
An Attention Cascade Global–Local Network for Remote Sensing Scene Classification



Abstract
:1. Introduction
2. Related Work
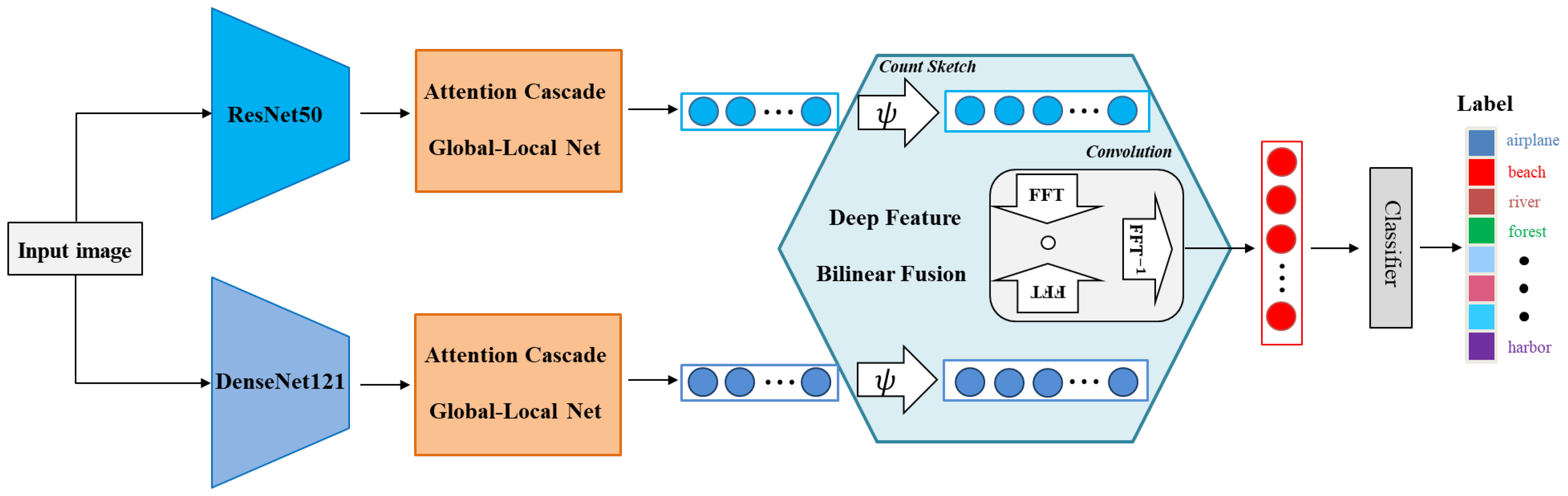
3. The Proposed Method
3.1. Feature Extraction
3.2. Attention Cascade Global-Local Net (ACGLNet)
3.3. Deep Feature Bilinear Fusion
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Setups
4.4. Performance Comparison
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A unified framework for multi-label image classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2285–2294. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference and Workshop, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-local attention network for aerial scene classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, C.; Zheng, Y.; Wang, R. Decision-Level Fusion with a Pluginable Importance Factor Generator for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 3579. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, T.; Wang, Y.; Wang, R.; Wang, Q. A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 433. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J.; Han, J.; Guo, L. Auto-encoder-based shared mid-level visual dictionary learning for scene classification using very high resolution remote sensing images. IET Comput. Vis. 2015, 9, 639–647. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Soh, L.K.; Tsatsoulis, C. Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 1999, 37, 780–795. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state-of-the-art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Ratha, N.K.; Lakshmanan, S. Object detection using gabor filters. Pattern Recognit. 1997, 30, 295–309. [Google Scholar] [CrossRef]
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2016, 348, 209–226. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2014, 18, 1527–1554. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xing, C.; Ma, L.; Yang, X. Stacked Denoise autoencoder based feature extraction and classification for hyperspectral images. J. Sens. 2016, 2016, 3632943. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 818–832. [Google Scholar] [CrossRef]
- Zhou, Z.; Zheng, Y.; Ye, H. Satellite image scene classification via convNet with context aggregation. In Proceedings of the 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; pp. 329–339. [Google Scholar]
- Yuan, Y.; Fang, J.; Lu, X.; Feng, Y. Remote sensing image scene classification using rearranged local features. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1779–1792. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Nogueira, K.; Penatti, O.A.; Santos, J.A.D. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]
- Ye, L.; Wang, L.; Sun, Y.; Zhao, L.; Wei, Y. Parallel multi-stage features fusion of deep convolutional neural networks for aerial scene classification. Remote Sens. Lett. 2018, 9, 294–303. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Aerial scene classification via multilevel fusion based on deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 287–291. [Google Scholar] [CrossRef]
- Leng, J.; Liu, Y.; Chen, S. Context-Aware Attention Network for Image Recognition. Neural Comput. Appl. 2019, 31, 9295–9305. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, Z.; Zhang, W.; Yi, Y.; Zhang, C.; Xu, Q. A convolutional neural network based on grouping structure for scene classification. Remote Sens. 2021, 13, 2457. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A multi-branch feature fusion strategy based on an attention mechanism for remote sensing image scene classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based denseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Li, F.; Feng, R.; Han, W.; Wang, L. An augmentation attention mechanism for high-spatial-resolution remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 3862–3878. [Google Scholar] [CrossRef]
- Guo, D.; Xia, Y.; Luo, X. Scene classification of remote sensing images based on saliency dual attention residual network. IEEE Access 2020, 8, 6344–6357. [Google Scholar] [CrossRef]
- Fan, R.; Wang, L.; Feng, R.; Zhou, Y. Attention based residual network for high-resolution remote sensing imagery scene classification. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1346–1349. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 3085–3094. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact bilinear pooling. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 317–326. [Google Scholar]
- Pham, N.; Pagh, R. Fast and scalable polynomial kernels via explieit feature maps. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 239–247. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogram. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef] [Green Version]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2015, 10, 745–752. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, F. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Anwer, R.M.; Khan, F.S.; Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Wang, S.; Ning, C.; Zhou, H. Enhanced feature pyramid network with deep semantic embedding for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7918–7932. [Google Scholar] [CrossRef]
- Shafaey, M.A.; Salem, M.A.M.; Ebeid, H.M.; Al-Berry, M.N.; Tolba, M.F. Comparison of CNNs for remote sensing scene classification. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 27–32. [Google Scholar]
- Altaei, M.; Ahmed, S.; Ayad, H. Effect of texture feature combination on satellite image classification. Int. J. Adv. Res. Comput. Sci. 2018, 9, 675–683. [Google Scholar] [CrossRef] [Green Version]
- Tian, Q.; Wan, S.; Jin, P.; Xu, J.; Zou, C.; Li, X. A novel feature fusion with self-adaptive weight method based on deep learning for image classification. In Proceedings of the 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; pp. 426–436. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| d | OA (%) |
|---|---|
| 128 | 93.05 |
| 256 | 93.45 |
| 512 | 94.07 |
| 1024 | 94.44 |
| Methods | 80% Training Ratio | 50% Training Ratio |
|---|---|---|
| BoVW [50] | 76.81 | |
| BoVW+SCK [49] | 77.71 | |
| MS-CLBP+FV [53] | 93.00 ± 1.20 | 88.76 ± 0.76 |
| GoogLeNet [50] | 94.31 ± 0.89 | 92.70 ± 0.60 |
| CaffeNet [50] | 95.02 ± 0.81 | 93.98 ± 0.67 |
| VGG-VD-16 [50] | 95.21 ± 1.20 | 94.14 ± 0.69 |
| CNN-NN [54] | 97.19 | |
| Fusion by addition [13] | 97.42 ± 1.79 | |
| ResNet-TP-50 [23] | 98.56 ± 0.53 | 97.68 ± 0.26 |
| Two-Stream Fusion [8] | 98.02 ± 1.03 | 96.97 ± 0.75 |
| PMS [30] | 98.1 | |
| VGG-16-CapsNet [55] | 98.81 ± 0.12 | 95.33 ± 0.18 |
| GCFs+LOFs [52] | 99 ± 0.35 | 97.37 ± 0.44 |
| TEX-Net-LF [56] | 96.42 ± 0.49 | 95.89 ± 0.37 |
| Overfeat [26] | 90.91 ± 1.19 | |
| Ours | 99.46 ± 0.12 | 98.14 ± 0.25 |
| Methods | 50% Images for Training | 20% Images for Training |
|---|---|---|
| BoVW [50] | 67.65 ± 0.49 | 61.40 ± 0.41 |
| IFK(SIFT) [50] | 77.33 ± 0.37 | 70.60 ± 0.42 |
| TEX-Net-LF [56] | 92.96 ± 0.18 | 90.87 ± 0.11 |
| ARCNet-VGG16 [40] | 93.10 ± 0.55 | 88.75 ± 0.40 |
| Fusion by addition [13] | 91.87 ± 0.36 | |
| Fusion by concatenation [13] | 91.86 ± 0.28 | |
| Two-Stream Fusion [8] | 94.58 ± 0.25 | 92.32 ± 0.41 |
| EFPN-DSE-TDFF [57] | 94.50 ± 0.30 | 94.02 ± 0.21 |
| VGG-VD-16 [50] | 89.64 ± 0.36 | 86.59 ± 0.29 |
| CaffeNet [50] | 89.53 ± 0.31 | 86.86 ± 0.47 |
| GoogLeNet [50] | 86.39 ± 0.55 | 83.44 ± 0.40 |
| Ours | 96.10 ± 0.10 | 94.44 ± 0.09 |
| Methods | 50% Images for Training | 20% Images for Training |
|---|---|---|
| VGGNet(SVM) [58] | 97.5 ± 0.02 | |
| GoogleNet(SVM) [58] | 97.7 ± 0.02 | |
| Inception-V3(SVM) [58] | 97 ± 0.02 | |
| ResNet 101(SVM) [58] | 98.6 ± 0.02 | |
| PRC [59] | 99.52 ± 0.17 | |
| SDAResNet [42] | 99.58 ± 0.10 | 99.30 ± 0.08 |
| GLANet(SVM) [9] | 99.40 ± 0.21 | 98.91 ± 0.19 |
| GLANet [9] | 99.65 ± 0.11 | 99.46 ± 0.13 |
| ResNet-101_singlecrop [60] | 95.37 | |
| FW- ResNet-101_singlecrop [60] | 84.3 | 81.37 |
| Ours | 99.67 ± 0.11 | 99.50 ± 0.07 |
| Methods | 80% Images for Training |
|---|---|
| ARCNet-VGGNet16 [38] | 92.70 ± 0.35 |
| ARCNet-ResNet34 [38] | 91.28 ± 0.45 |
| ARCNet-Alexnet [38] | 85.75 ± 0.35 |
| VGG-VD-16 [50] | 89.12 ± 0.35 |
| Fine-tuning VGGNet16 [38] | 87.45 ± 0.45 |
| Fine-tuning GoogLeNet [38] | 82.57 ± 0.12 |
| Fine-tuning AlexNet [38] | 81.22 ± 0.19 |
| Ours | 96.02 ± 0.24 |
| Plan | Architecture | 50% Images for Training | 20% Images for Training |
|---|---|---|---|
| 1 | Without Spatial Attention | 95.22 | 93.69 |
| 2 | Without Cross-Scale Cascade | 95.76 | 94.18 |
| 3 | Ours | 96.10 | 94.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Yu, T.; Yang, H.; Wang, R.; Wang, Q. An Attention Cascade Global–Local Network for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 2042. https://doi.org/10.3390/rs14092042
Shen J, Yu T, Yang H, Wang R, Wang Q. An Attention Cascade Global–Local Network for Remote Sensing Scene Classification. Remote Sensing. 2022; 14(9):2042. https://doi.org/10.3390/rs14092042
Chicago/Turabian StyleShen, Junge, Tianwei Yu, Haopeng Yang, Ruxin Wang, and Qi Wang. 2022. "An Attention Cascade Global–Local Network for Remote Sensing Scene Classification" Remote Sensing 14, no. 9: 2042. https://doi.org/10.3390/rs14092042