1. Introduction
Automatic tree detection and counting using high-resolution remote sensing images has attracted the attention of a large number of researchers in recent decades. Information about the shape, localization, and health of trees in plantation areas are essential for intelligent agriculture to monitor the quality of tree growth. The image acquisition usually comes from satellites and Unmanned Aerial Vehicles (UAVs). Due to the rapid development of satellite and UAV technologies, abundant data have further promoted the development of related tree detection and counting technologies.
In general, most existing methods of tree detection and counting are concentrated on satellite images [
1,
2,
3,
4,
5]. Firstly, the whole large scale remote sensing image is split into hundreds of patches using the sliding window technique. Then classification or detection-based methods are used to detect and localize the targets. Finally, the detection results from individual patches are fused into the whole remote sensing image. The satellite technique is a powerful tool for monitoring tasks, including land cover change detection, fire monitoring, urban construction, natural disaster monitoring, etc. Recently, UAVs have become promising tools to obtain high quality images with low-cost, lightweight and high frequency usage, which have potentials for various analysis and monitoring domains, including environmental monitoring and analysis, precise and intelligent agriculture, and disease detection [
6]. However, what UAVs acquire with camera devices is a series of image data, and sequence image detection could result in a lot of duplication, which is not convenient and reduces detection efficiency and quality in large scale regions. Therefore, aerial image mapping is a necessary task before image analysis.
In recent decades, aerial image stitching has been used in lots of situations, such as agricultural plant protection, forest fire monitoring, forest tree counting, post-disaster assessment and military investigations. Generally, there are two ways to realize aerial image mosaicing tasks. One is offline mosaicing [
7,
8,
9], where whole images of a target region captured with unmanned aerial vehicles (UAVs) are processed and optimized together. This approach requires integrated necessary information of captured images for image mapping, which generally leads to accurate stitching results. The other is online mosaicing, with real-time estimates [
10,
11,
12]. It is necessary in some special application scenarios like post-disaster rescue, military reconnaissance and tree asset statistics, which are situations that place high demand on time efficiency. In general, the major differences between online and offline mosaicing are camera pose estimation algorithms and the 3D point cloud generation method. Structure from motion (SfM) [
13,
14] and simultaneous localization and mapping (SLAM) [
15,
16,
17,
18] are two classic methods used to estimate the camera pose and generate a point cloud. Simultaneous localization and mapping (SLAM) is the technique to construct or update a map of an unknown environment while simultaneously keeping track of an agent’s location within it. Structure from motion (SfM) is a photogrammetric range imaging technique for estimating three-dimensional structures from two-dimensional image sequences that may be coupled with local motion signals. After the camera pose and point cloud are obtained with one of above-mentioned techniques, the captured images are then projected to the correct position with homography transformation methods. Finally, these discrete pictures are fused to form a whole mosaic. However, SfM methods [
13,
14,
19,
20] are basic offline algorithms with expensive computation, which places high demand on hardware requirements. Therefore, it is inconvenient to be deployed on edge devices. By the way, long computations will reduce the overall work efficiency, potentially increases the time cost, especially for large-scale planting statistics introduced in this paper. For most SLAM methods [
10], a bundle adjustment algorithm is used to estimate camera poses and refine landmark positions; landmark positions are the key feature points jointly observed with multiple images. Although the SLAM-based real-time system is faster than the SfM-based mapping system, the step of bundle adjustment is still time-consuming for real-time construction systems and the matching performance is poor under low overlap conditions. To solve these problems, a multiplanar hypothesis-based pose optimization method is proposed to estimate camera poses and generate mosaicing simultaneously. This could accelerate the calculation speed and achieve robust stitching performance with sequential low overlap images in the embedded devices.
For tree counting and detection tasks, most of the early works [
21,
22] focused on feature representation design. Some good handcrafted features like Scale invariant feature transform (SIFT) and histogram of oriented gradient (HOG) were firstly used to extract key points. Then classifiers like support vector machine (SVM) [
22,
23], Random Forests [
24], K-Means [
25] and extreme learning machine (ELM) were conducted to accomplish target trees detection task using above-mentioned traditionally handcrafted features. Nevertheless, the detection scenes are relatively simple; the trees are sparsely distributed and clearly outlined with no canopy overlapping. Thus, the traditional handcrafted features-based methods could conduct the task with good performance. However, these methods are not end-to-end frameworks, and they consist of several separate algorithm steps that could bring extra unexpected noise or errors because of careless data transport between separate algorithms. In addition, handcrafted feature engineering requires expensive computation and efforts that depend on experts knowledge which is not easily obtained for various intelligent tasks.
Recently, because of the powerful capability of learning features, convolutional neural networks (CNNs) [
26] have achieved great success in various fields including computer vision, natural language processing, medical diagnosis, and so forth [
5,
27,
28,
29,
30,
31,
32]. Existing works could be divided into detection-based, segmentation-based, and regression-based methods. For detection-based supervised methods, researchers collect large amounts of tree data for deep learning (DL) algorithms to learn meaningful features for tree counting or other object detection task [
1,
5,
33,
34,
35,
36,
37,
38]. In [
2,
6,
39,
40,
41], CNN framework and full supervised Faster R-CNN [
42] are designed for oil-palm trees or other fruit detection with bounding box annotations. For segmentation-based supervised methods, some U-Net [
43] and Fully Convolutional Neural Networks (FCNs) [
32]-based detection works [
44,
45] are used to estimate the presence map of trees with remote sensing images, which generate the final results with mask that contains contour and size of tree. However, the “box in, box out” detection-based or “mask in, mask out” segmentation-based methods require lots of careful annotations that are time-consuming and laborious because of irregular target shape and complicated detection scenes. In order to alleviate the heavy annotation problem, the “point in, point out” regression-based methods have attracted attention. In [
46,
47], the researchers simultaneously predict the localization and number of persons with estimating the density maps using point annotation information. However, these methods only predict the center point while ignoring the size and contour of target objects. To fast count the trees with high quality on UAVs, a weakly supervised deep learning-based tree counting framework is proposed in this paper, which could avoid expensive bounding box or mask annotation costs. Not only the accurate number of trees but also the mask of objects could be obtained; the results are comparable to those of strongly supervised methods [
42].
In summary, we propose an aerial orthophoto mosaicing-based tree counting framework to realize fast completed automatic tree detection and counting in this paper. The tree detection and counting task is completed with a planar restricted pose graph optimization-based integrated real-time orthoimage generation and point-based supervised training framework. Therefore, the proposed pipeline could be able to improve the accuracy and speed of mosaicing and tree counting, and it is efficient and robust for board devices. The main contributions are as follows:
A novel efficient tree detection and counting framework for UAVs: Compared to the current tree counting pipeline, our method provides a real-time solution for detection tasks with UAVs. High-quality mosaicing is efficiently generated with less calculations; detection and counting task is completed with fast annotation, training and inference analysis pipelines.
A multiplanar hypothesis-based online pose optimization: A multiplanar hypothesis-based pose optimization method is proposed to estimate camera poses and generate mosaicing simultaneously. The number of parameters about reprojection error is effectively reduced; the method could accelerate the calculation speed and achieve robust stitching performance with sequential low overlap images in the embedded devices.
Point-supervised-based attention detection framework: A point supervised method could not only estimate the localization of trees but also generate a contour mask that is comparable to full supervised methods. The supervised label information is easy to be obtained, which could be effective for entire learning framework.
An embedded system with a proposed algorithm on UAVs: An embedded fully automatic system is embedded into the UAV for completing integrated stitching and tree counting tasks; the whole procedure requires no human intervention at all. In addition, buildings or trees could have a greater negative impact on the communication link between the UAV and a ground station; the embedded system could ignore this negative effects and improve work efficiency.
The remainder of this article is organized as follows.
Section 2 briefly reviews the related work. In
Section 3, the two-stage vision framework is illustrated in detail. Experimental results and discussions are presented in
Section 4. Finally, we draw conclusions about the proposed fast tree counting pipeline in
Section 5.
3. Methodology
3.1. Overview
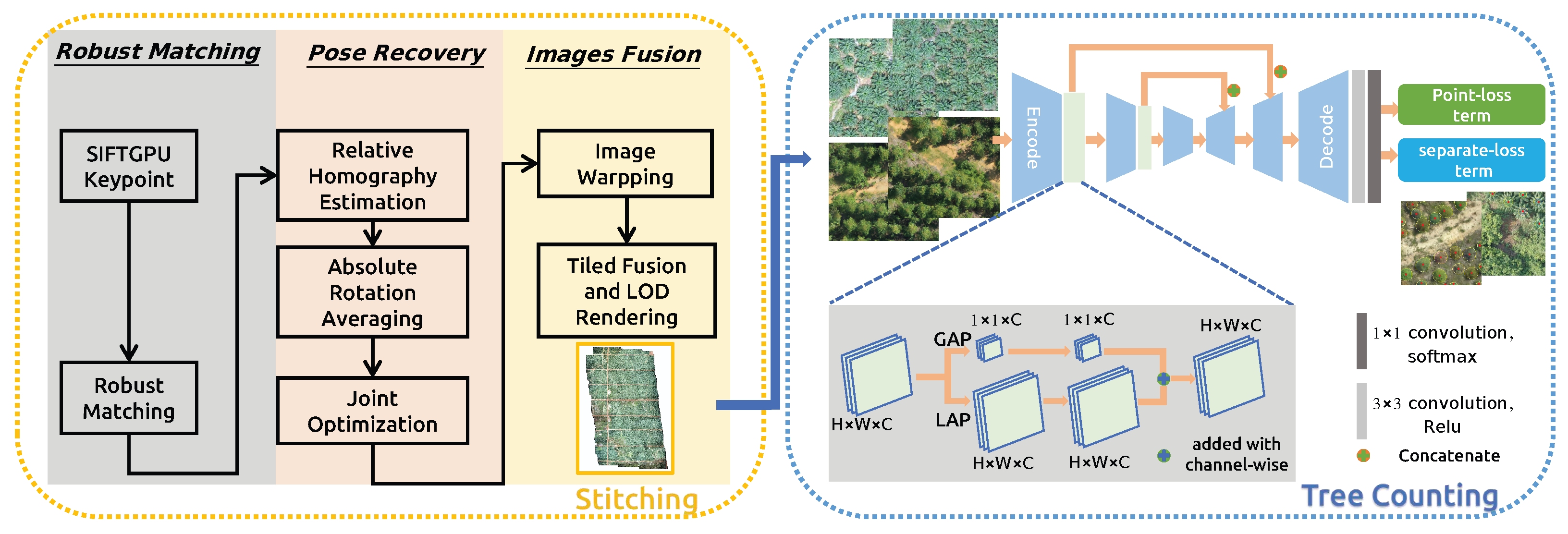
The whole proposed system is an integrated vision framework named real-time orthophoto mosaicing-based tree counting pipeline illustrated in
Figure 1, which includes “real-time stitching” and “fast tree counting” modules. In the stitching step, sequential images with GNSS information are obtained through the UAV Software Development Kit (SDK) and posted to the algorithm during flight mission. After the interesting region of map detection, a fast detection algorithm is used to complete the tree counting task. There are mainly two advantages: (1) we only use a series of image data captured to detect trees, which will result in a lot of duplications because of overlap among images; this is not convenient and reduces detection efficiency and quality in large scale regions. A real-time stitching module could quickly reconstruct the region areas with high quality for the next tree counting analysis, which could improve the detection performance with a global perspective. (2) After the orthophoto mosaicing is generated, it is cut into tiles, this data format is suitable for the next tree detection with parallel computation. Thus, the calculation efficiency of the entire workflow is high, and it could be easily connected to a geographic information system (GIS) for visualization or deployed into embedded devices like UAVs.
In the stitching procedure, when the algorithm receives real-time captured images, it extracts the key-points and inserts them into a matching graph using appearance and spatial-based faster neighbor query and matching algorithms. After the matching operation, the algorithm computes absolute rotation and translation by aligning the visual position with the GNSS position. While in the optimization step, the error in the graph propagates through homograph matrix. The propagation, which is-based on homograph matrix is robust and efficiency, making it possible to handle tough sequences whose overlap is less than 50%. Every frame with pose is delivered to stitching thread. In addition, our orthomosaic is fused with weighted multi-band laplacian pyramid, which makes it seamless and smoother. Considering the large-scale reconstruction and smooth rendering, the algorithm balances memory and hard disk useage, using an Least Recently Used (LRU) to manage multiple zoom level tiles, which ensures the invariance of the shape of the object, as well as the correctness of the direction and mutual position, so it is often used in navigation and aviation. A Level of Detail (LoD) algorithm is adopted to update the multiple zoom level tiles, which could increase the efficiency of rendering with decreasing the workload on graphics computation procedure.
In the detection procedure, in order to effectively predict the localization of trees for large scale scenes, and avoid expensive bounding box or mask annotations, a weakly supervised attention method only with point annotations that could reduce human annotation labor is introduced in this section. The proposed weakly semantic segmentation network not only predicts the positions of trees but also obtains the outline of trees. The U-Net framework is an encoder–decoder architecture consisting of contracting path and expanding path designed to capture context and extract discriminative feature representations. Inspired by this, a novel point-supervised attention network is proposed, which is pre-trained with RestNet-50 with first four encoder layers to obtain the feature representation, which could be further improved with spatial unit (SU) consisting of global average pooling (GAP) and local average pooling (LAP) operations for the tree detection task. In the training step, point supervised loss function consisting of point-loss and separate-loss terms, which are used to guide the network to generate the mask of trees with point supervised information. After the network is trained completely, the weights of the proposed network are fixed and deployed in edge device like UAV for tree detection. For the convenience of deployment and application, we train two sets of weights for acacia and oil-palm detection, respectively. When we apply the pipeline for new tree species, several hundreds of annotated data are needed to train the network and generate the new weights. In the inference step, firstly, the orthophoto mosaicing is real-time-generated with sequential images captured in UAV; secondly, the generated orthophoto mosaicing is cut into thousands of tiles and served in the form of Hyper Text Transfer Protocol (HTTP). A well-trained network is used to obtain the localization and number of instances for tree detection task with each tile from interesting regions.
3.2. Real Time Generating Orthophoto Mosaicing
The traditional SLAM methods proposed optimize poses that are-based on GNSS and multiplanar hypothesis, which ensures robustness under low overlap. Like SLAM system-based on feature points, we choose SIFT for its stability. For efficiency, the OpenGL Shading Language (GLSL)-based SIFT algorithm is used to extract the feature points of the image, and GLSL requires a GPU that has large memory and supports dynamic branching to accelerate the computation of SIFT description. The RootSIFT algorithm [
60] is adopted to generate the descriptors to further improve the matching quality and enhance the robustness. After calculating the pose, we project the photo onto a two-dimensional map according to the optimized plane, and adopt LoD for smooth rendering.
3.2.1. Keypoint Detection and Matching
Considering that SIFT algorithm contains a large number of independent pixel wise processes, the GLSL accelerated SIFT is performed to improve the computing speed and platform independency. That is to say, the algorithm has the potential to be deployed in embedded or mobile terminals. The matching process adopts the RootSIFT method to normalize the descriptor and calculate the square root to measure the distance between two SIFT feature points. Some studies have proven that this method is better than the method of directly using Euclidean distance to measure similarity.
3.2.2. Online Planar Restricted Pose Recovery
In
Figure 2, unlike the general full-scene plane assumption, our proposed method adopts the multiplanar assumption, that is, each image captured is assumed to be flat. The general full-scene plane assumption could result in larger estimation bias. This multiplanar assumption processing method weakens the shortcoming of full-scene plane assumption and improves the generalizability of the method for aerial image stitching.
When the overlap is low, the traditional PnP-based pose tracking cannot work properly, due to the lack of common view; tracking is equivalent to the initialization. To accurately estimate camera poses, we first decouple and estimate the rotation and translation separately, adopting rotation and translation averaging algorithm [
61]. Then the GNSS information is fused in the rotation averaging procedure to make the system more stable. Unlike the general bundle adjustment algorithm, the graph optimization procedure depends on the homograph propagation and does not need triangulation, and reprojection errors are not constructed with map points, which accelerate the mapping speed and improve the robustness of system. For image i, the camera poses and height will be composed of a seven-DOF parameter,
,
,
and
are the rotation, translation matrix and flight height for image
i, respectively. The submap
is obtained according to the matches and geodetic position. The optimization function is as follows:
where
is the GNSS prior factor, which is an error loss used to optimize the camera pose with considering the GNSS information.
is the local cartesian coordinates computed from the GNSS information for each frame, while
is the reprojection error of match
between frames
i and
j, it is defined as:
Here,
is the unit vector represents the view direction of keypoint
and
p is the 3D coordinates of the keypoint.
are the local ground height estimation of image
.
is denoted as the pinhole projection in camera coordinates, and
is the inverse projection in the plane where
:
The Ceres Solver library (
http://ceres-solver.org, accessed on 1 March 2022) is a large scale non-linear optimization library that is used to deal with the graph optimization problem in the proposed pipeline.
3.2.3. Georeferenced Images Fusion with Tiling and LoD
After the camera pose estimation, the original images are reprojected onto the digital orthophoto map (DOM). Due to the overlapping of captured sequential images, the adaptive weighted multiband algorithm [
10] is adopted to fuse the images. The generated mosaicing consists of several level pyramid tiles with LoD, which could increase the efficiency of rendering with decreasing the graphics workload for visualization. In addition, a thread-safe LRU technique is used to cache the segmented image tiles to decrease memory cost and a thread pool is used to process the tiles in parallel for further speed acceleration.
3.3. Weakly Supervised Attention Counting Tree Network
After orthophoto generation, we cut the oil-palm and acacia orthophoto into thousands of tiles, and split the collected tile images into training and testing sets. In the following experiment part, the training dataset consists of 2880 images of acacia and 2280 images of oil-palm, and the test dataset consists of 1920 images of acacia and 1520 images of oil-palm that are used to test the proposed method’s effectiveness. The training set is labeled with labelme toolbox [
62] by point annotation. Then the labelled data is fed into a weakly supervised attention counting tree network to learn the feature representation of target tree. The network consists of attention-based tree feature extractor and point supervised loss function described as follows.
3.3.1. Attention Based Tree Feature Extractor Network
In the attention-based tree feature extractor network (ATFENet), the U-net similar CNN architecture, ResNet-50 is adopted as the network backbone to complete the feature extractor procedure. The contracting path and expanding path are combined through skip-connections [
43] to capture abundant context and learn to extract discriminative feature representations for localization task. The size of input original images and output prediction mask are both N × W × H. Thus, The output array is a pixel-by-pixel semantic mask predicted with 1 × 1 convolution and softmax function in the last layer of network to determine which pixel is target tree or not.
Inspired by the human visual perception system, attention mechanism constructs the dependent relationships between the input and target information, has been tried in many intelligence-related tasks, like scene parsing, sentences translation and so forth [
63]. An attention mechanism could quickly extract important features from the sparse data, while a self-attention mechanism is an improvement of attention mechanism, which reduces the dependence on external information and could better capture the internal correlation of data or features. Therefore, we design an attention-based tree feature extractor network, which captures the rich global and local relationships to effectively model tree detection-related feature relationships. Concretely, we introduce a spatial unit (SU) that consists of global average pooling (GAP) and local average pooling (LAP) operations, which could exploit the global and local spatial channel-wise interdependencies to simultaneously obtain large-size and small-size properties. The global average pooling (GAP) operation is performed on the encode’s output feature map to exploit the information with a global perspective in the first branch. The local average pooling (LAP) with a kernel size
of and a stride of 1 is performed to exploit the informativeness with a local perspective, which computes the average values of sub region whose size is
and traverses the feature map with a sliding window step size of 1. A point-wise convolution with a kernel size of
is adopted to exploit the channel-wise interdependencies. Through the above operations, the spatial features are fully exploited to quality-boost the basic feature maps for the tree detection task.
3.3.2. Point Supervised Loss Function
The point supervised loss function consists of two terms, which are point level loss and separate loss. Point level loss is a semantic segmentation method designed by Bearman et al. [
64], and is used to predict each pixel class according to the point annotations. The separate loss could predict the tree mask and split the masks into individual tree according to the point annotations. The proposed point supervised loss function could be written as below:
Point level loss term. Because we provide point supervised information for training, labels of the pixels corresponding to the supervised points are tree classes, and the other pixel labels are 0. The point annotation labels are used to optimize the cross-entropy function of the model.
denotes the pixels of the image and
is the class label of pixel
i. The
is the score of pixel
i belonging to class
c, and the softmax function at pixel
i is
. The point level loss is defined as follows:
where, the
S is the output of softmax function,
P denotes the tree ground truth label, where
N (
N ≥ 0) is the class number of target trees,
is 1, 2, …, n (1 ≤ n ≤
N) correspondingly.
Separate loss term. The point level loss could determine which pixel belongs to a tree class or background. However, the inference model could encounter a condition that two or more trees in one mask area, which decrease the performance of tree detection and counting tasks. Therefore, a separate loss term is designed to divide the mask containing many target objects into individual trees according to the annotations. The watershed algorithm [
65] is used to generate individual object blob from the whole tree blobs. The
L is denoted as the set of pixels representing the boundaries generated with watershed method.
This term guarantees the tree masks only contain single target tree. In the formula, is the background probability at pixel i, is the number point annotations ground truth in each image, is the pixels regarded as the tree with training model but there is not any ground-truth point annotation in the pixels. The predictions located in are considered as false positives or unlabelled predictions. For example, the wrong predicted masks shown in Figure 10c are typical false positives, and the second part of this loss could guide this loss term results reduce less false positive tree predictions so as to improve the detection precision.
3.4. Application with Fast Orthophoto Mosaicing and Tree Counting
We design the interface and software development kit (SDK) to embed the integrated tree counting pipeline into fixed wing drones. Nvidia Jetson Xavier NX could ad super computation performance in small devices. The powerful accelerated computing ability is enough to run deep learning-based neural networks in parallel for various AI application systems. Thus, we insert the integrated vision framework into the Jetson Xavier NX device with using a drone interface obtaining camera images and drone status parameters. When the region of plantation needs to be investigated, a way-point mission is automatically generated with flight height and the overlap rate of captured sequential images. The aerial orthophoto displayed in real time is incrementally updated with processing sequential data.Then a well trained tree counting neural network is used to detect interesting trees with generated orthophoto mosaicing.
This fully automatic integrated perception and analysis system requires no human intervention at all. There are mainly two advantages for UAV-related applications: on one hand, image mosaicing quality depends on the captured images quality, the real-time-embedded system on UAVs could guarantee the quality of data captured with a camera and ignore the negative impacts of communication links, which is suitable for drone operations in large-scale and complex areas. On the other hand, fully autonomous operation greatly improves work efficiency, which greatly reduces time, money and labor costs. Thus, the proposed embedded integrated stitching and tree counting pipeline improves the intelligence of the entire process and greatly reduces costs on the premise of ensuring quality.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}