
Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds



Abstract
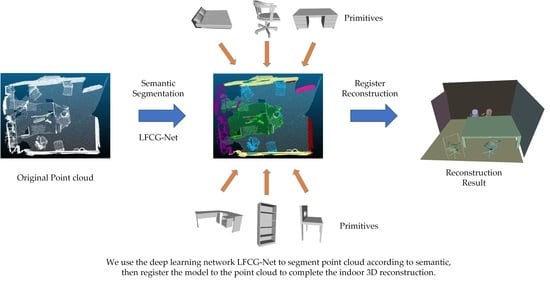
:
1. Introduction
- (1)
- Low degree of automation. Most of the existing methods reconstruct high-quality 3D semantic models manually or semi-automatically.
- (2)
- Insufficient semantic utilization. Existing modeling methods do not fully utilize the semantic information of point clouds, which contains the priors that can improve the resilience to the noise and incompleteness of point clouds.
- (3)
- Loss of details in geometry and incomplete detailed characterization. Existing methods often do not fully describe details such as edges and corners, especially for complex shapes, which affects the visualization.
- (4)
- Oversized geometric data. The existing methods mostly generate triangular mesh from dense point clouds. The data size is much larger than that of the semantics, which is inefficient for visualization.
- (1)
- We propose an efficient and accurate point-cloud semantic-segmentation network (LFCG-Net).
- (2)
- Based on the enumerable features of indoor scenes, we propose a 3D-ESF indoor-model library and an ESF-descriptor-based retrieval algorithm.
- (3)
- We propose a robust and coarse-to-fine registration algorithm to rapidly reconstruct the 3D scene from the incomplete point cloud.
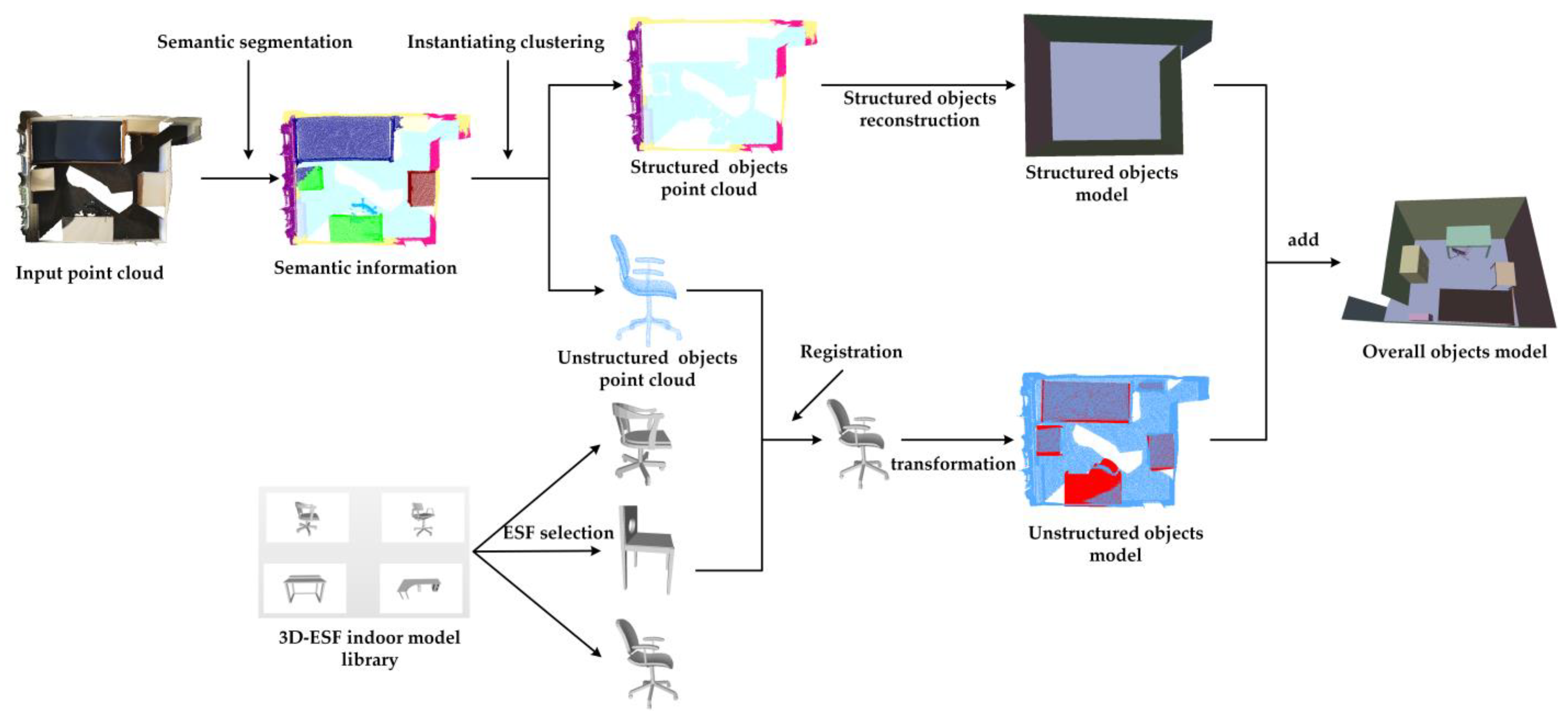
2. Materials and Methods
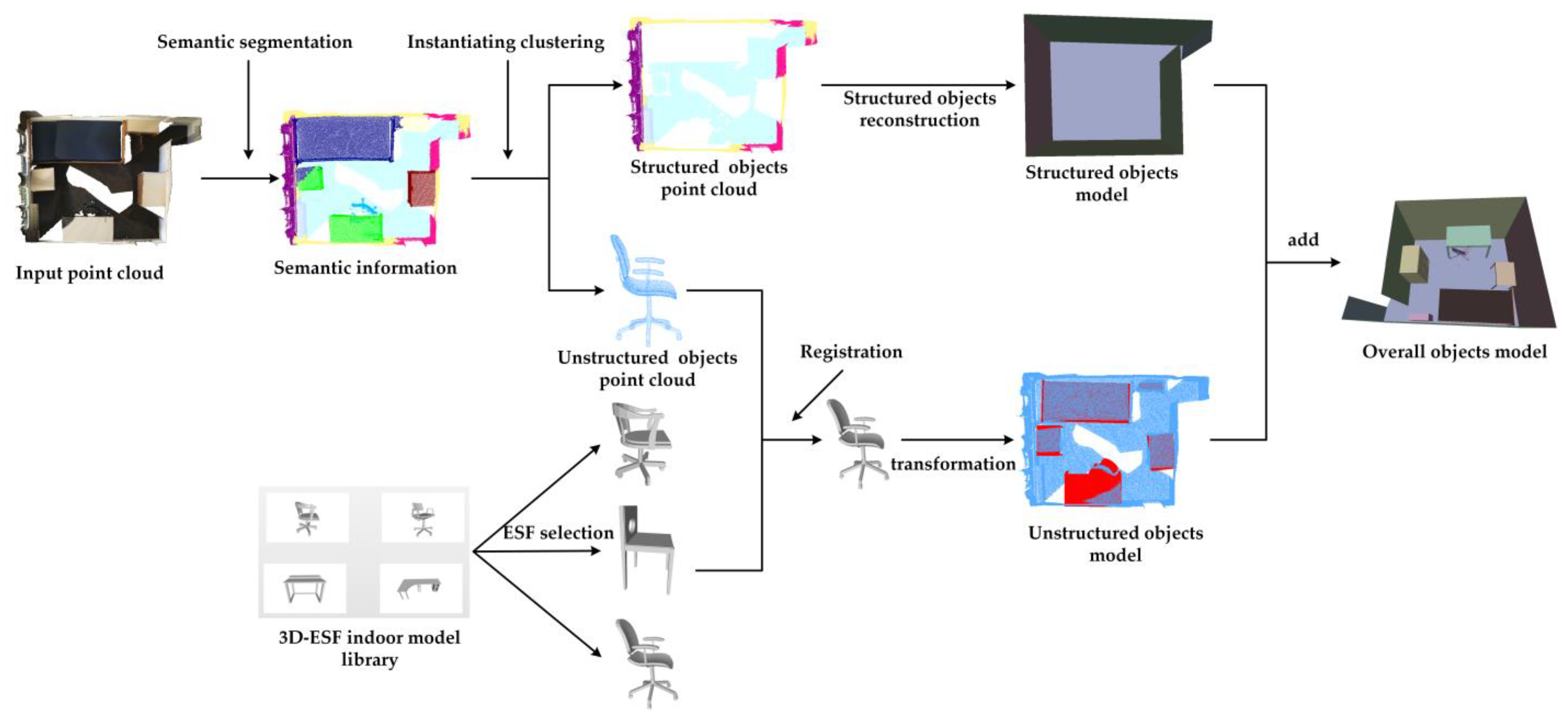
- (1)
- Semantic segmentation. We fed the point cloud into our LFCG-Net to obtain the semantic labels of the point cloud;
- (2)
- Instantiating clustering. Based on the semantic segmentation result, an instantiating-clustering algorithm was applied to separate the point clusters into individual clusters.
- (3)
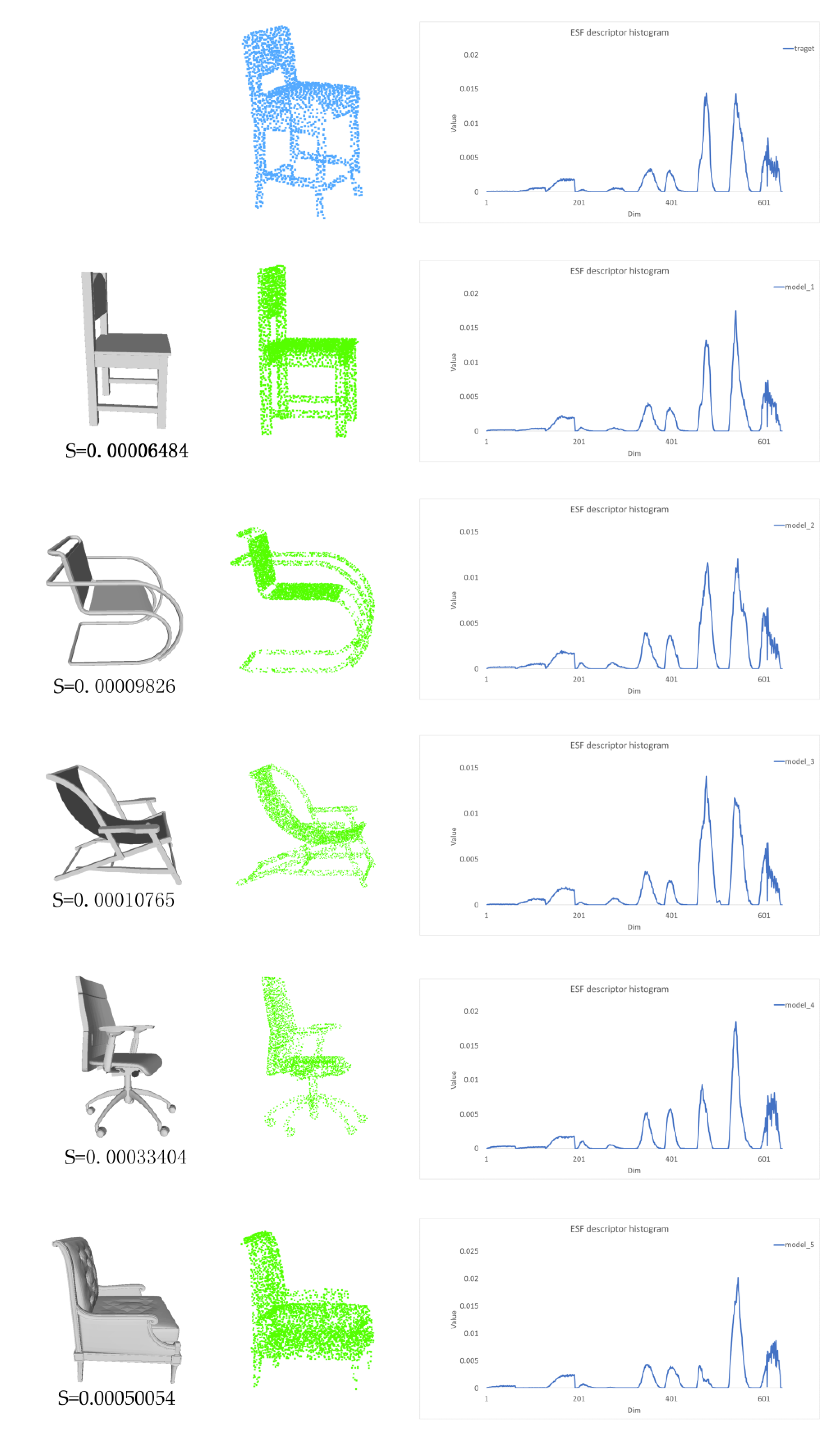
- Unstructured-objects reconstruction. We retrieved the similar candidate models in our 3D-ESF indoor model library with the semantic label and ESF descriptors. Next, we registered the model to the scene;
- (4)
- Structured-objects reconstruction. The plane-fitting algorithm was used to model objects such as walls, floors, ceilings, etc.
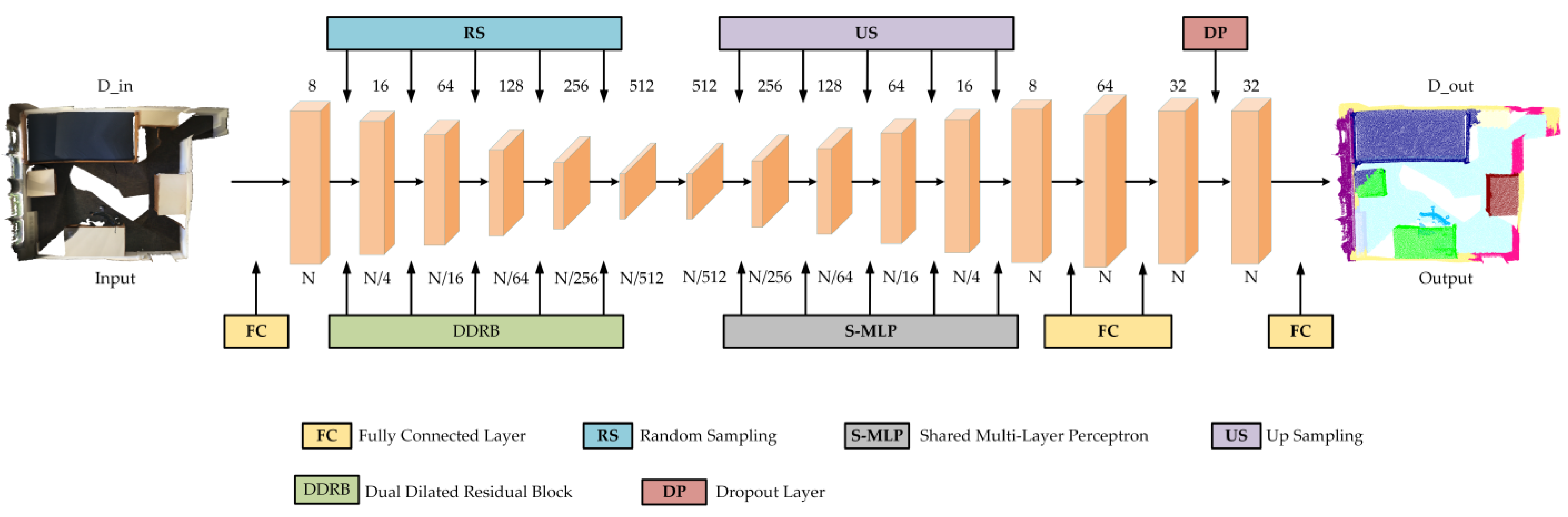
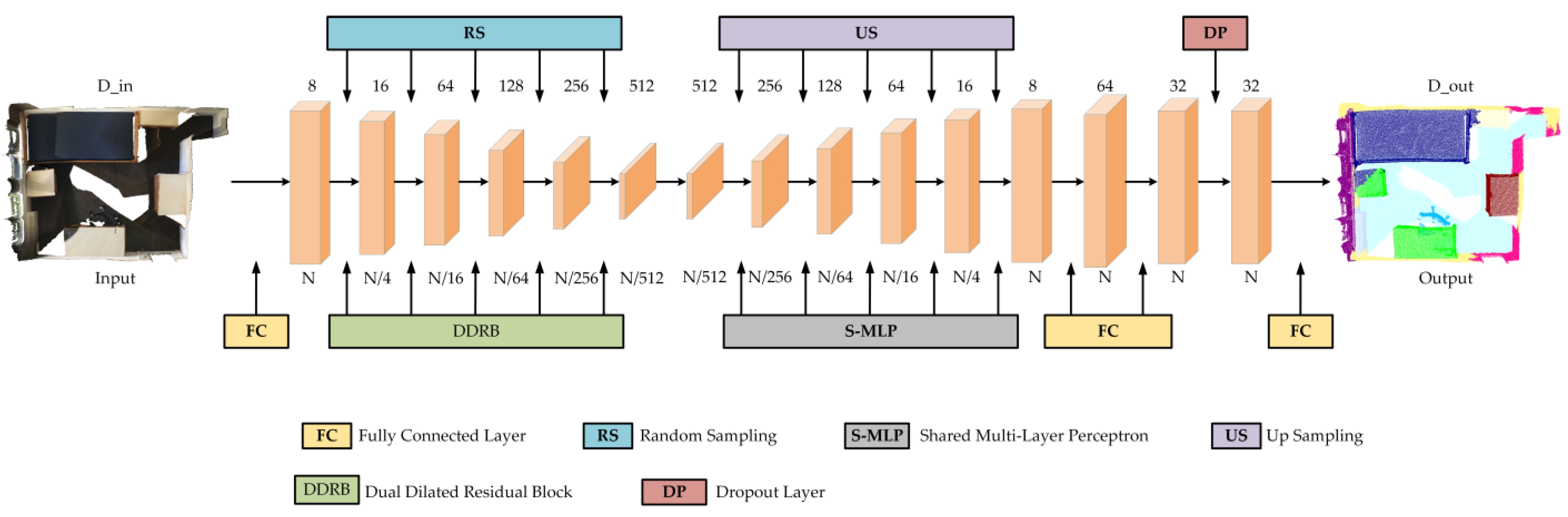
2.1. Local Fully Connected Graph Network
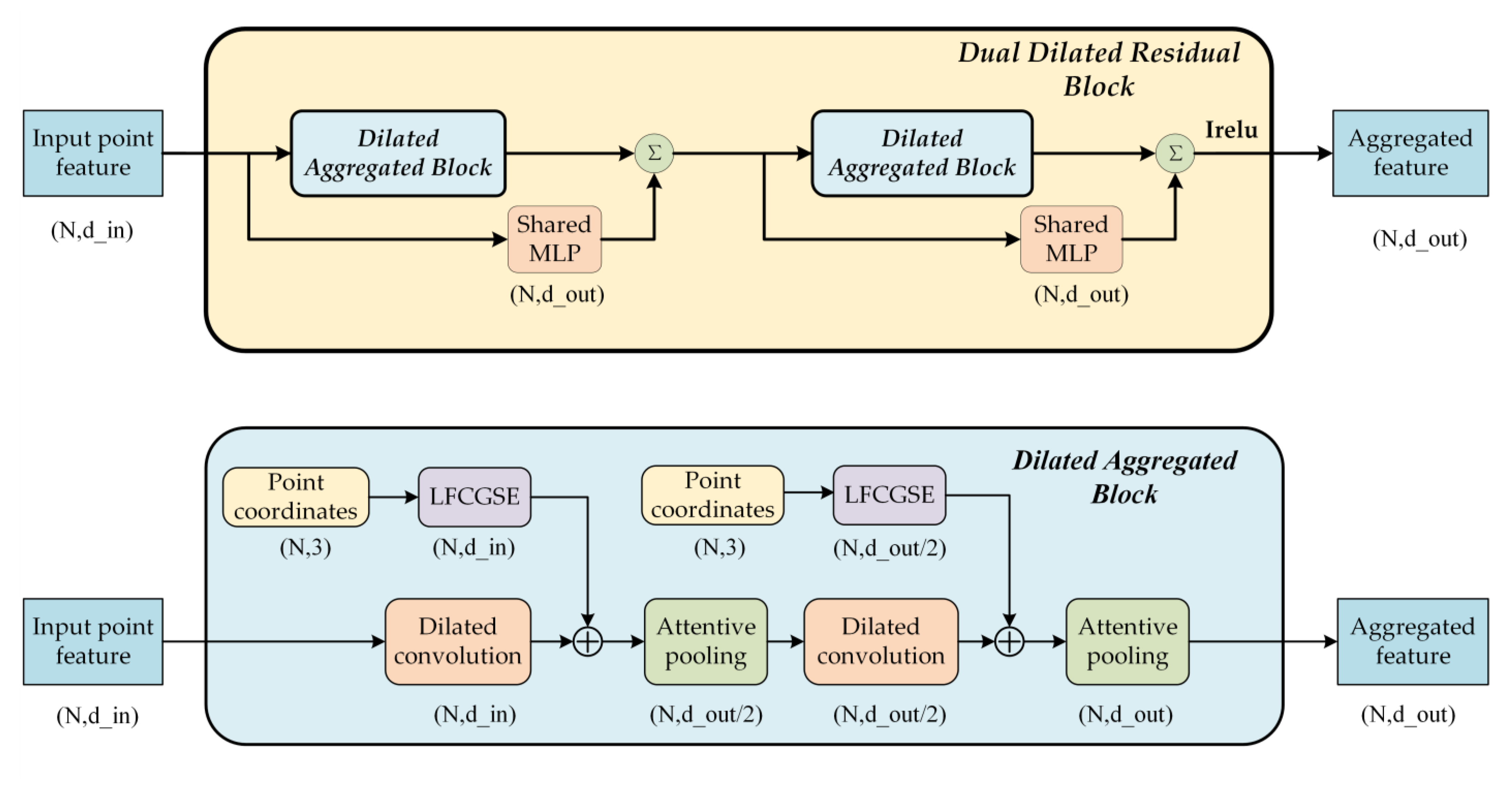
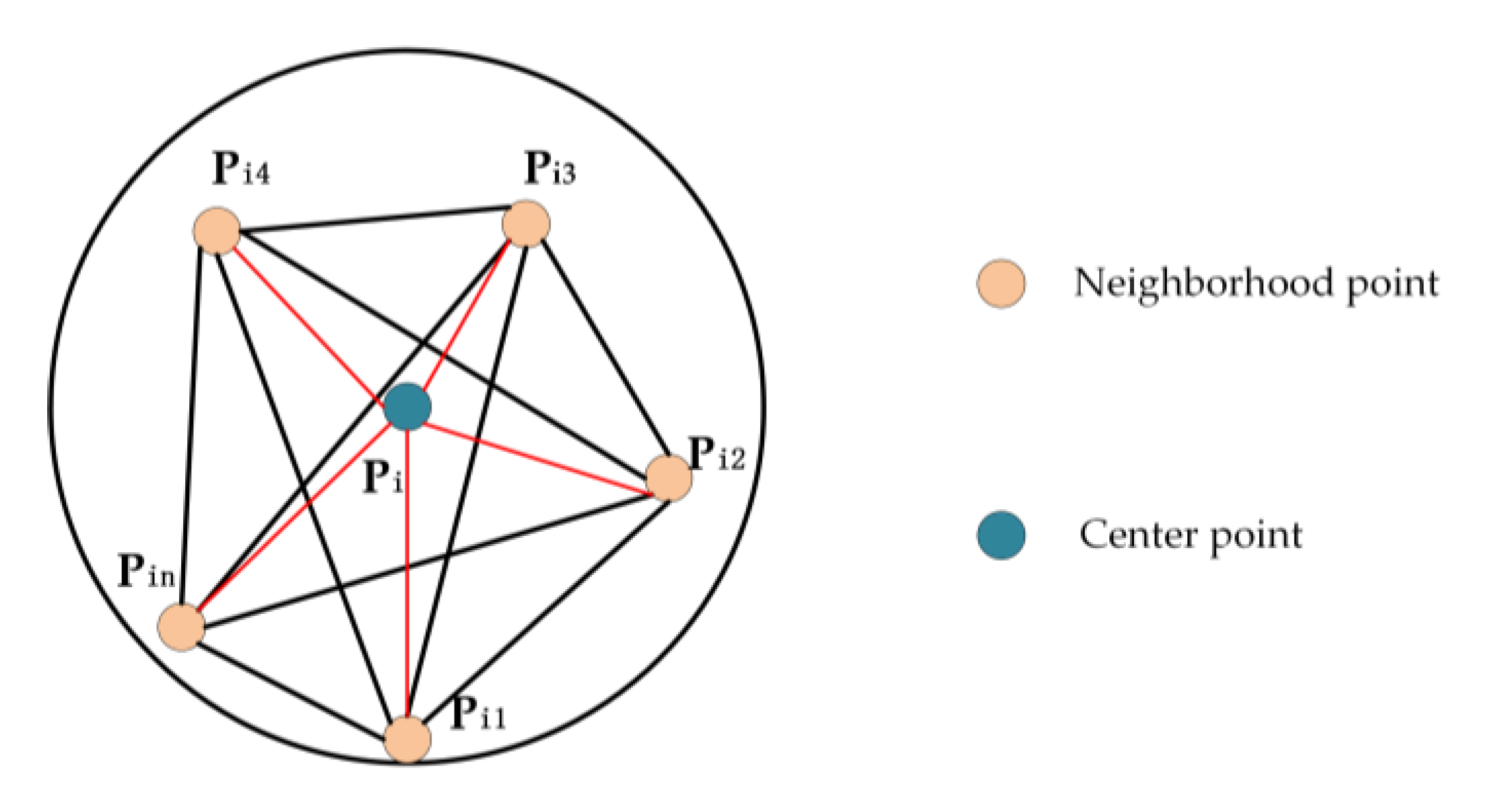
2.1.1. Local Fully Connected Graph Spatial-Encoding Module
2.1.2. Attentive Pooling
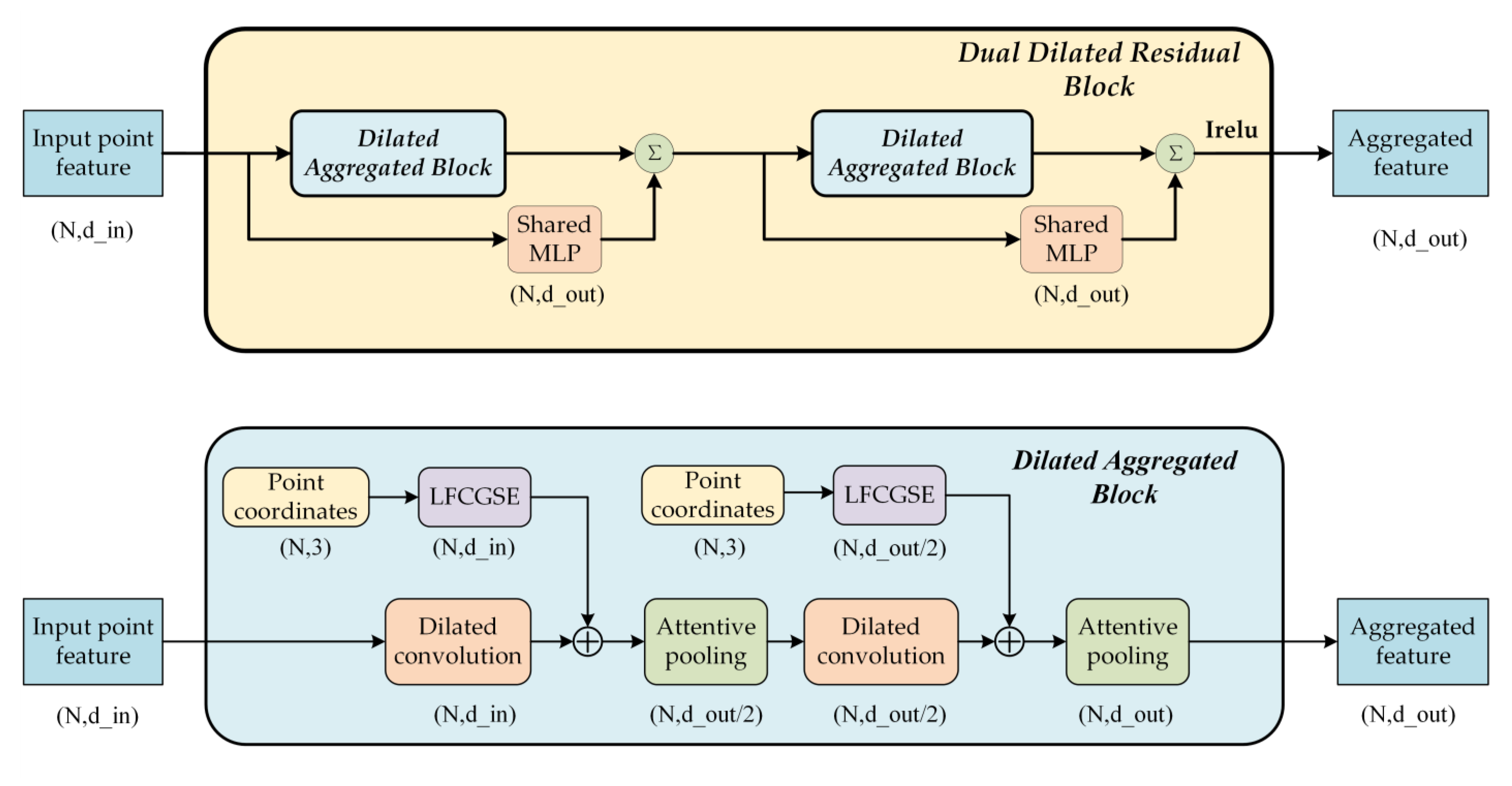
2.1.3. Dual Dilated Residual Aggregation Module
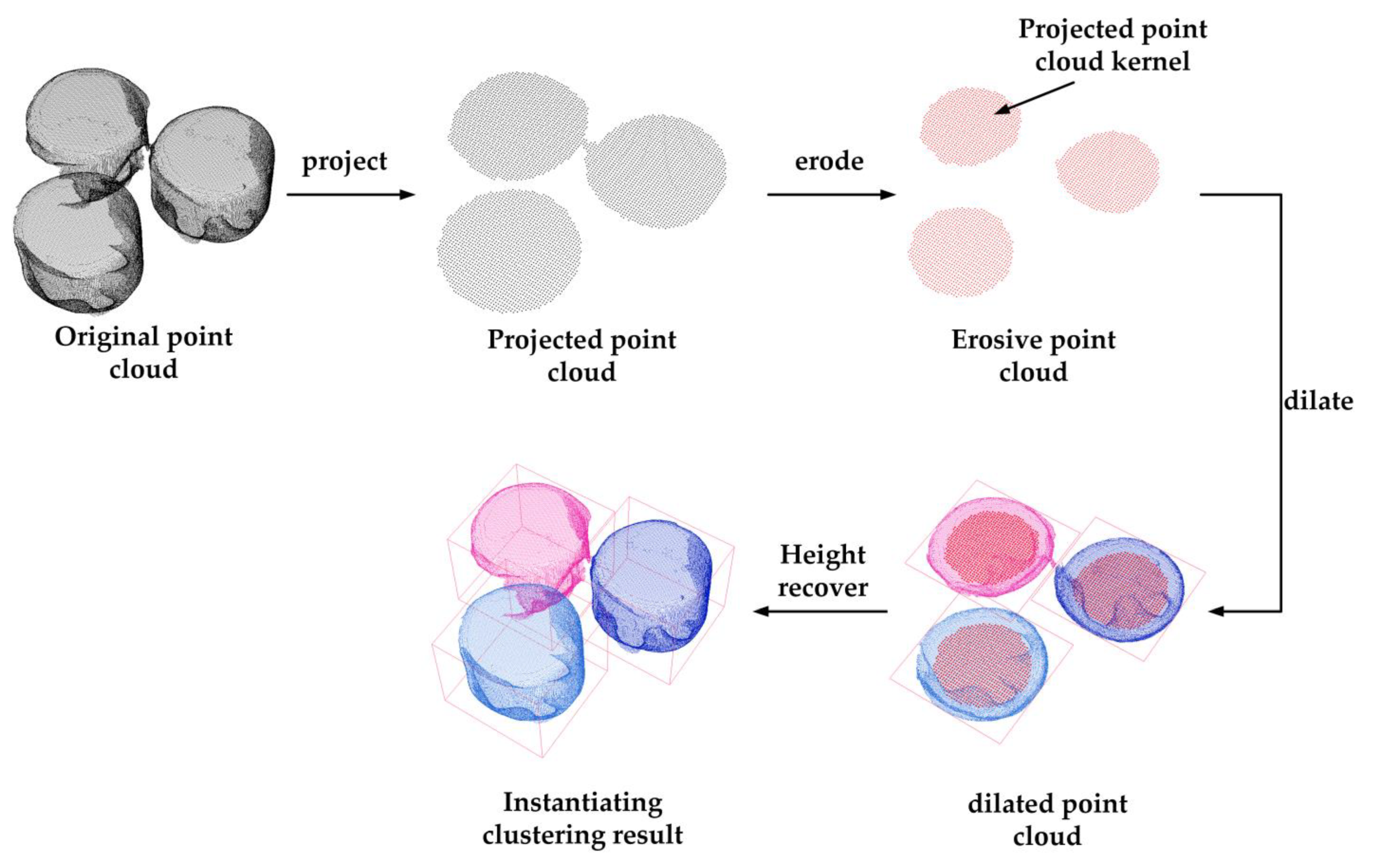
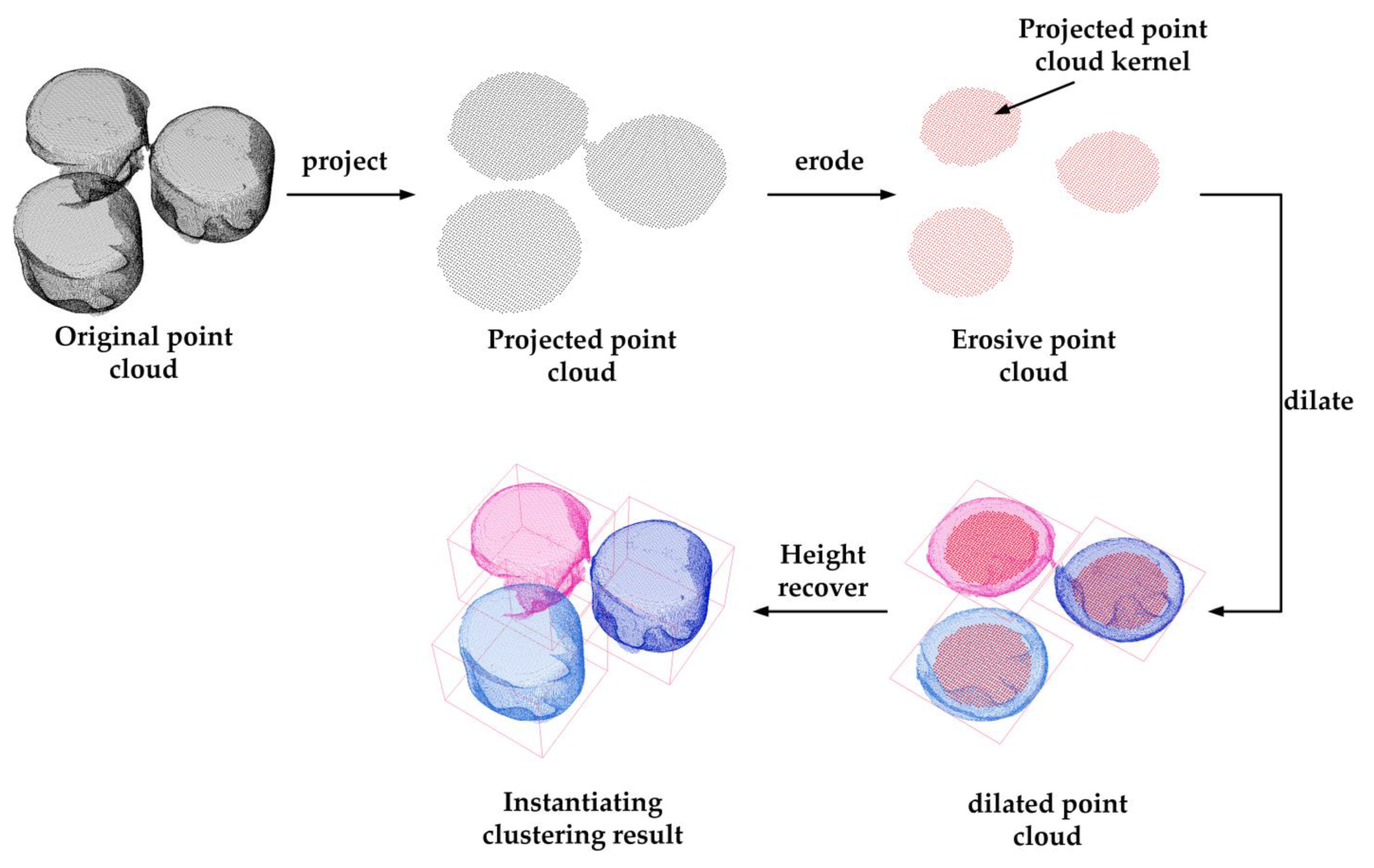
2.2. Instantiating Clustering
- (1)
- Point-cloud projection. The point cloud Pl with the semantic label l is projected onto a 2D plane to obtain the original projection point cloud Pl2D, after which grid sampling is performed to obtain the sampled 2D point cloud Ql.
- (2)
- Point-cloud erosion. To remove the adhesive areas between two point clusters, the erosion operation is performed on the sampled point cloud. The points that do not have enough number of points in neighborhoods are removed.
- (3)
- Euclidean clustering. Based on the corrosion on point clouds, the Euclidean clustering is used to obtain instantiate point sets Qlkernel = {Ql1, Ql2, Ql3, ...}, which is called projected point cloud kernel.
- (4)
- Point-cloud dilation. The Qlkernel is used as query point set, a dilation is performed on the original projected point cloud Pl2D to obtain the instantiating point set Pli = {Pl1, Pl2, Pl3, ...} (the indices of Pl2D are the same as those of Pl).
- (5)
- Height recovery. The point-cloud height value is assigned from Pl to {Pl1, Pl2, Pl3, ...}, according to the indices.
2.3. Reconstruction of Unstructured Objects
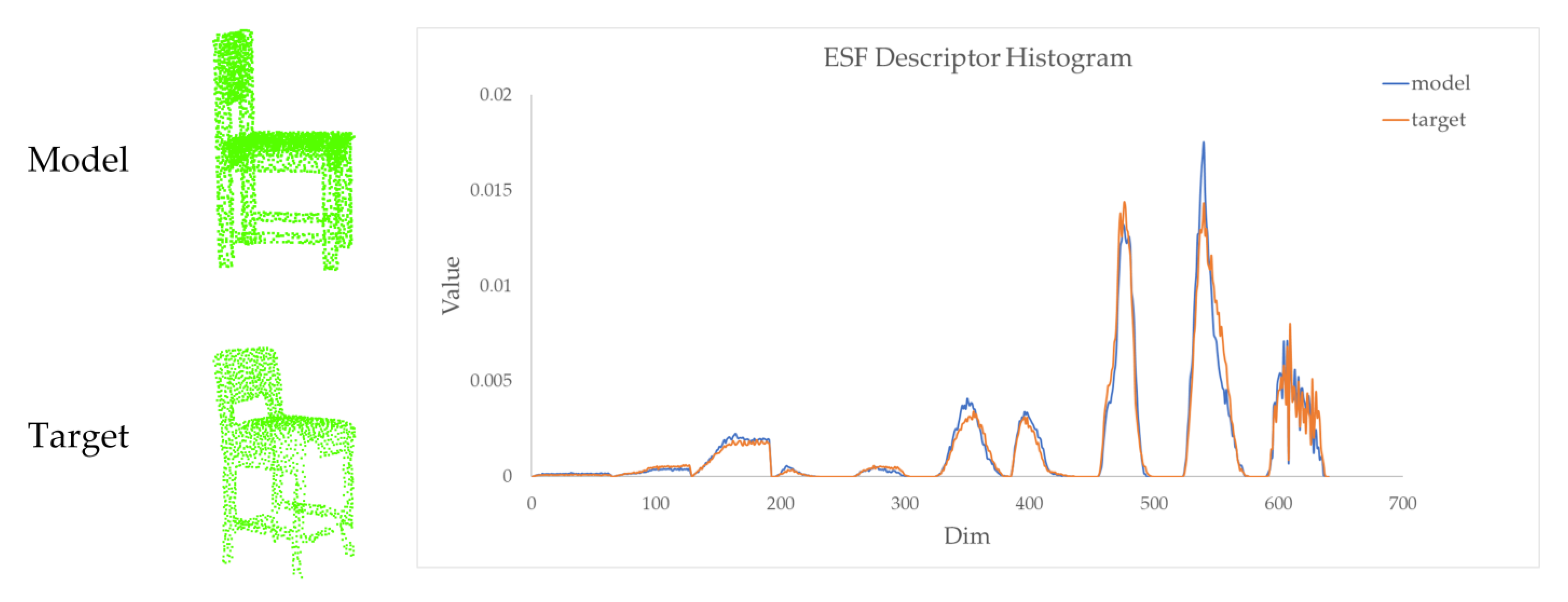
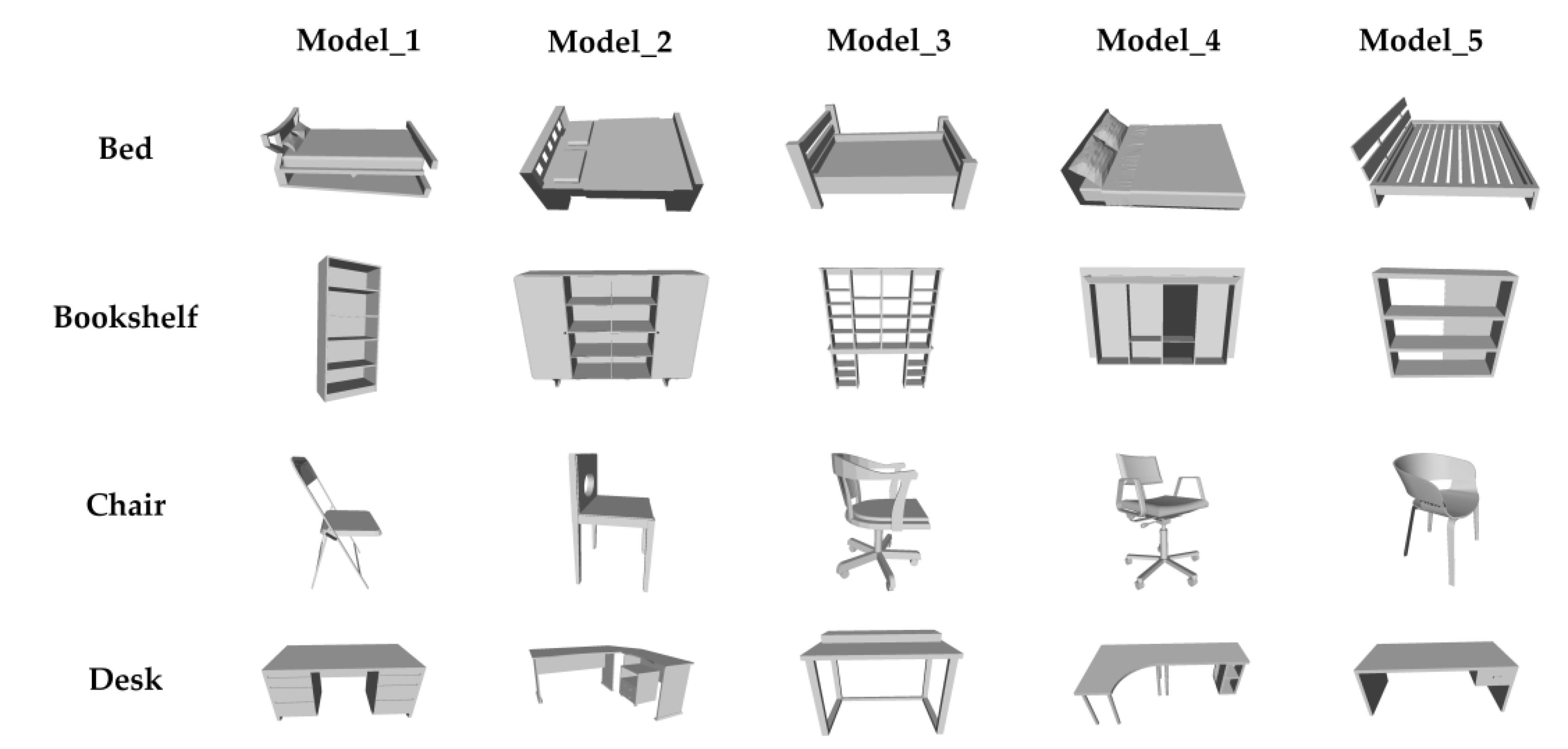
2.3.1. 3D-ESF Indoor Model Library
- (1)
- 3D template model set
- (2)
- ESF descriptor index
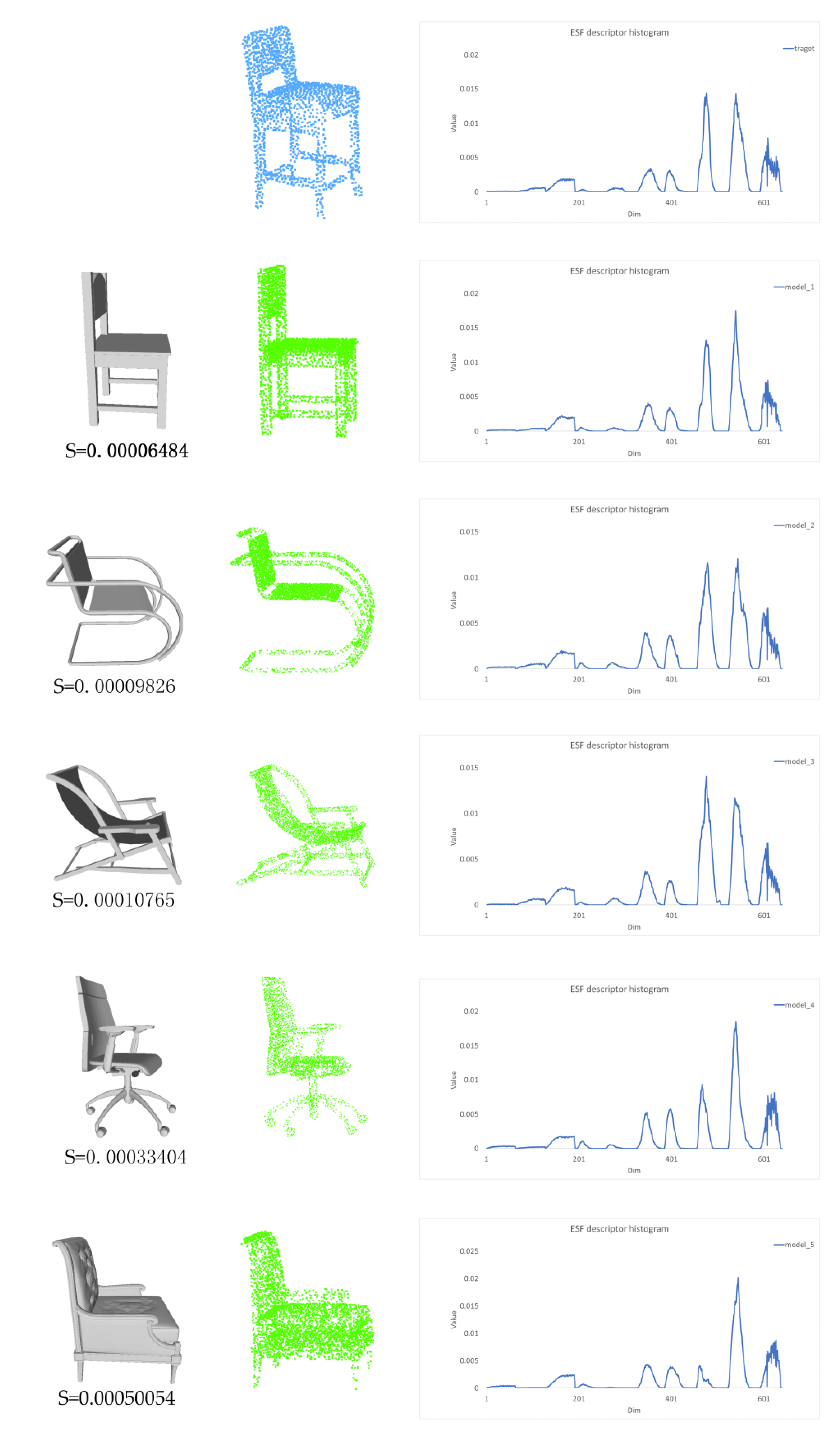
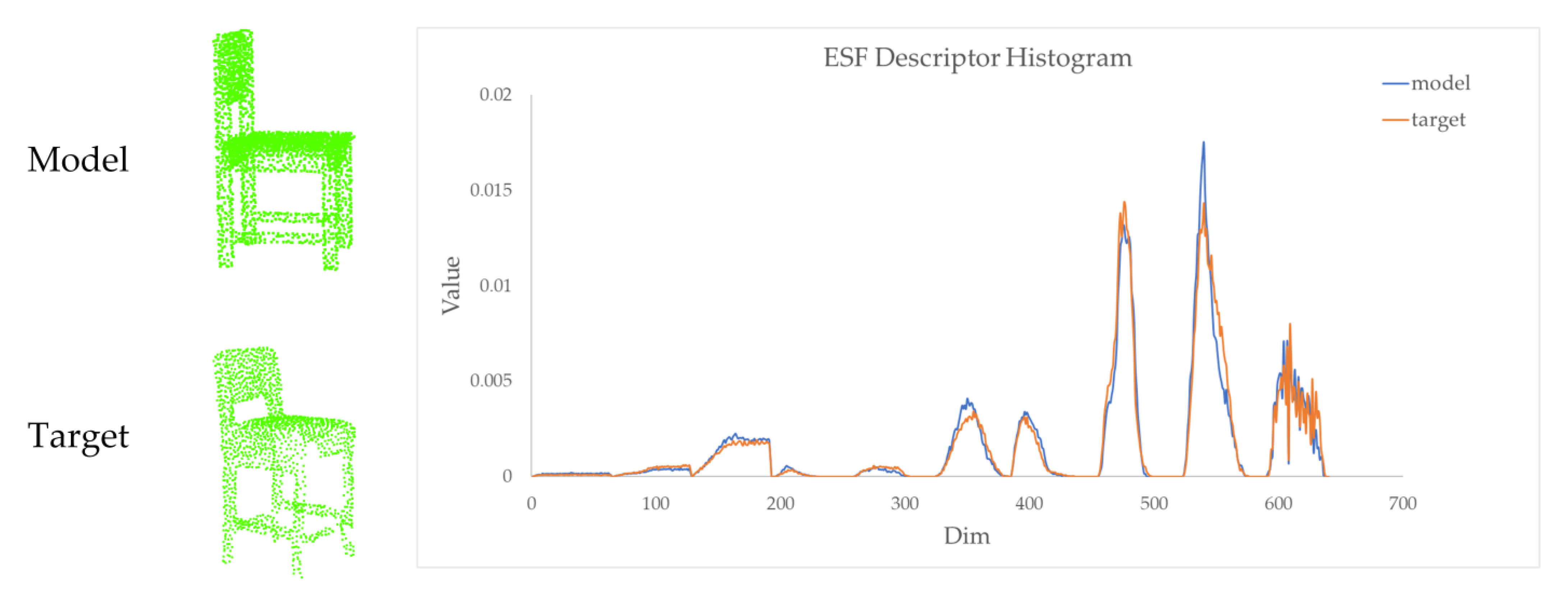
2.3.2. Model Retrieval
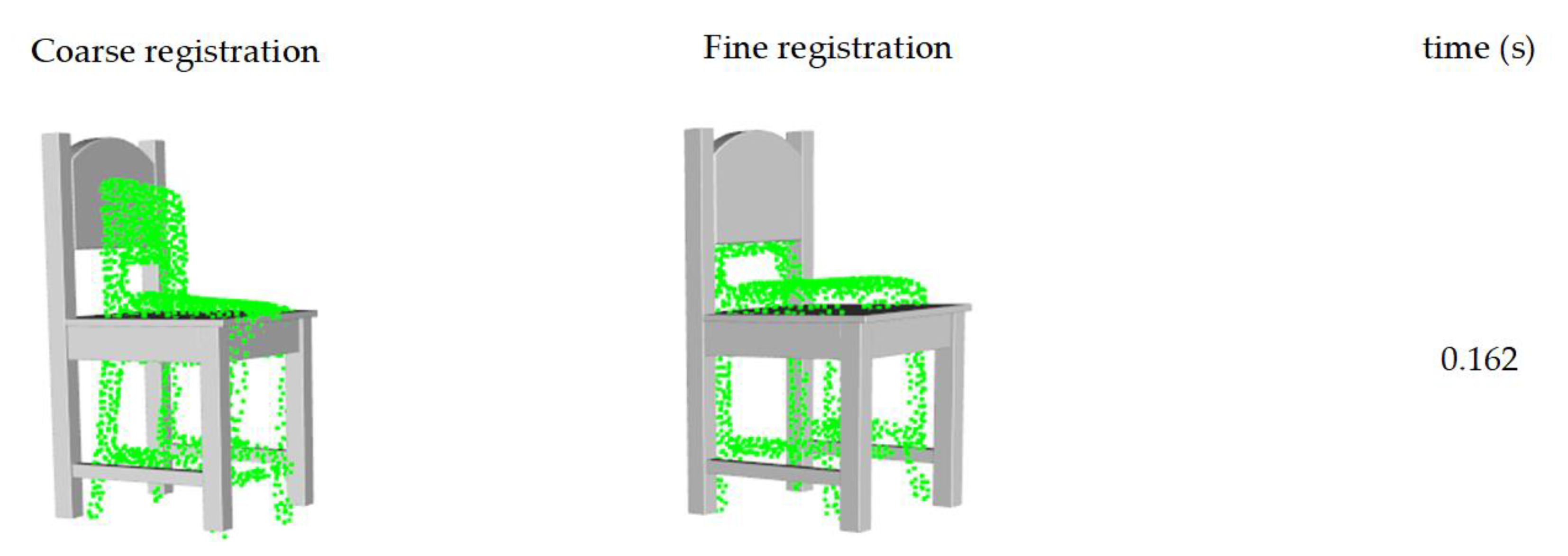
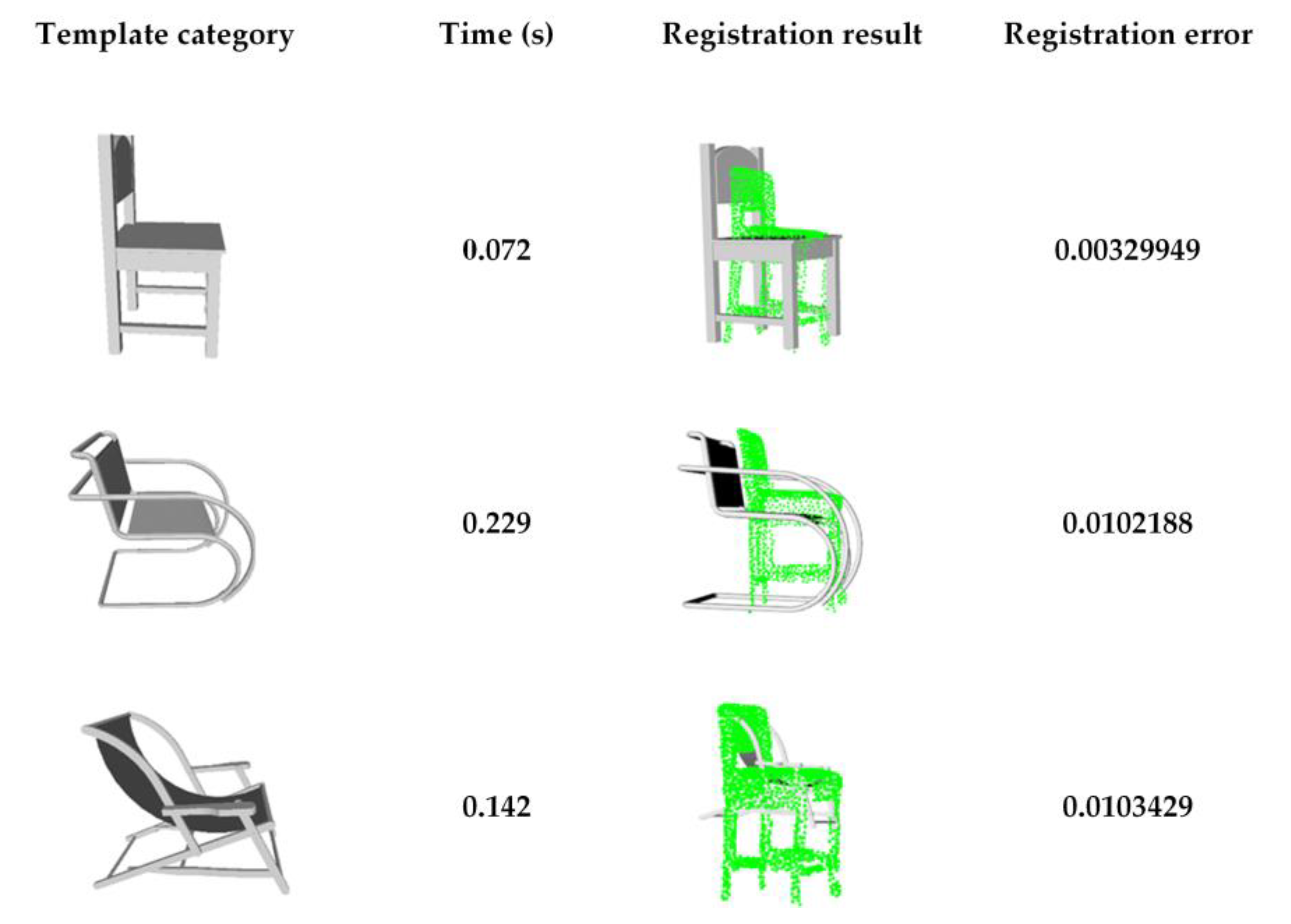
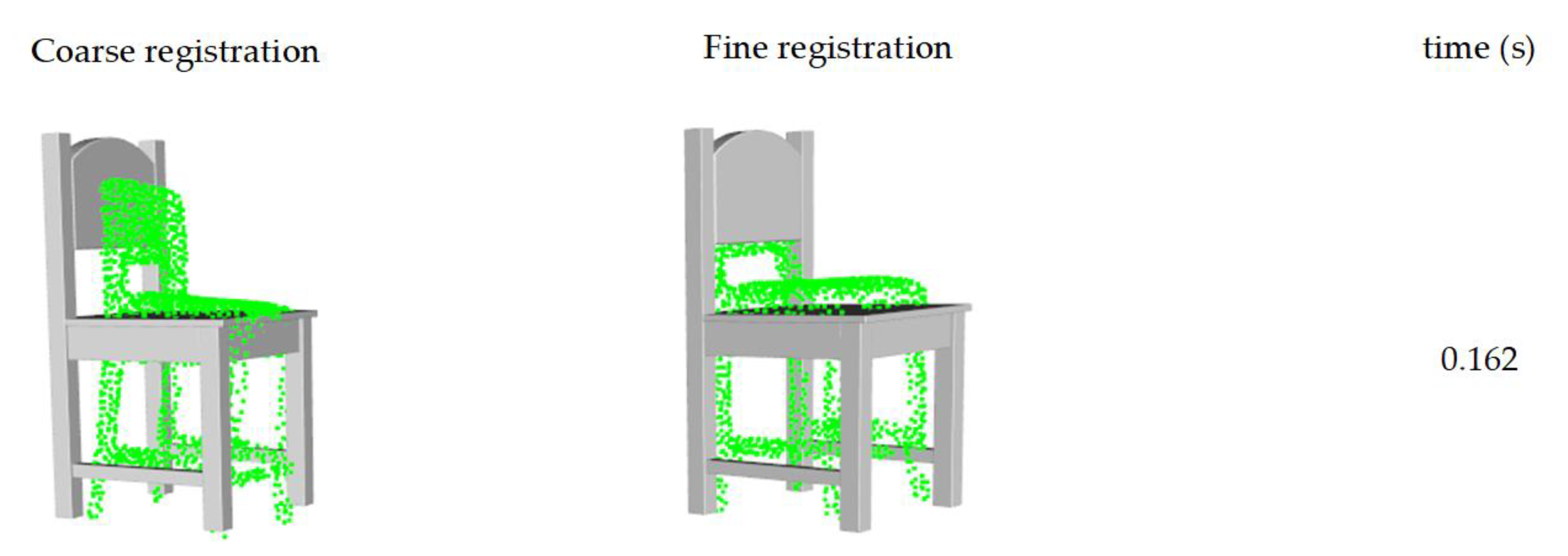
2.3.3. Coarse-to-Fine Registration
- (1)
- Projection-based coarse registration
- (2)
- Scale adjustment. To adjust the scale of the template model to that of the target point cloud, we calculate the size ratios of their bounding boxes in the x,y,z direction. Considering the incomplete point cloud may cause the bounding box of the target point cloud to be shrink in a certain direction, the highest ratio in the x,y,z direction is selected as the scaling factor.
- (3)
- Coarse registration. Based on the priors, the furniture is generally vertical and aligned with the floor. Hence, we project both the target point cloud and the template point cloud on the xoy plane. Next, ISS key point [33] detection is performed, which can improve the computational efficiency while maintaining the original features. Base on the ISS key points, the FPFH (Fast Point Feature Histograms) registration [34] is performed. In addition, the one with the lowest registration error among the candidates is selected.
- (4)
- Model-to-scene fine registration
2.4. Structured-Object Reconstruction
3. Results
3.1. Point-Cloud Semantic-Segmentation Experiment
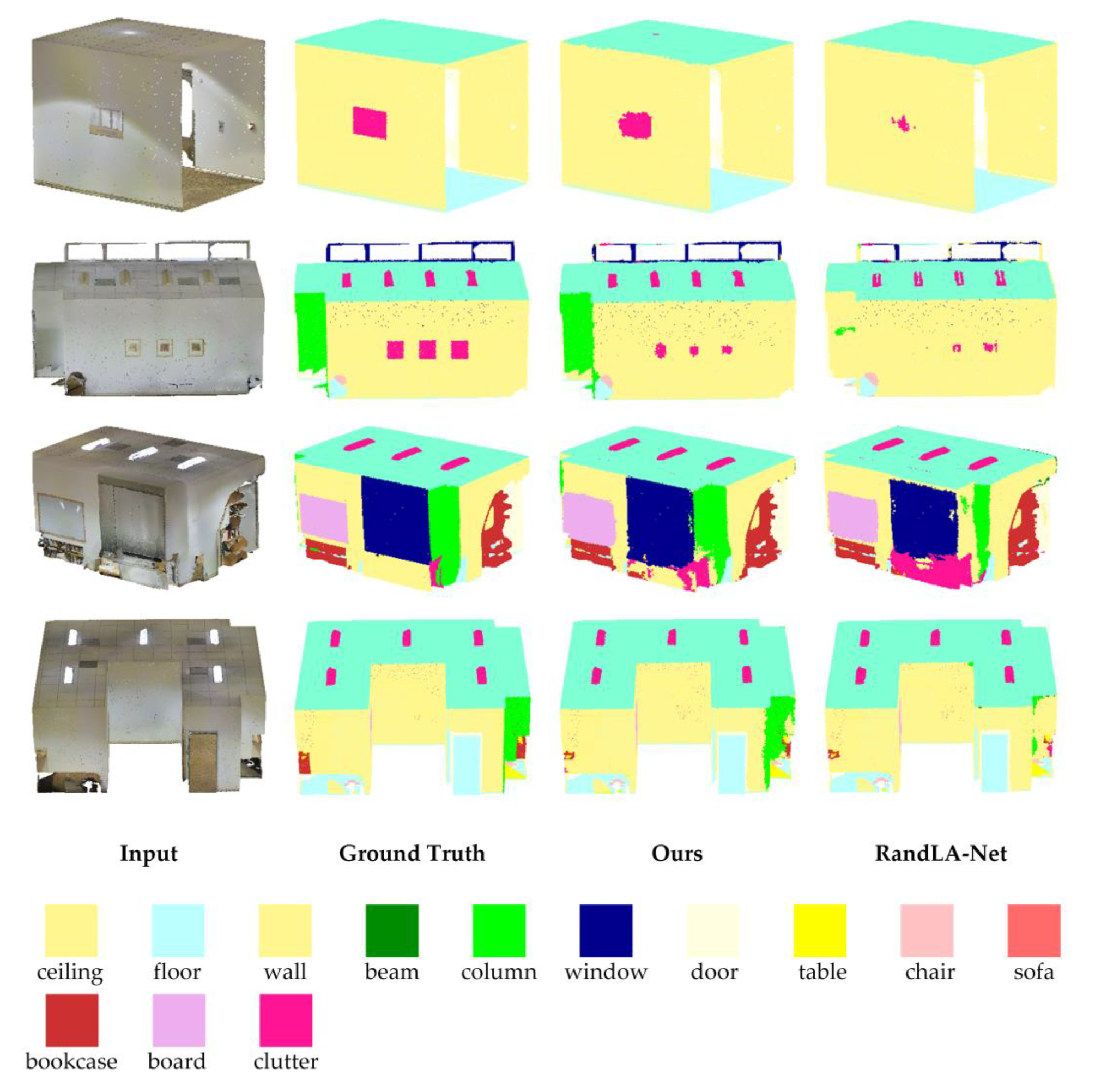
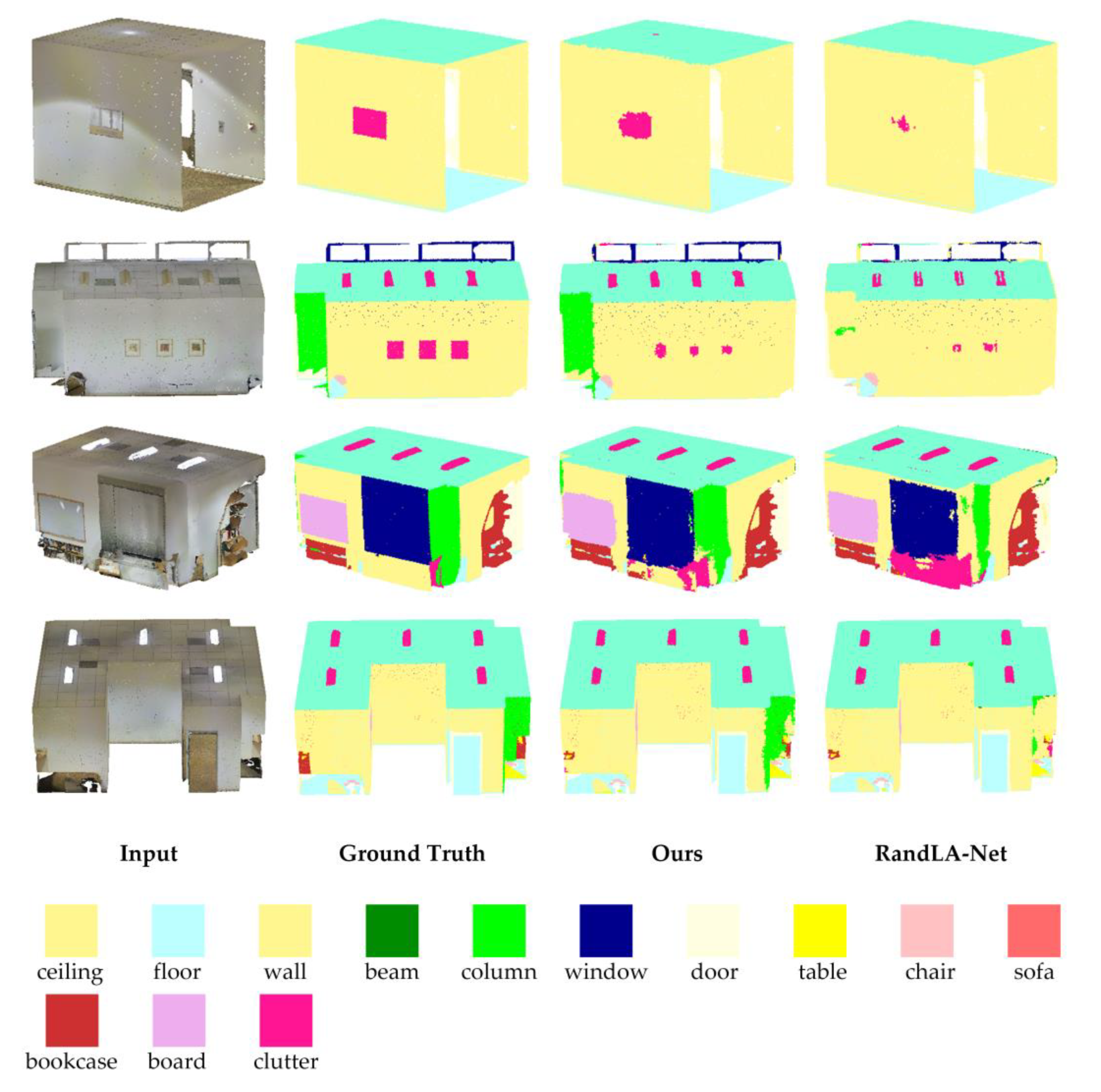
3.1.1. The Semantic Segmentation on S3DIS
3.1.2. Semantic Segmentation on ScanNet
3.1.3. Ablation Experiment
- (1)
- (2)
- The dual dilated residual block (DDRB) is replaced with the dilated residual block (DRB) in RandLA-Net [26].
- (3)
- The local fully connected graph spatial-encoding module (LFCGSE) is replaced with the local spatial-encoding module (LocSE) in RandLA-Net [26].
- (4)
- The local fully connected graph spatial-encoding module (LFCGSE) and the dual dilated residual block (DDRB) are used.
3.2. Semantic Reconstruction Experimentation
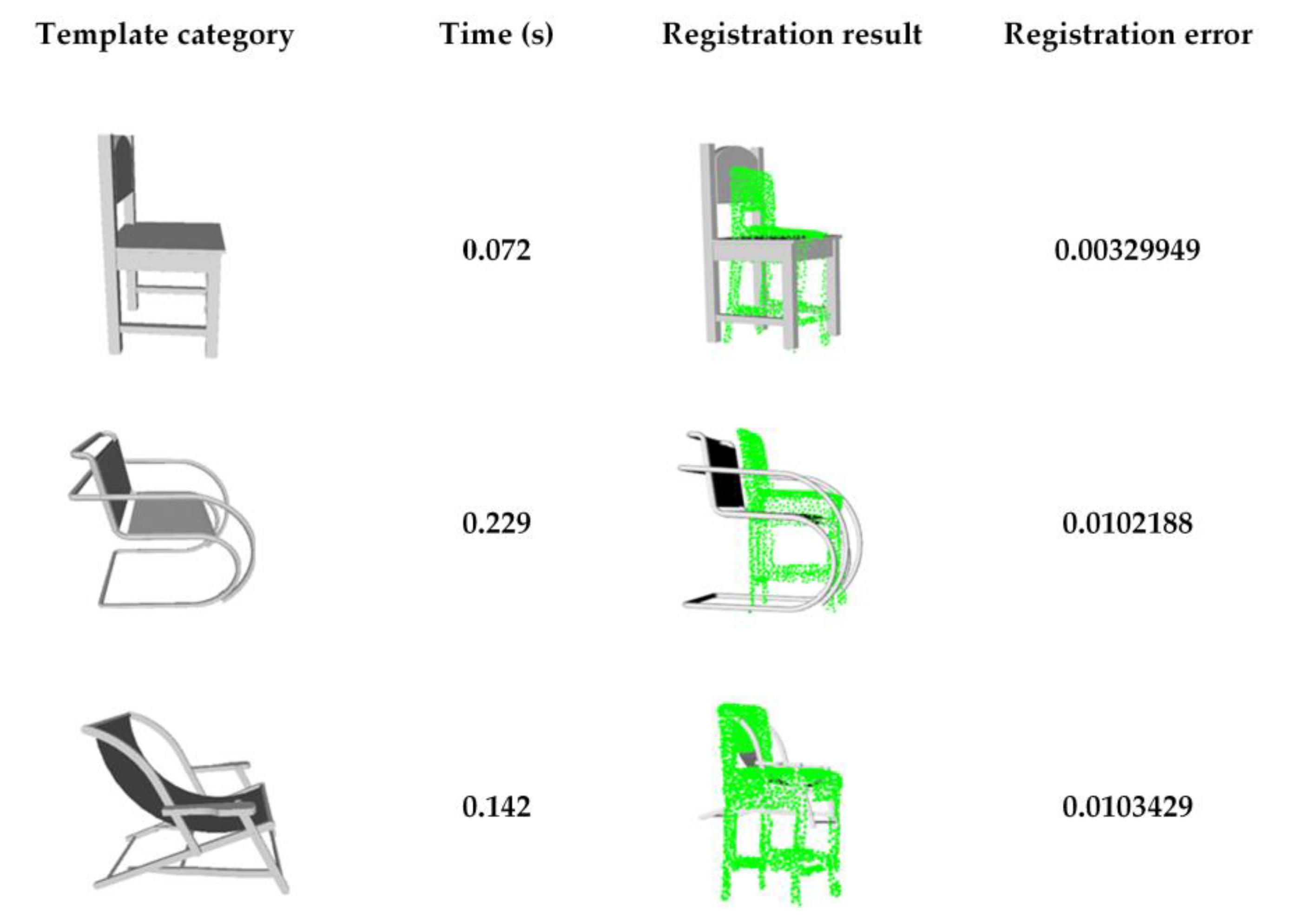
3.2.1. Unstructured-Object Reconstruction
3.2.2. Comparison of Related Methods
- (1)
- SAC-IA (Sample Consensus Initial Aligment) without semantics. Performance of the SAC-IA registration;
- (2)
- SAC-IA with semantics. Performance of the SAC-IA registration on the point cloud with the same semantic label;
- (3)
- ISS+FPFH with semantics (ours).
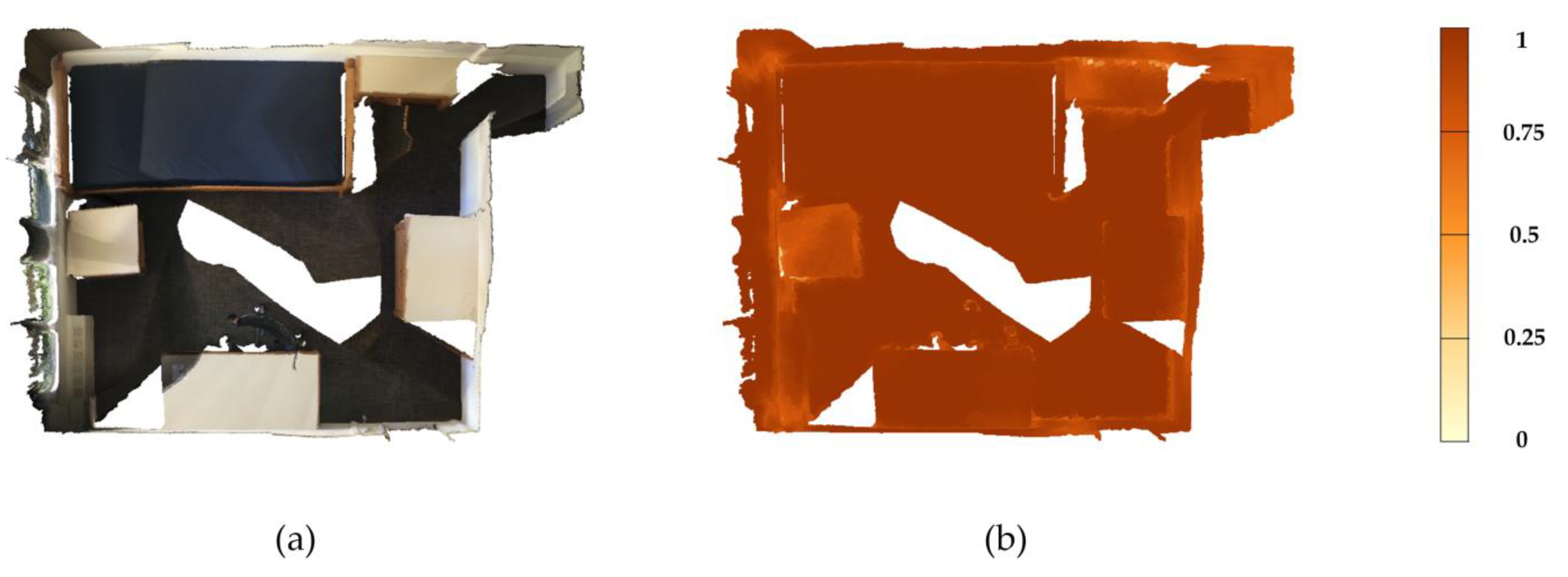
3.3. Overall Reconstruction
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinect Fusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 559–568. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.; McDonald, J. Kintinuous: Spatially Extended KinectFusion. CSAIL Tech. Rep. 2012. Available online: https://dspace.mit.edu/handle/1721.1/71756 (accessed on 6 October 2021).
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.; Glocker, B.; Davison, A. ElasticFusion: Dense SLAM without a pose graph. Robot. Sci. Syst. 2015. [Google Scholar] [CrossRef]
- Jung, J.; Hong, S.; Jeong, S.; Kim, S.; Cho, H.; Hong, S.; Heo, J. Productive modeling for development of as-built BIM of existing indoor structures. Autom. Constr. 2014, 42, 68–77. [Google Scholar] [CrossRef]
- Wang, C.; Cho, Y.K.; Kim, C. Automatic BIM component extraction from point clouds of existing buildings for sustainability applications. Autom. Constr. 2015, 56, 1–13. [Google Scholar] [CrossRef]
- Kang, Z.; Zhong, R.; Wu, A.; Shi, Z.; Luo, Z. An Efficient Planar Feature Fitting Method Using Point Cloud Simplification and Threshold-Independent BaySAC. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1842–1846. [Google Scholar] [CrossRef]
- Poux, F.; Neuville, R.; Nys, G.-A.; Billen, R. 3D Point Cloud Semantic Modelling: Integrated Framework for Indoor Spaces and Furniture. Remote Sens. 2018, 10, 1412. [Google Scholar] [CrossRef]
- Nan, L.; Xie, K.; Sharf, A. A search-classify approach for cluttered indoor scene understanding. ACM Trans. Graph. 2012, 31, 1–137. [Google Scholar] [CrossRef]
- Xu, K.; Li, H.; Zhang, H.; Cohen-Or, D.; Xiong, Y.; Cheng, Z.-Q. Style-content separation by anisotropic part scales. In Proceedings of the ACM SIGGRAPH Asia 2010 Papers; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Zheng, Y.; Weng, Q. Model-Driven Reconstruction of 3-D Buildings Using LiDAR Data. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1541–1545. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.-G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images; Computer Vision Foundation: New York, NY, USA, 2018; pp. 52–67. Available online: https://openaccess.thecvf.com/content_ECCV_2018/html/Nanyang_Wang_Pixel2Mesh_Generating_3D_ECCV_2018_paper.html (accessed on 6 October 2021).
- Gkioxari, G.; Malik, J.; Johnson, J. Mesh R-CNN; Computer Vision Foundation: New York, NY, USA, 2019; pp. 9785–9795. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Gkioxari_Mesh_R-CNN_ICCV_2019_paper.html (accessed on 27 October 2021).
- Wen, C.; Zhang, Y.; Li, Z.; Fu, Y. Pixel2Mesh++: Multi-View 3D Mesh Generation via Deformation; Computer Vision Foundation: New York, NY, USA, 2019; pp. 1042–1051. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Wen_Pixel2Mesh_Multi-View_3D_Mesh_Generation_via_Deformation_ICCV_2019_paper.html (accessed on 5 October 2021).
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation; Computer Vision Foundation: New York, NY, USA, 2019; pp. 165–174. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Park_DeepSDF_Learning_Continuous_Signed_Distance_Functions_for_Shape_Representation_CVPR_2019_paper.html (accessed on 13 September 2021).
- Huang, J.; You, S. Point cloud labeling using 3D Convolutional Neural Network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation; Computer Vision Foundation: New York, NY, USA, 2017; pp. 652–660. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Qi_PointNet_Deep_Learning_CVPR_2017_paper.html (accessed on 9 July 2021).
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/hash/d8bf84be3800d12f74d8b05e9b89836f-Abstract.html (accessed on 1 July 2021).
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, Available online: https://proceedings.neurips.cc/paper/2018/hash/f5f8590cd58a54e94377e6ae2eded4d9-Abstract.html (accessed on 6 October 2021).
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation With Superpoint Graphs; Computer Vision Foundation: New York, NY, USA, 2018; pp. 4558–4567. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Landrieu_Large-Scale_Point_Cloud_CVPR_2018_paper.html (accessed on 3 January 2022).
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds; Computer Vision Foundation: New York, NY, USA, 2020; pp. 11108–11117. Available online: https://openaccess.thecvf.com/content_CVPR_2020/html/Hu_RandLA-Net_Efficient_Semantic_Segmentation_of_Large-Scale_Point_Clouds_CVPR_2020_paper.html (accessed on 6 January 2022).
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3D object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Phuket, Thailand, 7–11 December 2010; pp. 2987–2992. [Google Scholar] [CrossRef]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds; Computer Vision Foundation: New York, NY, USA, 2019; pp. 9621–9630. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Wu_PointConv_Deep_Convolutional_Networks_on_3D_Point_Clouds_CVPR_2019_paper.html (accessed on 9 January 2022).
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-Shape Convolutional Neural Network for Point Cloud Analysis; Computer Vision Foundation: New York, NY, USA, 2019; pp. 8895–8904. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Liu_Relation-Shape_Convolutional_Neural_Network_for_Point_Cloud_Analysis_CVPR_2019_paper.html (accessed on 19 January 2022).
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar] [CrossRef]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. DeepGCNs: Can GCNs Go as Deep as CNNs? Computer Vision Foundation: New York, NY, USA, 2019; pp. 9267–9276. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Li_DeepGCNs_Can_GCNs_Go_As_Deep_As_CNNs_ICCV_2019_paper.html (accessed on 3 June 2022).
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes; Computer Vision Foundation: New York, NY, USA, 2015; pp. 1912–1920. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2015/html/Wu_3D_ShapeNets_A_2015_CVPR_paper.html (accessed on 8 June 2022).
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3D object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces; Computer Vision Foundation: New York, NY, USA, 2016; pp. 1534–1543. Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/Armeni_3D_Semantic_Parsing_CVPR_2016_paper.html (accessed on 17 June 2022).
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Niessner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes; Computer Vision Foundation: New York, NY, USA, 2017; pp. 5828–5839. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Dai_ScanNet_Richly-Annotated_3D_CVPR_2017_paper.html (accessed on 19 July 2022).
- Zhao, H.; Jiang, L.; Fu, C.-W.; Jia, J. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing; Computer Vision Foundation: New York, NY, USA, 2019; pp. 5565–5573. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Zhao_PointWeb_Enhancing_Local_Neighborhood_Features_for_Point_Cloud_Processing_CVPR_2019_paper.html (accessed on 9 June 2022).
- Choy, C.; Gwak, J.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks; Computer Vision Foundation: New York, NY, USA, 2019; pp. 3075–3084. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Choy_4D_Spatio-Temporal_ConvNets_Minkowski_Convolutional_Neural_Networks_CVPR_2019_paper.html (accessed on 8 February 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU | mAcc | OA | ceiling | floor | wall | beam | column | window | door | table | chair | sofa | bookcase | board | clutter |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [18] | 41.1 | 49.0 | - | 88.8 | 97.3 | 69.8 | 0.1 | 3.9 | 46.3 | 10.8 | 59.0 | 52.6 | 5.9 | 40.3 | 26.4 | 33.2 |
| PointCNN [21] | 57.3 | 63.9 | 85.9 | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 | 22.8 | 62.1 | 74.4 | 80.6 | 31.7 | 66.7 | 62.1 | 56.7 |
| SPGraph [25] | 58.0 | 66.5 | 86.4 | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 84.7 | 75.4 | 69.8 | 52.6 | 2.1 | 52.2 |
| PointWeb [37] | 60.3 | 66.6 | 87.0 | 92.0 | 98.5 | 79.4 | 0.0 | 21.1 | 59.7 | 34.8 | 76.3 | 88.3 | 46.9 | 69.3 | 64.9 | 52.5 |
| RandLA-Net [26] | 62.5 | 71.5 | 87.2 | 91.1 | 95.6 | 80.2 | 0.0 | 25.0 | 62.1 | 47.3 | 76.0 | 83.5 | 61.2 | 70.9 | 65.5 | 53.9 |
| MinkowskiNet [38] | 65.4 | 71.7 | - | 91.8 | 98.7 | 86.2 | 0.0 | 34.1 | 48.9 | 62.4 | 81.6 | 89.8 | 47.2 | 74.9 | 74.4 | 58.6 |
| Ours | 65.4 | 73.6 | 88.8 | 93.2 | 97.9 | 82.8 | 0.0 | 24.9 | 65.1 | 59.6 | 78.0 | 88.3 | 67.7 | 71.1 | 65.5 | 55.6 |
| Method | mIoU | wall | floor | chair | tabel | desk | bed | bookshelf | sofa | sink | bathtub | toilet | curtain | counter | door | window | Shower curtain | refrigerator | picture | cabinet | Other furniture |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pointnet++ [19] | 33.9 | 52.3 | 67.7 | 36.0 | 23.2 | 27.8 | 47.8 | 45.8 | 34.6 | 36.4 | 58.4 | 54.8 | 24.7 | 25.0 | 26.1 | 25.2 | 14.5 | 21.2 | 11.7 | 25.6 | 18.3 |
| RandLA-Net [26] | 61.9 | 70.7 | 95.5 | 80.4 | 65.2 | 61.0 | 85.1 | 76.7 | 74.8 | 61.8 | 81.7 | 76.4 | 58.0 | 58.6 | 38.6 | 43.7 | 63.5 | 47.1 | 27.8 | 29.9 | 41.5 |
| Ours | 64.1 | 73.2 | 95.4 | 83.0 | 66.1 | 60.8 | 86.1 | 76.8 | 77.8 | 64.3 | 80.7 | 77.4 | 58.9 | 56.2 | 45.4 | 44.2 | 71.5 | 51.8 | 28.8 | 35.7 | 46.7 |
| Operator | mIoU (%) |
|---|---|
| DRB and LocSE | 62.5 |
| DRB and LFCGSE | 64.3 |
| DDRB and LocSE | 64.4 |
| DDRB and LFCGSE | 65.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Wang, Q.; Ai, H.; Zhang, L. Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds. Remote Sens. 2022, 14, 4820. https://doi.org/10.3390/rs14194820
Wang T, Wang Q, Ai H, Zhang L. Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds. Remote Sensing. 2022; 14(19):4820. https://doi.org/10.3390/rs14194820
Chicago/Turabian StyleWang, Tengfei, Qingdong Wang, Haibin Ai, and Li Zhang. 2022. "Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds" Remote Sensing 14, no. 19: 4820. https://doi.org/10.3390/rs14194820
APA StyleWang, T., Wang, Q., Ai, H., & Zhang, L. (2022). Semantics-and-Primitives-Guided Indoor 3D Reconstruction from Point Clouds. Remote Sensing, 14(19), 4820. https://doi.org/10.3390/rs14194820