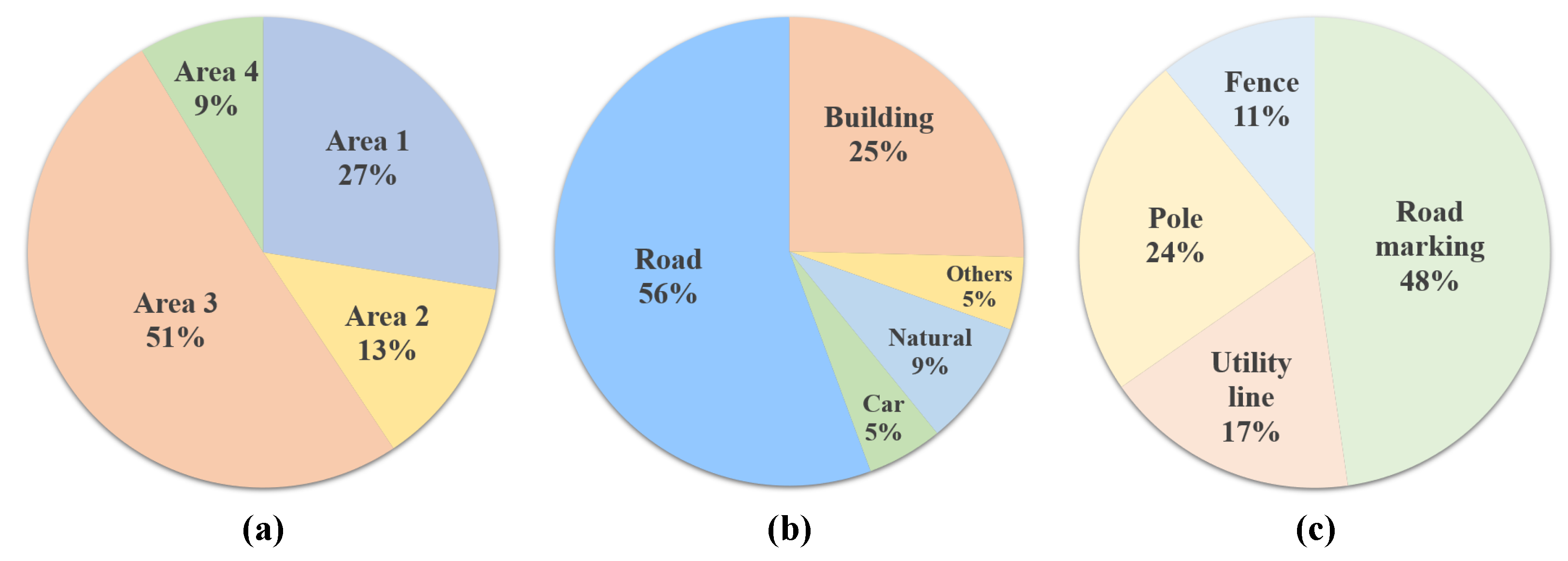
4.2.1. Dataset Description
4.2.2. Results and Visualization with Sufficient Training Samples
4.2.3. Results and Visualization with Insufficient Training Samples
4.3. Outdoor Scene Segmentation
4.3.1. Dataset Description
4.3.2. Results and Visualization with Sufficient Training Samples
4.3.3. Results and Visualization with Insufficient Training Samples
4.4. Ablation Study
4.4.1. Effectiveness and Performance of the Random Graph Module
4.4.2. Effectiveness of the Feature Extraction Module
4.4.3. Exploration of the Number of PGCN Modules
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D Mapping With an RGB-D Camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Xu, Y.; Xie, Z.; Tang, W.; Wan, J.; Wu, W. LEARD-Net: Semantic Segmentation for Large-Scale Point Cloud Scene. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102953. [Google Scholar] [CrossRef]
- Han, X.; Dong, Z.; Yang, B. A point-based deep learning network for semantic segmentation of MLS point clouds. Isprs J. Photogramm. Remote. Sens. 2021, 175, 199–214. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph 2019, 38, 146. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Li, G.; Müller, M.; Thabet, A.; Ghanem, B. DeepGCNs: Can GCNs Go As Deep As CNNs? In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Hu, B.; Xu, Y.; Wan, B.; Wu, X.; Yi, G. Hydrothermally altered mineral mapping using synthetic application of Sentinel-2A MSI, ASTER and Hyperion data in the Duolong area, Tibetan Plateau, China. Ore Geol. Rev. 2018, 101, 384–397. [Google Scholar] [CrossRef]
- Hu, B.; Wan, B.; Xu, Y.; Tao, L.; Wu, X.; Qiu, Q.; Wu, Y.; Deng, H. Mapping hydrothermally altered minerals with AST_07XT, AST_05 and Hyperion datasets using a voting-based extreme learning machine algorithm. Ore Geol. Rev. 2019, 114, 103116. [Google Scholar] [CrossRef]
- Hu, B.; Xu, Y.; Huang, X.; Cheng, Q.; Ding, Q.; Bai, L.; Li, Y. Improving Urban Land Cover Classification with Combined Use of Sentinel-2 and Sentinel-1 Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 533. [Google Scholar] [CrossRef]
- Xu, Y.; He, Z.; Xie, X.; Xie, Z.; Luo, J.; Xie, H. Building function classification in Nanjing, China, using deep learning. Trans. Gis 2022, 26, 2145–2165. [Google Scholar] [CrossRef]
- Zou, L.; Tang, H.; Chen, K.; Jia, K. Geometry-Aware Self-Training for Unsupervised Domain Adaptation on Object Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Poursaeed, O.; Jiang, T.; Qiao, H.; Xu, N.; Kim, V.G. Self-Supervised Learning of Point Clouds via Orientation Estimation. In Proceedings of the International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Xu, Y.; Jin, S.; Chen, Z.; Xie, X.; Hu, S.; Xie, Z. Application of a graph convolutional network with visual and semantic features to classify urban scenes. Int. J. Geogr. Inf. Sci. 2022, 1–26. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhao, N.; Chua, T.S.; Lee, G.H. Few-shot 3d point cloud semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, R.; Li, X.; Heng, P.-A.; Fu, C.-W. PointAugment: An Auto-Augmentation Framework for Point Cloud Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Candad, 8–13 December 2014. [Google Scholar]
- Zhou, J.; Shen, J.; Yu, S.; Chen, G.; Xuan, Q. M-Evolve: Structural-Mapping-Based Data Augmentation for Graph Classification. IEEE Trans. Netw. Sci. Eng. 2021, 8, 190–200. [Google Scholar] [CrossRef]
- Wu, W.; Xie, Z.; Xu, Y.; Zeng, Z.; Wan, J. Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture. Remote. Sens. 2021, 13, 4917. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-view Harmonized Bilinear Network for 3D Object Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Le, T.; Duan, Y. PointGrid: A Deep Network for 3D Shape Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Zeng, Z.; Yuan, D.; Qiu, Q. DGANet: A Dilated Graph Attention-Based Network for Local Feature Extraction on 3D Point Clouds. Remote. Sens. 2021, 13, 3484. [Google Scholar] [CrossRef]
- Xu, Q.; Sun, X.; Wu, C.-Y.; Wang, P.; Neumann, U. Grid-GCN for Fast and Scalable Point Cloud Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, J.; Ni, B.; Li, C.; Yang, J.; Tian, Q. Dynamic Points Agglomeration for Hierarchical Point Sets Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Landrieu, L.; Boussaha, M. Point Cloud Oversegmentation With Graph-Structured Deep Metric Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A Bayesian Data Augmentation Approach for Learning Deep Models. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart Augmentation Learning an Optimal Data Augmentation Strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph Contrastive Learning with Augmentations. In Proceedings of the Neural Information Processing Systems, online, 6–12 December 2020. [Google Scholar]
- Tang, Z.; Qiao, Z.; Hong, X.; Wang, Y.; Dharejo, F.A.; Zhou, Y.; Du, Y. Data Augmentation for Graph Convolutional Network on Semi-Supervised Classification. In Proceedings of the Web and Big Data, Guangzhou, China, 23–25 August 2021. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fische, M.; Savares, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent Slice Networks for 3D Segmentation of Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3D Recurrent Neural Networks with Context Fusion for Point Cloud Semantic Segmentation. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Z.; Hua, B.-S.; Yeung, S.-K. ShellNet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ma, L.; Li, Y.; Li, J.; Tan, W.; Yu, Y.; Chapman, M.A. Multi-Scale Point-Wise Convolutional Neural Networks for 3D Object Segmentation From LiDAR Point Clouds in Large-Scale Environments. IEEE Trans. Intell. Transp. Syst. 2021, 22, 821–836. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Cao, D.; Li, J. TGNet: Geometric Graph CNN on 3-D Point Cloud Segmentation. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 3588–3600. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [6] | 78.6 | 47.6 | 88.0 | 88.7 | 69.3 | 42.4 | 23.1 | 47.5 | 51.6 | 54.1 | 42.0 | 9.6 | 38.2 | 29.4 | 35.2 |
| RSNet [45] | - | 56.5 | 92.5 | 92.8 | 78.6 | 32.8 | 34.4 | 51.6 | 68.1 | 59.7 | 60.1 | 16.4 | 50.2 | 44.9 | 52.0 |
| 3P-RNN [46] | 86.9 | 56.3 | 92.9 | 93.8 | 73.1 | 42.5 | 25.9 | 47.6 | 59.2 | 60.4 | 66.7 | 24.8 | 57.0 | 36.7 | 51.6 |
| SPG [37] | 86.4 | 62.1 | 89.9 | 95.1 | 76.4 | 62.8 | 47.1 | 55.3 | 68.4 | 73.5 | 69.2 | 63.2 | 45.9 | 8.7 | 52.9 |
| ShellNet [47] | 87.1 | 66.8 | 90.2 | 93.6 | 79.9 | 60.4 | 44.1 | 64.9 | 52.9 | 71.6 | 84.7 | 53.8 | 64.6 | 48.6 | 59.4 |
| RandLA-Net [9] | 88.0 | 70.0 | 93.1 | 96.1 | 80.6 | 62.4 | 48.0 | 64.4 | 69.4 | 69.4 | 76.4 | 60.0 | 64.2 | 65.9 | 60.1 |
| DeepGCNs [12] | 85.9 | 60.0 | 93.1 | 95.3 | 78.2 | 33.9 | 37.4 | 56.1 | 68.2 | 64.9 | 61.0 | 34.6 | 51.5 | 51.1 | 54.4 |
| DGCNN [8] | 84.5 | 55.5 | 93.2 | 95.9 | 72.8 | 54.6 | 32.2 | 56.2 | 50.7 | 62.8 | 63.4 | 22.7 | 38.2 | 32.5 | 46.8 |
| RG-GCN (Ours) | 88.1 | 63.7 | 94.0 | 96.2 | 79.1 | 60.4 | 44.3 | 60.1 | 65.9 | 70.8 | 64.9 | 30.8 | 51.9 | 52.6 | 56.4 |
| Method | OA | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [6] | 66.8 | 31.4 | 74.6 | 81.0 | 56.7 | 14.5 | 6.7 | 17.9 | 31.9 | 39.3 | 28.9 | 1.7 | 23.7 | 8.9 | 23.1 |
| PointNet++ [7] | 75.6 | 38.8 | 85.6 | 90.5 | 65.9 | 16.4 | 6.4 | 3.4 | 36.2 | 55.8 | 51.9 | 4.9 | 35.8 | 20.8 | 31.1 |
| DGCNN [8] | 76.4 | 38.3 | 88.0 | 89.5 | 63.8 | 21.0 | 12.2 | 21.2 | 36.8 | 50.4 | 39.6 | 3.4 | 29.4 | 9.5 | 33.7 |
| KPConv [11] | 80.2 | 43.6 | 83.8 | 89.1 | 65.3 | 11.0 | 20.8 | 27.7 | 31.5 | 51.4 | 52.3 | 25.3 | 28.4 | 40.4 | 40.0 |
| RandLA-Net [9] | 80.5 | 48.2 | 88.8 | 92.0 | 68.4 | 28.5 | 20.2 | 38.1 | 44.3 | 51.8 | 49.5 | 25.4 | 34.8 | 42.2 | 42.7 |
| DeepGCNs [12] | 78.8 | 40.4 | 89.5 | 90.5 | 57.5 | 26.5 | 19.2 | 34.9 | 38.5 | 52.1 | 32.1 | 1.3 | 32.4 | 17.4 | 33.0 |
| RG-GCN (Ours) | 81.1 | 45.8 | 89.3 | 92.9 | 70.1 | 26.7 | 13.8 | 33.6 | 43.0 | 57.6 | 51.1 | 14.8 | 37.0 | 23.6 | 41.2 |
| Method | OA | mIoU | Road | Road mrk. | Nature | Buil. | Util. Line | Pole | Car | Fence |
|---|---|---|---|---|---|---|---|---|---|---|
| PointNet++ [7] | 92.6 | 59.5 | 92.9 | 0.0 | 86.1 | 82.2 | 60.9 | 62.8 | 76.4 | 14.4 |
| MS-PCNN [48] | 90.0 | 65.9 | 93.8 | 3.8 | 93.5 | 82.6 | 67.8 | 71.9 | 91.1 | 22.5 |
| TGNet [49] | 94.1 | 61.3 | 93.5 | 0.0 | 90.8 | 81.6 | 65.3 | 62.9 | 88.7 | 7.9 |
| MS-TGNet [44] | 95.7 | 70.5 | 94.4 | 17.2 | 95.7 | 88.8 | 76.0 | 73.9 | 94.2 | 23.6 |
| DeepGCNs [12] | 94.8 | 67.1 | 94.2 | 33.8 | 91.2 | 85.3 | 65.7 | 62.9 | 73.6 | 30.4 |
| KPConv [11] | 95.4 | 69.1 | 94.6 | 0.1 | 96.1 | 91.5 | 87.7 | 81.6 | 85.7 | 15.7 |
| RandLA-Net [9] | 92.9 | 77.7 | 94.6 | 42.6 | 96.9 | 93.0 | 86.5 | 78.0 | 92.9 | 37.1 |
| DGCNN [8] | 94.2 | 61.7 | 93.9 | 0.0 | 91.3 | 80.4 | 62.4 | 62.3 | 88.3 | 15.8 |
| RG-GCN (Ours) | 96.5 | 74.5 | 98.2 | 79.4 | 91.8 | 86.1 | 72.4 | 69.9 | 82.1 | 16.0 |
| Method | OA | mIoU | Road | Road mrk. | Nature | Buil. | Util. Line | Pole | Car | Fence |
|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [6] | 71.6 | 24.0 | 79.9 | 0.4 | 29.4 | 63.8 | 7.1 | 7.6 | 3.2 | 0.7 |
| PointNet++ [7] | 77.1 | 35.2 | 84.4 | 0.0 | 39.2 | 65.8 | 29.1 | 19.3 | 35.6 | 8.2 |
| DGCNN [8] | 77.8 | 35.9 | 82.2 | 0.6 | 43.9 | 63.2 | 28.9 | 17.1 | 43.5 | 7.8 |
| DeepGCNs [12] | 82.2 | 40.2 | 86.7 | 15.8 | 47.8 | 66.7 | 25.5 | 24.9 | 41.6 | 12.4 |
| RandLA-Net [9] | 83.8 | 44.7 | 88.2 | 24.5 | 51.3 | 74.1 | 37.0 | 26.9 | 40.2 | 15.5 |
| RG-GCN (Ours) | 84.5 | 43.5 | 89.9 | 21.1 | 45.8 | 71.2 | 39.8 | 24.8 | 41.2 | 14.0 |
| Samples | Parameter | OA (%) | mAcc (%) | mIoU (%) | Times (ms) |
|---|---|---|---|---|---|
| sufficient | 92.1 | 85.4 | 76.7 | 554.7 | |
| 92.1 | 86.5 | 77.2 | 520.4 | ||
| 92.7 | 87.9 | 78.4 | 501.3 | ||
| 92.5 | 86.8 | 77.7 | 467.6 | ||
| 91.8 | 85.0 | 75.5 | 445.7 | ||
| 91.1 | 83.8 | 74.3 | 409.3 | ||
| 90.6 | 82.5 | 72.9 | 387.1 | ||
| sufficient | 91.8 | 85.4 | 75.2 | 232.8 | |
| 92.3 | 86.9 | 77.6 | 326.4 | ||
| 92.4 | 87.6 | 77.9 | 397.5 | ||
| 92.7 | 87.9 | 78.4 | 501.3 | ||
| 92.1 | 87.1 | 76.9 | 592.2 | ||
| 92.0 | 86.9 | 76.4 | 696.3 | ||
| 91.8 | 85.8 | 75.5 | 906.3 | ||
| insufficient | 81.1 | 60.7 | 48.8 | 547.4 | |
| 81.5 | 62.1 | 49.0 | 511.6 | ||
| 82.3 | 62.8 | 49.9 | 489.9 | ||
| 81.8 | 61.9 | 49.1 | 462.3 | ||
| 80.6 | 58.7 | 47.8 | 439.6 | ||
| 80.3 | 58.0 | 46.9 | 405.9 | ||
| 79.8 | 56.8 | 46.2 | 384.9 | ||
| insufficient | 79.7 | 60.1 | 46.1 | 228.4 | |
| 80.0 | 60.7 | 47.6 | 323.8 | ||
| 81.3 | 61.3 | 48.5 | 394.9 | ||
| 82.3 | 62.8 | 49.9 | 489.9 | ||
| 81.5 | 60.6 | 48.4 | 594.7 | ||
| 81.2 | 60.2 | 47.9 | 688.4 | ||
| 80.6 | 59.8 | 47.7 | 800.2 |
| Samples | Parameter | OA (%) | mAcc (%) | mIoU (%) |
|---|---|---|---|---|
| sufficient | non-FEM | 86.4 | 70.9 | 60.6 |
| with-FEM | 88.1 | 74.0 | 63.7 | |
| insufficient | non-FEM | 79.5 | 52.6 | 42.7 |
| with-FEM | 81.1 | 56.0 | 45.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z.; Xu, Y.; Xie, Z.; Wan, J.; Wu, W.; Dai, W. RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4055. https://doi.org/10.3390/rs14164055
Zeng Z, Xu Y, Xie Z, Wan J, Wu W, Dai W. RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation. Remote Sensing. 2022; 14(16):4055. https://doi.org/10.3390/rs14164055
Chicago/Turabian StyleZeng, Ziyin, Yongyang Xu, Zhong Xie, Jie Wan, Weichao Wu, and Wenxia Dai. 2022. "RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation" Remote Sensing 14, no. 16: 4055. https://doi.org/10.3390/rs14164055
APA StyleZeng, Z., Xu, Y., Xie, Z., Wan, J., Wu, W., & Dai, W. (2022). RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation. Remote Sensing, 14(16), 4055. https://doi.org/10.3390/rs14164055