1. Introduction
UAVs are widely used in national defense, agriculture, surveying and mapping, target detection, and inspection. The localization system is the basis of autonomous flight, but GNSS (Global Navigation Satellite System) is susceptible to an electromagnetic environment or interference attacks. The visual-based localization method is less affected by electromagnetic interference. Therefore, the research on visual localization is of great significance for UAVs [
1,
2,
3,
4,
5].
Image matching is the key module of the visual geo-localization method for UAVs. This method finds the local similarity between UAV and satellite images and achieves geo-localization by the geographic information stored in satellite images. Limited by the resolution of satellite images, the method is applicable to 2D localization of flight altitudes about 100–1000 m. If the flight altitude changes, the reference map images must be re-selected [
6,
7].
At present, there are two types of image-matching algorithms [
8,
9,
10,
11,
12]. The first type of method is the traditional image matching based on handcrafted features and feature descriptions. They are often designed based on corner features and blob features. Corner features can be defined as the intersection of two lines and can be searched by gradient, intensity, and contour curvature. The Harris [
13] operator is a typical feature detection method based on gradient, which uses a two-order moment matrix or auto-correlation matrix to find the directions of the fastest and lowest gray value changes. The FAST (Features from Accelerated Segment Test) [
14] detector is designed based on illumination intensity. The FAST detector is efficient with high repeatability. The ORB (Oriented FAST and Rotated BRIEF) [
15] algorithm combines the FAST detector and the BRIEF (Binary Robust Independent Elementary Features) [
16] algorithm. BRIEF is an intensity-based feature descriptor with better robustness. With the advantages of both, ORB is rotation, scale invariance, and real-time. Curvature-based Detectors use image structure to extract feature points, which is not common in practical applications.
Blob features are generally local closed regions on the image. The pixels in the region are similar and different from those in the surrounding neighborhoods. Second-order partial derivative and image segmentation are two major methods to exact blob features. SIFT (Scale-Invariant Feature Transform) [
17] and SURF (Speeded Up Robust Feature) [
18] are two representative algorithms based on the second-order partial derivative. SIFT is the most common image-matching method, which is scale-invariant and rotation-invariance. SIFT can maintain relatively high accuracy in most scenes. SURF is an improvement of SIFT, which raises the efficiency of the algorithm and can be applied in the real-time vision system. MSER (Maximally Stable Extremal Region) [
19] is a typical method based on region segmentation. It can extract stable blob features in a large range and is robust to perspective changes.
The theory of traditional methods is well-established, and the performance in ordinary scenes is also good. However, there are large differences between UAV and satellite images in terms of image quality, gradient, intensity, viewpoint, etc., resulting in great differences in the features extracted from the heterogeneous images. Therefore, stable matching cannot be established. Traditional methods are not a good choice for visual geo-localization.
Another method is based on deep learning. Different from the traditional methods, the features used in the matching method are extracted by CNN (Convolutional Neural Network). Deep learning has advantages in feature extraction and can obtain more robust semantic features. There are two types of image-matching methods based on deep learning: detector-based and detector-free. The detector-based matching methods will extract appropriate local features from the feature map to form feature points. The common extraction strategy is to select the maximum values in the channels and feature maps. Refs. [
20,
21] successfully implemented feature point extraction based on deep learning and achieved better performance than traditional methods. Ref. [
22] proposed a self-supervised training method called SuperPoint, and effectively trained a feature point extraction model. In addition, because of the excellent performance of SuperPoint, many feature point extraction models based on self-supervised have emerged [
23,
24,
25,
26,
27].
The detector-free matching methods don’t extract feature points and process the entire feature map, which can directly output dense description or matching. Ref. [
28] first proposed a detector-free matching method called SIFT Flow, using local SIFT features to achieve dense matching between images. Subsequently, refs. [
29,
30] designed a feature-matching method based on deep learning, and the nearest neighbor search is used as a post-processing step to match dense features. However, the nearest neighbor matching method is not robust enough. Ref. [
31] proposed an end-to-end matching method, which is called NCNET (Neighborhood Consensus Networks). The model realizes feature extraction and feature matching, which improves the performance of the matching algorithm. However, the efficiency of the model is not ideal. DRC-NET (Densely Connected Recurrent Convolutional Neural Network) [
32] designed a coarse-to-fine matching method to keep the matching accuracy while improving the matching efficiency.
With the application of a Transformer [
33] in machine vision, SuperGlue [
34] proposed a local feature-matching method based on the Transformer and the optimal transmission problem. SuperGlue is detector-based and takes two sets of interest points with their descriptors as input. It learns matches through graph neural networks and finally achieves impressive results, which improves image-matching precision to a new level. Ref. [
35] tried to integrate the Transformer into the detector-free matching method. They proposed LoFTR (Local Feature matching with Transformers), which uses Transformer to integrate self-attention and cross-attention into the features and gets better results on multiple datasets. MatchFormer [
36] recognizes the feature extraction ability of the Transformer and directly uses the Transformer to realize dense matching.
However, the differences between UAV and satellite images and the limitation of the computing power of the UAV platform will continue to affect the efficiency and robustness of the algorithm adversely. Some researchers have improved the deep learning method for image matching. Many works analyzed the characteristics of UAVs and satellite images and designed feature and semantic fusion models based on deep learning, and the position of UAVs is obtained by homography matrix. Liu et al. [
37] designed a localization system based on point and line features for UAV upper altitude direction estimation. Zhang et al. [
38] developed an image-matching method based on a pretrained ResNet50 (Residual Network) [
39] model. By fine-tuning the parameters, a uniform distribution of feature corresponding points can be obtained under different environments. Wen et al. [
40] recognized the disadvantage of shadow and scale in image matching and proposed an improved Wallis shadow automatic compensation method. In addition, an M-O SiamRPN (Multi-order Siamese Region Proposal Network) with weight adaptive joint MIoU (Multiple Intersection Over Union) loss functions is proposed to achieve good localization precision.
Moreover, the localization algorithm based on image retrieval is also developed gradually. Wang et al. [
41] proposed an LPN (local patterns network) for matching images of UAVs and satellites in the University-1652 [
42] dataset. LPN incorporates contextual information and adopts a rotating invariant square ring feature partitioning strategy to enable the network to locate through auxiliary targets such as houses, roads, and trees. Ding et al. [
43] proposed a cross-view matching method based on image classification and solved the imbalance problem of input sample numbers between UAV and satellite images. Zhuang et al. [
44] tried to integrate self-attention into the features, and the inference time was shortened by 30% through the multi-branch structure. However, this kind of method cannot achieve high-precision localization; it is also difficult to design the segmentation rules of the base map and the dimensions of the classifier.
Although there have been some achievements in the research of visual geo-localization for UAVs, it still needs further research on more reasonable image-matching approaches for UAV visual geo-localization. Firstly, there are a lot of weak texture and repeated texture areas in the flight scene, which caused the matching failure. Secondly, the viewpoint and scale are often different between UAVs and satellite images, which will affect the robustness of matching. Finally, the calculation power of light UAVs is always weak. To ameliorate the above limitations, a matching model based on deep learning and a matching strategy based on a perspective transformation module are proposed. Moreover, a complete localization system is designed at the same time. The main contributions of our work are summarized as follows:
A fast end-to-end feature-matching model is proposed. The model adopts the matching strategy from coarse to fine, and the minimum Euclidean distance is used to accelerate the coarse matching.
The detector-free matching method and perspective transformation module are proposed to improve the matching robustness. In addition, a transformation criterion is added to ensure the efficiency of the algorithm.
A complete visual geo-localization system is designed, including the image preprocessing module, the image matching module, and the localization module.
The remainder of this article is organized as follows.
Section 2 describes the proposed feature-matching model, perspective transformation module, and localization system. In
Section 3, the effectiveness of the proposed framework is verified using both public and self-built datasets. The discussion and conclusion are in
Section 4 and
Section 5, respectively
4. Discussion
The experimental results showed that the proposed method improves the localization precision by 12.84% and the localization efficiency by 18.75% compared with the current typical methods. The superior performance of the method can be attributed to several aspects.
Considering the computing power limitation of the UAVs, we choose resnet18 as the feature extraction backbone. In the coarse matching stage, the matching is accelerated by reducing the resolution and the minimum Euclidean distance. The ablation experiment on Hpatches shows that the minimum Euclidean distance retains 91.6% precision of the pretrained model, which greatly improves the matching efficiency at the same time. In addition, the efficiency of different methods is compared on Jetson Xavier NX. The single matching time of the proposed method is 0.65 s, which is superior to the current typical methods. In the fine-matching stage, the coordinates are refined by using high-resolution feature maps. We adopt the DSNT layer in the fine matching module, which is a differentiable numerical variation layer that can achieve sub-pixel matching precision. The experimental results on the Hpatches dataset show that our method has a precision advantage in both matching points and homography estimation.
Moreover, the experimental results showed that the method is superior in the scene of the weak texture and viewpoint change. Availability to weak texture data is attributed to the detector-free method, which estimates possible matches for all pixels to attain more stable matching points, and the transformer is used to generate a pretrained model which integrates local and global features of the image to obtain stronger feature expression. We tested the matching methods on the self-built dataset, and the results show that the proposed method achieves the most robust matching. The proposed method outputs the most matching points in the weak texture region. Moreover, our method achieves the optimal localization precision of 2.24 m. The perspective transformation module is used as image rectification to enhance the adaptability of the model to the viewpoint data. The ablation experiment on the Hpatches dataset demonstrates its effectiveness. The precision of matching points for viewpoints data is improved by 15%, while the number of matching points is increased by 1500 on average. In addition, the estimated homography matrix precision is improved by 21%. The subsequent experimental results on the ICRA dataset also show that the proposed method is robust to viewpoint changes.
However, the proposed method still needs to be improved in two aspects. According to the efficiency experimental results, the matching time of 0.65 s is still insufficient for application in real-time systems. Moreover, the results of localization experiments show that the trajectory of visual geo-localization is not smooth. Because the localization of different frames is independent of each other and the errors of the matching method are unstable. The correlation of consecutive frames should be utilized.


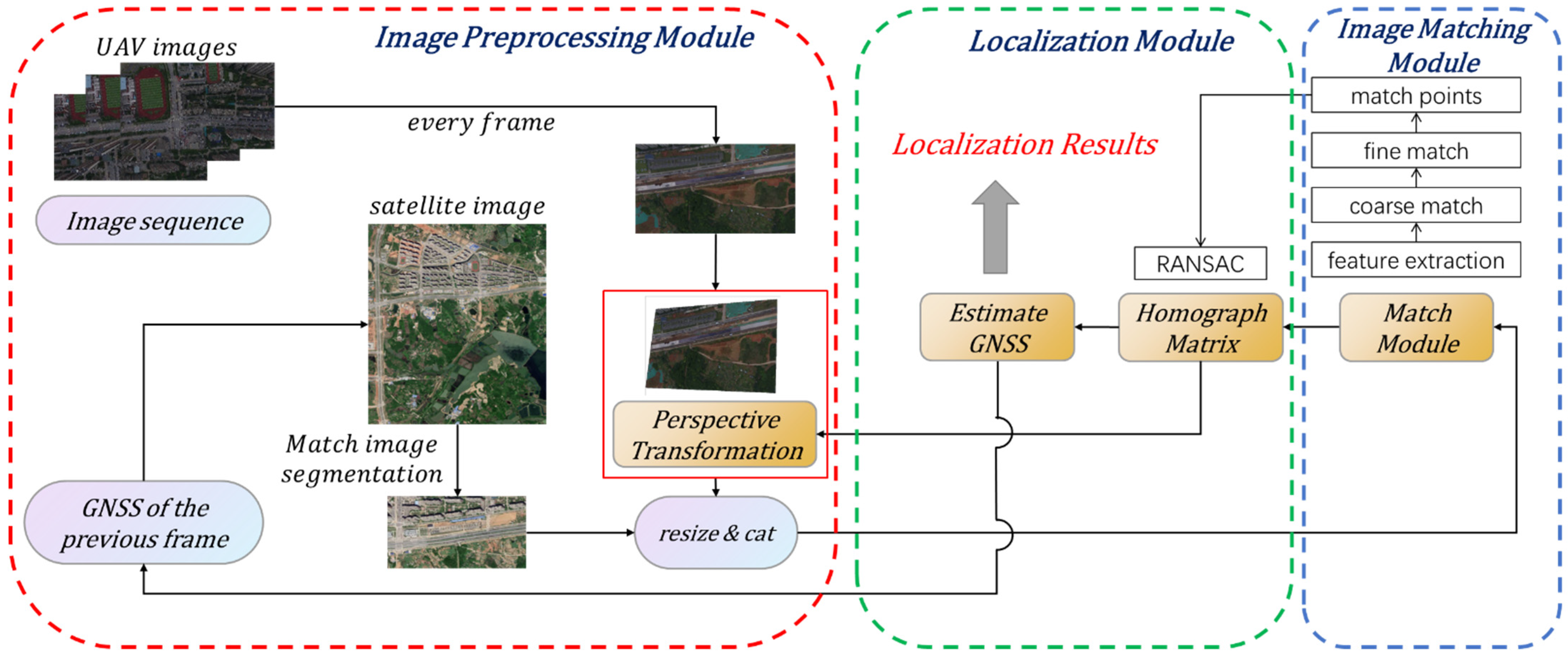
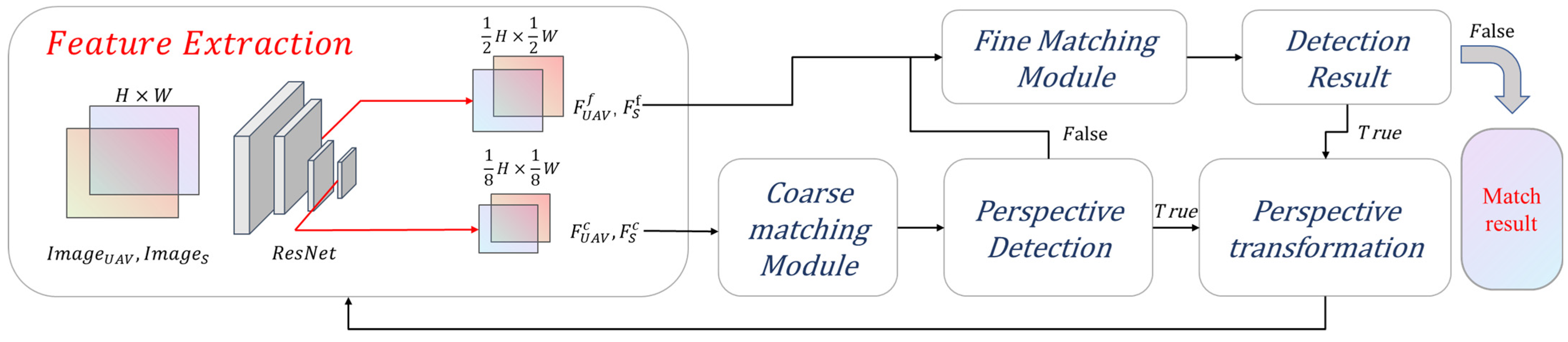











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}