



Dimensionality Reduction and Classification of Hyperspectral Remote Sensing Image Feature Extraction

Abstract
:
1. Introduction
2. Hyperspectral Dimensionality Reduction
2.1. Feature Extraction Dimensionality Reduction
2.2. Linear Dimensionality Reduction
2.3. Nonlinear Dimensionality Reduction
2.4. UMAP
3. Hyperspectral Image Classification Methods
3.1. Hard and Soft Classification for Hyperspectral Images
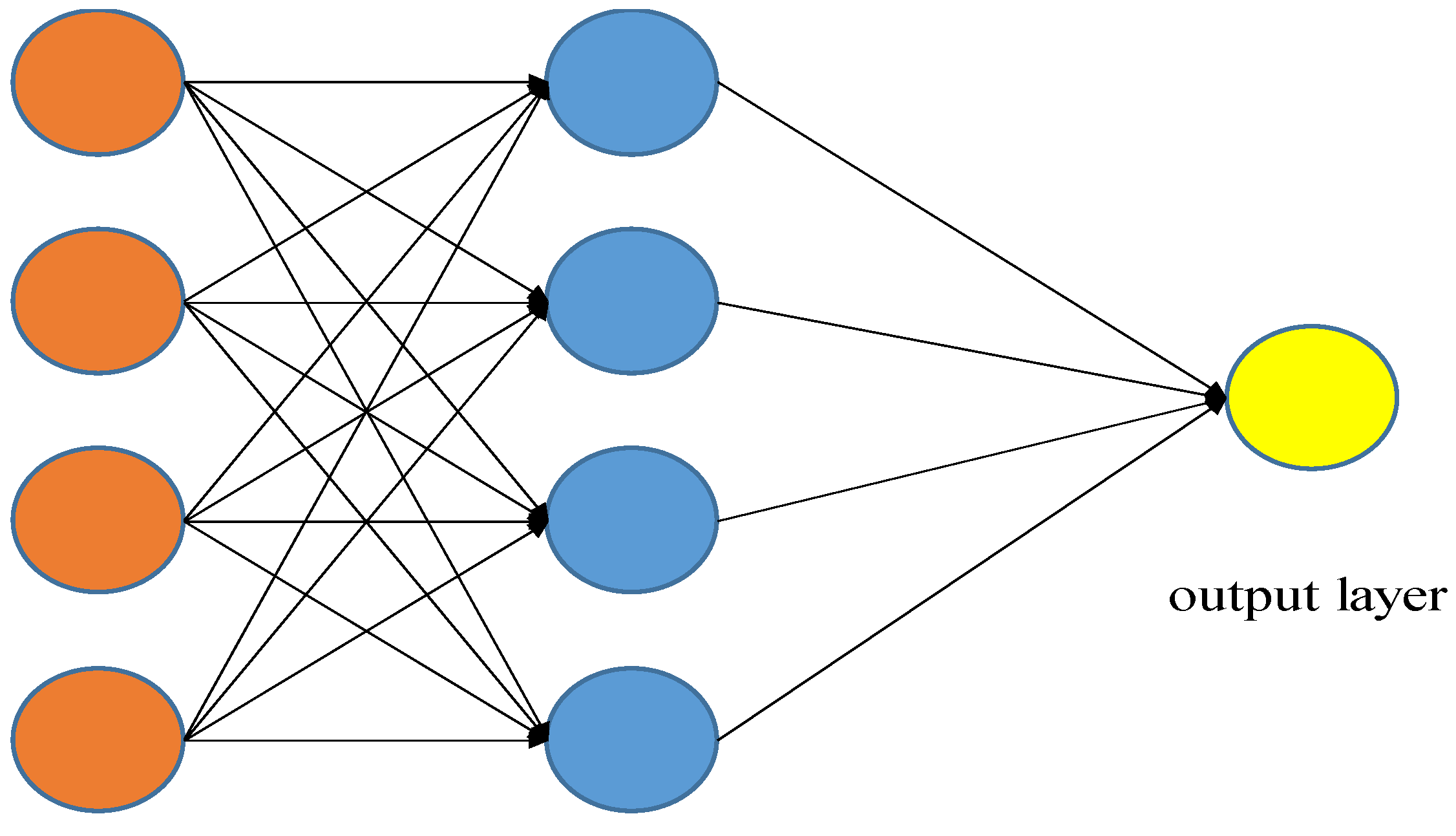
3.2. Neural Networks
3.3. Support Vector Machine
4. Experimental Results and Analysis
4.1. Hyperspectral Image Description
4.2. Results and Analysis
4.2.1. PCA
4.2.2. KNN Proximity Classification
4.2.3. Gaussian Maximum Likelihood Classifier
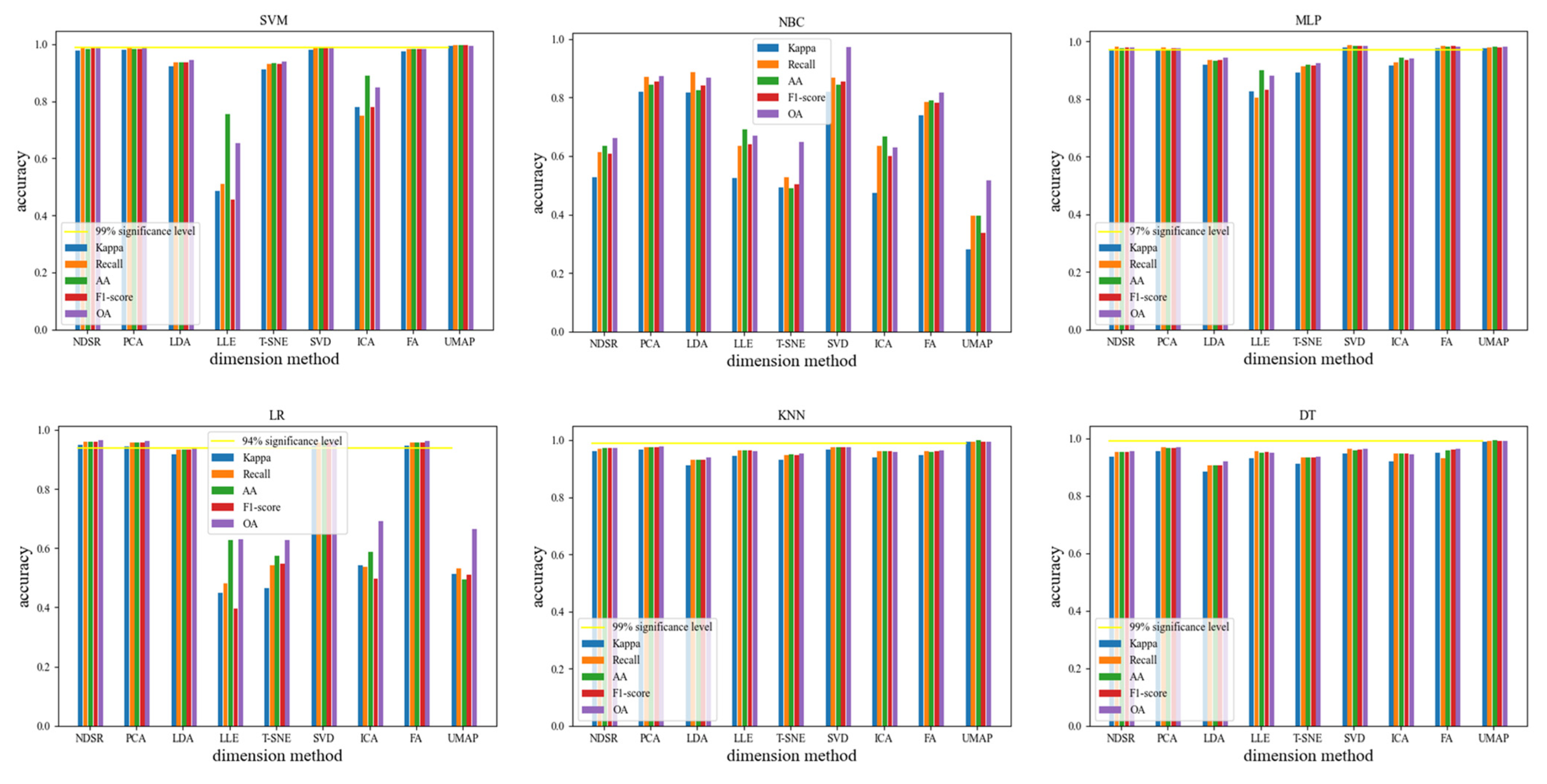
4.2.4. Dimensionality Reduction Method Combined with Classification
4.2.5. Accuracy of Various Dimensionality Reduction Methods for Each Terrain Classification
4.3. Soft Classification of Hyperspectral Images
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, Q.Q.; Bao-Qing, H.U.; Luo, C. Research into Remote Sensing Technology Application in Geological Hazard Analysis. J. Guangxi Teach. Educ. Univ. (Nat. Sci. Ed.) 2016, 33, 130–134. [Google Scholar]
- Jian, W.U. Advances in researches on hyperspectral remote sensing forestry information-extracting technology. Spectrosc. Spectr. Anal. 2011, 31, 2305. [Google Scholar]
- Ge, Y.; Thomasson, J.A.; Sui, R. Remote sensing of soil properties in precision agriculture: A review. Front. Earth Sci. 2011, 5, 229–238. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. On Combining Multiple Features for Hyperspectral Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 879–893. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A. Fast dimensionality reduction and classification of hyperspectral images with extreme learning machines. J. Real-Time Image Process. 2018, 15, 439–462. [Google Scholar] [CrossRef]
- Mou, L.; Lu, X.; Li, X.; Zhu, X.X. Nonlocal graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8246–8257. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Liu, Q.; Ghamisi, P.; Bhattacharyya, S.S. Hyperspectral image classification with attention-aided CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2281–2293. [Google Scholar] [CrossRef]
- Borges, J.S.; Marcal, A. Evaluation of feature extraction and reduction methods for hyperspectral images. New Dev. Chall. Remote Sens. 2007, 29, 265–274. [Google Scholar]
- Yuan, Y.; Zhu, G.; Wang, Q. Hyperspectral Band Selection by Multitask Sparsity Pursuit. IEEE Trans. Geosci. Remote Sens. 2014, 53, 631–644. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Kernel Principal Component Analysis for the Classification of Hyperspectral Remote Sensing Data over Urban Areas. EURASIP J. Adv. Signal Process. 2009, 2009, 783194. [Google Scholar] [CrossRef]
- Kuo, B.C.; Ho, H.H.; Li, C.H.; Hung, C.C. A Kernel-Based Feature Selection Method for SVM with RBF Kernel for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 317–326. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Xing, Z.; Gang, W.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 7, 2094–2107. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Marsheva, T.; Zhou, D. Semi-Supervised Graph-Based Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Damodaran, B.B.; Nidamanuri, R.R. Assessment of the impact of dimensionality reduction methods on information classes and classifiers for hyperspectral image classification by multiple classifier system. Adv. Space Res. 2014, 53, 1720–1734. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Okwuashi, O.; Ndehedehe, C.E. Deep support vector machine for hyperspectral image classification. Pattern Recognit. 2020, 103, 107298. [Google Scholar] [CrossRef]
- Jain, D.K.; Dubey, S.B.; Choubey, R.K.; Sinhal, A.; Arjaria, S.K.; Jain, A.; Wang, H. An approach for hyperspectral image classification by optimizing SVM using self organizing map. J. Comput. Sci. 2018, 25, 252–259. [Google Scholar] [CrossRef]
- Tu, B.; Wang, J.; Kang, X.; Zhang, G.; Ou, X.; Guo, L. KNN-based representation of superpixels for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4032–4047. [Google Scholar] [CrossRef]
- Bo, C.; Lu, H.; Wang, D. Spectral-spatial K-Nearest Neighbor approach for hyperspectral image classification. Multimed. Tools Appl. 2018, 77, 10419–10436. [Google Scholar] [CrossRef]
- Xu, S.; Liu, S.; Wang, H.; Chen, W.; Zhang, F.; Xiao, Z. A hyperspectral image classification approach based on feature fusion and multi-layered gradient boosting decision trees. Entropy 2020, 23, 20. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Du, B.; Zhang, L. Dimensionality reduction with enhanced hybrid-graph discriminant learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5336–5353. [Google Scholar] [CrossRef]
- Li, W.; Feng, F.; Li, H.; Du, Q. Discriminant analysis-based dimension reduction for hyperspectral image classification: A survey of the most recent advances and an experimental comparison of different techniques. IEEE Geosci. Remote Sens. Mag. 2018, 6, 15–34. [Google Scholar] [CrossRef]
- Huang, H.; Shi, G.; He, H.; Duan, Y.; Luo, F. Dimensionality reduction of hyperspectral imagery based on spatial–spectral manifold learning. IEEE Trans. Cybern. 2019, 50, 2604–2616. [Google Scholar] [CrossRef]
- Ramamurthy, M.; Robinson, Y.H.; Vimal, S.; Suresh, A. Auto encoder based dimensionality reduction and classification using convolutional neural networks for hyperspectral images. Microprocess. Microsyst. 2020, 79, 103280. [Google Scholar] [CrossRef]
- Paul, A.; Chaki, N. Dimensionality reduction of hyperspectral images using pooling. Pattern Recognit. Image Anal. 2019, 29, 72–78. [Google Scholar] [CrossRef]
- Shlens, J. A tutorial on principal component analysis: Derivation, discussion and singular value decomposition. arXiv 2003, arXiv:1404.1100. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mooi, E.; Sarstedt, M. Factor Analysis. In A Concise Guide to Market Research: The Process, Data, and Methods Using IBM SPSS Statistics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 201–236. [Google Scholar]
- Golub, G.H. Singular value decomposition and least squares solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Prasad, P.S. Independent Component Analysis; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Roweis, S.; Saul, L. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Hinton, P.G. Visualizing Data using t-SNE Laurens van der Maaten MICC-IKAT. J. Mach. Learn. Res. 2017, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A superpixelwise PCA approach for unsupervised feature extraction of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef] [Green Version]
- Zabalza, J.; Ren, J.; Yang, M.; Zhang, Y.; Wang, J.; Marshall, S.; Han, J. Novel folded-PCA for improved feature extraction and data reduction with hyperspectral imaging and SAR in remote sensing. ISPRS J. Photogramm. Remote Sens. 2014, 93, 112–122. [Google Scholar] [CrossRef]
- Uddin, M.; Mamun, M.; Hossain, M. Feature extraction for hyperspectral image classification. In Proceedings of the 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Dhaka, Bangladesh, 21–23 December 2017; IEEE: New York, NY, USA, 2017; pp. 379–382. [Google Scholar]
- Ahmad, M.; Shabbir, S.; Raza, R.A.; Mazzara, M.; Distefano, S.; Khan, A.M. Hyperspectral image classification: Artifacts of dimension reduction on hybrid CNN. arXiv 2021, arXiv:2101.10532. [Google Scholar]
- Zhao, X.; Liang, Y.; Guo, A.J.; Zhu, F. Classification of small-scale hyperspectral images with multi-source deep transfer learning. Remote Sens. Lett. 2020, 11, 303–312. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Ma, L.; Du, Q. Discriminative transfer joint matching for domain adaptation in hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 972–976. [Google Scholar] [CrossRef]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral image classification on insufficient-sample and feature learning using deep neural networks: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]
- Sellami, A.; Tabbone, S. Deep neural networks-based relevant latent representation learning for hyperspectral image classification. Pattern Recognit. 2022, 121, 108224. [Google Scholar] [CrossRef]
- Zhou, B.; Duan, X.; Ye, D.; Wei, W.; Damaševičius, R. Multi-Level Features Extraction for Discontinuous Target Tracking in Remote Sensing Image Monitoring. Sensors 2019, 19, 4855. [Google Scholar] [CrossRef]
- Khan, S.S.; Ran, Q.; Khan, M.; Zhang, M. Hyperspectral image classification using nearest regularized subspace with Manhattan distance. J. Appl. Remote Sens. 2019, 14, 1. [Google Scholar] [CrossRef]
- Yao, D.; Zhi-Li, Z.; Xiao-Feng, Z.; Wei, C.; Fang, H.; Yao-Ming, C.; Cai, W.-W. Deep hybrid: Multi-graph neural network collaboration for hyperspectral image classification. Def. Technol. 2022. [Google Scholar] [CrossRef]
- Khan, S.S.; Khan, M.; Haider, S.; Damaševičius, R. Hyperspectral image classification using NRS with different distance measurement techniques. Multimedia Tools Appl. 2022, 81, 24869–24885. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Ahmad, M.; Plaza, A.; Chanussot, J. Hyperspectral and LiDAR Data Classification Using Joint CNNs and Morphological Feature Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar]
- Hang, R.; Li, Z.; Ghamisi, P.; Hong, D.; Xia, G.; Liu, Q. Classification of hyperspectral and LiDAR data using coupled CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4939–4950. [Google Scholar] [CrossRef] [Green Version]
- L-Alimi, D.A.; Al-qaness, M.A.; Cai, Z.; Dahou, A.; Shao, Y.; Issaka, S. Meta-Learner Hybrid Models to Classify Hyperspectral Images. Remote Sens. 2022, 14, 1038. [Google Scholar] [CrossRef]
- Shang, Y.; Zheng, X.; Li, J.; Liu, D.; Wang, P. A Comparative Analysis of Swarm Intelligence and Evolutionary Algorithms for Feature Selection in SVM-Based Hyperspectral Image Classification. Remote Sens. 2022, 14, 3019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Asphalt | Grass | Tree | Roof | |
|---|---|---|---|---|
| Number | 29,954 | 32,328 | 24,805 | 7162 |
| Train set | 23,963 | 25,910 | 19,766 | 5760 |
| Test set | 5991 | 6418 | 5039 | 1402 |
| KNN | k = 3 | k = 4 | k = 5 |
|---|---|---|---|
| AA | 0.9587 | 0.9754 | 0.9751 |
| OA | 0.9564 | 0.9770 | 0.9762 |
| KAPPA | 0.9382 | 0.9675 | 0.9664 |
| RECALL | 0.9600 | 0.9755 | 0.9752 |
| F1-SCORE | 0.9593 | 0.9754 | 0.9751 |
| Asphalt | Grass | Tree | Roof | |
|---|---|---|---|---|
| PA | 0.8502 | 0.9029 | 0.8968 | 0.9139 |
| OA | 0.9234 | 0.8814 | 0.9137 | 0.7108 |
| F1-Score | 0.8853 | 0.8920 | 0.9051 | 0.7996 |
| None Dimensionality Reduction | PCA | LDA | LLE | T-SNE | SVD | ICA | FA | UMAP | ||
|---|---|---|---|---|---|---|---|---|---|---|
| k-Nearest Neighbor | Kappa | 0.9612 | 0.9674 | 0.9126 | 0.9460 | 0.9322 | 0.9659 | 0.9401 | 0.9479 | 0.9938 |
| Recall | 0.9690 | 0.9755 | 0.9314 | 0.9642 | 0.9468 | 0.9745 | 0.9617 | 0.9608 | 0.9957 | |
| AA | 0.9736 | 0.9754 | 0.9297 | 0.9631 | 0.9499 | 0.9750 | 0.9604 | 0.9593 | 0.9987 | |
| F1-score | 0.9712 | 0.9754 | 0.9306 | 0.9636 | 0.9483 | 0.9747 | 0.9610 | 0.9600 | 0.9957 | |
| OA | 0.9729 | 0.9770 | 0.9382 | 0.9618 | 0.9521 | 0.9759 | 0.9577 | 0.9631 | 0.9956 | |
| P | 0.1445 | 2 × 10−5 | 0.044 | 0.0005 | 0.2471 | 0.0205 | 0.0114 | 4 × 10−6 | ||
| Naive Bayesian Classifier | Kappa | 0.5269 | 0.8200 | 0.8181 | 0.5237 | 0.4931 | 0.8190 | 0.4751 | 0.7392 | 0.2816 |
| Recall | 0.6128 | 0.8702 | 0.8859 | 0.6346 | 0.5271 | 0.8692 | 0.6346 | 0.7843 | 0.3961 | |
| AA | 0.6358 | 0.8441 | 0.8253 | 0.6923 | 0.4901 | 0.8436 | 0.6661 | 0.7902 | 0.3972 | |
| F1-score | 0.6070 | 0.8551 | 0.8410 | 0.6405 | 0.5035 | 0.8544 | 0.5998 | 0.7833 | 0.3369 | |
| OA | 0.6617 | 0.8721 | 0.8692 | 0.6708 | 0.6494 | 0.9714 | 0.6285 | 0.8165 | 0.5167 | |
| P | 9 × 10−6 | 1 × 10−6 | 0.5411 | 0.0767 | 6 × 10−5 | 0.8466 | 0.0001 | 0.0011 | ||
| Support Vector Machine | Kappa | 0.9790 | 0.9796 | 0.9228 | 0.4850 | 0.9127 | 0.9819 | 0.7803 | 0.9763 | 0.9937 |
| Recall | 0.9852 | 0.9855 | 0.9371 | 0.5092 | 0.9312 | 0.9862 | 0.7492 | 0.9839 | 0.9958 | |
| AA | 0.9845 | 0.9832 | 0.9375 | 0.7552 | 0.9328 | 0.9855 | 0.8908 | 0.9822 | 0.9957 | |
| F1-score | 0.9848 | 0.9843 | 0.9373 | 0.4542 | 0.9319 | 0.9859 | 0.7795 | 0.9831 | 0.9957 | |
| OA | 0.9851 | 0.9856 | 0.9455 | 0.6544 | 0.9384 | 0.9872 | 0.8485 | 0.9833 | 0.9955 | |
| P | 0.8780 | 1 × 10−6 | 0.0001 | 2 × 10−6 | 0.2953 | 0.0002 | 0.3226 | 1 × 10−5 | ||
| Decision Tree | Kappa | 0.9374 | 0.9562 | 0.8855 | 0.9300 | 0.9116 | 0.9483 | 0.9208 | 0.9488 | 0.9890 |
| Recall | 0.9540 | 0.9682 | 0.9075 | 0.9546 | 0.9346 | 0.9627 | 0.9477 | 0.9316 | 0.9923 | |
| AA | 0.9520 | 0.9656 | 0.9049 | 0.9504 | 0.9331 | 0.9596 | 0.9464 | 0.9589 | 0.9927 | |
| F1-score | 0.9529 | 0.9669 | 0.9062 | 0.9525 | 0.9338 | 0.9612 | 0.9469 | 0.9603 | 0.9925 | |
| OA | 0.9558 | 0.9691 | 0.9191 | 0.9506 | 0.9376 | 0.9635 | 0.9441 | 0.9639 | 0.9922 | |
| P | 0.0065 | 9 × 10−5 | 0.6285 | 0.0078 | 0.0806 | 0.1688 | 0.7430 | 2 × 10−6 | ||
| Logistic Regression | Kappa | 0.9491 | 0.9451 | 0.9167 | 0.4480 | 0.4663 | 0.9459 | 0.5427 | 0.9468 | 0.5121 |
| Recall | 0.9597 | 0.9569 | 0.9326 | 0.4804 | 0.5416 | 0.9569 | 0.5372 | 0.9571 | 0.5308 | |
| AA | 0.9588 | 0.9576 | 0.9325 | 0.6262 | 0.5754 | 0.9574 | 0.5875 | 0.9582 | 0.4935 | |
| F1-score | 0.9592 | 0.9572 | 0.9326 | 0.3946 | 0.5483 | 0.9572 | 0.4979 | 0.9576 | 0.5106 | |
| OA | 0.9641 | 0.9613 | 0.9412 | 0.6308 | 0.6283 | 0.9618 | 0.6923 | 0.9624 | 0.6650 | |
| P | 0.5074 | 0.0004 | 2 × 10−5 | 3 × 10−7 | 0.5353 | 3 × 10−6 | 0.6350 | 1 × 10−8 | ||
| Multi-layer Perceptron | Kappa | 0.9701 | 0.9666 | 0.9197 | 0.8274 | 0.8924 | 0.9784 | 0.9154 | 0.9749 | 0.9748 |
| Recall | 0.9814 | 0.9772 | 0.9362 | 0.8042 | 0.9142 | 0.9854 | 0.9281 | 0.9832 | 0.9786 | |
| AA | 0.9751 | 0.9743 | 0.9330 | 0.9002 | 0.9194 | 0.9835 | 0.9441 | 0.9819 | 0.9809 | |
| F1-score | 0.9782 | 0.9757 | 0.9346 | 0.8322 | 0.9168 | 0.9844 | 0.9356 | 0.9826 | 0.9797 | |
| OA | 0.9789 | 0.9764 | 0.9432 | 0.8798 | 0.9241 | 0.9847 | 0.9404 | 0.9823 | 0.9822 | |
| P | 0.3516 | 8 × 10−6 | 9 × 10−5 | 5 × 10−6 | 0.0222 | 4 × 10−5 | 0.1249 | 0.3116 | ||
| RMSE | R2 | p-Value | |
|---|---|---|---|
| Linear Logistic Regression | 0.103 | 0.709 | 0.869 |
| Neural Networks | 0.042 | 0.979 | 0.071 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Cui, J.; Zhang, X.; Han, Y.; Cao, L. Dimensionality Reduction and Classification of Hyperspectral Remote Sensing Image Feature Extraction. Remote Sens. 2022, 14, 4579. https://doi.org/10.3390/rs14184579
Li H, Cui J, Zhang X, Han Y, Cao L. Dimensionality Reduction and Classification of Hyperspectral Remote Sensing Image Feature Extraction. Remote Sensing. 2022; 14(18):4579. https://doi.org/10.3390/rs14184579
Chicago/Turabian StyleLi, Hongda, Jian Cui, Xinle Zhang, Yongqi Han, and Liying Cao. 2022. "Dimensionality Reduction and Classification of Hyperspectral Remote Sensing Image Feature Extraction" Remote Sensing 14, no. 18: 4579. https://doi.org/10.3390/rs14184579
APA StyleLi, H., Cui, J., Zhang, X., Han, Y., & Cao, L. (2022). Dimensionality Reduction and Classification of Hyperspectral Remote Sensing Image Feature Extraction. Remote Sensing, 14(18), 4579. https://doi.org/10.3390/rs14184579