
Modeling the Leaf Area Index of Inner Mongolia Grassland Based on Machine Learning Regression Algorithms Incorporating Empirical Knowledge

 ,
,  ,
, 

Abstract
:
1. Introduction
2. Materials and Methods
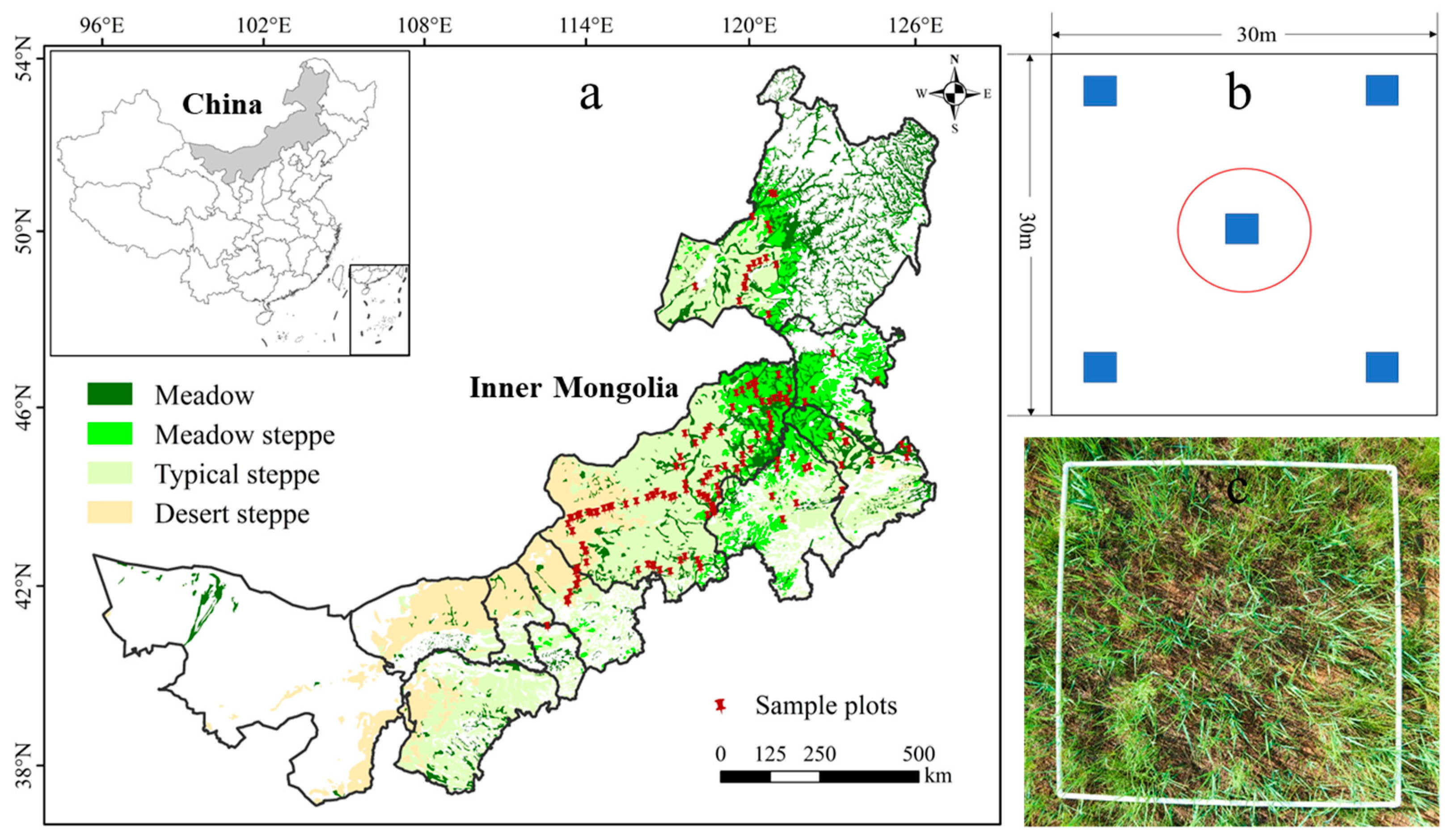
2.1. Study Region
2.2. Data Collection and Processing
2.2.1. In Situ LAI Measurement
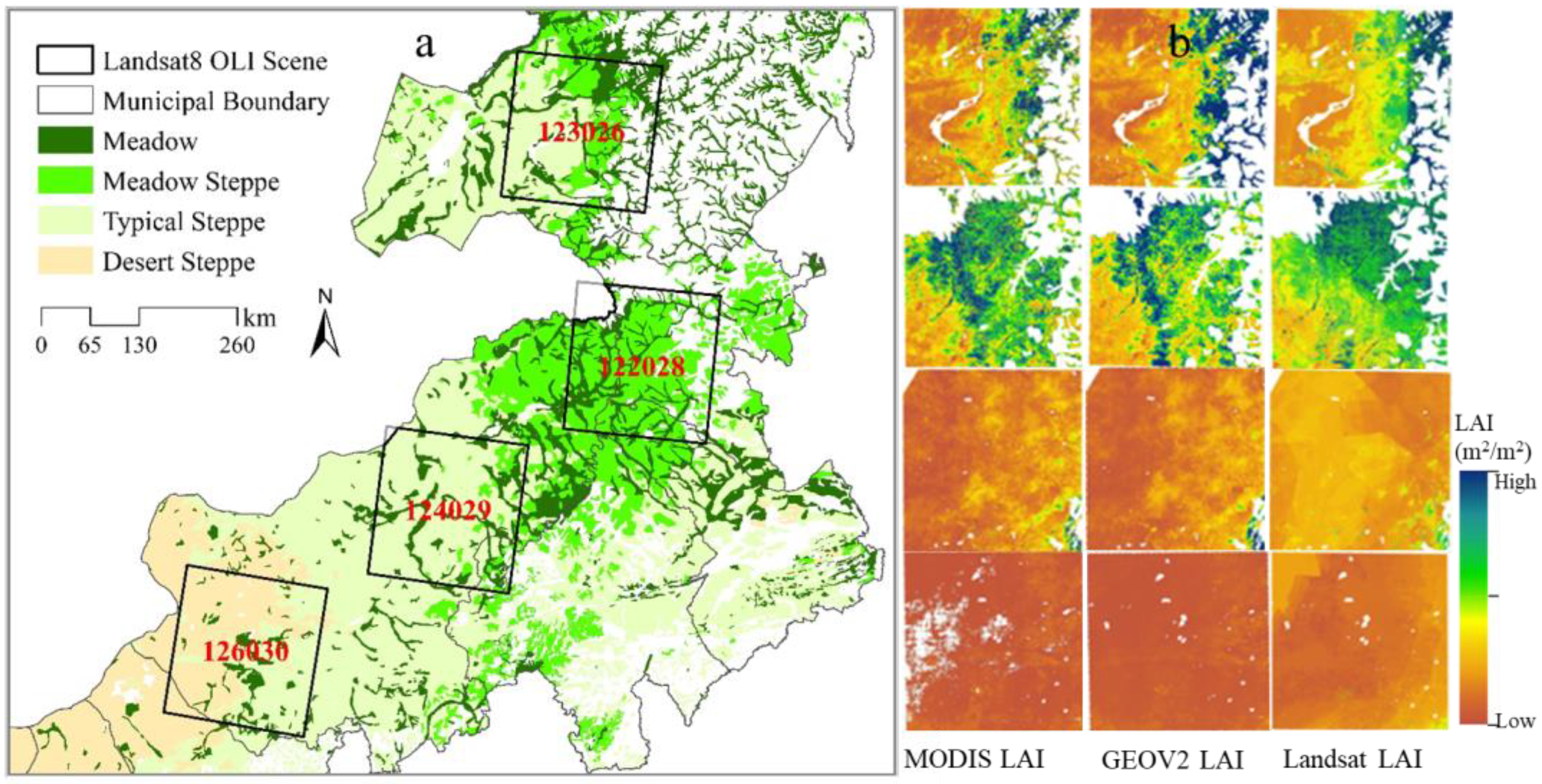
2.2.2. Remotely Sensed Data
2.2.3. Climate, Soil and Topography Data
2.2.4. Grassland Type Data
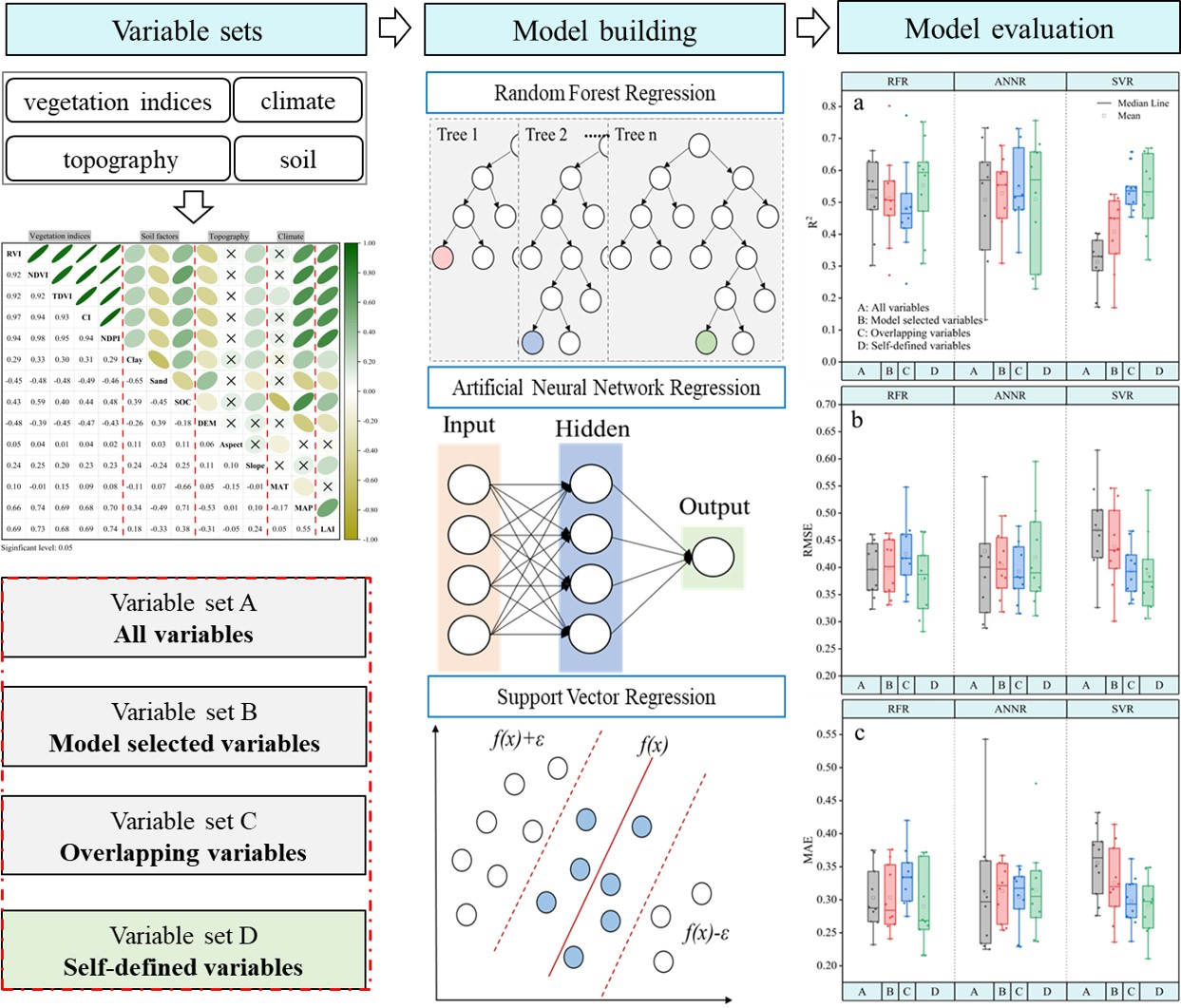
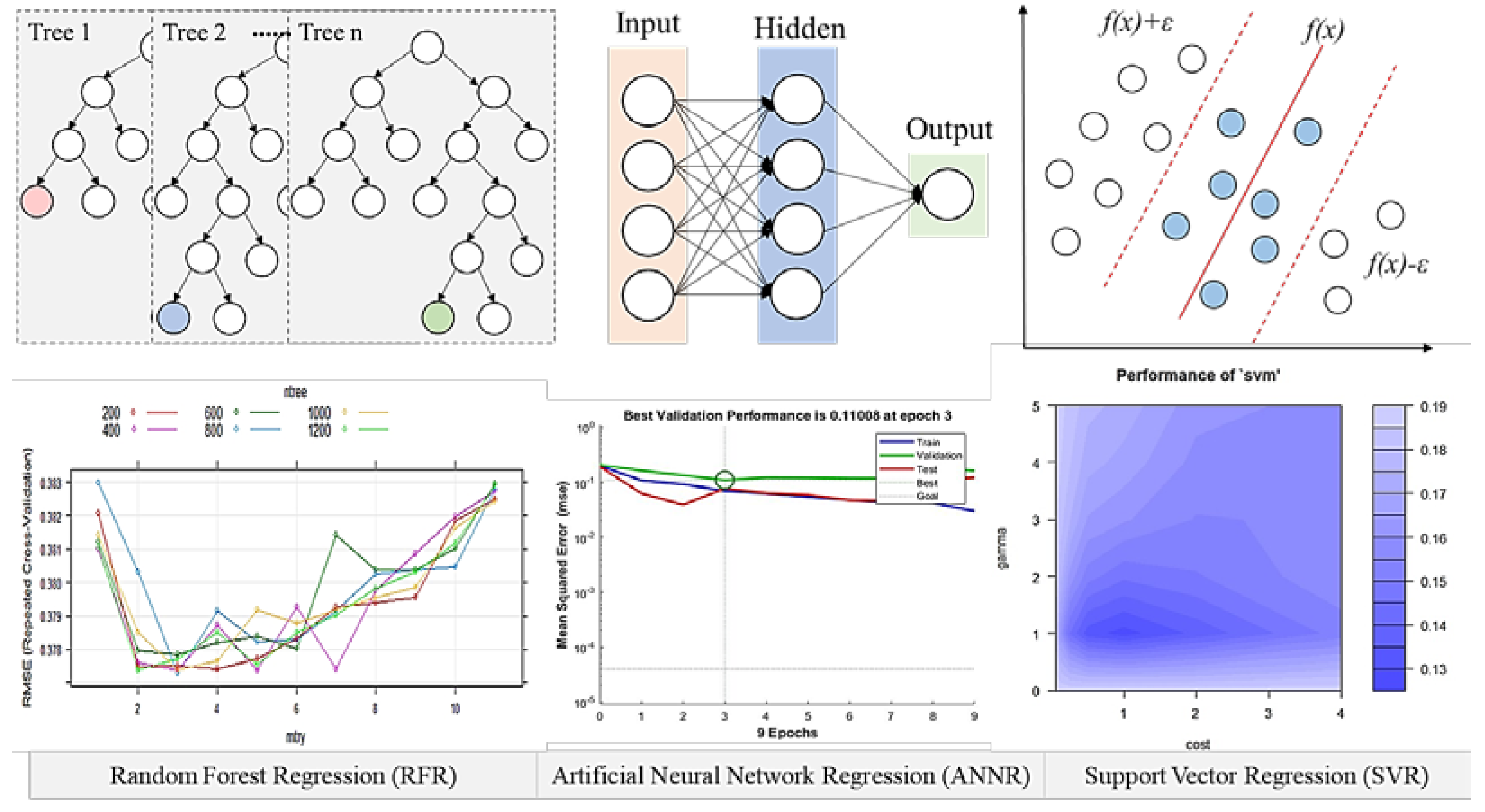
2.3. Machine Learning Algorithms and Measure of Variable Importance Methods
2.3.1. Random Forest Regression
2.3.2. Artificial Neural Network Regression
2.3.3. Support Vector Regression
2.4. Performance Evaluation of the Model
3. Results
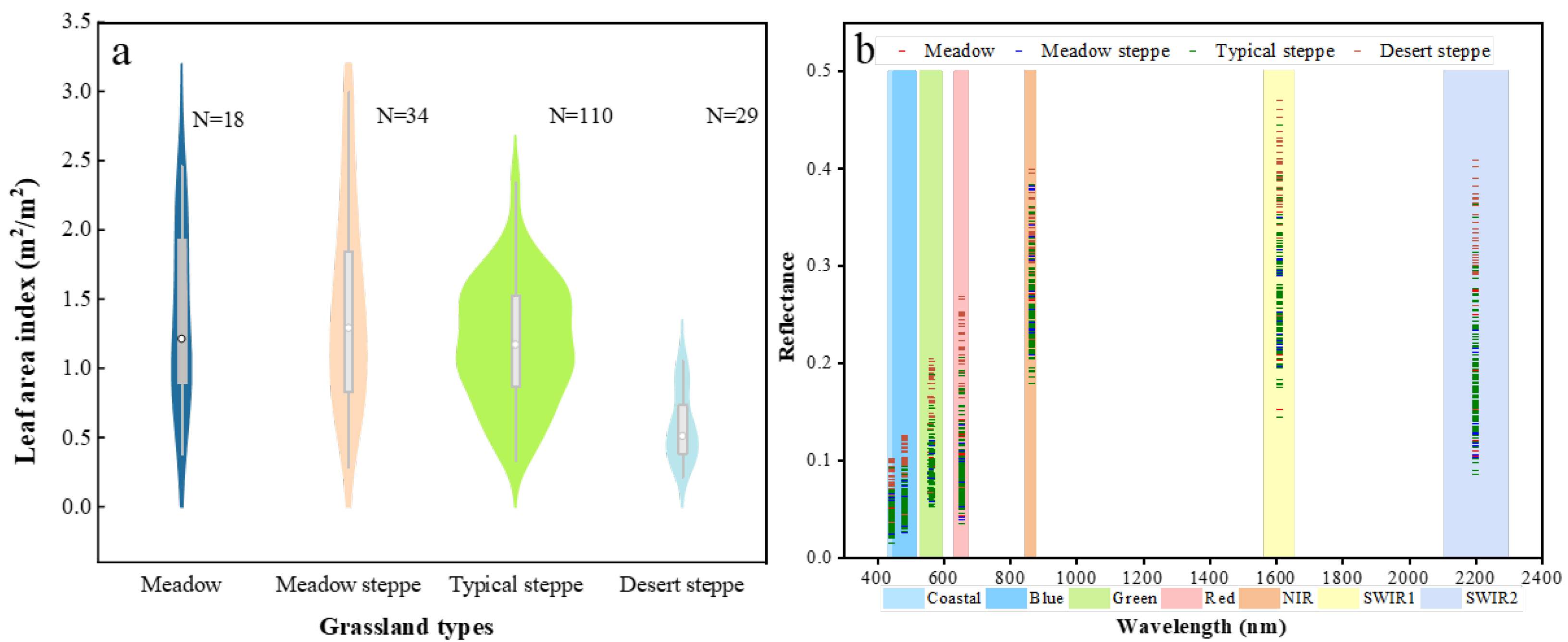
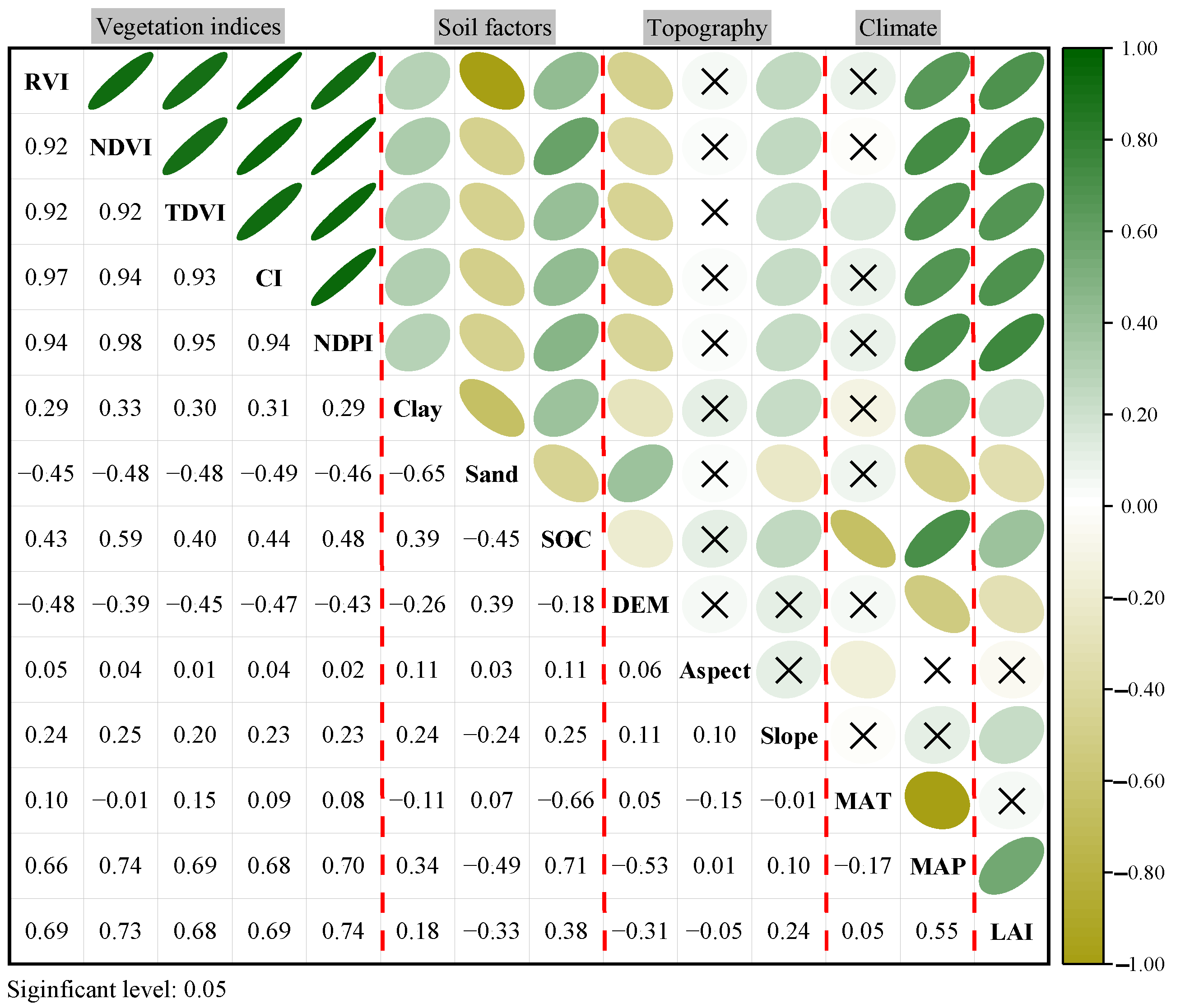
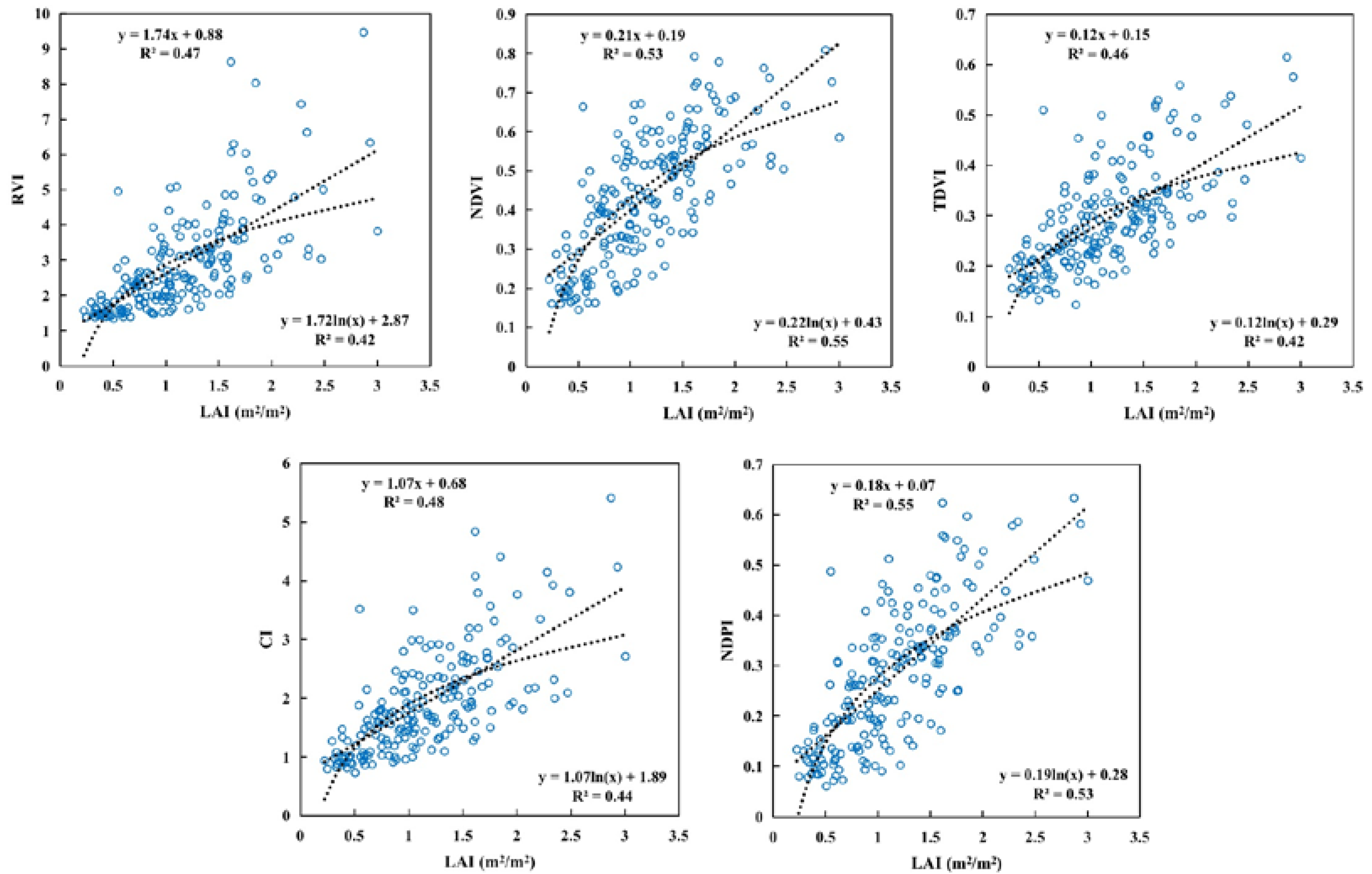
3.1. In Situ LAI Characteristics and Correlation Analysis
3.2. Variable Importance
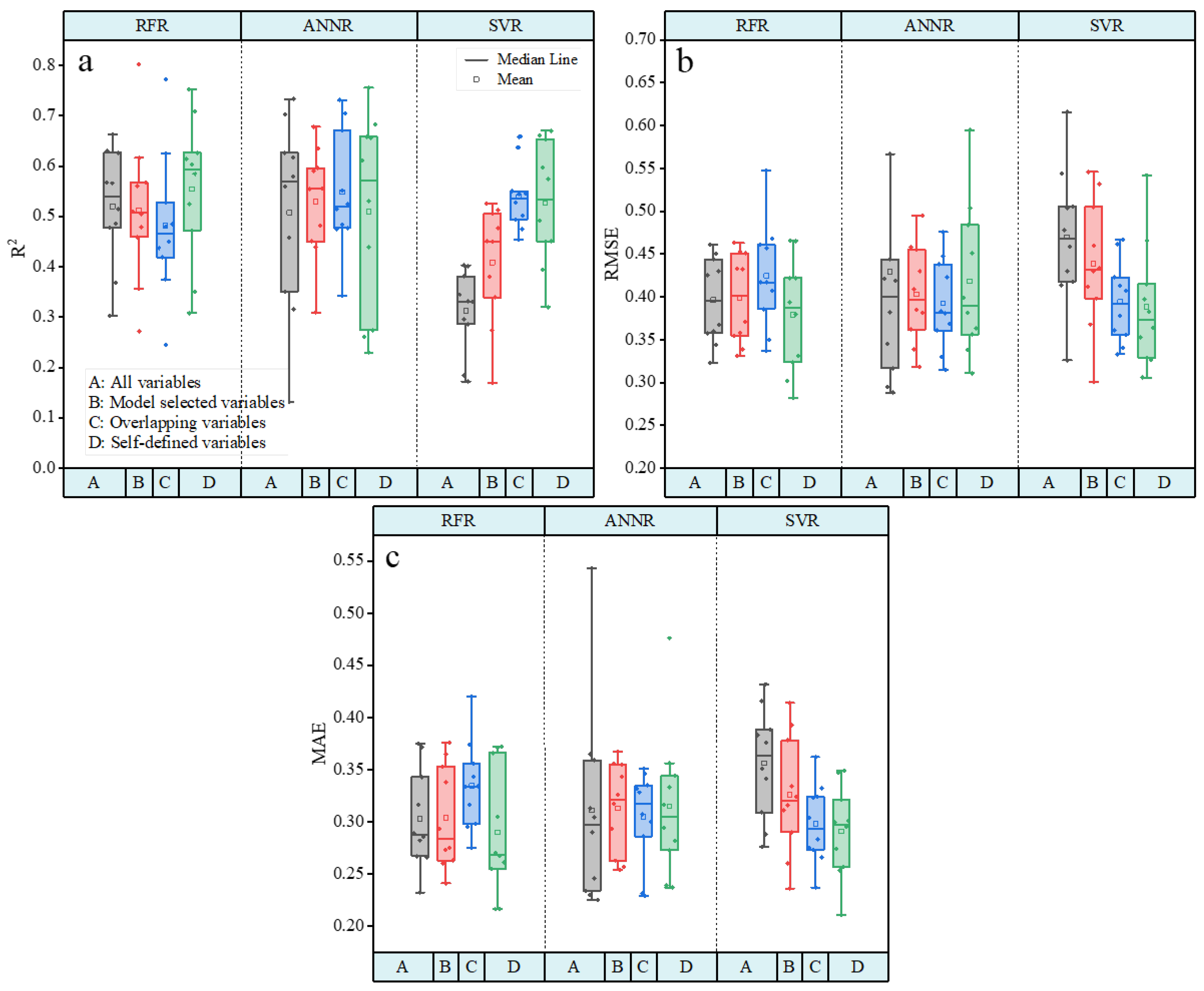
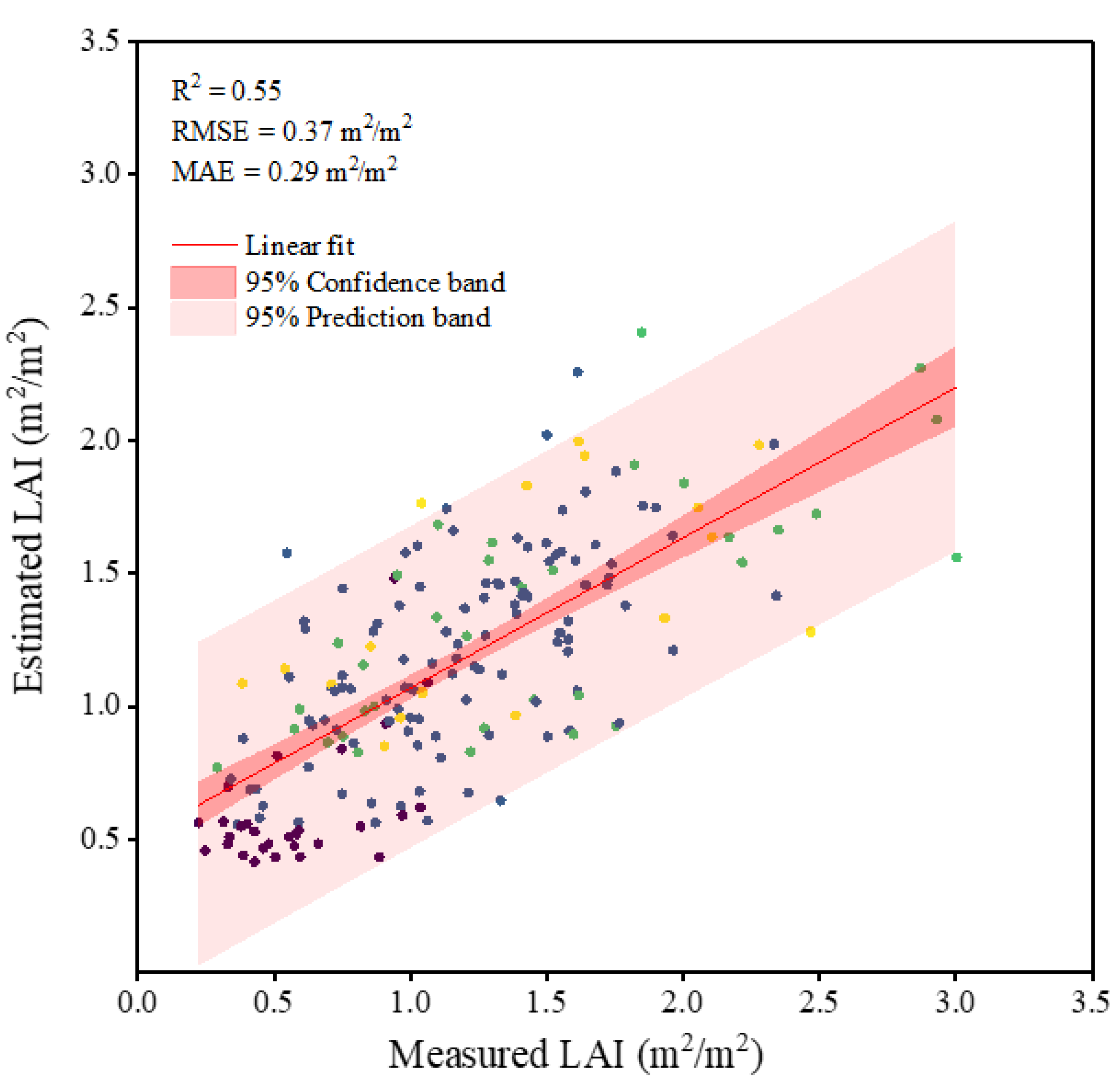
3.3. Model Building and Evaluation
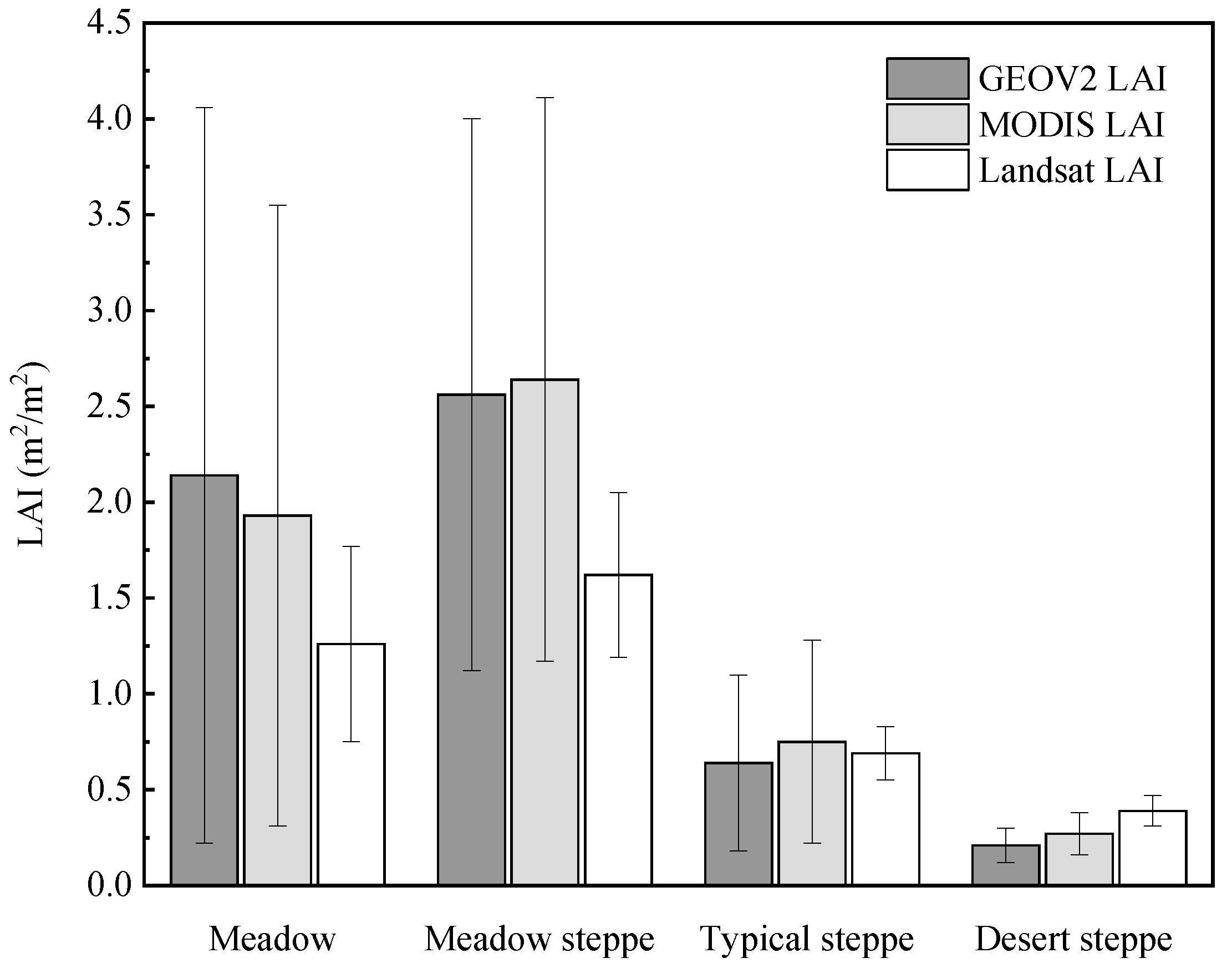
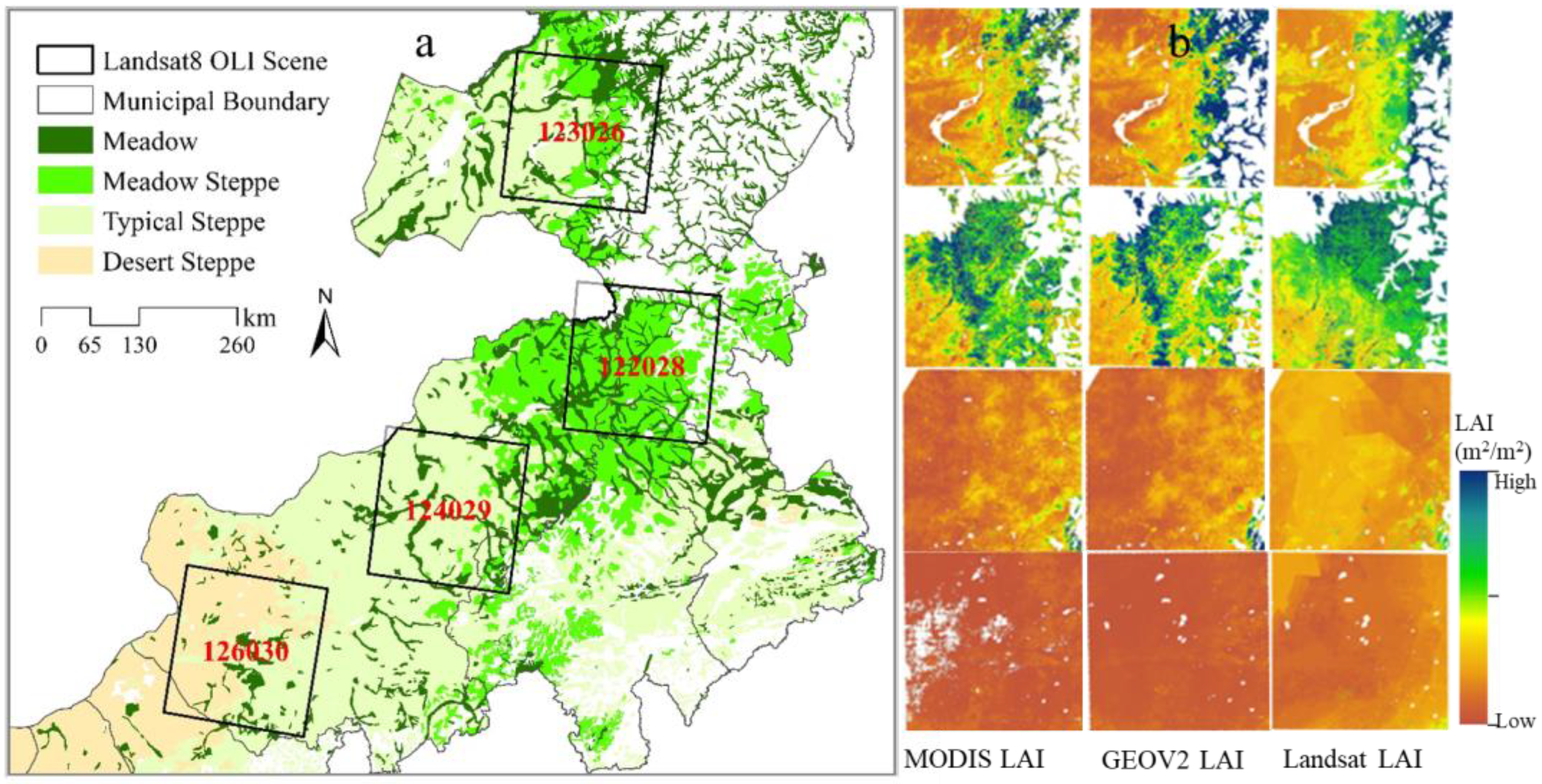
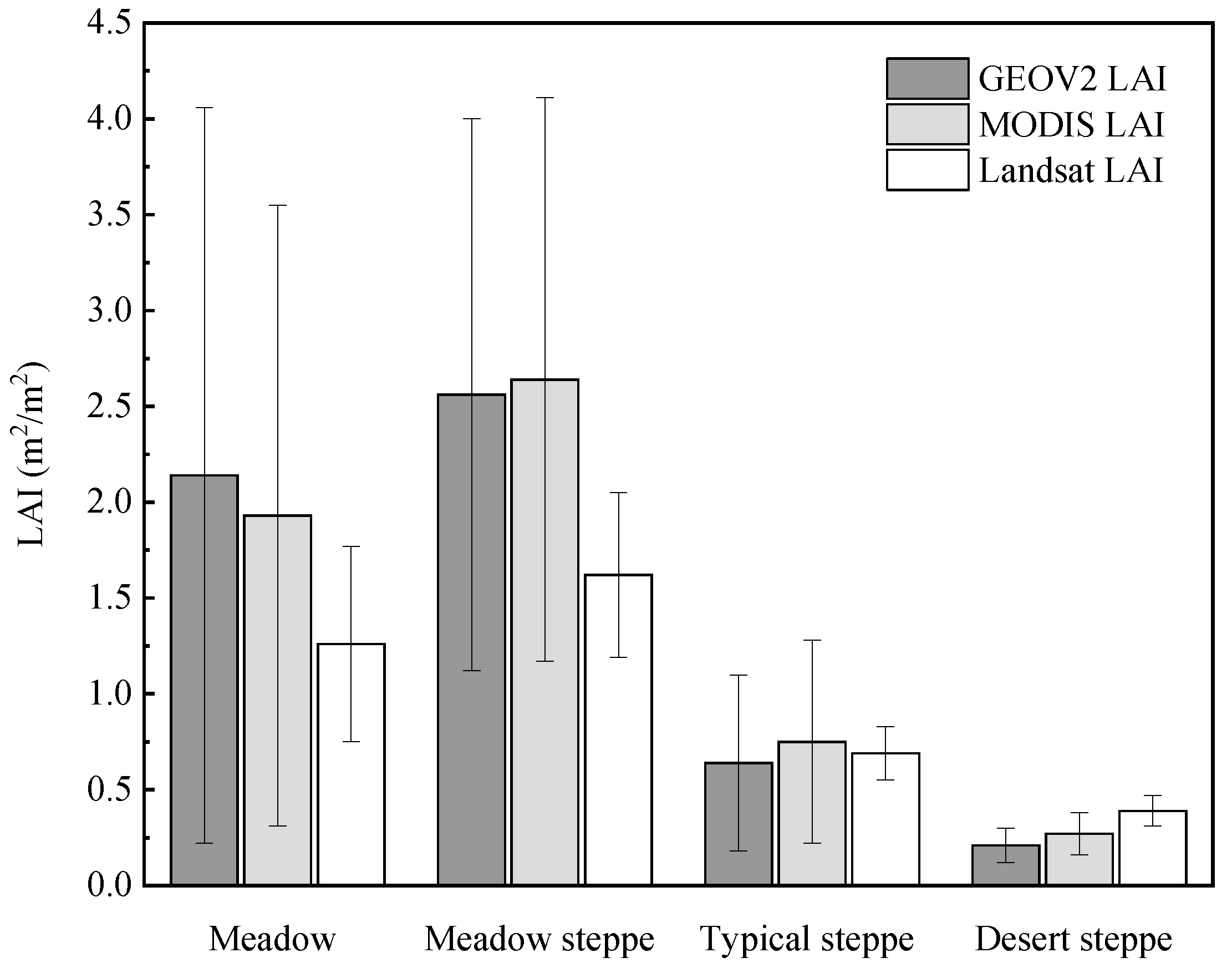
3.4. Intercomparison with Other LAI Products
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scurlock, J.M.O.; Hall, D.O. The global carbon sink: A grassland perspective. Glob. Chang. Biol. 2010, 4, 229–233. [Google Scholar] [CrossRef]
- Watson, D.J. Comparative and physiological studies on growth of field crop variation in net assimilation rate and leaf area between species and varieties and within years. Ann. Bot. 1947, 11, 41–76. [Google Scholar] [CrossRef]
- Chen, J.M.; Black, T.A. Defining leaf area index for non-flat leaves. Plant Cell Environ. 1992, 15, 421–429. [Google Scholar] [CrossRef]
- Fang, H.L.; Baret, F.; Plummer, S.; Schaepman-Strub, G. An overview of global leaf area index (LAI): Methods, products, validation, and applications. Rev. Geophys. 2019, 57, 739–799. [Google Scholar] [CrossRef]
- Wang, Y.J.; Woodcock, C.E.; Buermann, W.; Stenberg, P.; Voipio, P.; Smolander, H.; Häme, T.; Tian, Y.H.; Hu, J.N.; Knyazikhin, Y.; et al. Evaluation of the MODIS LAI algorithm at a coniferous forest site in Finland. Remote Sens. Environ. 2004, 91, 114–127. [Google Scholar] [CrossRef]
- Sellers, P.J.; Dickinson, R.E.; Randall, D.A.; Betts, A.K.; Hall, F.G.; Berry, J.A.; Collatz, G.J.; Denning, A.S.; Mooney, H.A.; Nobre, C.A.; et al. Modeling the exchanges of energy, water, and carbon between continents and the atmosphere. Science 1997, 275, 502–509. [Google Scholar] [CrossRef] [PubMed]
- Chase, T.N.; Pielke, R.A.; Kittel, T.G.F.; Nemani, R.; Running, S.W. Sensitivity of a general circulation model to global changes in leaf area index. J. Geophys. Res.: Atmos. 1996, 101, 7393–7408. [Google Scholar] [CrossRef]
- Thornton, P.K.; Ericksen, P.J.; Herrero, M.; Challinor, A.J. Climate variability and vulnerability to climate change: A review. Glob. Chang. Biol. 2014, 20, 3313–3328. [Google Scholar] [CrossRef] [PubMed]
- Liang, T.G.; Yang, S.X.; Feng, Q.S.; Liu, B.K.; Zhang, R.P.; Huang, X.D.; Xie, H.J. Multi-factor modeling of above-ground biomass in alpine grassland: A case study in the Three-River Headwaters Region, China. Remote Sens. Environ. 2016, 186, 164–172. [Google Scholar] [CrossRef]
- Chen, Y.F.; Dong, M. Spatial heterogeneity in ecological systems. Ecol. Sin. 2003, 23, 346–352. [Google Scholar] [CrossRef]
- Martínez, B.; García-Haro, F.J.; Coca, F.C. Derivation of high-resolution leaf area index maps in support of validation activities: Application to the cropland Barrax site. Agric. For. Meteorol. 2009, 149, 130–145. [Google Scholar] [CrossRef]
- Weiss, M.; Baret, F.; Smith, G.J.; Jonckheere, I.; Coppin, P. Review of methods for in situ leaf area index (LAI) determination: Part II. Estimation of LAI, errors and sampling. Agric. For. Meteorol. 2004, 121, 37–53. [Google Scholar] [CrossRef]
- Jonckheere, I.; Fleck, S.; Nackaerts, K.; Muys, B.; Coppin, P.; Weiss, M.; Baret, F. Review of methods for in situ leaf area index determination: Part I. Theories, sensors and hemispherical photography. Agric. For. Meteorol. 2004, 121, 19–35. [Google Scholar] [CrossRef]
- Zhang, B. Current status and future prospects of remote sensing. Bull. Chin. Acad. Sci. 2017, 32, 774–784. [Google Scholar]
- Li, X.C.; Xu, X.G.; Bao, Y.S.; Huang, W.J.; Luo, J.H.; Dong, Y.Y.; Song, X.Y.; Wang, J.H. Retrieving LAI of winter wheat based on sensitive vegetation index by the segmentation method. Sci. Agric. Sin. 2012, 45, 3486–3496. [Google Scholar]
- Li, K.L.; Jiang, J.J.; Mao, R.Z.; Ni, S.X. The modeling of vegetation through leaf area index by means of remote sensing. Acta Ecol. Sin. 2005, 25, 1491–1496. [Google Scholar]
- Fang, H.L.; Liang, S.L.; Kuusk, A. Retrieving leaf area index using a genetic algorithm with a canopy radiative transfer model. Remote Sens. Environ. 2003, 85, 257–270. [Google Scholar] [CrossRef]
- Verrelst, J.; Malenovský, Z.; Tol, C.V.; Camps-Valls, G.; Gastellu-Etchegorry, J.P.; Lewis, P.; North, P.; Moreno, J. Quantifying vegetation biophysical variables from imaging spectroscopy data: A review on retrieval methods. Surv. Geophys. 2019, 40, 589–629. [Google Scholar] [CrossRef]
- Verrelst, J.; Camps-Valls, G.; Muñoz-Marí, J.; Rivera, J.P.; Veroustraete, F.; Clevers, J.G.P.W.; Moreno, J. Optical remote sensing and the retrieval of terrestrial vegetation bio-geophysical properties—A review. ISPRS J. Photogramm. 2015, 108, 273–290. [Google Scholar] [CrossRef]
- Baret, F.; Buis, S. Estimating Canopy Characteristics from Remote Sensing Observations: Review of Methods and Associated Problems; Springer: Dordrecht, The Netherlands, 2008. [Google Scholar] [CrossRef]
- Durbha, S.S.; King, R.L.; Younan, N.H. Support vector machines regression for retrieval of leaf area index from multiangle imaging spectroradiometer. Remote Sens. Environ. 2007, 107, 348–361. [Google Scholar] [CrossRef]
- Verrelst, J.; Muñoz, J.; Alonso, L.; Delegido, J.; Rivera, J.P.; Camps-Valls, G.; Moreno, J. Machine learning regression algorithms for biophysical parameter retrieval: Opportunities for Sentinel-2 and -3. Remote Sens. Environ. 2012, 118, 127–139. [Google Scholar] [CrossRef]
- Jalonen, J.; Järvelä, J.; Virtanen, J.P.; Vaaja, M.; Kurkela, M.; Hyyppä, H. Determining characteristic vegetation areas by terrestrial laser scanning for floodplain flow modeling. Water 2015, 7, 420–437. [Google Scholar] [CrossRef] [Green Version]
- Berterretche, M.; Hudak, A.T.; Cohen, W.B.; Maiersperger, T.K.; Gower, S.T.; Dungan, J. Comparison of regression and geostatistical methods for mapping Leaf Area Index (LAI) with Landsat ETM+ data over a boreal forest. Remote Sens. Environ. 2005, 96, 49–61. [Google Scholar] [CrossRef]
- Zhong, S.F.; Zhang, K.; Bagheri, M.; Burken, J.G.; Gu, A.; Li, B.K.; Ma, X.M.; Marrone, B.L.; Ren, Z.Y.J.; Schrier, J.; et al. Machine Learning: New ideas and tools in environmental science and engineering. Environ. Sci. Technol. 2021, 55, 12741–12754. [Google Scholar] [CrossRef]
- Li, Z.W.; Wang, J.H.; Tang, H.; Huang, C.Q.; Yang, F.; Chen, B.R.; Wang, X.; Xin, X.P.; Ge, Y. Predicting grassland leaf area index in the meadow steppes of northern China: A comparative study of regression approaches and hybrid geostatistical methods. Remote Sens. 2016, 8, 632. [Google Scholar] [CrossRef]
- Han, Z.Y.; Zhu, X.C.; Fang, X.Y.; Wang, Z.Y.; Wang, L.; Zhao, G.X.; Jiang, Y.M. Hyperspectral estimation of apple tree canopy LAI based on SVM and RF regression. Spectrosc. Spectr. Anal. 2016, 36, 800–805. [Google Scholar]
- Pullanagari, R.R.; Kereszturi, G.; Yule, I.J. Mapping of macro and micro nutrients of mixed pastures using airborne AisaFENIX hyperspectral imagery. ISPRS J. Photogramm. 2016, 117, 1–10. [Google Scholar] [CrossRef]
- Ding, L.; Li, Z.W.; Shen, B.B.; Wang, X.; Xu, D.W.; Yan, R.R.; Yan, Y.C.; Xin, X.P.; Xiao, J.F.; Li, M.; et al. Spatial patterns and driving factors of aboveground and belowground biomass over the eastern Eurasian steppe. Sci. Total Environ. 2022, 803, 149700. [Google Scholar] [CrossRef]
- Jordan, C.F. Derivation of leaf-area index from quality of light on the forest floor. Ecology 1969, 50, 663–666. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation System in the Great Plains with ERTS; Goddard Space Flight Center 3d ERTS-1 Symposium; NASA: Washington DC, USA, 1974; Volume 1, pp. 309–317. [Google Scholar]
- Bannari, A.; Asalhi, H.; Teillet, P.M. Transformed difference vegetation index (TDVI) for vegetation cover mapping. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002; pp. 3053–3055. [Google Scholar]
- Gitelson, A.A.; Vina, A.; Arkebauer, T.J.; Rundquist, D.C.; Keydan, G.; Leavitt, B. Remote estimation of leaf area index and green leaf biomass in maize canopies. Geophys. Res. Lett. 2003, 30, 1248. [Google Scholar] [CrossRef]
- Wang, C.; Chen, J.; Wu, J.; Tang, Y.H.; Shi, P.J.; Black, T.A.; Zhu, K. A snow-free vegetation index for improved monitoring of vegetation spring green-up date in deciduous ecosystems. Remote Sens. Environ. 2017, 196, 1–12. [Google Scholar] [CrossRef]
- Myneni, R.B.; Hoffman, S.; Knyazikhin, Y.; Privette, J.L.; Glassy, J.; Tian, Y.; Wang, Y.; Song, X.; Zhang, Y.; Smith, G.R.; et al. Global products of vegetation leaf area and fraction absorbed PAR from year one of MODIS data. Remote Sens. Environ. 2002, 83, 214–231. [Google Scholar] [CrossRef]
- Baret, F.; Weiss, M.; Lacaze, R.; Camacho, F.; Makhmara, H.; Pacholcyzk, P.; Smets, B. GEOV1: LAI and FAPAR essential climate variables and FCOVER global time series capitalizing over existing products. Part1: Principles of development and production. Remote Sens. Environ. 2013, 137, 299–309. [Google Scholar] [CrossRef]
- DAHV (Department of Animal Husbandry and Veterinary, the Ministry of Agriculture of the People’s Republic of China); NAHVS (National Animal Husbandry and Veterinary Service; The Ministry of Agriculture of the People’s Republic of China). Rangeland Resources of China; China Science and Technology Press: Beijing, China, 1996. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Liu, J.J.; Zhou, T.; Luo, H.; Liu, X.; Yu, P.X.; Zhang, Y.J.; Zhou, P.F. Diverse roles of previous years’ water conditions in gross primary productivity in China. Remote Sens. 2021, 13, 58. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Lek, S.; Guégan, J.F. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Chen, Z.L.; Jia, K.; Xiao, C.; Wei, D.D.; Zhao, X.; Lan, J.H.; Wei, X.Q.; Yao, Y.Y.; Wang, B.; Sun, Y.; et al. Leaf area index estimation algorithm for GF-5 hyperspectral data based on different feature selection and machine learning methods. Remote Sens. 2020, 12, 2110. [Google Scholar] [CrossRef]
- Tiryaki, S.; Aydin, A. An artificial neural network model for predicting compression strength of heat treated woods and comparison with a multiple linear regression model. Constr. Build. Mater. 2014, 62, 102–108. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cherkassky, V.; Ma, Y.Q. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef]
- Liu, J.G.; Pattey, E.; Jégo, G. Assessment of vegetation indices for regional crop green LAI estimation from Landsat images over multiple growing seasons. Remote Sens. Environ. 2012, 123, 347–358. [Google Scholar] [CrossRef]
- Xu, D.W.; Wang, C.; Chen, J.; Shen, M.G.; Shen, B.B.; Yan, R.R.; Li, Z.W.; Karnieli, A.; Chen, J.Q.; Yan, Y.C.; et al. The superiority of the normalized difference phenology index (NDPI) for estimating grassland aboveground fresh biomass. Remote Sens. Environ. 2021, 264, 112578. [Google Scholar] [CrossRef]
- Ding, L. Simulating Production Capacity of Grassland in Northeastern China and Analysising Its Spatiotemporal Patterns. Ph.D. Thesis, Graduate School of Chinese Academy of Agricultural Sciences, Beijing, China, 2021. [Google Scholar]
- Ge, J.; Hou, M.J.; Liang, T.G.; Feng, Q.S.; Meng, X.Y.; Liu, J.; Bao, X.Y.; Gao, H.Y. Spatiotemporal dynamics of grassland aboveground biomass and its driving factors in North China over the past 20 years. Sci. Total Environ. 2022, 826, 154226. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.C.; Luo, Z.K.; Huang, Y.; Sun, W.J.; Wei, Y.R.; Xiao, L.J.; Deng, X.; Zhu, J.H.; Li, T.T.; Zhang, W. Simulating the spatiotemporal variations in aboveground biomass in Inner Mongolian grasslands under environmental changes. Atmos. Chem. Phys. 2021, 21, 3059–3071. [Google Scholar] [CrossRef]
- Dong, T.F.; Liu, J.G.; Shang, J.L.; Qian, B.D.; Ma, B.L.; Kovacs, J.M.; Walters, D.; Jiao, X.F.; Geng, X.Y.; Shi, Y.C. Assessment of red-edge vegetation indices for crop leaf area index estimation. Remote Sens. Environ. 2019, 222, 133–143. [Google Scholar] [CrossRef]
- Jiapaer, G.; Liang, S.L.; Yi, Q.X.; Liu, J.P. Vegetation dynamics and responses to recent climate change in Xinjiang using leaf area index as an indicator. Ecol. Indic. 2015, 58, 64–76. [Google Scholar] [CrossRef]
- Fang, H.L.; Wei, S.S.; Liang, S.L. Validation of MODIS and CYCLOPES LAI products using global field measurement data. Remote Sens. Environ. 2012, 119, 43–54. [Google Scholar] [CrossRef]
- Jiang, J.Y.; Xiao, Z.Q.; Wang, J.D.; Song, J.L. Multiscale estimation of leaf area index from satellite observations based on an ensemble multiscale filter. Remote Sens. 2016, 8, 229. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation Index | Equation | References |
|---|---|---|
| Ratio Vegetation Index | [30] | |
| Normalized Difference Vegetation Index | [31] | |
| Transformed Difference Vegetation Index | [32] | |
| Chlorophyll Index | [33] | |
| Normalized Difference Phenology Index | [34] |
| Variables | RFR | ANNR | SVR | |||
|---|---|---|---|---|---|---|
| %IncMSE | Ranks | Contribution (%) | Ranks | Importance | Ranks | |
| NDPI | 23.39 | 1 | 30.66 | 1 | 0.21 | 1 |
| NDVI | 18.48 | 3 | 16.79 | 3 | 0.14 | 2 |
| RVI | 19.00 | 2 | 2.67 | 6 | 0.11 | 4 |
| MAP | 13.36 | 4 | 2.23 | 7 | 0.11 | 3 |
| TDVI | 7.62 | 6 | 16.94 | 2 | 0.06 | 7 |
| CI | 12.27 | 5 | 13.87 | 4 | 0.04 | 9 |
| Clay | −0.65 | 10 | 12.72 | 5 | 0.10 | 5 |
| Slope | 0.33 | 9 | 1.35 | 9 | 0.09 | 6 |
| SOC | 6.19 | 7 | 0.19 | 11 | 0.05 | 8 |
| DEM | 5.68 | 8 | 1.14 | 10 | 0.04 | 10 |
| Sand | −2.19 | 11 | 1.44 | 8 | 0.04 | 11 |
| Product Types | Spatial Resolution | Date | |||
|---|---|---|---|---|---|
| 123026 | 122028 | 124029 | 126030 | ||
| Landsat LAI | 30 m | 16 July 2019 | 22 July 2018 | 17 July 2017 | 28 July 2016 |
| MODIS LAI | 500 m | 19 July 2019 | 27 July 2018 | 19 July 2017 | 26 July 2016 |
| GEOV2 LAI | 1 km | 20 July 2019 | 20 July 2018 | 20 July 2017 | 31 July 2016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, B.; Ding, L.; Ma, L.; Li, Z.; Pulatov, A.; Kulenbekov, Z.; Chen, J.; Mambetova, S.; Hou, L.; Xu, D.; et al. Modeling the Leaf Area Index of Inner Mongolia Grassland Based on Machine Learning Regression Algorithms Incorporating Empirical Knowledge. Remote Sens. 2022, 14, 4196. https://doi.org/10.3390/rs14174196
Shen B, Ding L, Ma L, Li Z, Pulatov A, Kulenbekov Z, Chen J, Mambetova S, Hou L, Xu D, et al. Modeling the Leaf Area Index of Inner Mongolia Grassland Based on Machine Learning Regression Algorithms Incorporating Empirical Knowledge. Remote Sensing. 2022; 14(17):4196. https://doi.org/10.3390/rs14174196
Chicago/Turabian StyleShen, Beibei, Lei Ding, Leichao Ma, Zhenwang Li, Alim Pulatov, Zheenbek Kulenbekov, Jiquan Chen, Saltanat Mambetova, Lulu Hou, Dawei Xu, and et al. 2022. "Modeling the Leaf Area Index of Inner Mongolia Grassland Based on Machine Learning Regression Algorithms Incorporating Empirical Knowledge" Remote Sensing 14, no. 17: 4196. https://doi.org/10.3390/rs14174196
APA StyleShen, B., Ding, L., Ma, L., Li, Z., Pulatov, A., Kulenbekov, Z., Chen, J., Mambetova, S., Hou, L., Xu, D., Wang, X., & Xin, X. (2022). Modeling the Leaf Area Index of Inner Mongolia Grassland Based on Machine Learning Regression Algorithms Incorporating Empirical Knowledge. Remote Sensing, 14(17), 4196. https://doi.org/10.3390/rs14174196