
Tropical Cyclone Intensity Estimation Using Himawari-8 Satellite Cloud Products and Deep Learning



Abstract
:1. Introduction
2. Data and Methods
2.1. Himawari-8 Geostationary Satellite Cloud Products
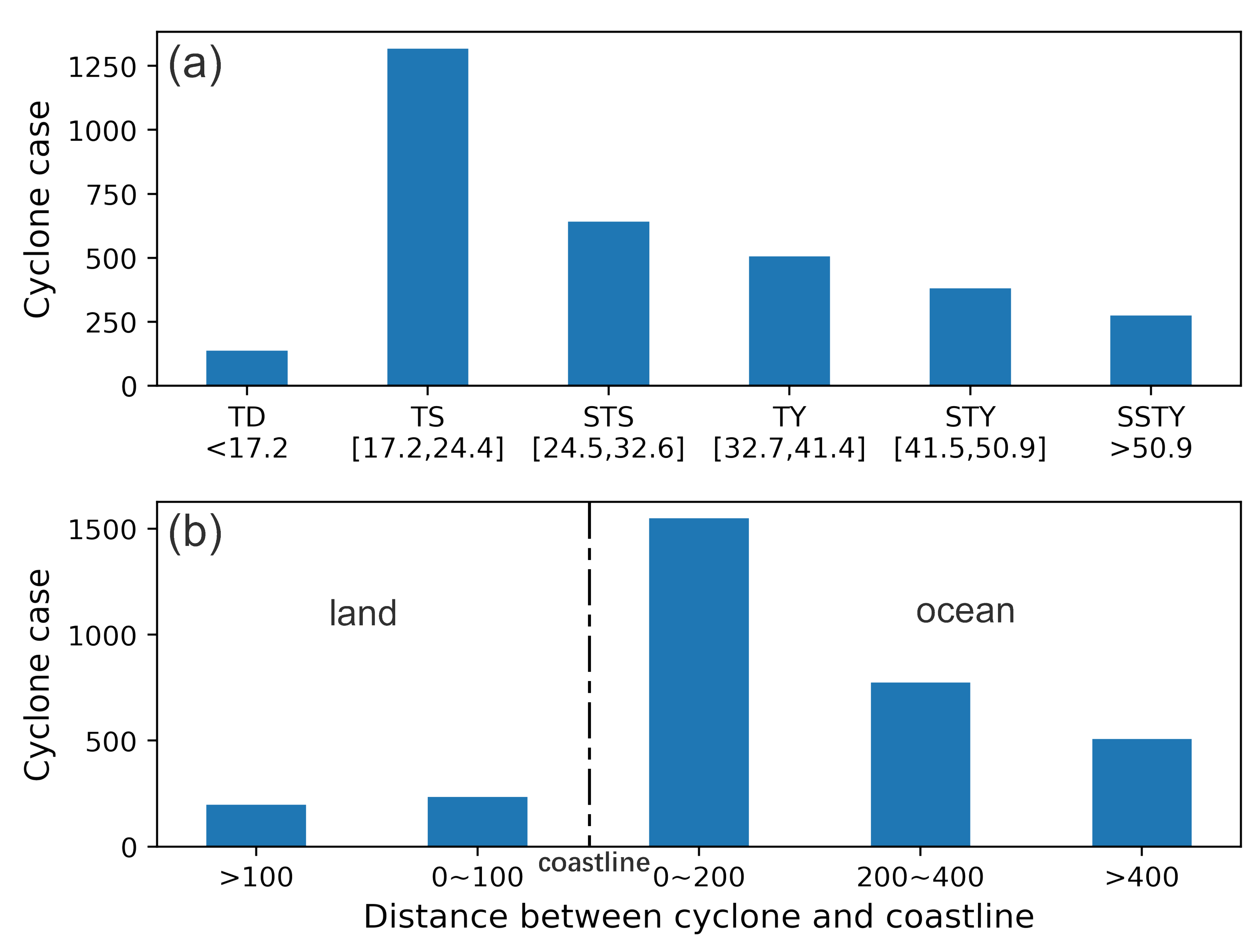
2.2. TC Data
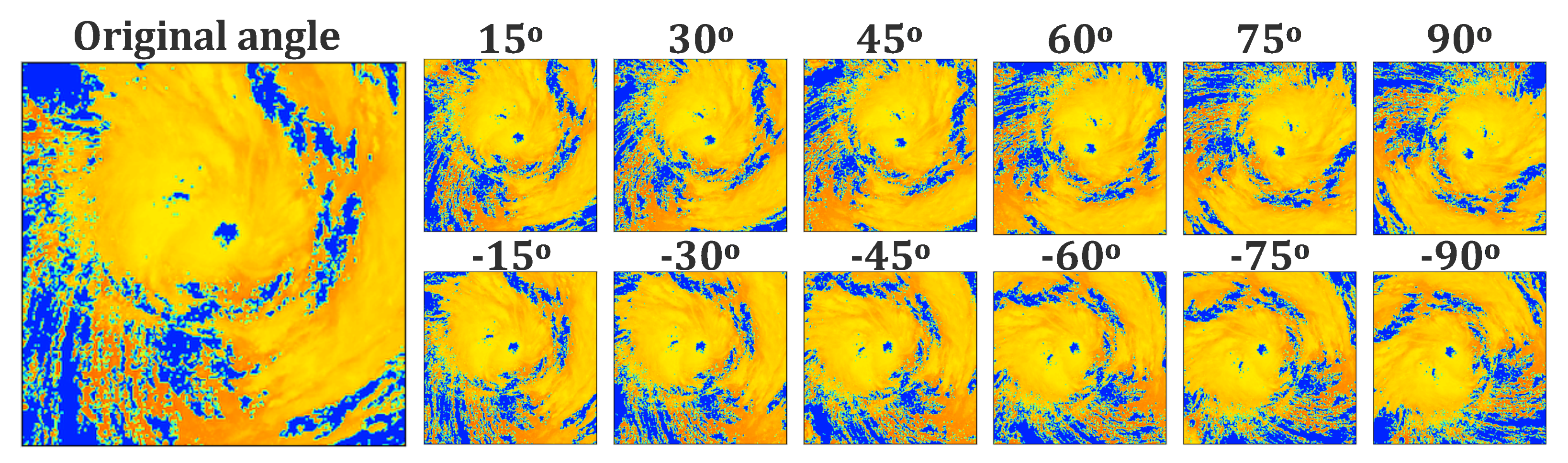
2.3. Data Augmentation
2.4. Convolutional Neural Network (CNN)
2.5. Residual Learning
2.6. Attention Mechanism
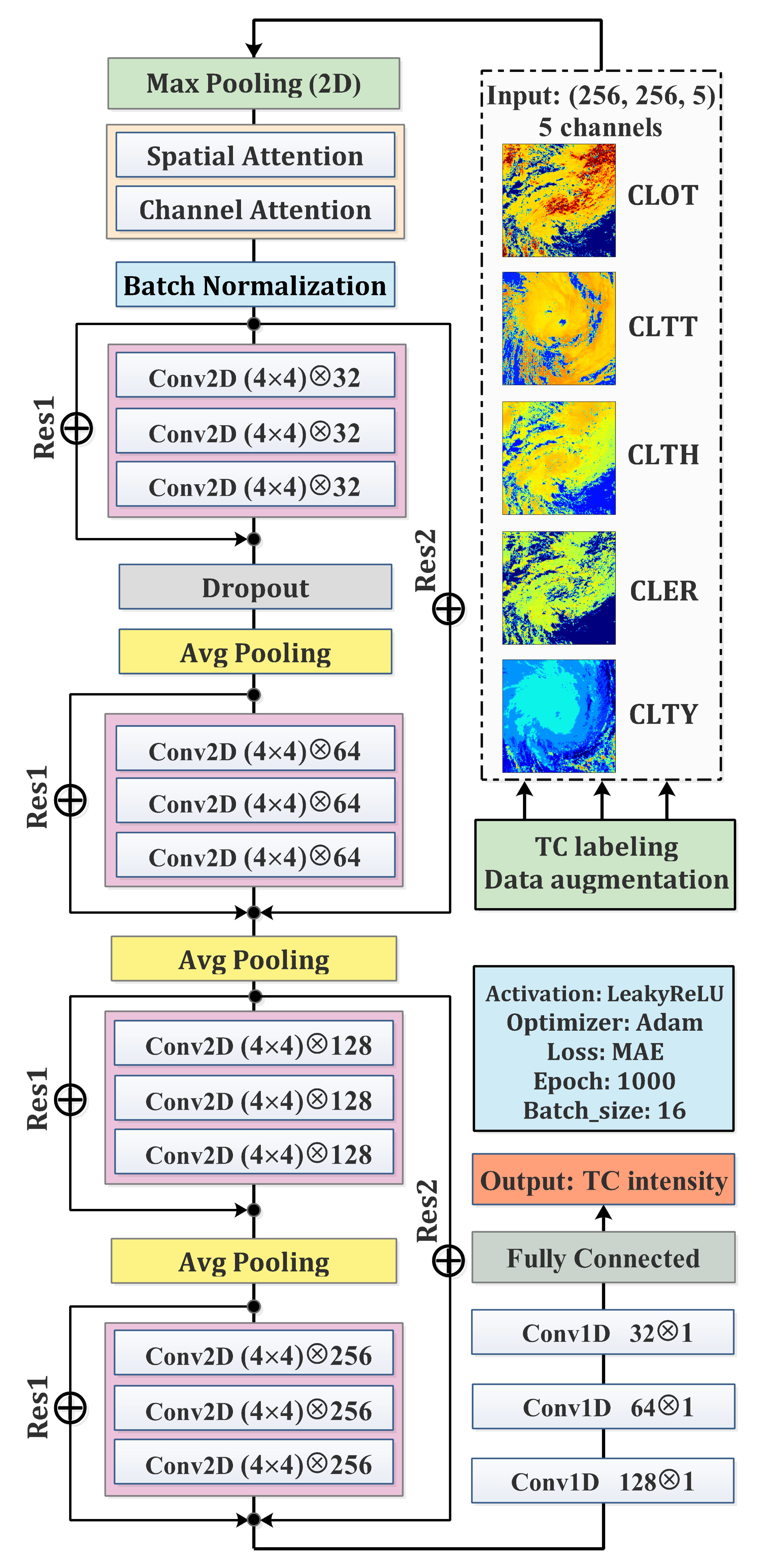
2.7. The Framework of TC Intensity Estimation Model
3. Results
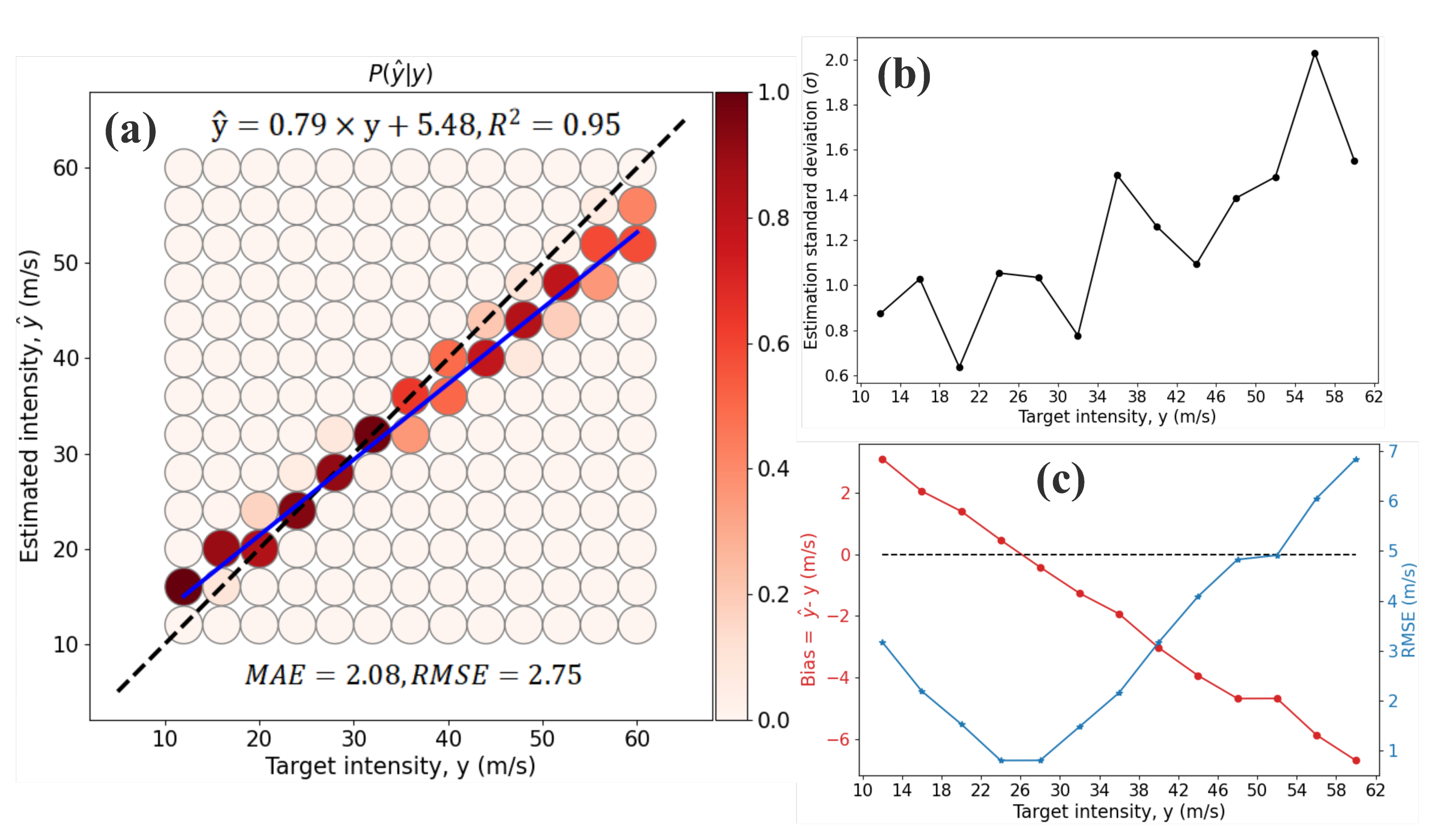
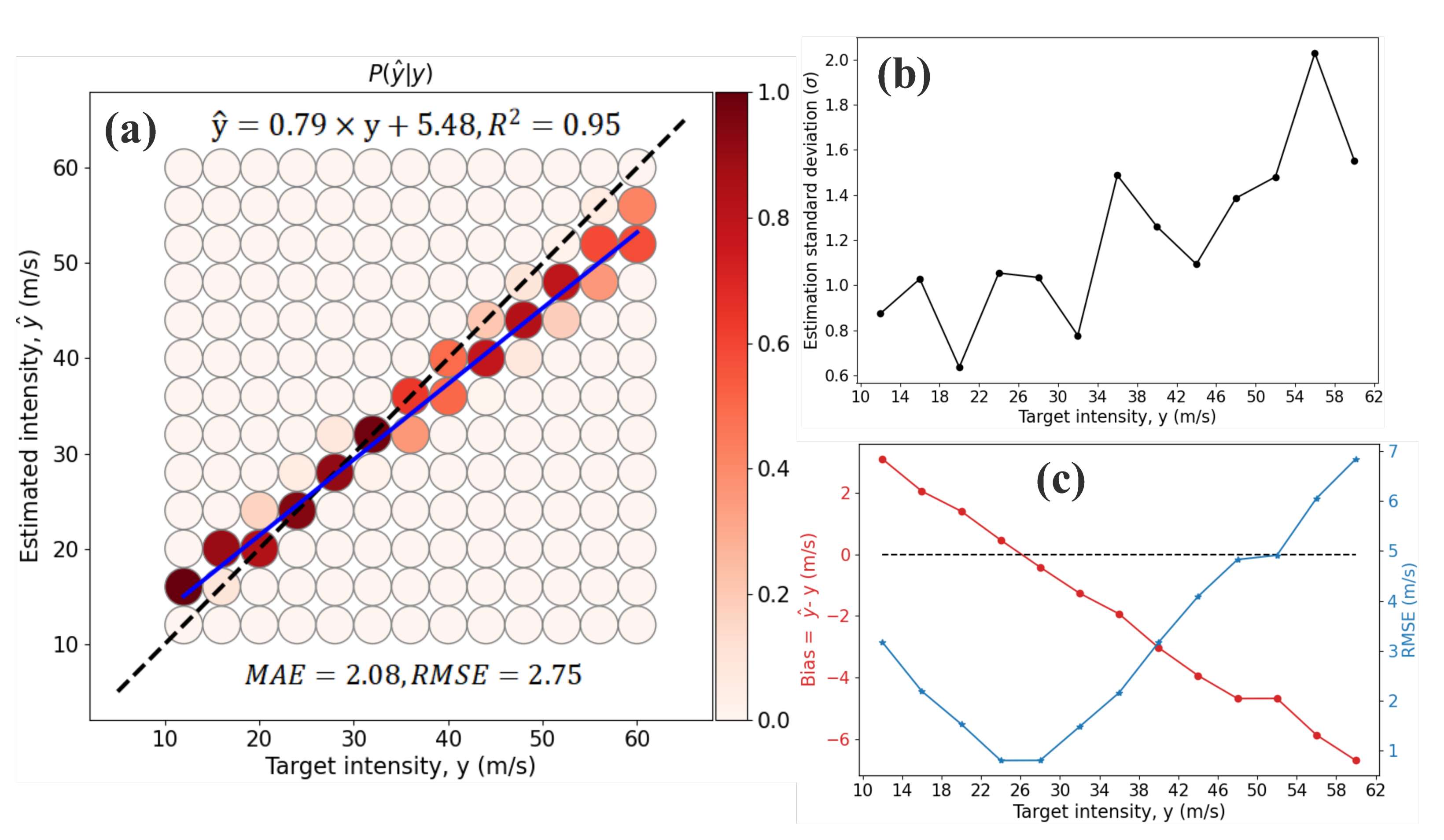
3.1. Assessment on Cross-Validation Data
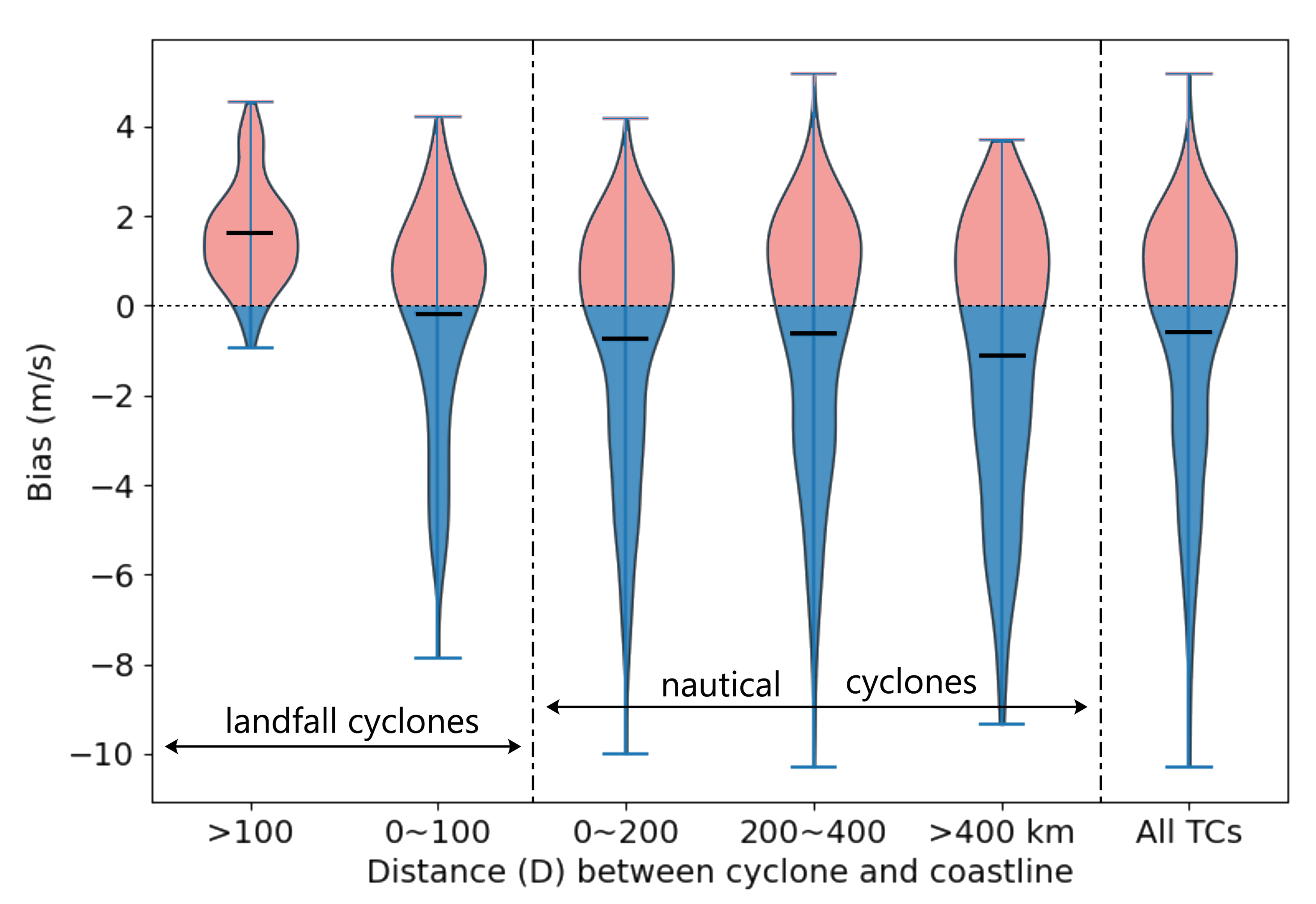
3.2. Performance on Independent Test Data
4. Discussion
4.1. Interpretability of the Model
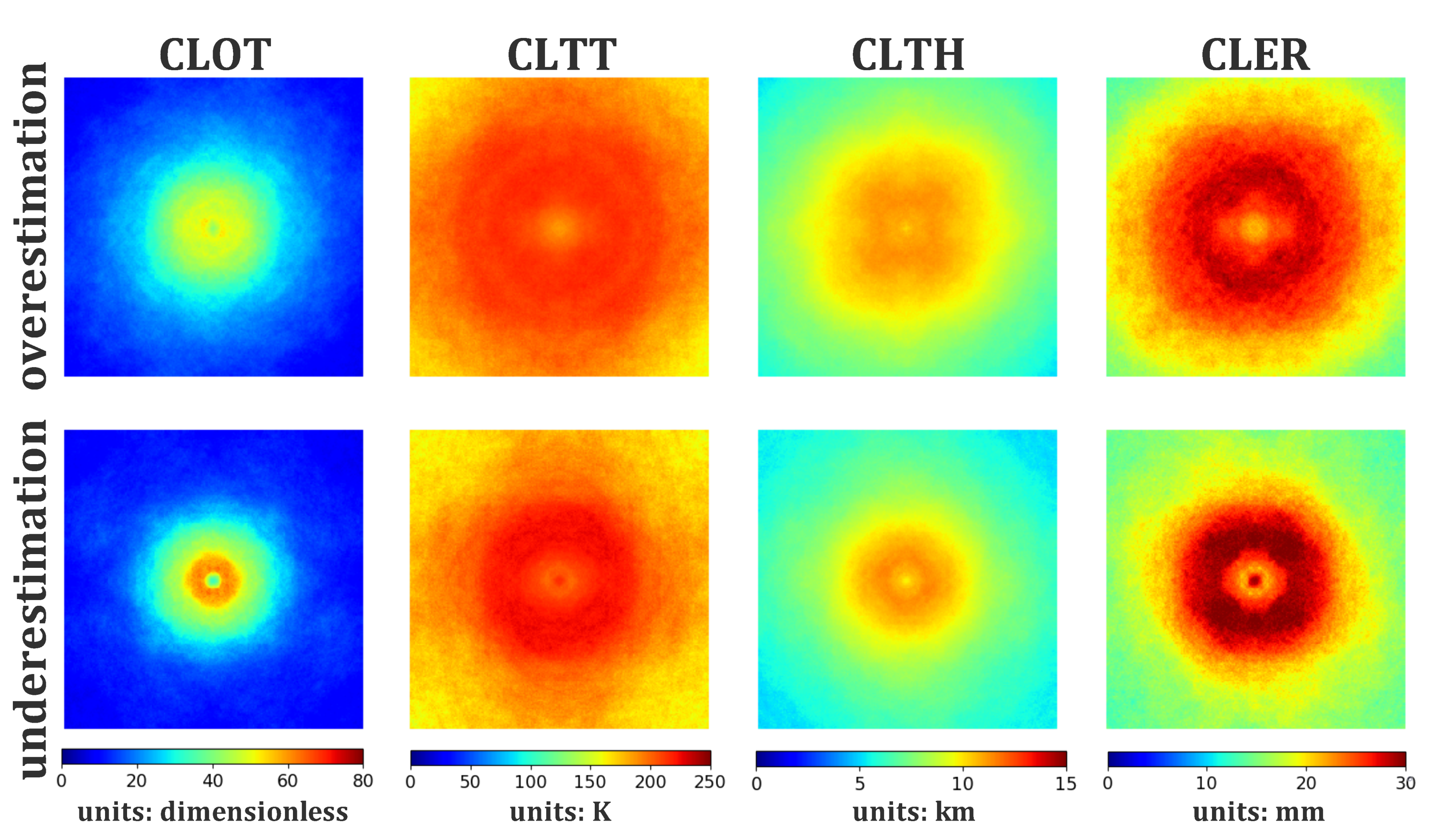
4.2. Initial Cloud Products under Different TC Intensities
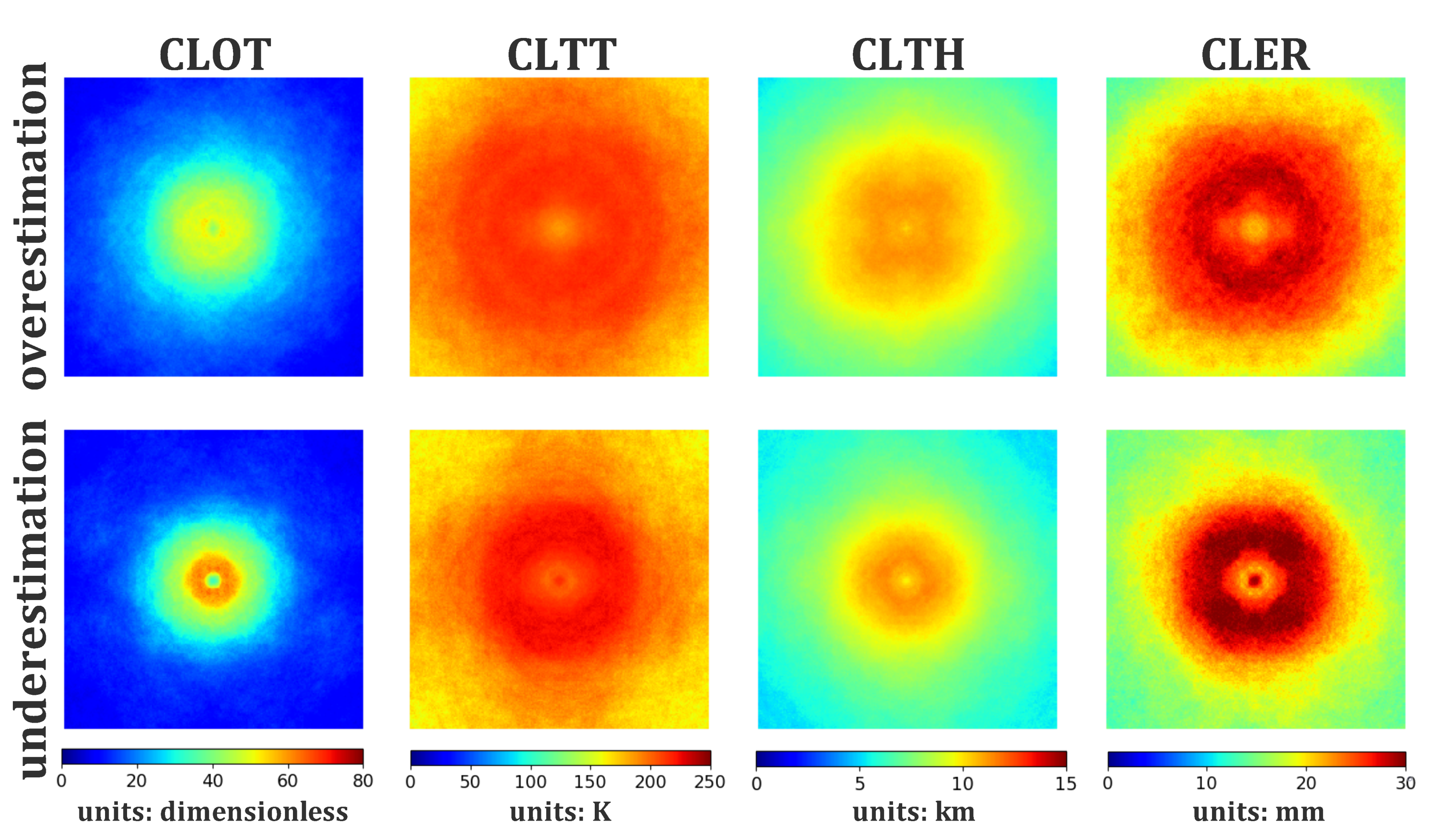
4.3. Cloud Product Composites on Overestimation and Underestimation
4.4. Further Discussion on the Model’s Architecture
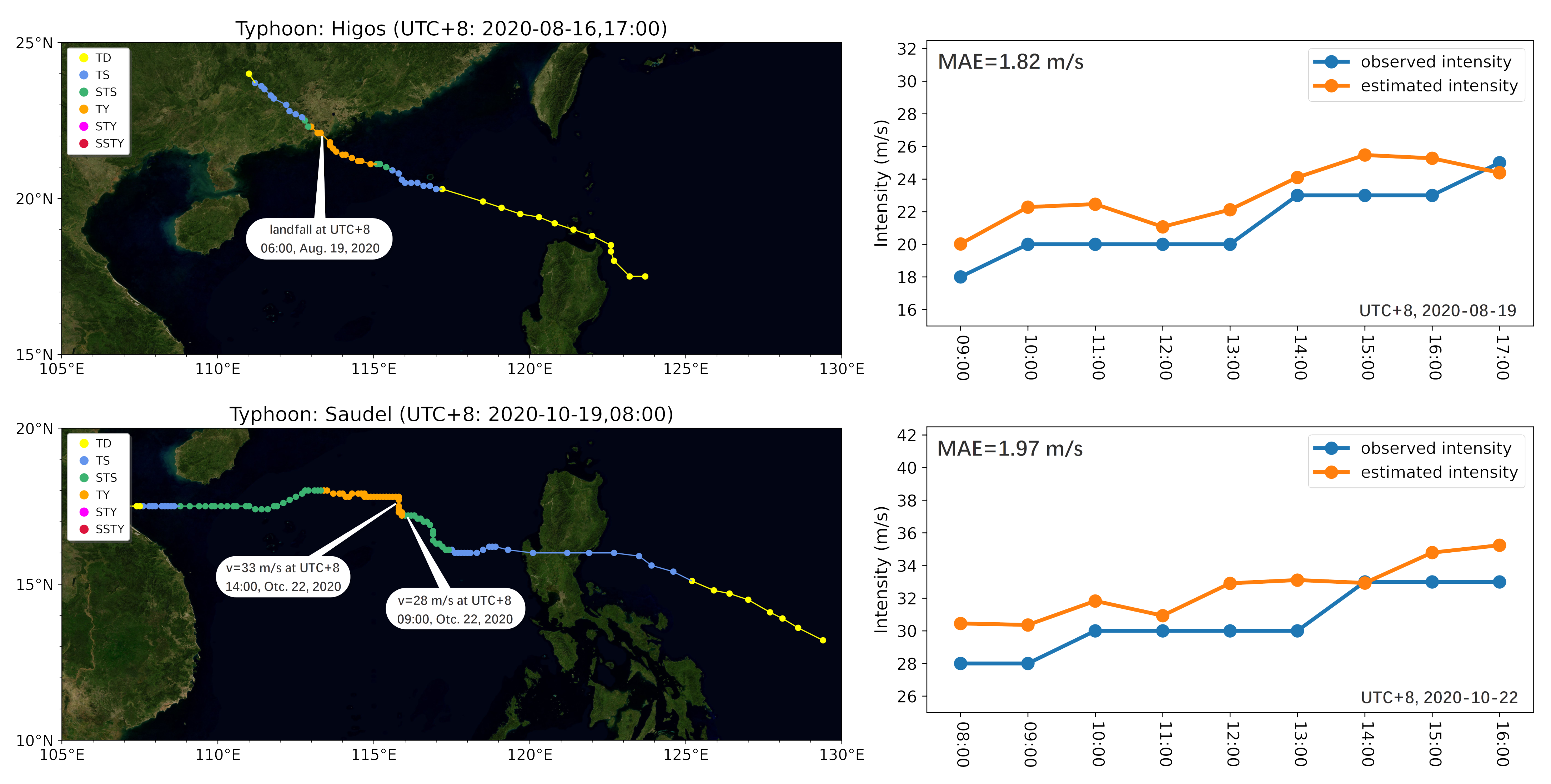
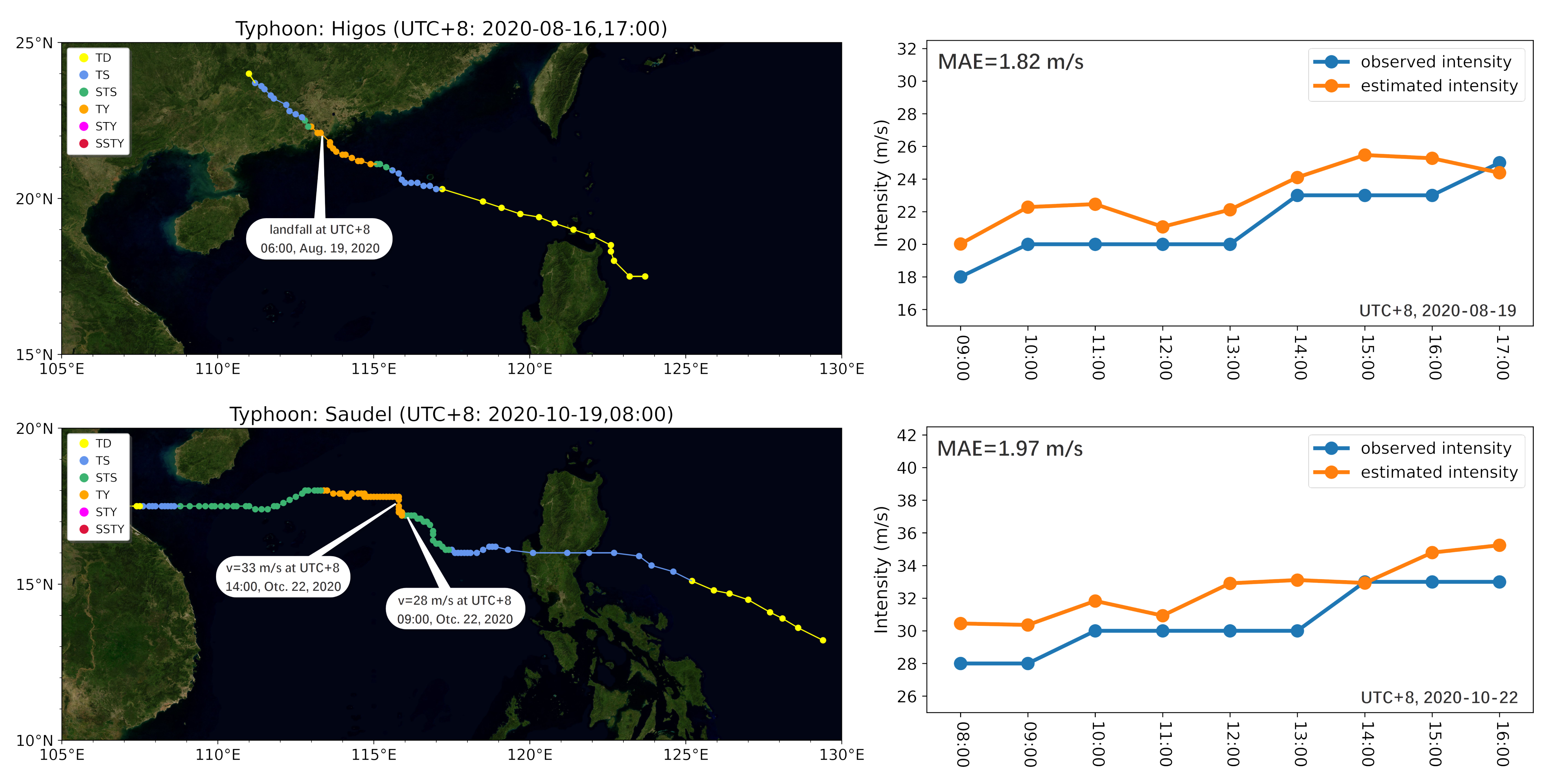
4.5. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tang, D.L.; Sui, G.; Lavy, G.; Pozdnyakov, D.; Song, Y.T.; Switzer, A.D. (Eds.) Typhoon Impact and Crisis Management; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–578. [Google Scholar]
- Davis, C.A. Resolving tropical cyclone intensity in models. Geophys. Res. Lett. 2018, 45, 2082–2087. [Google Scholar] [CrossRef]
- Pamela, P.; Chiara, P.; Alessandro, A.; Stefano, P.; Annett, W. Tropical Cyclone ENAWO—Post-Event Report. 2017. Available online: https://publications.jrc.ec.europa.eu/repository/handle/JRC108086 (accessed on 31 January 2022).
- Courtney, J.B.; Langlade, S.; Sampson, C.R.; Knaff, J.A.; Birchard, T.; Barlow, S.; Kotalg, S.D.; Kriat, T.; Lee, W.; Pasch, R.; et al. Operational perspectives on tropical cyclone intensity change part 1: Recent advances in intensity guidance. Trop. Cyclone Res. Rev. 2019, 8, 123–133. [Google Scholar] [CrossRef]
- DeMaria, M.; Sampson, C.R.; Knaff, J.A.; Musgrave, K.D. Is tropical cyclone intensity guidance improving? Bull. Am. Meteorol. Soc. 2014, 95, 387–398. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.H.; Moon, I.J.; Chu, P.S. Statistical–dynamical typhoon intensity predictions in the western North Pacific using track pattern clustering and ocean coupling predictors. Weather Forecast. 2018, 33, 347–365. [Google Scholar] [CrossRef]
- Leroux, M.D.; Wood, K.; Elsberry, R.L.; Cayanan, E.O.; Hendricks, E.; Kucas, M.; Otto, P.; Rogers, R.; Sampson, B.; Yu, Z. Recent advances in research and forecasting of tropical cyclone track, intensity, and structure at landfall. Trop. Cyclone Res. Rev. 2018, 7, 85–105. [Google Scholar]
- Judt, F.; Chen, S.S. Predictability and dynamics of tropical cyclone rapid intensification deduced from high-resolution stochastic ensembles. Mon. Weather Rev. 2016, 144, 4395–4420. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, C.; Sun, R.; Wang, Z. A multiple linear regression model for tropical cyclone intensity estimation from satellite infrared images. Atmosphere 2016, 7, 40. [Google Scholar] [CrossRef] [Green Version]
- Zhuge, X.Y.; Guan, J.; Yu, F.; Wang, Y. A new satellite-based indicator for estimation of the western North Pacific tropical cyclone current intensity. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5661–5676. [Google Scholar] [CrossRef]
- Shimada, U.; Sawada, M.; Yamada, H. Evaluation of the accuracy and utility of tropical cyclone intensity estimation using single ground-based Doppler radar observations. Mon. Weather Rev. 2016, 144, 1823–1840. [Google Scholar] [CrossRef]
- Moreno, D.C. Tropical Cyclone Intensity and Position Analysis Using Passive Microwave Imager and Sounder Data; Air Force Institute of Technology Wright-Patterson AFB OH Graduate School of Engineering and Management: Wright-Patterson Air Force Base, OH, USA, 2015. [Google Scholar]
- Zhang, C.J.; Wang, X.J.; Ma, L.M.; Lu, X.Q. Tropical cyclone intensity classification and estimation using infrared satellite images with deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2070–2086. [Google Scholar] [CrossRef]
- Lee, J.; Im, J.; Cha, D.H.; Park, H.; Sim, S. Tropical cyclone intensity estimation using multi-dimensional convolutional neural networks from geostationary satellite data. Remote Sens. 2020, 12, 108. [Google Scholar] [CrossRef] [Green Version]
- Oyama, R.; Nagata, K.; Kawada, H.; Koide, N. Development of a product based on consensus between Dvorak and AMSU tropical cyclone central pressure estimates at JMA. RSMC Tokyo-Typhoon Cent. Tech. Rev. 2016, 18, 8. [Google Scholar]
- Pradhan, R.; Aygun, R.S.; Maskey, M.; Ramachandran, R.; Cecil, D.J. Tropical cyclone intensity estimation using a deep convolutional neural network. IEEE Trans. Image Process. 2017, 27, 692–702. [Google Scholar] [CrossRef] [PubMed]
- Dvorak, V.F. Tropical cyclone intensity analysis and forecasting from satellite imagery. Mon. Weather Rev. 1975, 103, 420–430. [Google Scholar] [CrossRef]
- Dvorak, V.F. Tropical Cyclone Intensity Analysis Using Satellite Data (Vol. 11); US Department of Commerce, National Oceanic and Atmospheric Administration, National Environmental Satellite, Data, and Information Service: Washington, DC, USA, 1984. [Google Scholar]
- Olander, T.L.; Velden, C.S.; Kossin, J.P. The advanced objective dvorak technique (AODT)–latest upgrades and future directions. In Proceedings of the 26th Conference on Hurricanes and Tropical Meteorology, Miami, FL, USA, 3–7 May 2004; pp. 294–295. [Google Scholar]
- Olander, T.L.; Velden, C.S. The advanced Dvorak technique: Continued development of an objective scheme to estimate tropical cyclone intensity using geostationary infrared satellite imagery. Weather Forecast. 2007, 22, 287–298. [Google Scholar] [CrossRef]
- Pineros, M.F.; Ritchie, E.A.; Tyo, J.S. Objective measures of tropical cyclone structure and intensity change from remotely sensed infrared image data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3574–3580. [Google Scholar] [CrossRef]
- Ritchie, E.A.; Wood, K.M.; Rodríguez-Herrera, O.G.; Piñeros, M.F.; Tyo, J.S. Satellite-derived tropical cyclone intensity in the North Pacific Ocean using the deviation-angle variance technique. Weather Forecast. 2014, 29, 505–516. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wimmers, A.; Velden, C.; Cossuth, J.H. Using deep learning to estimate tropical cyclone intensity from satellite passive microwave imagery. Mon. Weather Rev. 2019, 147, 2261–2282. [Google Scholar] [CrossRef]
- Chen, G.; Chen, Z.; Zhou, F.; Yu, X.; Zhang, H.; Zhu, L. A semisupervised deep learning framework for tropical cyclone intensity estimation. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Combinido, J.S.; Mendoza, J.R.; Aborot, J. A convolutional neural network approach for estimating tropical cyclone intensity using satellite-based infrared images. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1474–1480. [Google Scholar]
- Maskey, M.; Ramachandran, R.; Ramasubramanian, M.; Gurung, I.; Freitag, B.; Kaulfus, A.; Bollinger, B.; Cecil, D.J.; Miller, J. Deepti: Deep-learning-based tropical cyclone intensity estimation system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4271–4281. [Google Scholar] [CrossRef]
- Zhuo, J.Y.; Tan, Z.M. Physics-Augmented Deep Learning to Improve Tropical Cyclone Intensity and Size Estimation from Satellite Imagery. Mon. Weather Rev. 2021, 149, 2097–2113. [Google Scholar] [CrossRef]
- Wang, C.; Zheng, G.; Li, X.; Xu, Q.; Liu, B.; Zhang, J. Tropical Cyclone Intensity Estimation From Geostationary Satellite Imagery Using Deep Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, W.; Wang, X. Machine learning in tropical cyclone forecast modeling: A review. Atmosphere 2020, 11, 676. [Google Scholar] [CrossRef]
- Tan, J.; Chen, S.; Lee, C.Y.; Dong, G.; Hu, W.; Wang, J. Projected changes of typhoon intensity in a regional climate model: Development of a machine learning bias correction scheme. Int. J. Climatol. 2021, 41, 2749–2764. [Google Scholar] [CrossRef]
- Bessho, K.; Date, K.; Hayashi, M.; Ikeda, A.; Yoshida, R. An introduction to himawari-8/9—Japan’s new-generation geostationary meteorological satellites. J. Meteorol. Soc. Jpn. 2016, 94, 151–183. [Google Scholar] [CrossRef] [Green Version]
- Takeuchi, Y. An Introduction of Advanced Technology for Tropical Cyclone Observation, Analysis and Forecast in JMA. Trop. Cyclone Res. Rev. 2018, 7, 153–163. [Google Scholar]
- Honda, T.; Miyoshi, T.; Lien, G.Y.; Nishizawa, S.; Yoshida, R.; Adachi, S.A.; Bessho, K. Assimilating all-sky Himawari-8 satellite infrared radiances: A case of Typhoon Soudelor 2015. Mon. Weather Rev. 2018, 146, 213–229. [Google Scholar] [CrossRef]
- Lu, J.; Feng, T.; Li, J.; Cai, Z.; Xu, X.; Li, L.; Li, J. Impact of assimilating Himawari-8-derived layered precipitable water with varying cumulus and microphysics parameterization schemes on the simulation of Typhoon Hato. J. Geophys. Res. Atmos. 2019, 124, 3050–3071. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srinivas, S.; Sarvadevabhatla, R.K.; Mopuri, K.R.; Prabhu, N.; Kruthiventi, S.S.; Babu, R.V. An introduction to deep convolutional neural nets for computer vision. In Deep Learning for Medical Image Analysis; Academic Press: Cambridge, MA, USA, 2017; pp. 25–52. [Google Scholar]
- Wu, J. Introduction to convolutional neural networks. Natl. Key Lab Nov. Softw. Technol. Nanjing Univ. China 2017, 2017, 495. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Networks 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Quebec, QC, Canada, 13 May 2010; pp. 249–256. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Olander, T.L.; Velden, C.S. The Advanced Dvorak Technique (ADT) for estimating tropical cyclone intensity: Update and new capabilities. Weather Forecast. 2019, 34, 905–922. [Google Scholar] [CrossRef]
- Pineros, M.F.; Ritchie, E.A.; Tyo, J.S. Estimating tropical cyclone intensity from infrared image data. Weather Forecast. 2011, 26, 690–698. [Google Scholar] [CrossRef]
- Chen, G.; Wu, C.C.; Huang, Y.H. The role of near-core convective and stratiform heating/cooling in tropical cyclone structure and intensity. J. Atmos. Sci. 2018, 75, 297–326. [Google Scholar] [CrossRef]
- Lianshou, C.; Zhexian, L.; Ying, L. Research advances on tropical cyclone landfall process. Acta Meteor. Sin. 2004, 62, 541–549. [Google Scholar]
- Lin, I.I.; Chen, C.H.; Pun, I.F.; Liu, W.T.; Wu, C.C. Warm ocean anomaly, air sea fluxes, and the rapid intensification of tropical cyclone Nargis 2008. Geophys. Res. Lett. 2009, 36, 9–13. [Google Scholar] [CrossRef] [Green Version]
- Mei, W.; Xie, S.P.; Primeau, F.; McWilliams, J.C.; Pasquero, C. Northwestern Pacific typhoon intensity controlled by changes in ocean temperatures. Sci. Adv. 2015, 1, e1500014. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhong, Z.; Li, T.; Yi, L.; Hu, Y.; Wan, H.; Chen, H.; Liao, Q.; Ma, C.; Li, Q. Impact of ocean warming on tropical cyclone size and its destructiveness. Sci. Rep. 2017, 7, 8154. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, Q.; Hang, R. Tropical cyclone intensity estimation using two-branch convolutional neural network from infrared and water vapor images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 586–597. [Google Scholar] [CrossRef]
- Wang, X.; Wang, W.; Yan, B. Tropical Cyclone Intensity Change Prediction Based on Surrounding Environmental Conditions with Deep Learning. Water 2020, 12, 2685. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model/Method | Satellite Data/Channel | RMSE (m/s) | Reference |
|---|---|---|---|
| ADT | IR, visible/PMW imagery | 5.77 | [45] |
| DAV | GOES-12, IR (10.7 µm) | 6.68 | [46] |
| DAVT | MTSAT, IR (10.7 µm) | 6.55 | [22] |
| DeepMicroNet | DMSP, TRMM, Aqua AMSR-E etc. | 4.93 | [25] |
| CNN-TC | GridSat, IR1, WV, PMW | 4.31∼4.52 | [26] |
| 2D-CNN, 3D-CNN | COMS MI, IR1, IR2, WV, SWIR | 4.27∼5.82 | [14] |
| TCICENet, TCICENet-S | GMS, GEO, MTSAT, H-8, etc. | 4.42∼4.93 | [13] |
| VGG-ResNet-CBAM | H-8 L2 cloud products | 4.06 | This study |
| Architecture | Num. of Parameters | Running Time (s) | MAE (m/s) | RMSE (m/s) |
|---|---|---|---|---|
| VGG | 3,478,241 | 138 | 3.62 | 4.62 |
| VGG + CA | 3,478,257 | 136 | 3.61 | 4.53 |
| VGG + SA | 3,478,260 | 145 | 3.81 | 4.80 |
| VGG + CBAM | 2,789,700 | 78 | 3.40 | 4.29 |
| VGG + CBAM + Res1 | 301,444 | 114 | 3.23 | 4.06 |
| VGG + CBAM + Res2 | 844,932 | 67 | 3.57 | 4.43 |
| VGG + CBAM + Res1 + Res2 | 2,929,220 | 126 | 3.38 | 4.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Yang, Q.; Hu, J.; Huang, Q.; Chen, S. Tropical Cyclone Intensity Estimation Using Himawari-8 Satellite Cloud Products and Deep Learning. Remote Sens. 2022, 14, 812. https://doi.org/10.3390/rs14040812
Tan J, Yang Q, Hu J, Huang Q, Chen S. Tropical Cyclone Intensity Estimation Using Himawari-8 Satellite Cloud Products and Deep Learning. Remote Sensing. 2022; 14(4):812. https://doi.org/10.3390/rs14040812
Chicago/Turabian StyleTan, Jinkai, Qidong Yang, Junjun Hu, Qiqiao Huang, and Sheng Chen. 2022. "Tropical Cyclone Intensity Estimation Using Himawari-8 Satellite Cloud Products and Deep Learning" Remote Sensing 14, no. 4: 812. https://doi.org/10.3390/rs14040812