



Robust Cuboid Modeling from Noisy and Incomplete 3D Point Clouds Using Gaussian Mixture Model

Abstract
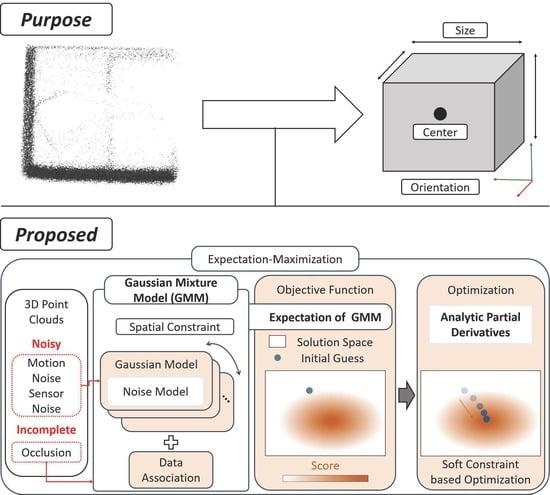
1. Introduction
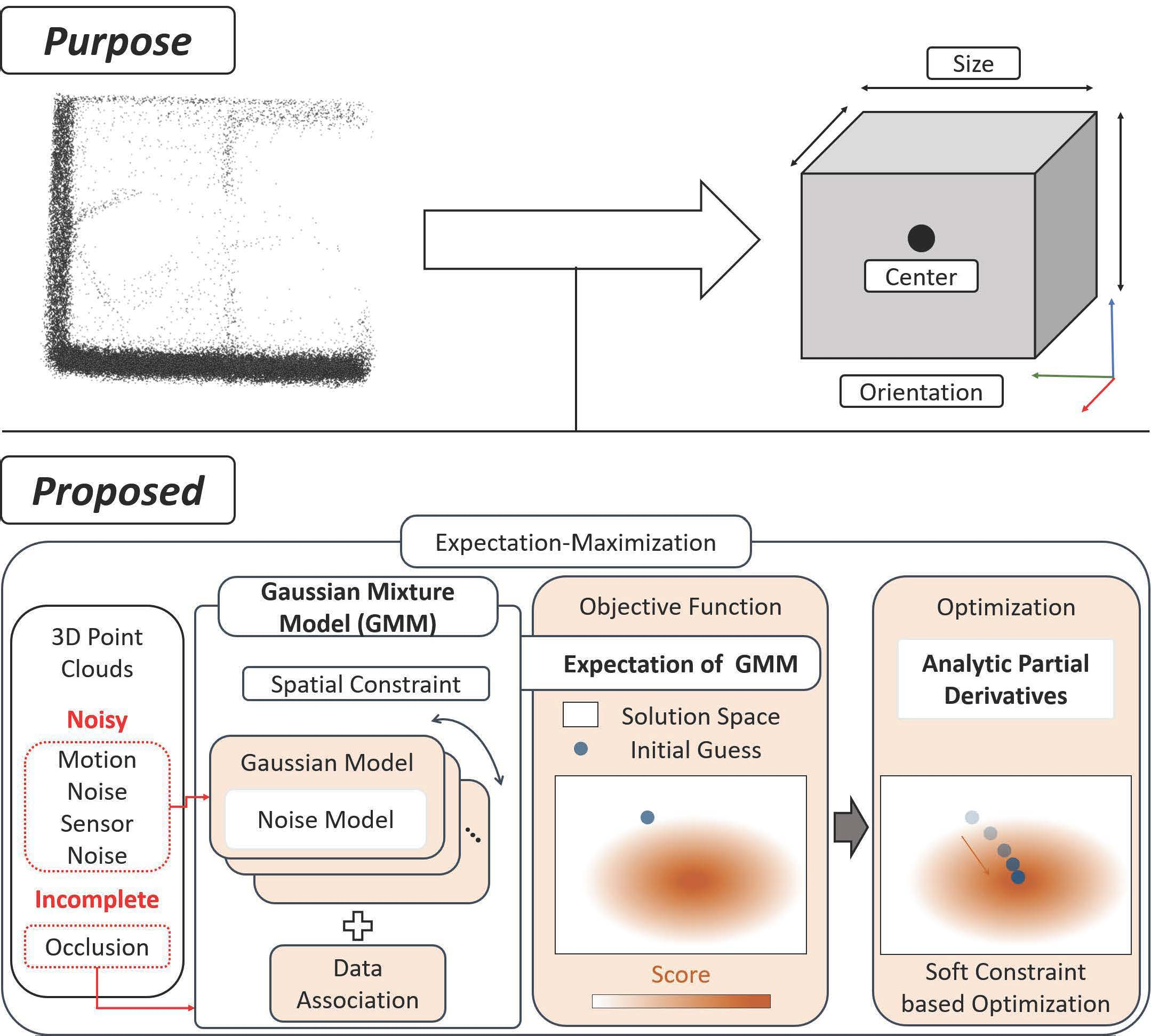
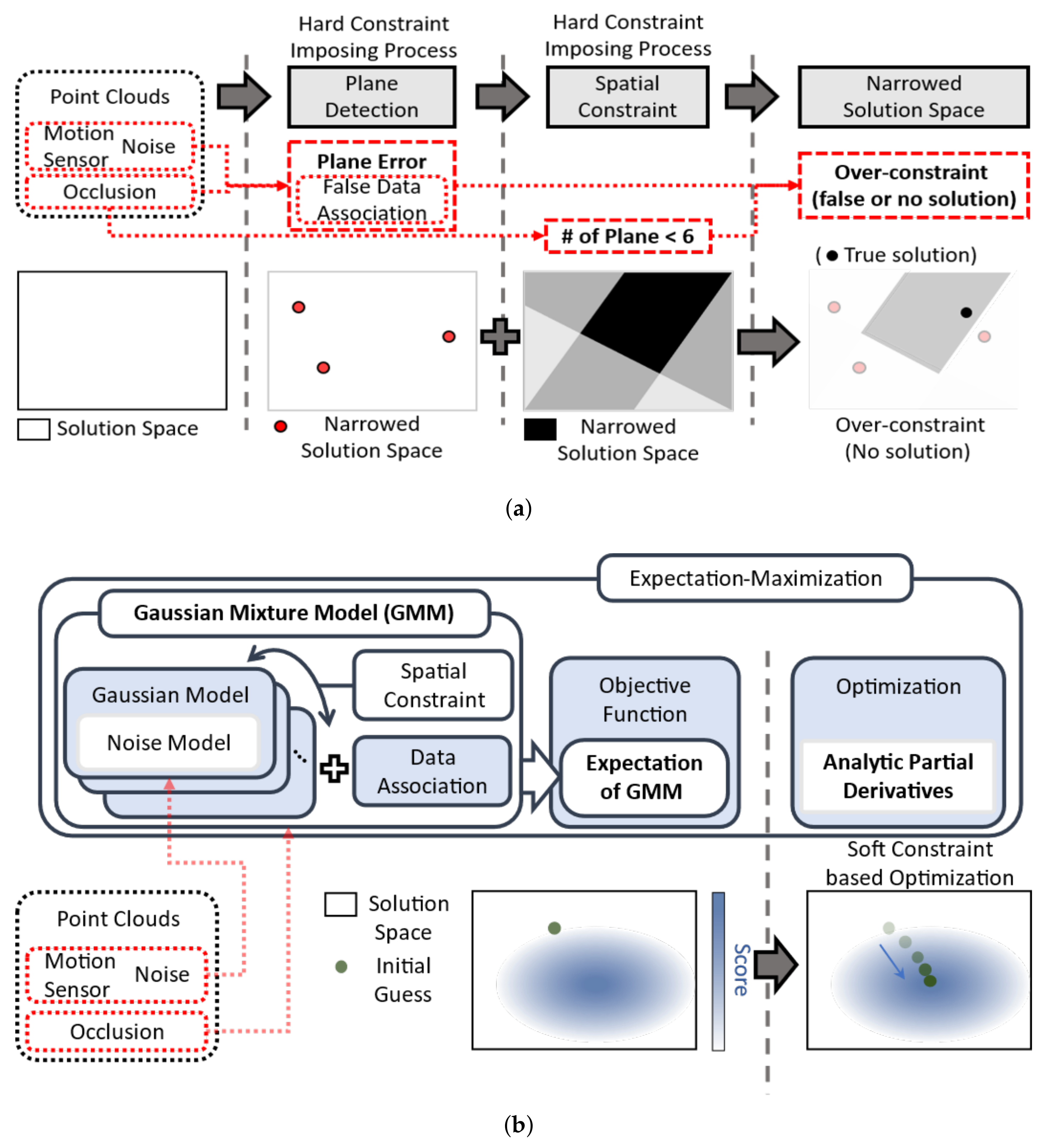
- We introduced a GMM to estimate a cuboid model directly from point clouds to ensure model robustness against noise and occlusion by simultaneously considering noise, spatial constraints, and data association.
- We derived analytic partial derivatives of the expected values of GMM with respect to cuboid parameters to achieve effective optimization.
- We verified and evaluated the advantages of the proposed approach over a previous cuboid modeling method by conducting extensive experiments using synthetic and real data.
2. Matetials and Methods
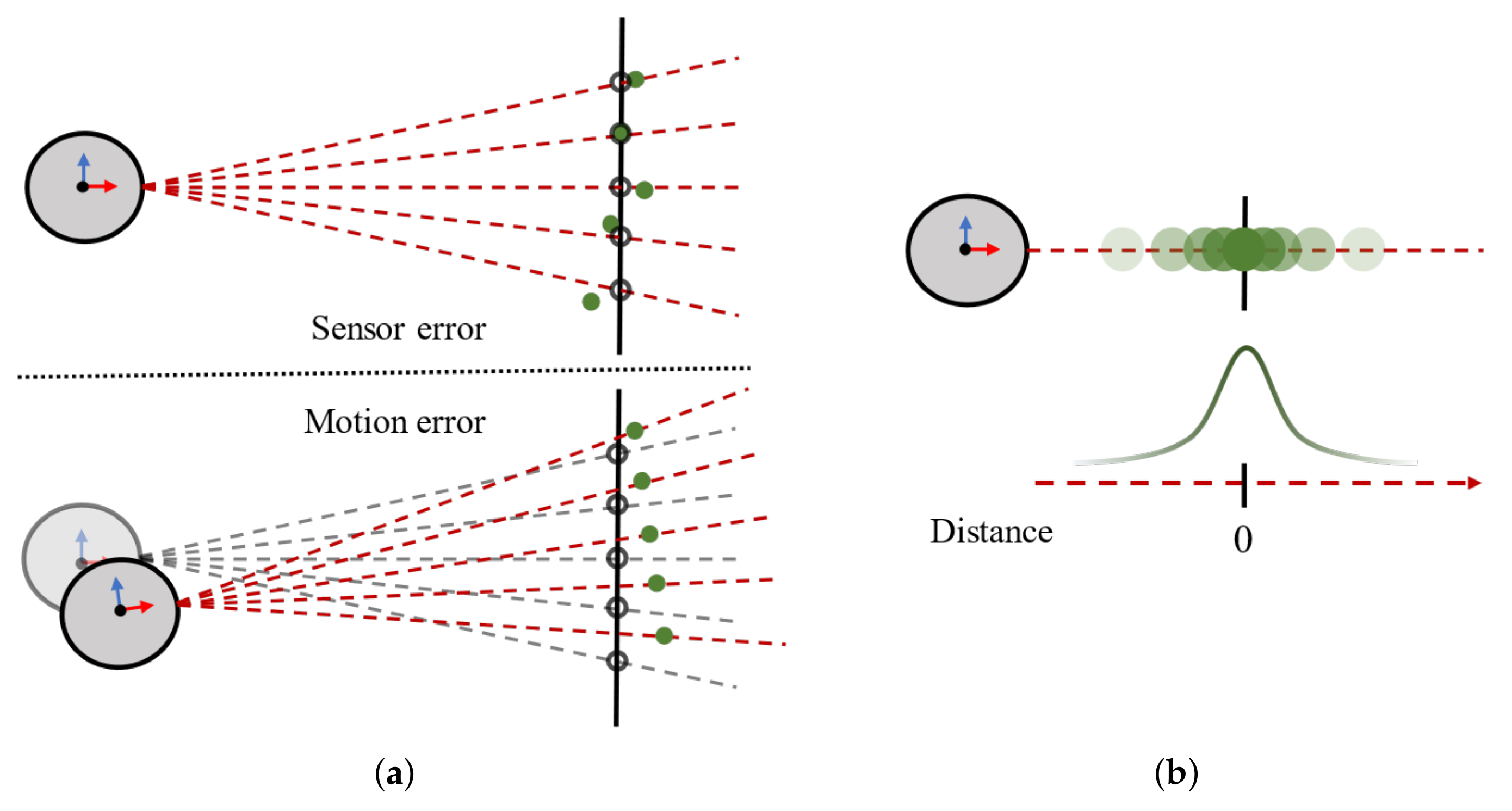
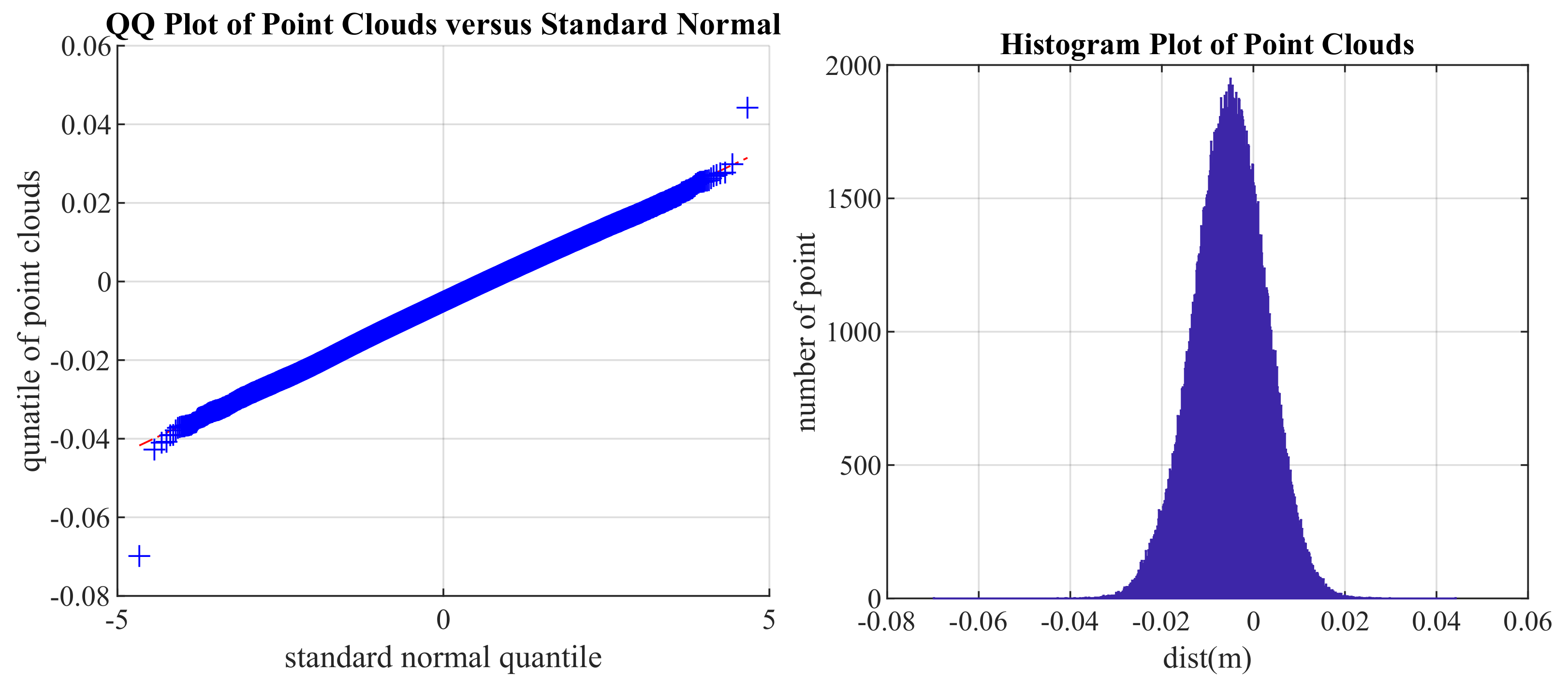
2.1. Gaussian Assumption of Point Distribution
2.2. Cuboid as GMM
- Latent variables ():(Probability that a point is generated from the j-th Gaussian model.)
- Size of a cuboid (width, depth, and height):
- Center of a cuboid:
- Euler angle of a cuboid orientation:
- X, Y, Z axes of the cuboid coordinate system:
- N Observations (Points):
- Parameters (K): ()
2.3. Expectation of GMM
2.4. Optimization
2.4.1. Gradient Ascending
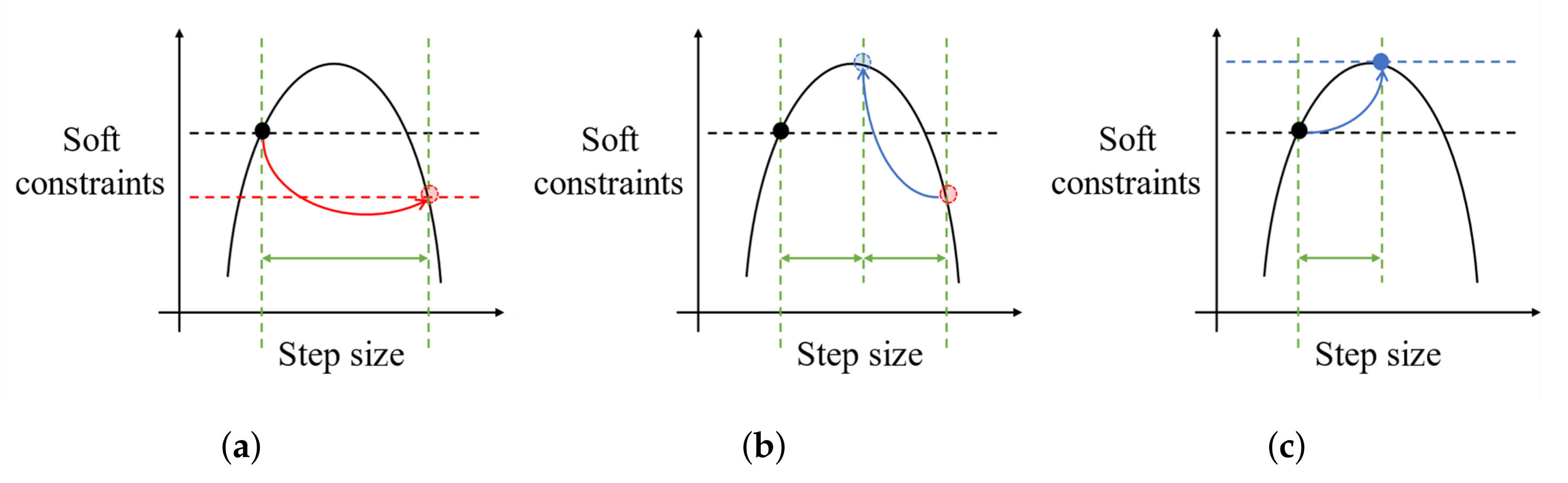
2.4.2. Backtracking Line Search
2.5. Implementation Details
| Algorithm 1: Cuboid Modeling |
 |
3. Results
3.1. Comparison Implementation
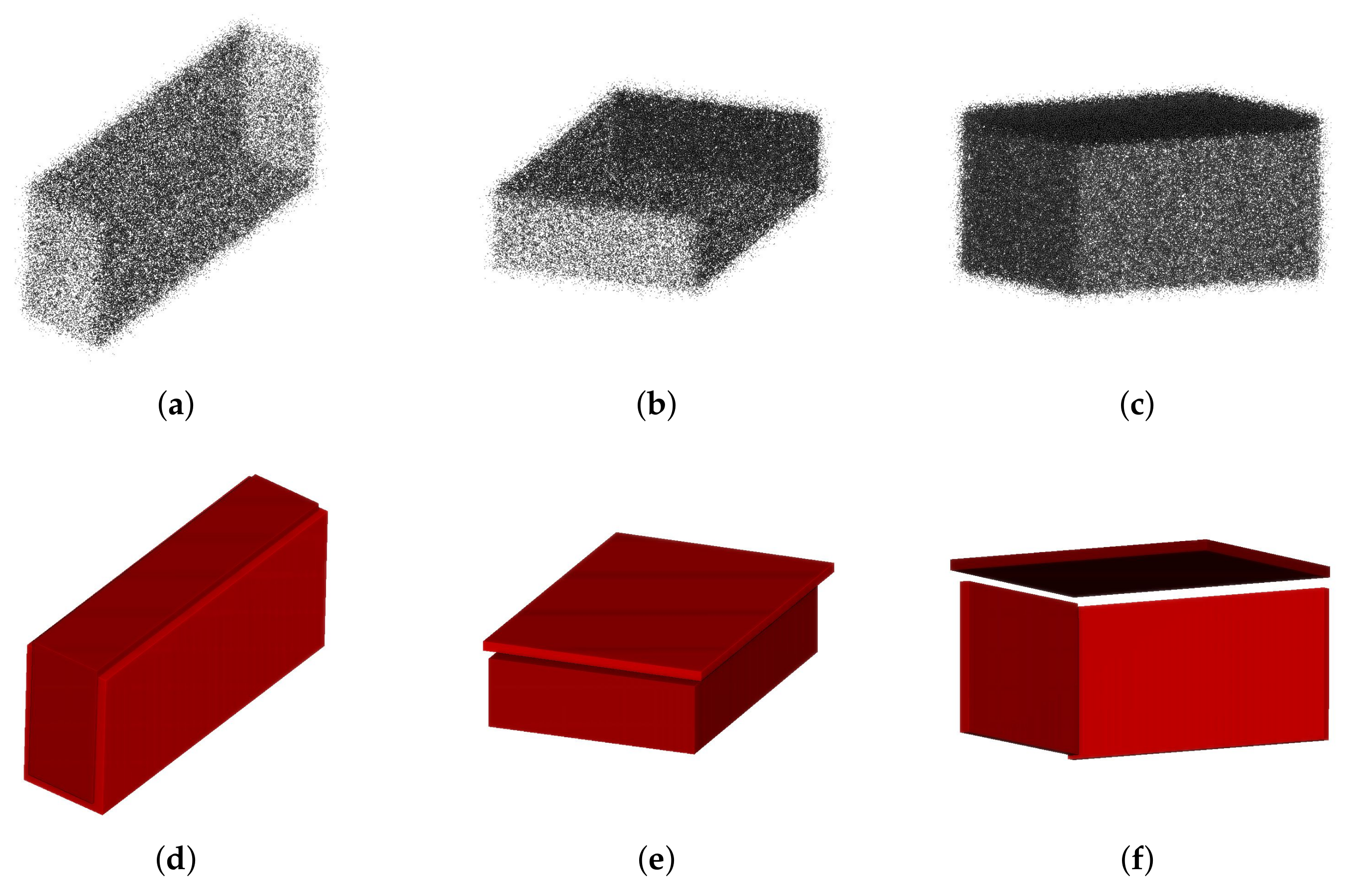
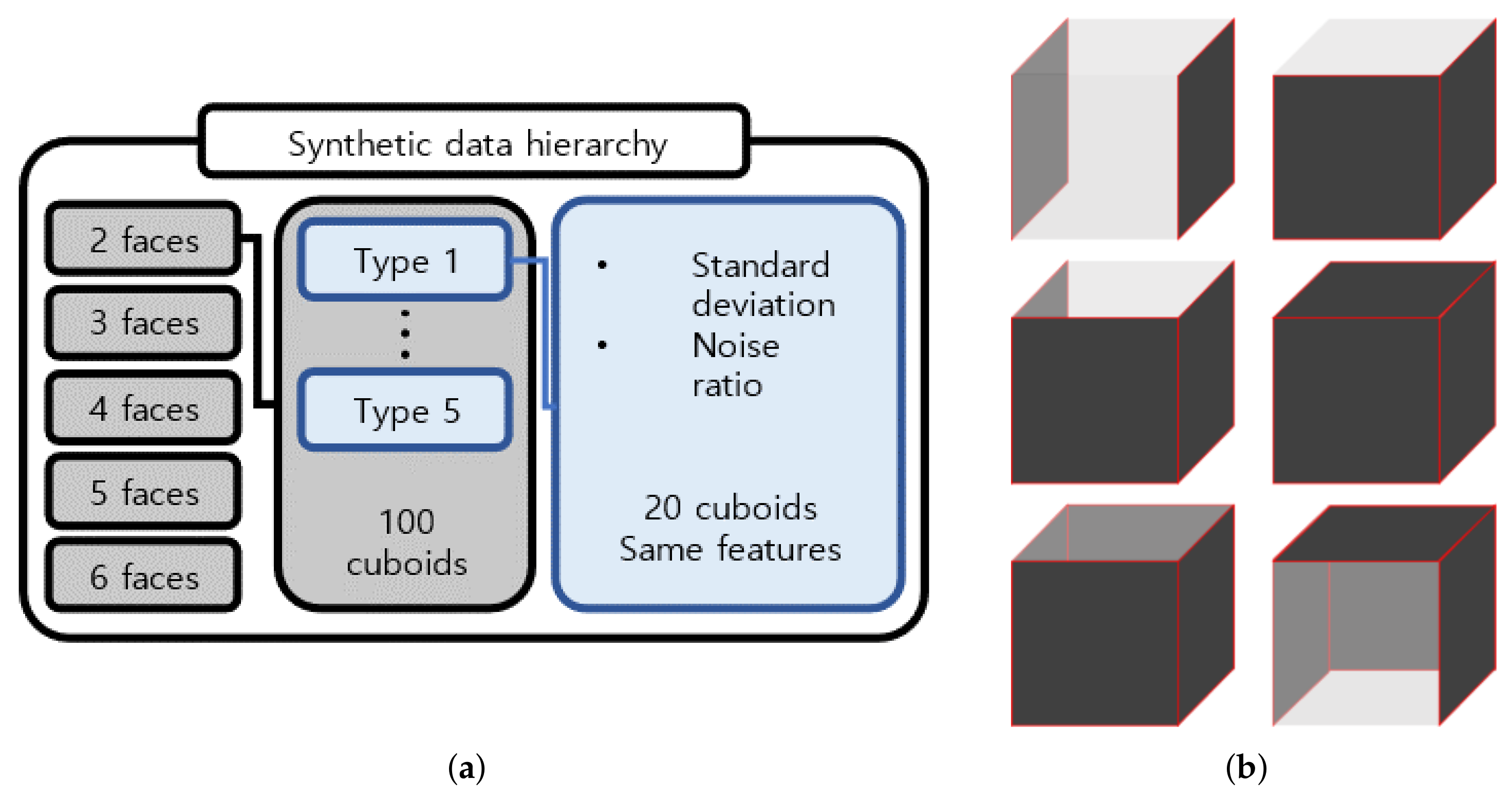
3.2. Synthetic Data
3.3. Real Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Linearized Rotation Matrix
- Quaternion:
- Inverse of q:
- LH Compound:
- RH Compound:
- To rotate v:
References
- Zhang, Y.; Xu, W.; Tong, Y.; Zhou, K. Online Structure Analysis for Real-Time Indoor Scene Reconstruction. ACM Trans. Graph. 2015, 34, 159:1–159:13. [Google Scholar] [CrossRef]
- Wang, J.; Oliveira, M.M. Improved Scene Reconstruction from Range Images. Comput. Graph. Forum 2002, 21, 521–530. [Google Scholar] [CrossRef]
- Rabbani, T.; Dijkman, S.; van den Heuvel, F.; Vosselman, G. An integrated approach for modelling and global registration of point clouds. ISPRS J. Photogramm. Remote Sens. 2007, 61, 355–370. [Google Scholar] [CrossRef]
- Jiang, H.; Xiao, J. A Linear Approach to Matching Cuboids in RGBD Images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2171–2178. [Google Scholar]
- Trevor, A.J.B.; Rogers, J.G.; Christensen, H.I. Planar surface SLAM with 3D and 2D sensors. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St Paul, MN, USA, 14–18 May 2012; pp. 3041–3048. [Google Scholar]
- Lee, K.; Ryu, S.H.; Yeon, S.; Cho, H.; Jun, C.; Kang, J.; Choi, H.; Hyeon, J.; Baek, I.; Jung, W.; et al. Accurate Continuous Sweeping Framework in Indoor Spaces With Backpack Sensor System for Applications to 3-D Mapping. IEEE Robot. Autom. Lett. 2016, 1, 316–323. [Google Scholar] [CrossRef]
- Décoret, X.; Durand, F.; Sillion, F.X.; Dorsey, J. Billboard Clouds for Extreme Model Simplification. In Proceedings of the ACM SIGGRAPH 2003 Papers, San Diego, CA, USA, 27–31 July 2003; pp. 689–696. [Google Scholar]
- Ren, Z.; Wang, R.; Snyder, J.; Zhou, K.; Liu, X.; Sun, B.; Sloan, P.P.; Bao, H.; Peng, Q.; Guo, B. Real-Time Soft Shadows in Dynamic Scenes Using Spherical Harmonic Exponentiation. In Proceedings of the ACM SIGGRAPH 2006 Papers, Boston, MA, USA, 30 July–3 August 2006; pp. 977–986. [Google Scholar]
- Li, Y.; Wu, X.; Chrysathou, Y.; Sharf, A.; Cohen-Or, D.; Mitra, N.J. GlobFit: Consistently Fitting Primitives by Discovering Global Relations. ACM Trans. Graph. 2011, 30, 52:1–52:12. [Google Scholar] [CrossRef]
- Wei, Q.; Jiang, Z.; Zhang, H. Robust Spacecraft Component Detection in Point Clouds. Sensors 2018, 18, 933. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Yin, K.; Huang, H.; Zhang, H.; Gong, M.; Cohen-Or, D. Generalized Cylinder Decomposition. ACM Trans. Graph. 2015, 34, 171:1–171:14. [Google Scholar] [CrossRef]
- Thiery, J.M.; Guy, E.; Boubekeur, T. Sphere-Meshes: Shape Approximation Using Spherical Quadric Error Metrics. ACM Trans. Graph. 2013, 32, 178:1–178:12. [Google Scholar] [CrossRef]
- Shtof, A.; Agathos, A.; Gingold, Y.; Shamir, A.; Cohen-Or, D. Geosemantic Snapping for Sketch-Based Modeling. Comput. Graph. Forum 2013, 32, 245–253. [Google Scholar] [CrossRef]
- Mohammadi, M.; Rashidi, M.; Mousavi, V.; Karami, A.; Yu, Y.; Samali, B. Case study on accuracy comparison of digital twins developed for a heritage bridge via UAV photogrammetry and terrestrial laser scanning. In Proceedings of the 10th International Conference on Structural Health Monitoring of Intelligent Infrastructure, Porto, Portugal, 30 June–2 July 2021. [Google Scholar]
- Mohammadi, M.; Rashidi, M.; Mousavi, V.; Karami, A.; Yu, Y.; Samali, B. Quality Evaluation of Digital Twins Generated Based on UAV Photogrammetry and TLS: Bridge Case Study. Remote Sens. 2021, 13, 3499. [Google Scholar] [CrossRef]
- Mohammadi, M.; Rashidi, M.; Mousavi, V.; Yu, Y.; Samali, B. Application of TLS Method in Digitization of Bridge Infrastructures: A Path to BrIM Development. Remote Sens. 2022, 14, 1148. [Google Scholar] [CrossRef]
- Rashidi, M.; Mohammadi, M.; Sadeghlou Kivi, S.; Abdolvand, M.M.; Truong-Hong, L.; Samali, B. A Decade of Modern Bridge Monitoring Using Terrestrial Laser Scanning: Review and Future Directions. Remote Sens. 2020, 12, 3796. [Google Scholar] [CrossRef]
- Mishima, M.; Uchiyama, H.; Thomas, D.; Taniguchi, R.i.; Roberto, R.; Lima, J.a.P.; Teichrieb, V. RGB-D SLAM based incremental cuboid modeling. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 414–429. [Google Scholar]
- Wu, Q.; Xu, K.; Wang, J. Constructing 3D CSG Models from 3D Raw Point Clouds. Comput. Graph. Forum 2018, 37, 221–232. [Google Scholar] [CrossRef]
- Hu, H.; Immel, F.; Janosovits, J.; Lauer, M.; Stiller, C. A Cuboid Detection and Tracking System using A Multi RGBD Camera Setup for Intelligent Manipulation and Logistics. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering, Lyon, France, 23–27 August 2021; pp. 1097–1103. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Borrmann, D.; Elseberg, J.; Lingemann, K.; Nüchter, A. The 3D Hough Transform for plane detection in point clouds: A review and a new accumulator design. 3D Res. 2011, 2, 1–3. [Google Scholar] [CrossRef]
- Reynolds, D. Gaussian Mixture Models. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 659–663. ISBN 978-0-387-73003-5. [Google Scholar]
- Öner, M.; Deveci Kocakoç, I. JMASM 49: A compilation of some popular goodness of fit tests for normal distribution: Their algorithms and MATLAB codes (MATLAB). J. Mod. Appl. Stat. Methods 2017, 16, 547–575. [Google Scholar] [CrossRef]
- Moon, T. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Van den Bos, A. Appendix C: Positive Semidefinite and Positive Definite Matrices. In Parameter Estimation for Scientists and Engineers; John Wiley & Sons, Ltd.: West Sussex, UK, 2007; pp. 259–263. ISBN 978-0-470-17386-2. [Google Scholar]
- Korsawe, J. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/18264-minimal-bounding-box (accessed on 24 February 2022).
- Prakhar. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/54778-sample3d-vertices-faces-n (accessed on 24 February 2022).
- Barfoot, T.; Forbes, J.R.; Furgale, P.T. Pose estimation using linearized rotations and quaternion algebra. Acta Astronaut. 2011, 68, 101–112. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No Solution (#) | False Solution (#) | Total (#) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | - | - | Angle () | 1.6959 | Volume (%) | 0.2707 | Center (m) | 0.0545 | - | - |
| Method | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| 2 faces | 50 | 0 | 1 | 1 | 49 | 26 | 49 | 7 | 99 | 26 |
| 3 faces | 1 | 0 | 1 | 0 | 26 | 14 | 30 | 0 | 36 | 14 |
| 4 faces | 0 | 0 | 0 | 0 | 4 | 1 | 8 | 0 | 12 | 1 |
| 5 faces | 1 | 0 | 1 | 0 | 5 | 0 | 9 | 0 | 14 | 0 |
| 6 faces | 0 | 0 | 0 | 0 | 4 | 0 | 4 | 0 | 5 | 0 |
| 2 faces | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 | |||||
| Noise ratio (%) | 57.7682 | 69.1235 | 52.0047 | 95.2211 | 77.8355 | |||||
| Standard deviation (m) | 0.0345 | 0.0300 | 0.0254 | 0.0234 | 0.0226 | |||||
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| Angle () | - | 0.1510 | 0.3117 | 0.1800 | - | 0.1207 | - | 0.1083 | - | 0.2585 |
| Volume (%) | - | 12.3106 | 8.1916 | 11.3878 | - | 10.3600 | - | 8.0948 | - | 7.0110 |
| Center (m) | - | 0.0239 | 0.0159 | 0.0177 | - | 0.0133 | - | 0.0160 | - | 0.0121 |
| No solution (#) | 8 | 0 | 10 | 0 | 11 | 0 | 9 | 0 | 12 | 0 |
| False solution (#) | 12 | 6 | 9 | 9 | 9 | 3 | 11 | 4 | 8 | 4 |
| 3 faces | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 | |||||
| Noise ratio (%) | 74.4527 | 78.2890 | 68.1002 | 75.9664 | 52.8059 | |||||
| Standard deviation (m) | 0.0270 | 0.0395 | 0.0301 | 0.0296 | 0.0258 | |||||
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| Angle () | 0.4237 | 0.1658 | 0.4316 | 0.1587 | 0.3297 | 0.1856 | 0.2714 | 0.0675 | 0.2842 | 0.1065 |
| Volume (%) | 12.3168 | 12.1011 | 14.8920 | 10.9064 | 6.9875 | 8.9226 | 7.9783 | 8.6473 | 10.2818 | 8.5232 |
| Center (m) | 0.0215 | 0.0140 | 0.0318 | 0.0248 | 0.0363 | 0.0165 | 0.0333 | 0.0191 | 0.0189 | 0.0111 |
| No solution (#) | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| False solution (#) | 2 | 6 | 16 | 1 | 7 | 2 | 8 | 3 | 2 | 2 |
| 4 faces | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 | |||||
| Noise ratio (%) | 86.6996 | 79.0972 | 88.4985 | 57.3732 | 68.4000 | |||||
| Standard deviation (m) | 0.0212 | 0.0247 | 0.0233 | 0.0223 | 0.0390 | |||||
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| Angle () | 0.2514 | 0.0691 | 0.2942 | 0.0754 | 0.2734 | 0.0435 | 0.1377 | 0.0479 | 0.4077 | 0.1068 |
| Volume (%) | 5.3674 | 5.0826 | 6.9858 | 6.1936 | 6.1756 | 5.2580 | 5.5300 | 4.9170 | 9.4658 | 6.3098 |
| Center (m) | 0.0221 | 0.0122 | 0.0274 | 0.0115 | 0.0223 | 0.0149 | 0.0184 | 0.0120 | 0.0322 | 0.0169 |
| No solution (#) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| False solution (#) | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 11 | 0 |
| 5 faces | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 | |||||
| Noise ratio (%) | 71.9658 | 54.1036 | 88.2604 | 90.6294 | 50.4478 | |||||
| Standard deviation (m) | 0.0282 | 0.0260 | 0.0329 | 0.0207 | 0.0394 | |||||
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| Angle () | 0.1609 | 0.1124 | 0.1291 | 0.0465 | 0.1687 | 0.0453 | 0.2014 | 0.0458 | 0.2424 | 0.0393 |
| Volume (%) | 5.9736 | 3.4493 | 4.1928 | 2.6833 | 6.8393 | 1.8585 | 4.3038 | 1.7682 | 5.4678 | 2.5914 |
| Center (m) | 0.0198 | 0.0085 | 0.0199 | 0.0068 | 0.0286 | 0.0130 | 0.0173 | 0.0086 | 0.0339 | 0.0123 |
| No solution (#) | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| False solution (#) | 1 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 3 | 0 |
| 6 faces | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 | |||||
| Noise ratio (%) | 95.2056 | 90.6593 | 57.5372 | 97.8511 | 80.7944 | |||||
| Standard deviation (m) | 0.0207 | 0.0383 | 0.0390 | 0.0216 | 0.0316 | |||||
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed |
| Angle () | 0.1819 | 0.0576 | 0.2741 | 0.1072 | 0.1575 | 0.0844 | 0.2271 | 0.0530 | 0.1770 | 0.0687 |
| Volume (%) | 2.8148 | 1.4583 | 3.9445 | 1.8364 | 2.4620 | 1.3033 | 2.9298 | 1.4658 | 3.4836 | 1.2712 |
| Center (m) | 0.0087 | 0.0003 | 0.0089 | 0.0006 | 0.0075 | 0.0004 | 0.0054 | 0.0002 | 0.0078 | 0.0003 |
| No solution (#) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| False solution (#) | 0 | 0 | 2 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 3 Faces | 4 Faces | 5 Faces | 6 Faces | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | Wei et al. | Proposed | |
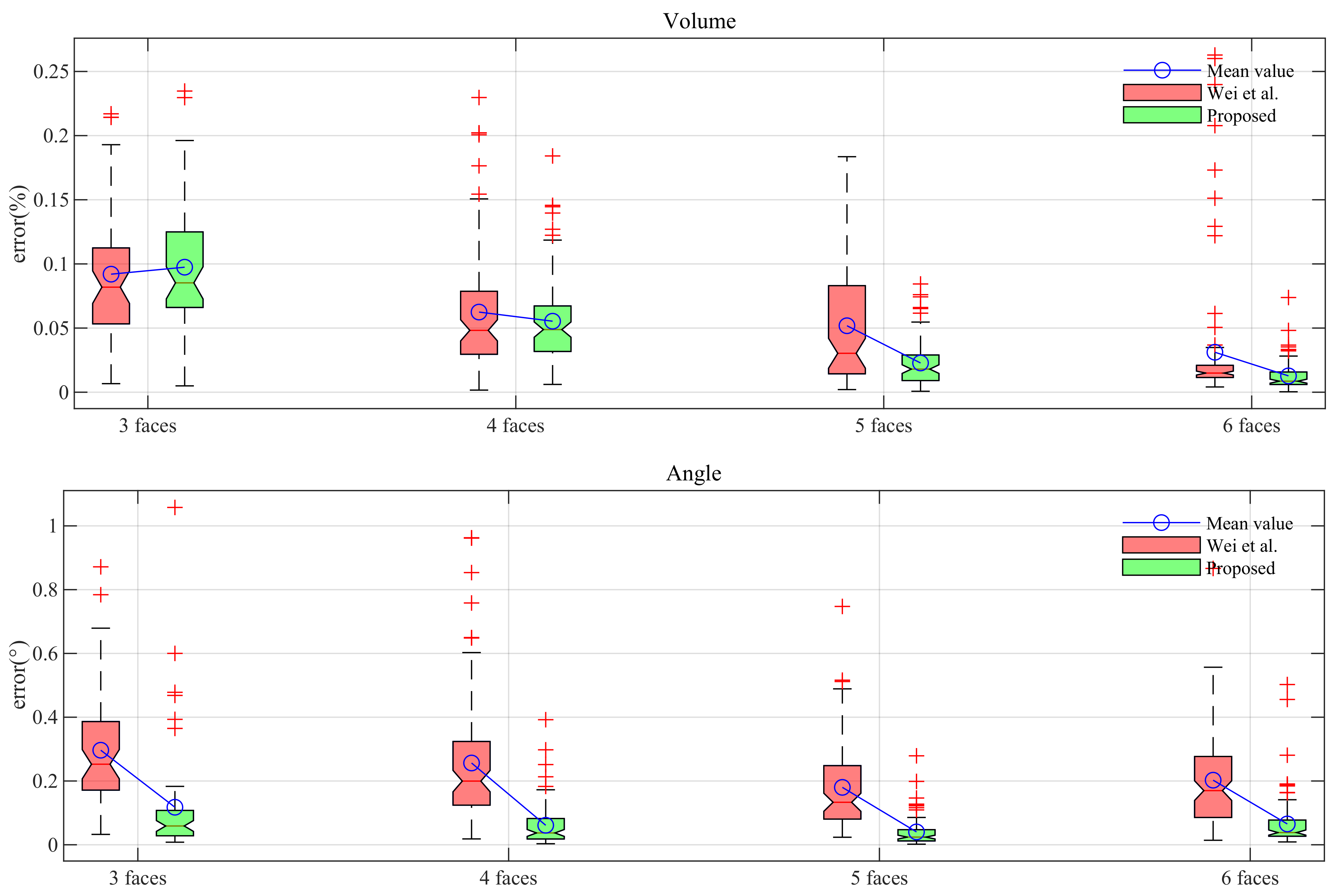
| Angle | Mean | 0.2965 | 0.1177 | 0.2564 | 0.0612 | 0.1800 | 0.0403 | 0.2025 | 0.0653 |
| () | Standard deviation | 0.1766 | 0.1825 | 0.1989 | 0.0662 | 0.1385 | 0.0450 | 0.1634 | 0.0782 |
| Volume | Mean | 0.0920 | 0.0974 | 0.0625 | 0.0553 | 0.0518 | 0.0228 | 0.0312 | 0.0127 |
| (%) | Standard deviation | 0.0565 | 0.0504 | 0.0502 | 0.0348 | 0.0499 | 0.0183 | 0.0526 | 0.0111 |
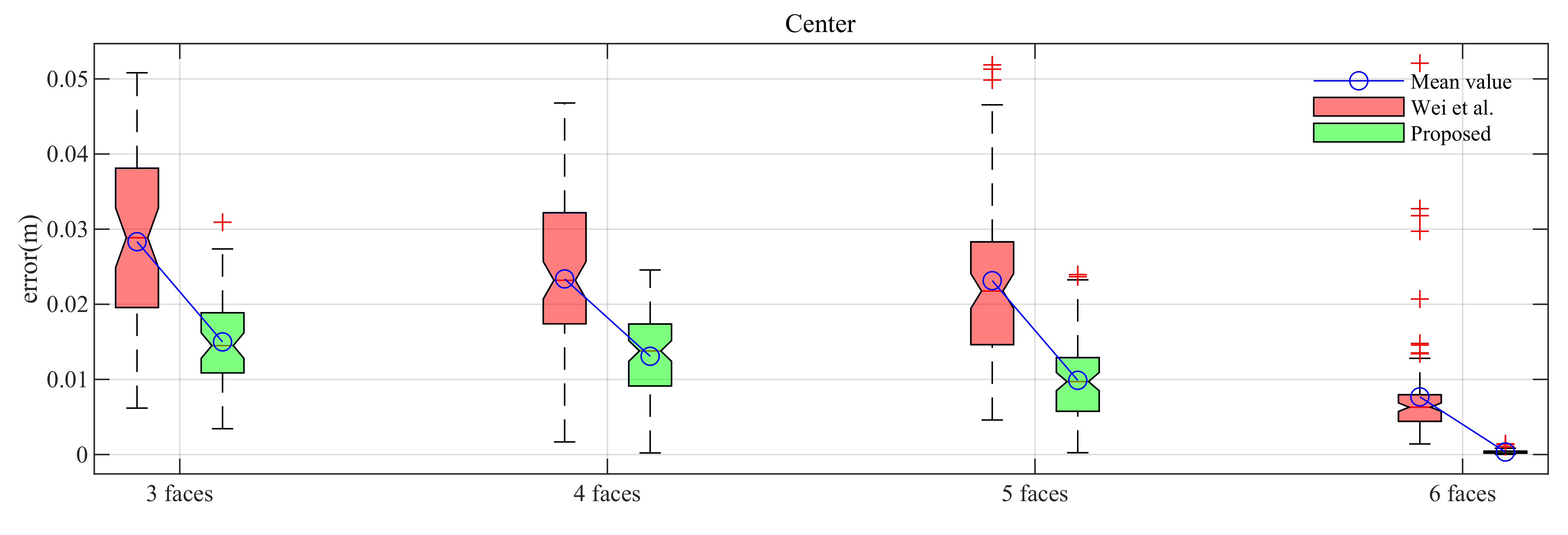
| Center | Mean | 0.0283 | 0.0150 | 0.0234 | 0.0131 | 0.0231 | 0.0099 | 0.0077 | 0.0003 |
| (m) | Standard deviation | 0.0120 | 0.0061 | 0.0112 | 0.0057 | 0.0109 | 0.0056 | 0.0071 | 0.0002 |
| Used data (#) | 54 | 87 | 86 | 95 | |||||
| No Solution (#) | False Solution (#) | Total (#) | ||||||
|---|---|---|---|---|---|---|---|---|
| Threshold | - | 75th (m) | 0.0454 | 80th (m) | 0.0509 | 85th (m) | 0.0578 | - |
| Wei et al. | 154 | 46 | 50 | 64 | 218 | |||
| w/o BTLS | 29 | 18 | 18 | 15 | 47 | |||
| Proposed | 2 | 4 | 4 | 2 | 6 | |||
| Results with Succeeded Data by Each Method | |||||||
|---|---|---|---|---|---|---|---|
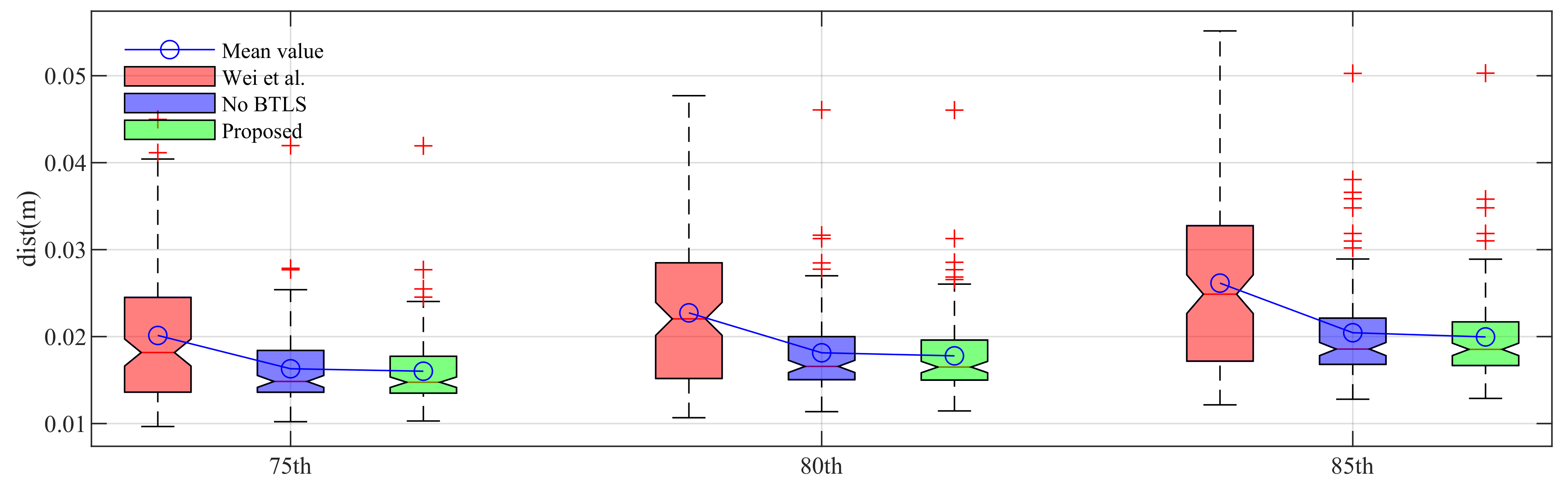
| percentiles | 75th | 80th | 85th | Used data | |||
| mean (m) | std (m) | mean (m) | std (m) | mean (m) | std (m) | (#) | |
| Wei et al. | 0.0198 | 0.0076 | 0.0224 | 0.0084 | 0.0259 | 0.0102 | 136 |
| w/o BTLS | 0.0211 | 0.0073 | 0.0231 | 0.0079 | 0.0256 | 0.0085 | 307 |
| Proposed | 0.0205 | 0.0071 | 0.0226 | 0.0076 | 0.0250 | 0.0082 | 348 |
| Results with Succeeded Data by Both Methods | |||||||
| percentiles | 75th | 80th | 85th | Used data | |||
| mean (m) | std (m) | mean (m) | std (m) | mean (m) | std (m) | (#) | |
| Wei et al. | 0.0201 | 0.0078 | 0.0227 | 0.0086 | 0.0261 | 0.0104 | |
| w/o BTLS | 0.0163 | 0.0043 | 0.0181 | 0.0048 | 0.0204 | 0.0056 | 121 |
| Proposed | 0.0160 | 0.0041 | 0.0178 | 0.0045 | 0.0200 | 0.0051 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, W.; Hyeon, J.; Doh, N. Robust Cuboid Modeling from Noisy and Incomplete 3D Point Clouds Using Gaussian Mixture Model. Remote Sens. 2022, 14, 5035. https://doi.org/10.3390/rs14195035
Jung W, Hyeon J, Doh N. Robust Cuboid Modeling from Noisy and Incomplete 3D Point Clouds Using Gaussian Mixture Model. Remote Sensing. 2022; 14(19):5035. https://doi.org/10.3390/rs14195035
Chicago/Turabian StyleJung, Woonhyung, Janghun Hyeon, and Nakju Doh. 2022. "Robust Cuboid Modeling from Noisy and Incomplete 3D Point Clouds Using Gaussian Mixture Model" Remote Sensing 14, no. 19: 5035. https://doi.org/10.3390/rs14195035
APA StyleJung, W., Hyeon, J., & Doh, N. (2022). Robust Cuboid Modeling from Noisy and Incomplete 3D Point Clouds Using Gaussian Mixture Model. Remote Sensing, 14(19), 5035. https://doi.org/10.3390/rs14195035