
Mapping Residential Vacancies with Multisource Spatiotemporal Data: A Case Study in Beijing



Abstract
:1. Introduction
2. Materials and Methods
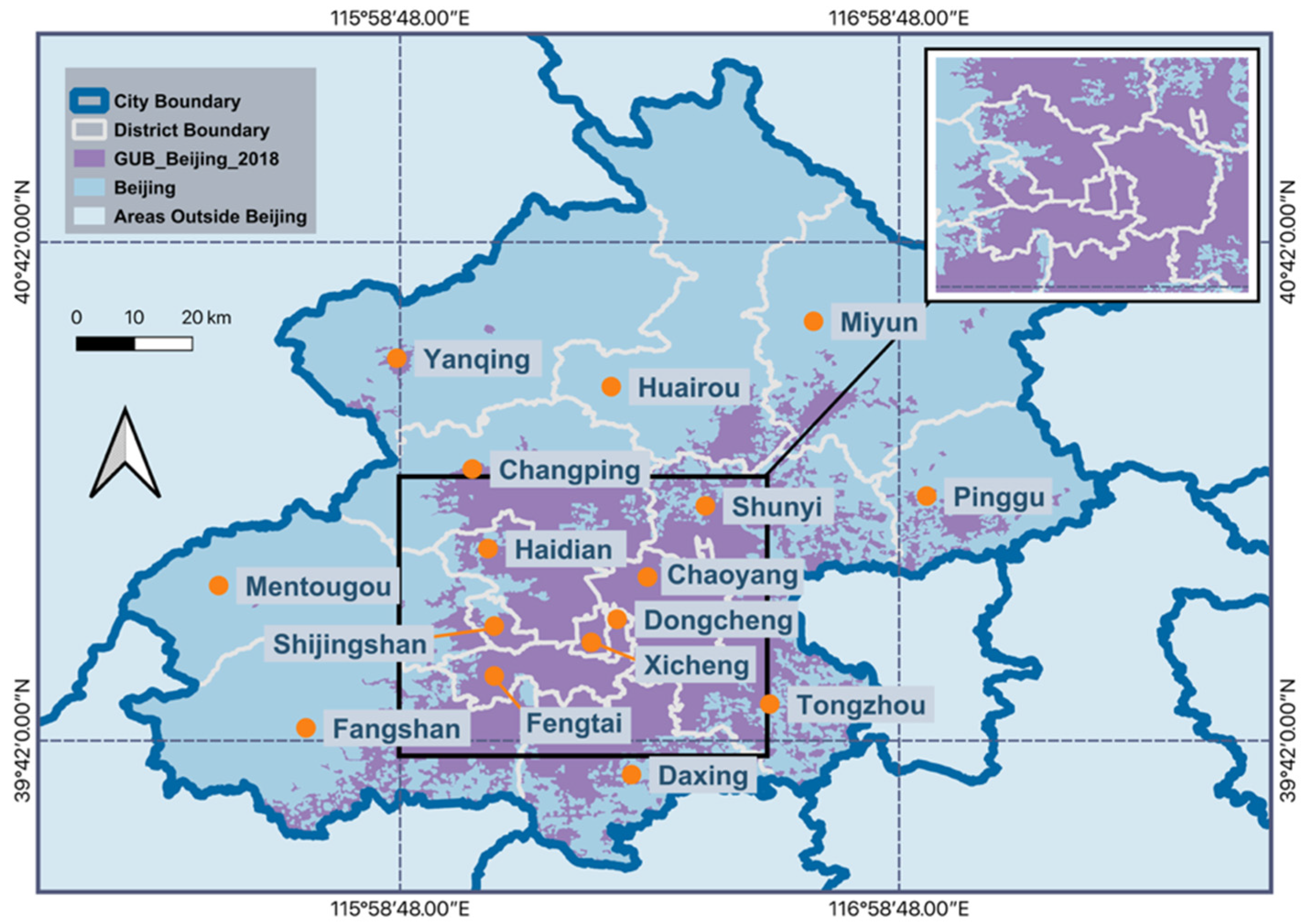
2.1. Study Area
2.2. Datasets
2.2.1. Luojia-1 Nighttime Light Data
2.2.2. Easygo Crowdedness Data
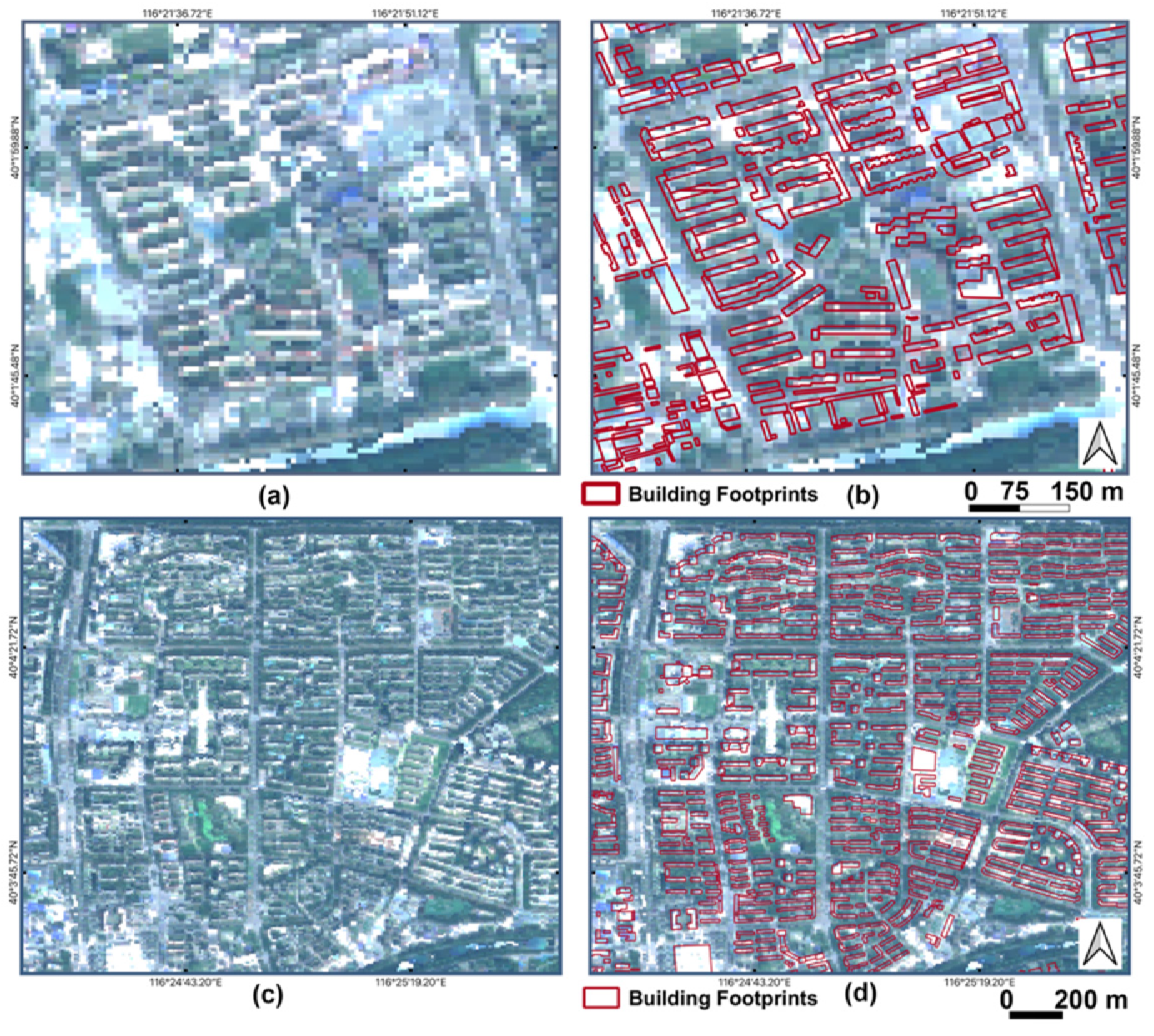
2.2.3. Baidu Maps Building Footprints
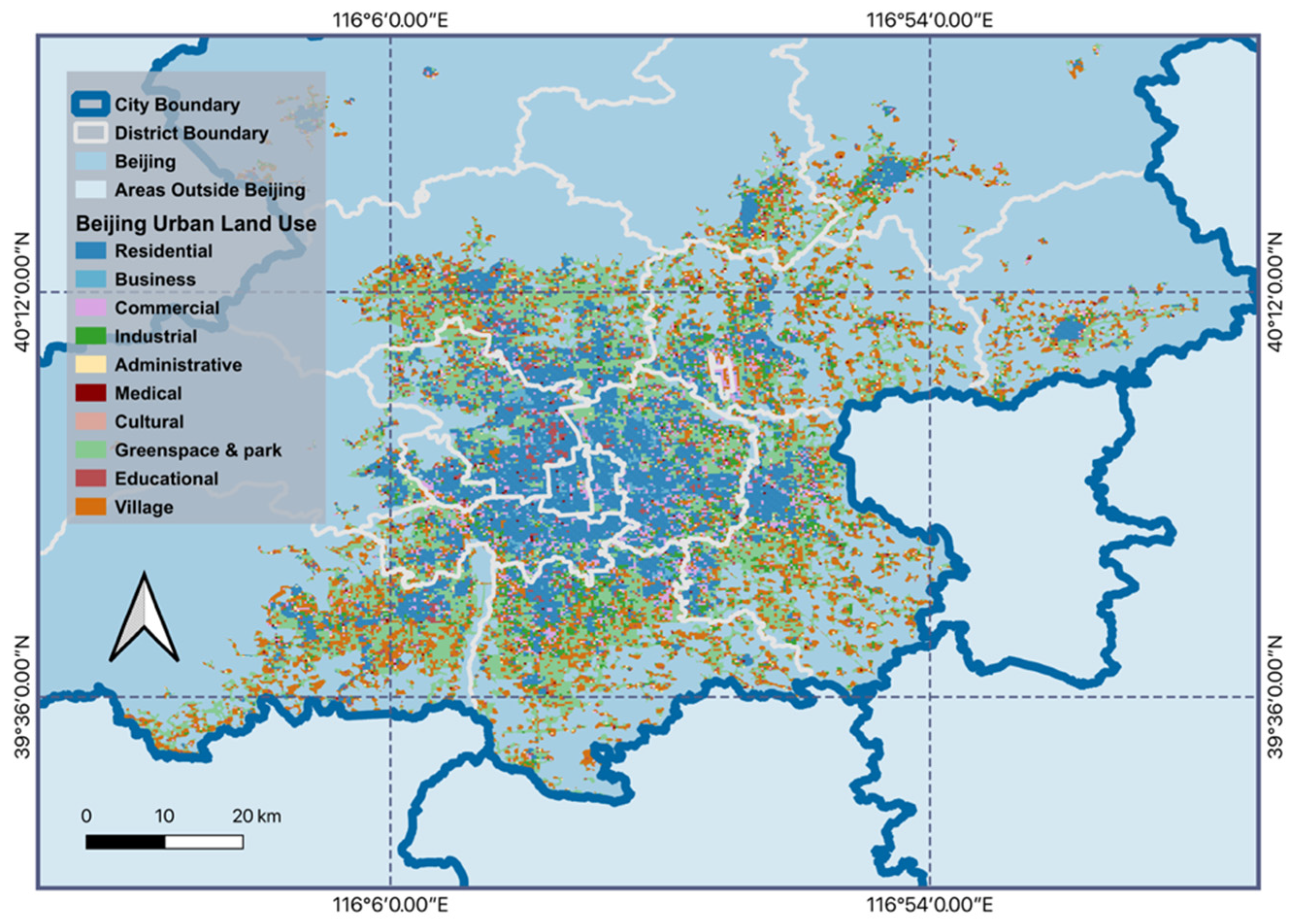
2.2.4. EULUC-Beijing Land Use Product
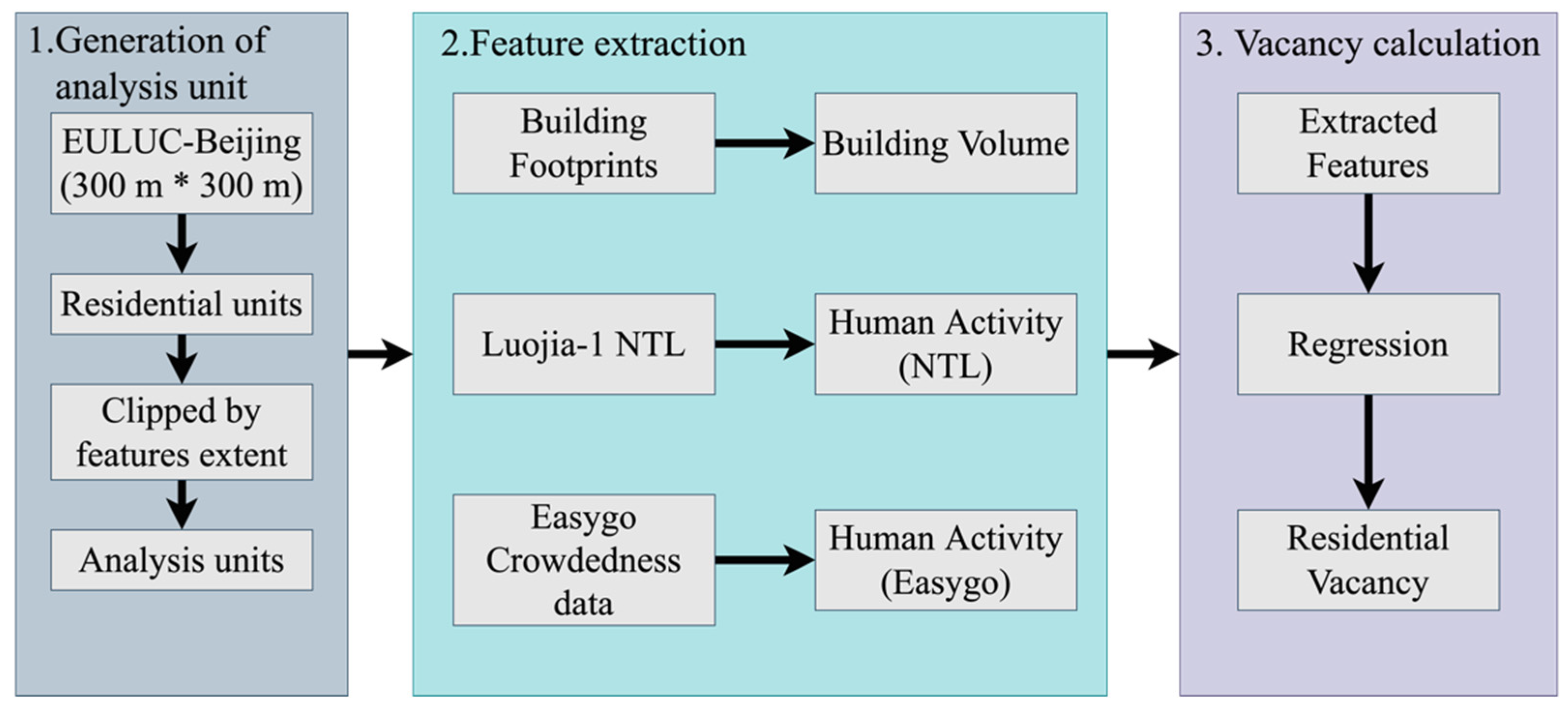
2.3. Methods
2.3.1. Generation of Analysis Units
2.3.2. Feature Extraction
Extraction of Building Volumes
Extraction of Human Activity Intensities
2.3.3. Vacancy Calculation
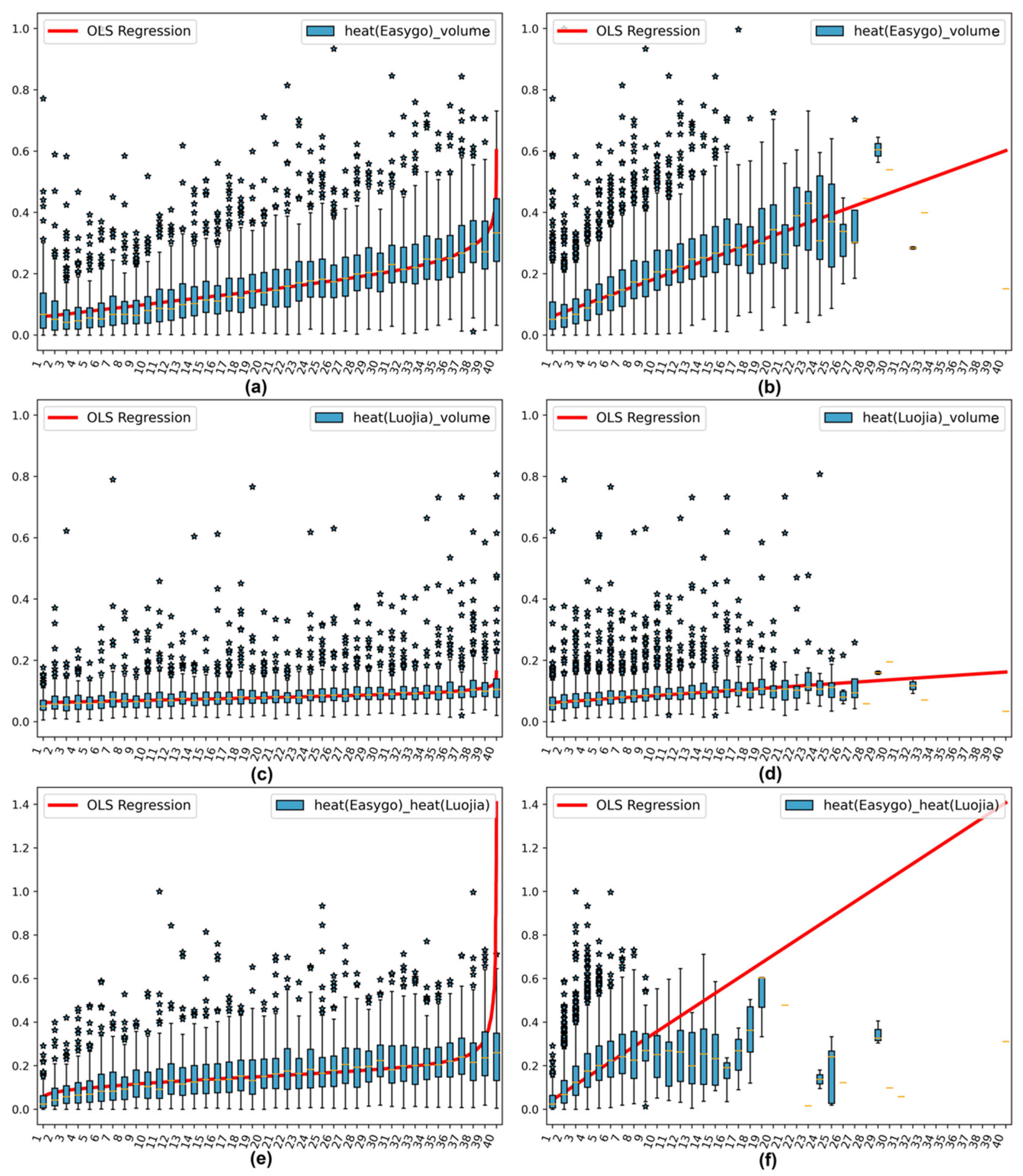
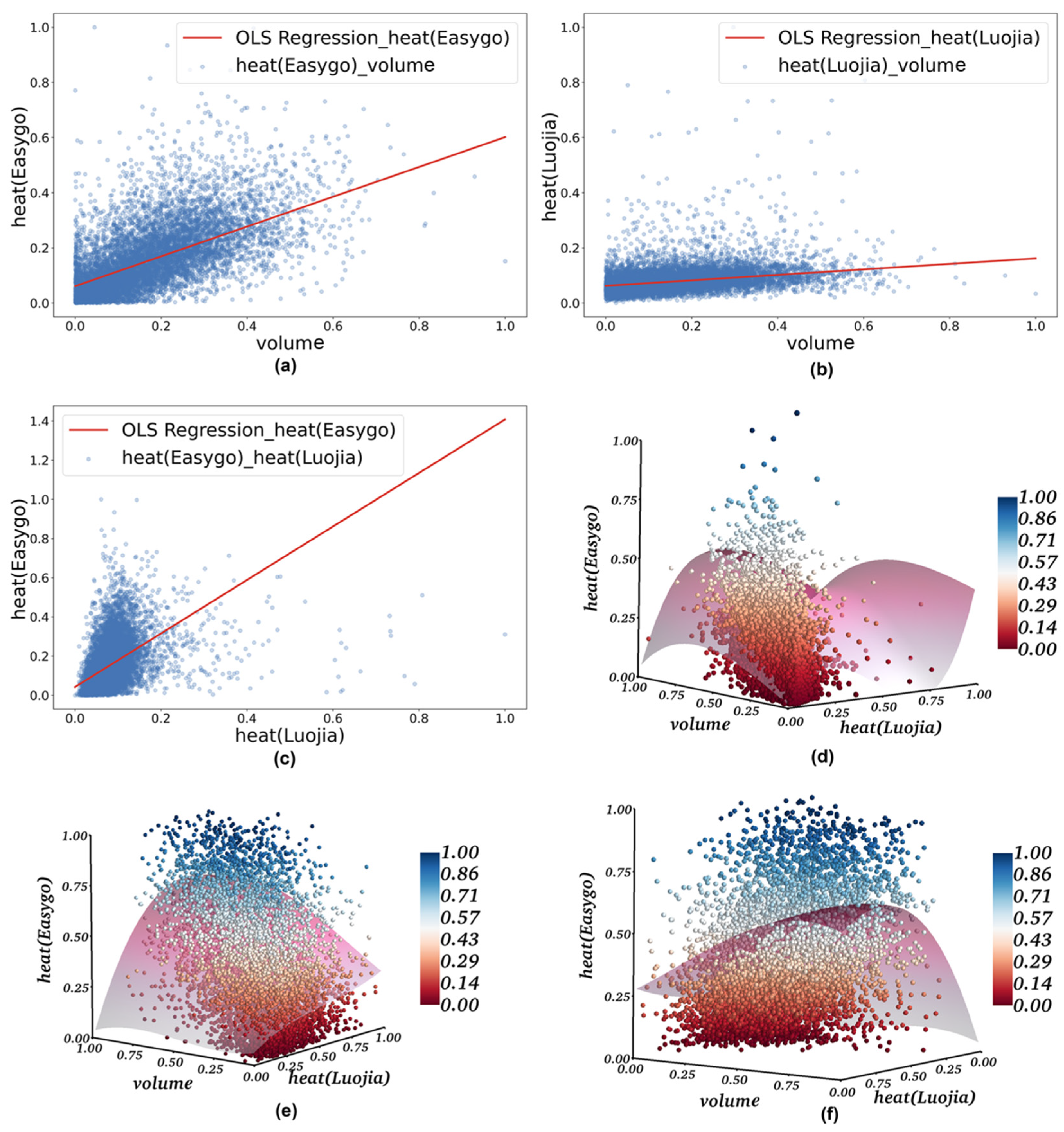
Examination of Features
Conducting Regressions
Vacancy Calculation
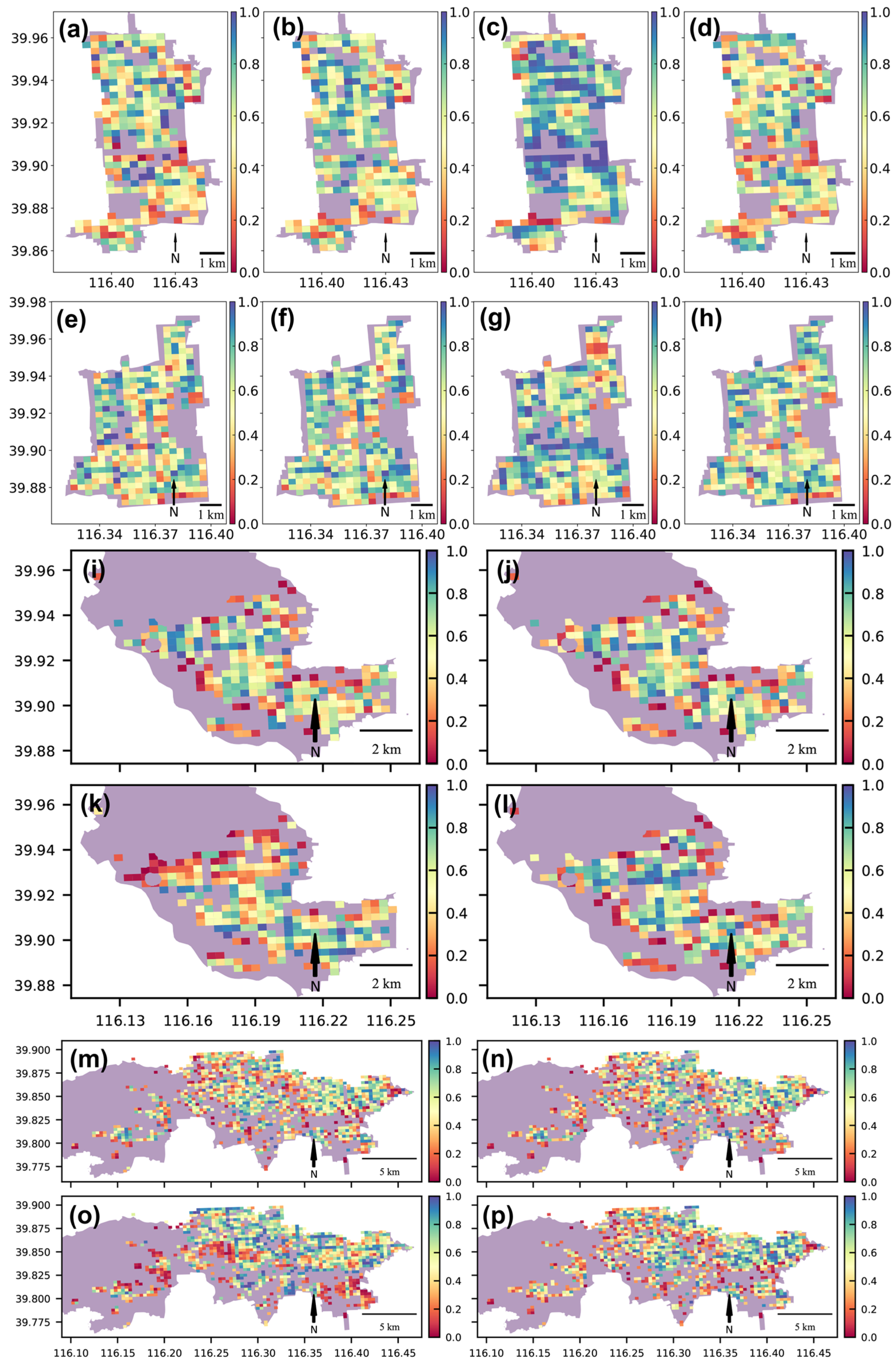
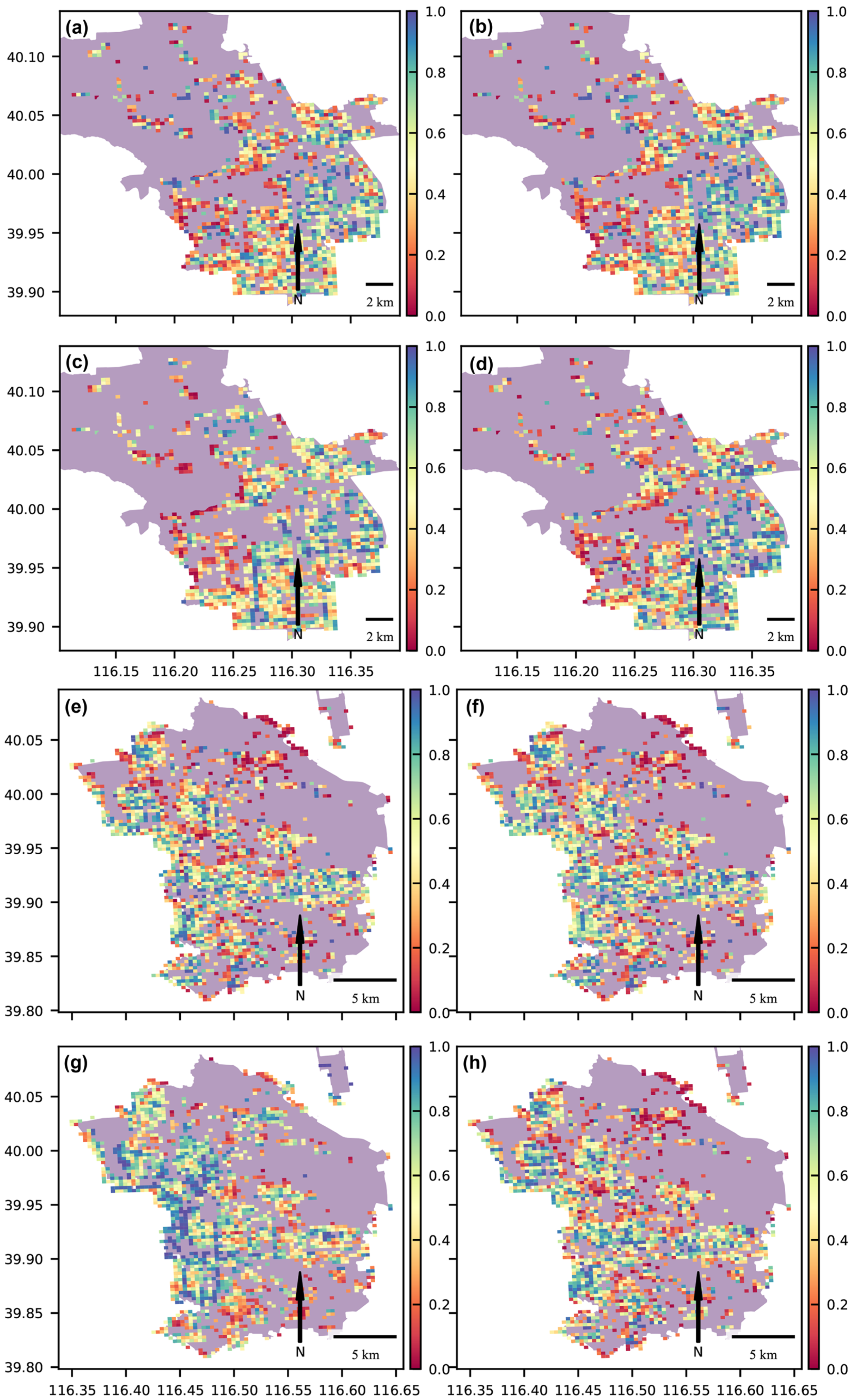
3. Results
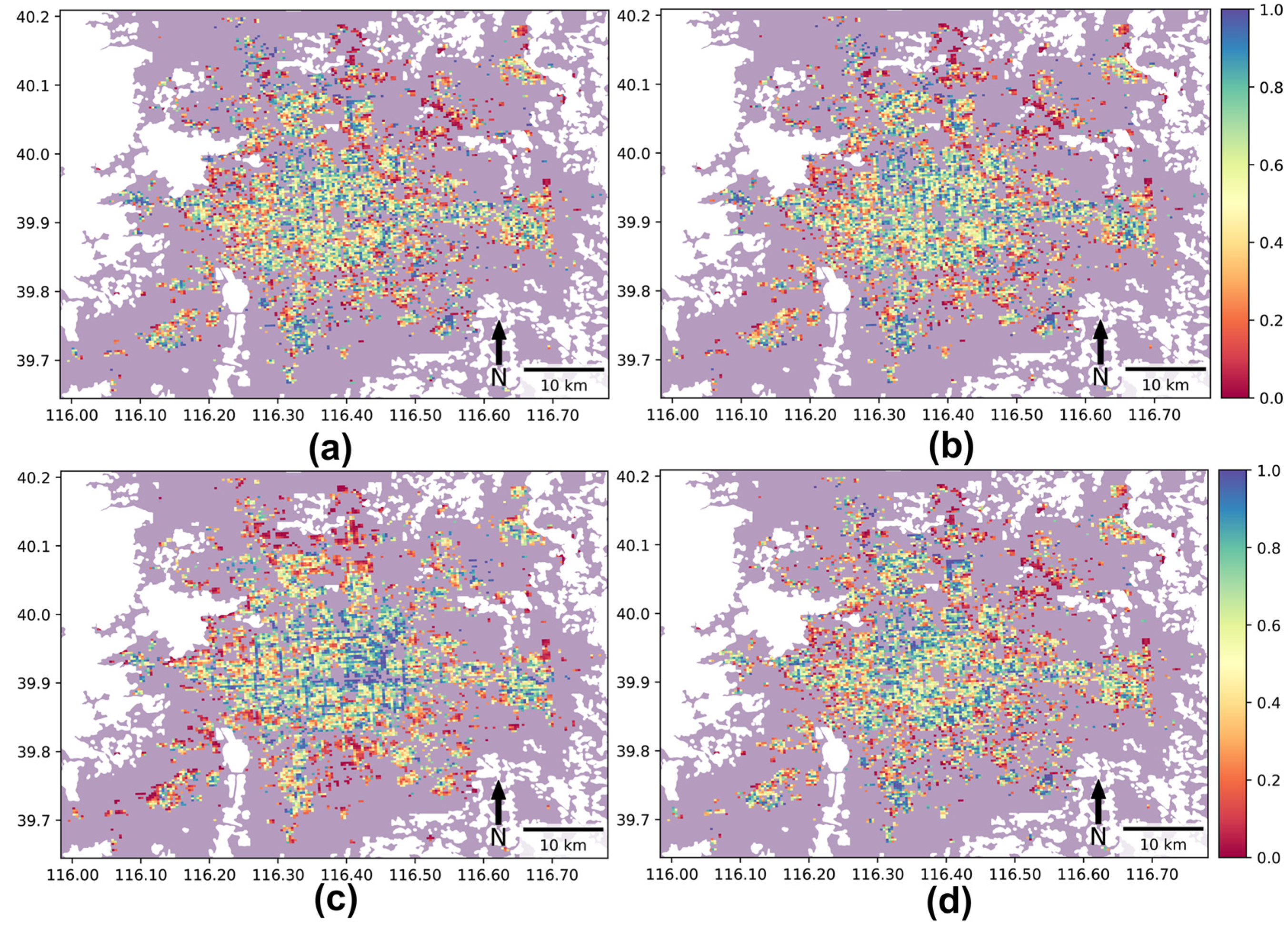
3.1. Spatial Pattern of the Mapping Results
3.2. Comparison of Mapping Results at the District Level
3.3. Analysis of the Regression Results
3.4. Validation of the Most-Vacant Units
3.5. Discussion of Advantages and Disadvantages among Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Wei, Y.D.; Liao, F.H.; Huang, Z. Administrative hierarchy and urban land expansion in transitional China. Appl. Geogr. 2015, 56, 177–186. [Google Scholar] [CrossRef]
- Wang, L.; Li, C.; Ying, Q.; Cheng, X.; Wang, X.; Li, X.; Hu, L.; Liang, L.; Yu, L.; Huang, H.; et al. China’s urban expansion from 1990 to 2010 determined with satellite remote sensing. Chin. Sci. Bull. 2012, 57, 2802–2812. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Li, X.; Zhang, W. 40-Year (1978–2017) human settlement changes in China reflected by impervious surfaces from satellite remote sensing. Sci. Bull. 2019, 64, 756–763. [Google Scholar] [CrossRef] [Green Version]
- Cartier, C. Territorial Urbanization and the Party-State in China. Territ. Politics Gov. 2015, 3, 294–320. [Google Scholar] [CrossRef]
- Gu, C.; Wei, Y.D.; Cook, I.G. Planning Beijing: Socialist city, transitional city, and global city. Urban Geogr. 2015, 36, 905–926. [Google Scholar] [CrossRef]
- Lu, H.; Zhang, C.; Liu, G.; Ye, X.; Miao, C. Mapping China’s Ghost Cities through the Combination of Nighttime Satellite Data and Daytime Satellite Data. Remote Sens. 2018, 10, 1037. [Google Scholar] [CrossRef] [Green Version]
- Young, O.R.; Guttman, D.; Qi, Y.; Bachus, K.; Belis, D.; Cheng, H.; Lin, A.; Schreifels, J.; Van Eynde, S.; Wang, Y.; et al. Institutionalized governance processes: Comparing environmental problem solving in China and the United States. Glob. Environ. Chang. 2015, 31, 163–173. [Google Scholar] [CrossRef]
- Shepard, W. Ghost Cities of China: The Story of Cities without People in the World’s most Populated Country, 1st ed.; Zed Books: London, UK, 2015; p. 218. [Google Scholar]
- Chen, Z.; Yu, B.; Hu, Y.; Huang, C.; Shi, K.; Wu, J. Estimating House Vacancy Rate in Metropolitan Areas Using NPP-VIIRS Nighttime Light Composite Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2188–2197. [Google Scholar] [CrossRef]
- Zheng, Q.; Zeng, Y.; Deng, J.; Wang, K.; Jiang, R.; Ye, Z. “Ghost cities” identification using multi-source remote sensing datasets: A case study in Yangtze River Delta. Appl. Geogr. 2017, 80, 112–121. [Google Scholar] [CrossRef]
- Guidance from the Ministry of Land and Resources on Promoting the Economical and Intensive Use of Land. Available online: http://f.mnr.gov.cn/202102/t20210214_2611863.html (accessed on 29 June 2020).
- Chi, G.; Liu, Y.; Wu, H.J.A. Ghost Cities Analysis Based on Positioning Data in China. arXiv 2015, arXiv:1510.08505. [Google Scholar]
- Leichtle, T.; Lakes, T.; Zhu, X.X.; Taubenböck, H. Has Dongying developed to a ghost city?—Evidence from multi-temporal population estimation based on VHR remote sensing and census counts. Comput. Environ. Urban Syst. 2019, 78, 101372. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Hong, Y.; Qi, J.G. Spatio-temporal dynamics and evolution of land use change and landscape pattern in response to rapid urbanization. Landsc. Urban Plan. 2009, 92, 187–198. [Google Scholar] [CrossRef]
- Xie, Y.; Weng, Q. Updating urban extents with nighttime light imagery by using an object-based thresholding method. Remote Sens. Environ. 2016, 187, 1–13. [Google Scholar] [CrossRef]
- Gao, B.; Huang, Q.; He, C.; Sun, Z.; Zhang, D. How does sprawl differ across cities in China? A multi-scale investigation using nighttime light and census data. Landsc. Urban Plan. 2016, 148, 89–98. [Google Scholar] [CrossRef]
- Yu, B.; Shi, K.; Hu, Y.; Huang, C.; Chen, Z.; Wu, J. Poverty Evaluation Using NPP-VIIRS Nighttime Light Composite Data at the County Level in China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1217–1229. [Google Scholar] [CrossRef]
- Cai, J.; Huang, B.; Song, Y. Using multi-source geospatial big data to identify the structure of polycentric cities. Remote Sens. Environ. 2017, 202, 210–221. [Google Scholar] [CrossRef]
- Zhang, Q.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Zheng, Q.; Deng, J.; Jiang, R.; Wang, K.; Xue, X.; Lin, Y.; Huang, Z.; Shen, Z.; Li, J.; Shahtahmassebi, A.R. Monitoring and assessing “ghost cities” in Northeast China from the view of nighttime light remote sensing data. Habitat Int. 2017, 70, 34–42. [Google Scholar] [CrossRef]
- Ju, Y.; Dronova, I.; Ma, Q.; Zhang, X. Analysis of urbanization dynamics in mainland China using pixel-based night-time light trajectories from 1992 to 2013. Int. J. Remote Sens. 2017, 38, 6047–6072. [Google Scholar] [CrossRef]
- Ge, W.; Yang, H.; Zhu, X.; Ma, M.; Yang, Y. Ghost City Extraction and Rate Estimation in China Based on NPP-VIIRS Night-Time Light Data. Isprs Int. J. Geo-Inf. 2018, 7, 219. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.; Long, Y.; Sun, W.; Lu, Y.; Yang, X.; Tang, J. Evaluating cities’ vitality and identifying ghost cities in China with emerging geographical data. Cities 2017, 63, 98–109. [Google Scholar] [CrossRef]
- Williams, S.; Xu, W.; Tan, S.B.; Foster, M.J.; Chen, C. Ghost cities of China: Identifying urban vacancy through social media data. Cities 2019, 94, 275–285. [Google Scholar] [CrossRef]
- Gong, P.; Li, X.; Wang, J.; Bai, Y.; Chen, B.; Hu, T.; Liu, X.; Xu, B.; Yang, J.; Zhang, W.; et al. Annual maps of global artificial impervious area (GAIA) between 1985 and 2018. Remote Sens. Environ. 2020, 236, 111510. [Google Scholar] [CrossRef]
- Li, X.; Zhao, L.; Li, D.; Xu, H. Mapping Urban Extent Using Luojia 1-01 Nighttime Light Imagery. Sensors 2018, 18, 3665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, F.; Zhang, F.; Li, X.; Wang, P.; Liang, J.; Mei, Y.; Cheng, W.; Qian, Y. Spatiotemporal Patterns of the Use of Urban Green Spaces and External Factors Contributing to Their Use in Central Beijing. Int. J. Environ. Res. Public Health 2017, 14, 237. [Google Scholar] [CrossRef]
- Li, X.; Hu, T.; Gong, P.; Du, S.; Chen, B.; Li, X.; Dai, Q. Mapping Essential Urban Land Use Categories in Beijing with a Fast Area of Interest (AOI)-Based Method. Remote Sens. 2021, 13, 477. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Extent (Lonmin, Latmin, Lonmax, Latmax) |
|---|---|
| Residential units | (115.675, 39.447, 117.297, 40.660) |
| NTL | (113.645, 38.486, 117.506, 41.090) |
| Easygo | (115.987, 39.653, 116.779, 40.199) |
| Building footprints | (115.466, 39.491, 117.441, 40.710) |
| Method | Degree | Independent Variable(s) | Dependent Variable | Abbreviation |
|---|---|---|---|---|
| nonlinear | 3 | volume, heat (Luojia) | heat (Easygo) | VLE |
| linear | 1 | volume | heat (Easygo) | VE |
| linear | 1 | volume | heat (Luojia) | VL |
| linear | 1 | heat (Luojia) | heat (Easygo) | LE |
| Method | Villa | Newly Built | Demolition | Greenspace | Land Use | Wasted | Others |
|---|---|---|---|---|---|---|---|
| VE | 96 | 22 | 42 | 13 | 19 | 5 | 3 |
| LE | 48 | 44 | 22 | 50 | 24 | 1 | 11 |
| VL | 87 | 20 | 40 | 19 | 25 | 5 | 4 |
| VLE | 90 | 25 | 39 | 14 | 24 | 5 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Gong, P. Mapping Residential Vacancies with Multisource Spatiotemporal Data: A Case Study in Beijing. Remote Sens. 2022, 14, 376. https://doi.org/10.3390/rs14020376
Li X, Gong P. Mapping Residential Vacancies with Multisource Spatiotemporal Data: A Case Study in Beijing. Remote Sensing. 2022; 14(2):376. https://doi.org/10.3390/rs14020376
Chicago/Turabian StyleLi, Xiaoting, and Peng Gong. 2022. "Mapping Residential Vacancies with Multisource Spatiotemporal Data: A Case Study in Beijing" Remote Sensing 14, no. 2: 376. https://doi.org/10.3390/rs14020376