1. Introduction
HSIs usually contain information on tens to hundreds of continuous spectral bands in the target area. Therefore, HSIs have a high spectral resolution but lower spatial resolution due to hardware limitations. In contrast, PANs are usually single-band images in the visible range, having high spatial resolution but low spectral resolution. Pansharpening involves the reconstruction of low-resolution (LR) HSIs and high-resolution (HR) PANs to generate HR-HSIs, and has been widely used in image classification [
1], target detection [
2], and road recognition [
3].
Traditional HSI pansharpening technologies can be broadly divided into four categories: component substitution-based methods [
4,
5], model-based methods [
6,
7], multi-resolution analysis [
8], and hybrid methods [
9]. Each of these categories has certain limitations. Component substitution-based methods can cause certain types of spectral distortion; multi-resolution analysis-based methods require complex calculations; hybrid methods combine component substitution and multi-resolution analysis, thus providing good spectral retention but fewer spatial details; and, finally, model-based methods are limited by network parameter number and computational complexity.
In recent years, deep learning has been widely used in the field of image processing [
10,
11,
12,
13,
14,
15,
16], while pansharpening has been at the primary stage of exploration [
17]. Yang et al. [
18] proposed a convolutional neural network (CNN) for pansharpening (PanNet), which was performed via ResNet [
19] in the high-pass filter domain. Zhu et al. [
20] designed a spectral attention module (SeAM) to extract the spectral features of HSIs. Zhang et al. [
21] designed a residual channel attention module (RCAM) to solve the spectral reconstruction problem. However, as is well-known, CNNs can learn one feature more easily than multiple features, and have fewer parameters. Moreover, in the feature extraction process, simultaneous learning of multiple features is affected by the features’ effects on each other. To reduce the influence of these effects, Zhang et al. [
22] improved classification results by measuring the difference in the probabilistic behavior between the spectral features of two pixels. Xie et al. [
23] used the mean square error (MSE) loss and spectral angle mapper (SAM) loss to constrain spatial and spectral feature losses, respectively. Qu et al. [
15] proposed a residual hyper-dense network and a CNN with cascade residual hyper-dense blocks. The former network extends Denset to solve the problem of spatial spectrum fusion. The latter network allows direct connections between pairs of layers within the same stream and those across different streams, which means that it learns more complex combinations between the HS and PAN images.
The above studies show that the better the spatial and spectral feature learning, the better the fusion result for deep-learning-based hyperspectral pansharpening methods. However, it is well known that hyperspectral images contain a large amount of data because of many bands. Thus, it is a challenge for the hyperspectral pansharpening method to fully learn and utilize the spatial and spectral features without increasing computation excessively. Commonly, single feature learning is easier than multiple feature learning, while multiple collaborative learning is more effective than single feature learning. Inspired by mutual learning, in this paper, we explore a novel pansharpening method that learns the spatial and spectral characteristics separately and establishes the relationship between them to learn from each other to achieve desirable results.
In recent years, a deep mutual-learning strategy (DML) [
24] has been proposed for image classification, and includes multiple original networks that mutually learn from each other. This unique training strategy has great potential for multi-feature learning of a single task using few parameters. It therefore has research value in the field of HSI pansharpening. To the authors’ knowledge, there has been no application of DML to HSI pansharpening.
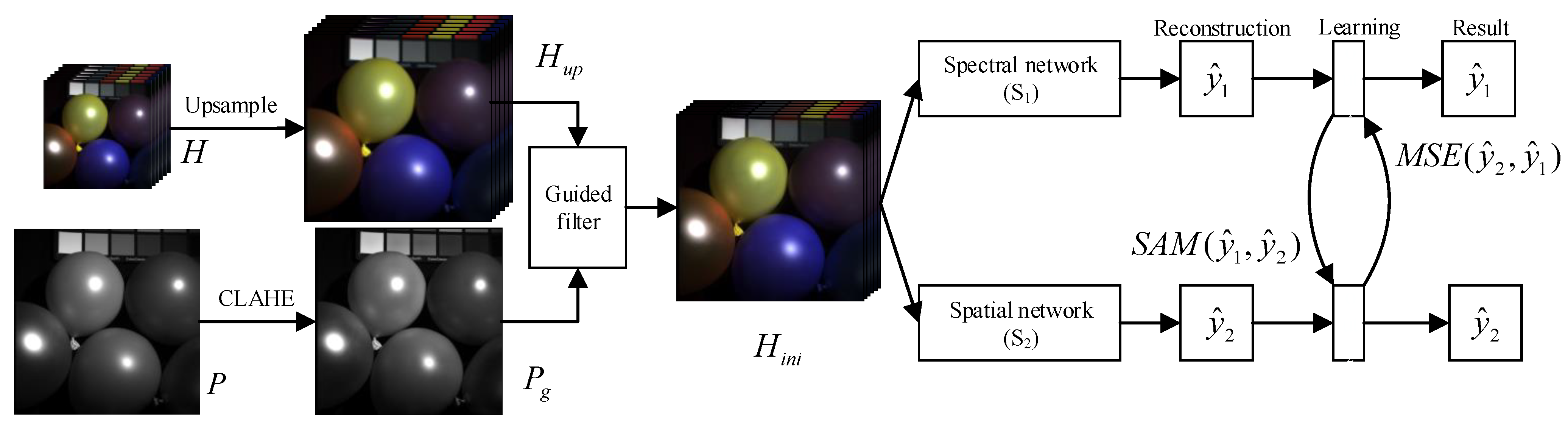
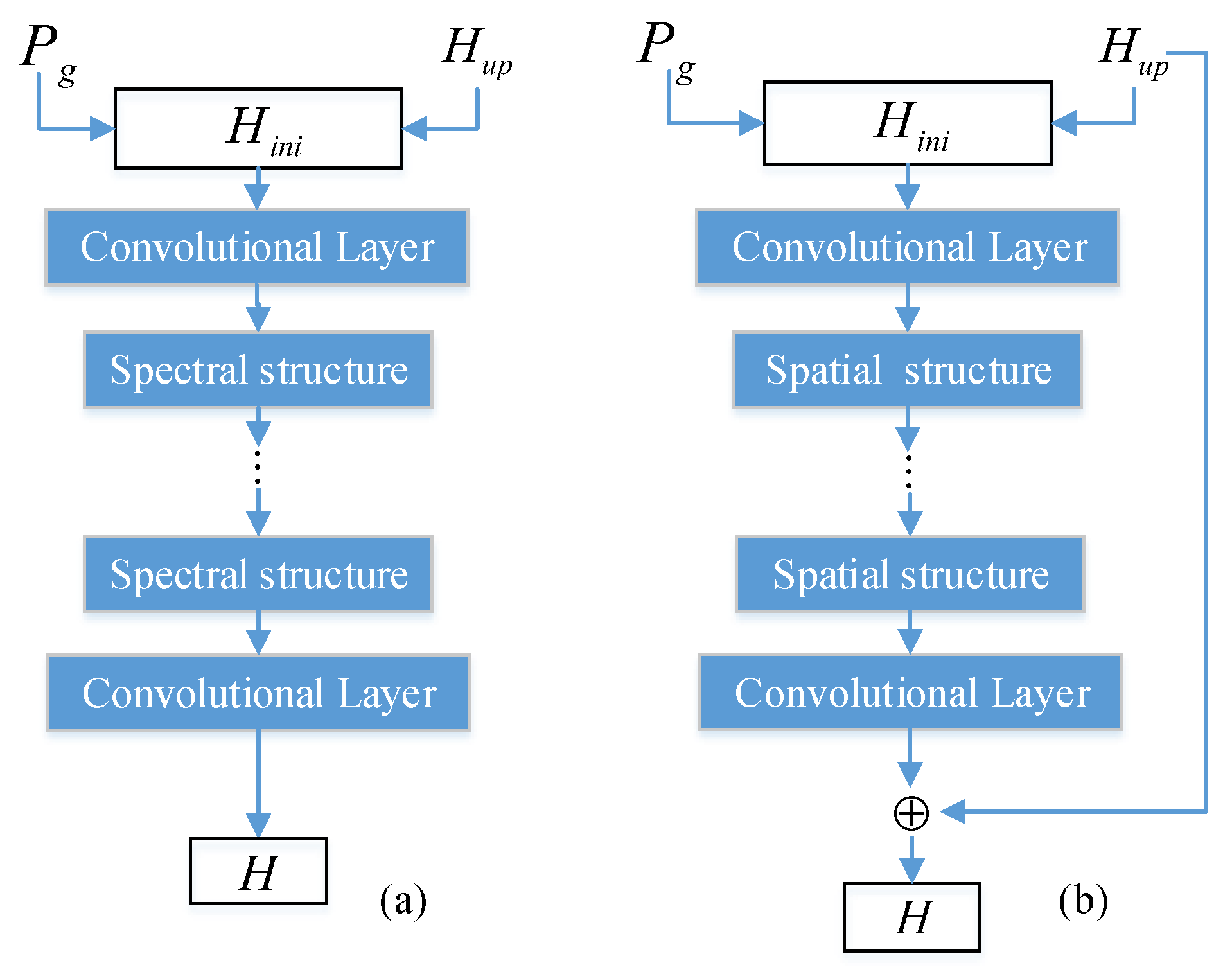
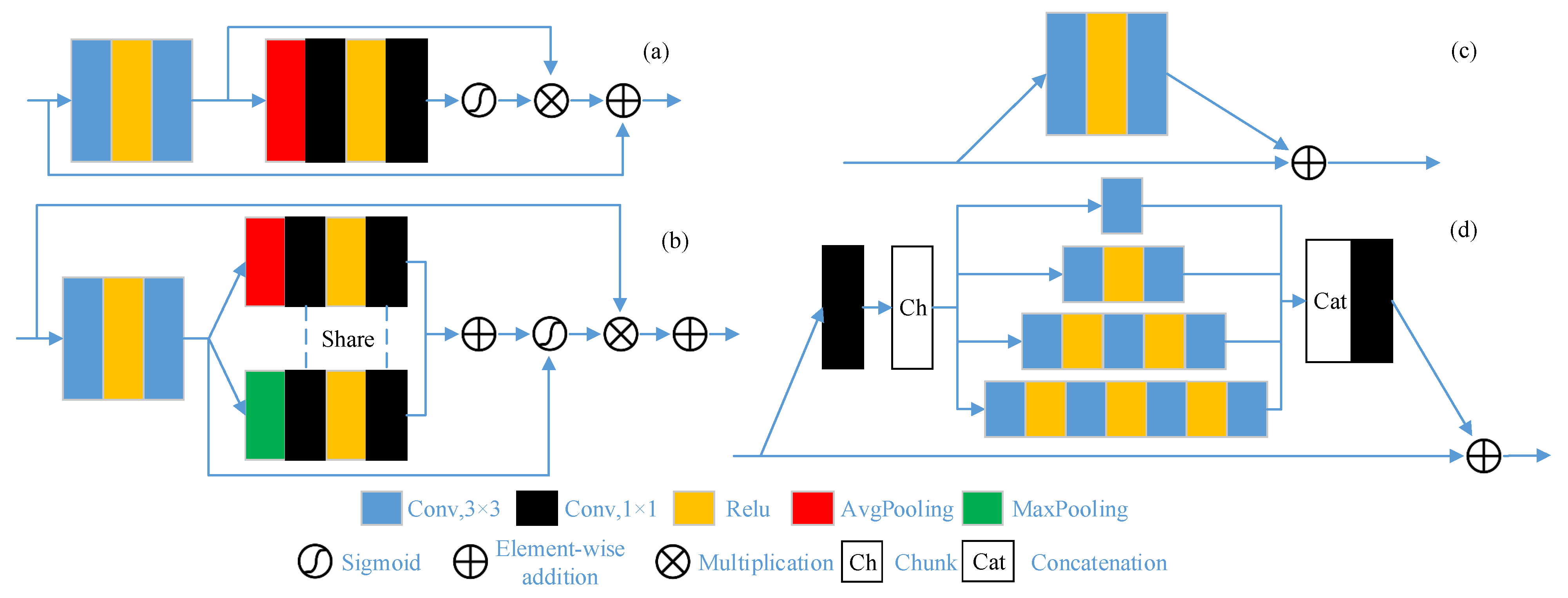
This paper proposes a deep mutual-learning framework integrating spectral-spatial information-mining (SSML) for HSI pansharpening. In the SSML framework, two simple networks, a spectral and a spatial network, are designed for mutual learning. The two networks learn different features independently; for instance, the spectral network captures only spectral features, while the spatial network focuses only on spatial details. Then, the DML strategy enables them to learn each other’s features. In addition, a hybrid loss function is derived by constraining spectral and spatial information between the two networks. The main contributions of this paper are summarized below:
This paper proposes an SSML framework which introduces a DML strategy into HSI pansharpening for the first time; four cross experiments are performed to verify the proposed SSML framework’s effectiveness, and the network’s generalization ability is confirmed by the latest research results in the field of HSI generalization sharpening.
A hybrid loss function, which considers the HSI characteristics, is designed to enable each network in the SSML framework to learn a certain feature independently, thus improving its overall performance so that the SSML framework can successfully generate a high-quality HR-HSI.
The rest of the paper is organized as follows.
Section 2 presents related work, while
Section 3 introduces the proposed SSML.
Section 4 describes and analyzes the experimental results. Finally,
Section 5 concludes the paper with a short overview of its contributions to research.
2. Related Work
The DML strategy [
24] was initially proposed for image classification, but, after several years of development, it has been applied in many fields [
25,
26,
27]. The DML strategy uses a mutual-loss learning function, which allows multiple small networks to learn the same task together under different initial conditions, thereby improving the performance of each of the networks [
24]. For classification problems, Kullback–Leibler (KL) divergence [
28] has often been used as a mutual learning loss function in the DML because it can calculate the asymmetric measure of the probability distribution between two networks; it is defined by:
where
calculates the distance from
to
However, in the field of HSI pansharpening, it is usually necessary to evaluate the image quality rather than the probability distribution of pixels. HSIs have a high correlation between pixels in each band. Therefore, it is necessary to consider other loss functions as the mutual learning loss function instead of the KL divergence. Traditionally, MSE and SAM [
29] have been used to evaluate the spatial quality and spectral distortion of HSIs. Therefore, the effects of the MSE and SAM on the proposed SSML framework’s performance are examined in this paper.
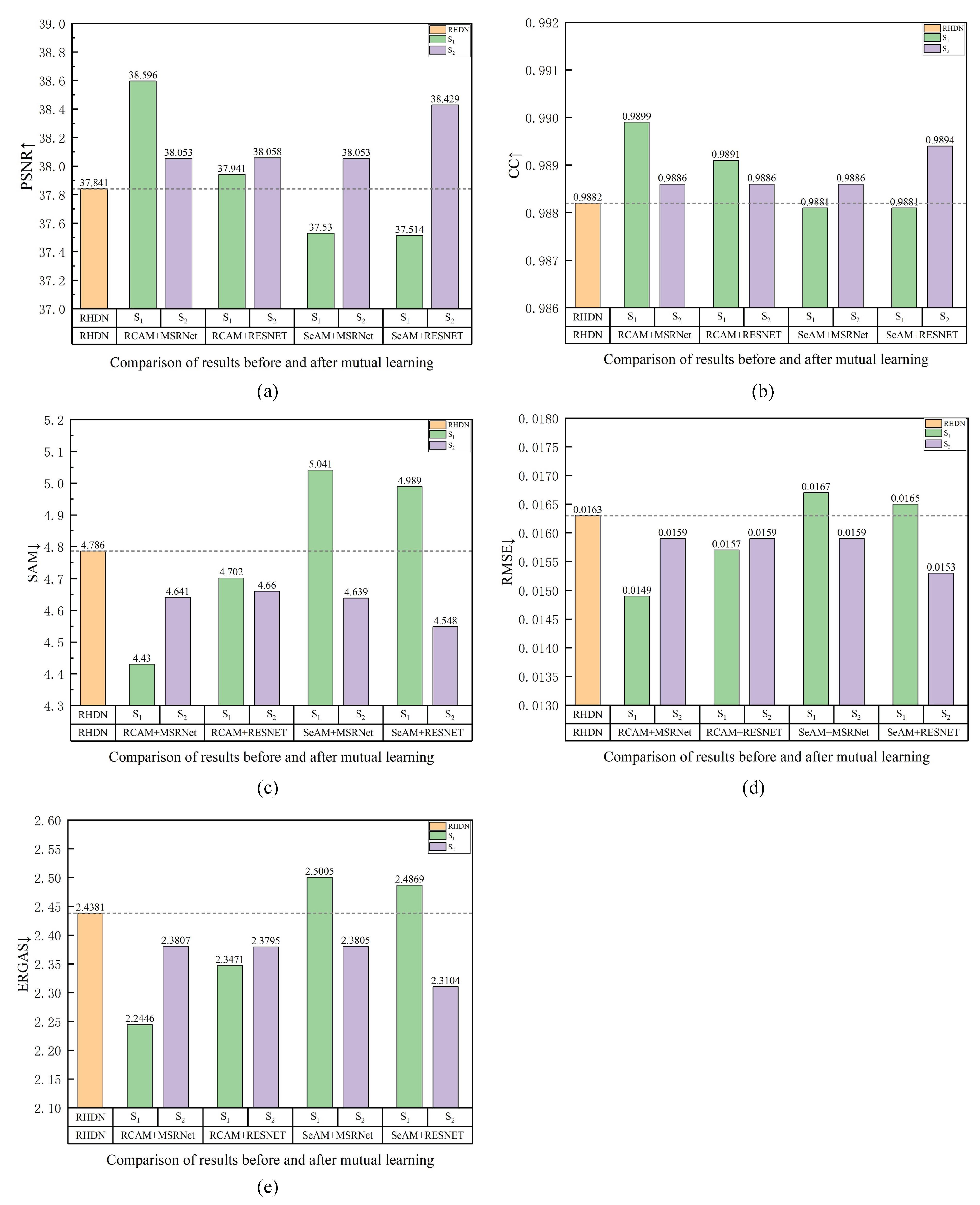
5. Conclusions
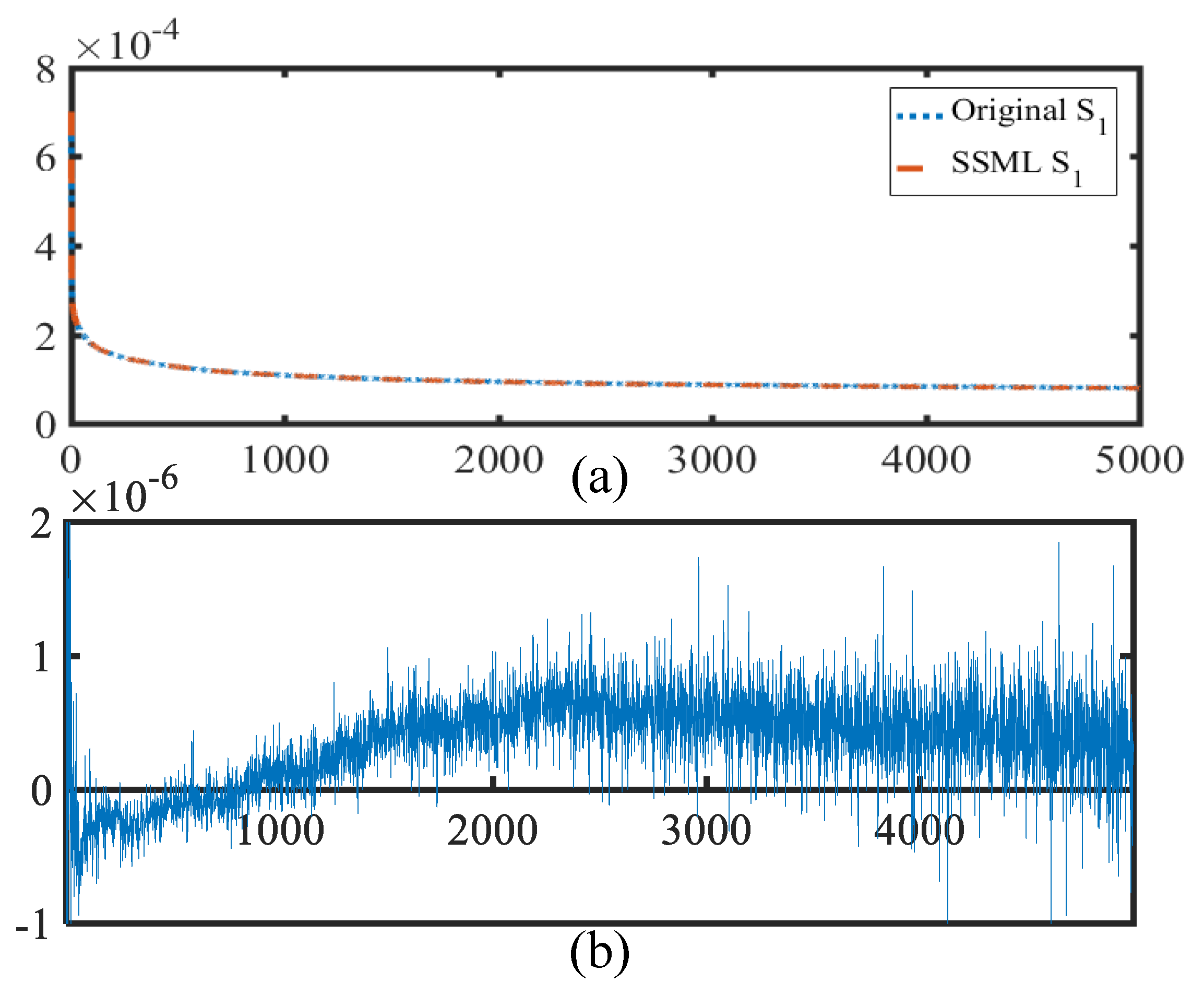
This paper proposes an SSML framework integrating spectral-spatial information-mining for HSI pansharpening. In contrast to the existing CNN-based hyperspectral pansharpening framework, based on the DML strategy, we designed spectral and spatial networks for learning the spectral and spatial features. Furthermore, a set of mixed loss functions, based on a mutual learning strategy, is proposed for transfer of information for different features, which can extract features without introducing excessive computation through mutual learning. In experiments undertaken, several cases were examined to evaluate the effect of DML on the pansharpening result. The results demonstrated that introducing the DML strategy into the SSML framework was able to help achieve improved results in HSI pansharpening. The performance of the SSML framework was compared with several state-of-the-art methods; the results of the comparisons demonstrated the effectiveness and advantages of the proposed SSML framework. The latest fusion results were used to verify the generalization ability of the SSML framework, with improved results observed. Discussion of the feasibility of the hybrid loss function and the number of deep network parameters suggested that the proposed SSML framework represents a promising framework for HSI pansharpening.
In future, HSI pansharpening under the SSML framework will be explored further to identify improved spectral-spatial features for HSIs. A further research direction will involve the application of the DML strategy to other image-processing fields.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}