
A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images—Analysis Unit, Model Scalability and Transferability



Abstract
:1. Introduction
1.1. Scope and Organization of This Paper
1.2. Existing Challenges in the Landcover Classification with VHR Images
1.2.1. Intra-Class Variability and Inter-Class Similarity for VHR Data
1.2.2. Imbalance, Inconsistency, and Lack of Quality Training Data
1.2.3. Model and Scene Transferability
1.3. Efforts of Harnessing Novel Machine Learning Applications and Multi-Source Data under the RS Contexts
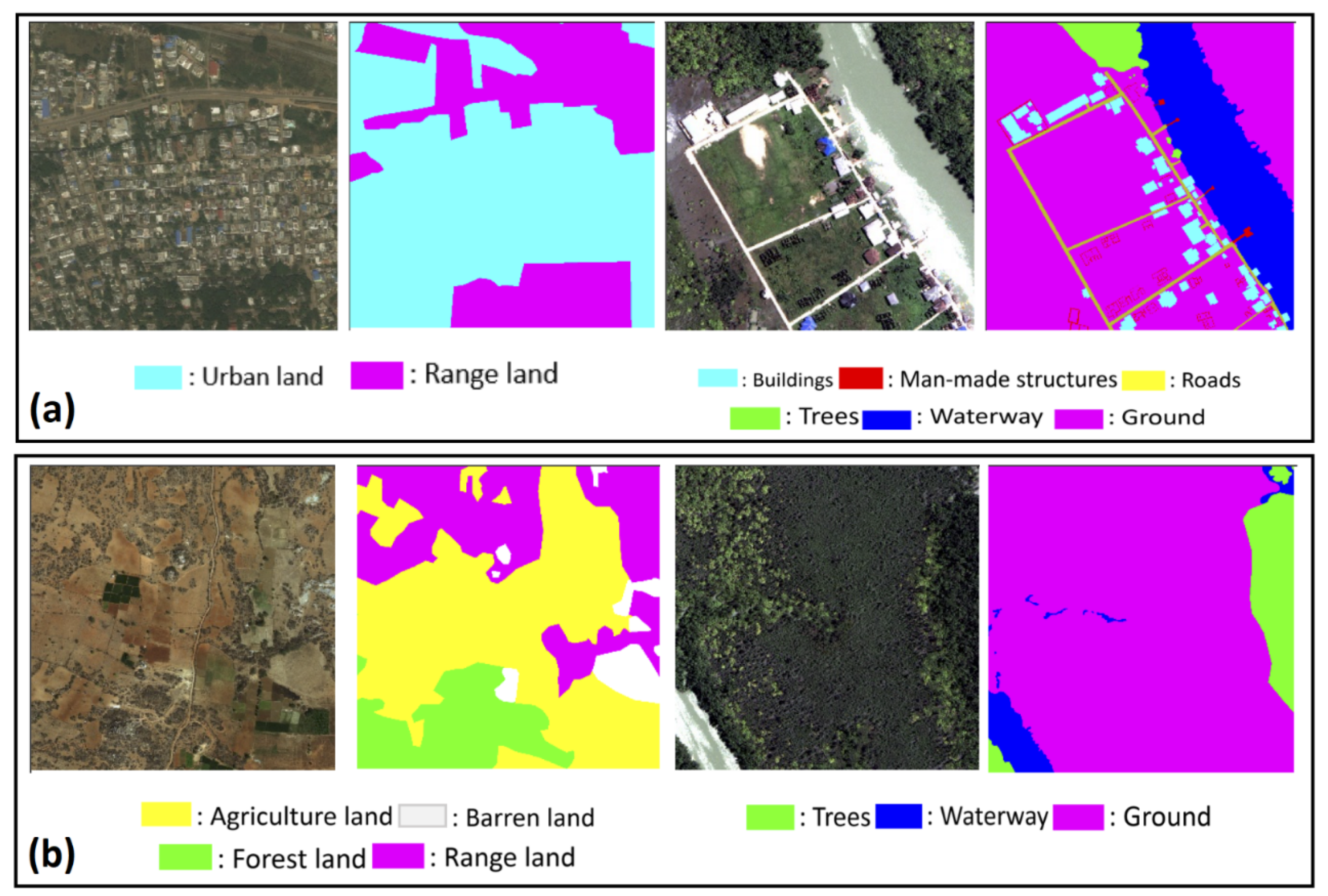
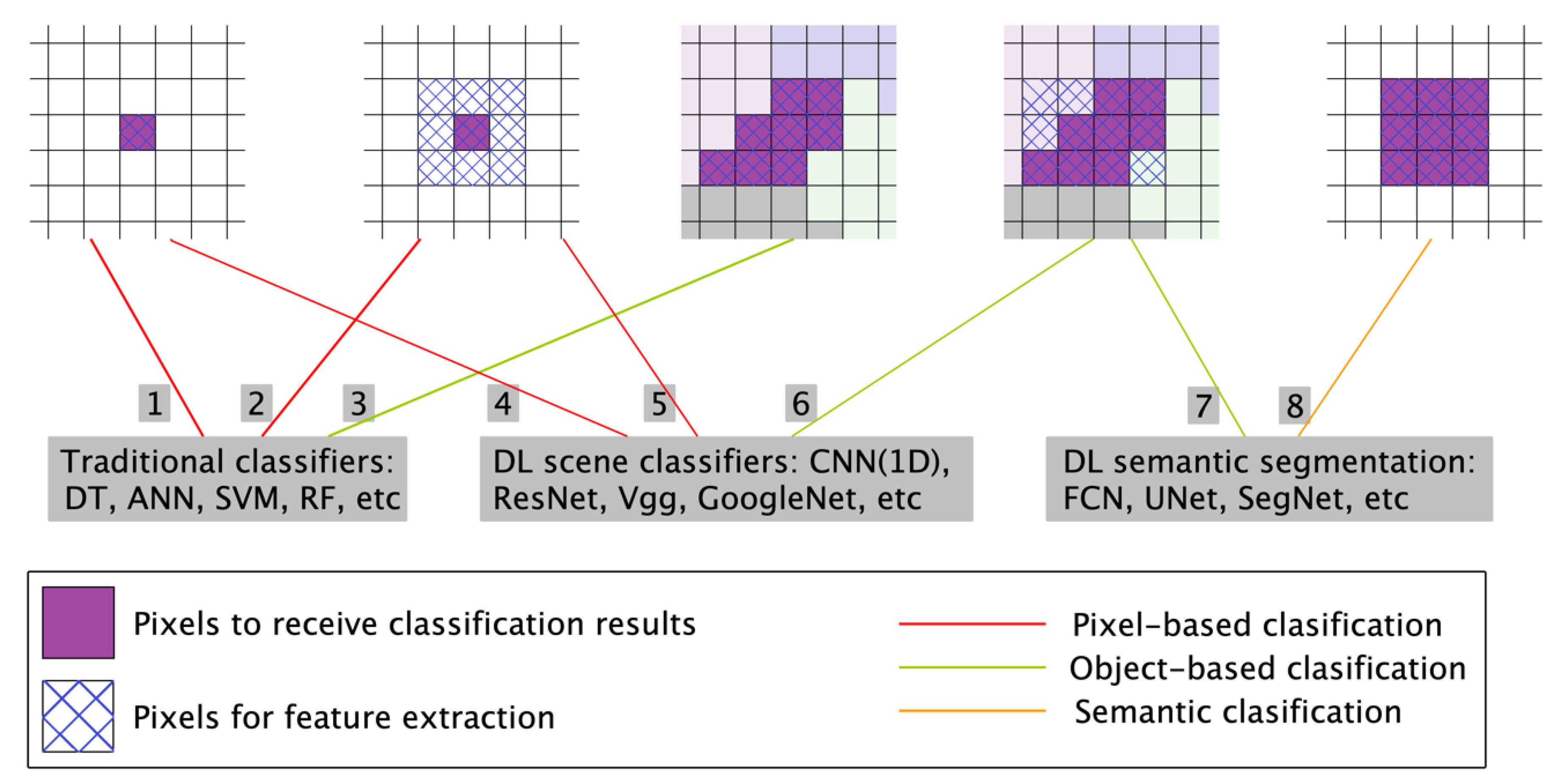
2. An Overview of Typical Landcover Classification Methods
2.1. Pixel-Based Mapping Method
2.2. Object-Based Image Analysis (OBIA)
2.3. Semantic Segmentation
3. Literature Review of Landcover Classification Methods Addressing the Data Sparsity and Scalability Challenges
3.1. Weak Supervision and Semi-Supervision for Noisy and Incomplete Training Sets
3.1.1. Incomplete Samples
3.1.2. Inexact Samples
3.1.3. Inaccurate Samples
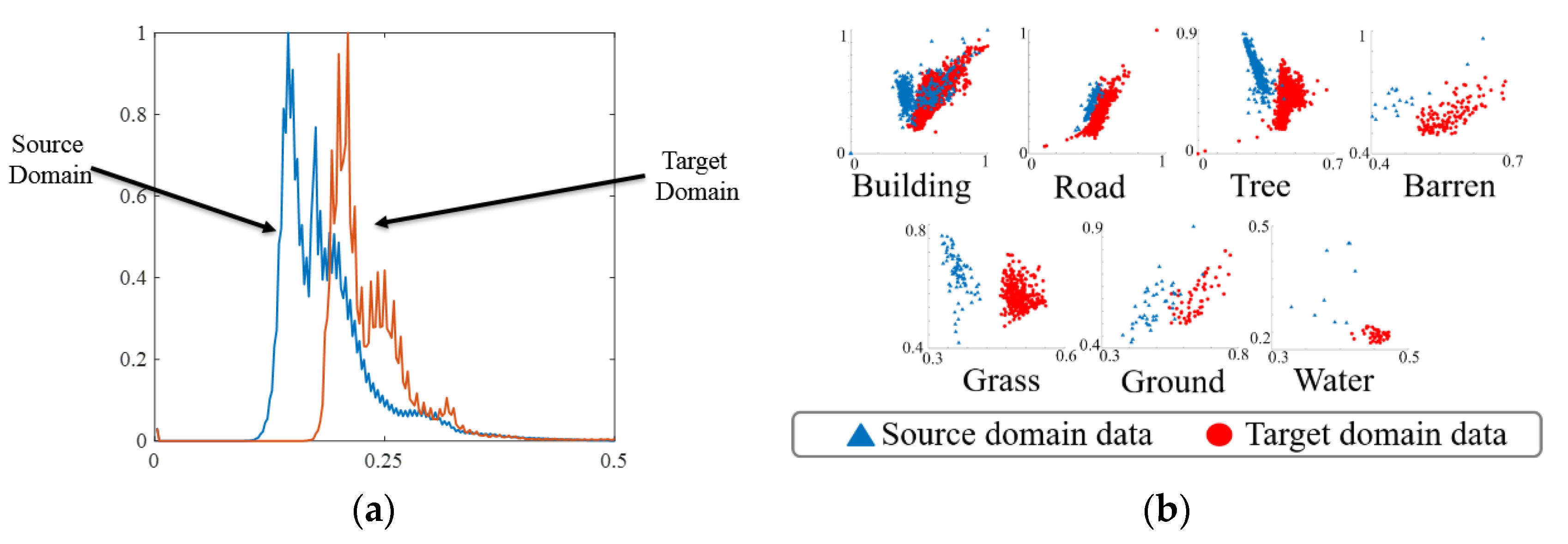
3.2. Transfer Learning and Domain Adaptation for RS Classification
3.2.1. Domain Adaptation
3.2.2. Model Fine-Tuning
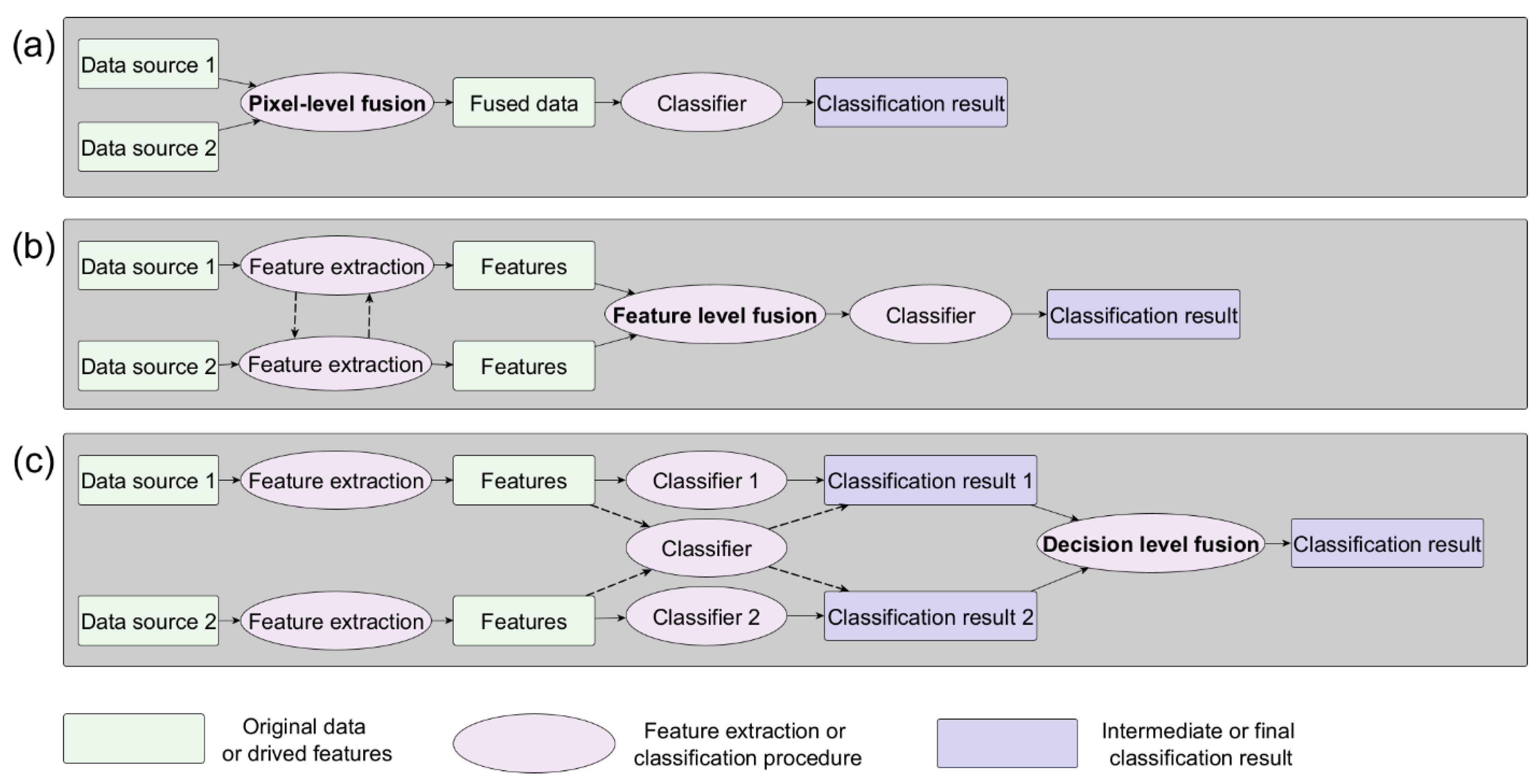
3.3. Multi-Sensor, Multi-Temporal and Multi-View Fusion
3.3.1. Pixel-Level Fusion
3.3.2. Feature-Level Fusion
3.3.3. Decision-Level Fusion
3.3.4. Multi-View Fusion
4. Final Remarks and Future Needs
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Homer, C.H.; Fry, J.A.; Barnes, C.A. The national land cover database. US Geol. Surv. Fact Sheet 2012, 3020, 1–4. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. Isprs J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef] [Green Version]
- Bello, S.A.; Yu, S.S.; Wang, C.; Adam, J.M.; Li, J. Review: Deep Learning on 3D Point Clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. Isprs J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.L.; Ye, Y.X.; Yin, G.F.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. Isprs J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study Over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef] [Green Version]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Ghanbari, H.; Mahdianpari, M.; Homayouni, S.; Mohammadimanesh, F. A Meta-Analysis of Convolutional Neural Networks for Remote Sensing Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3602–3613. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Qin, R. A mean shift vector-based shape feature for classification of high spatial resolution remotely sensed imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1974–1985. [Google Scholar] [CrossRef]
- Ghamisi, P.; Dalla Mura, M.; Benediktsson, J.A. A survey on spectral–spatial classification techniques based on attribute profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2335–2353. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Liu, W.; Qin, R. A MultiKernel Domain Adaptation Method for Unsupervised Transfer Learning on Cross-Source and Cross-Region Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4279–4289. [Google Scholar] [CrossRef]
- Cai, S.; Liu, D.; Sulla-Menashe, D.; Friedl, M.A. Enhancing MODIS land cover product with a spatial–temporal modeling algorithm. Remote Sens. Environ. 2014, 147, 243–255. [Google Scholar] [CrossRef]
- Williams, D.L.; Goward, S.; Arvidson, T. Landsat. Photogramm. Eng. Remote Sens. 2006, 72, 1171–1178. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Daly, T.M.; Nataraajan, R. Swapping bricks for clicks: Crowdsourcing longitudinal data on Amazon Turk. J. Bus. Res. 2015, 68, 2603–2609. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- SpaceNet. SpaceNet on Amazon Web Services (AWS). Available online: https://spacenet.ai/datasets/ (accessed on 1 December 2021).
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Schmitt, M.; Ahmadi, S.A.; Hänsch, R. There is no data like more data--current status of machine learning datasets in remote sensing. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Kaggle. Dstl Satellite Imagery Feature Detection. Available online: https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection (accessed on 24 May 2021).
- Burke, M.; Driscoll, A.; Lobell, D.B.; Ermon, S. Using satellite imagery to understand and promote sustainable development. Science 2021, 371, eabe8628. [Google Scholar] [CrossRef] [PubMed]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2041–2050. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, Multisource, Multitarget, and Life-Long Domain Adaptation for Semantic Segmentation of Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1067–1081. [Google Scholar] [CrossRef]
- Elshamli, A.; Taylor, G.W.; Areibi, S. Multisource domain adaptation for remote sensing using deep neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3328–3340. [Google Scholar] [CrossRef]
- Li, A.; Lu, Z.; Wang, L.; Xiang, T.; Wen, J.-R. Zero-shot scene classification for high spatial resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4157–4167. [Google Scholar] [CrossRef]
- Larochelle, H. Few-Shot Learning. In Computer Vision: A Reference Guide; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–4. [Google Scholar]
- Barrington-Leigh, C.; Millard-Ball, A. The world’s user-generated road map is more than 80% complete. PLoS ONE 2017, 12, e0180698. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Sunde, M.; Diamond, D.; Elliott, L.; Hanberry, P.; True, D. Mapping high-resolution percentage canopy cover using a multi-sensor approach. Remote Sens. Environ. 2020, 242, 111748. [Google Scholar] [CrossRef]
- Mohanaiah, P.; Sathyanarayana, P.; GuruKumar, L. Image texture feature extraction using GLCM approach. Int. J. Sci. Res. Publ. 2013, 3, 1–5. [Google Scholar]
- Chen, D.; Stow, D.; Gong, P. Examining the effect of spatial resolution and texture window size on classification accuracy: An urban environment case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Liu, S.; Qi, Z.; Li, X.; Yeh, A. Integration of Convolutional Neural Networks and Object-Based Post-Classification Refinement for Land Use and Land Cover Mapping with Optical and SAR Data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H-2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Martins, V.S.; Kaleita, A.L.; Gelder, B.K.; da Silveira, H.L.; Abe, C.A. Exploring multiscale object-based convolutional neural network (multi-OCNN) for remote sensing image classification at high spatial resolution. ISPRS J. Photogramm. Remote Sens. 2020, 168, 56–73. [Google Scholar] [CrossRef]
- Arndt, J.; Lunga, D. Large-Scale Classification of Urban Structural Units From Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2634–2648. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Jia, P.; Zhang, M.; Yu, W.; Shen, F.; Shen, Y. Convolutional neural network based classification for hyperspectral data. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5075–5078. [Google Scholar]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 705–718. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Achanta, R.; Susstrunk, S. Superpixels and polygons using simple non-iterative clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4651–4660. [Google Scholar]
- Whiteside, T.G.; Boggs, G.S.; Maier, S.W. Comparing object-based and pixel-based classifications for mapping savannas. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 884–893. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Ke, Y.; Quackenbush, L.J.; Im, J. Synergistic use of QuickBird multispectral imagery and LIDAR data for object-based forest species classification. Remote Sens. Environ. 2010, 114, 1141–1154. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atitinson, P. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A New Method for Region-Based Majority Voting CNNs for Very High Resolution Image Classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Tong, X.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Bo, Y.; Chen, J.; Tiede, D.; Blaschke, T.; Emery, W.J. Exploring semantic elements for urban scene recognition: Deep integration of high-resolution imagery and OpenStreetMap (OSM). ISPRS J. Photogramm. Remote Sens. 2019, 151, 237–250. [Google Scholar] [CrossRef]
- Mboga, N.; Georganos, S.; Grippa, T.; Lennert, M.; Vanhuysse, S.; Wolff, E. Fully Convolutional Networks and Geographic Object-Based Image Analysis for the Classification of VHR Imagery. Remote Sens. 2019, 11, 597. [Google Scholar] [CrossRef] [Green Version]
- De Luca, G.; Silva, J.M.N.; Cerasoli, S.; Araújo, J.; Campos, J.; Di Fazio, S.; Modica, G. Object-based land cover classification of cork oak woodlands using UAV imagery and Orfeo ToolBox. Remote Sens. 2019, 11, 1238. [Google Scholar] [CrossRef] [Green Version]
- Heleno, S.; Silveira, M.; Matias, M.; Pina, P. Assessment of supervised methods for mapping rainfall induced landslides in VHR images. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 850–853. [Google Scholar]
- Liu, T.; Abd-Elrahman, A. An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System. Remote Sens. 2018, 10, 457. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Abd-Elrahman, A.; Morton, J.; Wilhelm, V.L. Comparing fully convolutional networks, random forest, support vector machine, and patch-based deep convolutional neural networks for object-based wetland mapping using images from small unmanned aircraft system. GIScience Remote Sens. 2018, 55, 243–264. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A. Deep convolutional neural network training enrichment using multi-view object-based analysis of Unmanned Aerial systems imagery for wetlands classification. ISPRS J. Photogramm. Remote Sens. 2018, 139, 154–170. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A.; Dewitt, B.; Smith, S.; Morton, J.; Wilhelm, V.L. Evaluating the potential of multi-view data extraction from small Unmanned Aerial Systems (UASs) for object-based classification for Wetland land covers. GIScience Remote Sens. 2019, 56, 130–159. [Google Scholar] [CrossRef]
- Pande-Chhetri, R.; Abd-Elrahman, A.; Liu, T.; Morton, J.; Wilhelm, V.L. Object-based classification of wetland vegetation using very high-resolution unmanned air system imagery. Eur. J. Remote Sens. 2017, 50, 564–576. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Yang, L. A Fully Automatic Method for Rapidly Mapping Impacted Area by Natural Disaster. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, 26 September–2 October 2020; pp. 6906–6909. [Google Scholar]
- Liu, T.; Yang, L.; Lunga, D.D. Towards Misregistration-Tolerant Change Detection using Deep Learning Techniques with Object-Based Image Analysis. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 420–423. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. Gisci. Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Chen, T.; Qiu, C.; Schmitt, M.; Zhu, X.; Sabel, C.; Prishchepov, A. Mapping horizontal and vertical urban densification in Denmark with Landsat time-series from 1985 to 2018: A semantic segmentation solution. Remote Sens. Environ. 2020, 251, 112096. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the united states. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Wei, P.; Chai, D.; Lin, T.; Tang, C.; Du, M.; Huang, J. Large-scale rice mapping under different years based on time-series Sentinel-1 images using deep semantic segmentation model. Isprs J. Photogramm. Remote Sens. 2021, 174, 198–214. [Google Scholar] [CrossRef]
- Zhang, D.; Pan, Y.; Zhang, J.; Hu, T.; Zhao, J.; Li, N.; Chen, Q. A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution. Remote Sens. Environ. 2020, 247, 111912. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, G.; Vukomanovic, J.; Singh, K.; Liu, Y.; Holden, S.; Meentemeyer, R. Recurrent Shadow Attention Model (RSAM) for shadow removal in high-resolution urban land-cover mapping. Remote Sens. Environ. 2020, 247, 111945. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping--Challenges and Opportunities. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-3-2020, 795–802. [Google Scholar] [CrossRef]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4981–4990. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision And pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2953–2961. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Liu, X.; Huang, X. An active relearning framework for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3468–3486. [Google Scholar] [CrossRef]
- Robinson, C.; Malkin, K.; Jojic, N.; Chen, H.; Qin, R.; Xiao, C.; Schmitt, M.; Ghamisi, P.; Hänsch, R.; Yokoya, N. Global Land-Cover Mapping With Weak Supervision: Outcome of the 2020 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3185–3199. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 876–885. [Google Scholar]
- Li, H.; Wang, Y.; Xiang, S.; Duan, J.; Zhu, F.; Pan, C. A label propagation method using spatial-spectral consistency for hyperspectral image classification. Int. J. Remote Sens. 2016, 37, 191–211. [Google Scholar] [CrossRef]
- Qiao, R.; Ghodsi, A.; Wu, H.; Chang, Y.; Wang, C. Simple weakly supervised deep learning pipeline for detecting individual red-attacked trees in VHR remote sensing images. Remote Sens. Lett. 2020, 11, 650–658. [Google Scholar] [CrossRef]
- Wei, Y.; Ji, S. Scribble-Based Weakly Supervised Deep Learning for Road Surface Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602312. [Google Scholar] [CrossRef]
- Carlson, T.N.; Ripley, D.A. On the relation between NDVI, fractional vegetation cover, and leaf area index. Remote Sens. Environ. 1997, 62, 241–252. [Google Scholar] [CrossRef]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Gao, B.-C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Immitzer, M.; Neuwirth, M.; Böck, S.; Brenner, H.; Vuolo, F.; Atzberger, C. Optimal input features for tree species classification in Central Europe based on multi-temporal Sentinel-2 data. Remote Sens. 2019, 11, 2599. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Ma, J.; Lv, X.; Chen, D. Hierarchical weakly supervised learning for residential area semantic segmentation in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 117–121. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Luo, N.; Wan, T.; Hao, H.; Lu, Q. Fusing high-spatial-resolution remotely sensed imagery and OpenStreetMap data for land cover classification over urban areas. Remote Sens. 2019, 11, 88. [Google Scholar] [CrossRef] [Green Version]
- Wan, T.; Lu, H.; Lu, Q.; Luo, N. Classification of high-resolution remote-sensing image using openstreetmap information. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2305–2309. [Google Scholar] [CrossRef]
- Comandur, B.; Kak, A.C. Semantic Labeling of Large-Area Geographic Regions Using Multi-View and Multi-Date Satellite Images, and Noisy OSM Training Labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4573–4594. [Google Scholar] [CrossRef]
- Zhang, R.; Albrecht, C.; Zhang, W.; Cui, X.; Finkler, U.; Kung, D.; Lu, S. Map Generation from Large Scale Incomplete and Inaccurate Data Labels. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 6–10 July 2020; pp. 2514–2522. [Google Scholar]
- Wang, S.; Di Tommaso, S.; Faulkner, J.; Friedel, T.; Kennepohl, A.; Strey, R.; Lobell, D.B. Mapping crop types in southeast india with smartphone crowdsourcing and deep learning. Remote Sens. 2020, 12, 2957. [Google Scholar] [CrossRef]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer learning via dimensionality reduction. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008; pp. 677–682. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 8–12 April 2013; pp. 2200–2207. [Google Scholar]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised transfer component analysis for domain adaptation in remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–450. [Google Scholar]
- Liu, W.; Su, F.; Jin, X.; Li, H.; Qin, R. Bispace Domain Adaptation Network for Remotely Sensed Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. Colormapgan: Unsupervised domain adaptation for semantic segmentation using color mapping generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wang, D.; Luo, M. Generative Adversarial Network-Based Full-Space Domain Adaptation for Land Cover Classification From Multiple-Source Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3816–3828. [Google Scholar] [CrossRef]
- Zou, M.; Zhong, Y. Transfer learning for classification of optical satellite image. Sens. Imaging 2018, 19, 6. [Google Scholar] [CrossRef]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large scale high-resolution land cover mapping with multi-resolution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12726–12735. [Google Scholar]
- Laurin, G.V.; Liesenberg, V.; Chen, Q.; Guerriero, L.; Del Frate, F.; Bartolini, A.; Coomes, D.; Wilebore, B.; Lindsell, J.; Valentini, R. Optical and SAR sensor synergies for forest and land cover mapping in a tropical site in West Africa. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 7–16. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Zhang, Q.; Qin, R.; Huang, X.; Fang, Y.; Liu, L. Classification of Ultra-High Resolution Orthophotos Combined with DSM Using a Dual Morphological Top Hat Profile. Remote Sens. 2015, 7, 16422–16440. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.; Kobayashi, N.; Mochizuki, K.-I. Crop classification from Sentinel-2-derived vegetation indices using ensemble learning. J. Appl. Remote Sens. 2018, 12, 026019. [Google Scholar] [CrossRef] [Green Version]
- Gerstmann, H.; Möller, M.; Gläßer, C. Optimization of spectral indices and long-term separability analysis for classification of cereal crops using multi-spectral RapidEye imagery. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 115–125. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey. 2009. Available online: http://digital.library.wisc.edu/1793/60660 (accessed on 15 November 2021).
- Luo, T.; Kramer, K.; Goldgof, D.B.; Hall, L.O.; Samson, S.; Remsen, A.; Hopkins, T.; Cohn, D. Active learning to recognize multiple types of plankton. J. Mach. Learn. Res. 2005, 6, 589–613. [Google Scholar]
- Tuia, D.; Pasolli, E.; Emery, W.J. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. arXiv 2016, arXiv:1606.04080. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep meta metric learning for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6983–6994. [Google Scholar] [CrossRef]
- Cheng, G.; Cai, L.; Lang, C.; Yao, X.; Chen, J.; Guo, L.; Han, J. SPNet: Siamese-prototype network for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5608011. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7844–7853. [Google Scholar] [CrossRef]
- Tingzon, I.; Orden, A.; Go, K.; Sy, S.; Sekara, V.; Weber, I.; Fatehkia, M.; García-Herranz, M.; Kim, D. Mapping poverty in the Philippines using machine learning, satellite imagery, and crowd-sourced geospatial information. In Proceedings of the AI for Social Good ICML 2019 Workshop, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Daumé III, H. Frustratingly easy domain adaptation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 256–263. [Google Scholar]
- Deng, X.; Zhu, Y.; Tian, Y.; Newsam, S. Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 5–9 January 2021; pp. 2160–2169. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- ISPRS. ISPRS Semantic Labeling Benchmark Dataset. Available online: http://www2.isprs.org/commissions/comm3/wg4/3d-semantic-labeling.html (accessed on 18 April 2018).
- Christie, G.; Fendley, N.; Wilson, J.; Mukherjee, R. Functional map of the world. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6172–6180. [Google Scholar]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Ericsson, L.; Gouk, H.; Hospedales, T.M. How Well Do Self-Supervised Models Transfer? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5414–5423. [Google Scholar]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-optical fusion for crop type mapping using deep learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Witharana, C.; Bhuiyan, M.; Liljedahl, A.; Kanevskiy, M.; Epstein, H.; Jones, B.; Daanen, R.; Griffin, C.; Kent, K.; Jones, M. Understanding the synergies of deep learning and data fusion of multispectral and panchromatic high resolution commercial satellite imagery for automated ice-wedge polygon detection. Isprs J. Photogramm. Remote Sens. 2020, 170, 174–191. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ma, W.; Shen, J.; Zhu, H.; Zhang, J.; Zhao, J.; Hou, B.; Jiao, L. A Novel Adaptive Hybrid Fusion Network for Multiresolution Remote Sensing Images Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5400617. [Google Scholar] [CrossRef]
- Vivone, G.; Dalla Mura, M.; Garzelli, A.; Restaino, R.; Scarpa, G.; Ulfarsson, M.; Alparone, L.; Chanussot, J. A New Benchmark Based on Recent Advances in Multispectral Pansharpening: Revisiting Pansharpening With Classical and Emerging Pansharpening Methods. Ieee Geosci. Remote Sens. Mag. 2021, 9, 53–81. [Google Scholar] [CrossRef]
- Meng, X.; Xiong, Y.; Shao, F.; Shen, H.; Sun, W.; Yang, G.; Yuan, Q.; Fu, R.; Zhang, H. A Large-Scale Benchmark Data Set for Evaluating Pansharpening Performance: Overview and Implementation. Ieee Geosci. Remote Sens. Mag. 2021, 9, 18–52. [Google Scholar] [CrossRef]
- Loncan, L.; De Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simoes, M. Hyperspectral pansharpening: A review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Hong, D.; Zhu, X. MIMA: MAPPER-Induced Manifold Alignment for Semi-Supervised Fusion of Optical Image and Polarimetric SAR Data. Ieee Trans. Geosci. Remote Sens. 2019, 57, 9025–9040. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of Landsat-8 and Sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and Multitemporal Data Fusion in Remote Sensing A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef] [Green Version]
- Jia, S.; Zhan, Z.; Zhang, M.; Xu, M.; Huang, Q.; Zhou, J.; Jia, X. Multiple Feature-Based Superpixel-Level Decision Fusion for Hyperspectral and LiDAR Data Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1437–1452. [Google Scholar] [CrossRef]
- Hoffman-Hall, A.; Loboda, T.V.; Hall, J.V.; Carroll, M.L.; Chen, D. Mapping remote rural settlements at 30 m spatial resolution using geospatial data-fusion. Remote Sens. Environ. 2019, 233, 111386. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.; Ghamisi, P.; Jia, X.; Gu, Y. Deep Fusion of Remote Sensing Data for Accurate Classification. Ieee Geosci. Remote Sens. Lett. 2017, 14, 1253–1257. [Google Scholar] [CrossRef]
- Cao, R.; Tu, W.; Yang, C.; Li, Q.; Liu, J.; Zhu, J.; Zhang, Q.; Li, Q.; Qiu, G. Deep learning-based remote and social sensing data fusion for urban region function recognition. Isprs J. Photogramm. Remote Sens. 2020, 163, 82–97. [Google Scholar] [CrossRef]
- Zhu, H.; Ma, W.; Li, L.; Jiao, L.; Yang, S.; Hou, B. A Dual–Branch Attention fusion deep network for multiresolution remote–Sensing image classification. Inf. Fusion 2020, 58, 116–131. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Stein, A. Fusenet: End-to-end multispectral vhr image fusion and classification. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2091–2094. [Google Scholar]
- Quan, L.; Li, H.; Li, H.; Jiang, W.; Lou, Z.; Chen, L. Two-Stream Dense Feature Fusion Network Based on RGB-D Data for the Real-Time Prediction of Weed Aboveground Fresh Weight in a Field Environment. Remote Sens. 2021, 13, 2288. [Google Scholar] [CrossRef]
- Qin, N.; Hu, X.; Dai, H. Deep fusion of multi-view and multimodal representation of ALS point cloud for 3D terrain scene recognition. ISPRS J. Photogramm. Remote Sens. 2018, 143, 205–212. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Weikmann, G.; Paris, C.; Bruzzone, L. TimeSen2Crop: A Million Labeled Samples Dataset of Sentinel 2 Image Time Series for Crop-Type Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4699–4708. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Russwurm, M.; Korner, M. Self-attention for raw optical Satellite Time Series Classification. Isprs J. Photogramm. Remote Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247. [Google Scholar] [CrossRef]
- Zhang, G.; Ghamisi, P.; Zhu, X.X. Fusion of heterogeneous earth observation data for the classification of local climate zones. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7623–7642. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A. Multi-view object-based classification of wetland land covers using unmanned aircraft system images. Remote Sens. Environ. 2018, 216, 122–138. [Google Scholar] [CrossRef]
- Ahmad, S.K.; Hossain, F.; Eldardiry, H.; Pavelsky, T.M. A fusion approach for water area classification using visible, near infrared and synthetic aperture radar for South Asian conditions. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2471–2480. [Google Scholar] [CrossRef]
- Matasci, G.; Longbotham, N.; Pacifici, F.; Kanevski, M.; Tuia, D. Understanding angular effects in VHR imagery and their significance for urban land-cover model portability: A study of two multi-angle in-track image sequences. ISPRS J. Photogramm. Remote Sens. 2015, 107, 99–111. [Google Scholar] [CrossRef]
- Yan, Y.; Deng, L.; Liu, X.; Zhu, L. Application of UAV-Based Multi-angle Hyperspectral Remote Sensing in Fine Vegetation Classification. Remote Sens. 2019, 11, 2753. [Google Scholar] [CrossRef] [Green Version]
- de Colstoun, E.C.B.; Walthall, C.L. Improving global scale land cover classifications with multi-directional POLDER data and a decision tree classifier. Remote Sens. Environ. 2006, 100, 474–485. [Google Scholar] [CrossRef]
- Su, L.; Chopping, M.J.; Rango, A.; Martonchik, J.V.; Peters, D.P. Support vector machines for recognition of semi-arid vegetation types using MISR multi-angle imagery. Remote Sens. Environ. 2007, 107, 299–311. [Google Scholar] [CrossRef]
- Mahtab, A.; Sridhar, V.; Navalgund, R.R. Impact of surface anisotropy on classification accuracy of selected vegetation classes: An evaluation using multidate multiangular MISR data over parts of Madhya Pradesh, India. IEEE Trans. Geosci. Remote Sens. 2008, 46, 250–258. [Google Scholar] [CrossRef]
- Koukal, T.; Atzberger, C.; Schneider, W. Evaluation of semi-empirical BRDF models inverted against multi-angle data from a digital airborne frame camera for enhancing forest type classification. Remote Sens. Environ. 2014, 151, 27–43. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.J.; Pacifici, F. Very high resolution multiangle urban classification analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1155–1170. [Google Scholar] [CrossRef]
- Huang, X.; Chen, H.; Gong, J. Angular difference feature extraction for urban scene classification using ZY-3 multi-angle high-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2018, 135, 127–141. [Google Scholar] [CrossRef]
- Huang, X.; Yang, J.; Li, J.; Wen, D. Urban functional zone mapping by integrating high spatial resolution nighttime light and daytime multi-view imagery. Isprs J. Photogramm. Remote Sens. 2021, 175, 403–415. [Google Scholar] [CrossRef]
- Liu, C.; Huang, X.; Zhu, Z.; Chen, H.; Tang, X.; Gong, J. Automatic extraction of built-up area from ZY3 multi-view satellite imagery: Analysis of 45 global cities. Remote Sens. Environ. 2019, 226, 51–73. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Descriptions | Application Scenario in RS Data | Examples of Relevant Works |
|---|---|---|---|
| Weakly supervised/Semi-supervised learning | Semi-supervised learning aims to address tasks where a small set of labeled data and a large amount of unlabeled data are available, while Weak supervision assumes the labeled data to be noisy and contain errors, and the learning methods consider the uncertainty level of the available label information. In RS, this is often mixed-used with semi-automation. The readers may refer to the explanations in the texts | In RS classification, the noisy inputs are categorized as the following three types:
| [20,36,74,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116] |
| Transfer learning and domain adaptation | Transfer learning (TL) is defined as transferring learned knowledge from one task to the other, normally by understanding the distribution of the feature space are different and need to be aligned through domain adaptation methods. | In RS, TL is normally defined as transferring knowledge (e.g., for classification) learned from one dataset and applied to another dataset that is drastically different in geographical location, or captured by different sensors/platforms. This also includes cases where deep models need to be fine-tuned given sparsely labeled data for training. | [20,117,118,119,120,121,122,123,124,125,126] |
| Multi-Modal and Multi-view learning | Data fusion methods are general approaches that utilize multiple coherent data sources or labels for performing classification tasks. Multi-view image-based learning is a subset of data fusion approaches that utilize the redundancies of multi-angular images to enhance the learning and is less covered in the literature, which this section will focus on. | Data fusion approaches are widely applicable since multi-modality remotely sensed such as SAR, optical, and LiDAR data, as well as multi-resolution, multi-sensor and multi-view data. The use of multi-view/multi-angular data is very common in photogrammetric collections. Using multi-view images enhances augments information of an area of interest and hence improves the accuracies. | [80,127,128,129,130] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, R.; Liu, T. A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images—Analysis Unit, Model Scalability and Transferability. Remote Sens. 2022, 14, 646. https://doi.org/10.3390/rs14030646
Qin R, Liu T. A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images—Analysis Unit, Model Scalability and Transferability. Remote Sensing. 2022; 14(3):646. https://doi.org/10.3390/rs14030646
Chicago/Turabian StyleQin, Rongjun, and Tao Liu. 2022. "A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images—Analysis Unit, Model Scalability and Transferability" Remote Sensing 14, no. 3: 646. https://doi.org/10.3390/rs14030646
APA StyleQin, R., & Liu, T. (2022). A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images—Analysis Unit, Model Scalability and Transferability. Remote Sensing, 14(3), 646. https://doi.org/10.3390/rs14030646