1. Introduction
Urban scene parsing of high-resolution remote-sensing images (HRRSIs) (or semantic segmentation in computer vision) refers to parsing different semantic regions from the images. It is crucial to the widespread applications of remote sensing, such as change detection [
1,
2,
3], ecological environment monitoring [
4,
5], natural disaster assessment [
6,
7], building area statistics [
8,
9,
10], UAV remote sensing [
11,
12], etc. In recent years, deep learning has significantly developed [
13]. Benefiting from this, many advanced semantic segmentation methods have been proposed [
14]. Their advantage lies in that they can automatically learn rich discriminative semantic features from large amounts of images. Based on these features, the model can further parse out regions that belong to different semantics.
Although those approaches perform well in natural image processing, they still have many shortcomings when dealing with complex urban scenes in HRRSIs. For example, features extracted from trees and grass in urban scenes often present ambiguous boundaries, which prevent accurate detection of edges. In addition, the sizes of different types of objects in HRRSIs vary drastically (such as cars and buildings). Therefore, urban scene parsing requires a model that can effectively extract not only the boundary contours of objects, but also multi-scale features.
Multi-scale contextual information plays a very important role in various vision tasks. Therefore, various neural networks have been proposed to improve the multi-scale feature capturing ability. A feature pyramid network (FPN) [
15] combines the low-level feature maps from top-down pathways with the high-level ones in bottom-up pathways via lateral connections, which greatly enhances the multi-scale feature extraction capability of the model. UNet [
16] uses a concatenated form to combine features with different scales in the skip connection process. Furthermore, the DeepLab series [
17,
18,
19] adopts atrous convolution to maintain a higher resolution of the feature maps. On this basis, an atrous spatial pyramid pooling (ASPP) module is proposed to extract multi-scale features from high-level semantic feature maps with high-resolution by arranging atrous convolutions with different dilation rates in parallel.
Although these methods can effectively extract multi-scale features, they still lack effective representations of low-level features (e.g., edge details) in complex scenes in HRRSIs. To remedy this deficiency, ref. [
20] proposed a Dice-based [
21] edge-aware loss function to supervise the prediction results of the segmentation network. However, it does not make use of edge features explicitly, making the representation of features less efficient. Moreover, BES-Net [
22] leverages edge information explicitly to enhance semantic features and improves intra-class consistency, thereby achieving effective prediction results concerning edge regions. It integrates edge information directly in the middle layers of the feature extraction network, which enhances the representation of edge features. However, in addition to edge information, the features of these intermediate layers also contain enormous complex and redundant features. Although explicit edge supervision can force models to optimize for object edges, they still lack an effective mined edge representation.
In addition to the edges, there are inevitably plenty of hard regions with a complex distribution of objects in urban scenes of HRRSIs. The existence of these regions seriously hinders the improvement of classification accuracy. Therefore, enhancing the feature representation capacity of the model for such regions is the key to improving the model’s overall performance. Online hard example mining (OHEM) [
23] selects and optimizes hard example points according to the loss value. PointRend [
24] uses a multilayer perceptron to re-train difficult sample points for further improvement. These methods select and optimize hard examples from the prediction logits of the model with pixels as the basic unit. Therefore, they lack an effective representation of the regional information that is difficult to classify. To put this into perspective, in the urban scenes of HRRSIs, there are widespread areas with an unbalanced distribution of objects, and they are very difficult to classify. For example, numerous multi-class objects coexist in a small residential area, while a large area such as a park is dominated by low vegetation. Therefore, sufficient and effective mining of informative features in hard regions with a complex distribution of ground objects is the key to urban scene parsing of HRRSIs. However, simply performing pixel-to-pixel mining of hard examples from the logits predicted by the network will inevitably lose important contextual information, resulting in an ineffective representation of hard regions. In this work, we managed to mine the information of hard regions from the features in the middle layers of the model. Since this information is orthogonal to edge details and multi-scale features, it can compensate for the insufficient representation of difficult regions in the model.
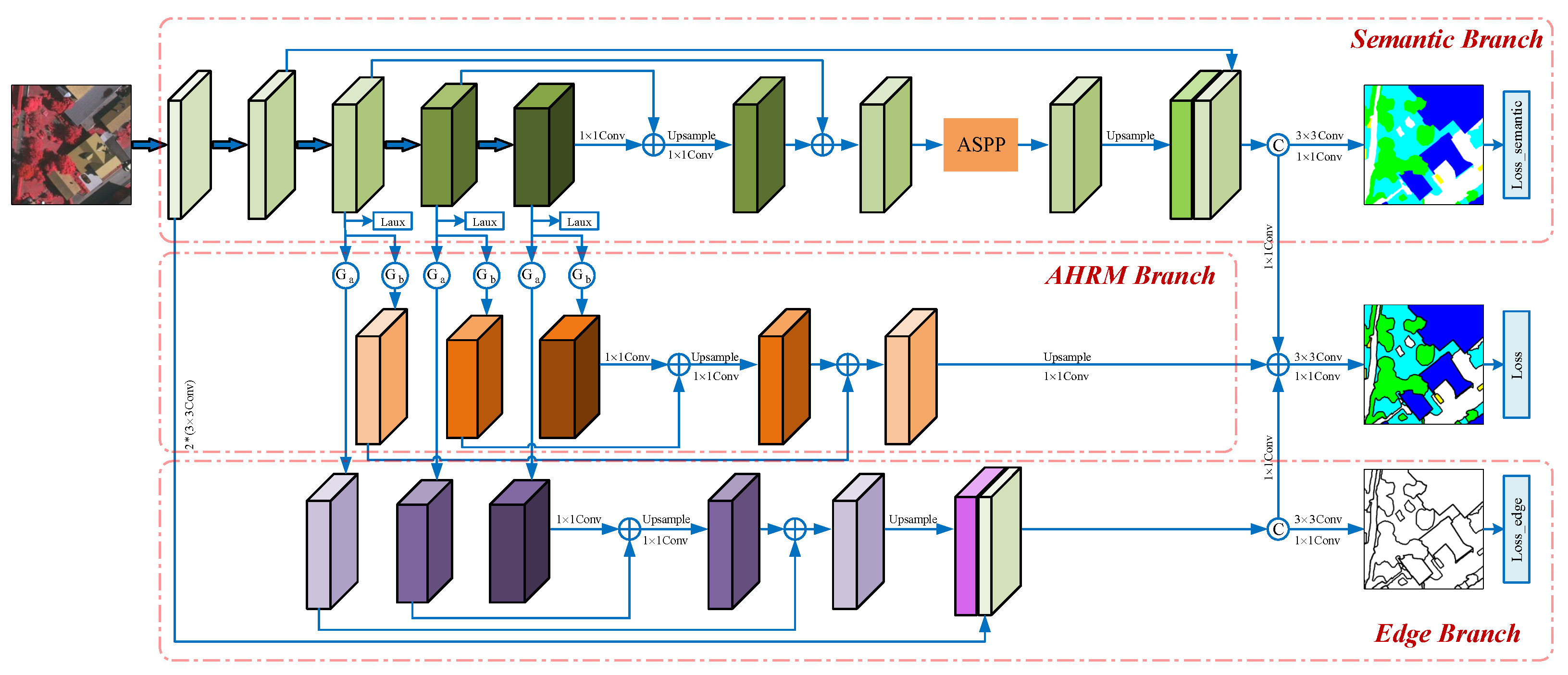
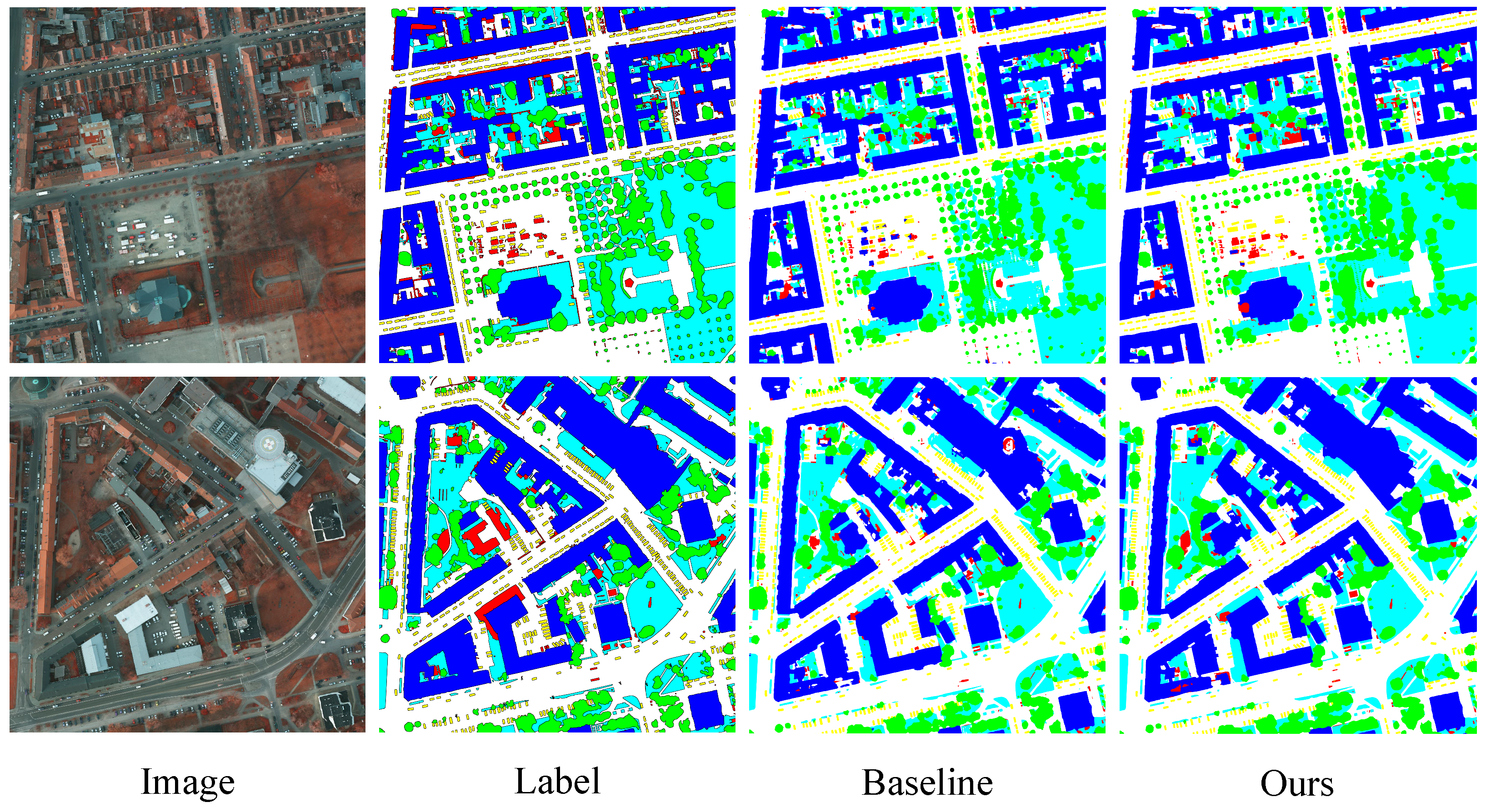
In response to the issues described above, we propose a multi-branch adaptive hard region mining network (MBANet) for parsing urban scenes in HRRSIs. The network comprises three branches: (1) the semantic branch, (2) the AHRM branch, and (3) the edge branch. Specifically, the multi-scale semantic branch is the main branch. It adopts FPN-structured ResNet50 as the backbone and then cascades the ASPP module to extract multi-scale contextual information. We propose a prediction uncertainty gating mechanism based on information entropy for the AHRM branch. Through the screening of the gating mechanism, this branch can adaptively mine the regions with strong uncertainty in the prediction results. Then, the mined hard region features are fused by FPN to obtain the representation of uncertain regions. In the edge-extraction branch, we construct another gating unit to qualitatively filter edge features in the outputs of different blocks of ResNet based on the degree of confusion of the predicted results. The gating unit can effectively filter out most redundant information except the edge features. Then, FPN is used to fuse the filtered edge features to extract the edge information of objects. At the end of this branch, we use explicit edge supervision to guide the learning of the model. The final result is obtained by summing the features of these three branches and then upsampling them to restore their resolution. Finally, we conducted appropriate experiments on two HRRSI datasets from ISPRS. The ablation experiments demonstrate that each branch is effective. Compared to prior methods, our model achieves state-of-the-art (SOTA) performance.
The main contributions of this paper are summarized as follows:
A multi-branch adaptive hard region mining network is proposed to perform urban scene parsing of HRRSIs. It consists of a multi-scale semantic branch, an AHRM branch, and an edge-extraction branch. We performed experimental validation on two HRRSI datasets from ISPRS and obtained SOTA performance;
A prediction uncertainty gating mechanism based on an entropy map is proposed. Then, an adaptive hard region mining branch is constructed based on this gating unit to adaptively mine hard regions in the images and extract their informative features;
An edge-extraction branch is constructed using the gating unit based on the predicted confusion map to filter out most of the redundant information except edge features in the output of each block of ResNet, thereby qualitatively screening edge features. Finally, an edge loss is used to supervise its training explicitly.
The remainder of this paper contains the following sections. We present related works in recent years in
Section 2. Then, we detail the MBANet in
Section 3. We present the datasets and experimental setup of our experiments in
Section 4. We analyze the branches of MBANet in detail with ablation experiments and verify the compatibility of the three branches in
Section 4.3. Furthermore, we compare the MBANet with several other methods in
Section 4.4. Finally, we summarize in
Section 5.
3. Methodology
In this section, we described the proposed method. First, the framework of MBANet is introduced. Subsequently, the structure of the semantic branch, AHRM, and edge branches are described in detail. Finally, the loss functions used in MBANet are introduced.
3.1. The Framework of MBANet
MBANet uses ResNet50 as the backbone network and replaces the normal convolution of the last block with atrous convolution to extract feature maps with higher resolution (output stride = 16). MBANet consists of three branches in parallel, namely, a semantic branch, an AHRM branch, and an edge branch, as shown in
Figure 1.
The semantic branch uses ResNet50 as the backbone to formulate an FPN for extracting hierarchical multi-scale semantic features, which are then fed to an ASPP module to capture multi-scale contextual information. Following the idea of DeepLab, the low-level features of the first block of ResNet are added to the outputs of ASPP to enrich the extracted contextual information. The AHRM branch exploits an entropy-based gating mechanism that adaptively mines hard regions from the outputs of the last three blocks of ResNet to enhance the features of these hard regions. Finally, the enhanced multi-scale feature outputs from the three blocks are integrated with FPN to obtain the salient features of hard regions. Similarly, the edge branch uses another gating mechanism based on the prediction confusion map (PCM) [
50] to explicitly extract object edges from the outputs of the last three blocks of ResNet, after which the multi-scale edge features are aggregated in FPN. Finally, to enrich the detailed spatial information, the aggregated features are combined with the features of the
convolutional layer of ResNet. The features extracted by these three branches have complementary properties. Therefore, the final features of MBANet are simply the sum of these three sets of features. The final features are passed through the
and
convolutional layers to perform classification and finally upsampled to generate prediction results. Details of each branch are described in the following subsections.
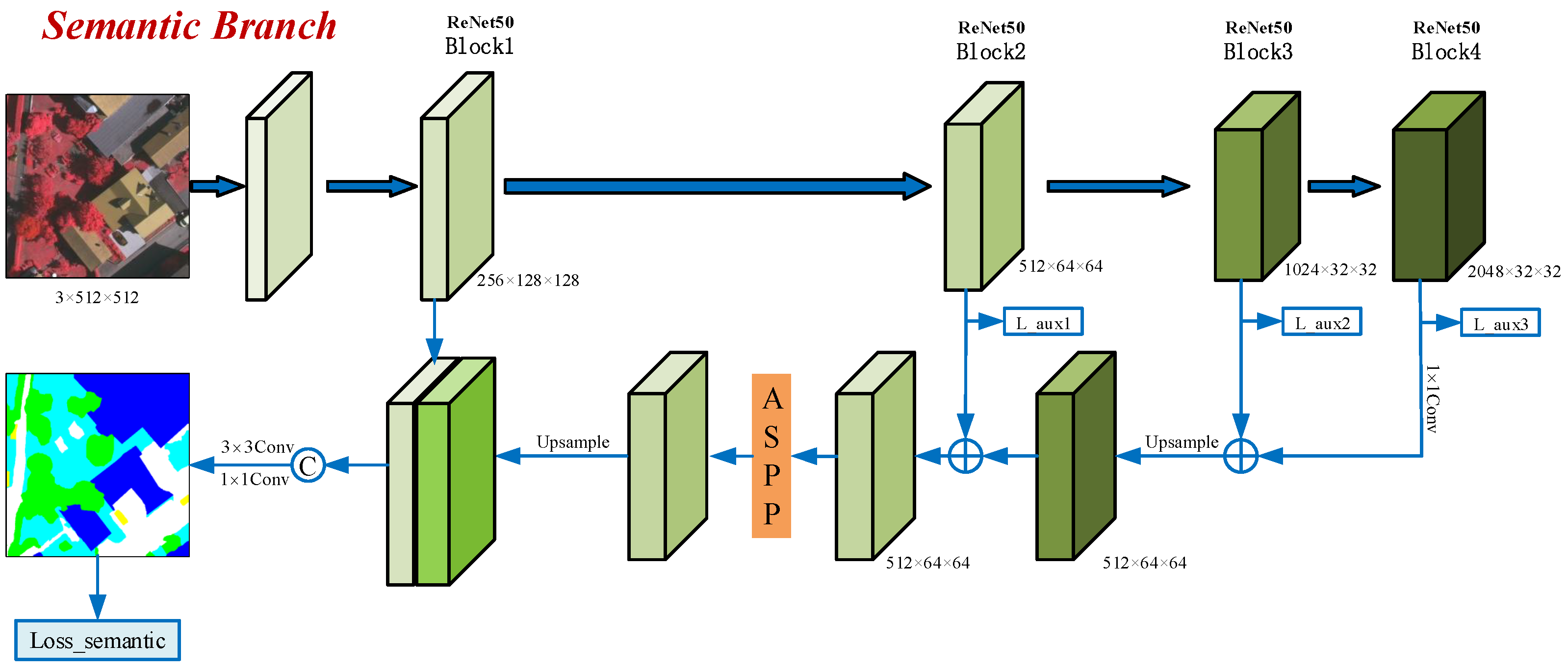
3.2. Semantic Branch
The semantic branch is the main branch of MBANet, which aims to extract multi-scale features that are very important for the accurate segmentation of objects with different scales. To balance feature representation capability, computational complexity, and memory footprint, we choose ResNet50 as the backbone network. In order to maintain an effective representation of small objects (e.g., cars), the DeepLab series [
17,
18,
19] replaces conventional convolutions in the last two blocks of ResNet with atrous convolutions (output stride = 8) to obtain high-resolution feature maps. Subsequently, the ASPP module is concatenated to capture multi-scale contextual information. To reduce memory footprint, MBANet uses atrous convolution as a substitute for the conventional convolution in the last block of ResNet (output stride = 16). Meanwhile, in order to obtain higher resolution feature maps, we utilize an FPN to aggregate the features of the last three blocks of ResNet. This approach can not only aggregate multi-scale features to a certain extent, but also increase the resolution of feature maps (equivalent to output stride = 8) while having fewer channels (1/4 of the fourth block of ResNet). Compared to the DeepLab series, this method significantly reduces the number of feature map input channels to the ASPP module, and therefore decreases computational cost and memory usage. The features obtained by the ASPP module are concatenated with those of the first block of ResNet. Then, their channels are decreased to 64 by
convolution. The final feature of MBANet is obtained by fusing the 64-channel features and the output features of the other two branches. To provide explicit supervision to the semantic branch, the 64-channel features are smoothed with
and
convolutional layers and upsampled to obtain semantic segmentation results. Lastly, the semantic loss (Loss_semantic in
Figure 2) is computed over the segmentation results and labels.
Apart from this, we utilize the feature maps of the last three blocks of ResNet to make coarse auxiliary predictions and set an auxiliary loss for each block (Loss_aux1, Loss_aux2, and Loss_aux3 in
Figure 2).
This setting serves two purposes. On one hand, it can provide deep supervision for the backbone network with the help of separately designed losses for different blocks. On the other hand, the coarse predictions in the setting act as the basis of the two gating mechanisms used in the other two branches.
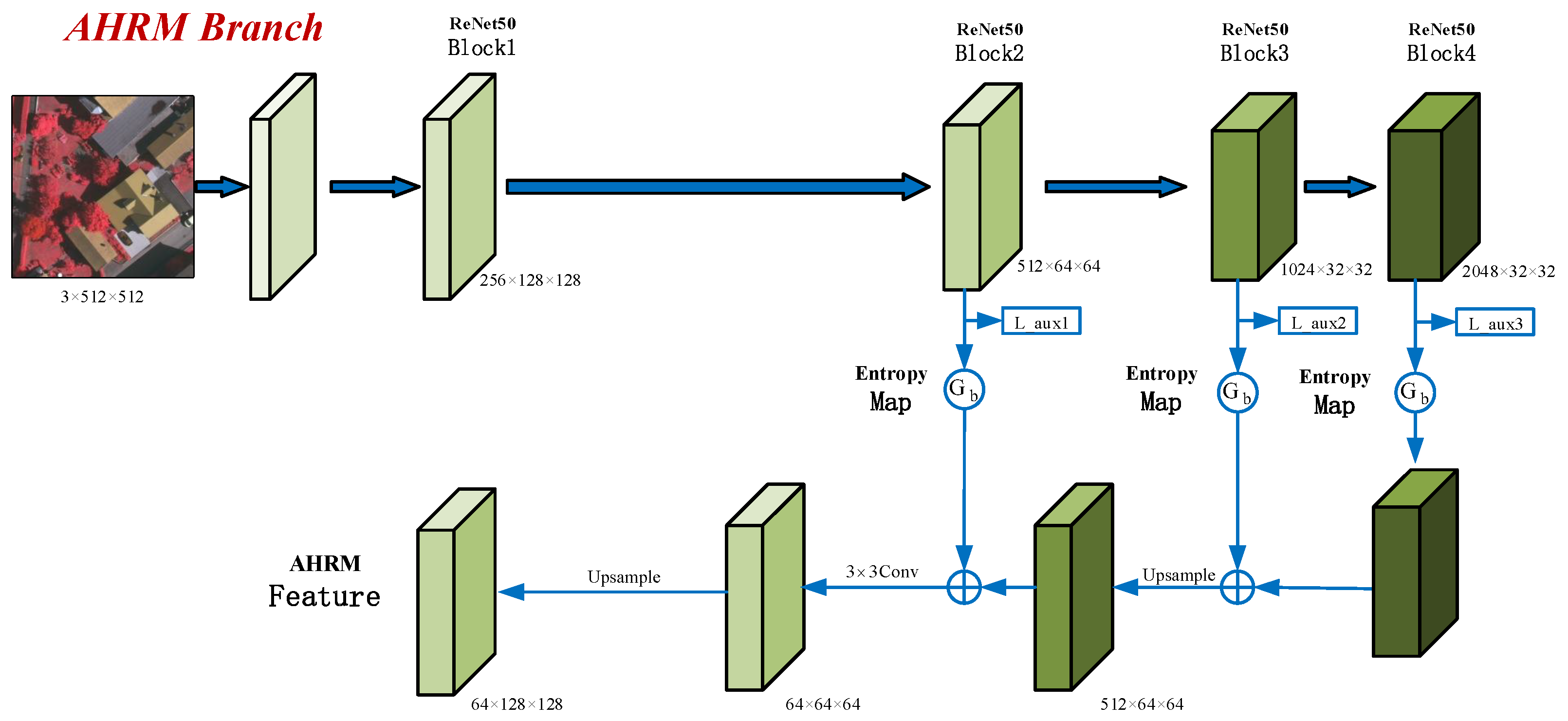
3.3. AHRM Branch
The goal of the AHRM branch is to explicitly extract the features of hard regions from the outputs of the last three blocks of ResNet as showen in
Figure 3. Therefore, effectively measuring the classification difficulty of each sample is the key to hard region mining. As mentioned above, we use the last three blocks of ResNet for coarse prediction. As with the final segmentation results, the coarse results consist of six channels at a given location, corresponding to the probabilities of the six classes in the dataset. We will use the entropy of the six channels, represented as a vector, to measure the classification difficulty of a sample, because high entropy implies low prediction stability, and vice versa.
We calculate the entropy of the three auxiliary prediction results for every pixel and thus obtain three entropy maps. Pixels with higher entropy in the maps are harder to classify. We downsample the three entropy maps to obtain the gating unit of each block. The features of each block are then multiplied by the value of the corresponding gate to highlight the features of hard regions in the image. Features of hard regions with different resolutions from the three blocks are aggregated by the FPN. Finally, the aggregated features are reduced to 64 channels by convolution and upsampled to restore their resolution. These 64-channel hard region feature maps are part of the final feature maps of MBANet.
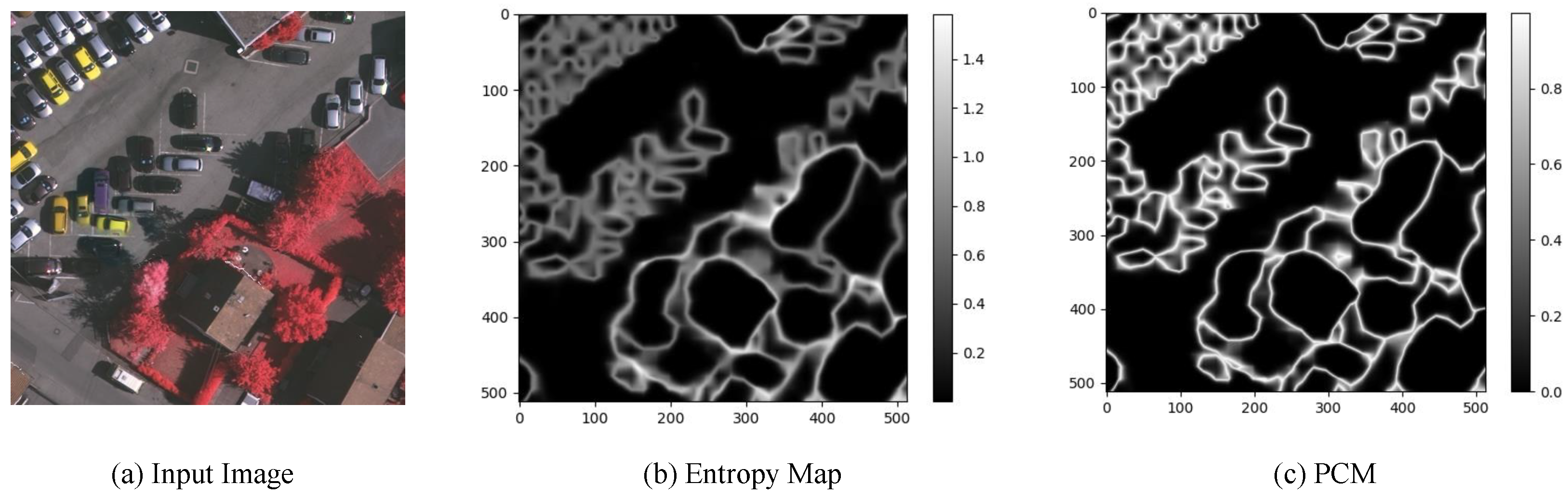
As shown in
Figure 4b, we have visualized the entropy map of the prediction results of the last block’s auxiliary branch so as to gain a deeper understanding of the method. The entropy of each pixel in this image ranges from 0 to 1.6. Observing the entropy maps of all the test images, we empirically found that the value range stabilizes in the range of (0, 1.8). Samples with higher entropy are continuously distributed around the boundary to form connected regions. The brighter regions in the image have higher entropy, which means that the prediction uncertainty for the region is higher and, therefore, more difficult to classify accurately. It can be seen that these regions are mostly distributed near the edges. Note that the upper left part of the entropy map is brighter except for the edge regions. It can be found in the input image that many cars are parked in this area. The close arrangement of these cars and the interference of shadows make it difficult to parse this area accurately. The AHRM branch uses the entropy map as a gating unit, which multiplies pixel-by-pixel feature map outputs by different blocks of ResNet so as to enhance features in hard regions while suppressing features in easy regions.
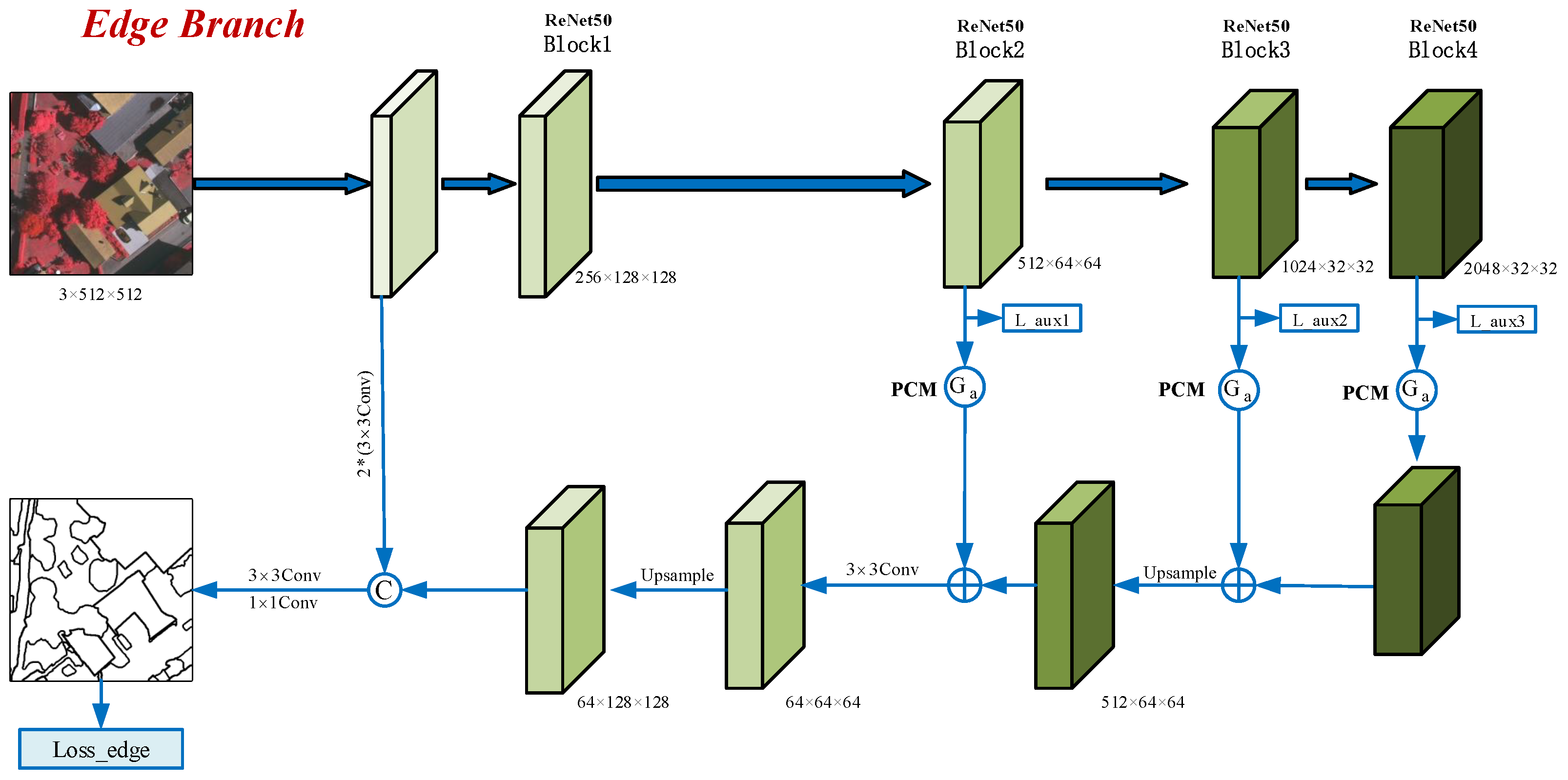
3.4. Edge Branch
It can be seen that hard regions (i.e., brighter regions in
Figure 4b) mostly cluster around the edges. These hard-to-classify regions are very difficult to train with direct supervision. In this work, we elaborately devise an edge branch to extract edge features explicitly which is shown in
Figure 5. In prior approaches, the most commonly used edge-extraction method is to learn edge information from the intermediate layers through a simple convolutional layer [
22,
44]. These learnable convolution kernels perform feature extraction on all pixels equally in the feature map and are combined with an edge loss (e.g., BCE loss) to guide model training. The method of feature learning used by these methods has a certain blindness. However, the fundamental driver for learning edge features with convolutional kernels is edge loss supervision. Therefore, in this paper, we manage to remove this blindness.
Our previous work [
50] proposed a prediction confusion map (PCM), as shown in
Figure 4c, which is generated through the following steps. (1) For a given pixel, sort the predicted logits; (2) take the difference between the top two maxima; (3) reverse this difference to obtain the prediction confusion of the pixel; (4) extend these operations to all pixels in the image to yield a PCM.
Unlike the entropy map calculation method, a PCM is obtained from only the top two maxima in the prediction logits, corresponding to the probabilities of the two most likely classes of the pixel. The PCM uses the inversion of the difference between these two maxima to measure the prediction confusion of each pixel. The smaller the difference is, the more difficult it is to classify the corresponding pixels. It is difficult to predict the brighter points of the PCM accurately because of the inversion operation. As shown in
Figure 4c, most of the highly confusing pixels are concentrated around the edges. Furthermore, compared with the ambiguous representation of edges by the entropy map of
Figure 4b, the PCM highlights the object boundaries more clearly. As a result, the PCM can effectively represent edges in prediction results. Inspired by this, we utilize a PCM as the gating unit of the edge branch to capture edge information from intermediate feature maps. The edge gating mechanism can effectively tackle the blindness of indiscriminate feature learning.
Similar to the AHRM branch, we compute the PCMs based on the predictions of the last three blocks of ResNet and downsample them as the edge-extraction gating units. The gating units are multiplied by the outputs of the corresponding blocks to extract edge information from intermediate layer features explicitly. Finally, the edge features of different resolutions are aggregated by an FPN. The features obtained by the first convolutional layer of ResNet contain many spatial details, which can make up for the insufficient representation of boundary details in the intermediate layers of ResNet. We use two convolutional layers to filter out redundant details and concatenate them with the aggregated edge features. Subsequently, their channels are reduced to 64 by a convolutional layer, and their resolution is restored by upsampling. These 64-channel edge feature maps are part of the final feature of MBANet.
To provide explicit supervision for the edge branch, we use a and a convolutional layer to obtain edge prediction results on the final edge features, and calculate the edge loss between the edge prediction and the edge labels. Specifically, since edge prediction is a binary classification task, a binary cross-entropy (BCE) loss is employed in this branch. We extract the boundaries of objects from the ground truth to construct edge labels.
3.5. Loss Function
The proposed MBANet consists of three parallel network branches. Apart from the loss of the final result, both the semantic branch and the edge branch have loss supervision. Furthermore, auxiliary losses are set for the last three blocks of the backbone network—ResNet. Therefore, the final loss (
) consists of six parts, among which the loss of the final result of the network (
), the loss of the semantic branch (
), and the other three auxiliary losses (
,
, and
) are all cross-entropy losses. A BCE loss (
) is used to supervise training in the edge branch. We set a weighting factor
to balance the proportion of auxiliary losses. Additionally, we performed ablation studies on the Vaihingen dataset, and eventually found the optimal value of
. Therefore, the final loss
is formulated as













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}