
M-O SiamRPN with Weight Adaptive Joint MIoU for UAV Visual Localization

Abstract
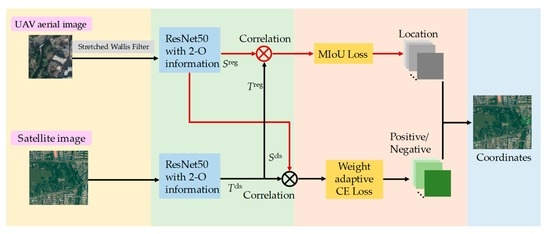
:
1. Introduction
- Pseudo-features caused by shadows: The height variation in the terrain and tall buildings lead to shadows in the collected aerial images [26], and the flight time of the UAV is uncertain, so the changing light conditions during a day cause different shadow appearance. These non-ideal effects result in the original information being masked and generating pseudo-edges, which make it difficult to extract the desired features.
- Blurred edge of tiny target: Because of the large size of aerial images, the target in the hole image occupies a small number of pixels with tiny sizes, which are easily disturbed by the background [27]. Since aerial images are usually acquired in motion, there exist blurred edges of the target image due to shaking. The high-resolution features and high-level semantic features of the deep network cannot be obtained at the same time [28]. After multi-layer feature extraction, the features of small targets may be lost. Consequently, it is necessary to explore feature extraction for blurred edges of tiny targets.
- Information imbalance: The regions whose overlapping rate with the target region are less than the threshold value are defined as negative samples, resulting in an unavoidable class imbalance in the target detection task [29]. The loss in backpropagation is obtained by accumulating all samples in a batch, so the training process is dominated by negative samples and the positive samples are not sufficiently trained.
- An improved Wallis shadow automatic compensation method is proposed. A pixel contrast-based stretching factor is constructed to increase the effectiveness of shadow compensation of the Wallis filter. The recovered images are used for searching and matching to reduce the effect of shadows on localization results.
- Multi-order features based on spatial continuity are generated to extract the blurred edges of tiny targets. Here, a feature map selection criterion based on spatial continuity is proposed to construct the second-order feature via a first-order feature map with richer spatial information Normalized covariance is introduced in the Siamese network structure to increase the second-order information and enhance the sensitivity of features to edges.
- To improve the classification and location regression performance degradation caused by positive and negative sample imbalance, we propose a weight adaptive joint multiple intersection over union loss function. Depending on the number of positive and negative samples, the weight adaptive scale automatically changes the loss penalty factor for classification. In addition, multiple intersection over union (MIoU) based on generalized intersection over union (GIoU) and distance intersection over union (DIoU) are constructed to constrain the regression anchor box from different perspectives.
2. Materials and Methods
2.1. Pre-Processing: Stretched Wallis Shadow Compensation Method
2.2. M-O SiamRPN with Weight Adaptive Joint Multiple Intersection over Union for Visual Localization
2.2.1. M-O SiamRPN Framework
- Siamese ResNet backbone: Inspired by SiamRPN, the first-order features used for classification and regression to perform correlation are extracted by the Siamese structure of shared weights. Here, to enhance the feature representation, AlexNet is replaced with Resnet50 [22] in the original SiamRPN structure to increase the network depth.
- Multiple-order information generation module is constructed to sufficiently exploit the complementary characteristics of texture sensitivity of second-order information with the semantic information of first-order features and the different resolution features. For further increasing the representation of second-order features for texture, as well as removing redundant information to avoid overly complex networks, a convolution kernel selection criterion based on spatial continuity is proposed. Using this criterion, first-order features with richer texture information are selected for the generation of second-order information. The second-order information is introduced by adding the covariance matrix to the residual module.
- RPN with multiple constraints: Corresponding to the Siamese structure used for feature extraction, RPN also contains two branches: the classification branch and the regression branch, where both branches are performed with correlation operations as:
2.2.2. First-Order Feature Selection Criteria Based on Spatially Continuity
2.2.3. Multiple-Order Feature for Blurred Edges of Tiny Target
2.2.4. Weight Adaptive Joint Multiple Intersection over Union Loss Function
2.3. Experiment Setup
2.3.1. Details about UAV Platform
2.3.2. Dataset
2.3.3. Network Parameters
2.3.4. Evaluation Metrics
3. Results
3.1. Training Process Results
3.2. Performance Evaluation
3.3. Contribution of Multiple-Order Feature
3.4. Contribution of Weight Adaptive Joint MIoU Loss Function
3.5. Qualitative Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, W.; Li, H.; Wu, Q.; Chen, X.; Ngan, K.N. Simultaneously detecting and counting dense vehicles from drone images. IEEE Trans. Ind. Electron. 2019, 66, 9651–9662. [Google Scholar] [CrossRef]
- Ye, Z.; Wei, J.; Lin, Y.; Guo, Q.; Zhang, J.; Zhang, H.; Deng, H.; Yang, K. Extraction of Olive Crown Based on UAV Visible Images and the U2-Net Deep Learning Model. Remote Sens. 2022, 14, 1523. [Google Scholar] [CrossRef]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-Area Image Geolocalization with Aerial Reference Imagery. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3961–3969. [Google Scholar]
- Morales, J.J.; Kassas, Z.M. Tightly Coupled Inertial Navigation System with Signals of Opportunity Aiding. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1930–1948. [Google Scholar] [CrossRef]
- Zhang, F.; Shan, B.; Wang, Y.; Hu, Y.; Teng, H. MIMU/GPS Integrated Navigation Filtering Algorithm under the Condition of Satellite Missing. In Proceedings of the IEEE CSAA Guidance, Navigation and Control Conference (GNCC), Xiamen, China, 10–12 August 2018. [Google Scholar]
- Liu, Y.; Luo, Q.; Zhou, Y. Deep Learning-Enabled Fusion to Bridge GPS Outages for INS/GPS Integrated Navigation. IEEE Sens. J. 2022, 22, 8974–8985. [Google Scholar] [CrossRef]
- Guo, Y.; Wu, M.; Tang, K.; Tie, J.; Li, X. Covert spoofing algorithm of UAV based on GPS/INS-integrated navigation. IEEE Trans. Veh. Technol. 2019, 68, 6557–6564. [Google Scholar] [CrossRef]
- Wortsman, M.; Ehsani, K.; Rastegari, M.; Farhadi, A.; Mottaghi, R. Learning to Learn How to Learn: Self-Adaptive Visual Navigation Using Meta-Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6743–6752. [Google Scholar]
- Qian, J.; Chen, K.; Chen, Q.; Yang, Y.; Zhang, J.; Chen, S. Robust Visual-Lidar Simultaneous Localization and Mapping System for UAV. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. arXiv 2020, arXiv:2002.12186. [Google Scholar]
- Liu, Y.; Tao, J.; Kong, D.; Zhang, Y.; Li, P. A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation. Remote Sens. 2022, 14, 1430. [Google Scholar] [CrossRef]
- Majdik, A.L.; Verda, D.; Albers-Schoenberg, Y.; Scaramuzza, D. Air-ground matching: Appearance-based gps-denied urban localization of micro aerial vehicles. J. Field Robot. 2015, 32, 1015–1039. [Google Scholar] [CrossRef]
- Chang, K.; Yan, L. LLNet: A Fusion Classification Network for Land Localization in Real-World Scenarios. Remote Sens. 2022, 14, 1876. [Google Scholar] [CrossRef]
- Zhai, R.; Yuan, Y. A Method of Vision Aided GNSS Positioning Using Semantic Information in Complex Urban Environment. Remote Sens. 2022, 14, 869. [Google Scholar] [CrossRef]
- Nassar, A.; Amer, K.; ElHakim, R.; ElHelw, M. A Deep CNN-Based Framework for Enhanced Aerial Imagery Registration with Applications to UAV Geolocalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1513–1523. [Google Scholar]
- Ahn, S.; Kang, H.; Lee, J. Aerial-Satellite Image Matching Framework for UAV Absolute Visual Localization using Contrastive Learning. In Proceedings of the International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 12–15 October 2021. [Google Scholar]
- Wu, Q.; Xu, K.; Wang, J.; Xu, M.; Manocha, D. Reinforcement learning based visual navigation with information-theoretic regularization. IEEE Robot. Autom. Lett. 2021, 6, 731–738. [Google Scholar] [CrossRef]
- Cen, M.; Jung, C. Fully Convolutional Siamese Fusion Networks for Object Tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3718–3722. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware Siamese Networks for Visual Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A Twofold Siamese Network for Real-Time Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jiang, H.; Chen, A.; Wu, Y.; Zhang, C.; Chi, Z.; Li, M.; Wang, X. Vegetation Monitoring for Mountainous Regions Using a New Integrated Topographic Correction (ITC) of the SCS + C Correction and the Shadow-Eliminated Vegetation Index. Remote Sens. 2022, 14, 3073. [Google Scholar] [CrossRef]
- Chen, J.; Huang, B.; Li, J.; Wang, Y.; Ren, M.; Xu, T. Learning Spatio-Temporal Attention Based Siamese Network for Tracking UAVs in theWild. Remote Sens. 2022, 14, 1797. [Google Scholar] [CrossRef]
- Yu, W.; Yang, K.; Yao, H.; Sun, X.; Xu, P. Exploiting the complementary strengths of multi-layer CNN features for image retrieval. Neurocomputing 2017, 237, 235–241. [Google Scholar] [CrossRef]
- Feng, J.; Xu, P.; Pu, S.; Zhao, K.; Zhang, H. Robust Visual Tracking by Embedding Combination and Weighted-Gradient Optimization. Pattern Recognit. 2020, 104, 107339. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Trans. Geosci. Remote Sens. 2018, 5, 8–36. [Google Scholar] [CrossRef]
- Gao, X.; Wan, Y.; Zheng, S. Automatic Shadow Detection and Compensation of Aerial Remote Sensing Images. Geomat. Inf. Sci. Wuhan Univ. 2012, 37, 1299–1302. [Google Scholar]
- Zhou, T.; Fu, H.; Sun, C.; Wang, S. Shadow Detection and Compensation from Remote Sensing Images under Complex Urban Conditions. Remote Sens. 2021, 13, 699. [Google Scholar] [CrossRef]
- Powell, M. Least frobenius norm updating of quadratic models that satisfy interpolation conditions. Math Program. 2004, 100, 183–215. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wu, Y.; Sun, Q.; Hou, Y.; Zhang, J.; Wei, X. Deep covariance estimation hashing. IEEE Access 2019, 7, 113225. [Google Scholar] [CrossRef]
- Li, P.; Chen, S. Gaussian process approach for metric learning. Pattern Recognit. 2019, 87, 17–28. [Google Scholar] [CrossRef]
- Denman, E.D.; Beavers, A.N. The matrix Sign function and computations in systems. Appl. Math. Comput. 1976, 2, 63–94. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4012–4021. [Google Scholar]
- Saqlain, M.; Abbas, Q.; Lee, J.Y. A Deep Convolutional Neural Network for Wafer Defect Identification on an Imbalanced Dataset in Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2020, 33, 436–444. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (ICCV), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar]
- Shen, Z.; Dai, Y.; Rao, Z. CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13901–13910. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GlobalTrack: A Simple and Strong Baseline for Long-term Tracking. arXiv 2019, arXiv:1912.08531. [Google Scholar] [CrossRef]
- Li, P.; Xie, J.; Wang, Q.; Zuo, W. Is Second-Order Information Helpful for Large-Scale Visual Recognition? In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2089–2097. [Google Scholar]
- Lin, T.-Y.; RoyChowdhury, A.; Maji, S. Bilinear Convolutional Neural Networks for Fine-Grained Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1309–1322. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | FPS | CLE |
|---|---|---|
| This work | 35 | 5.47 |
| SiamRPN++ [42] | 30 | 5.98 |
| SiamRPN [24] | 37 | 6.26 |
| CFNet [43] | 47 | 6.11 |
| SiamFC [18] | 41 | 6.56 |
| Global Tacker [44] | 40 | 5.83 |
| Backbone | Precision | Success Rate | FPS | CLE |
|---|---|---|---|---|
| AlexNet [21] | 0.951 | 0.707 | 38 | 6.26 |
| ResNet18 [22] | 0.954 | 0.710 | 37 | 6.11 |
| ResNet50 [22] | 0.959 | 0.711 | 37 | 6.07 |
| ResNet50 with M-O feature (p = 10%) | 0.968 | 0.722 | 33 | 5.54 |
| ResNet50 with M-O feature (p = 30%) | 0.979 | 0.732 | 35 | 5.47 |
| ResNet50 with M-O feature (p = 50%) | 0.980 | 0.730 | 32 | 5.43 |
| ResNet50 with M-O feature (p = 100%) | 0.978 | 0.730 | 30 | 5.50 |
| Loss Function | AP50 | AP60 | AP70 | AP80 | AP90 |
|---|---|---|---|---|---|
| LIoU | 82.46% | 72.75% | 60.26% | 39.57% | 8.75% |
| Relative improve | 3.96% | 4.70% | 3.87% | 3.09% | 5.12% |
| LCIoU | 83.31% | 74.19% | 60.71% | 39.15% | 8.62% |
| Relative improve | 3.11% | 3.26% | 3.42% | 3.51% | 5.25% |
| LDIoU | 83.57% | 75.14% | 61.43% | 40.60% | 8.81% |
| Relative improve | 2.85% | 2.31% | 2.70% | 2.06% | 5.06% |
| LGIoU | 84.18% | 76.33% | 61.87% | 39.64% | 9.22% |
| Relative improve | 2.24% | 1.12% | 2.26% | 3.02% | 4.65% |
| LMIoU | 85.36% | 76.57% | 62.61% | 40.15% | 9.81% |
| Relative improve. | 1.06 | 0.88% | 1.52 % | 2.51% | 4.06% |
| LMIoU with weight adaptive | 86.42% | 77.45% | 64.13% | 42.66% | 13.87% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, K.; Chu, J.; Chen, J.; Chen, Y.; Cai, J. M-O SiamRPN with Weight Adaptive Joint MIoU for UAV Visual Localization. Remote Sens. 2022, 14, 4467. https://doi.org/10.3390/rs14184467
Wen K, Chu J, Chen J, Chen Y, Cai J. M-O SiamRPN with Weight Adaptive Joint MIoU for UAV Visual Localization. Remote Sensing. 2022; 14(18):4467. https://doi.org/10.3390/rs14184467
Chicago/Turabian StyleWen, Kailin, Jie Chu, Jiayan Chen, Yu Chen, and Jueping Cai. 2022. "M-O SiamRPN with Weight Adaptive Joint MIoU for UAV Visual Localization" Remote Sensing 14, no. 18: 4467. https://doi.org/10.3390/rs14184467