
Locality Constrained Low Rank Representation and Automatic Dictionary Learning for Hyperspectral Anomaly Detection


Abstract
:1. Introduction
- (1)
- We introduce an locality constrained low rank representation to model the background and anomaly part for the HSI. By introducing the locality constrained term, this model encourages pixels with similar spectrum to have similar representation coefficient.
- (2)
- The dictionary learning is integrated into the LRR model, and a compact dictionary can be learned iteratively, instead of the widely-used clustering algorithms.
- (3)
- Our HAD method is a one-step algorithm, the representation coefficient matrix, dictionary matrix and anomaly matrix can be obtained simultaneously.
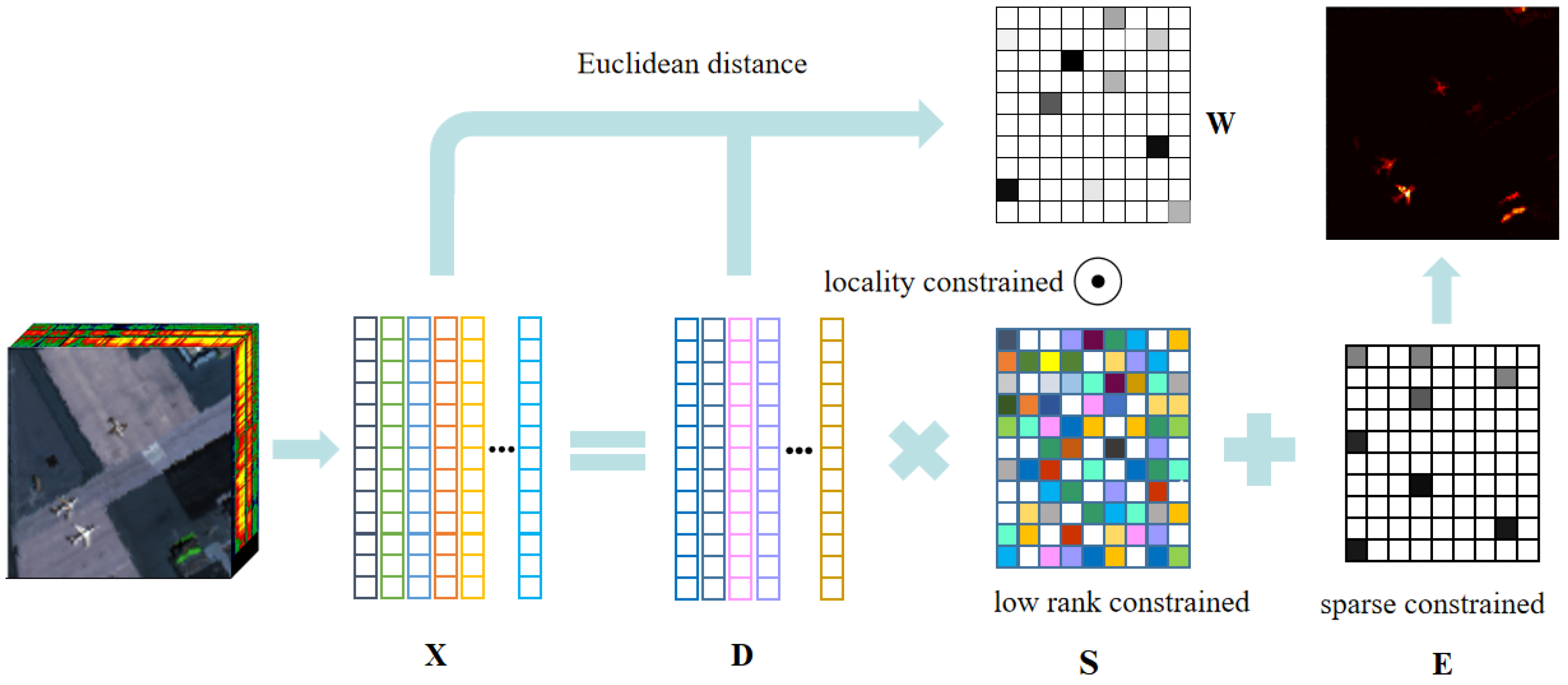
2. Proposed Method
2.1. LRR for Hyperspectral Anomaly Detection
2.2. Locality Constrained LRR
2.3. Active Dictionary Learning for LRR
| Algorithm 1 HAD algorithm based on LCLRR model. |
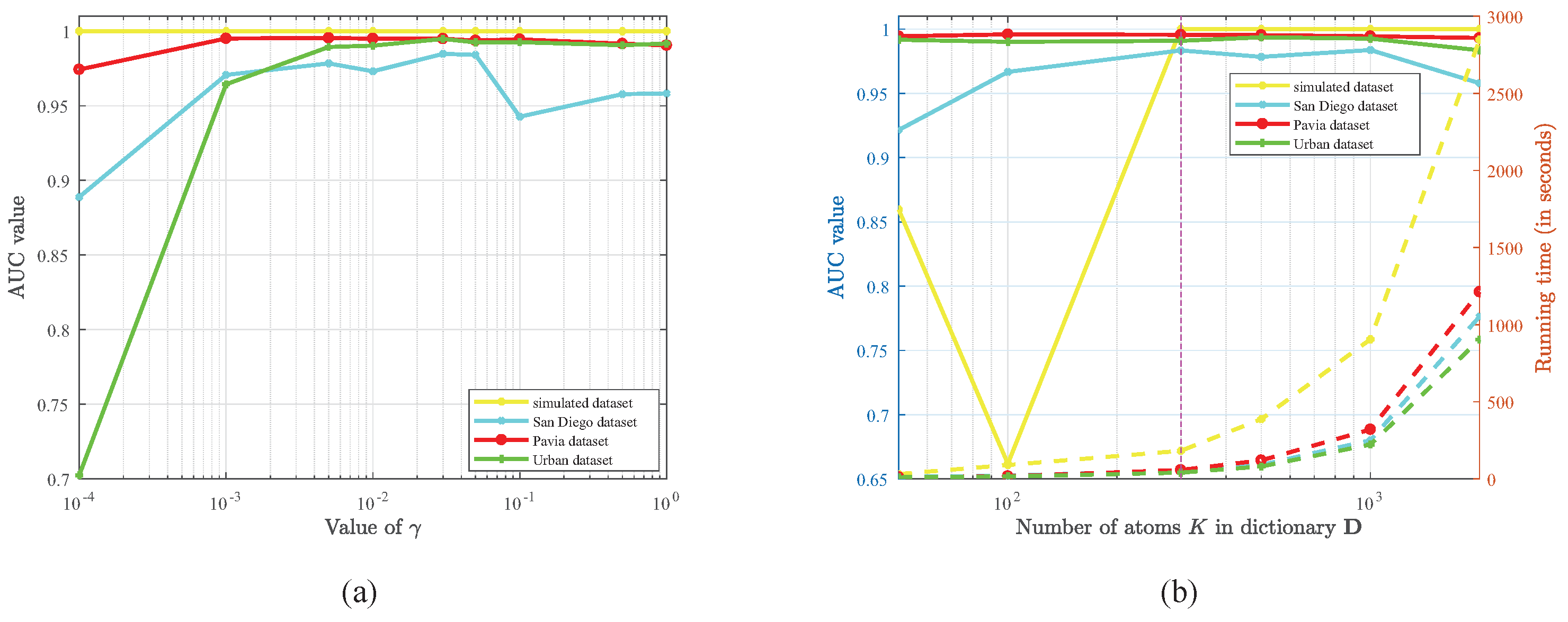
Hyperspectral image ; Regularization parameter , , and ; Number of atoms K in dictionary ;
Anomaly detection map . |
2.4. Optimization Procedure of LCLRR
| Algorithm 2 The optimization of problem (10) by the IALM algorithm. |
Input matrix ; Regularization parameter , , and ; Weight matrix ;
Representation coefficient matrix ; Dictionary matrix ; Residual matrix ;
, , , , , .
do
|
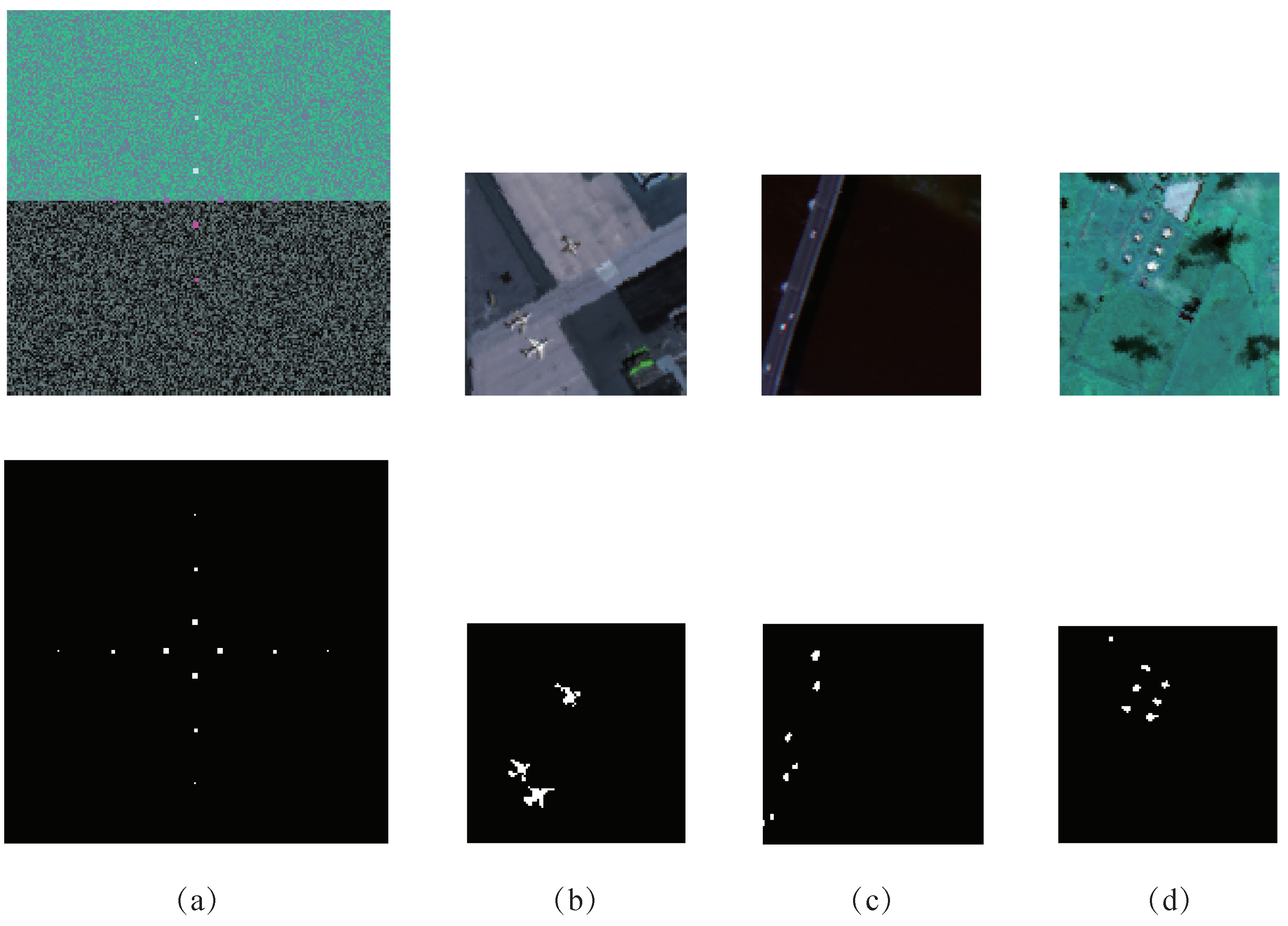
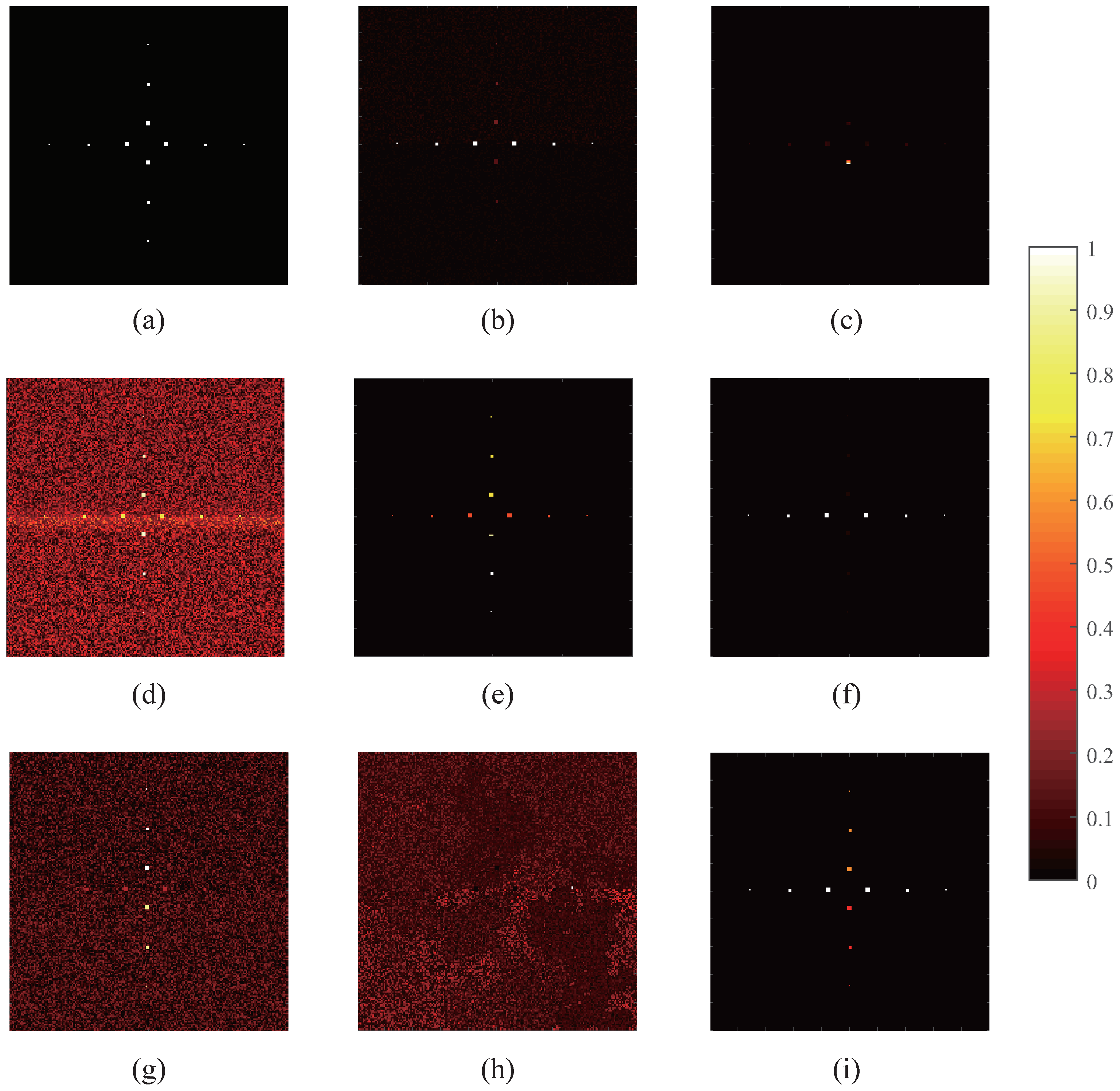
3. Experiments and Result Analysis
3.1. HSI Dataset
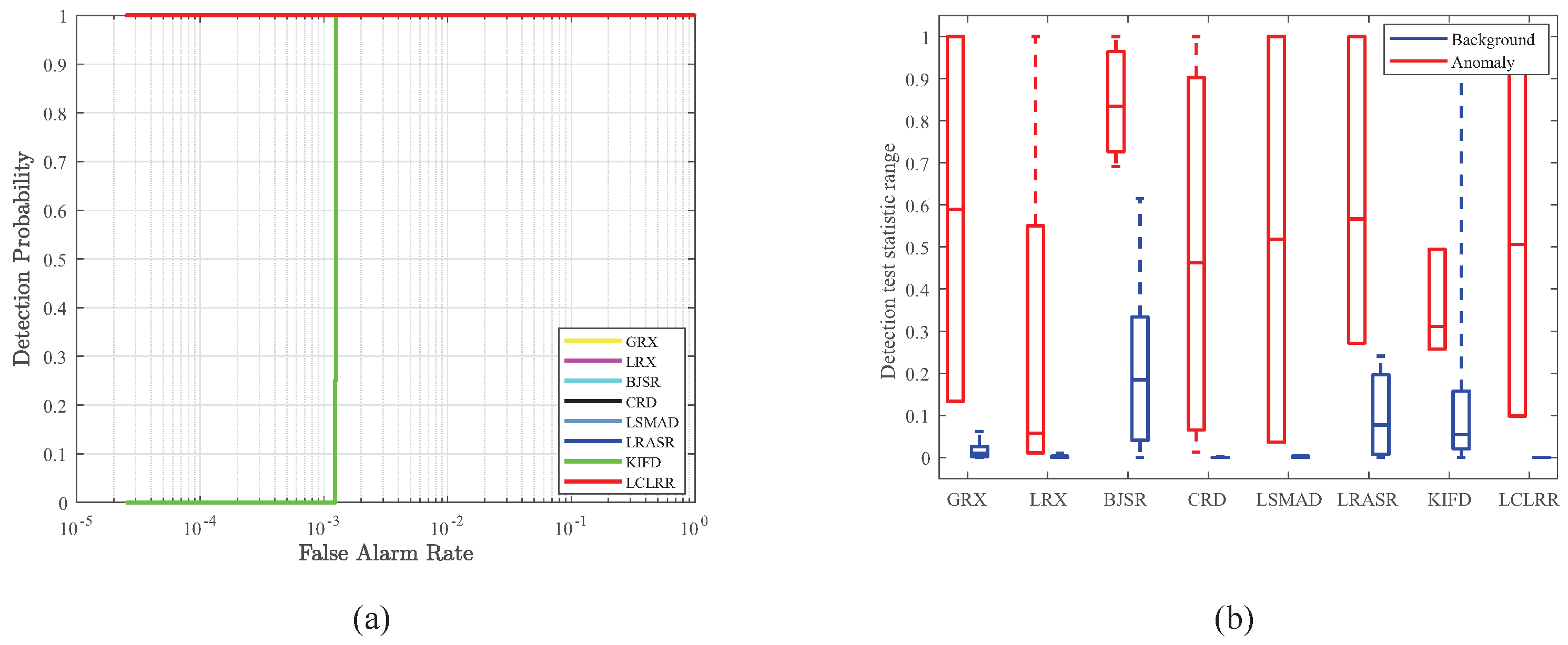
3.2. Comparison Algorithm and Evaluation Metrics
3.3. Detection Performance
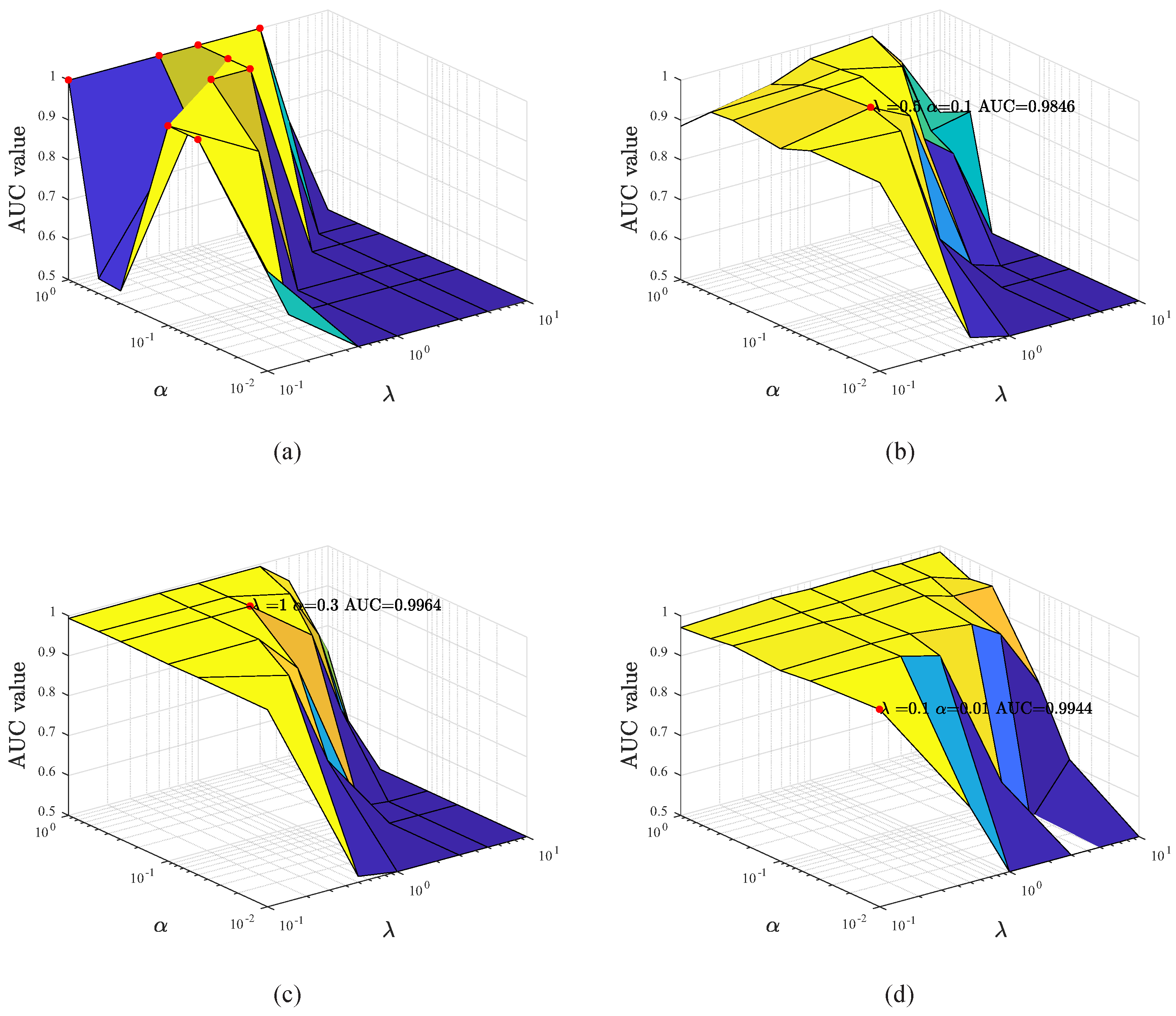
3.4. Parameters Analyses and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing: A Comprehensive Overview of the State of the Art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yuan, Z.; Wang, Q. Unsupervised deep noise modeling for hyperspectral image change detection. Remote Sens. 2019, 11, 258. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Wang, Q.; Li, X. Discriminant analysis with graph learning for hyperspectral image classification. Remote Sens. 2018, 10, 836. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Feng, Y.; Yu, X. Hyperspectral Target Detection with an Auxiliary Generative Adversarial Network. Remote Sens. 2021, 13, 4454. [Google Scholar] [CrossRef]
- Su, H.; Wu, Z.; Zhang, H.; Du, Q. Hyperspectral Anomaly Detection: A Survey. IEEE Geosci. Remote Sens. Mag. 2021, 2–28. [Google Scholar] [CrossRef]
- Gao, L.; Yang, B.; Du, Q.; Zhang, B. Adjusted spectral matched filter for target detection in hyperspectral imagery. Remote Sens. 2015, 7, 6611–6634. [Google Scholar] [CrossRef] [Green Version]
- Matteoli, S.; Diani, M.; Corsini, G. A tutorial overview of anomaly detection in hyperspectral images. IEEE Aerosp. Electron. Syst. Mag. 2010, 25, 5–28. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated hyperspectral cueing for civilian search and rescue. Proc. IEEE 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Theiler, J.; Ziemann, A.; Matteoli, S.; Diani, M. Spectral variability of remotely sensed target materials: Causes, models, and strategies for mitigation and robust exploitation. IEEE Geosci. Remote Sens. Mag. 2019, 7, 8–30. [Google Scholar] [CrossRef]
- Kruse, F.A.; Boardman, J.W.; Huntington, J.F. Comparison of airborne hyperspectral data and EO-1 Hyperion for mineral mapping. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1388–1400. [Google Scholar] [CrossRef] [Green Version]
- Transon, J.; d’Andrimont, R.; Maugnard, A.; Defourny, P. Survey of hyperspectral earth observation applications from space in the sentinel-2 context. Remote Sens. 2018, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Reed, I.S.; Yu, X. Adaptive multiple-band CFAR detection of an optical pattern with unknown spectral distribution. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, B.; Ran, Q.; Gao, L.; Li, J.; Plaza, A. Weighted-RXD and Linear Filter-Based RXD: Improving Background Statistics Estimation for Anomaly Detection in Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2351–2366. [Google Scholar] [CrossRef]
- Taitano, Y.P.; Geier, B.A.; Bauer, K.W. A locally adaptable iterative RX detector. EURASIP J. Adv. Signal Process. 2010, 2010, 341908. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Fan, Y.; Xu, M. A Background-Purification-Based Framework for Anomaly Target Detection in Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1238–1242. [Google Scholar] [CrossRef]
- Kwon, H.; Nasrabadi, N.M. Kernel RX-algorithm: A nonlinear anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 388–397. [Google Scholar] [CrossRef]
- Zhou, J.; Kwan, C.; Ayhan, B.; Eismann, M.T. A Novel Cluster Kernel RX Algorithm for Anomaly and Change Detection Using Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6497–6504. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse representation for target detection in hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhang, L.; Ma, L. Hyperspectral anomaly detection by the use of background joint sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2523–2533. [Google Scholar] [CrossRef]
- Ma, D.; Yuan, Y.; Wang, Q. Hyperspectral anomaly detection via discriminative feature learning with multiple-dictionary sparse representation. Remote Sens. 2018, 10, 745. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Du, Q. Collaborative representation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1463–1474. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Gao, L.; Zhang, B.; Ma, P.; Sun, J. A Background Refinement Collaborative Representation Method with Saliency Weight for Hyperspectral Anomaly Detection. In Proceedings of the 2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2412–2415. [Google Scholar]
- Sun, W.; Liu, C.; Li, J.; Lai, Y.M.; Li, W. Low-rank and sparse matrix decomposition-based anomaly detection for hyperspectral imagery. J. Appl. Remote Sens. 2014, 8, 083641. [Google Scholar] [CrossRef]
- Zhou, T.; Tao, D. Godec: Randomized low-rank & sparse matrix decomposition in noisy case. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 33–40. [Google Scholar]
- Zhang, Y.; Du, B.; Zhang, L.; Wang, S. A Low-Rank and Sparse Matrix Decomposition-Based Mahalanobis Distance Method for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1376–1389. [Google Scholar] [CrossRef]
- Qu, Y.; Wang, W.; Guo, R.; Ayhan, B.; Kwan, C.; Vance, S.; Qi, H. Hyperspectral anomaly detection through spectral unmixing and dictionary-based low-rank decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4391–4405. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Li, J.; Plaza, A.; Wei, Z. Anomaly detection in hyperspectral images based on low-rank and sparse representation. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1990–2000. [Google Scholar] [CrossRef]
- Song, S.; Yang, Y.; Zhou, H.; Chan, J.C.W. Hyperspectral Anomaly Detection via Graph Dictionary-Based Low Rank Decomposition with Texture Feature Extraction. Remote Sens. 2020, 12, 3966. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; He, X.; Li, X. Locality and structure regularized low rank representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 911–923. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, M.; Nie, F.; Wang, Q. A multiview-based parameter free framework for group detection. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4147–4153. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Bertsekas, D.P. Constrained Optimization and Lagrange Multiplier Methods; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Li, H.; Feng, R.; Wang, L.; Zhong, Y.; Zhang, L.; Wei, L. Low-Rank Representation Incorporating Local Spatial Constraint for Hyperspectral Anomaly Detection. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium, Brussels, Belgium, 11–16 July 2021; pp. 4424–4427. [Google Scholar]
- Li, X.; Chen, M.; Nie, F.; Wang, Q. Locality adaptive discriminant analysis. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 2201–2207. [Google Scholar]
- Cox, M.A.; Cox, T.F. Multidimensional scaling. In Handbook of Data Visualization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 315–347. [Google Scholar]
- Yin, H.F.; Wu, X.J.; Kittler, J. Face Recognition via Locality Constrained Low Rank Representation and Dictionary Learning. arXiv 2019, arXiv:1912.03145. [Google Scholar]
- Pan, L.; Li, H.C.; Chen, X.D. Locality constrained low-rank representation for hyperspectral image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 493–496. [Google Scholar]
- Yang, Y.; Zhang, J.; Song, S.; Liu, D. Hyperspectral anomaly detection via dictionary construction-based low-rank representation and adaptive weighting. Remote Sens. 2019, 11, 192. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Ma, D.; Wang, Q. Hyperspectral Anomaly Detection by Graph Pixel Selection. IEEE Trans. Cybern. 2016, 46, 3123–3134. [Google Scholar] [CrossRef]
- Li, S.; Zhang, K.; Duan, P.; Kang, X. Hyperspectral anomaly detection with kernel isolation forest. IEEE Trans. Geosci. Remote Sens. 2019, 58, 319–329. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Kerekes, J. Receiver operating characteristic curve confidence intervals and regions. IEEE Geosci. Remote Sens. Lett. 2008, 5, 251–255. [Google Scholar] [CrossRef] [Green Version]
- Williamson, D.F.; Parker, R.A.; Kendrick, J.S. The box plot: A simple visual method to interpret data. Ann. Intern. Med. 1989, 110, 916–921. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Simulated | San Diego Airport | Pavia Center | Texas Coast Urban |
|---|---|---|---|---|
| GRX [12] | 1 | 0.9403 | 0.9901 | 0.9907 |
| LRX [12] | 1 | 0.8173 (5,29 ) | 0.9734 (5,29) | 0.9124 (5,29) |
| BJSR [19] | 1 | 0.8844 (3,23) | 0.9579 (5,23) | 0.9200 (5,23) |
| CRD [21] | 1 | 0.9159 (5,23) | 0.9623 (5,29) | 0.9421 (5,23) |
| LSMAD [25] | 1 | 0.9666 | 0.9877 | 0.9833 |
| LRASR [27] | 1 | 0.8661 | 0.7148 | 0.9425 |
| KIFD [41] | 0.9988 | 0.9919 | 0.7707 | 0.9178 |
| LCLRR | 1 | 0.9846 | 0.9957 | 0.9944 |
| Methods | Simulated | San Diego Airport | Pavia Center | Texas Coast Urban |
|---|---|---|---|---|
| GRX [12] | 1.35 | 0.10 | 0.26 | 0.16 |
| LRX [12] | 45.90 | 50.14 (5,29) | 23.59 (5,29) | 60.25 (5,29) |
| BJSR [19] | 26.63 | 6.15 (3,23) | 6.39 (5,23) | 5.93 (5,23) |
| CRD [21] | 1631.15 (5,23) | 297.06 (5,23) | 498.54 (5,29) | 286.66 (5,23) |
| LSMAD [25] | 15.91 | 10.48 | 7.75 | 13.04 |
| LRASR [27] | 262.91 | 37.70 | 47.93 | 40.45 |
| KIFD [41] | 377.42 | 58.41 | 59.06 | 54.49 |
| LCLRR | 182.51 | 54.23 | 58.13 | 40.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Liu, K.; Li, X. Locality Constrained Low Rank Representation and Automatic Dictionary Learning for Hyperspectral Anomaly Detection. Remote Sens. 2022, 14, 1327. https://doi.org/10.3390/rs14061327
Huang J, Liu K, Li X. Locality Constrained Low Rank Representation and Automatic Dictionary Learning for Hyperspectral Anomaly Detection. Remote Sensing. 2022; 14(6):1327. https://doi.org/10.3390/rs14061327
Chicago/Turabian StyleHuang, Ju, Kang Liu, and Xuelong Li. 2022. "Locality Constrained Low Rank Representation and Automatic Dictionary Learning for Hyperspectral Anomaly Detection" Remote Sensing 14, no. 6: 1327. https://doi.org/10.3390/rs14061327
APA StyleHuang, J., Liu, K., & Li, X. (2022). Locality Constrained Low Rank Representation and Automatic Dictionary Learning for Hyperspectral Anomaly Detection. Remote Sensing, 14(6), 1327. https://doi.org/10.3390/rs14061327