1. Introduction
Optical remote sensing images contain a large amount of scene information and intuitively reflect the shape, color, and texture of objects. Referring to specific algorithms, object detection of optical remote sensing images aims to search for and locate the objects of interest, such as aircraft, tanks, ships, and vehicles. Typical applications are urban planning, land use, disaster survey, military monitoring, and so on [
1,
2]. With the rapid development of observation technologies, the resolutions of acquired remote sensing images are becoming higher and higher. These high-resolution remote sensing images can provide detailed high-quality information that offers great opportunities to develop object-level applications. The characteristics and challenges of remote sensing images are summarized as follows: large scale, diverse direction, various shapes, and complex background. A multitude of works have aimed to theoretically and practically solve these problems [
3].
The early object-detection algorithms for optical remote sensing images were mostly based on manually designed features [
4,
5,
6,
7,
8,
9]. Usually, candidate regions were first extracted, and then the features were manually designed for the objects. Finally, the object categories were determined by certain classifiers. Typical strategies were prior region uses, template matching, feature classification, selective search, etc. From the human perception of the object location, some methods learned the prior knowledge of candidate regions. This strategy is widely used for some representative applications, including segmentation of ocean and land for ship detection and airport detection for aircraft detection. To separate the sea surface, Antelo et al. [
4] utilized the active contour method by constructing and minimizing the energy function. Some methods adopted the idea of template matching and match the candidate feature with the template library of objects. Liu et al. [
7] proposed an aircraft detection method from coarse to fine. First, template matching is used to find the candidate areas of aircraft, and then principal component analysis (PCA) and a kernel density function are used to identify each area. Xu et al. [
6] generated a ship shape library based on the Hough transform and used the sliding window method to calculate the feature similarity between each window region and shape library. The feature classification-based methods [
10,
11] usually extract the sliding window features first, and then certain classifiers are designed to predict the sliding image patches. Zhang et al. [
12] used a sliding window to generate windows of different sizes and aspect ratios and extracted the visual features for each window. The cascading support vector machine (SVM) is then applied to complete the extraction process of candidate regions. The frequently used tool of selective search-based methods is segmentation which applies the similarity-merging strategy to obtain large areas. Aiming to capture possible object locations, Uijlings et al. [
13] applied the appearance structure to guide the sampling process for the selective search. To reduce the search space, Liu et al. [
14] analyzed the possibility of covering ships by rotated bounding boxes. In addition, a small number of potential candidates with high scores are found by a multi-cascaded linear model.
The methods mentioned above mostly adopted the traversal search method possessing redundant calculation and cannot deal with the complex and changeable environment of remote sensing images. Therefore, a great many algorithms have also tried to address the aspect of feature extraction. Feature extraction is the most critical step that directly affects the performance and efficiency of a detection algorithm. The commonly used features in object detection of remote sensing images include the color feature, the texture feature, the edge shape, and the context feature. To overcome the variable characteristics of the sea environment, Morillas et al. [
15] proposed using block color and texture features for ship detection. In order to detect buildings, Konstantinidis et al. [
16] combined the first module-enhanced HOG-LBP features and the second module region refinement processes. The texture feature is a visual feature that describes the homogeneity of the image, reflecting the slow change or periodic change of the object surface structure. Brekke et al. [
17] conducted oil-spill detection based on the different texture characteristics between the sea surface area and the sea surface oil-slick area. In addition, the edge features reflect the object edge and shape information. To facilitate object detection, edge shape features are usually required to be invariant in scale, translation, and rotation. Sun et al. [
18] extracted SIFT features from the sliding window and used the bag of words (BoW) model for classification. Cheng et al. [
19] extracted binarized normed gradients (BING) for each window and used weighted SVM classifiers to improve the calculating speed. Tong et al. [
20] also used SIFT features for the ship candidate areas. After extracting candidate ships, Shi et al. [
21] extracted HOG (histograms of oriented gradients) features for each region. Then an AdaBoost classifier was adopted to screen and classify candidate regions. To improve the rotation invariance of the HOG feature, Zhang et al. [
22] utilized part models to generate rotation invariance features. Moreover, the context feature, which mainly represents the spatial position relation of sequential topology adjacency between different instances, is also worthwhile [
23,
24,
25]. On the basis of active contour segmentation, Liu et al. [
23] introduced an energy function method to complete the separation of the sea. The ships are detected using context analyses and shape description. Using Markov random fields (MRF), Gu et al. [
24], modeled the spatial position relations of objects to discriminate the object categories.
However, the adaptation range and robustness of traditional object-detection algorithms are limited, making them difficult to apply in complex environments of remote sensing images. With the thriving development of deep learning, the deep features extracted by a neural network have a stronger semantic representation ability and discrimination [
26,
27]. In light of the improvement of diversified object directions, some object-detection methods enhance the training image samples [
28,
29]. Cheng et al. [
30] optimized a new objective function by introducing regularized constraints to achieve rotation invariance. Later on, Cheng et al. [
31] also added a rotation-invariant regularizer to convolutional neural network (CNN) features by an objective function that can force tight mapping of feature representations to achieve rotation invariability. The ORSIm detector [
32] adopted a novel space-frequency channel feature (SFCF) to deal with the rotation problem. This method comprehensively considers the rotation-invariant features from both the frequency domain and the spatial domain. To provide for small-scale objects [
33,
34], Zhang et al. [
35] up-sampled candidate regions that were extracted in the previous stage. Replacing the convolution, Liu et al. [
36] used dilated convolution to reduce parameters on the same receptive field. However, dilated convolution could cause the loss of local information. Wang et al. [
37] improved the loss function to increase the training weight of small objects by combining with shallow information. The R3Det [
38] improved the positioning accuracy of dense objects by adding fine-tuning modules to ensure the alignment of object features and object centers. Some works also aim to improve the adaptation of various object scales [
39,
40,
41,
42,
43]. Based on the Faster R-CNN [
44], Zhang et al. [
41] introduced a candidate region extraction network to detect objects of different scales. A full-scale object-detection network (FSD-NET) was proposed in [
42], and this network contained a backbone with a multi-scale enhanced network. In [
43], a global component to a local network (GLNet) was also proposed, and the spatial contextual correlations were encoded by the long short-term memory with a clip. Given that the horizontal bounding boxes are not friendly to oriented objects, a large number of works adopted oriented quadrangles to surround the objects [
45,
46,
47,
48,
49]. Zhu et al. [
46] proposed an adaptive-period-embedding (APE) method to represent oriented objects of aerial images. Instead of regressing the four vertices of oriented objects, an effective and simple framework was proposed in [
48]. In this framework, the vertex of horizontal bounding boxes on each corresponding side is glided to the oriented object. Different remote-sensing sensors possess the benefits of complementary information, hence the works [
50,
51] are based on deep neural networks and integrate several features to obtain an overall performance improvement.
The human visual mechanism possesses the ability to focus on a saliency region with obvious visual features, ignoring irrelevant background. Therefore, the attention mechanism is the most frequently used technique to improve the semantic representation [
52,
53,
54]. To reduce the detection area, Song et al. [
55] utilized color, direction, and gradient information to extract visual features and extracted ship regions according to saliency characteristics. To determine a potential airport, Yao et al. [
8] adopted saliency regions to extract scale invariant feature transform (SIFT) features. In [
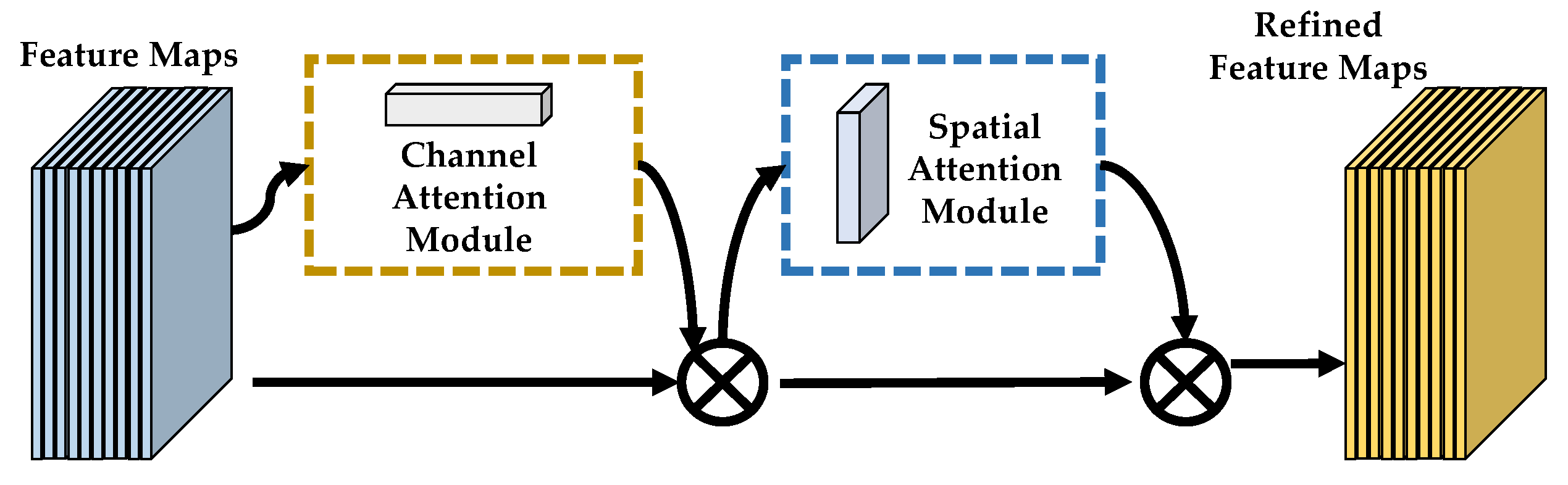
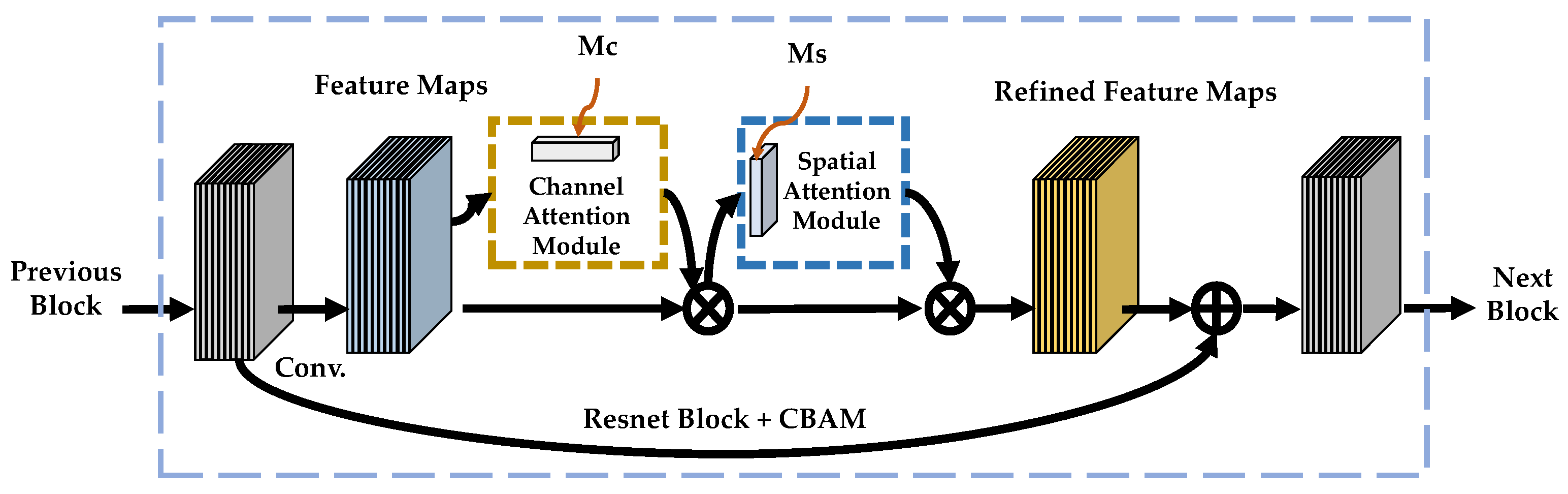
56], the authors proposed a convolutional block attention module which consists of a channel attention module and a spatial attention module. Wang et al. [
57] used a multi-scale attention structure with a residual connection to meet the scale change. For multi-category detection, Wang et al. [
45] also adopted a semantic attention-based network to extract the semantic representation of the oriented bounding box. In light of the densely distributed objects, the SCRDet [
58] added a pixel attention mechanism and channel attention mechanism. With respect to the loss funtion, Sun et al. [
59] proposed an adaptive saliency-biased loss (ASBL) for the both image level and the anchor level. In addition, the SCRDet++ [
60] indirectly used the attention mechanism to improve the boundary differentiation of dense objects. Similarly, the work [
61] used the density saliency attention to detect clustered buildings.
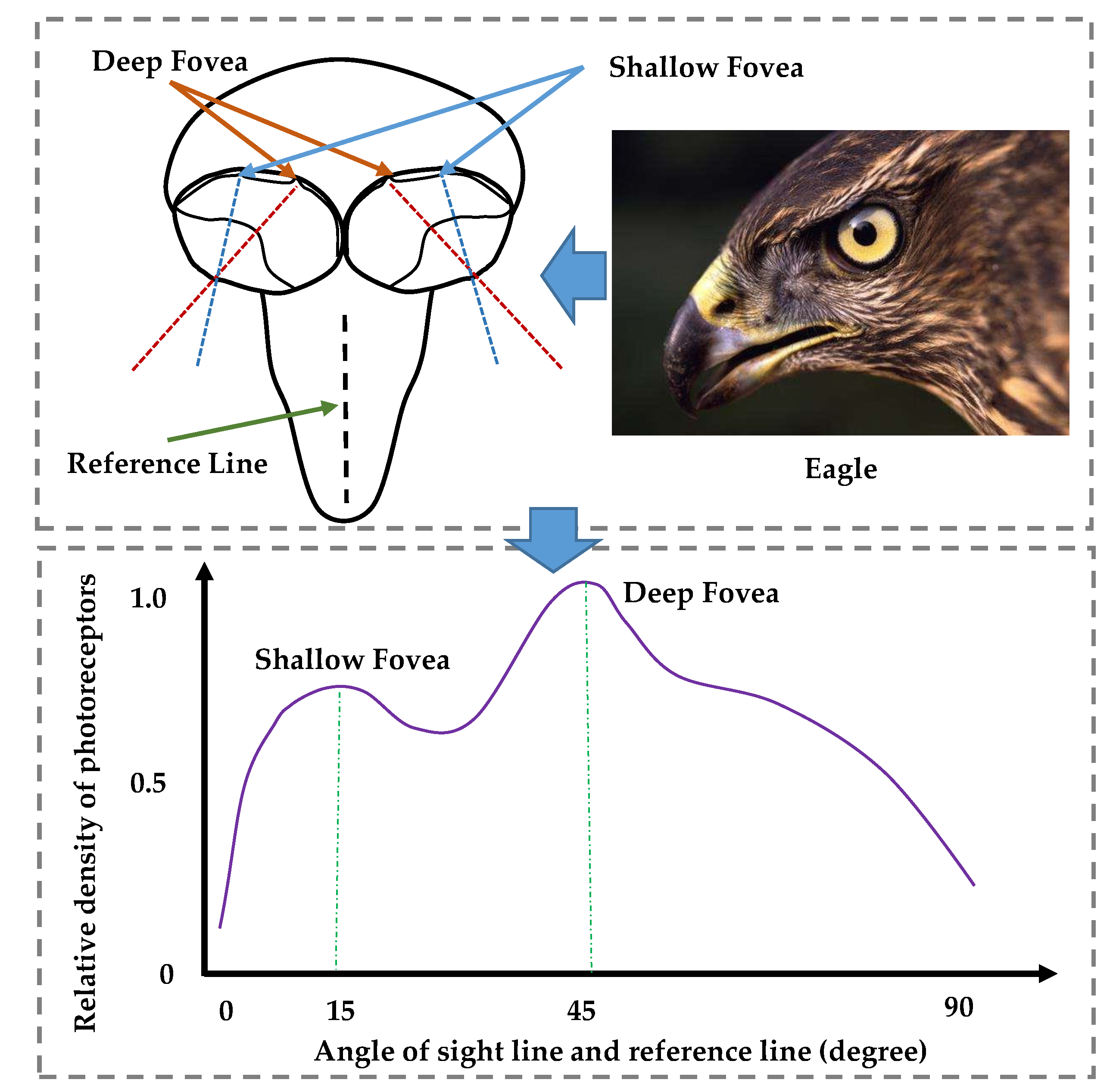
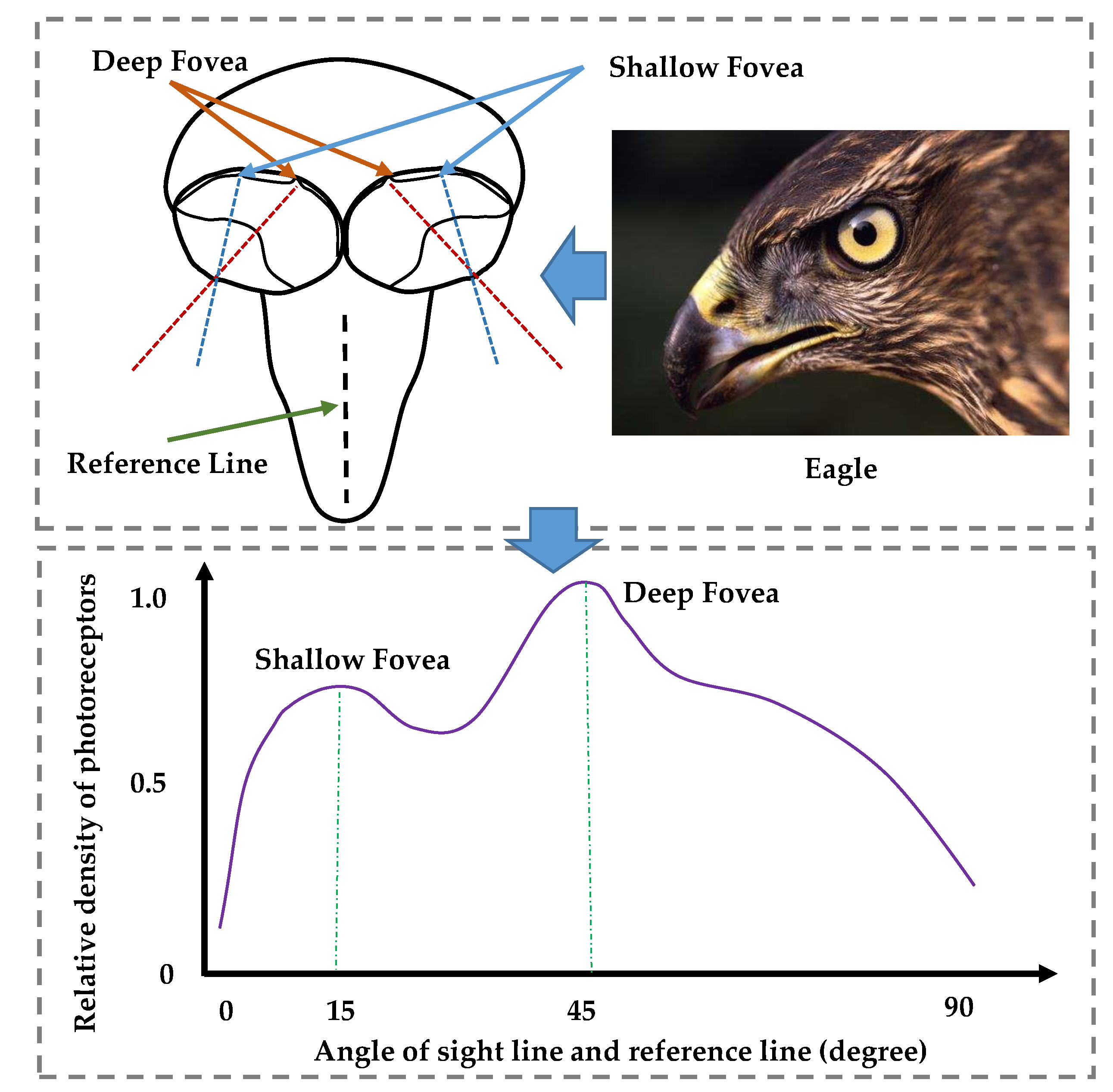
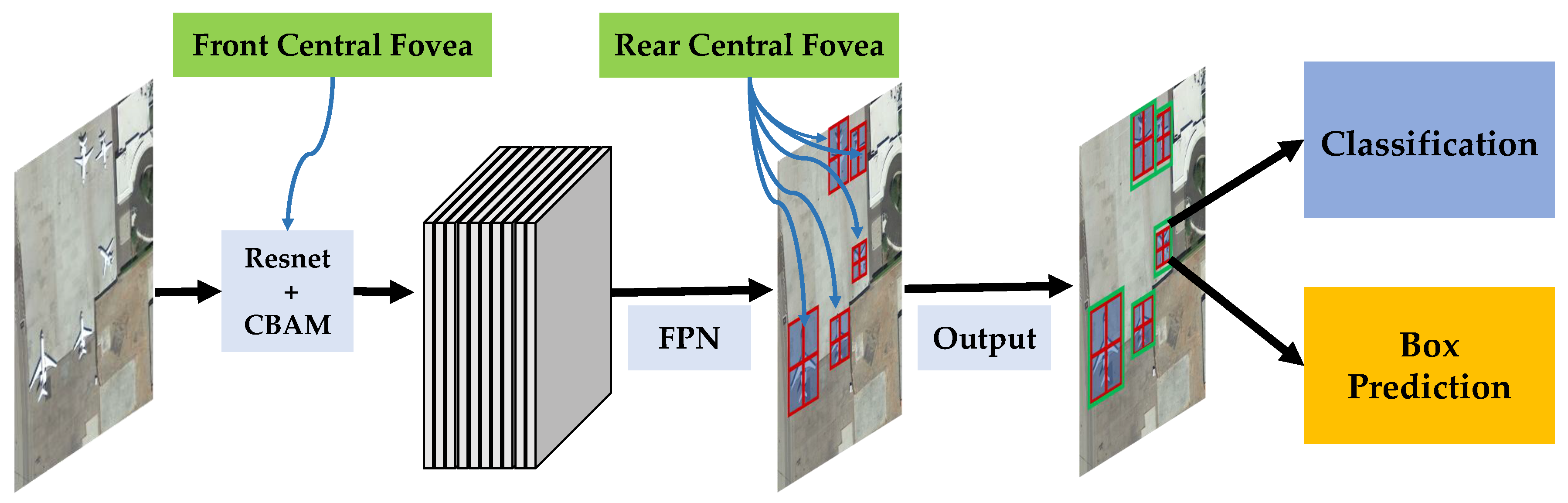
Although there are many good attention-based approaches for the object detection of remote sensing images, the robust problem is not yet completely solved. Therefore, in this paper, we propose a novel structure aiming to learn more robust and accurate object classification and positioning for remote sensing images. This framework is inspired by the eagle-eye, which has its complementary and exchangeable mechanism between the two foveae. The main contributions are as follows:
- (1)
We propose a new architecture named the eagle-eye fovea network (EFNet) to detect objects in remote sensing images. This architecture is inspired by the vision attention mechanism and the cascade attention mechanism of eagle-eyes.
- (2)
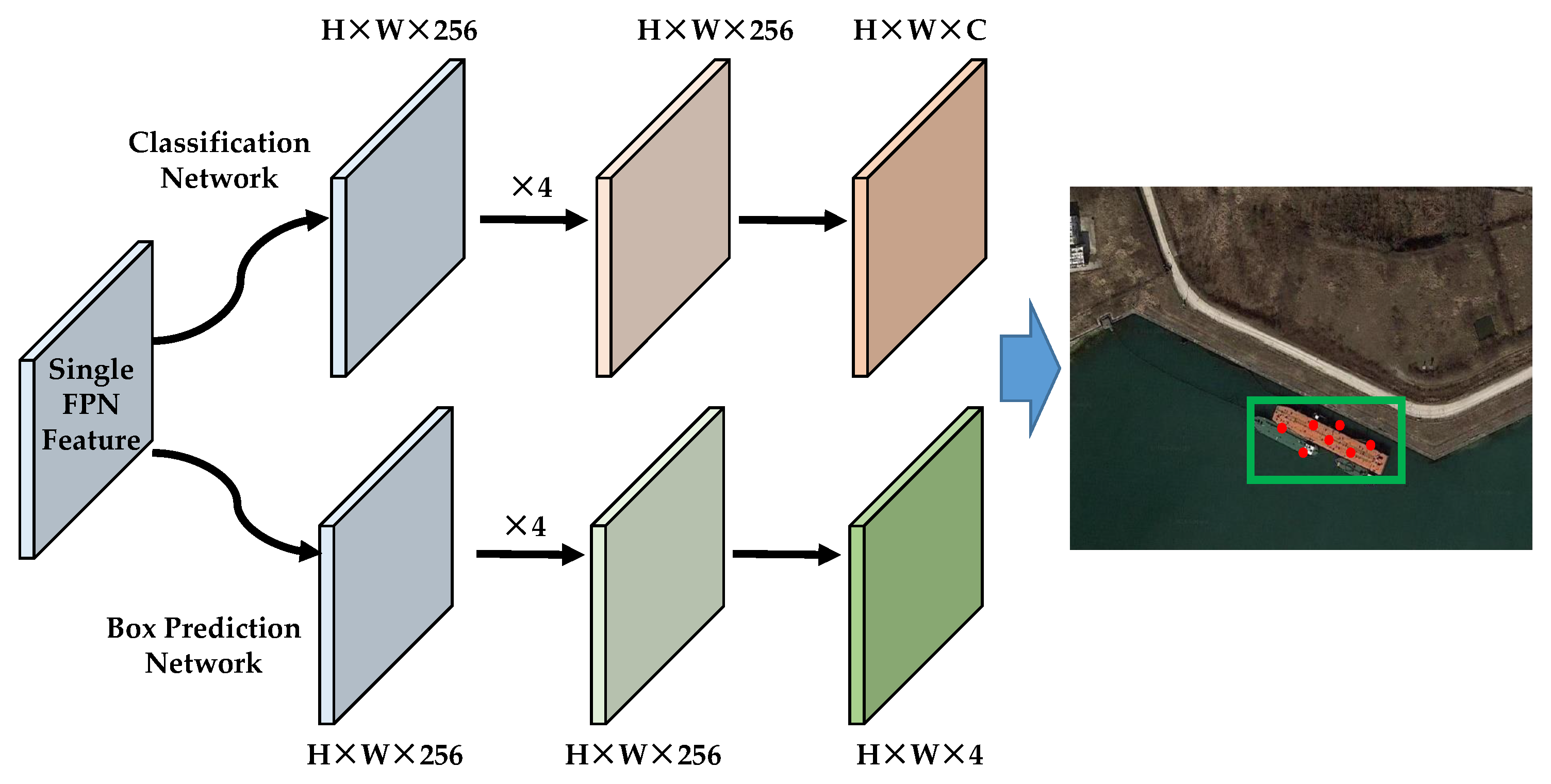
Two eagle-eye fovea modules, front central fovea (FCF) and rear central fovea (RCF), are included in the EFNet. The FCF mainly aims to learn the candidate–object knowledge based on the channel attention and the spatial attention, while the RCF aims mainly to predict the refined objects with two subnetworks without anchors.
- (3)
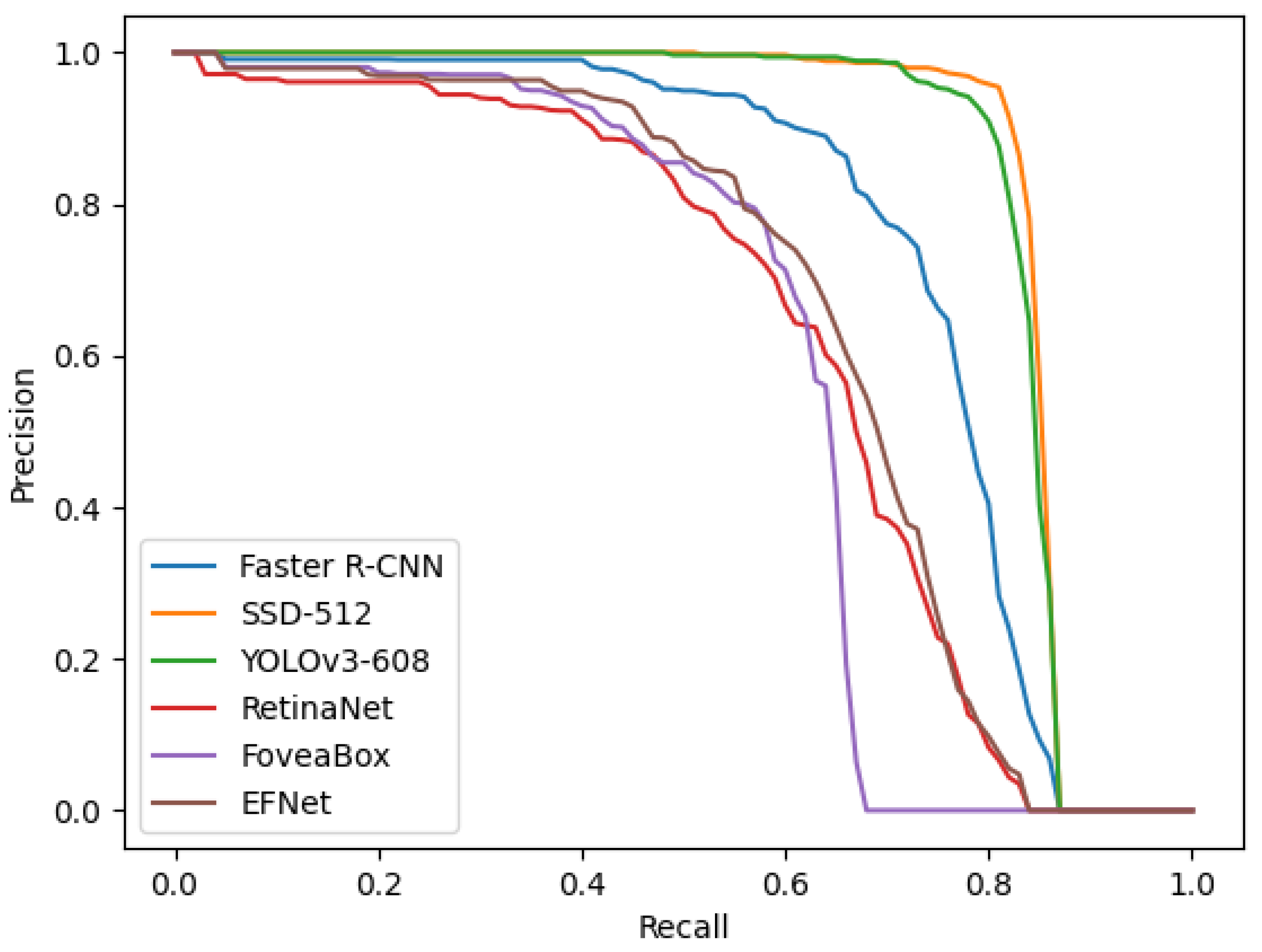
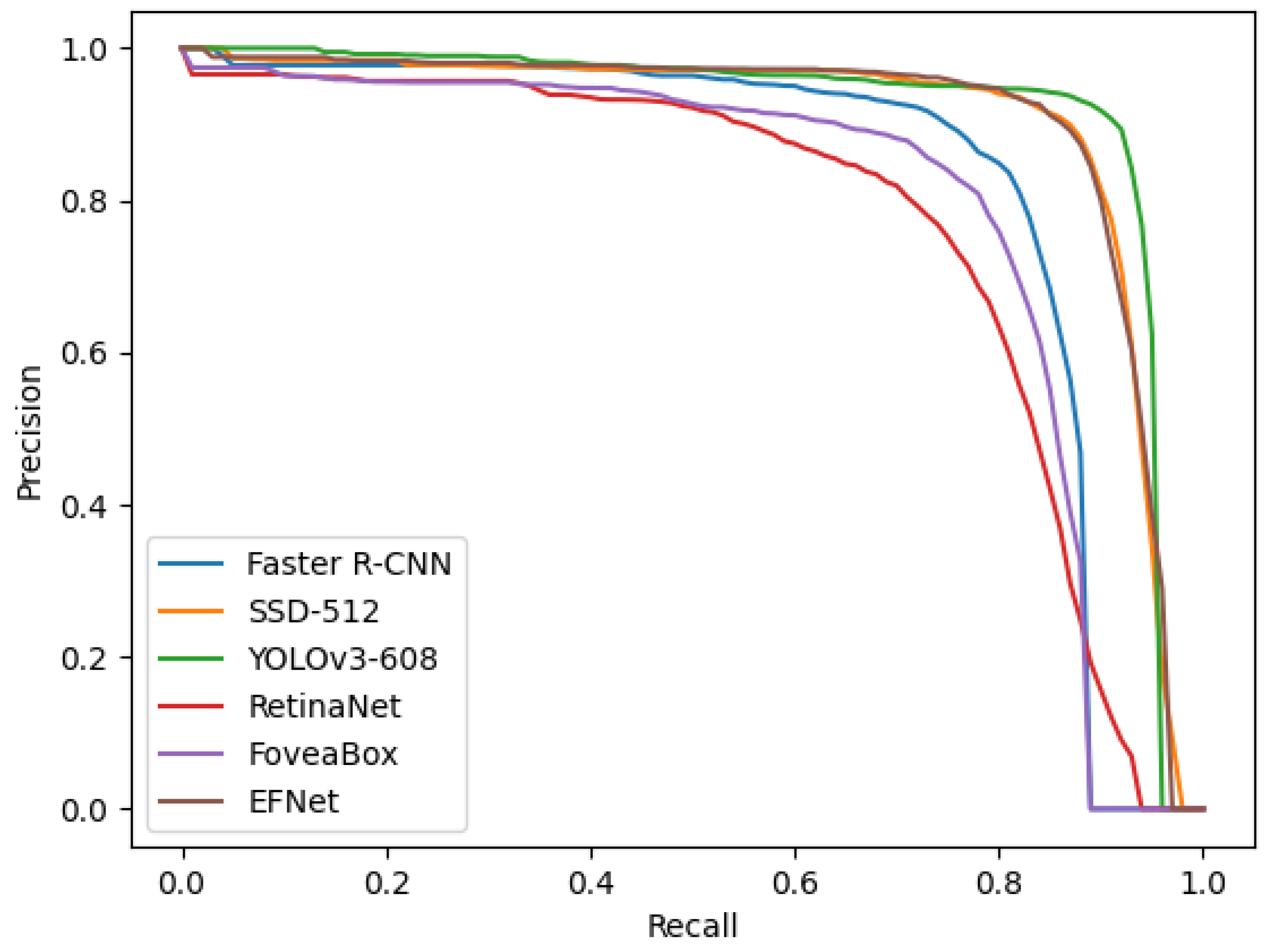
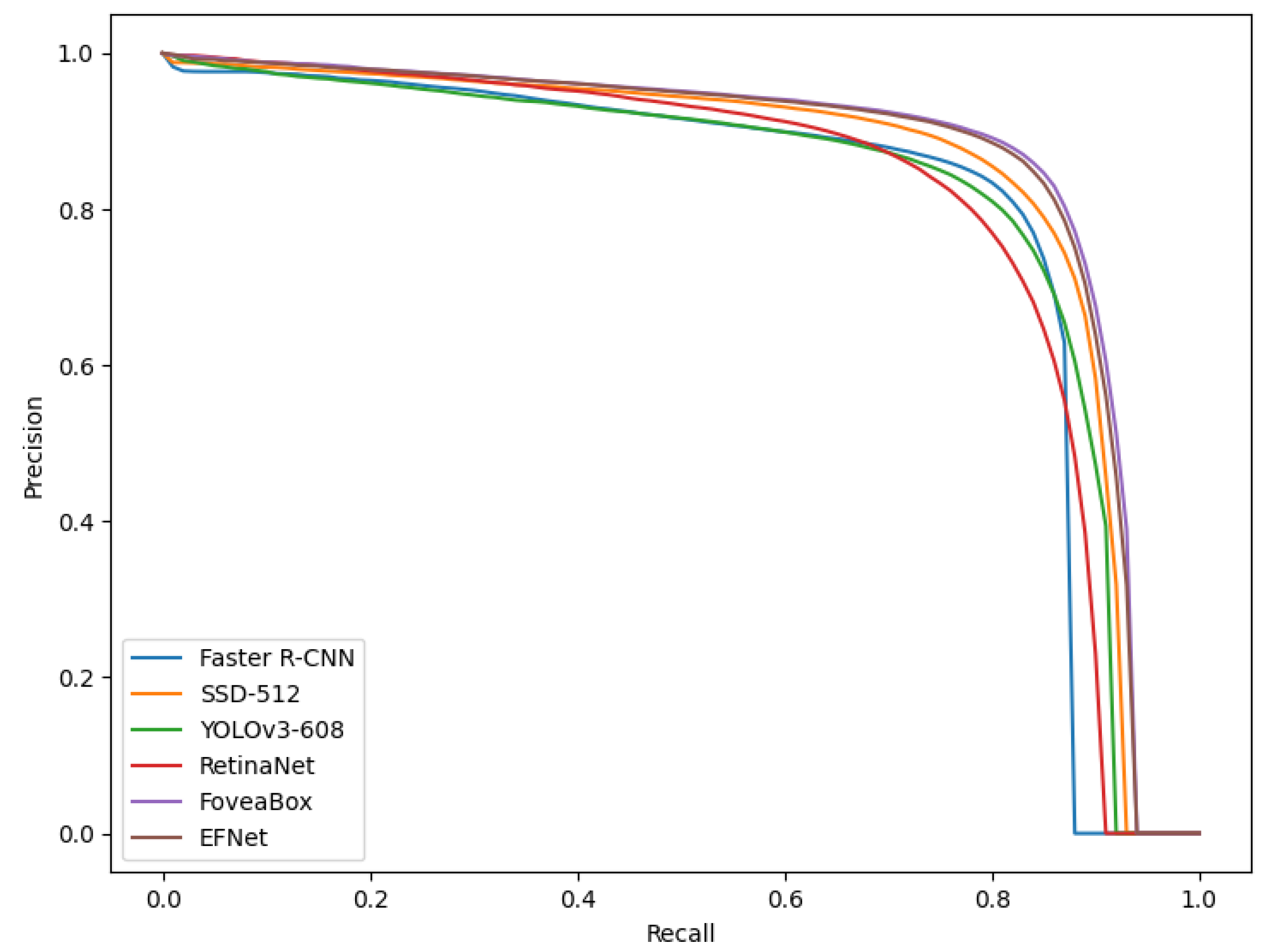
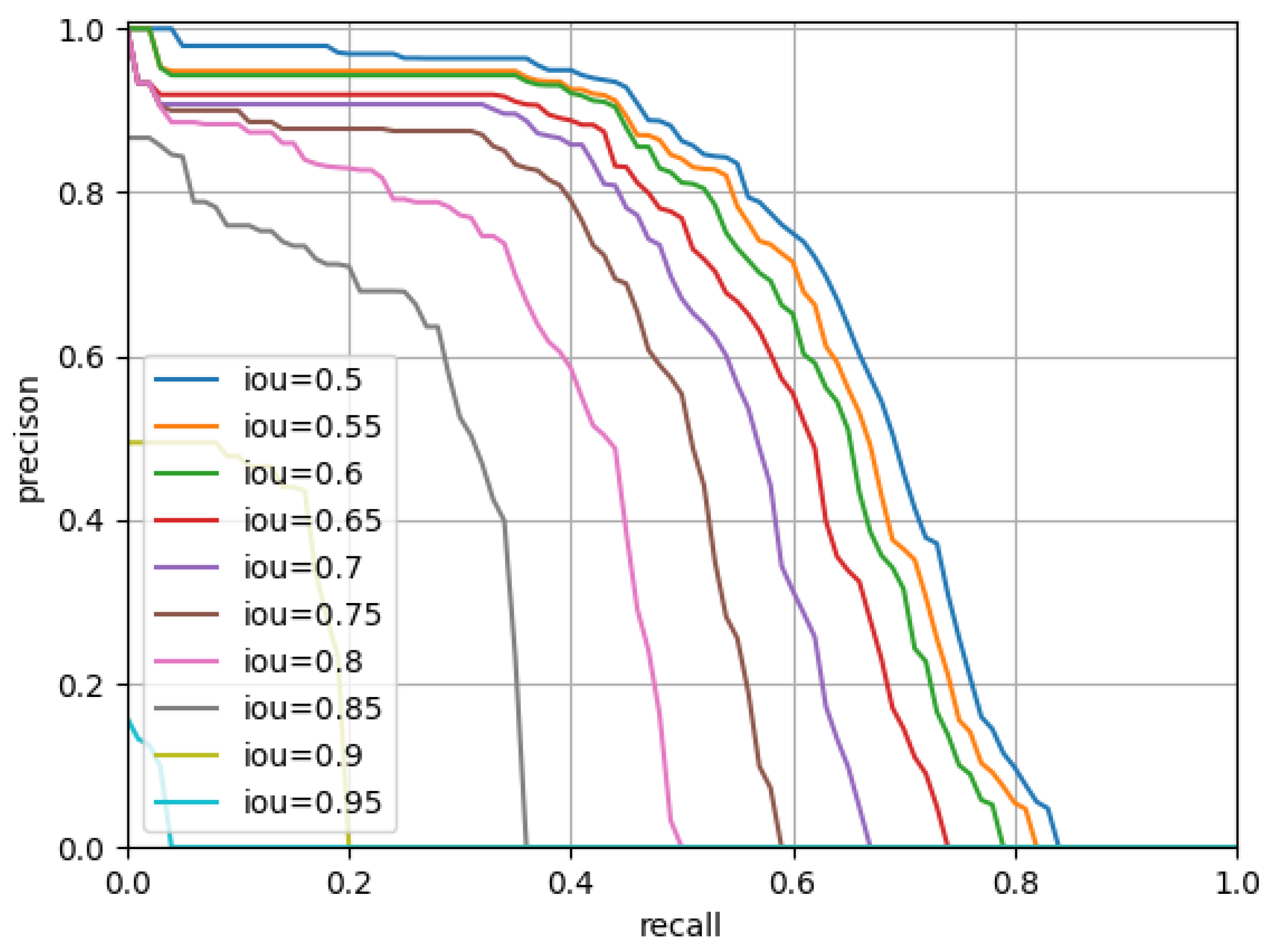
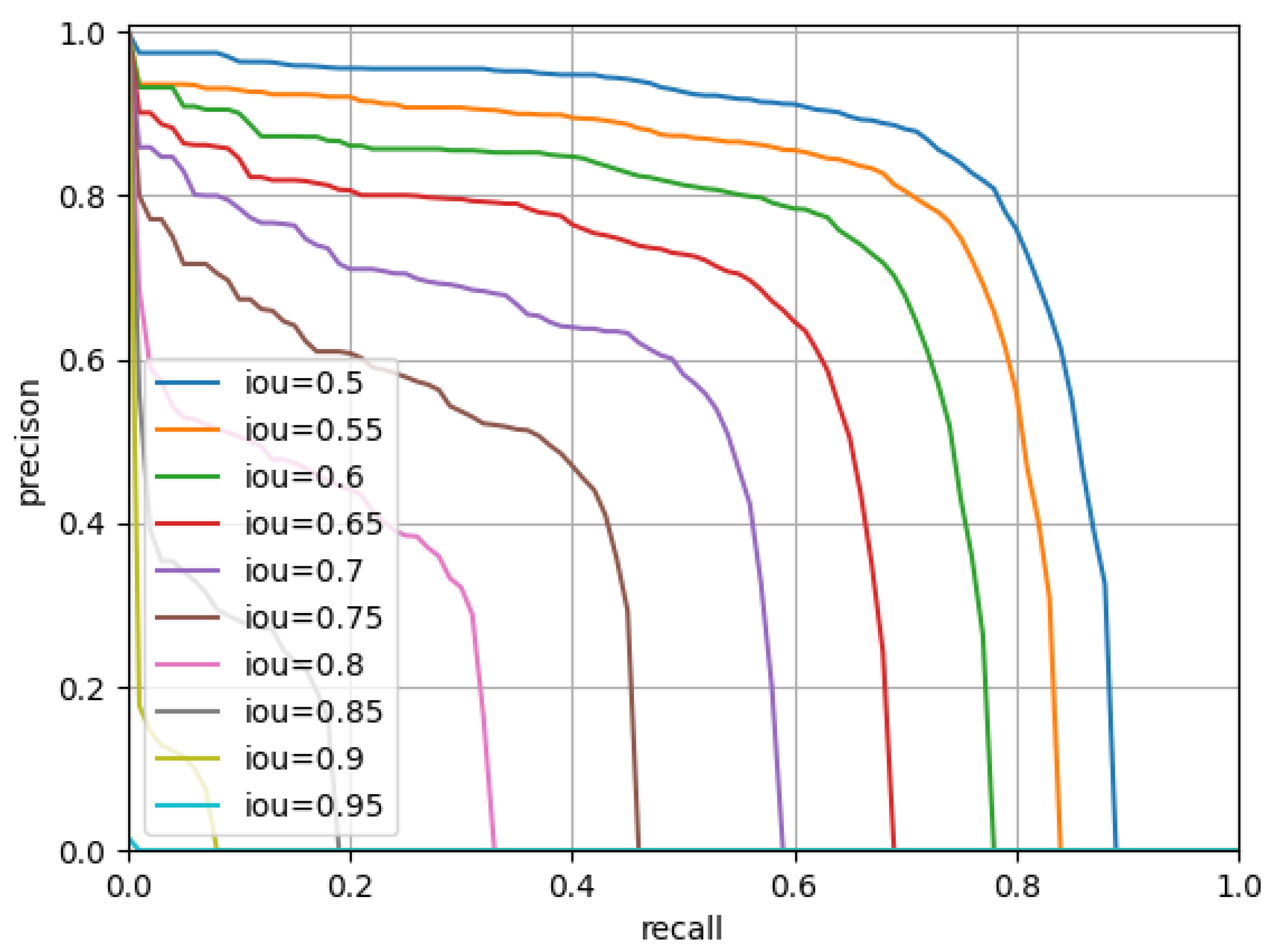
The two central foveae possess the complementary mechanism. The experimental results in three public datasets for object detection in remote sensing images demonstrates the effectiveness of the proposed architecture and method.
The remaining sections of this paper are organized as follows. Some related works are reviewed in
Section 2. The proposed methodology is introduced in
Section 3.
Section 4 shows the experimental results. A discussion follows in
Section 5. Finally,
Section 6 includes our conclusion.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}