
Rapid Vehicle Detection in Aerial Images under the Complex Background of Dense Urban Areas

Abstract
:1. Introduction
- (1)
- An adaptive image segmentation method based on the parameters of aerospace vehicles and cameras is proposed; this method limits the size of the target to a small range by dynamically adjusting the crop size. It plays a major role in improving the speed and accuracy of model detection.
- (2)
- In view of the high speed and accuracy of YOLOv4 [33], this paper uses YOLOv4 as the main frame of vehicle detection. We present the single-scale rapid convolutional neural network (SSRD-Net). A structure with denser prediction anchor frames is proposed, optimizing the feature fusion structure to improve the ability to detect small targets.
- (3)
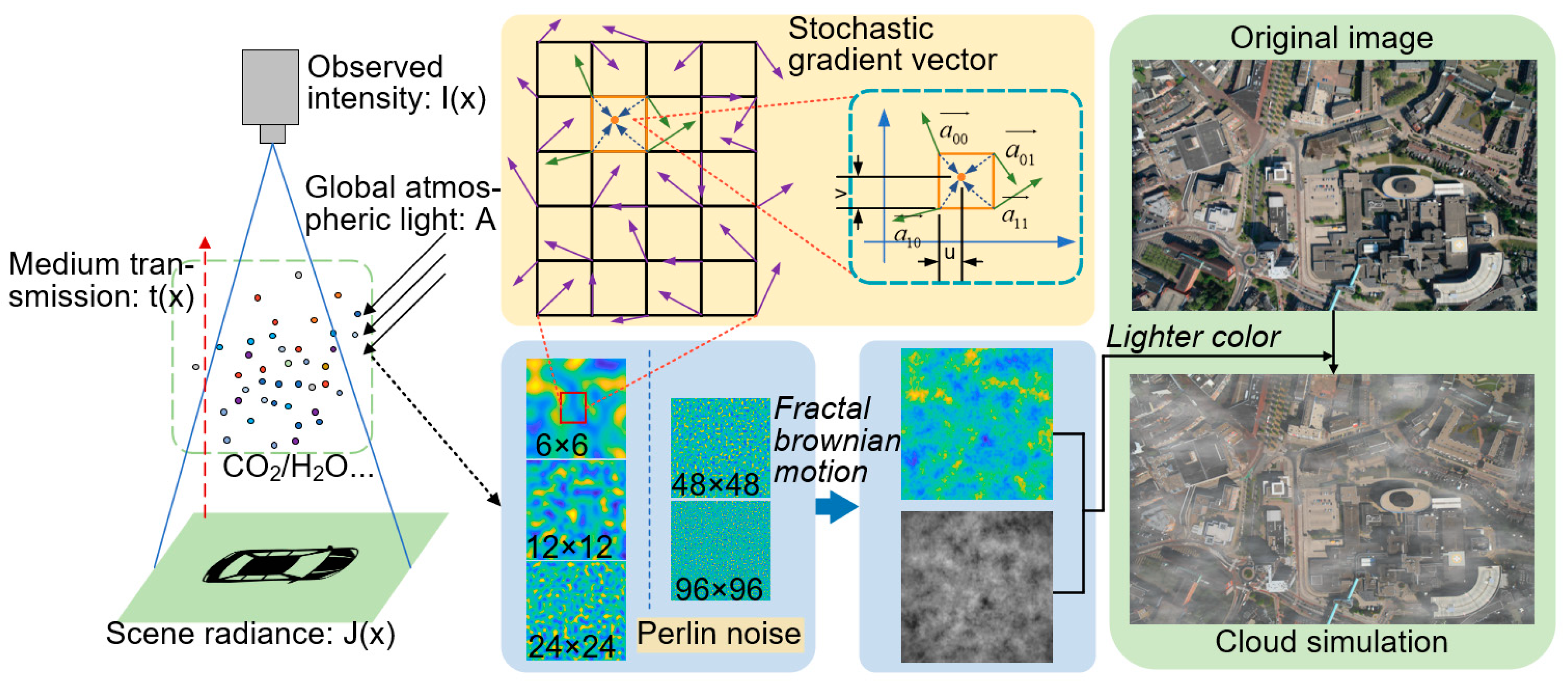
- We designed an aerial remote sensing image dataset (RO-ARS) with rotating boxes. The dataset has annotated flight height and camera focal length. In order to improve the authenticity of the dataset, we propose affine transformation and haze simulation methods to augment the dataset.
2. Method
2.1. Image Segmentation
2.2. Data Augmentation
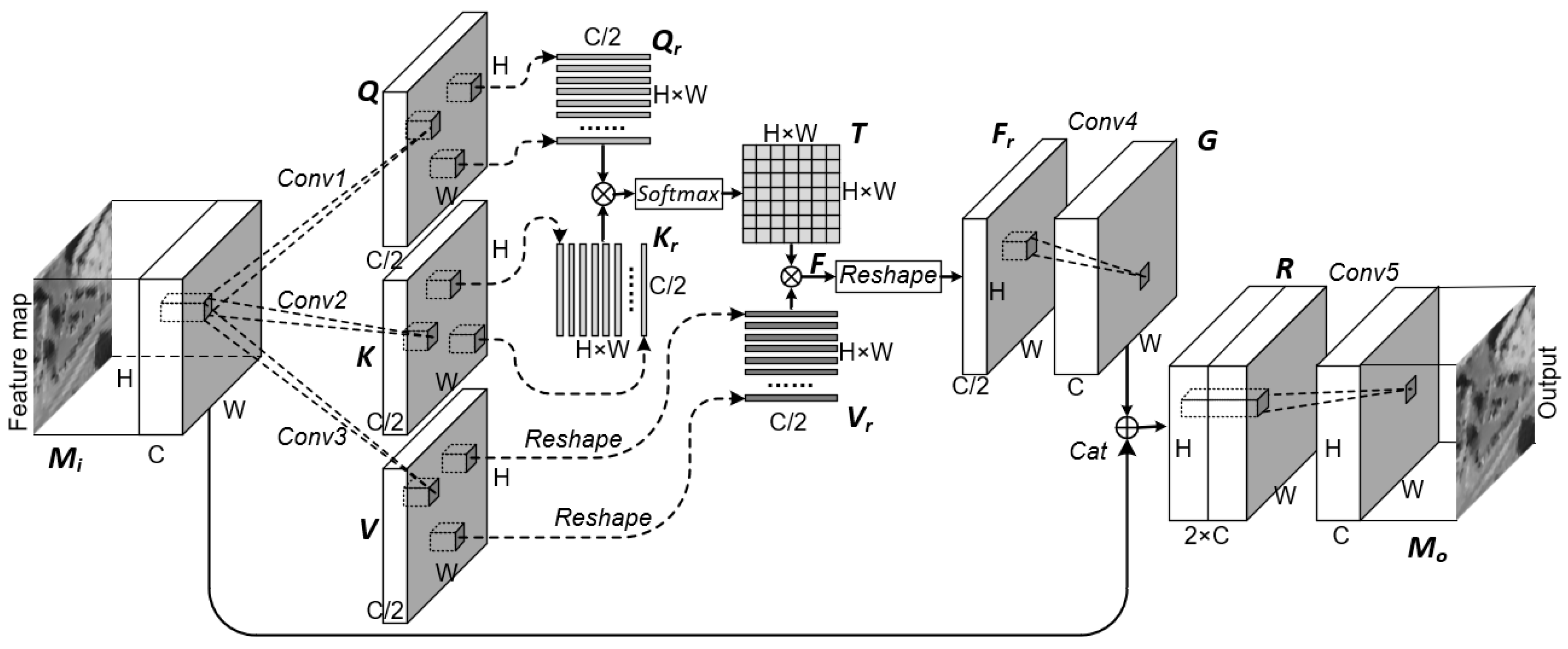
2.3. The Proposed SSRD-Net
2.3.1. Overall Architecture
2.3.2. Global Relational Block
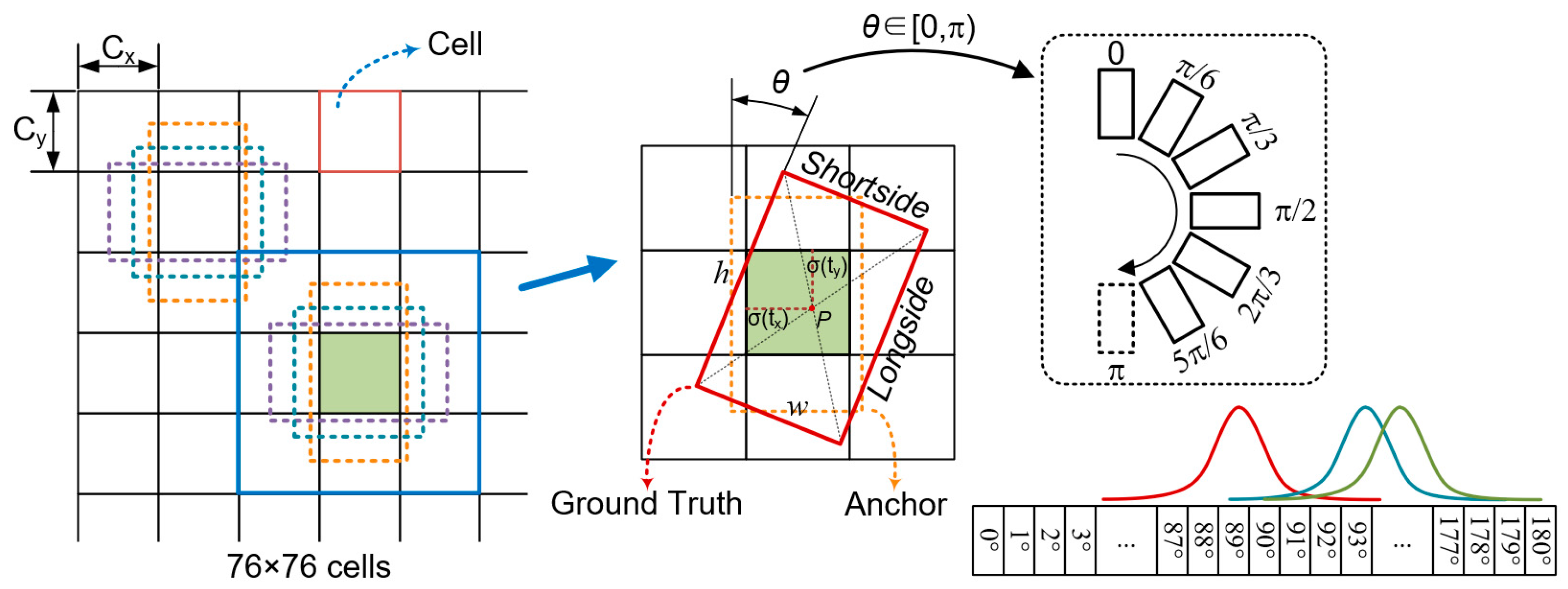
2.3.3. Prediction
| Algorithm 1 Skew IoU computation | |
| 1: | Input: Vertex coordinates of rotating bounding boxes , |
| 2: | Output: IOU between rotating bounding boxes , |
| 3: | Set, |
| 3: | Add intersection points of and to |
| 4: | Add the vertex of inside to |
| 5: | Add the vertex of inside to |
| 6: | Set the mean coordinates of the point in |
| 7: | Compare the coordinates of each point in and , Sort into anticlockwise order |
| 8: | Split convex polygon into triangles |
| 9: | For each triangle () in do |
| 10: | (Heron’s formula) |
| 11: | |
| 12: | End for |
| 13: | |
3. Result
3.1. Datasets
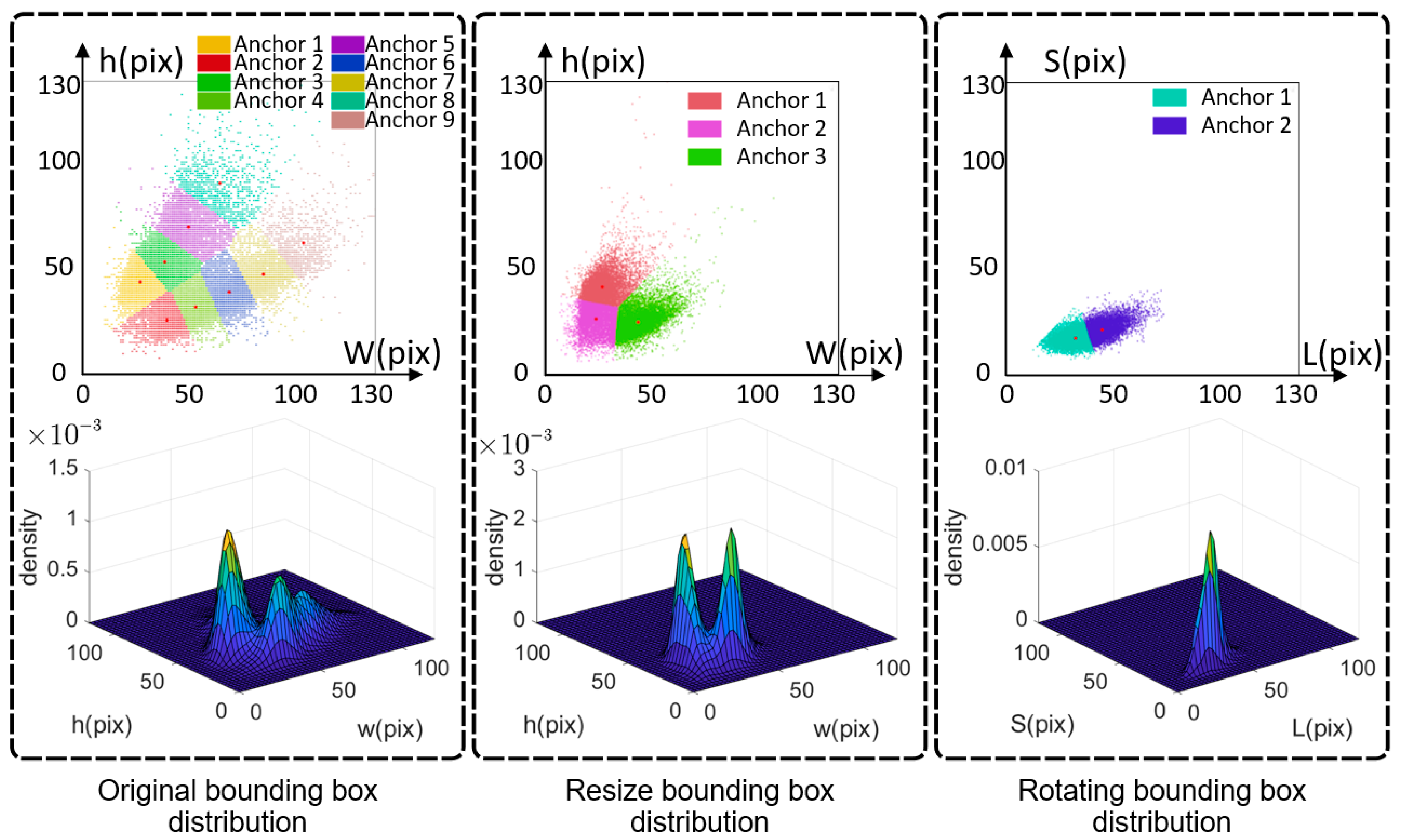
3.1.1. Image Segmentation
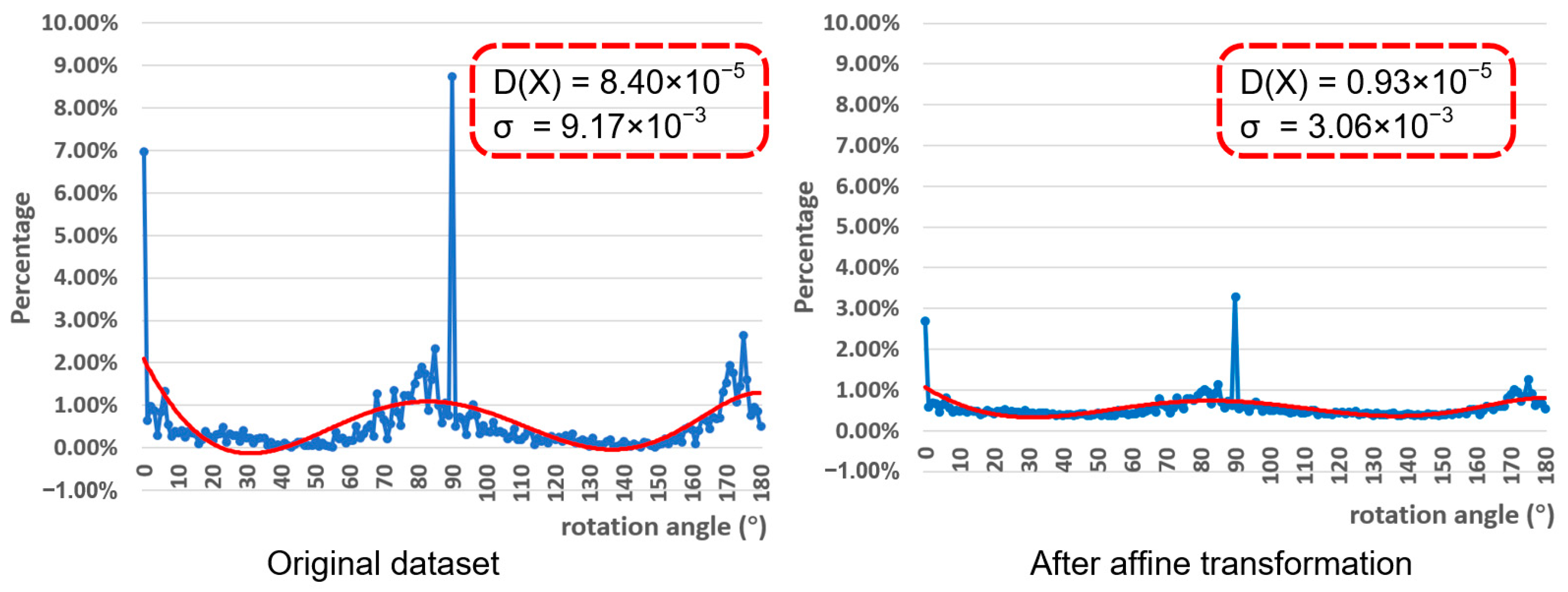
3.1.2. Angles Distribution
3.1.3. Cloud Simulation
3.2. Model Size
3.3. Evaluation Metrics
3.4. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-Based Object Counting by Spatially Regularized Regional Proposal Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4165–4173. [Google Scholar]
- Liao, W.; Chen, X.; Yang, J.F.; Roth, S.; Goesele, M.; Yang, M.Y.; Rosenhahn, B. LR-CNN: Local-aware Region CNN for Vehicle Detection in Aerial Imagery. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, Nice, France, 31 August–2 September 2020; pp. 381–388. [Google Scholar]
- Ferreira de Carvalho, O.L.; Abílio de Carvalho, O.; Olino de Albuquerque, A.; Castro Santana, N.; Leandro Borges, D.; Trancoso Gomes, R.; Fontes Guimarães, R. Bounding Box-Free Instance Segmentation Using Semi-Supervised Learning for Generating a City-Scale Vehicle Dataset. arXiv 2021, arXiv:2111.12122. [Google Scholar]
- Deng, Z.P.; Sun, H.; Zhou, S.L.; Zhao, J.P.; Zou, H.X. Toward Fast and Accurate Vehicle Detection in Aerial Images Using Coupled Region-Based Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Tang, T.Y.; Zhou, S.L.; Deng, Z.P.; Zou, H.X.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, Y.; Gong, Y.P.; Xiao, Z.F.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Xu, Y.Z.; Yu, G.Z.; Wang, Y.P.; Wu, X.K.; Ma, Y.L. Car Detection from Low-Altitude UAV Imagery with the Faster R-CNN. J. Adv. Transp. 2017, 2017. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.X.; Shi, Z.W.; Guo, Y.H.; Ye, J.P. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, America, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade Object Detection with Deformable Part Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.B.; Felzenszwalb, P.F.; McAllester, D. Object Detection with Grammar Models. In Proceedings of the International Conference on Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; pp. 442–450. [Google Scholar]
- Wang, S. Vehicle detection on Aerial Images by Extracting Corner Features for Rotational Invariant Shape Matching. In Proceedings of the IEEE 11th International Conference on Computer and Information Technology (CIT), Paphos, Cyprus, 31 August–2 September 2011; pp. 171–175. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Dollar, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5351–5359. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Ob-jects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zuo, C.; Qian, J.; Feng, S.; Yin, W.; Li, Y.; Fan, P.; Han, J.; Qian, K.; Chen, Q. Deep learning in optical metrology: A review. Light Sci. Appl. 2022, 11, 39. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, G.; Qiao, H.; Bao, F.; Deng, Y.; Wu, J.; He, Y.; Yun, J.; Lin, X.; Xie, H.; et al. Unsupervised content-preserving transformation for optical microscopy. Light Sci. Appl. 2021, 10, 44. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Luo, R.; Liu, X. Spectral imaging with deep learning. Light Sci. Appl. 2022, 11, 61. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Singh, M.; Cetintas, E.; Luo, Y.; Rivenson, Y.; Larin, K.V.; Ozcan, A. Neural network-based image reconstruction in swept-source optical coherence tomography using undersampled spectral data. Light Sci. Appl. 2021, 10, 155. [Google Scholar] [CrossRef]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. arXiv 2020, arXiv:2009.06732. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.H.; Chen, H.T.; Chen, X.H.; Guo, J.Y.; Liu, Z.H.; Tang, Y.H.; Xiao, A.; Xu, C.J.; Xu, Y.X.; et al. A Survey on Vision Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Waqas Zamir, S.; Shahbaz Khan, F.; Shah, M. Transformers in Vision: A Survey. arXiv 2021, arXiv:2101.01169. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Dai, J.F.; Qi, H.Z.; Xiong, Y.W.; Li, Y.; Zhang, G.D.; Hu, H.; Wei, Y.C. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Yang, M.Y.; Liao, W.T.; Li, X.B.; Cao, Y.P.; Rosenhahn, B. Vehicle Detection in Aerial Images. Photogramm. Eng. Remote Sens. 2019, 85, 297–304. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.B.; Datcu, M.; Pelillo, M.; Zhang, L.P. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, GA, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Van Etten, A. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, GA, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, J.N.; Wei, Y.C.; Liang, X.D.; Dong, J.; Xu, T.F.; Feng, J.S.; Yan, S.C. Attentive Contexts for Object Detection. IEEE Trans. Multimed. 2017, 19, 944–954. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.L.; Gupta, A. Spatial Memory for Context Reasoning in Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4106–4116. [Google Scholar]
- Cao, J.X.; Chen, Q.; Guo, J.; Shi, R.C. Attention-guided Context Feature Pyramid Network for Object Detection. arXiv 2020, arXiv:2005.11475. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small Object Detection using Context and Attention. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (IEEE ICAIIC), Jeju Island, Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- He, K.M.; Sun, J.; Tang, X.O. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Hsieh, C.H.; Zhao, Q.F.; Cheng, W.C. Single Image Haze Removal Using Weak Dark Channel Prior. In Proceedings of the International Conference on Awareness Science and Technology (iCAST), Fukuoka, Japan, 19–21 September 2018; pp. 214–219. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 2347–2354. [Google Scholar]
- Zhu, Q.S.; Mai, J.M.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Cai, B.L.; Xu, X.M.; Jia, K.; Qing, C.M.; Tao, D.C. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming Auto-Encoders. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Espoo, Finland, 14–17 June 2011; pp. 44–51. [Google Scholar]
- Yip, B. Face and eye rectification in video conference using affine transform. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Genoa, Italy, 11–14 September 2005; pp. 3021–3024. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kerkyra (Corfu), Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Perlin, K. An Image Synthesizer. SIGGRAPH Comput. Graph. 1985, 19, 287–296. [Google Scholar] [CrossRef]
- Perlin, K. Improving noise. ACM Trans. Graph. 2002, 21, 681–682. [Google Scholar] [CrossRef]
- Fulinski, A. Fractional Brownian Motions. Acta Phys. Pol. B Proc. Suppl. 2020, 51, 1097–1129. [Google Scholar] [CrossRef]
- Zili, M. Generalized fractional Brownian motion. Mod. Stoch. Theory Appl. 2017, 4, 15–24. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.L.; Girshick, R.; Gupta, A.; He, K.M. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, GA, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Chen, Y.P.; Kalantidis, Y.; Li, J.S.; Yan, S.C.; Feng, J.S. A2-Nets: Double Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Yue, K.Y.; Sun, M.; Yuan, Y.C.; Zhou, F.; Ding, E.R.; Xu, F.X. Compact Generalized Non-local Network. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Ren, D.W.; Liu, W.; Ye, R.G.; Hu, Q.H.; Zuo, W.M. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.Q.; Han, J.W. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhu, H.G.; Chen, X.G.; Dai, W.Q.; Fu, K.; Ye, Q.X.; Jiao, J.B. Orientation Robust Object Detection in Aerial Images Using Deep Convolutional Neural Network. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Chen, H.; Shi, Z.W. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Lu, X.Q.; Zhang, Y.L.; Yuan, Y.; Feng, Y.C. Gated and Axis-Concentrated Localization Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 179–192. [Google Scholar] [CrossRef]
- Song, S.; Chaudhuri, K.; Sarwate, A.D. Stochastic gradient descent with differentially private updates. In Proceedings of the IEEE Global Conference on Signal and Information Processing (GLOBALSIP), Austin, TX, USA, 3–5 December 2013; pp. 245–248. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| From | Number | Type | Output Shape | Param | |
|---|---|---|---|---|---|
| / | / | / | input | [−1, 3, 608, 608] | / |
| 0 | −1 | 1 | Upsample | [−1, 3, 1216, 1216] | - |
| 1 | −1 | 1 | Focus | [−1, 64, 608, 608] | 7040 |
| 2 | −1 | 1 | Convolution | [−1, 128, 304, 304] | 73,984 |
| 3 | −1 | 1 | Convolution | [−1, 128, 152, 152] | 147,712 |
| 4 | −1 | 3 | BottleneckCSP | [−1, 128, 152, 152] | 161,152 |
| 5 | −1 | 1 | Convolution | [−1, 256, 76, 76] | 295,424 |
| 6 | −1 | 9 | BottleneckCSP | [−1, 256, 76, 76] | 1,627,904 |
| 7 | −1 | 1 | Convolution | [−1, 512, 38, 38] | 1,180,672 |
| 8 | −1 | 9 | BottleneckCSP | [−1, 512, 38, 38] | 6,499,840 |
| 9 | −1 | 1 | Convolution | [−1, 1024, 19, 19] | 4,720,640 |
| 10 | −1 | 1 | SPP | [−1, 1024, 19, 19] | 2,624,512 |
| 11 | −1 | 3 | BottleneckCSP | [−1, 1024, 19, 19] | 10,234,880 |
| 12 | −1 | 1 | Convolution | [−1, 512, 19, 19] | 525,312 |
| 13 | −1 | 1 | GR Block | [−1, 512, 19, 19] | 1,048,576 |
| 14 | −1 | 1 | Upsample | [−1, 512, 38, 38] | - |
| 15 | [−1, 7] | 1 | Concat | [−1, 1024, 38, 38] | - |
| 16 | −1 | 1 | BottleneckCSP | [−1, 512, 38, 38] | 1,510,912 |
| 17 | −1 | 1 | Convolution | [−1, 256, 38, 38] | 131,584 |
| 18 | −1 | 1 | GR Block | [−1, 256, 38, 38] | 262,144 |
| 19 | −1 | 1 | Upsample | [−1, 256, 76, 76] | - |
| 20 | [−1, 5] | 1 | Concat | [−1, 512, 76, 76] | - |
| 21 | −1 | 1 | BottleneckCSP | [−1, 256, 76, 76] | 378,624 |
| 22 | −1 | 1 | Detect | [−1, 17328, 186] | 143,406 |
| 388 Conv layers | 3.157 × 108 gradients | 103.0 GFLOPS | 3.157 × 107 parameters | ||
| Dataset | Images | Instances | Image Size | Source | Annotation Way | Cloud | F/H |
|---|---|---|---|---|---|---|---|
| ITCVD [40] | 135 | 23,543 | 5616 × 3744 | Aircraft | Horizontal | × | × |
| DLR 3K [50] | 20 | 14,235 | 5616 × 3744 | Aircraft | Horizontal | × | × |
| DIOR [69] | 23,463 | 192,472 | 800 × 800 | Google Earth | Horizontal | × | × |
| UCAS-AOD [70] | 910 | 6029 | ~1280 × 680 | Google Earth | Horizontal | × | × |
| DOTA [41] | 2806 | 188,282 | ~2000 × 1000 | Google Earth | Oriented | × | × |
| LEVIR [71] | 22,000+ | 10,000+ | 800 × 600 | Google Earth | Horizontal | × | × |
| HRRSD [72] | 21,761 | 55,740 | ~1000 × 1000 | Google Earth | Horizontal | × | × |
| RO-ARS | 200 | 35,879 | ~2000 × 1000 | Aircraft | Oriented | √ | √ |
| Method | Input Shape | Anchors | Head | Parameters | Params Size (MB) |
|---|---|---|---|---|---|
| YOLOv3 | 3 × 608 × 608 | 9 | 3 | 61,949,149 | 236.32 |
| YOLOv4 | 3 × 608 × 608 | 9 | 3 | 63,943,071 | 245.53 |
| YOLOv5-m | 3 × 608 × 608 | 9 | 3 | 22,229,358 | 84.80 |
| YOLOv5-base | 3 × 608 × 608 | 9 | 3 | 48,384,174 | 184.57 |
| YOLOv5-x | 3 × 608 × 608 | 9 | 3 | 89,671,790 | 342.07 |
| SSD | 3 × 608 × 608 | 9 | 3 | 23,745,908 | 90.58 |
| Faster-RCNN | 3 × 608 × 608 | 9 | 3 | 137,078,239 | 522.91 |
| SSRD-base (ours) | 3 × 608 × 608 | 3 | 1 | 31,574,318 | 120.45 |
| SSRD-tiny (ours) | 3 × 608 × 608 | 3 | 1 | 5,375,662 | 20.51 |
| Dataset | Train (Cloud) | Test (Cloud) | Precision | Recall | F1 | AP@0.5 | AP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| ITCVD | × | × | 63.64% | 75.73% | 0.6916 | 73.78% | 35.34% |
| ITCVD | × | √ | 57.34% | 54.34% | 0.5580 | 53.32% | 20.45% |
| ITCVD | √ | √ | 62.55% | 70.27% | 0.6619 | 71.32% | 33.72% |
| DLR 3K | × | × | 72.56% | 84.34% | 0.7801 | 78.89% | 43.23% |
| DLR 3K | × | √ | 64.32% | 59.23% | 0.6167 | 60.08% | 35.08% |
| DLR 3K | √ | √ | 70.32% | 78.89% | 0.7436 | 75.23% | 41.87% |
| Method | Backbone | Epoch | Precision | Recall | F1 | AP@0.5 | AP@0.5:0.95 | Time (Blocks) |
|---|---|---|---|---|---|---|---|---|
| HOG + SVM | / | / | 6.52% | 21.19% | 0.0997 | / | / | 1.3 fps |
| SSD300 | VGG16 | / | 25.55% | 47.34% | 0.3318 | 24.46% | 12.45% | 45.5 fps |
| Faster-RCNN | ResNet | / | 39.18% | 57.36% | 0.4656 | 39.21% | 16.34% | 7.2 fps |
| YOLOv3 | Darknet53 | / | 21.18% | 68.65% | 0.3237 | 53.34% | 20.34% | 51.3 fps |
| YOLOv4 | CSPDarknet53 | / | 39.72% | 79.25% | 0.5291 | 65.31% | 25.38% | 56.4 fps |
| YOLOv5s | CSPDarknet53 | 100 | 27.18% | 77.52% | 0.4025 | 58.54% | 21.18% | 71.4 fps |
| 200 | 34.28% | 80.96% | 0.4817 | 68.99% | 27.20% | |||
| YOLOv5m | CSPDarknet53 | 100 | 26.44% | 81.96% | 0.3998 | 64.11% | 24.67% | 62.1 fps |
| 200 | 36.82% | 79.68% | 0.5036 | 68.56% | 28.36% | |||
| YOLOv5-base | CSPDarknet53 | 100 | 32.23% | 77.53% | 0.4555 | 55.37% | 23.09% | 48.5 fps |
| 200 | 40.11% | 73.21% | 0.5182 | 60.33% | 23.54% | |||
| YOLOv5x | CSPDarknet53 | 40 | 17.68% | 81.31% | 0.2904 | 53.34% | 20.02% | 30.7 fps |
| 100 | 17.54% | 81.06% | 0.2883 | 26.67% | 10.28% | |||
| 150 | 26.35% | 78.66% | 0.3948 | 40.10% | 16.11% | |||
| 200 | 33.29% | 77.59% | 0.4659 | 48.25% | 20.09% | |||
| SSRD-base (No up-sample & GR block) | CSPDarknet53 | 100 | 40.06% | 75.12% | 0.5225 | 62.92% | 23.63% | 61.5 fps |
| 200 | 44.54% | 76.50% | 0.5630 | 65.70% | 26.39% | |||
| SSRD-base (No up-sample) | CSPDarknet53 | 100 | 42.23% | 75.69% | 0.5421 | 65.22% | 26.60% | 57.8 fps |
| 200 | 56.74% | 72.74% | 0.6375 | 69.04% | 29.31% | |||
| SSRD-base (No GR block) | CSPDarknet53 | 100 | 48.68% | 71.67% | 0.5798 | 65.77% | 26.93% | 54.9 fps |
| 200 | 57.49% | 64.48% | 0.6078 | 65.90% | 28.06% | |||
| SSRD-base (ours) | CSPDarknet53 | 100 | 51.76% | 76.80% | 0.6184 | 68.29% | 30.57% | 49.6 fps |
| 200 | 62.52% | 72.70% | 0.6722 | 72.23% | 31.69% | |||
| SSRD-tiny (ours) | CSPDarknet53 | 100 | 41.44% | 76.24% | 0.5369 | 65.36% | 25.42% | 92.6 fps |
| 200 | 51.62% | 76.43% | 0.6152 | 70.30% | 27.78% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, S.; Liu, J.; Tian, Y.; Zuo, Y.; Liu, C. Rapid Vehicle Detection in Aerial Images under the Complex Background of Dense Urban Areas. Remote Sens. 2022, 14, 2088. https://doi.org/10.3390/rs14092088
Zhu S, Liu J, Tian Y, Zuo Y, Liu C. Rapid Vehicle Detection in Aerial Images under the Complex Background of Dense Urban Areas. Remote Sensing. 2022; 14(9):2088. https://doi.org/10.3390/rs14092088
Chicago/Turabian StyleZhu, Shengjie, Jinghong Liu, Yang Tian, Yujia Zuo, and Chenglong Liu. 2022. "Rapid Vehicle Detection in Aerial Images under the Complex Background of Dense Urban Areas" Remote Sensing 14, no. 9: 2088. https://doi.org/10.3390/rs14092088
APA StyleZhu, S., Liu, J., Tian, Y., Zuo, Y., & Liu, C. (2022). Rapid Vehicle Detection in Aerial Images under the Complex Background of Dense Urban Areas. Remote Sensing, 14(9), 2088. https://doi.org/10.3390/rs14092088