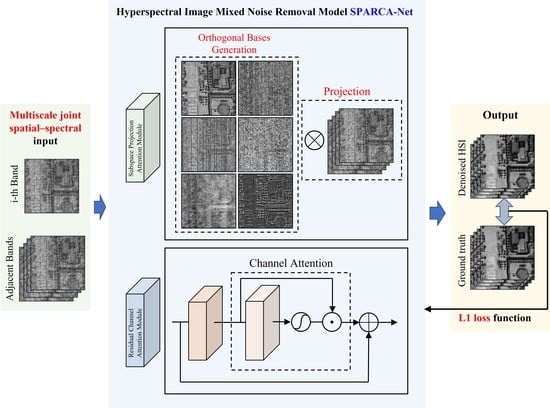
In this section, to verify the performance of the proposed HSI denoising model as well as the comparison methods, we conducted synthetic and real data experiments. For the synthetic Gaussian noise situation, nine different denoising algorithms, which are BM4D [
19], LRMR [
25], NAILRMA [
26], FastHyDe [
36], L1HyMixDe [
38], E3DTV [
31], LRTDTV [
35], HSI-DeNet [
48] and HSID-CNN [
49], were selected as comparison algorithms. For the synthetic complex noise cases, LRMR [
25], NAILRMA [
26], NGmeet [
37], L1HyMixDe [
38], E3DTV [
31], LRTDTV [
35], HSI-DeNet [
48] and HSID-CNN [
49] were selected as comparison algorithms. The parameters of all the comparison traditional methods were as provided in their original papers. For the DL-based methods, we retrained the comparison networks with the same dataset settings of our model and finetuned the parameters to achieve their best performance. Moreover, we performed a sensitivity analysis to investigate the effect of hyperparameters on performance, and an ablation study was conducted to demonstrate the effectiveness of the proposed OSPA and CA modules.
4.1. Synthetic Experiments
We quantitatively evaluate the performance of the proposed model as well as other competing HSI denoising algorithms by conducting synthetic data experiments on two widely adopted HSI datasets: Washington DC Mall and Pavia Center.
(1) Washington DC Mall: These data were acquired by HYDICE sensor, the spatial resolution of which is 2.8 m. The image size is 1280 × 307× 191, and it was divided into two parts, 1080 × 307 ×191 and 200 × 200 × 191, for training and testing, respectively.
(2) Pavia Centre: This image was taken by ROSIS sensor during the flight in Pavia. Its wavelength range is 430 to 860 nm with 115 spectral bands. For our synthetic experiments, 80 bands remained and 35 bands were discarded due to the atmospheric absorption affection. The spatial resolution of this data is 1.3 m, and we chose an image of size 200 × 200 × 80 in our experiments to further test the generalization ability of our proposed network.
The adjacent spectral band number of our model was set to 24 during all the training procedures, referring to HSID-CNN. The dimension of orthogonal projection subspace P was set to 10 for all the modules; we will discuss the effect of the value of P on the model performance in subsequent sensitivity experiments. The proposed model was trained with an Adam optimizer [
64], which was set to its default parameters (
and
). The parameters of the network were initialized using the Kaiming initialization method. The initial learning rate was set to 0.001, and a linear step decay schedule set from 1000 to 20,000 epochs was adopted. The training data were randomly cropped into 32 × 32, and the batch size was set to 64. In order to increase the training samples, we utilized image rotation (angles of 0°, 90°, 180°, 270°) and multiscale resizing (scales of 0.5, 1, 1.5, 2) during the training. Before adding simulated noise, the HSI was normalized to [0, 1]. We set up five cases for better comparison, fully considering Gaussian noise, stripes, deadlines, impulse noise (salt and pepper noise) and a mixture of all the above; the setting details are as follows:
Case 1 (Gaussian non-i.i.d. noise): We added zero-mean Gaussian noise with varying intensities randomly selected from 25 to 75 to all bands of the image.
Case 2 (Gaussian + stripe noise): The images were added with the non-i.i.d Gaussian noise mentioned in Case 1. In addition, we randomly selected 30% of the bands to add stripe noise, and the number of stripes in each selected band was randomly set from 5% to 15% of the columns.
Case 3 (Gaussian + deadline noise): All bands in the image were corrupted by the non-i.i.d Gaussian noise mentioned in Case 1. On top of this, 30% of the bands were randomly selected to add deadline noise. The number of deadlines in each selected band was randomly set from 5% to 15% of the columns.
Case 4 (Gaussian + impulse noise): All bands were corrupted by non-i.i.d Gaussian noise mentioned in Case 1. Based on this, we randomly selected 30% of the bands to add impulse noise with varying intensities, and the percentage of impulse range was set from 10% to 70% randomly.
Case 5 (Mixed noise): All bands were corrupted by Gaussian non-i.i.d noise (Case 1), stripe noise (Case 2), deadline noise (Case 3) and impulse noise (Case 4).
We quantitatively evaluated the performance of the algorithms by calculating the peak signal-to-noise ratio (PSNR), the structural similarity (SSIM) and the spectral angle mapper (SAM) before and after image denoising. PSNR and SSIM are two spatial-based evaluation metrics, while SAM is a spectral domain evaluation metric. The larger the PSNR and SSIM, the better the denoising effect of the corresponding methods, while smaller values of SAM imply better performance.
Table 1 shows the denoised quantitative results of different algorithms applied to Washington DC Mall data with Gaussian i.i.d. noise, which means all the bands of HSI were contaminated by zero-mean Gaussian noise with the same intensity (
,
, respectively). It can be seen from the denoised results of
Table 1 that the performance of our method is the best except for FastHyDe. Our method significantly outperformed some typical denoising methods, such as LRMR, BM4D and NAILRMA. The FastHyDe method is a representative method for the Gaussian noise removal; it can be observed that our method achieved comparable performance in all the Gaussian noise cases compared to FastHyDe. Specifically, our MPSNR is, on average, 0.5 dB smaller than FastHyDe, but, in some metrics, such as MSSIM, our result is better than FastHyDe. For all three different Gaussian noise levels, our model achieved an improvement in MPSNR by at least 0.7 dB compared with the well-trained DL-based methods (HSID-CNN and HSI-DeNet). For visual evaluation, the false color images synthesized with band 50, 70 and 112 of the Washington DC (noise level σ = 75) were shown in
Figure 5. It can be observed that our model and FastHyDe yield the closest results to the original one compared with the other methods, preserving the details while denoising.
Then, we evaluate the denoising effect of the proposed method and comparison methods in complex noise cases. The quantitative assessment results before and after denoising are shown in
Table 2, and the results for visual comparison are shown in
Figure 6. It can be easily seen from
Table 2 that our method achieved better results than the other compared denoising methods in all the cases. Benefiting from the CA module and OSPA module, the former exploring the global correlation of the spectral domain, the latter reconstructing the local structures by exploring the non-local spatial correlation information, our approach yields better recovery results and higher spectral reconstruction fidelity than the other methods. The low-rank matrix-based methods, such as LRMR, NAILRMA and E3DTV, lose part of the structure information in the process of low-rank matrix approximation; therefore, the denoising effect is relatively poor, as can be seen from the denoised images in
Figure 6. LRTDTV’s results are the best except for the three DL-based methods, mainly because it is based on a low-rank tensor, which fully expresses the structure of HSIs and the characteristics of noise, but it can be observed from the enlarged view in
Figure 7h that there is still slight stripe noise remaining. The band-wise PSNR and SSIM are depicted in
Figure 8 for further quantitative assessment; we can observe that our method obtained better PSNR and SSIM in almost all the bands compared to the other comparison methods.
To further verify the denoising performance of the proposed model for mixed noise, we conducted synthetic noise experiments on the Pavia Center data. Noise from Case 1 to Case 5 was added to the Pavia data for testing.
Table 3 shows the quantitative assessment results, and
Figure 7 shows the vision comparison of the denoising results for Case 5. It can be seen that our method achieved the best results, although the gains on the Pavia data are not that large compared to those on the DC data shown in
Table 2. It can be easily observed from
Figure 7 that the results of our model, LRTDTV, and two DL-based methods, removing most of the mixed noise, are closest to the original reference images. The band-wise PSNR and SSIM are depicted in
Figure 9; for almost all the bands in the Pavia data, our method achieves higher PSNR values and SSIM values compared to other competing methods. The experiment results on the Pavia data proved that our model has a certain generalization ability. If we need to further improve or maintain the superior performance and generalization ability of our model on different test datasets, we need to train the model on more datasets containing all these types of noise and finetune the network.
4.2. Real HSI Denoising
In this section, two real HSI data, namely Indian Pines data and GF-5 (Gaofen-5) data, were employed to further validate the effectiveness of the proposed model.
(1) Indian Pines: These data were recorded over north-western Indiana, containing 220 spectral channels, the GSD of which is 20 m. The selected scene is a size of 145 × 145 pixels, and a few bands were corrupted by heavy mixed noise (including Gaussian noise and sparse noise, e.g., impulse and stripe noise).
(2) GF-5 Data: These data were acquired by the Advanced Hyperspectral Imager (AHSI) loaded by the Chinese GF-5 satellite in January 2020 over an area of Fujian Province, China. The image wavelength range is 400 to 2500 nm, including 330 bands. Due to atmospheric absorption, 17 bands were removed, and 313 spectral bands were retained. In our experiments, an image with a size of 200 × 200 pixels was selected.
The parameters of all the traditional comparison methods were the suggested ones given in the original literature. For the DL-based methods, we used the trained network from the synthetic experiment above. To visually compare the effect of restoration, we show the second band image and the false color image synthesized with band 61, 34 and 1 in
Figure 10 and
Figure 11, respectively. From
Figure 10, we can observe that the proposed method removed most of the noise, while other comparison methods did not completely remove complex noise. From the zoomed image of
Figure 11, it can be observed that our method and LRTDTV removed most of the noise while preserving the spatial details. In addition, the corresponding computational times of all the algorithms on the Indian dataset (145 × 145 × 220) were given in
Table 4. It can be seen that, although HSID-CNN and HSI-DeNet yielded less runtime, our method acquired the best result in the third shortest runtime. Considering the reason, it is mainly because matrix multiplication is used in the OSPA module of our model, which is relatively time-consuming. Nevertheless, our method is obviously much faster than all the traditional methods.
To further verify the effectiveness of denoising, a random forest (RF) classifier [
65] and support vector machine (SVM) [
66] were used to classify the Indian Pines data before and after denoising. Sixteen ground truth classes were employed for testing the classification accuracy. The training sets included 10% of the test samples randomly generated from each class. The overall accuracy (OA) and the kappa coefficient were given as evaluation indexes in
Table 5. As can be seen, our method yields the highest classification accuracy whether using RF or SVM; the OA and kappa values corresponding to RF are 0.8812 and 0.8587, respectively, and the OA and kappa corresponding to SVM are 0.8997 and 0.8174, respectively.
Figure 12 shows the results for Indian Pines using the RF classifier.
For the GF-5 data, the denoised results are shown in
Figure 13 and
Figure 14.
Figure 14 plots second band denoised images for all the methods; it can be observed that our method exhibits the best result as most of the stripe noise was removed. Although NAILRMA also removed most of the noise and shows a relatively clean image, many structures are significantly different from the original image, probably because, in the process of low-rank matrix approximation, some structural information was removed as noise. Although the stripe noise was removed in E3DTV’s result, the image is obviously over-smoothed. LRTDTV shows a relatively better denoising effect than DL-based HSID-CNN and HSI-DeNet.
Figure 14 shows the false color images synthesized with band 1, 34 and 61 of the denoised GF-5 data. It can be observed that the proposed method achieved relatively good denoising results, and the zoomed area shows that the stripe noise and dots pattern noise were almost removed. As we mentioned above, the denoised image of NAILRMA is very clean and sharp but has obvious differences from the original image. The E3DTV result still shows over-smoothing. LRTDTV also exhibits a relatively good denoising effect, but, in the area of the blue box, there is still obvious stripe noise.
4.3. Sensitivity and Ablation Study
We examined three major determinants of our model: (a) the dimension of the orthogonal subspace, P; (b) the performance of the OSPA module; (c) the performance of the CA module.
Table 6 provides the results of the experiment on DC Mall data with different P values; a mixture noise setting in Case 5 was applied to this experiment. As we can see, when P = 30, the model was unstable and did not converge; the OSPA module cannot work effectively as a subspace projection since P is greater than the dimension size of the input. In addition to this, a lager P value also increased the difficulty of training. When P = 1, the dimension of the subspace is too small, the learning ability of the network decreased and less information would be retained, resulting in unsatisfactory training results. When P = 10 and 20, the trained model has comparable denoising performance, with MSPNRs of 33.56 and 33.45, respectively, so it can be seen that the value of P selected in our model is a robust hyperparameter within a reasonable range.
Next, to demonstrate the necessity and effectiveness of the two core modules in the proposed model, OSPA and CA, we conducted the ablation study on the effects of the OSPA and CA modules. Specifically, the ablation experiments were conducted on the Washington DC data, and the same training strategy and parameter settings as in the synthetic experiments were used. The test experiment was carried out under the condition of mixed noise (Case 5). The results are reported in
Table 7.
As seen from
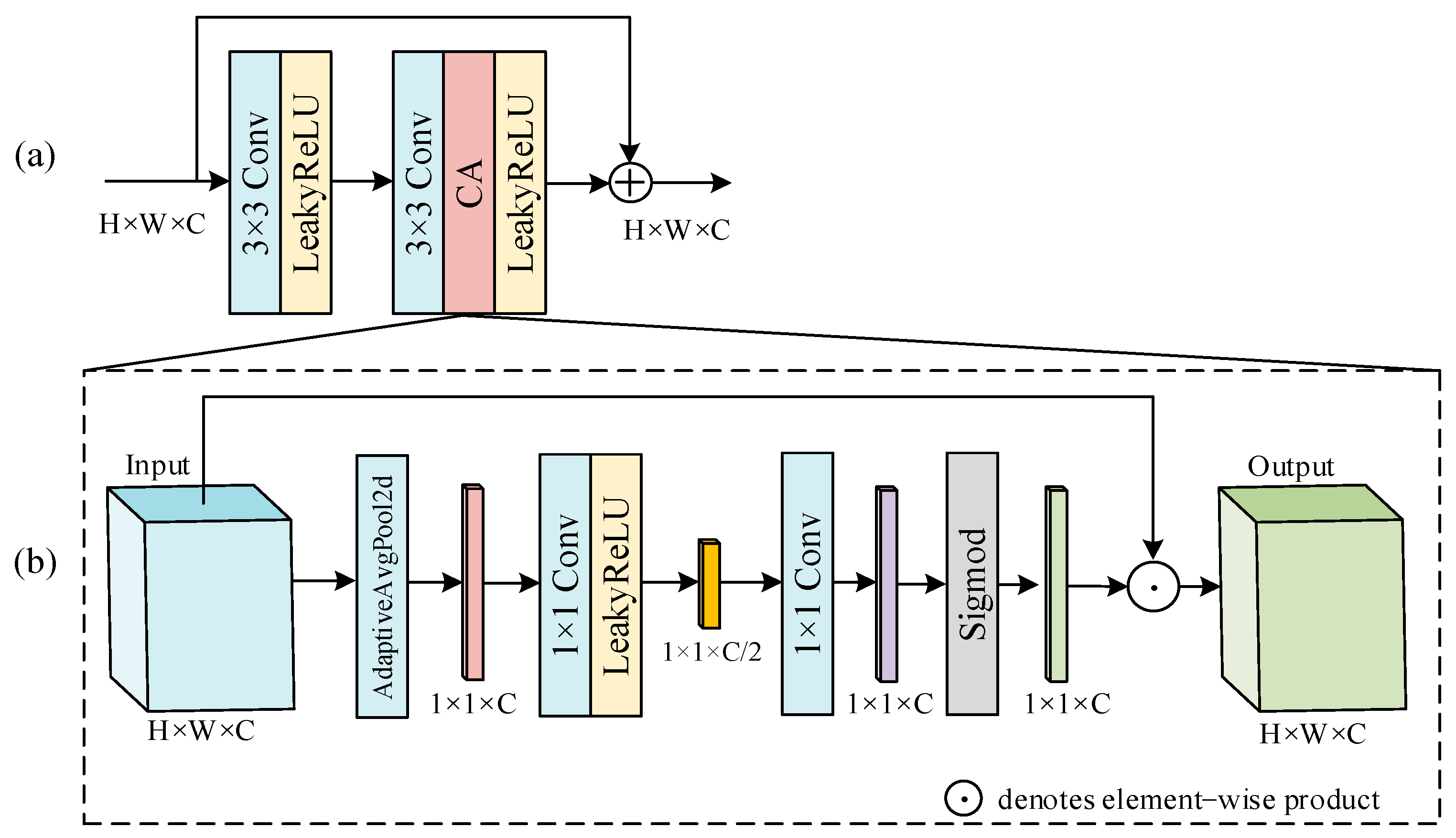
Table 7, the original network without the OSPA and CA modules obtained the PSNR = 32.04 and SSIM = 0.8736, with slightly lower performance than HSI-DeNet. By including the OSPA modules to the model, the improvements of 0.51 and 0.0066 were achieved in MPSNR and MSSIM, respectively, while MSAM decreased by 0.0061. This is because OSPA considers the global spatial correlation, which removed spatial-related noise and recovered the original structures of images more precisely. Then, by integrating the CA modules to the model, we achieved an improvement of 0.85 and 0.0195 on MPSNR and MSSIM, respectively, and the MSAM decreased by 0.0090. This is because the CA could explore the correlations between the feature maps so that more global spectral information can be utilized. Overall, compared to the model without OSPA and CA, our original proposed model improved the MPSNR by 1.52, MSSIM by 0.0314, and decreased MSAM by 0.0135.
One insight of our work lies in the orthogonal subspace projection based on the spatial attention mechanism. To further understand how it works, we took the DC data as an example and examined the subspace generated by the OSPA module. We chose the experimental settings of Case 5 (complex noise) and zoomed into the lower left corner of the image for better visual observation.
Figure 15a shows the visualization of the 10 basis vectors; it can be obviously seen that basically all the vectors contain the dots pattern (corresponding to Gaussian noise) that evenly spans the whole image, some vectors contain a slight stripe pattern (corresponding to stripe noise) and some vectors contain a clear spatial structure consistent with the ground truth image.
Figure 15b plots band 70 of the ground truth and the denoised results with and without OSPA, respectively. We can conclude that a more detailed spatial structure is recovered in the denoised image with the virtue of OSPA.
It could be speculated that such an improvement in detailed spatial structure recovery should be attributed to the non-local and global spatial correlations explored by the OSPA module, which means that the recovered structure information can be supported by similar structures in other parts of the image. The OSPA module could effectively separate structural noise and original data by learning subspace bases and selectively remove noise through the projection process, thus yielding a restoration result with more faithful texture structure.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}