Although the remote sensing image captioning and remote sensing image scene classification tasks have different domains and final outputs, they both need to extract and apply the features of remote sensing images: the scene classification task uses visual features to classify and obtain category labels, and the image captioning task identifies and converts visual features into text descriptions. The scene classification task and the image captioning task intersect in the extraction process of visual features. Therefore, the remote sensing image captioning model in this paper adopts an encoder-decoder structure: the encoder, which is trained in the scene classification task, is used to extract features from the input remote sensing image, and the decoder generates captions based on the features. The encoder usually uses a series of convolutional neural network (CNN)-based networks pre-trained in the scene classification tasks because of their simple structures and powerful performance. Here, the encoder is denoted by
. Given a remote sensing image
as input, the visual features extracted by the encoder are:
where we apply average pooling to the features extracted by the encoder. For the CNN here, we choose ResNet, a classic and still powerful network. The visual features
of the remote sensing image output from the encoder are fed to a decoder for decoding. The decoder can use recurrent networks (RNN), long-short term memory networks (LSTM), etc. LSTM is a special RNN, which is often chosen as the decoder of remote sensing image captioning models. As a sequential model, LSTM can learn long dependencies and overcome gradient vanishing to achieve better functionality. The information transfer in LSTM is controlled by a forget gate
, an input gate
and an output gate
. The forget gate
controls whether to clear the current value, the input gate
determines whether to obtain new input information, and the output gate
determines whether to output a new value. The structure of the LSTM at time
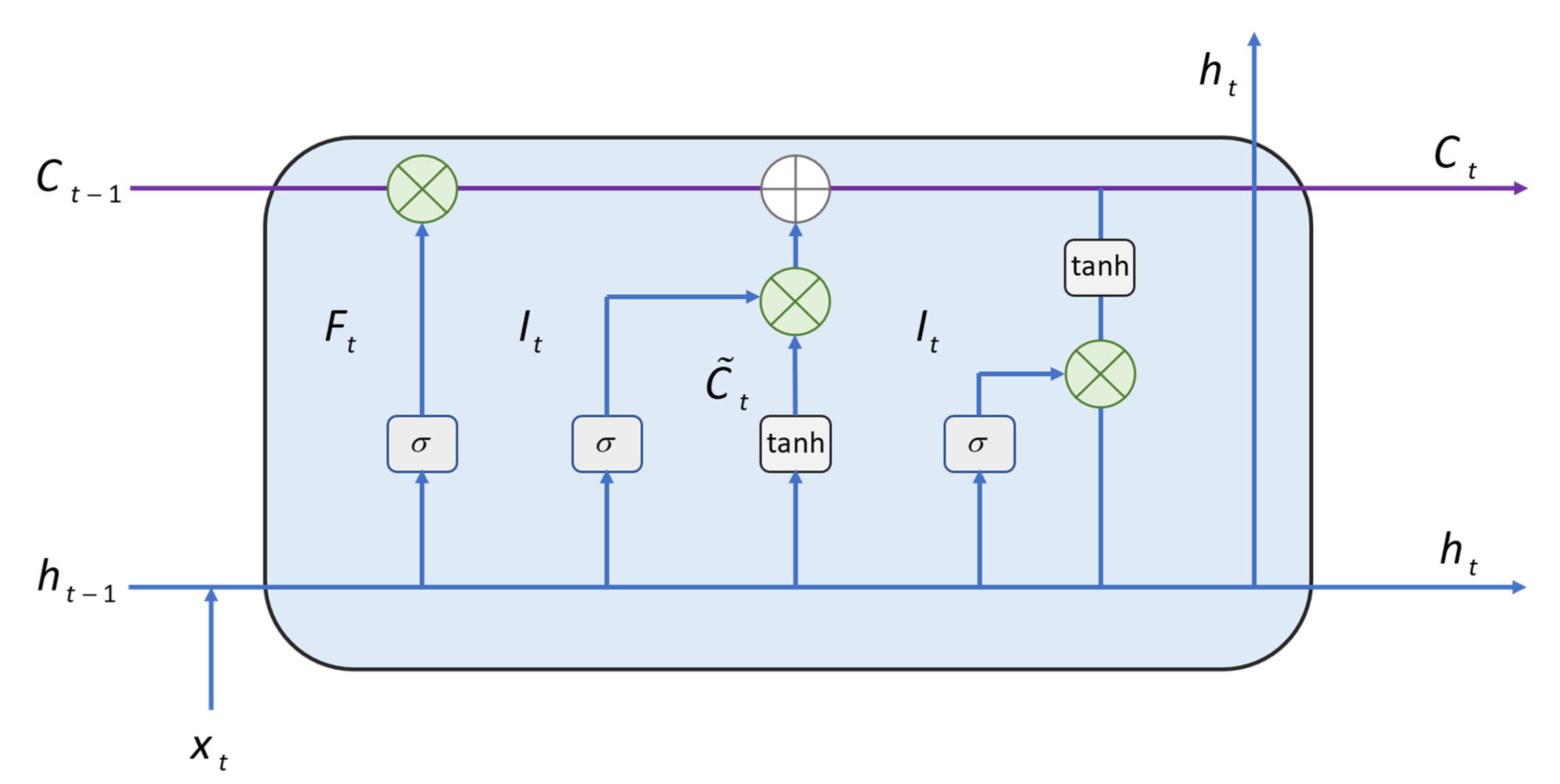
and the parameter transfer method are shown in
Figure 1. At time
, the parameters in LSTM are updated as follows:
Finally, to generate word probabilities
, we use a “softmax” layer to normalize the generated score vectors to probabilities.
represents the nonlinear activation function sigmoid and
represents the hyperbolic tangent function.
,
,
,
,
,
,
and
are the trainable weight matrices in LSTM.
,
,
and
are trainable biases.
and
are the trainable weight matrices of the input gate and
is the trainable bias of the input gate;
and
are the trainable weight matrices of the forget gate and
is the trainable bias of the forget gate;
and
are the trainable weight matrices of the output gate and
is the trainable bias of the output gate;
and
are the trainable weight matrices of the memory cell and
is the trainable bias of the memory cell. The memory cell
is used to store new state information.
represents the hidden state of the LSTM at time
and also the output of the LSTM at time
.
represents the input of the LSTM at time
.
is obtained by combining
and the encoder-extracted feature vectors
at time
in series:
.
is calculated based on
.
is calculated based on
, and so on.
and
are also calculated in this way. When
is 0,
and
will be initialized to 0 before model training.
,
and the visual features
output from the encoder are input to LSTM for training. The word vector
generated at time
is denoted as:
The LSTM decoder receives the features extracted from the remote sensing image by the encoder and generates the first word. The word embedding vector of the first word is passed to the LSTM as the new input for generating the second word. The decoder generates one word at each step, resulting in a textual description of the remote sensing image.
In the above encoder-decoder framework, the choice of encoder and decoder structures is not limited to the combination of CNN (ResNet) and LSTM, as described above. Various attention mechanisms are added to the LSTM to constitute new decoders. Transformers [
58] and models built based on a transformer (such as bert) have achieved great results in the field of natural language processing in recent years, and the decoder can also choose a transformer instead of LSTM. The encoder can also choose from different feature extraction networks, including CNNs with various attention models attached or even a transformer-based design, vision transformer. Using these powerful new designs to construct the baseline for image captioning has great potential to achieve strong performance. However, discussing the construction of encoders and decoders is not the focus of this study. Here we choose ResNet as the encoder and LSTM as the decoder for the baseline model of the few-shot remote sensing image captioning model. After setting the overall framework of few-shot remote sensing image captioning, we improve the performance of the few-shot remote sensing image captioning model from four perspectives: feature, temporal, manner, and optimization according to the characteristics of few-shot remote sensing image scenarios.
3.1. Feature: Self-Supervised Learning
We first improve the performance of the image captioning encoder in few-shot remote sensing image scenarios from the perspective of feature extraction. The remote sensing image captioning model based on the encoder-decoder structure needs the visual features of remote sensing images for text generation. This visual feature is the same as the visual feature used in the process of the remote sensing image scene classification process. Therefore, the remote sensing image feature extraction problem in few-shot scenarios can be transformed into a few-shot remote sensing image scene classification problem to be solved. In the few-shot scenario we set, only a small number of unlabeled remote sensing images can be used to train the remote sensing image scene classification model. We note that self-supervised learning can learn generic feature information contained within the data without using label information, providing a stable and generalizable feature representation for downstream tasks. As can be seen, the goal of both self-supervised learning and few-shot learning is to reduce the reliance of model training on labeled data. Therefore, our strategy is to use self-supervised learning to train a scene classification model as an encoder in a small amount of unlabeled remote sensing image samples. We choose the classical ResNet-101 as the structure of the encoder. ResNet-101 still performs brightly in real scenarios, combining accuracy and simplicity. After determining the structure of the encoder, we need to consider how to train the encoder using unlabeled remote sensing images. Here we use self-supervised learning to further improve the encoder’s generalization ability. Self-supervised learning performs consistency regularization on the encoder, focusing on the output of the encoder rather than the specific data labels for training. Here we borrow the self-supervised training paradigm from BYOL. Without changing the original model structure, the performance of the model is improved from the data without class labels.
Given an input remote sensing image, here denoted as
, we randomly adopt two different strategies
and
for data augmentation to obtain
and
. The two different data augmentation strategies adopted are derived from the strategies expounded in
Section 4.3. Regarding implementation details, the self-supervised learning model contains two-path modules: an online model and a target model. First of all, they both have encoders with the structure of ResNet-101, but the difference is the parameters of the encoders. Here, the encoder in the online model is denoted as
, and
is the parameter of the online model. The encoder in the target model is denoted as
, and
is the parameter of the target model. We input
and
to
in the online model and
in the target model, respectively. The role of
in the online model is to extract the remote sensing image
from
. Then, we input
into the projection layer
to project into a higher dimensional space to obtain the vector
. In the target model, a vector
is obtained by replacing
with
with the same structure. The structure of the projection layer
and
is a multilayer perceptron (MLP). The divergence between the online model and the target model occurs in the next step: the online model uses
to predict
output from the target model through an additional prediction layer
. The prediction layer
is structured as a multilayer perceptron like the projection layer
.
stops the gradient descent and updates the parameters with momentum through
:
where
is the decay rate, and the value is taken in [0,1]. This exponential moving average update strategy takes the target model as a mean teacher. The mean teacher constantly generates pseudo labels to serve as learning guidance and prediction objectives for the online model. The error
generated by the prediction is calculated as:
The difference between the predicted value and the target value is continuously reduced by continuously reducing to a minimum value. Stop gradient means that we do not allow the generated gradients to be back-propagated at each stochastic optimization step. We minimize with respect to only, but not . The gradient generated by the target path will not be passed to, that is, stop the gradient descent of this path. Only the gradients passed backwards by the online path are updated. The stop-gradient design prevents the output of the target path and the online path from collapsing to the same, ensuring that self-supervised learning proceeds smoothly. At the end of the training, only the encoder in the online model is saved.
Although BYOL can excellently improve the performance of the model in unlabeled data scenarios, BYOL does not take into account the local features in remote sensing images.
can be regarded as a global consistency loss. Local features are very important for the interpretation and application of remote sensing images, which are related to the capture and extraction of key targets. Therefore, we add additional learning of the local consistency of remote sensing images to BYOL to complement the model’s ability to extract local features of remote sensing images.
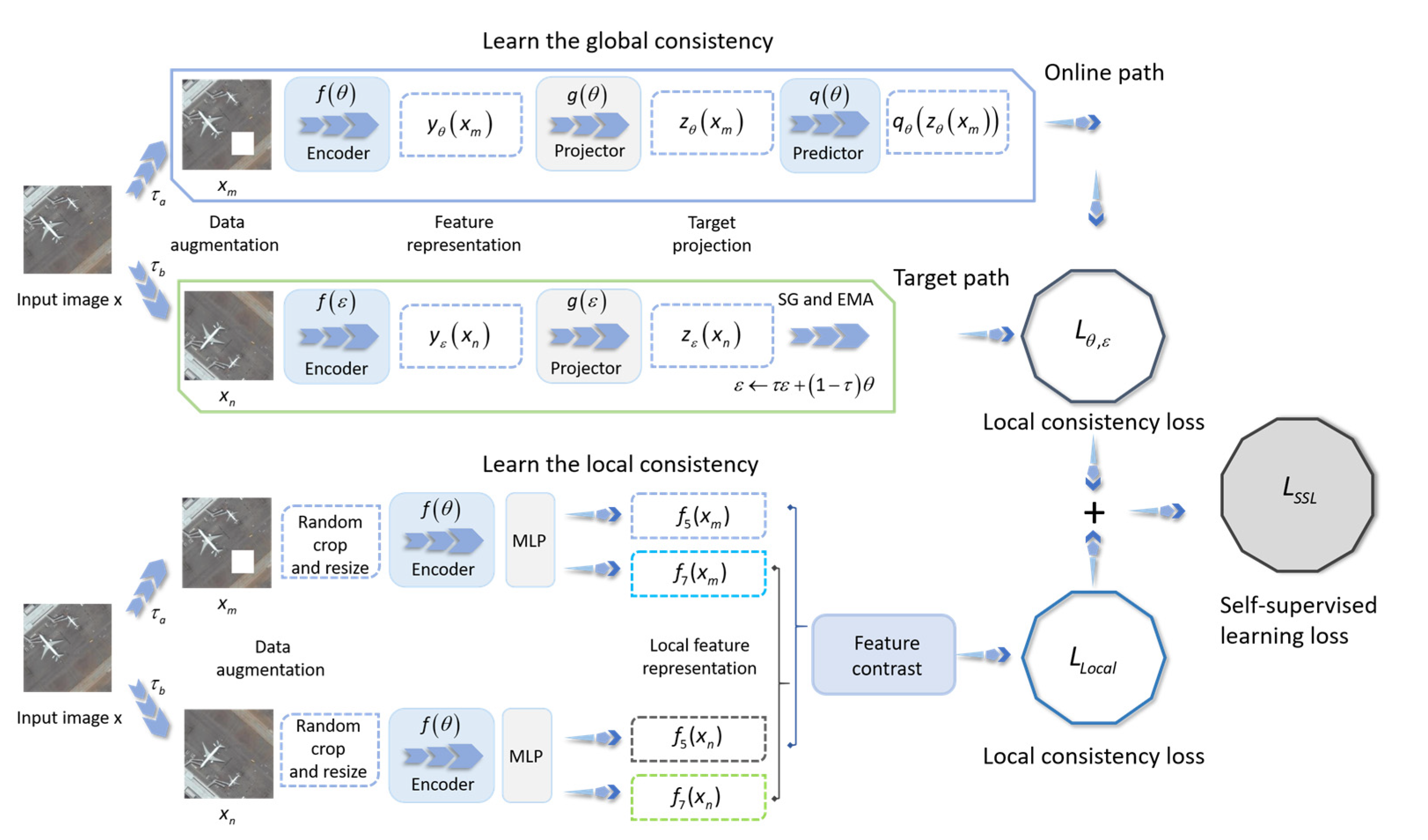
Figure 2 shows the schematic diagram of our self-supervised learning process.
In the process of the additional self-supervised learning, we directly select the local features extracted from remote sensing images for contrast learning. We also enhanced the input remote sensing images to get a large number of positive and negative pairs and input them into the classification model. The positive samples come from different data augmentation results of the same remote sensing image, and the negative samples are data augmentation results of different remote sensing images. A remote sensing image
is enhanced with different strategies to obtain
and
. We randomly crop
to obtain a 5 × 5 slice and adjust back to the original size of
to obtain
. We randomly crop
to obtain a 7 × 7 slice and adjust it back to the original size of
to obtain
. Subsequently,
and
are fed into the scene classification model (encoder)
for self-supervised learning based on feature comparison. Note that the encoder structure is the same for both
and
, and the parameters of the encoder are both
. The encoder
is followed by an MLP for feature projection. Symmetrically, randomly crop
to obtain a 7 × 7 slice and adjust back to the original size of
to obtain
. Randomly crop
to get a 5 × 5 slice and adjust back to the original size of
to obtain
. We adopt the same treatment as above for
and
.The loss function
generated in this process is calculated as follows:
where
represents the negative samples of remote sensing image
, and
is the square of Euclidean distance.
represents the feature extracted by inputting
or
into the encoder
and the MLP, and
represents the feature extracted by inputting
or
into the encoder
and the MLP.
and
represent positive pairs.
includes positive pairs and all negative pairs, and
is the InfoNCE loss. By continuously reducing
to promote the realization of local consistency, only the decoder
is saved after training. It is important to note that there is more than just the choice of
or
for contrast learning. Different choices for the size of cutting and the combination of contrast can constitute different contrast learning strategies. The reason we choose them here is that using
and
with smaller sizes for contrast learning can reduce the occupation of computing resources. Using
and
with small sizes is beneficial to learn the local consistency of remote sensing images. At the same time, the difference between
and
, which are close in size, will not be so large that it is too difficult for the encoder to learn. Finally, more
and
with smaller sizes can be generated from one image, which is conducive to alleviating the few-shot problem.
Therefore, considering the global consistency of the model to the images and the local consistency of the features, we implement self-supervised learning with decreasing and by gradient descent until a minimum value is reached. At the end of the training, only the encoder is retained. Self-supervised learning helps the encoder learn a general feature expression from a small number of unlabeled remote sensing images for remote sensing image scene classification. The semantic features are extracted from a limited number of remote sensing images using the encoder with caption labels but without class labels. Then the extracted semantic features are input into the decoder to generate captions. The decoder only needs to focus on generating captions for limited caption-labeled samples.
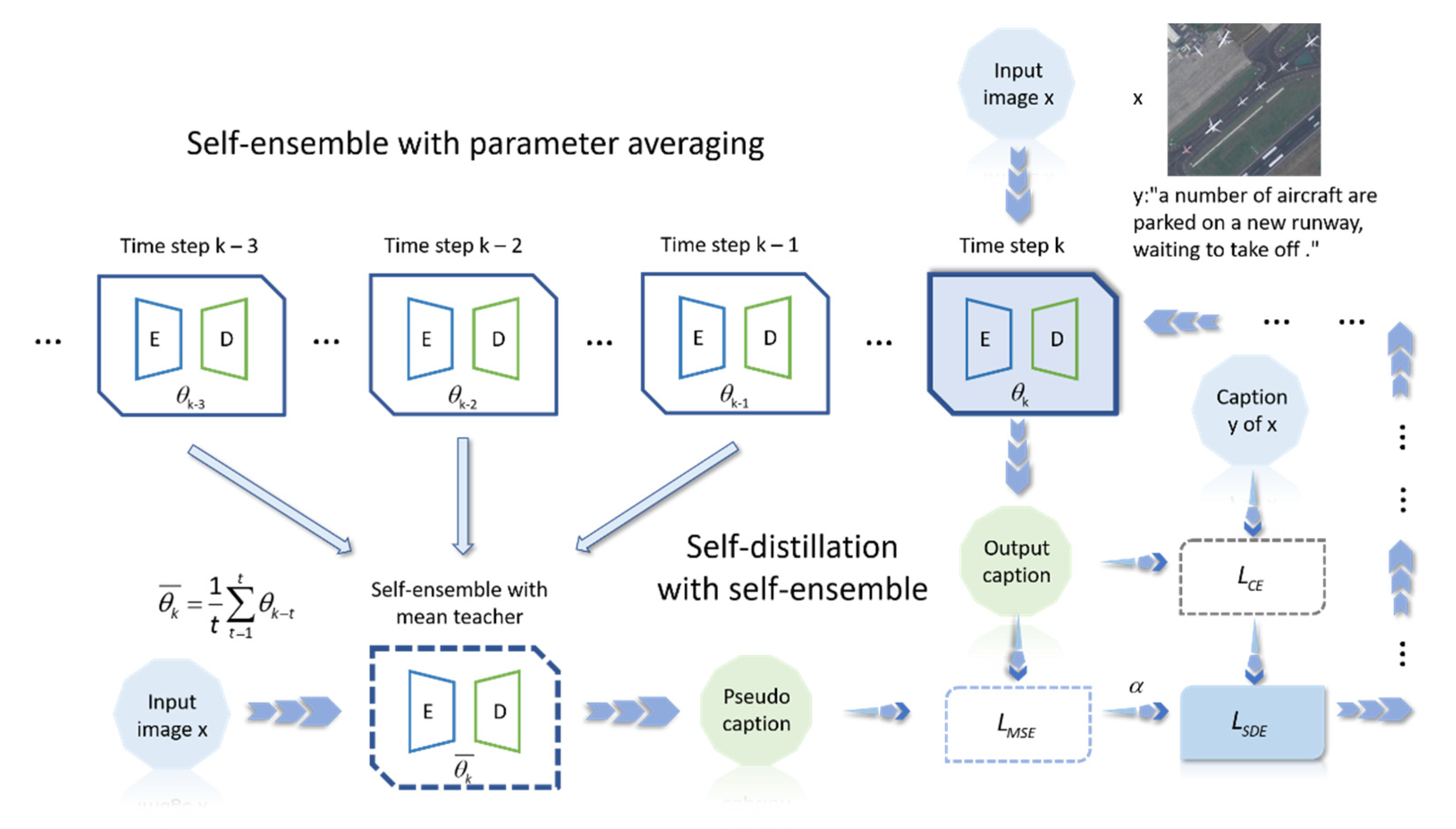
3.3. Manner: Self-Distillation
After using self-ensemble to improve the performance of the model from a temporal perspective, we further optimize the training manner of the model. Knowledge distillation can transfer knowledge from the teacher model to the student model. When the teacher model and the learning model have the same structure, knowledge distillation becomes self-distillation. Self-distillation eliminates the need to train additional models, additional prior knowledge and additional training data. Knowledge is transferred from the previous generation model to the next generation model in the form of pseudo labels. Model performance can be improved through multiple iterations. These characteristics of self-distillation can well alleviate the pain points of few-shot scenarios. We combine self-distillation with the above self-ensemble: unlike the common self-distillation in which the teacher model and the student model directly adopt the same structure, we use the model obtained from the self-ensemble as the teacher model to train the next generation of student models. A series of pseudo semantic annotation labels generated by the self-ensemble model is fed to the self-distillation model for training, and the self-distillation will continue to generate new pseudo semantic caption labels to store in the performance boost of the next-generation model. The loss function
of self-distillation combined with self-ensemble in the process of training the model
is:
where
represents the input image,
represents the semantic annotation label of
,
represents the cross-entropy loss,
represents the mean square error,
represents the parameters of the t generation model, and
is used to adjust the proportion of cross-entropy loss and mean square error.
represents the averaged parameters in the first
time steps, including the
k-generation model. The hyperparameter
determines the scale of self-ensemble with parameter averaging.
The schematic diagram of the self-distillation training strategy with self-ensemble is shown in
Figure 3. In the training process,
will change with the advance of the training step, which can prevent the model from overfitting. The performance obtained from self-distillation training will also be self-ensembled into the training of the next-generation model. Self-ensemble and self-distillation can promote each other in this process so that the training of the model tends to be stable, and finally, we obtain a model with the best performance in the training process.
3.4. Optimization: Self-Critical
In this section, the performance of the image captioning model is improved through parameter optimization of the image captioning model. There are several problems in the training and testing process of image captioning from few-shot remote sensing images. First, in the few-shot scenarios, the data distribution of the model does not match the process of training and testing. Because the total number of remote sensing image samples with caption labels is small, the number of samples with caption labels that can be obtained in the training stage is correspondingly small. The train set is expanded in various ways, but the train set will not be changed. The data distribution of the train set and the test set is different. In the process of training the image captioning model, the model will predict the next word based on the generated words and use gradient descent to continuously optimize the model. In this process, the difference in data distribution between the train set and the test set will be further accumulated. During the training process, the input of the model is all from the real dataset, and the labels of the samples are ground truth. However, the input of the model in the test process comes from the output of the previous time. The errors generated in the test process will continue to accumulate. This phenomenon is called exposure bias [
54]. Second, the image captioning model uses a loss function to tune the model parameter
during the training process but uses evaluation metrics such as BLEU, CIDEr, ROUGE, and SPICE to evaluate the performance during the testing process. These metrics are non-differentiable with respect to the parameter
, so it is not possible to use gradient descent to feed the test results directly to the model for optimization.
Several studies have shown that the policy-gradient method in reinforcement learning can be used to solve the problems of exposure bias and the non-differentiability of training metrics. Reinforcement learning defines a text generation model as an agent that interacts with the “environment”, defines descriptive captions and remote sensing image features as the “environment”, and considers the evaluation metric CIDEr score of descriptive captions as the reward
. The policy gradient method expresses the learning policy as
using the parameter
. The training expectation function is:
where
.
represents sequentially generated word sequences (sentences),
denotes the generated words sampled from the model using strategy
at time t, and
denotes negative expectation. The reward is adjusted by introducing a baseline b of the greedy decoding output to calculate the reward gradient estimation with feedback from the strategy parameters and the environment to achieve an optimal update of the parameter
and finally obtain the maximum cumulative reward. The gradient estimate on
is:
The baseline can be any function independent of . The introduction of can reduce the variance of the gradient estimate. This is an end-to-end method to search for the optimal solution in the policy space, which has a wide range of applications. This method also has obvious shortcomings: the gradient variance calculated under the reinforcement learning framework is very large. The training is very volatile, and the model is easy to converge to a local minimum, which is similar to the phenomenon of overfitting, resulting in poor quality of the generated captions. These disadvantages can be magnified in few-shot scenarios.
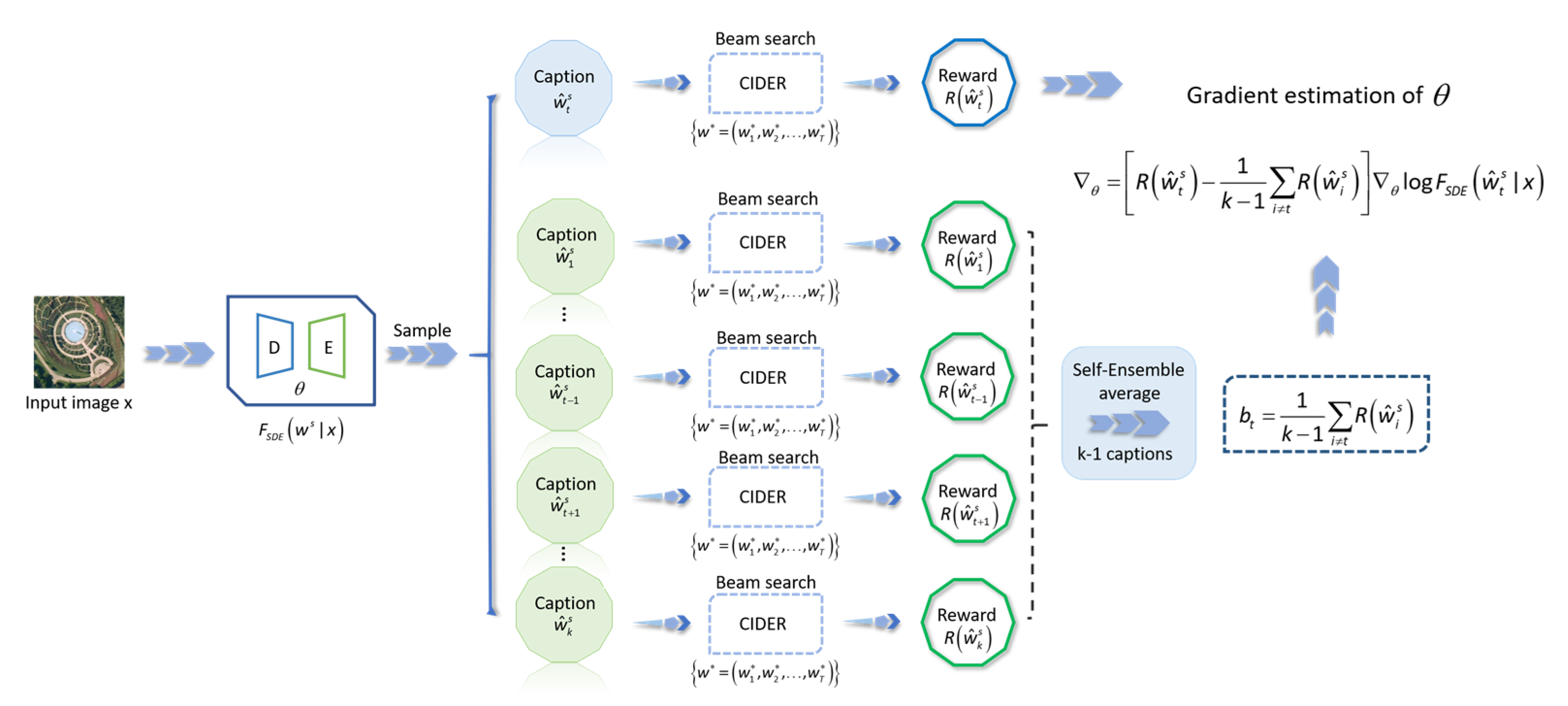
To solve the above problems, we adopt the self-critical paradigm [
57] proposed in the self-critical sequence training for image captioning (SCST) to optimize the process of using reinforcement learning to train the image captioning model. The self-critical technique in SCST introduces a baseline calculated by greedy search, which can reduce the gradient variance. The self-critical technique adjusts the baseline according to the greedy decoding output of the image captioning model in the test reasoning process and finally optimizes the image captioning model, achieving superior performance to the vanilla reinforcement learning. Ref. [
57] shows that the variance of the self-critical model is very small, and good results can be achieved in few-sot samples with the use of SGD. At the same time, the self-critical technique realizes the direct measurement of sequence variables by adjusting the baseline and promotes consistency in the process of training and testing. The optimization goal in self-critical training is to maximize the CIDEr scores of the generated captions. We follow this design, but different from the greedy search used in SCST to calculate the baseline, we simultaneously sample multiple captions of the same remote sensing image by the model and calculate a baseline with self-ensemble according to the beam search [
60]. The schematic diagram of using self-critical to optimize model parameters is shown in
Figure 4.
For few-shot remote sensing scenarios, we collect K captions of the input remote sensing image
generated by the model
after self-ensemble and self-distillation training:
,
. The caption label corresponding to the input remote sensing image
is
. When calculating the CIDEr scores of these K captions, we use beam search instead of greedy search. Beam search has a larger search space than greedy search. It does not pursue local optimization but global optimization. The speed and accuracy of training are better than greedy search. Beam search is very useful in scenarios where there are obvious differences in the data distribution between training samples and test samples [
3], and the few-shot scenario is one of them. Compared with greedy search, the calculation method of beam search can avoid the continuous accumulation of errors to a certain extent and reduce the adverse effects of exposure bias. We integrate the self-ensemble calculation method into the baseline calculation process as follows: we randomly select a caption
, and the baseline
of caption
is obtained by the average integration of the reward CIDEr scores of other K-1 captions:
where
is the CIDEr score of
. Because the K captions and the corresponding CIDEr scores are generated by the same model based on a remote sensing image, they are independent of each other. Therefore, the calculation of
does not depend on
, and
is a valid baseline. The self-ensemble here averages the scores of multiple captions generated by the model for the same input image. The gradient estimation of the parameter
of model
is calculated as:
Self-critical techniques using the baseline obtained from the self-ensemble model can improve the utilization of limited samples and effectively avoid the possible overfitting caused by few-shot problems. At the same time, it can further reduce the gradient variance in the reinforcement learning process and better optimize the few-shot remote sensing image captioning model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}