1. Introduction
Radar intra–pulse signal modulation classification is an important area in modern electronic warfare (EW) and plays a crucial role in electronic support measure (ESM) systems [
1,
2,
3]. In the modern battlefield, the quality of the intercepted radar intra–pulse signals is usually poor, and its quantity is low, causing great difficulties to the following classification task [
1].
There are mainly two categories of approaches for radar intra–pulse signal modulation classification: the traditional feature extraction–based approaches and the recent deep learning–based ones. For the first category, the algorithms usually extract some useful features from the signal before classification [
4,
5,
6,
7,
8,
9]. The feature extraction methods employed in these algorithms include time–frequency transform using short–time Fourier transform (STFT) in [
4], Choi–Williams’ time–frequency distribution in [
9], power feature extraction using Rihaczek distribution (RD) and Hough transform (HT) in [
5], integrated quadratic phase function (IQPF) and fractional Fourier transform (FrFT) in [
6], time–frequency transform using Wigner Ville distribution (WVD) and FrFT in [
7], and optimal classification atom and improved double–chains quantum genetic algorithm (IDCQGA) in [
8]. Although these algorithms perform well in some high signal–to–noise ratio (SNR) situations, they have common shortcomings. Firstly, their computation complexity is usually high, which causes a slow response from the system; secondly, the classification success rate is usually low with lower SNRs; thirdly, the identification thresholds of these algorithms are usually too sensitive to the signal parameters. These shortcomings greatly limit the practical usage of this category of algorithms.
With the fast development of deep learning techniques [
10,
11,
12], a new category of algorithms is applied to the radar intra–pulse signal modulation classification problem. Based on different domains of the signals worked on, they can be roughly divided into raw signal–based algorithms [
13,
14,
15] and time–frequency transformation–based ones [
16,
17,
18,
19,
20].
For the first class, the signal sequences are directly used as the input of the deep models, such as the network composed of convolutional neural network (CNN), long short–term memory (LSTM) network and fully connected network (FCN) in [
13]; CNN with attention mechanism model in [
14], etc. For the second class, time–frequency images are utilized as the input; for example, the model based on a convolutional autoencoder (CDAE) and CNN was proposed in [
16], CNN architecture (CNN–Xia) composed of 11 layers was used in [
18], and the deep residual network with attention mechanism was proposed in [
19]. Generally, the classification performance of the time–frequency image–based algorithms is better than that of the raw signal–based ones. However, the classification speed of the raw signal–based one is usually higher. Compared with the traditional feature extraction–based approaches, the deep learning–based solutions can overcome almost all the shortcomings of the traditional ones; however, they require a large number of well–labeled training samples. If only a small number of labeled data samples are available, the performance of these algorithms will degrade or even fail to work completely.
Few–shot learning (FSL) is proposed to solve the samples lacking a problem, which greatly relieves the burden of collecting large–scale supervised data [
21]. One of the most popular FSL methods is transfer learning [
22], which has been widely used in many fields, such as image classification [
23] and text classification [
24]. Some radar intra–pulse signal modulation classification algorithms based on transfer learning have also been proposed [
25,
26,
27,
28]. It has been found that the time–frequency image–based algorithms provide higher classification accuracy than the raw signal–based ones. In fact, the limitation of transfer learning is that a large number of labeled samples are still needed for training, although the source signals can be different from the target signals.
On the other hand, contrastive learning (CL) has also been proposed to solve the small samples problem. CL requires a large number of unlabeled samples for pretraining and a small number of labeled ones for fine–tuning, and its performance has been demonstrated in image classification [
29,
30,
31]. Although CL has been used in communication signal modulation classification [
32], its performance has not been studied in the context of radar intra–pulse modulation classification yet.
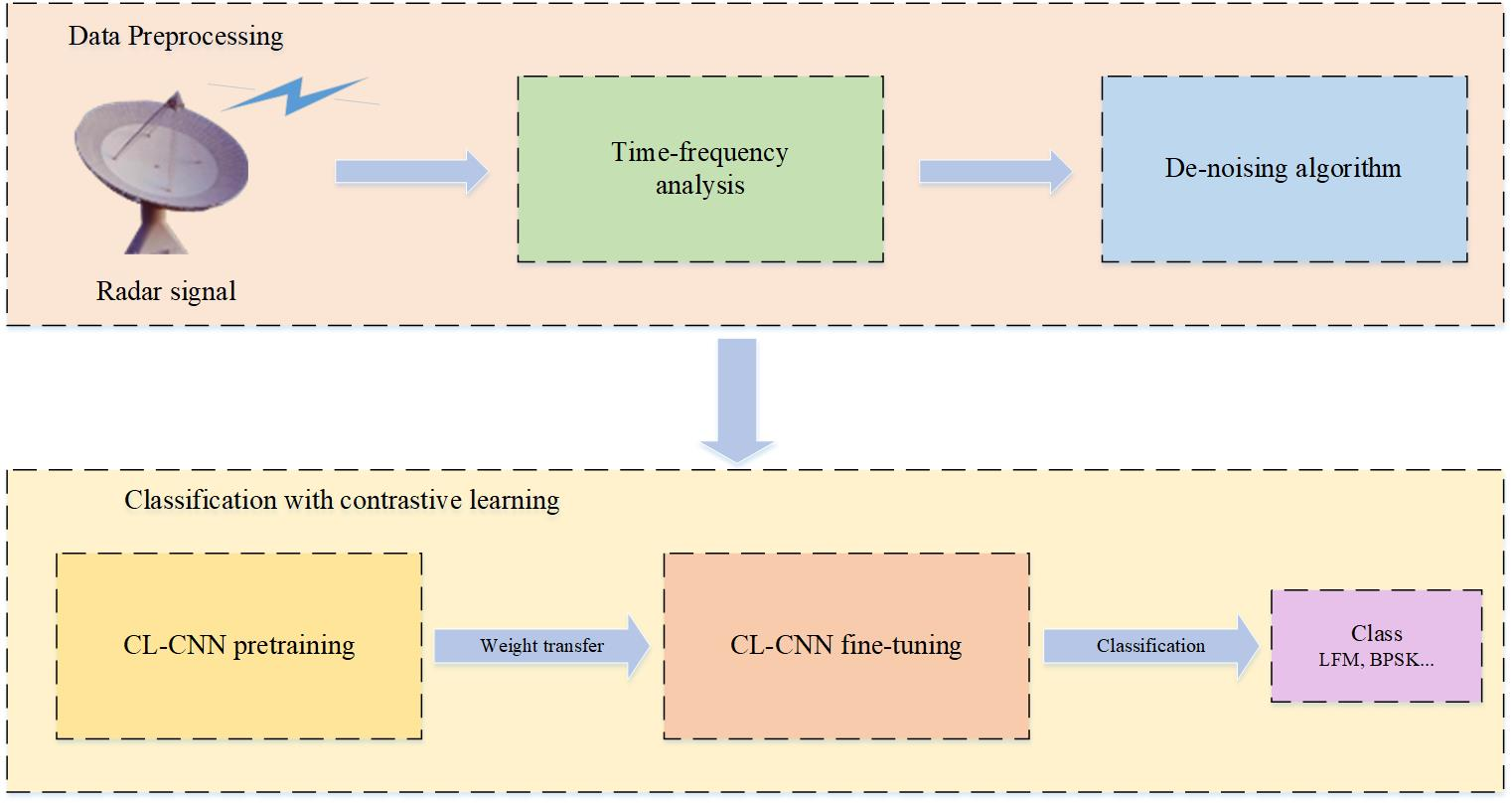
In this paper, a CL–based CNN with focal loss function (CL–CNN) model is proposed for radar intra–pulse modulation classification, which retains the core idea of CL and improves the classification accuracy with self–supervised pretraining. One common scenario in radar intra–pulse modulation classification is that the labeled samples for training are affected by white Gaussian noise, while tested samples may be affected by other types of noise. The impulsive noise may be the one having the most adverse effect on radar signals. In order to show that the CL–based model has good generalization property for different noise scenarios, in the simulation parts, the training samples are all embedded with white Gaussian noise. The simulation results show that the proposed model has better performance on classification accuracy compared with the other four deep models, i.e., AAMC–DCNN, CNN–Xia, ResNet (residual network) and SCRNN (Sequential Convolutional Recurrent Neural Network) and two traditional methods, i.e., KNN (K–Nearest Neighbor) and SVM (Support Vector Machine).
The paper is organized as follows. In
Section 2, some related works are introduced briefly. The signal preprocessing step is presented in
Section 3. In
Section 4, the CL–CNN model is provided, including an overview and detailed construction of the proposed model. The simulation results are presented in
Section 5, where the proposed model is compared with the other deep models and traditional methods, the impact of various settings for the proposed model are studied, and the generalization ability is also evaluated. Conclusions are drawn in
Section 6.
4. CL–CNN Model
4.1. Overview of the CL–CNN Model
The CL–based model needs a deep network to extract the features of images, and as CNN is widely used in image classification for its excellent feature extraction performance, it is employed in our CL–based network. The newly constructed network is called CL–CNN, and its architecture is shown in
Figure 1. There are mainly three parts in the pretraining stage, which are the stochastic data augmentation module, the encoder and the projection head. In the fine–tuning stage, the projection head is discarded, and the classification head is added after the encoder.
These parts play different roles in radar signal modulation classification. In the pretraining stage, the stochastic data augmentation module is mainly used for producing positive sample pairs and negative sample pairs, the encoder extracts representative features from data examples, the projection head maps representations to the space where the contrastive loss is applied and the classification head makes the final decision for modulation classification in the fine–tuning stage.
The training process of CL–CNN includes two steps, pretraining and fine–tuning, as shown in
Figure 1. In the pretraining step, the encoder and the projection head are pretrained with unlabeled augmented data to map the original time–frequency images into low–dimensional representations. The aim is to minimize the contrastive loss and make the features of the anchor data more similar to that of the positive data and more dissimilar to that of the negative ones.
In the fine–tuning step, the weight of the encoder is saved, and a classification head is built after it. The encoder and classification head are together trained with labeled data. The latent representation obtained from the last step has already learned the intrinsic information from the unlabeled data examples, so only a small number of labeled data is needed to fine–tune the model.
4.2. De–Noising Algorithm
A time–frequency analysis can reduce noise to some extent, but some noise still remains, especially at low SNRs. Denoising algorithms can be used to further reduce the noise in the time–frequency images. Two–dimensional Wiener filtering is one of the effective denoising algorithms that can adjust the effect of the filter according to the local variance of the image. A detailed introduction to 2D Wiener filtering is given below, and more details can be found in [
46].
Consider a 1D gray–scaled image of
pixels with value matrix
, and the value of each pixel is denoted as
. The size of a filter neighborhood is
, and the mean
and variance
of each pixel of the neighborhood can be calculated by the following equations:
where
is the filtered pixel of
and
the variance of the noise.
4.3. Data Augmentation
In this paper, the data augmentation part is implemented by random resized crop, horizontal flip and Gaussian noise. These data augmentation methods increase the diversity of the positive and negative sample pairs. In detail, ‘random resized crop’ randomly crops an area on the original image and then resizes it into a given size, and ‘horizontal flip’ flips the image horizontally. These two data augmentation methods enhance the generalization ability of the model. ‘Gaussian noise’ adds zero mean Gaussian noise to the original image, which distorts the high–frequency features and enhances the learning ability of the neural network.
Suppose the batch size of the input data is ; after data augmentation, each input sample in this batch forms a positive pair , and all remaining samples in this batch are used to form negative pairs.
4.4. Encoder
The encoder is a deep network used for feature extraction. The network cannot be too deep, as the gradient disappearance problem will appear, and the parameters of the previous layer cannot be trained effectively. The residual network (ResNet) is composed of some residual blocks, and it can alleviate the training difficulty by shortcut connections. The output of ResNet can be obtained by summing the output and input of multiple cascaded convolutional layers [
47]. There is a Rectified Linear Unit (ReLU) nonlinear activation function after each residual block. The structure of the residual block is shown in
Figure 2. It can be seen that the residual block mainly contains two
convolution layers (Conv), two batch normalization layers (BN) and three nonlinear activation function layers. For the input
, suppose
is the final output of the residual block, and it is the sum of the forward neural network
and
, i.e.,
.
4.5. Projection Head
The projection head is composed of two fully connected layers, which maps the output of the encoder to a low–dimensional feature space and helps identify the invariant features of each input. The processing steps are listed as follows.
- (1)
Calculate the output of the projection head for each input .
where
,
is the batch size,
and
are the weights of the two fully connected layers and
is the ReLU nonlinear activation function.
- (2)
Calculate the cosine similarity for each output of the projection head.
where
is the
norm, and
is the conjugate transposition operation.
- (3)
Calculate the average normalized temperature–scaled cross–entropy loss.
where
is the adjustable temperature parameter, and
is an indicator function. The value of the indicator is 0 if and only if
; otherwise, it is 1.
- (4)
Update the parameters of the encoder and projection head to minimize the loss .
4.6. Classification Head and Focal Loss Function
In the classification stage, as the parameters of the encoder have been pretrained and the projection head has been discarded, two fully connected layers are included to make the final decision on the modulation type.
In general, the cross–entropy loss function is widely used in the classification stage. However, the cross–entropy loss treats all the samples equally and does not differentiate the complicated samples and simple ones. Therefore, the classification performance may degrade due to the difficulty imbalance problem. The cross–entropy loss function can be written as
where
is the model’s estimated probability for the ground–truth class.
Compared with the cross–entropy loss function
, the focal loss function can be seen as the cross–entropy loss function with an extra adjustable parameter, which can be written as
where
is an adjustable hyperparameter.
Normally, the probability is small for difficult samples, which is and ; as a result, the focal loss does not change significantly. On the contrary, the probability of simple samples is large, so the contribution of this probability to the total loss is small. Employment of the focal loss in the classification head solves most of the difficulty imbalance problems and further improves the classification performance.
5. Simulations and Analyses
In this section, the classification performance of the CL–CNN model is compared with three deep models and two traditional methods, which are AAMC–DCNN, CNN–Xia, ResNet, SVM and KNN. The benchmark datasets are introduced, and the implementation details are introduced briefly. Then, the parameter settings of the CL–CNN model are studied, and the classification results are presented. All the simulation results are obtained by 50 trials.
5.1. Datasets
Simulations are conducted using two datasets, which contain nine types of radar intra–pulse signals shown in
Table 1 and are contaminated by Gaussian white noise and impulsive noise, separately. The parameter settings of the signals are listed in
Table 2, where
denotes the uniform random distribution of data in a fixed interval;
represents a random parameter set and
,
,
,
,
,
,
,
and
represent the sampling frequency, carrier frequency, bandwidth, number of samples, length of barker, number of carrier cycles in a single–phase symbol, number of segments, number of frequency steps and number of subcodes in a code, respectively.
The time–frequency images of four types of signals, i.e., LFM, two PSK and Frank, under white Gaussian noise and impulsive noise are shown in
Figure 3, respectively. There are clear differences between the signal images under different types of noise.
5.2. Comparisons with Deep Models and Traditional Methods
Three types of deep models and two types of traditional methods are compared with the CL–CNN model for radar intra–pulse signal modulation classification. Furthermore, the CL–CNN–CE model using the cross–entropy loss function is also considered as one comparison model, which is different from the CL–CNN model using the focal loss function. For all the deep models, the softmax activation function is used in the last layer, and the Adam optimizer and cross–entropy loss function are applied in the deep models. The details of the deep models and traditional methods are listed in
Table 3.
The AAMC–DCNN model is similar to DenseNet, but it has a dense–connection mechanism [
28]. A two–stage training strategy is adopted for the model. In the first stage, the model is pretrained on the widely used ImageNet dataset. In the second stage, the pretrained model is fine–tuned for classification using the time–frequency images of our datasets.
The CNN–Xia model contains several convolution layers, maxpooling layers and fully connected layers [
18]. There is a maxpooling layer after each convolution layer. Two fully connected layers and a dropout layer are added after the convolutional layers.
The ResNet model is a well–known deep convolutional neural network. The shortcut connections in the model can alleviate training difficulties in deeper networks without introducing either extra parameters or computational complexity. Many successful applications have been made using this model in modulation classification [
48,
49,
50].
The SCRNN (Sequential Convolutional Recurrent Neural Network) model combines the speed and lightness of the CNN and temporal sensitivity of RNN [
51]. It can be divided into three parts: the first part contains two convolutional layers with 128 filters and ReLU activation functions, the second part is two 128–unit LSTM layers with ReLU activation functions and the last part is a dense layer.
The SVM [
52] maps the input data into a high–dimensional feature space, where a linear decision surface is constructed. Different types of classes are located on different sides of the decision surface.
The KNN (K–Nearest Neighbor) follows the nearest decision rule and assigns an unclassified sample point to the nearest classified set [
53].
5.3. Implementation Details
For the first dataset, 5000 samples of each type of signals are produced for pretraining, while 85 and 1500 samples of each type of signals are produced for the fine–tuning and test, respectively. All of them are affected by Gaussian white noise. For the second dataset, 85 and 1500 samples of each type affected by impulse noise are produced to fine–tune and test the generalization ability of contrastive learning, respectively. The implementation details for the models and methods are shown in
Table 4.
The Adam optimizer with a learning rate of 0.001 is utilized. All the trainings and predictions are implemented in Pytorch.
5.4. Parameter Analyses
As the classification accuracy varies with the parameter settings, it is necessary to find the optimal parameters for the CL–CNN model. The impact of the parameter settings of the CL–CNN model is investigated below, including the adjustable parameter , the batch size and the number of CNN layers.
Figure 4 shows how the adjustable parameter
affects the classification accuracy. The value of
represents how much attention the model pays to difficult samples. A large
leads to a poor classification performance, which means that the model focuses too much on those samples. On the other hand, a small
also leads to a poor performance, which implies that the difficulty imbalance problem cannot be solved effectively, which degrades the performance of the model. It can be seen that the model with
gives the best performance, and the difficulty imbalance problem can be solved to some extent by adjusting this parameter.
The results by different batch sizes
N are shown in
Table 5, which indicates that the classification performance with batch size 32 is the best. Normally, a larger batch size will bring a better classification performance, but the performance will degrade when the batch size exceeds the threshold value [
54].
The simulation results for different numbers of layers are shown in
Table 6, which indicates that the classification performance of 34 layers is the best, with a running time of 7.72 s. Normally, a larger number of layers will increase the generalization ability and bring a better classification performance, but the performance will degrade due to the overfitting problem when the number of layers is too large.
5.5. Performance Comparisons
The classification results are presented in this subsection, including CL–CNN and CL–CNN–CE, four deep models and two traditional methods. In addition, CL–CNN–WP is also considered in the comparison, which has the same structure as CL–CNN– CE and is directly fine–tuned without pretraining. All the deep models and traditional methods are configured in their best performance. The first simulation tests the effect of denoising, the second to fifth simulations test the feature extraction ability of contrastive learning, the sixth and seventh simulations test the generalization ability and the last one is the statistical analysis. For all simulations, 1500 samples of each signal type are used for the test, and 15–85 samples of each signal type are used for fine–tuning.
In the first simulation, the performances of CL–CNN using filtered and unfiltered images as input are shown in
Table 7. The sample size for each class is set as 55. It can be seen that the method using filtered images achieves 3% to 4% more classification accuracy improvement than the one using unfiltered images at low SNRs. The comparison results indicate that the denoising algorithm is effective in reducing the effect of noise.
In the second simulation, the performances of CL–CNN, CL–CNN–CE and CL–CNN–WP are compared, and the results are shown in
Table 8. It can be seen that CL–CNN achieves 1% to 2% classification rate improvement compared with CL–CNN–CE, which implies that the focal loss function effectively solves the difficult imbalance problem to further improve the classification performance. The performance of CL–CNN–WP is the worst, especially in the case of insufficient samples. It indicates that the pretraining greatly improves both the feature extraction ability and classification performance with a limited number of samples.
In the third simulation, the performance of CL–CNN with different sample sizes for each class and SNR is presented, and the results are shown in
Table 9. The sample size for each type of signal increases from 15 to 85 with an interval of 10. It can be concluded that the proposed model exhibits good performance in a different number of samples, and the classification accuracy improves as the number of samples increases or SNR increases. When the SNR and sample size for each class are equal to or greater than −1 dB and 55, separately, the classification accuracy is more than 90%.
In the fourth simulation, the classification results of the deep models and traditional methods with the sample size per class 15 are shown in
Table 10. It can be seen that CL–CNN achieves much better classification accuracy than the other deep models and traditional methods, which indicates that CL improves the feature extraction ability of the proposed model. As the deep models, CNN–Xia, AAMC–DCNN and ResNet are based on time–frequency images, while SCRNN, SVM and KNN are based on signal sequences, the classification performances of the first three models are clearly better than those of the other three. As the architecture of AAMC–DCNN is complex and the number of samples is very small, the overfitting problem may cause degradation to its performance, and as a result, CNN–Xia performs better with a simple structure. The signal sequence–based solutions show poor performances due to low discriminating inputs; while, among them, the performance of SVM is better than that of KNN.
In the fifth simulation, the models with the sample sizes per class 55 are tested, and the results are shown in
Table 11. Although the sample size per class increases compared with that in the fourth simulation, CL–CNN still performs the best. It outperforms CNN–Xia and ResNet by nearly 4% for the whole SNR range. The performance of AAMC–DCNN has some improvement, which is comparable to CL–CNN with the SNR equal to or greater than 0 dB. The performance of SCRNN does not improve obviously when the sample size per class increases, as it may still suffer from the overfitting problem. The performance of KNN is better than that of SVM with an increased sample size for each class.
The confusion matrix is an important visual tool to compare the predicted results, which is provided in the sixth simulation. Confusion matrices of CL–CNN at various SNRs are presented in
Figure 5, where each column represents the predicted modulation class, and each row represents the real modulation class, and the numerical value on each grid denotes the classification probability of the corresponding modulation class. It can be seen that the diagonals become sharper with an increasing SNR, which illustrates that a higher SNR brings a better classification accuracy. However, confusion between Frank and P3 exists when the SNR is equal to or is lower than −5 dB, as it is difficult to distinguish their modulation features at low SNRs.
5.6. Generalization Ability Test
In the following two simulations, the Gaussian noise–affected signals are used in the first pretraining stage, and the impulsive noise–affected signals are utilized in the fine–tuning stage. As SCRNN, SVM and KNN use the signal sequence as the input, their performance is very poor in the impulsive noise scenario, so they are not included in the comparison. The classification results are presented in
Table 12 and
Table 13 with the sample size for each class set as 15 and 55, separately. It can be seen that the proposed CL–CNN has the best performance in
Table 12 and
Table 13. Generally, the performance of CL–CNN using impulsive noise–affected signals in the fine–tuning stage does not degrade much compared with that using Gaussian noise, which indicates that the proposed CL–CNN has a good generalization ability.
5.7. Statistical Analysis with McNemar’s Test
McNemar’s test is employed to evaluate the statistical significance between the CL–CNN model and some other deep models, i.e., AAMC–DCNN, CNN–Xia and ResNet. McNemar’s test can be written as
where
is defined as the number of samples misclassified by model 1 but classified successfully by model 2, while the definition of
is in contrast. A greater value of |z| means that two models have significant differences in performance.
Let CL–CNN be model 1 and AAMC–DCNN, CNN–Xia and ResNet be model 2, respectively. The values of |z| for different models are listed in
Table 14. It can be seen that the performance of the CL–CNN model is statistically different from those of comparison models.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}