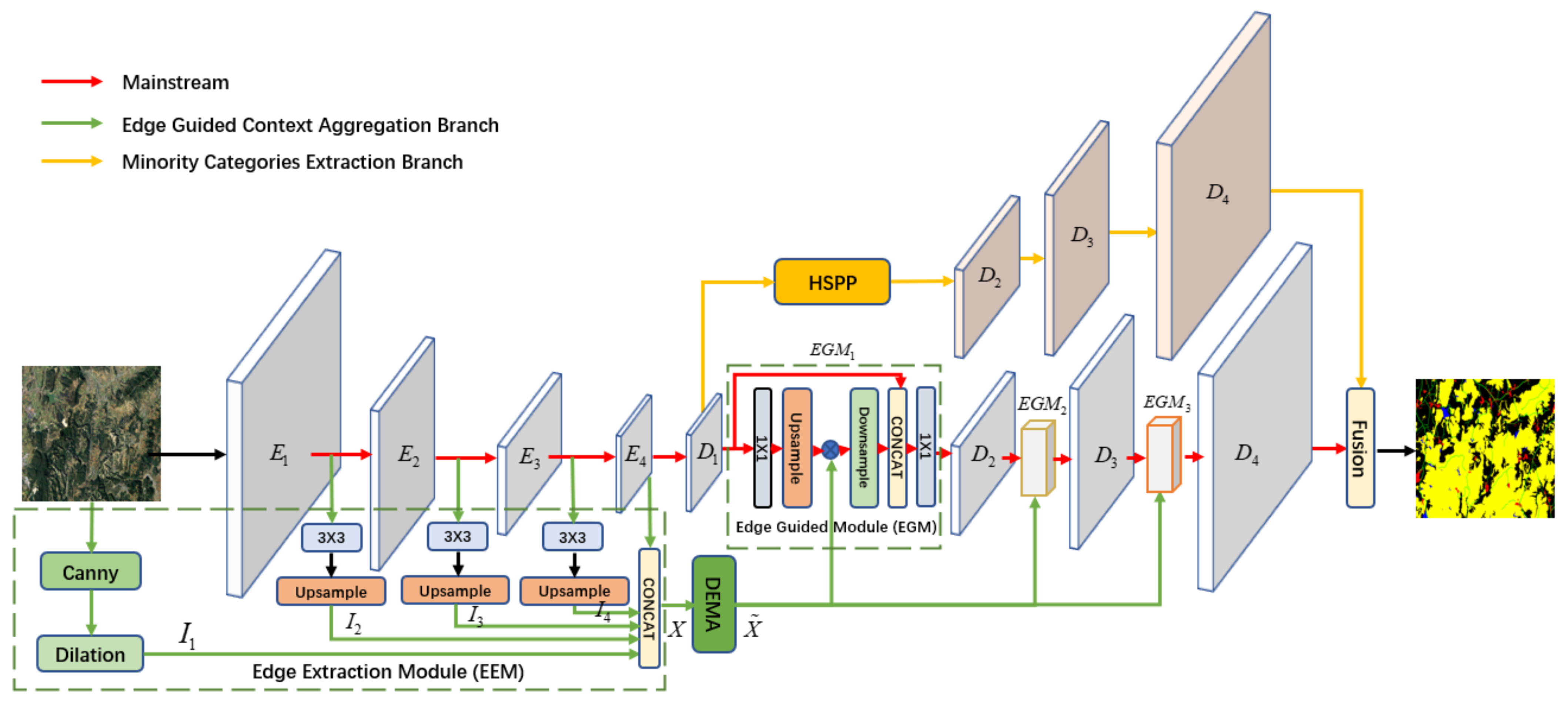
Figure 1.
Network architecture of the proposed edge guided context aggregation network (EGCAN). EGCAN contains three parts: the mainstream, the edge guided context aggregation branch, and the minority categories extraction branch.The input of the ECGAN is RGB images and the output is the corresponding segmentation result.
Figure 1.
Network architecture of the proposed edge guided context aggregation network (EGCAN). EGCAN contains three parts: the mainstream, the edge guided context aggregation branch, and the minority categories extraction branch.The input of the ECGAN is RGB images and the output is the corresponding segmentation result.
Figure 2.
An overview of the dual expectation maximization attention module (DEMA). DEMA contains two parts: SEMA and DEMA. The main steps of DEMA are step E and step M. Step E is purposed to calculate the spatial attention map z. Step M is purposed to maximize the maximum likelihood value obtained in step E to calculate the value of bases .
Figure 2.
An overview of the dual expectation maximization attention module (DEMA). DEMA contains two parts: SEMA and DEMA. The main steps of DEMA are step E and step M. Step E is purposed to calculate the spatial attention map z. Step M is purposed to maximize the maximum likelihood value obtained in step E to calculate the value of bases .
Figure 3.
An overview of the hybrid spatial pyramid pooling module (HSPP). The input of HSPP is from the output feature of the dilated Resnet101 backone network. The output of HSPP is the concatenation of different scales and rates of features.
Figure 3.
An overview of the hybrid spatial pyramid pooling module (HSPP). The input of HSPP is from the output feature of the dilated Resnet101 backone network. The output of HSPP is the concatenation of different scales and rates of features.
Figure 4.
Visual quality comparison of the proposed model over other different methods on the Tianzhi testing dataset.
Figure 4.
Visual quality comparison of the proposed model over other different methods on the Tianzhi testing dataset.
Figure 5.
Visual quality comparison of the proposed model over other different methods on the Vaihingen testing dataset.
Figure 5.
Visual quality comparison of the proposed model over other different methods on the Vaihingen testing dataset.
Figure 6.
Visual quality comparison of the proposed model over other different methods on the Potsdam testing dataset.
Figure 6.
Visual quality comparison of the proposed model over other different methods on the Potsdam testing dataset.
Figure 7.
Visual quality comparison of the proposed model over EEM on the Tianzhi testing dataset. (a) Unet, (b) Unet + sEEM, (c) Unet + EEM (without canny and dilation), (d) Unet + EEM (the whole).
Figure 7.
Visual quality comparison of the proposed model over EEM on the Tianzhi testing dataset. (a) Unet, (b) Unet + sEEM, (c) Unet + EEM (without canny and dilation), (d) Unet + EEM (the whole).
Figure 8.
Visual quality comparison of the proposed model over DEMA on the Tianzhi testing dataset. (a) Unet, (b) Unet + SEMA, (c) Unet + CEMA, (d) Unet + SEMA||CEMA, (e) Unet + CEMA→SEMA, (f) Unet + SEMA→CEMA.
Figure 8.
Visual quality comparison of the proposed model over DEMA on the Tianzhi testing dataset. (a) Unet, (b) Unet + SEMA, (c) Unet + CEMA, (d) Unet + SEMA||CEMA, (e) Unet + CEMA→SEMA, (f) Unet + SEMA→CEMA.
Figure 9.
Visual quality comparison of the proposed model over DEMA on the Tianzhi testing dataset. (a) Unet + EEM + DEM, (b) Unet + EEM + DEM + EGM1, (c) Unet + EEM + DEM + EGM1 + EGM2, (d) Unet + EEM + DEM + EGM1 + EGM2 + EGM3.
Figure 9.
Visual quality comparison of the proposed model over DEMA on the Tianzhi testing dataset. (a) Unet + EEM + DEM, (b) Unet + EEM + DEM + EGM1, (c) Unet + EEM + DEM + EGM1 + EGM2, (d) Unet + EEM + DEM + EGM1 + EGM2 + EGM3.
Figure 10.
Visual quality comparison of the proposed model over spatial pyramid pooling module on the Tianzhi testing dataset. (a) Unet + ASPP, (b) Unet + Non Local, (c) Unet + RCCA, (d) Unet + DNL, (e) Unet + HSPP.
Figure 10.
Visual quality comparison of the proposed model over spatial pyramid pooling module on the Tianzhi testing dataset. (a) Unet + ASPP, (b) Unet + Non Local, (c) Unet + RCCA, (d) Unet + DNL, (e) Unet + HSPP.
Table 1.
Hardware configuration.
Table 1.
Hardware configuration.
| CPU | Intel(R) Core(TM) i9-9900K CPU @ 3.60 GHz |
|---|
| RAM | 32 G |
| Disk | 2 T |
| GPU | GeForce GTX2080 Ti |
| System | Ubuntu 16.04 |
Table 2.
Quantitative comparisons between other methods and our method on the Tianzhi testing dataset. The bolded values represent the best results and the underlined values represent the second best results.
Table 2.
Quantitative comparisons between other methods and our method on the Tianzhi testing dataset. The bolded values represent the best results and the underlined values represent the second best results.
| Description | Farmland | Roads | Water | Vegetation | OA | mIoU |
|---|
| Deeplabv3+ | 65.2 | 34.9 | 93.8 | 73.4 | 83.7 | 66.8 |
| PSPNet | 64.5 | 34.9 | 93.9 | 72.7 | 83.4 | 66.5 |
| SegNet | 59.1 | 28.6 | 92.6 | 73.0 | 82.4 | 63.3 |
| UNet | 60.0 | 20.5 | 92.5 | 64.4 | 79.2 | 59.4 |
| ErfNet | 53.8 | 14.6 | 89.2 | 73.5 | 81.2 | 57.8 |
| FCN | 58.9 | 24.6 | 92.4 | 74.8 | 83.0 | 62.7 |
| Ours | 65.3 | 39.3 | 93.4 | 74.4 | 84.1 | 68.1 |
Table 3.
Quantitative comparisons between other methods and our proposed method on the Vaihingen testing dataset. The bolded values represent the best results and the underlined values represent the second best results.
Table 3.
Quantitative comparisons between other methods and our proposed method on the Vaihingen testing dataset. The bolded values represent the best results and the underlined values represent the second best results.
| Method | Imp_surf | Building | Low_veg | Tree | Car | Clutter | OA | Mean F1 |
|---|
| SVL_3 | 86.6 | 91.0 | 77.0 | 85.0 | 55.6 | 58.9 | 84.8 | 79.0 |
| DST_2 | 90.5 | 93.7 | 83.4 | 89.2 | 72.6 | 61.2 | 89.1 | 85.9 |
| UZ_1 | 89.2 | 92.5 | 81.6 | 86.9 | 57.3 | 58.6 | 87.3 | 81.5 |
| RIT_L7 | 90.1 | 93.2 | 81.4 | 87.2 | 72.0 | 63.4 | 87.8 | 84.8 |
| ONE_7 | 91.0 | 94.5 | 84.4 | 89.9 | 77.8 | 71.9 | 89.8 | 87.5 |
| ADL_3 | 89.5 | 93.2 | 82.3 | 88.2 | 63.3 | 69.6 | 88.0 | 83.3 |
| DLR_10 | 92.3 | 95.2 | 84.1 | 90.0 | 79.3 | 79.3 | 90.3 | 88.2 |
| CASIA2 | 93.2 | 96.0 | 84.7 | 89.9 | 86.7 | 84.7 | 91.1 | 90.1 |
| BKHN10 | 92.9 | 96.0 | 84.6 | 89.8 | 88.8 | 81.1 | 91.0 | 90.4 |
| TreeUNet | 92.5 | 94.9 | 83.6 | 89.6 | 85.9 | 82.6 | 90.4 | 89.3 |
| Ours | 93.2 | 95.8 | 84.2 | 89.9 | 85.3 | 85.6 | 91.0 | 89.7 |
Table 4.
Quantitative comparisons between other methods and our proposed method on the Potsdam testing dataset. Cascade denotes the Cascade-Edge-FCN and Correct denotes the Correct-Edge-FCN [
56]. EDENet denotes the edge distribution–enhanced semantic segmentation neural network [
57]. The bolded values represent the best results and the underlined values represent the second best results.
Table 4.
Quantitative comparisons between other methods and our proposed method on the Potsdam testing dataset. Cascade denotes the Cascade-Edge-FCN and Correct denotes the Correct-Edge-FCN [
56]. EDENet denotes the edge distribution–enhanced semantic segmentation neural network [
57]. The bolded values represent the best results and the underlined values represent the second best results.
| Method | Imp_surf | Building | Low_veg | Tree | Car | Clutter | OA | Mean F1 |
|---|
| SVL_1 | 83.5 | 91.7 | 72.2 | 63.2 | 62.2 | 69.3 | 77.8 | 74.6 |
| DST_5 | 92.5 | 96.4 | 86.7 | 88.0 | 94.7 | 78.4 | 90.3 | 91.7 |
| UZ_1 | 89.3 | 95.4 | 81.8 | 80.5 | 86.5 | 79.7 | 85.8 | 86.7 |
| RIT_L7 | 91.2 | 94.6 | 85.1 | 85.1 | 92.8 | 83.2 | 88.4 | 89.8 |
| SWJ_2 | 94.4 | 97.4 | 87.8 | 87.6 | 94.7 | 82.1 | 91.7 | 92.4 |
| CASIA2 | 93.3 | 97.0 | 87.7 | 88.4 | 96.2 | 83.0 | 91.1 | 92.5 |
| TreeUNet | 93.1 | 97.3 | 86.8 | 87.1 | 95.8 | 82.9 | 90.7 | 92.0 |
| Cascade | 76.3 | 82.2 | 78.3 | 81.7 | 83.5 | 86.9 | 81.4 | 82.3 |
| Correct | 83.5 | 88.2 | 84.9 | 86.1 | 85.6 | 87.5 | 85.9 | 86.4 |
| EDENet | 95.6 | 96.3 | 88.4 | 89.6 | 83.5 | 87.6 | 90.1 | 91.8 |
| Ours | 93.4 | 97.1 | 88.2 | 89.2 | 96.9 | 86.3 | 91.4 | 93.0 |
Table 5.
Quantitative comparisons on edge extraction module (EEM). (a) Unet, (b) Unet + sEEM, (c) Unet + EEM (without canny and dilation), (d) Unet + EEM (the whole). The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
Table 5.
Quantitative comparisons on edge extraction module (EEM). (a) Unet, (b) Unet + sEEM, (c) Unet + EEM (without canny and dilation), (d) Unet + EEM (the whole). The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
| Methods | a | b | c | d |
|---|
| sEEM | | ✓ | | |
| EEM (without Canny and Dilation) | | | ✓ | |
| EEM (the whole) | | | | ✓ |
| mIoU (↑) | 59.4 | 60.7 | 61.9 | 63.2 |
Table 6.
Quantitative comparisons on dual expectation maximization attention module (DEMA). (a) Unet, (b) Unet + SEMA, (c) Unet + CEMA, (d) Unet + SEMA||CEMA, (e) Unet + CEMA→SEMA, (f) Unet + SEMA→CEMA. The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
Table 6.
Quantitative comparisons on dual expectation maximization attention module (DEMA). (a) Unet, (b) Unet + SEMA, (c) Unet + CEMA, (d) Unet + SEMA||CEMA, (e) Unet + CEMA→SEMA, (f) Unet + SEMA→CEMA. The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
| Module Description | a | b | c | d | e | f |
|---|
| SEMA | | ✓ | | ✓ | ✓ | ✓ |
| CEMA | | | ✓ | ✓ | ✓ | ✓ |
| SEMA || CEMA | | | | ✓ | | |
| CEMA → SEMA | | | | | ✓ | |
| SEMA → CEMA | | | | | | ✓ |
| mIoU (↑) | 59.4 | 60.6 | 61.1 | 62.8 | 64.7 | 65.3 |
Table 7.
Quantitative comparisons on edge guided module (EGM). (a) Unet + EEM + DEM, (b) Unet + EEM + DEM + EGM1, (c) Unet + EEM + DEM + EGM1 + EGM2, (d) Unet + EEM + DEM + EGM1 + EGM2 + EGM3. The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
Table 7.
Quantitative comparisons on edge guided module (EGM). (a) Unet + EEM + DEM, (b) Unet + EEM + DEM + EGM1, (c) Unet + EEM + DEM + EGM1 + EGM2, (d) Unet + EEM + DEM + EGM1 + EGM2 + EGM3. The checkmarks indicate that the corresponding modules are selected. The bolded values represent the best results and the underlined values represent the second best results.
| Module Description | a | b | c | d |
|---|
| EGM1 | | ✓ | ✓ | ✓ |
| EGM2 | | | ✓ | ✓ |
| EGM3 | | | | ✓ |
| mIoU (↑) | 66.4 | 66.7 | 67.3 | 68.1 |
Table 8.
Quantitative comparisons on spatial pyramid module. (a) Unet + ASPP, (b) Unet + Non Local, (c) Unet + RCCA, (d) Unet + DNL, (e) Unet + HSPP. The bolded values represent the best results and the underlined values represent the second best results.
Table 8.
Quantitative comparisons on spatial pyramid module. (a) Unet + ASPP, (b) Unet + Non Local, (c) Unet + RCCA, (d) Unet + DNL, (e) Unet + HSPP. The bolded values represent the best results and the underlined values represent the second best results.
| Module Description | (a) | (b) | (c) | (d) | (e) |
|---|
| mIoU | 64.3 | 63.5 | 62.8 | 66.7 | 68.1 |


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}