
PGNet: Positioning Guidance Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Images


Abstract
:1. Introduction
- To the best of our knowledge, the proposed PGNet is the first to efficiently propagate the long-range dependence obtained by ViT to all pyramid-level feature maps in the semantic segmentation of VHR remote sensing images.
- The proposed PGM can effectively locate different semantic objects and then effectively solve the problem of large intra-class and small inter-class variations in VHR remote sensing images.
- The proposed SMCM can effectively extract multiscale information and then stably segment objects at different scales in VHR remote sensing images.
2. Related Work
2.1. Semantic Segmentation of VHR Remote Sensing Images
2.2. Transformer in Vision
3. Proposed Method
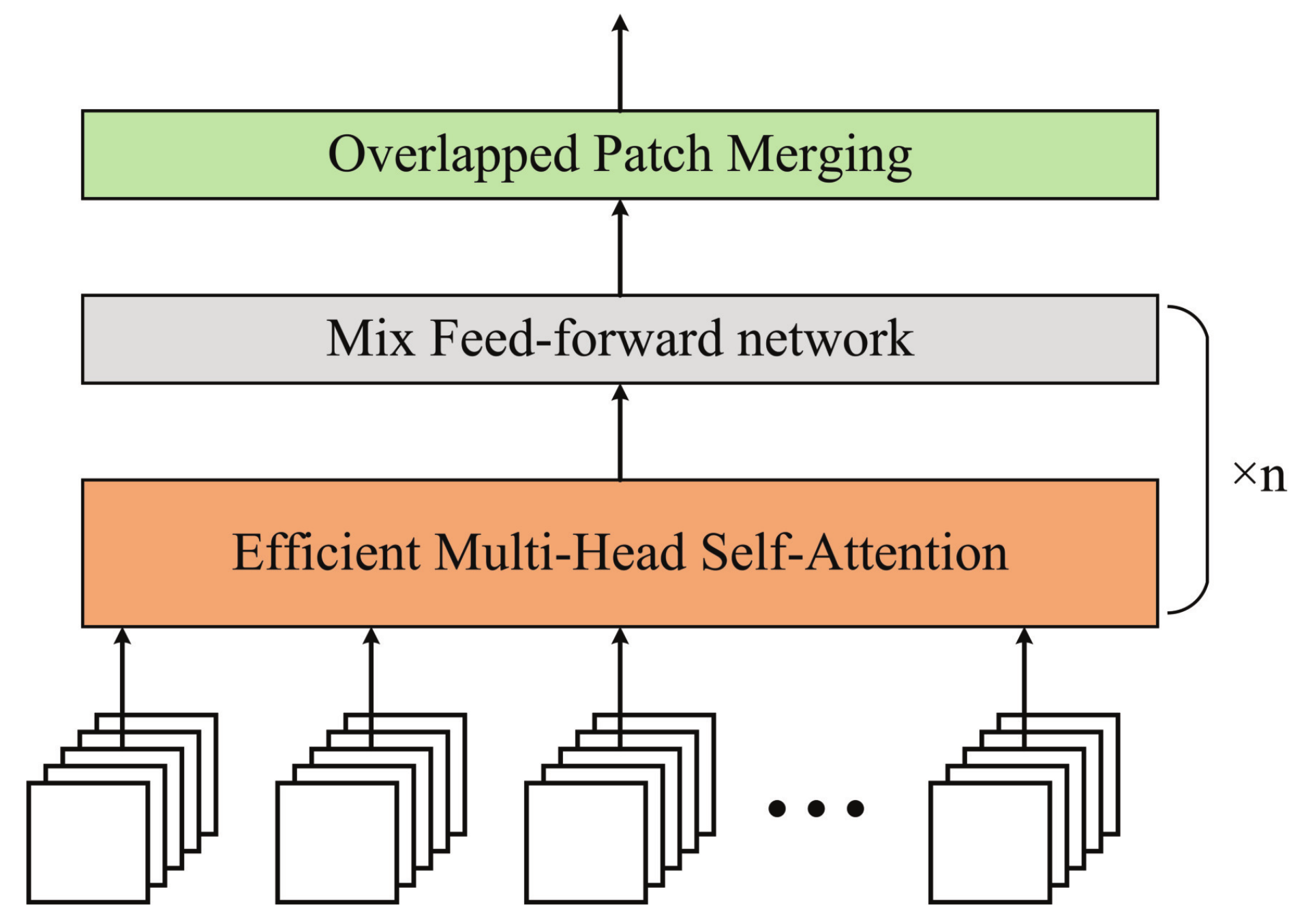
3.1. Feature Extractor
3.2. Positioning Guidance Module
3.3. Self-Multiscale Collection Module
3.4. Loss Function
4. Experiments and Discussions
4.1. Experimental Settings
4.1.1. Dataset Description
4.1.2. Comparison Methods and Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparative Experiments and Analysis
4.2.1. Experiments on the iSAID Dataset
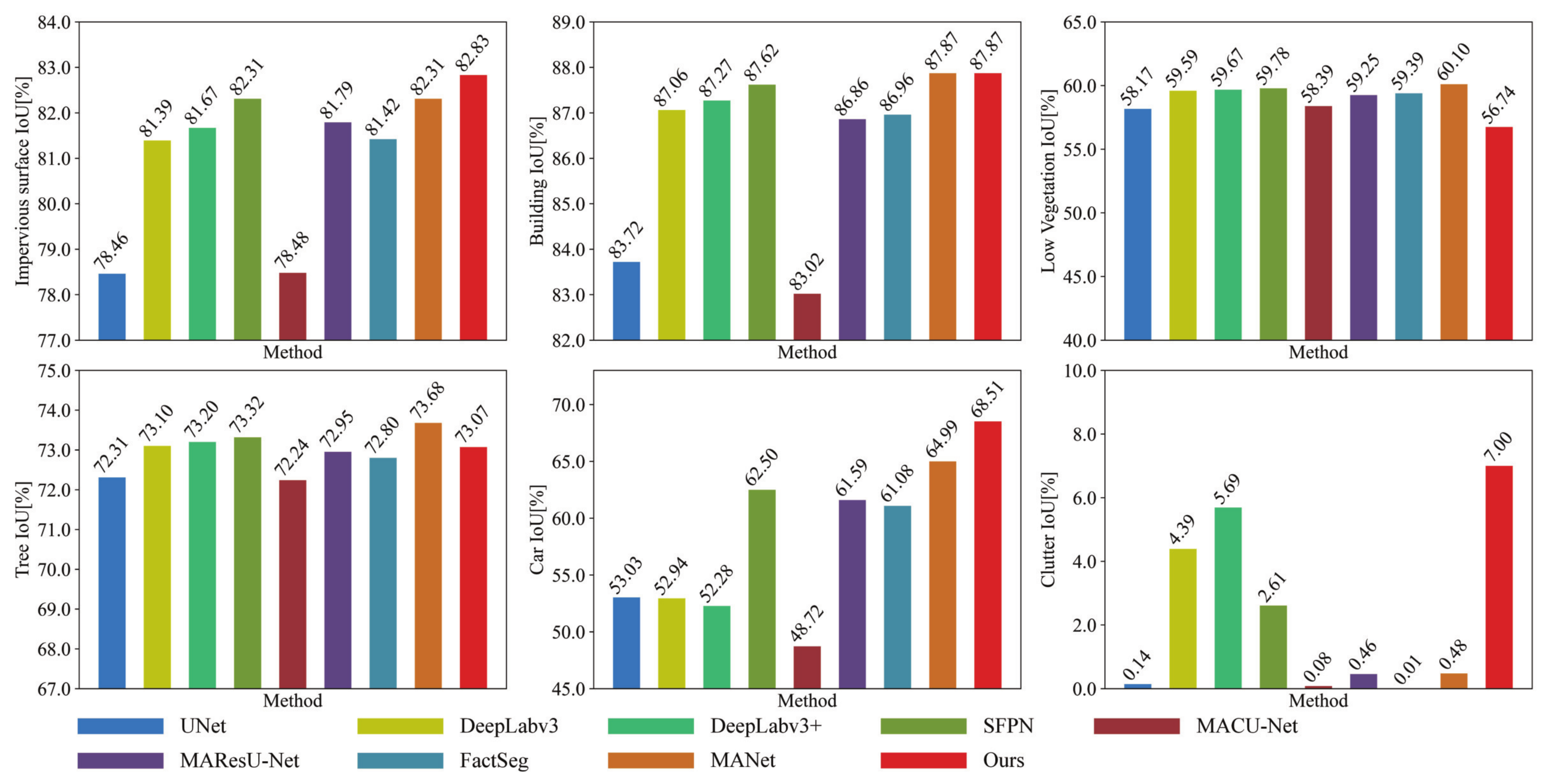
4.2.2. Experiments on the ISPRS Vaihingen Dataset

4.3. Ablation Experiments
4.3.1. Effect of Positioning Guidance Module

4.3.2. Effect of Self-Multiscale Collection Module
4.3.3. The Visualization Results of Ablation Experiments
4.3.4. Analysis of Different Feature Extractors

4.4. Analysis of Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LULC | Land Use and Land Cover |
| VHR | Very High Resolution |
| CNN | Convolutional Neural Network |
| ViT | Vision Transformer |
| PGNet | Positioning Guidance Network |
| PGM | Positioning Guidance Module |
| SMCM | Self-Multiscale Collection Module |
| RAG | Region Adjacency Graph |
| SRM | Statistical Region Merging |
| LBP | Local Binary Pattern |
| RHLBP | Regional Homogeneity Local Binary Pattern |
| SVM | Support-vector Machine |
| PSP | Pyramid Scene Parsing |
| PAM | Patch Attention Module |
| AEM | Attention Embedding Module |
| SOTA | State-Of-The-Art |
| PVT | Pyramid Vision Transformer |
| NLP | Natural Language Processing |
| MSA | Multi-head Self-Attention |
| QKV | Query-Key-Value |
References
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Lazarowska, A. Review of Collision Avoidance and Path Planning Methods for Ships Utilizing Radar Remote Sensing. Remote Sens. 2021, 13, 3265. [Google Scholar] [CrossRef]
- Ma, A.; Wang, J.; Zhong, Y.; Zheng, Z. FactSeg: Foreground Activation-Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606216. [Google Scholar] [CrossRef]
- Ding, L.; Lin, D.; Lin, S.; Zhang, J.; Cui, X.; Wang, Y.; Tang, H.; Bruzzone, L. Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410313. [Google Scholar] [CrossRef]
- Sahar, L.; Muthukumar, S.; French, S.P. Using aerial imagery and GIS in automated building footprint extraction and shape recognition for earthquake risk assessment of urban inventories. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3511–3520. [Google Scholar] [CrossRef]
- Tang, X.; Tu, Z.; Wang, Y.; Liu, M.; Li, D.; Fan, X. Automatic Detection of Coseismic Landslides Using a New Transformer Method. Remote Sens. 2022, 14, 2884. [Google Scholar] [CrossRef]
- Bi, H.; Xu, F.; Wei, Z.; Xue, Y.; Xu, Z. An active deep learning approach for minimally supervised PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9378–9395. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and Transformer Network for Crop Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Han, Z.; Hu, W.; Peng, S.; Lin, H.; Zhang, J.; Zhou, J.; Wang, P.; Dian, Y. Detection of Standing Dead Trees after Pine Wilt Disease Outbreak with Airborne Remote Sensing Imagery by Multi-Scale Spatial Attention Deep Learning and Gaussian Kernel Approach. Remote Sens. 2022, 14, 3075. [Google Scholar] [CrossRef]
- Bi, X.; Hu, J.; Xiao, B.; Li, W.; Gao, X. IEMask R-CNN: Information-enhanced Mask R-CNN. IEEE Trans. Big Data 2022, 1–13. [Google Scholar] [CrossRef]
- Xiao, B.; Yang, Z.; Qiu, X.; Xiao, J.; Wang, G.; Zeng, W.; Li, W.; Nian, Y.; Chen, W. PAM-DenseNet: A Deep Convolutional Neural Network for Computer-Aided COVID-19 Diagnosis. IEEE Trans. Cybern. 2021, 1–12. [Google Scholar] [CrossRef]
- Lei, J.; Gu, Y.; Xie, W.; Li, Y.; Du, Q. Boundary Extraction Constrained Siamese Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5621613. [Google Scholar] [CrossRef]
- Bi, X.; Shuai, C.; Liu, B.; Xiao, B.; Li, W.; Gao, X. Privacy-Preserving Color Image Feature Extraction by Quaternion Discrete Orthogonal Moments. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1655–1668. [Google Scholar] [CrossRef]
- Cheng, J.; Ji, Y.; Liu, H. Segmentation-based PolSAR image classification using visual features: RHLBP and color features. Remote Sens. 2015, 7, 6079–6106. [Google Scholar] [CrossRef]
- Zhang, X.; Xiao, P.; Song, X.; She, J. Boundary-constrained multi-scale segmentation method for remote sensing images. ISPRS J. Photogramm. Remote Sens. 2013, 78, 15–25. [Google Scholar] [CrossRef]
- Wang, M.; Dong, Z.; Cheng, Y.; Li, D. Optimal Segmentation of High-Resolution Remote Sensing Image by Combining Superpixels with the Minimum Spanning Tree. IEEE Trans. Geosci. Remote Sens. 2018, 56, 228–238. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607713. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4096–4105. [Google Scholar]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007205. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage attention ResU-Net for semantic segmentation of fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8009205. [Google Scholar] [CrossRef]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 28–37. [Google Scholar]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef]
- Wang, G.; Ren, P. Hyperspectral image classification with feature-oriented adversarial active learning. Remote Sens. 2020, 12, 3879. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Cui, B.; Chen, X.; Lu, Y. Semantic segmentation of remote sensing images using transfer learning and deep convolutional neural network with dense connection. IEEE Access 2020, 8, 116744–116755. [Google Scholar] [CrossRef]
- Stan, S.; Rostami, M. Unsupervised model adaptation for continual semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2593–2601. [Google Scholar]
- Bosilj, P.; Aptoula, E.; Duckett, T.; Cielniak, G. Transfer learning between crop types for semantic segmentation of crops versus weeds in precision agriculture. J. Field Robot. 2020, 37, 7–19. [Google Scholar] [CrossRef]
- Pan, F.; Shin, I.; Rameau, F.; Lee, S.; Kweon, I.S. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3764–3773. [Google Scholar]
- Xu, Q.; Ma, Y.; Wu, J.; Long, C.; Huang, X. Cdada: A curriculum domain adaptation for nighttime semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2962–2971. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Ke, L.; Danelljan, M.; Li, X.; Tai, Y.W.; Tang, C.K.; Yu, F. Mask Transfiner for High-Quality Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 4412–4421. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged object segmentation with distraction mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8772–8781. [Google Scholar]
- Liu, J.J.; Hou, Q.; Liu, Z.A.; Cheng, M.M. Poolnet+: Exploring the potential of pooling for salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An Empirical Study of Remote Sensing Pretraining. IEEE Trans. Geosci. Remote Sens. 2022. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [Green Version]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Pang, Y.; Zhao, X.; Xiang, T.Z.; Zhang, L.; Lu, H. Zoom in and Out: A Mixed-Scale Triplet Network for Camouflaged Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21 June 2022; pp. 2160–2170. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing semantics through points for aerial image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4217–4226. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Year | Training | Validation | Test | Class | Metrics |
|---|---|---|---|---|---|---|
| iSAID dataset [24] | 2019 | 1411 | 937 | 458 | 16 | |
| ISPRS Vaihingen dataset [25] | 2016 | 11 | 0 | 5 | 6 | , , |
| Method | per Class (%) | Rank | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BG | Ship | ST | BD | TC | BC | GTF | Bridge | LV | SV | HC | SP | RA | SBF | Plane | Harbor | |||
| UNet [46] | 35.57 (±5.63) | 98.16 (±0.22) | 48.10 (±3.81) | 0.00 (±0.00) | 17.09 (±15.32) | 73.20 (±10.19) | 8.74 (±8.01) | 18.44 (±4.09) | 3.66 (±3.22) | 51.58 (±3.36) | 36.43 (±2.48) | 0.00 (±0.00) | 32.81 (±5.32) | 39.09 (±5.81) | 26.53 (±18.45) | 69.47 (±7.17) | 45.84 (±3.46) | 8 |
| DeepLabv3 [23] | 59.26 (±0.25) | 98.72 (±0.01) | 59.78 (±0.31) | 52.17 (±1.09) | 76.05 (±0.95) | 84.64 (±0.12) | 60.44 (±0.43) | 59.61 (±0.83) | 32.45 (±0.55) | 54.94 (±0.12) | 34.52 (±0.09) | 28.55 (±1.44) | 44.70 (±0.94) | 66.85 (±0.24) | 73.93 (±0.68) | 75.98 (±0.03) | 44.66 (±0.81) | 5 |
| DeepLabv3+ [52] | 59.45 (±0.07) | 98.72 (±0.01) | 59.38 (±0.08) | 52.56 (±1.05) | 77.23 (±0.77) | 84.72 (±0.21) | 61.11 (±0.75) | 59.74(±1.79) | 32.65 (±0.29) | 54.96 (±0.25) | 34.77 (±0.62) | 28.70 (±1.92) | 44.91 (±0.85) | 66.62 (±0.63) | 74.28 (±0.20) | 76.06 (±0.16) | 44.87 (±0.97) | 4 |
| SFPN [47] | 61.55 (±0.17) | 98.85 (±0.01) | 64.58 (±0.25) | 58.41 (±2.16) | 75.19 (±0.89) | 86.65 (±0.28) | 57.83 (±1.07) | 51.51 (±1.18) | 33.88 (±0.53) | 58.75 (±0.45) | 45.21 (±0.07) | 30.82 (±1.10) | 47.82 (±0.49) | 68.65 (±0.28) | 72.16 (±0.91) | 81.15 (±0.29) | 53.31 (±0.21) | 3 |
| MACU-Net [20] | 31.44 (±0.71) | 98.12 (±0.06) | 44.53 (±0.49) | 0.00 (±0.00) | 2.57 (±4.46) | 67.57 (±0.87) | 0.14 (±0.24) | 23.64 (±1.54) | 0.00 (±0.00) | 47.05 (±0.69) | 29.32 (±2.57) | 0.00 (±0.00) | 26.31 (±8.93) | 13.01 (±7.12) | 45.57 (±5.75) | 64.06 (±1.03) | 41.05 (±1.43) | 9 |
| MAResU-Net [21] | 44.46 (±2.67) | 98.66 (±0.03) | 59.92 (±1.10) | 8.18 (±14.16) | 17.14 (±28.69) | 84.64 (±1.46) | 42.18 (±4.45) | 47.14 (±2.42) | 3.09 (±4.46) | 56.92 (±0.65) | 40.01 (±0.77) | 0.00 (±0.00) | 0.83 (±1.44) | 64.28 (±2.06) | 61.04 (±2.81) | 78.64 (±0.83) | 48.73 (±1.78) | 7 |
| FactSeg [3] | 63.88 (±0.32) | 98.91 (±0.01) | 68.34 (±0.30) | 60.01(±2.48) | 77.02 (±0.84) | 89.04(±0.29) | 57.36 (±1.15) | 53.32 (±1.65) | 36.62 (±0.82) | 61.89 (±0.51) | 49.51 (±0.61) | 38.45(±0.76) | 50.09 (±0.50) | 71.39 (±0.82) | 71.70 (±0.55) | 83.90 (±0.37) | 54.53 (±0.75) | 2 |
| MANet [18] | 58.90 (±1.46) | 98.84 (±0.03) | 64.29 (±1.15) | 50.06 (±3.62) | 69.40 (±1.93) | 87.67 (±0.18) | 56.96 (±1.46) | 48.18 (±3.28) | 31.33 (±0.93) | 59.40 (±0.52) | 46.36 (±1.15) | 10.44 (±14.64) | 45.74 (±2.26) | 68.60 (±0.23) | 68.15 (±1.40) | 81.91 (±0.31) | 55.06 (±0.97) | 6 |
| Ours | 65.37(±0.20) | 98.96(±0.02) | 70.76(±0.37) | 59.74 (±2.57) | 77.42(±0.23) | 88.56 (±0.09) | 65.41(±0.46) | 54.32 (±4.40) | 37.35(±0.40) | 62.35(±0.19) | 51.85(±0.35) | 38.09 (±0.61) | 50.26(±2.94) | 73.08(±0.39) | 75.53(±0.32) | 84.85(±0.12) | 57.43(±0.88) | 1 |
| Method | per Class (%) | Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | Clutter | |||||
| UNet [46] | 57.63 (±0.36) | 67.69 (±0.22) | 84.62 (±0.21) | 87.93 (±0.38) | 91.13 (±0.36) | 73.55 (±0.19) | 83.92 (±0.27) | 69.30 (±0.97) | 0.29 (±0.40) | 8 |
| DeepLabv3 [23] | 59.75 (±0.24) | 69.93 (±0.42) | 85.96 (±0.12) | 89.74 (±0.12) | 93.08 (±0.20) | 74.67 (±0.30) | 84.46 (±0.02) | 69.23 (±0.36) | 8.38 (±2.46) | 7 |
| DeepLabv3+ [52] | 59.97 (±0.15) | 70.30 (±0.19) | 86.07 (±0.09) | 89.91 (±0.13) | 93.21 (±0.06) | 74.74 (±0.22) | 84.53 (±0.15) | 68.66 (±0.40) | 10.76 (±1.08) | 6 |
| SFPN [47] | 61.21 (±0.42) | 70.57 (±0.66) | 86.36 (±0.08) | 90.29 (±0.07) | 93.04 (±0.07) | 74.82 (±0.15) | 84.60 (±0.10) | 76.92 (±0.27) | 3.39 (±3.46) | 3 |
| MACU-Net [20] | 56.82 (±0.21) | 66.99 (±0.14) | 84.48 (±0.17) | 87.94 (±0.32) | 90.72 (±0.38) | 73.73 (±0.32) | 83.88 (±0.18) | 65.51 (±1.14) | 0.16 (±0.25) | 9 |
| MAResU-Net [21] | 60.48 (±0.14) | 69.81 (±0.23) | 85.92 (±0.05) | 89.98 (±0.24) | 92.97 (±0.25) | 74.41 (±0.31) | 84.36 (±0.17) | 76.23 (±0.80) | 0.91 (±1.30) | 4 |
| FactSeg [3] | 60.27 (±0.51) | 69.57 (±0.38) | 85.95 (±0.18) | 89.76 (±0.23) | 93.02 (±0.11) | 74.52 (±0.42) | 84.25 (±0.10) | 75.82 (±1.66) | 0.01 (±0.02) | 5 |
| MANet [18] | 61.57 (±0.08) | 70.58 (±0.22) | 86.51(±0.01) | 90.29 (±0.02) | 93.53 (±0.13) | 75.07(±0.07) | 84.84(±0.05) | 78.78 (±0.42) | 0.95 (±1.65) | 2 |
| Ours | 62.67(±0.30) | 72.56(±0.32) | 86.32 (±0.06) | 90.61(±0.12) | 93.54(±0.13) | 72.39 (±0.28) | 84.44 (±0.25) | 81.31(±1.10) | 13.08(±1.88) | 1 |
| Version | per Class (%) | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BG | Ship | ST | BD | TC | BC | GTF | Bridge | LV | SV | HC | SP | RA | SBF | Plane | Harbor | ||
| Bas. | 63.15 | 98.90 | 69.04 | 54.69 | 79.77 | 87.72 | 63.07 | 51.93 | 36.62 | 61.45 | 49.36 | 37.48 | 45.48 | 67.01 | 69.28 | 83.71 | 54.95 |
| Bas. + PGM | 65.16 | 98.96 | 70.29 | 67.74 | 78.68 | 87.80 | 59.87 | 58.79 | 37.58 | 60.25 | 50.30 | 36.69 | 50.21 | 70.37 | 74.82 | 84.04 | 56.23 |
| Bas. + PGM + SMCM | 65.55 | 98.98 | 70.77 | 58.63 | 77.54 | 88.62 | 64.96 | 57.70 | 37.50 | 62.15 | 52.19 | 38.68 | 50.28 | 73.06 | 75.78 | 84.94 | 57.07 |
| Version | per Class (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | Clutter | ||||
| Bas. | 60.83 | 69.96 | 86.25 | 90.31 | 93.16 | 75.08 | 84.10 | 77.13 | 0.00 |
| Bas. + PGM | 61.13 | 70.17 | 86.23 | 90.46 | 93.23 | 74.83 | 84.34 | 78.18 | 0.09 |
| Bas. + PGM + SMCM | 62.88 | 72.91 | 86.35 | 90.57 | 93.54 | 72.23 | 84.52 | 81.44 | 15.14 |
| Version | Backbone | per Class (%) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BG | Ship | ST | BD | TC | BC | GTF | Bridge | LV | SV | HC | SP | RA | SBF | Plane | Harbor | ||||
| Bas. | ResNet50 | 61.51 | 98.85 | 64.29 | 57.54 | 76.13 | 86.33 | 58.48 | 50.70 | 33.31 | 58.92 | 45.13 | 31.48 | 48.39 | 68.95 | 71.24 | 81.20 | 53.18 | |
| Ours | 63.88 | +2.37 | 98.92 | 67.54 | 61.30 | 78.61 | 87.54 | 62.01 | 58.47 | 34.18 | 62.40 | 48.90 | 33.26 | 48.52 | 69.84 | 72.12 | 82.77 | 55.62 | |
| Bas. | Res2Net50 | 63.15 | 98.90 | 69.04 | 54.69 | 79.77 | 87.72 | 63.07 | 51.93 | 36.62 | 61.45 | 49.36 | 37.48 | 45.48 | 67.01 | 69.28 | 83.71 | 54.95 | |
| Ours | 65.55 | +2.40 | 98.98 | 70.77 | 58.63 | 77.54 | 88.62 | 64.96 | 57.70 | 37.50 | 62.15 | 52.19 | 38.68 | 50.28 | 73.06 | 75.78 | 84.94 | 57.07 | |
| Method | Parameters (M) | Time (s/Img) | |
|---|---|---|---|
| UNet [46] | 67.69 ± 0.22 | 9.85 | 8.4 |
| DeepLabv3 [23] | 69.93 ± 0.42 | 39.05 | 11.2 |
| DeepLabv3+ [52] | 70.30 ± 0.19 | 39.05 | 12.0 |
| SFPN [47] | 70.57 ± 0.66 | 28.48 | 11.4 |
| MACU-Net [20] | 66.99 ± 0.14 | 5.15 | 9.8 |
| MAResU-Net [21] | 69.81 ± 0.23 | 26.58 | 11.6 |
| FactSeg [3] | 69.57 ± 0.38 | 33.45 | 11.0 |
| MANet [18] | 70.58 ± 0.22 | 35.86 | 11.2 |
| Ours | 72.56 ± 0.32 | 42.67 | 12.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Hu, J.; Bi, X.; Li, W.; Gao, X. PGNet: Positioning Guidance Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 4219. https://doi.org/10.3390/rs14174219
Liu B, Hu J, Bi X, Li W, Gao X. PGNet: Positioning Guidance Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Images. Remote Sensing. 2022; 14(17):4219. https://doi.org/10.3390/rs14174219
Chicago/Turabian StyleLiu, Bo, Jinwu Hu, Xiuli Bi, Weisheng Li, and Xinbo Gao. 2022. "PGNet: Positioning Guidance Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Images" Remote Sensing 14, no. 17: 4219. https://doi.org/10.3390/rs14174219
APA StyleLiu, B., Hu, J., Bi, X., Li, W., & Gao, X. (2022). PGNet: Positioning Guidance Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Images. Remote Sensing, 14(17), 4219. https://doi.org/10.3390/rs14174219