1. Introduction
SAR images are widely used in the military field. Target recognition is the important support of military reconnaissance and attack. ATR can improve the efficiency of target recognition, and researchers in related fields have proposed a large number of ATR algorithms for SAR images. Among them, the relatively simple nearest-neighbor algorithm [
1] and, with a moderate degree of complexity, are the Principal Component Analysis (PCA) [
2], Two-Dimensional PCA (2DPCA) [
3], and Sparse Representation Classification (SRC) [
4]. Those with a high complexity are SVM [
5] and deep learning [
6,
7,
8]. A deep learning-based SAR image ATR algorithm is the best performance method [
7]. In the traditional ATR method, the most important step is to find the most representative features of the target, such as using a discrete wavelet analysis to extract the target features [
9], and then using SVM as a classifier for classification. The Principal Component Analysis (PCA) is used as the feature extractor, and then, the features are input into the ART2 neural network for classification [
10,
11], applying non-negative matrix factorization features to SAR target recognition [
12].
In recent years, the target recognition based on deep learning has achieved great success, and the application of deep learning in SAR target recognition has been widely concerned. Generally speaking, because of the small number of military target samples and the complexity of a deep neural network, it is easy to be overfitted in model training, which affects the accuracy of recognition. Data expansion of the training sample set can alleviate overfitting to some extent, but it cannot be avoided completely. Li X et al. proposed a method based on dividing the Convolutional Neural Network (CNN) into a CAE and Shallow Neural Network (SNN) to accelerate the training [
13], while it also causes the loss of the recognition rate and also has certain limitations on the image angle. Housseini A E. et al. proposed deep learning algorithms based on the convolutional neural network architecture [
14], extracting trained filters from the CAE and using them in the CNN has given a good result in terms of the time of calculation, but the accuracy is not better than either one. Chen S. et al. presented a new all-convolutional networks (A-ConvNets) [
15]; the experimental results on the MSTAR benchmark data can achieve an average accuracy of 99%, but under Extended Operating Conditions (EOC), only achieve more than 80%. Wagner et al. proposed to use CNN to extract the feature vector [
16] and then input the feature vector into SVM for classification. With the presented training methods, a correct classification rate of 99.5% in the confusion matrix best forced decision case was achieved. However, the experimental results under other conditions were more general. In the above articles, the experiments involving the MSTAR (Moving and Stational Target Acquisition and Recognition) database [
17] were only identified for ten different types of military targets, and the targets of the same type were not studied in depth, and the results were not extensive. However, in the related research of SAR image ATR, researchers usually set their problem under more ideal conditions. For example, in the existing literature on SAR image ATR technology, most people assume (or by default) that the center of the target to be identified is in the center of the sample image. There is literature assuming that the orientation of the target in SAR images is known or can be estimated [
7]. The actual SAR image ATR system usually includes three steps: detection, identification, and recognition [
18]. In the target detection stage, it is necessary to find the location of the military target from the large scene, and usually, the detection result will have a certain error [
19]. In the target identification stage, it is necessary to exclude the detected interference target and estimate the target pose and others. Due to the errors in both target detection and identification, it is difficult to ensure that the target is at the center of the sample image intercepted after detection and ensure that the identified posture is consistent with the actual situation. In addition, most of the applications based on starborne SAR images are used in geocoded data products, and the original SAR images will undergo a certain geometric deformation. For small image blocks in large scenes, this deformation can be roughly approximated using rotation transformations. Therefore, in order to reduce the dependence on the detection and discrimination accuracy, the SAR ATR algorithm closer to a real situation should have a high robustness in the target position and the image rotation.
In this paper, a method of SAR image ATR based on CAE and SVM is proposed. CAE can extract the features of the data by using an unsupervised method, and the nonlinear classification advantage of SVM can classify the features extracted by CAE to get a better classification effect. To improve the utility of the training model in real SAR environments, the effects of image rotation and center offset on the classification accuracy of ATR models in SAR images were also investigated. We also verified that the model has high classification accuracy for 12 different rotation angles and has ideal classification results for different center offset datasets. At the same time, in order to satisfy the higher recognition accuracy, the key object recognition method of CAE based on special initialization and improved loss function is proposed. While maintaining a high overall identification accuracy, it can further improve the recognition accuracy of the key targets and achieve a high accuracy identification of the specified targets.
3. Experimental Results and Analysis
In this paper, the MSTAR database is used for experimental verification. The database is provided by the MSTAR project jointly funded by the US Defense Preresearch Program Agency (DARPA) and the US Air Force Laboratory (AFRL). The database contains SAR images of different military targets obtained by a 0.3-m resolution X-band cluster mode airborne SAR system at different pitch angles and 360 circular flight conditions. The database includes three datasets: T72_BMP2_BTR70, T72 variant, and mixed target. The mixed target dataset includes seven different categories of military targets, namely armored personnel carriers: BTR-60 and BRDM-2, rocket launcher: 2S1, bulldozer: D7, tank: T62, truck: ZIL-131, and air defense unit: ZSU-234, whose optical photos and SAR images are shown in
Figure 3. The T72_BMP2_BTR70 dataset contains three types of targets with similar structures. Among them, BMP2 armored vehicles have three models: SN-C21, SN-9563, and SN-9566, and the T72 main battle tank has SN-132, SN-812, and SN-S7. The T72 variant dataset includes eight different models of the T72 main battle tank, namely, the A04, A05, A07, A10, A32, A62, A63, and A64.
The features of the target in the SAR images are very sensitive to the incident direction during shooting. Therefore, although the MSTAR database provides the SAR images taken at the 360° azimuth angle, it is impossible to describe the phenomenon of image rotation after shooting. The image sizes of the different targets in the original data were inconsistent, but the targets were all located in the center of the image. The SAR image looks blurred and out of focus due to a lack of resolution and the noise created by the background and SAR data processing. Using the T72_BMP2_BTR70 dataset as an example, samples with a rotation transformation and a center offset were generated using the original images. Using the original image center as the reference point, the intercepted image block of size 80 × 80 was taken as the sample used in the experiment. To expand the dataset, the resulting training samples were manipulated by translation and rotation, as shown in
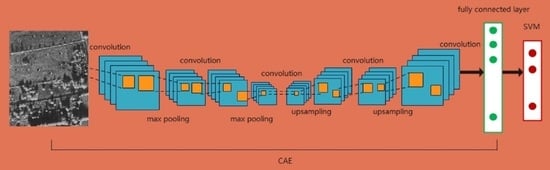
Figure 4. The training sample set was expanded by 12 times for all the images of 30° in the range from 0° to 330°. The translation operation of the image pixels was also performed, shifting in the range of 9 by 9 pixels in the two-dimensional direction of the sample image with three pixels as the steps. This translation mode expands the training sample set 36 times. For feature extraction training using the previously introduced method, the training sample set is input into the CAE model for pretraining, encoding the input samples using the encoder, and used to reconstruct the input samples using the decoder. The above data amplification method was used in the pretraining, and 3000 samples of each class were randomly selected from the amplified dataset as the training samples. The parameters of the CAE model used in the experiment are set as shown in
Figure 5. The encoder contains the four convolutional layers and the three maximum pooling layers, and the first three convolution layers are all connected behind them. The kernel function size of the four convolution layers is 6 × 6, 5 × 5, 5 × 5, and 3 × 3, and the number of kernel functions is successively 128, 64, 32, and 16. The decoder contains four convolutional layers, three upsampling layers, and the latter three convolution layers are all connected to an upsampling layer. The kernel function sizes of the four convolution layers are 3 × 3, 5 × 5, 5 × 5, and 6 × 6, and the number of kernel functions is successively 16, 32, 64, and 128. After CAE training, the reconstruction result of the target is as shown in
Figure 6. The first line is the original target image, and the next line is the reconstructed image. The reconstruction loss is 0.12. It can be seen from the diagram that the CAE model after training can reconstruct the original image well and has good capability of feature extraction.
After pretraining, the coding layer of the CAE model is connected with SVM to form a classification network; thus, the classification of military targets is realized. The identification results for the three types of targets in the T72_BMP2_BTR70 dataset are shown in
Table 1. The recognition results of a class of targets in the table represent the statistics of the corresponding class after classification. As can be seen from the table, the classification accuracy of the three types of targets reached more than 98%. The target recognition accuracy of the original CAE method with softmax as the classifier are also given. The difference between the two methods is that the original CAE method uses softmax as the classifier for classification recognition after pretraining while the CAE and SVM fusion method uses SVM as the classifier. The average recognition rate of the original CAE method is 97.0% and that of the fusion method of CAE and SVM is 99.0%, which is 2% higher than that of the original CAE method. In addition, the classification accuracy of other target recognition methods such as SVM, Multilayer Perceptron (MLP) and AdaBoost are given in
Table 2. It can be seen that the target recognition accuracy of the CAE and SVM fusion method proposed in this paper is better than that of the other methods given in the table. In order to verify the above conclusions, eight kinds of military targets in the T72 variant dataset, and seven kinds of military targets in the mixed target dataset were classified and identified, respectively, in the experiment, and the recognition accuracy of each military target can reach above 90%.
The model was trained using a training set with both a rotation angle and a center offset of 0. The trained models were used to predict the training and test sets with different rotation angles and different central offsets. The test on the training set can verify that, in the same original data, it is only affected by the accuracy of the model. The classification results for samples with different rotation angles are shown in
Table 3.
It can be seen that the model obtained by the synthetic training set has a high classification accuracy for all 15 different rotation angles. Although the classification accuracy of the model in the training set is higher than that of the test set, the 96.4% test set accuracy is enough to show that the model is effective and stable in ideal conditions (without rotation and translation).
The test results of this model on sample sets with different offsets are shown in
Table 4. The classification accuracy of the model for the training and test sets with a central offset is correlated with the offset. Overall, the larger the central offset, the lower the prediction accuracy of the model is, and the accuracy is slightly decreased as the offset increases.
Since high-resolution SAR images have smaller pixel blocks required to contain a single military target, some geometric transformations of large scene images (such as oblique conversion) have less impact on the military target image block. Even if the image of a large scene is geocoded, the deformation of the image block of the military target can be roughly approximate by the rotation transformation. On the other hand, the offset of the center as a major error in target extraction also has implications for target classification. Therefore, the image rotation and center offset can be taken as the important factors affecting the performance of starborne SAR, system army, and matter and event target ATR system. The robustness of recognition algorithms in rotation and translation can improve the performance of ATR systems in real application environments. Through the above experiments, we can see that the proposed model has a high classification accuracy for all 12 different rotation angles, and the classification results for the datasets with different central offsets are also very ideal.
In the previous experiments, only the slice image containing the target is processed, and only the target classification process in ATR is involved. The actual ATR process also includes the step of target detection, because the SAR scene image generally contains complex objects such as trees, buildings, grasslands, water bodies, etc., so the goal needs to be separated from the complex background first. Then, the target slice images are classified to recognize different target categories. In this paper, two-step improved CAE algorithm is used to realize the object end-to-end recognition. Firstly, the improved CAE algorithm is used to realize the binary classification of the scene image; that is, the scene is divided into target and background, and the target is extracted from the scene. Then, multiclassification recognition is carried out on the extracted target image. The open MSTAR dataset provides a 1748 × 1478 pixel image of the scene and the target slice. However, these scene images do not contain military targets. For experimental verification, a 128 × 128 pixel object slice image is embedded into the background image, as shown in
Figure 7a, which contains the background and three types of military objects in the T72_BMP2_BTR70 dataset. This method is reasonable, because both the background image and the target slice image are obtained by the same SAR system with a resolution of 0.3 m.
The target detection can be realized by binary classification, in which the fusion method of CAE and SVM is adopted, the target and background samples are used as training samples in the process of target detection, and the features are extracted through the trained CAE model; then, SVM is used as a classifier for classification. The background sample is selected randomly from the background image, and the target sample is selected from the same dataset as before. An example of a training sample set is shown in
Figure 8. The target contains different types of military targets in various poses. The background sample contains a variety of ground objects, such as trees, meadows, buildings, and farmland.
The trained binary CAE model can be used as a target detector to recognize military targets in complex scenes by a sliding window. The output of the classification is the probability of belonging to two categories. Here, 0.8 is chosen as the threshold value, and the area where the probability of belonging to a military target is greater than 0.8 is judged to be a military target; the three types of target detection results from the T72_BMP2_BTR70 dataset are shown in
Figure 7b. Red is the location area where the target may exist, and blue is the background area. According to the detection results, the slice image corresponding to the target area can be extracted from the scene, in which the 80 × 80 target image is extracted with the target as the slice center. Then, the separated object samples can be input into the previously trained multiclass CAE model to get the object category. If the T72, BMP2, and BTR70 objects detected in
Figure 7a are input into the corresponding CAE model that has been trained before, the target categories can be obtained. The final result is shown in
Figure 7c. The red box is the location of the target in the diagram, and the green text is the category of the target.
In the same way, the experiments are carried out on the scene in
Figure 7d of eight kinds of targets with the T72 variant and the scene in
Figure 7g of seven kinds of targets with mixed targets. The results of target detection are shown in
Figure 7e,h, respectively. The final identification result of the eight target classes of the T72 variant is shown in
Figure 7f, where the target class in the upper right corner is marked in red, indicating that the target is misclassified. The final recognition result of the seven mixed targets is shown in
Figure 7i, where the target category in the upper left corner is marked with yellow, indicating that the area is the background and is misclassified as the target. Although the result of recognition is misclassified and a false alarm, the result of statistical experiment on a large number of images shows that the accuracy of the whole recognition is still very high, which proves the validity of the fusion method of CAE and SVM.
The precise identification of the special object by changing the CAE network initialization and improving the loss function is verified by the MSTAR public database. This paper takes eight kinds of military targets of the T72 variant as an example to carry out target recognition. In order to study the influence of the improved loss function method on different targets, two targets, A04 and A10, are set as the key targets, and the other targets are the common targets.
In the experiment, the results of target recognition without the above initialization and the improvement of the loss function are studied, as shown in
Table 5. The identification accuracy of the key targets is not better than the other categories of targets, and failed to achieve the key identification of specific targets. In order to improve the identification accuracy of the key targets, the model was first trained by using the key target training samples to pretrain to achieve the model initialization, but the improved loss function was not adopted. The resulting target identification results are shown in
Table 6. In the experiment, the effect of the improved loss function on the accuracy of key target recognition is further studied. After model initialization and supervised training, the improved loss function is adopted. The result of target recognition is shown in
Table 7.
The experimental results show that the recognition accuracy of the key target is improved greatly after the model initialization and the improvement of the loss function. Although the recognition accuracy of ordinary targets decreases slightly, it is still above 90%, and the overall recognition accuracy of the target is kept at a good level.
To further verify the above conclusions, the seven categories of mixed targets were experimentally verified, and the 2s1 and T62 targets were selected as the key targets. The first set of experiments investigated without network initialization and improved loss function, and the target identification results are shown in
Table 8, it can be seen that the key identification of specific goals has not been achieved. The second set of experiments used the key target samples to achieve the model initialization and did not adopt the improved loss function, and the target identification results are shown in
Table 9, the recognition accuracy of the key targets 2s1 and T62 was improved by 1% compared to the previous recognition results, while the ordinary targets were slightly decreased, with the average accuracy decreasing by 0.29%. The third set of experiments further investigated the effect of the improved loss function on the recognition accuracy of the two key targets of 2s1 and T62. The target identification results are shown in
Table 10, and the recognition accuracy of the key targets 2s1 and T62 was improved 3% and 4% compared to the original method, the average recognition accuracy decreased by about 1.22% relative to the results of the original method. The above experimental results show that to initialize the model and improve the loss function can further improve the recognition accuracy of key targets while maintaining the high overall recognition accuracy and play a great role in the key identification and extraction of special targets.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}