
Comparison of CNNs and Vision Transformers-Based Hybrid Models Using Gradient Profile Loss for Classification of Oil Spills in SAR Images

 ,
,  , and
, and
Abstract
:1. Introduction
Related Work
2. Dataset
3. Methodology
3.1. UNet
3.2. EfficientNetV2
- In initial layers, the EfficientNetV2 extensively utilizes MBConv and fused-MBConv structures, as shown in Figure 3.
- During training, EfficientNetV2 uses a small expansion ratio for MBConv modules. It reduces the memory overhead and results in faster training.
- EfficientNet uses a small kernel size of 3 × 3. It reduces the receptive field during training, which can be compensated by adding some additional layers.
- The original EfficientNet has a last stride 1 × 1 stage with large number of trainable parameters. EfficientNetV2 does not utilize it to reduce memory usage and increase the training speed.
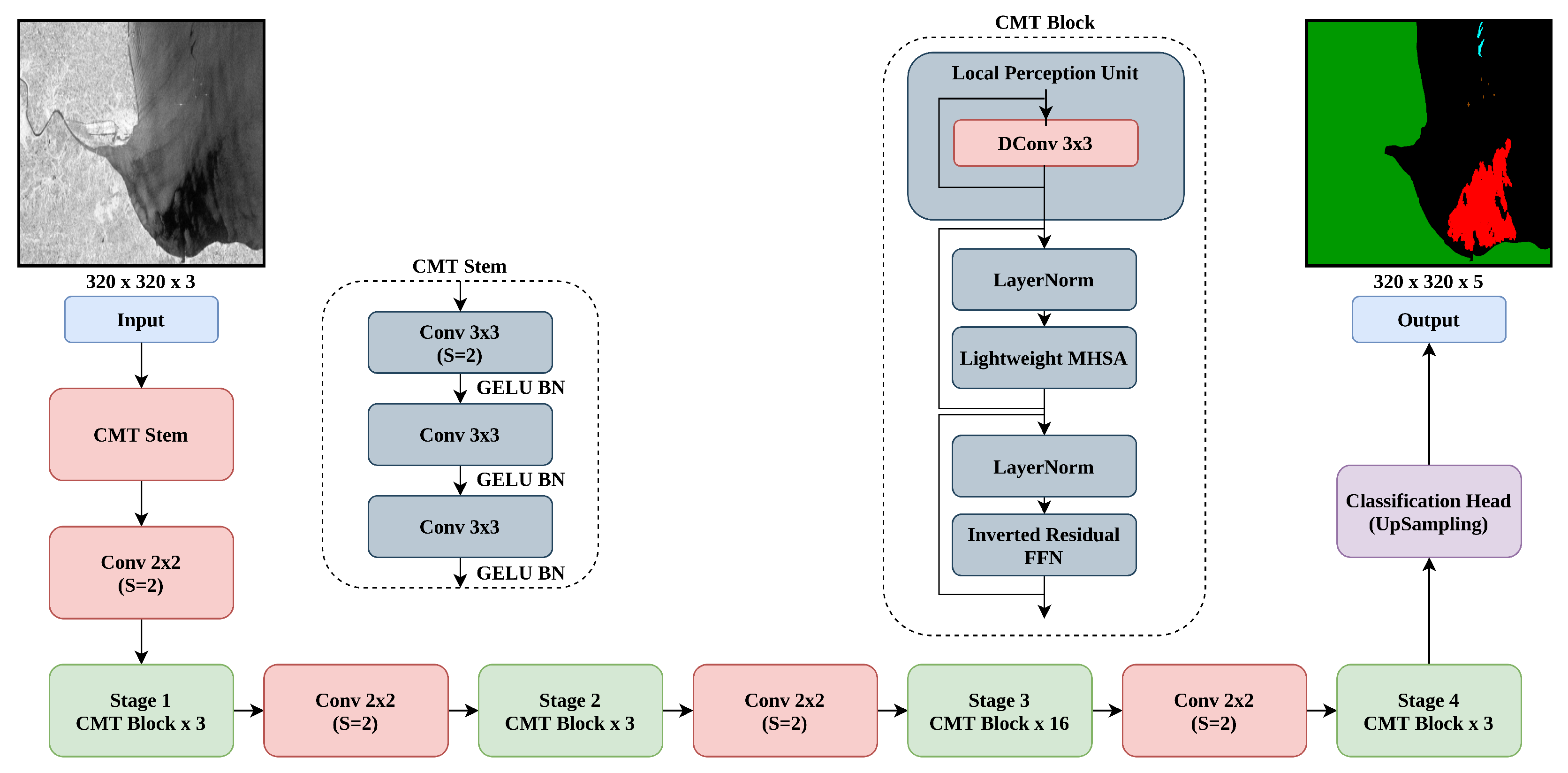
3.3. Convolutional Neural Networks Meet Vision Transformers (CMTs)
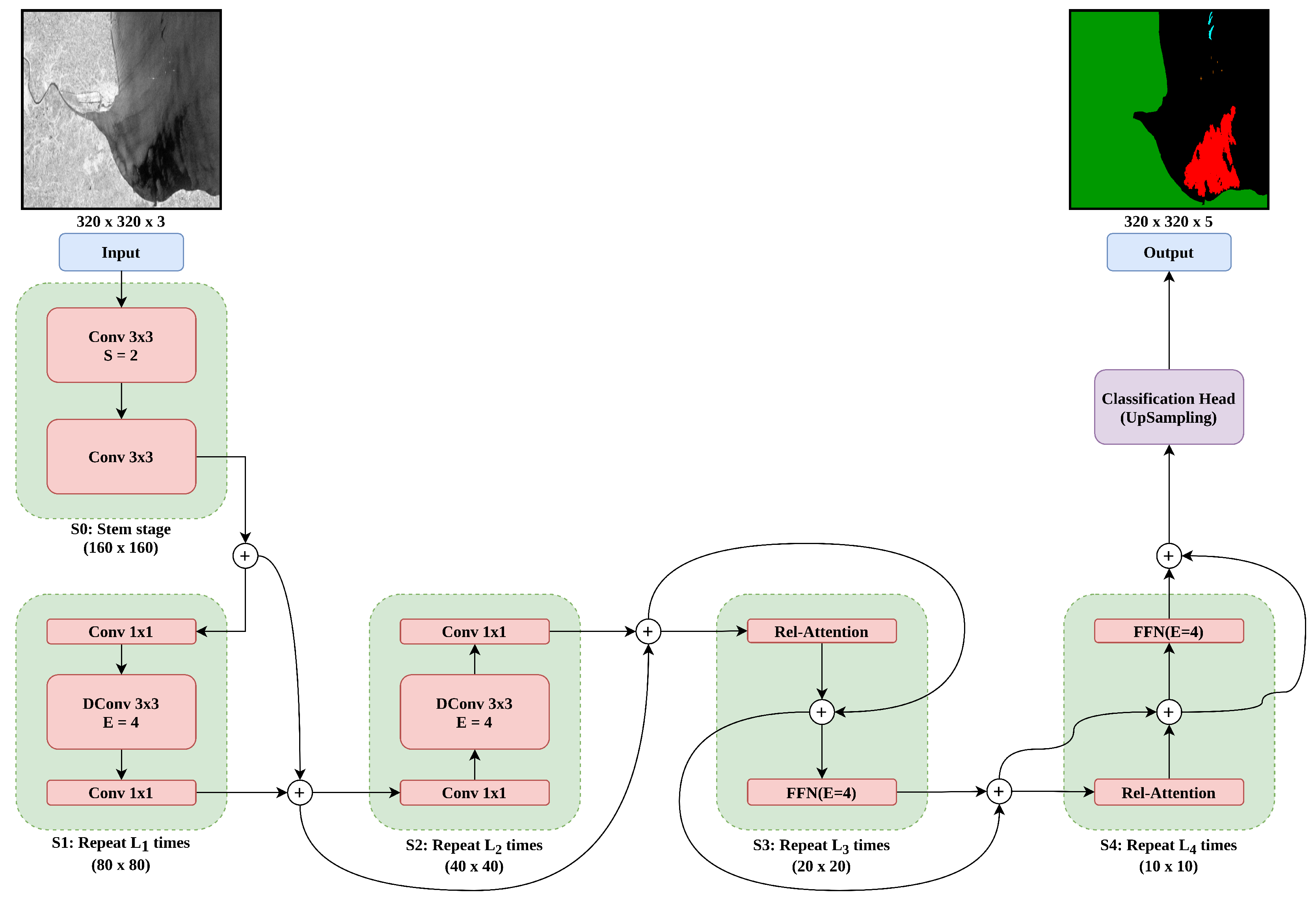
3.4. Convolution and Self-Attention Networks (CoAtNets)
- The advantages of both depthwise convolution and self-attention can be achieved by unifying them using simple relative attention.
- Vertical stacking of convolution and attention layers can improve the generalization, efficiency, and capacity of the models.
3.5. Experimental Setup
3.6. Commonly Used Semantic Segmentation Loss Functions
3.6.1. Categorical Cross-Entropy Loss
3.6.2. Categorical Focal Loss
3.6.3. Jaccard Loss
3.7. Gradient Profile Loss
4. Results
4.1. Comparison against State of the Art
4.2. Ablation on ResNet Series
4.3. Ablation on EfficientNetV2
4.4. Ablation on CMTs
4.5. Ablation on CoAtNet
4.6. Qualitative Results
5. Conclusions & Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Solberg, A.H.S. Remote Sensing of Ocean Oil-Spill Pollution. Proc. IEEE 2012, 100, 2931–2945. [Google Scholar] [CrossRef]
- Solberg, A.; Storvik, G.; Solberg, R.; Volden, E. Automatic detection of oil spills in ERS SAR images. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1916–1924. [Google Scholar] [CrossRef] [Green Version]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Wang, J. An End-to-End Oil-Spill Monitoring Method for Multisensory Satellite Images Based on Deep Semantic Segmentation. Sensors 2020, 20, 725. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, L.; Zhao, L.; Yu, Z. (Eds.) Advances in Natural Computation, Fuzzy Systems and Knowledge Discovery; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; Ehrlich, M.; Shah, S.; Davis, L.S.; Chellappa, R. Stacked U-Nets for Ground Material Segmentation in Remote Sensing Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Bianchi, F.M.; Grahn, J.; Eckerstorfer, M.; Malnes, E.; Vickers, H. Snow Avalanche Segmentation in SAR Images With Fully Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 75–82. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 2021 International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- Bello, I.; Zoph, B.; Le, Q.; Vaswani, A.; Shlens, J. Attention Augmented Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seol, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar] [CrossRef] [Green Version]
- Zhuoran, S.; Mingyuan, Z.; Haiyu, Z.; Shuai, Y.; Hongsheng, L. Efficient Attention: Attention with Linear Complexities. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Xu, C.; Tang, Y.; Xu, C.; Wang, Y. CMT: Convolutional Neural Networks Meet Vision Transformers. arXiv 2021, arXiv:2107.06263. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. arXiv 2021, arXiv:2106.04803. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 5 October 2021).
- Topouzelis, K.; Karathanassi, V.; Pavlakis, P.; Rokos, D. Detection and discrimination between oil spills and look-alike phenomena through neural networks. ISPRS J. Photogramm. Remote Sens. 2007, 62, 264–270. [Google Scholar] [CrossRef]
- Singha, S.; Bellerby, T.J.; Trieschmann, O. Satellite Oil Spill Detection Using Artificial Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2355–2363. [Google Scholar] [CrossRef]
- Garcia-Pineda, O.; MacDonald, I.R.; Li, X.; Jackson, C.R.; Pichel, W.G. Oil Spill Mapping and Measurement in the Gulf of Mexico With Textural Classifier Neural Network Algorithm (TCNNA). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2517–2525. [Google Scholar] [CrossRef]
- Guo, H.; Wei, G.; An, J. Dark Spot Detection in SAR Images of Oil Spill Using Segnet. Appl. Sci. 2018, 8, 2670. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. A Deep Neural Network for Oil Spill Semantic Segmentation in SAR Images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar] [CrossRef] [Green Version]
- Krestenitis, M.; Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. Oil Spill Identification from Satellite Images Using Deep Neural Networks. Remote Sens. 2019, 11, 1762. [Google Scholar] [CrossRef] [Green Version]
- Yekeen, S.T.; Balogun, A.L.; Yusof, K.B.W. A novel deep learning instance segmentation model for automated marine oil spill detection. ISPRS J. Photogramm. Remote Sens. 2020, 167, 190–200. [Google Scholar] [CrossRef]
- Krestenitis, M.; Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. Early Identification of Oil Spills in Satellite Images Using Deep CNNs. In MultiMedia Modeling; Springer International Publishing: Berlin, Germany, 2018; pp. 424–435. [Google Scholar] [CrossRef] [Green Version]
- Shaban, M.; Salim, R.; Khalifeh, H.A.; Khelifi, A.; Shalaby, A.; El-Mashad, S.; Mahmoud, A.; Ghazal, M.; El-Baz, A. A Deep-Learning Framework for the Detection of Oil Spills from SAR Data. Sensors 2021, 21, 2351. [Google Scholar] [CrossRef]
- Fan, Y.; Rui, X.; Zhang, G.; Yu, T.; Xu, X.; Poslad, S. Feature Merged Network for Oil Spill Detection Using SAR Images. Remote Sens. 2021, 13, 3174. [Google Scholar] [CrossRef]
- Basit, A.; Siddique, M.A.; Sarfraz, M.S. Deep Learning Based Oil Spill Classification Using Unet Convolutional Neural Network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar] [CrossRef]
- Nieto-Hidalgo, M.; Gallego, A.J.; Gil, P.; Pertusa, A. Two-Stage Convolutional Neural Network for Ship and Spill Detection Using SLAR Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5217–5230. [Google Scholar] [CrossRef] [Green Version]
- Zeng, K.; Wang, Y. A Deep Convolutional Neural Network for Oil Spill Detection from Spaceborne SAR Images. Remote Sens. 2020, 12, 1015. [Google Scholar] [CrossRef] [Green Version]
- Kervadec, H.; Bouchtiba, J.; Desrosiers, C.; Granger, E.; Dolz, J.; Ayed, I.B. Boundary loss for highly unbalanced segmentation. Med. Image Anal. 2021, 67, 101851. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Sarfraz, M.S.; Seibold, C.; Khalid, H.; Stiefelhagen, R. Content and Colour Distillation for Learning Image Translations with the Spatial Profile Loss. arXiv 2019, arXiv:1908.00274. [Google Scholar]
- Konik, M.; Bradtke, K. Object-oriented approach to oil spill detection using ENVISAT ASAR images. ISPRS J. Photogramm. Remote Sens. 2016, 118, 37–52. [Google Scholar] [CrossRef]
- Topouzelis, K.; Psyllos, A. Oil spill feature selection and classification using decision tree forest on SAR image data. ISPRS J. Photogramm. Remote Sens. 2012, 68, 135–143. [Google Scholar] [CrossRef]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 664–676. [Google Scholar] [CrossRef] [Green Version]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional Neural Network With Data Augmentation for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duque-Arias, D.; Velasco-Forero, S.; Deschaud, J.E.; Goulette, F.; Serna, A.; Decencière, E.; Marcotegui, B. On power Jaccard losses for semantic segmentation. In Proceedings of the VISAPP 2021: 16th International Conference on Computer Vision Theory and Applications, Virtual, 8–10 February 2021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Row | Model | Backbone | Loss Functions | Trainable Parameters | Sea Surface | Oil Spill | Look-Alike | Ship | Land | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | UNet | Resnet101 | Cross entropy | 51.5 M | 93.90% | 53.79% | 39.55% | 44.93% | 92.68% | 64.97% |
| 2 | DeepLab v3+ | Mobilenetv2 | Cross entropy | 2.1 M | 96.43% | 53.38% | 55.40% | 27.63% | 92.44% | 65.06% |
| 3 | DeepLab v3+ | Mobilenetv2 | GP + Jaccard + focal | 2.1 M | 96.00% | 53.84% | 59.34% | 70.73% | 97.29% | 75.44% |
| 4 | UNet | Resnet101 | GP +Jaccard + focal | 51.5 M | 96.00% | 63.95% | 60.87% | 74.61% | 96.81% | 78.45% |
| 5 | UNet | Mobilenetv2 | GP + Jaccard + focal | 10.6 M | 95.72% | 59.07% | 54.38% | 73.56% | 91.48% | 74.84% |
| Row | Related Work | mIoU Score | Score | Oil Spill Dataset | Number of Classes |
|---|---|---|---|---|---|
| 1 | Shaban et al. [31] | - | 80.00% | MKLab ITI-CERTH, Greece. | 2: Oil spills and lookalikes. |
| 2 | Fan et al. [32] | 61.90% | - | MKLab ITI-CERTH, Greece. | 5: Sea surface, oil spills, lookalikes, ship and land. |
| 3 | Krestenitis et al. [28] | 65.06% | - | MKLab ITI-CERTH, Greece. | 5: Sea surface, oil spills, lookalikes, ship and land. |
| 4 | Hidalgo et al. [34] | - | 71.00% | Spanish Maritime Safety and Rescue Agency (SASEMAR). | 3: Oil spills, ship and land. |
| 5 | Zeng et al. [35] | - | 84.59% | ORSI, Ocean University of China. | 2: Oil spills and lookalikes. |
| 6 | Proposed methodology | 78.45% | 82.47% | MKLab ITI-CERTH, Greece. | 5: Sea surface, oil spills, lookalikes, ship and land. |
| Row | UNet Backbone | Loss Functions | Trainable Parameters | Sea Surface | Oil Spill | Look-Alike | Ship | Land | mIoU | Score |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Resnet50 | Jaccard + focal | 32.5 M | 95.28% | 59.51% | 61.18% | 71.88% | 95.17% | 76.60% | 80.83% |
| 2 | Resnet50 | GP + Jaccard + focal | 32.5 M | 95.71% | 62.76% | 59.50% | 72.08% | 97.50% | 77.51% | 81.50% |
| 3 | Resnet101 | Jaccard + focal | 51.5 M | 95.19% | 58.85% | 60.93% | 73.07% | 94.54% | 76.52% | 80.42% |
| 4 | Resnet101 | GP + Jaccard + focal | 51.5 M | 96% | 63.95% | 60.87% | 74.61% | 96.81% | 78.45% | 82.47% |
| 5 | Resnet152 | Jaccard + focal | 67.1 M | 95.04% | 58.35% | 54.64% | 71.96% | 98.02% | 75.60% | 79.49% |
| 6 | Resnet152 | GP + Jaccard + focal | 67.1 M | 95.98% | 62.10% | 62.05% | 72.87% | 97.66% | 78.13% | 82.03% |
| Row | Model | Loss Functions | Trainable Parameters | Sea Surface | Oil Spill | Look-Alike | Ship | Land | mIoU | Score |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Small | Jaccard + focal | 30.0 M | 95.39% | 51.81% | 59.86% | 69.09% | 95.95% | 74.42% | 78.02% |
| 2 | Small | GP + Jaccard + focal | 30.0 M | 94.91% | 55.10% | 61.17% | 73.81% | 97.01% | 76.40% | 80.36% |
| 3 | B0 | Jaccard + focal | 15.7 M | 94.45% | 50.63% | 63.32% | 23.82% | 90.96% | 64.64% | 68.61% |
| 4 | B0 | GP + Jaccard + focal | 15.7 M | 95.09% | 54.03% | 60.40% | 70.47% | 96.38% | 75.27% | 79.26% |
| 5 | B1 | Jaccard + focal | 16.7 M | 94.97% | 51.98% | 62.00% | 69.09% | 95.33% | 74.67% | 78.39% |
| 6 | B1 | GP + Jaccard + focal | 16.7 M | 95.19% | 56.42% | 62.23% | 72.80% | 96.59% | 76.65% | 80.85% |
| 7 | B2 | Jaccard + focal | 19.2 M | 94.91% | 52.16% | 61.88% | 69.09% | 95.64% | 74.74% | 78.59% |
| 8 | B2 | GP + Jaccard + focal | 19.2 M | 95.32% | 55.40% | 61.75% | 70.95% | 96.85% | 76.05% | 80.08% |
| 9 | B3 | Jaccard + focal | 24.1 M | 94.79% | 51.67% | 59.53% | 71.18% | 95.78% | 74.59% | 78.73% |
| 10 | B3 | GP + Jaccard + focal | 24.1 M | 94.69% | 53.91% | 62.12% | 69.09% | 96.62% | 75.29% | 79.06% |
| Row | Model | Loss Functions | Trainable Parameters | Sea Surface | Oil Spill | Look-Alike | Ship | Land | mIoU | Score |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | CMTTiny | Jaccard + focal | 18.0 M | 94.98% | 43.57% | 59.95% | 46.01% | 91.30% | 67.16% | 70.82% |
| 2 | CMTTiny | GP + Jaccard + focal | 18.0 M | 94.71% | 50.06% | 57.54% | 69.09% | 90.77% | 72.43% | 76.10% |
| 3 | CMTXS | Jaccard + focal | 23.8 M | 93.11% | 26.66% | 54.47% | 13.23% | 89.49% | 55.39% | 58.39% |
| 4 | CMTXS | GP + Jaccard + focal | 23.8 M | 95.50% | 51.40% | 58.95% | 64.49% | 93.27% | 72.72% | 76.78% |
| 5 | CMTSmall | Jaccard + focal | 34.6 M | 90.15% | 12.86% | 40.16% | 16.73% | 45.07% | 41.00% | 43.43% |
| 6 | CMTSmall | GP + Jaccard + focal | 34.6 M | 95.02% | 33.14% | 56.98% | 69.09% | 68.26% | 64.50% | 67.29% |
| 7 | CoAtNet-0 | Jaccard + focal | 29.4 M | 92.53% | 41.03% | 55.02% | 54.22% | 92.20% | 67.00% | 70.77% |
| 8 | CoAtNet-0 | GP + Jaccard + focal | 29.4 M | 95.40% | 50.22% | 58.85% | 69.09% | 94.49% | 73.61% | 77.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basit, A.; Siddique, M.A.; Bhatti, M.K.; Sarfraz, M.S. Comparison of CNNs and Vision Transformers-Based Hybrid Models Using Gradient Profile Loss for Classification of Oil Spills in SAR Images. Remote Sens. 2022, 14, 2085. https://doi.org/10.3390/rs14092085
Basit A, Siddique MA, Bhatti MK, Sarfraz MS. Comparison of CNNs and Vision Transformers-Based Hybrid Models Using Gradient Profile Loss for Classification of Oil Spills in SAR Images. Remote Sensing. 2022; 14(9):2085. https://doi.org/10.3390/rs14092085
Chicago/Turabian StyleBasit, Abdul, Muhammad Adnan Siddique, Muhammad Khurram Bhatti, and Muhammad Saquib Sarfraz. 2022. "Comparison of CNNs and Vision Transformers-Based Hybrid Models Using Gradient Profile Loss for Classification of Oil Spills in SAR Images" Remote Sensing 14, no. 9: 2085. https://doi.org/10.3390/rs14092085