
Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies

 ,
,  ,
,
Abstract
1. Introduction
- To achieve efficient and accurate feature selection, a reinforcement learning framework was proposed. A supervised feature selection method was used, which considered the needs of the inversion task. We believe this is the first time reinforcement learning has been introduced into feature selection for a hyperspectral inversion task.
- The spectral feature selection problem was formulated as an MDP. A selection agent was then constructed, and the state of the agent was updated based on the spectral feature selection. To comprehensively evaluate the value of the features selected by the agent, two evaluation strategies were proposed: RLFSR-Net and RLFSR-Cv. With the support of the two strategies, the training of the feature selection model was completed to maximize the cumulative reward.
- The feature subsets selected by RLFSR-Net and RLFSR-Cv achieved inversion results that were comparable with those of the XGBoost model, and they outperformed the other data dimensionality reduction methods. As the number of features increased, the inversion accuracy of the feature subset generally improved. However, after reaching a certain number of features, the inversion accuracy decreased instead, due to the increase in noise and invalid information.
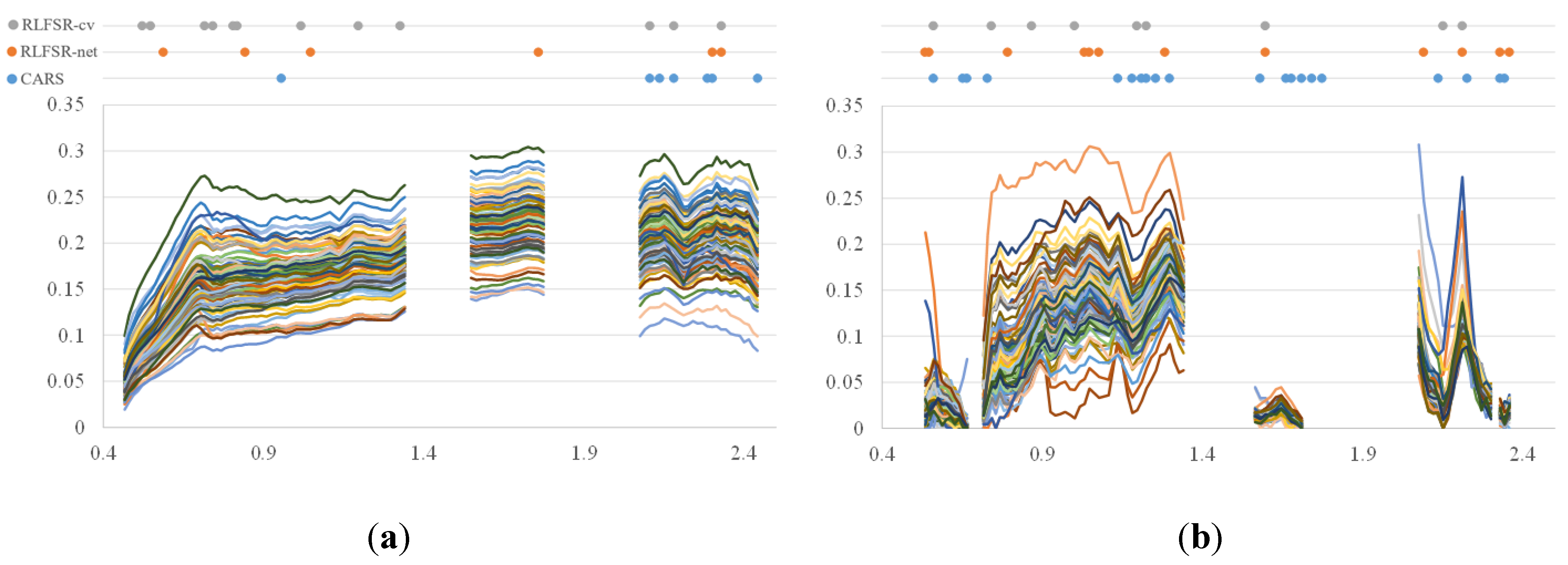
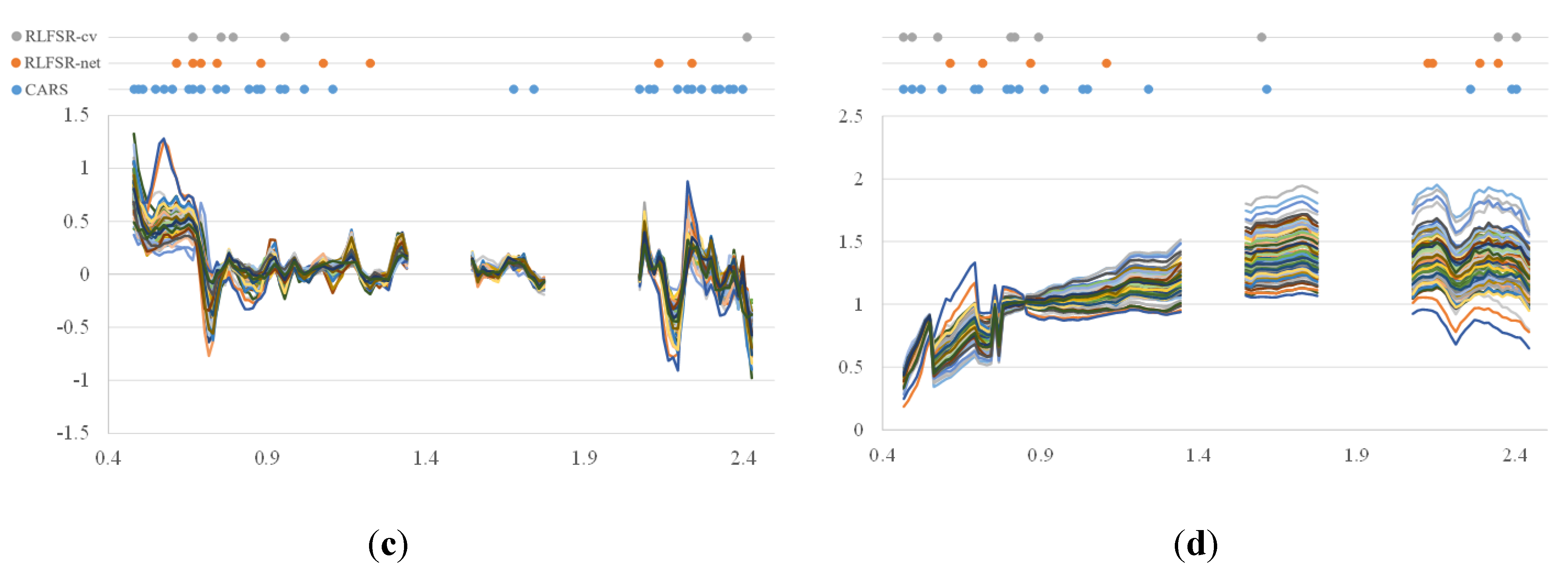
- The spectral features extracted by RLFSR-Net and RLFSR-Cv appeared to be in high agreement with those extracted by CARS, and were concentrated in the visible range and 2.2 μm, which was in line with the experience of SOM inversion. However, the proposed method could extract a more compact subset of features and achieve better inversion results.
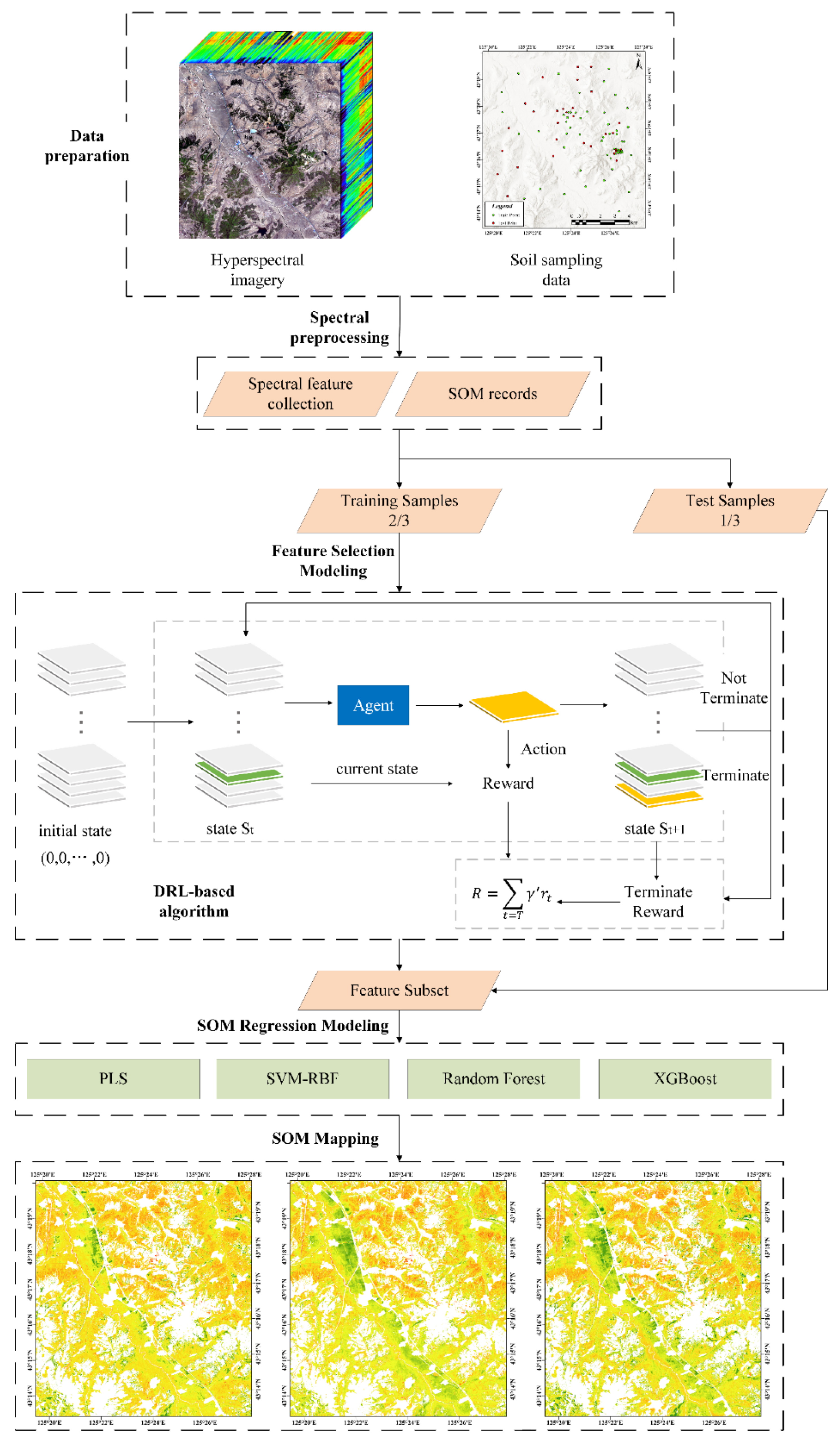
2. Methods
2.1. Feature Selection Modeling
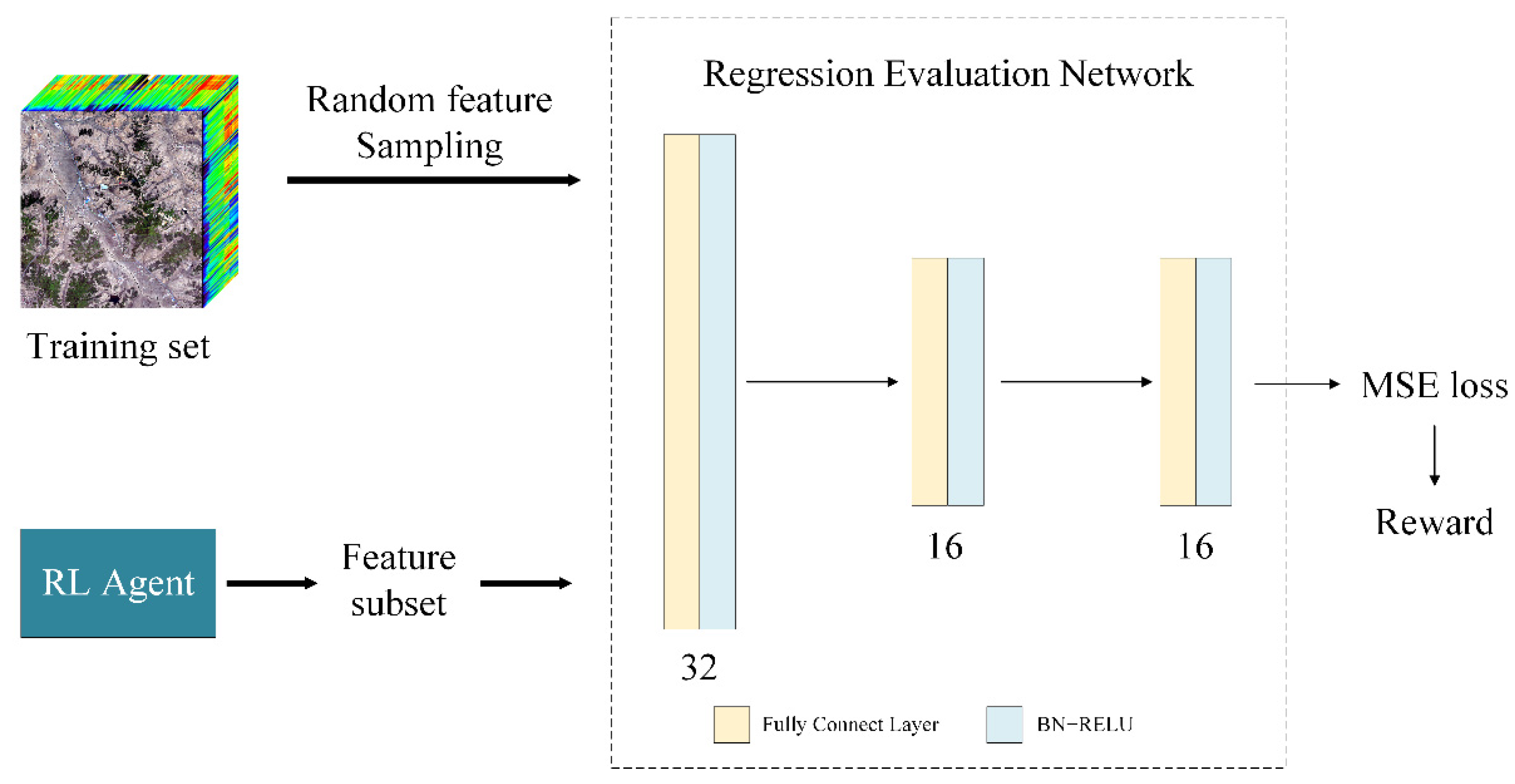
2.2. Feature Evaluation in RLFSR-Net
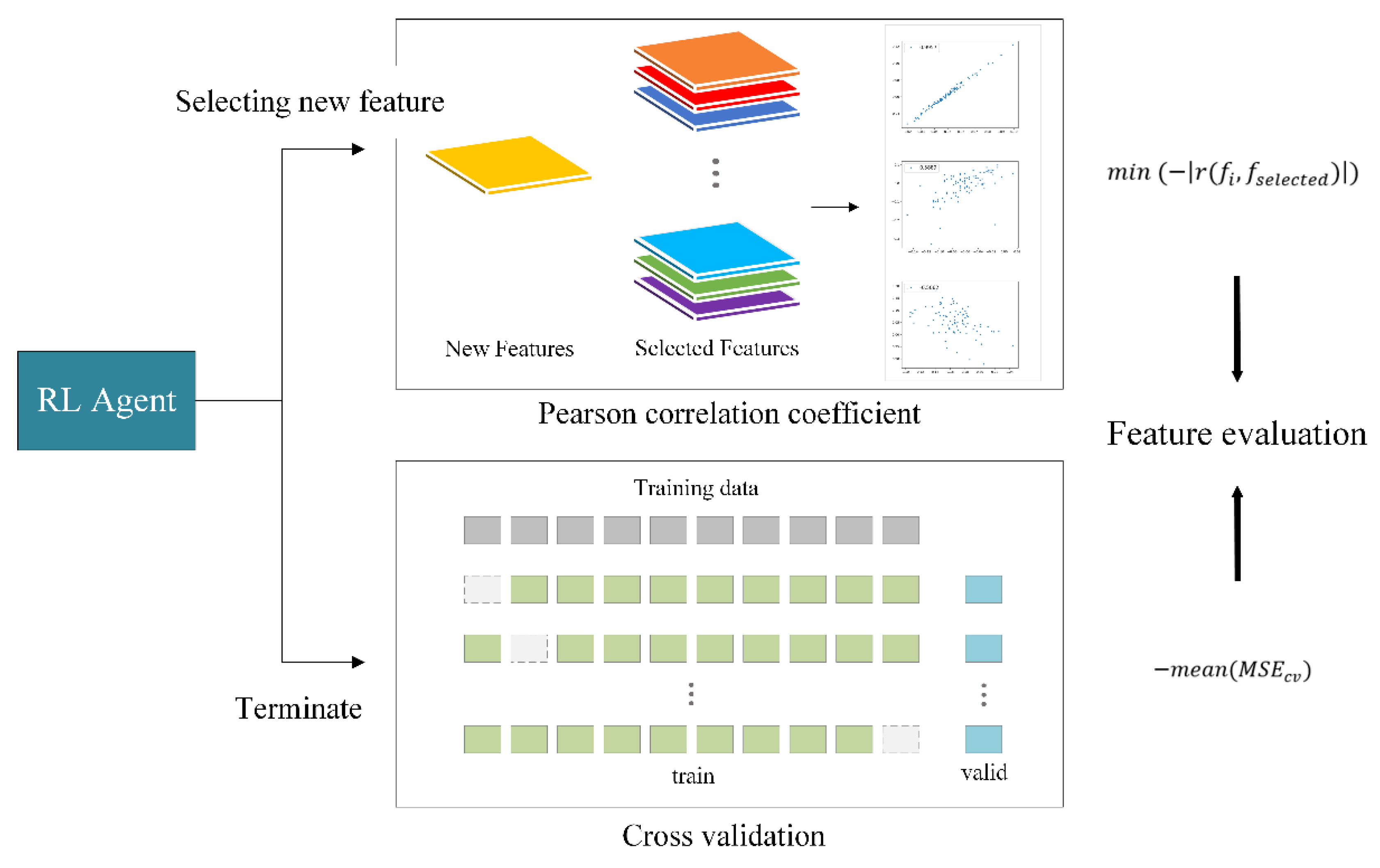
2.3. Feature Evaluation in RLFSR-Cv
2.3.1. Selecting a New Feature
2.3.2. Termination
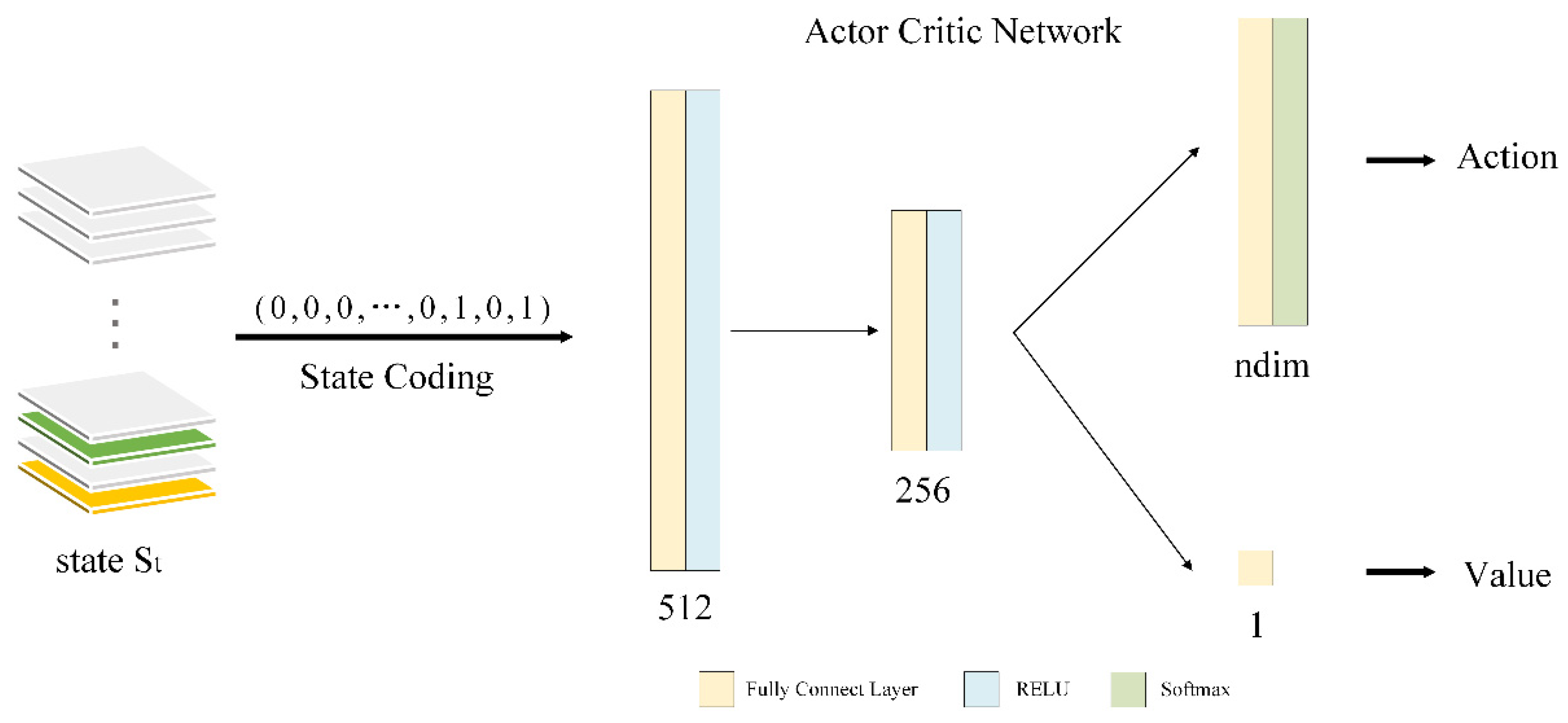
2.4. Deep Reinforcement Learning for the RLFSR Framework
2.4.1. Introduction to Deep Reinforcement Learning
2.4.2. Training of the A2C Algorithm
| Algorithm 1: The procedure of training the A2C-based network Input: hyperspectral training dataset Output: selected feature code number |
| 1: randomly initialize policy network parameter and value network parameter 2: initialize max iteration , update interval 3: for 1 to K: 4: for 1 to T: 5: while is terminate 6: initialize state , the reward 7: end 8: compute the output distribution of action according to policy 9: perform based on probability 10: 11: get the reward and new state 12: 13: 14: end 15: calculate long-term return 16: update based on the TD error 17: 18: update according to the advantage function 19: 20: end |
3. Experimental Results
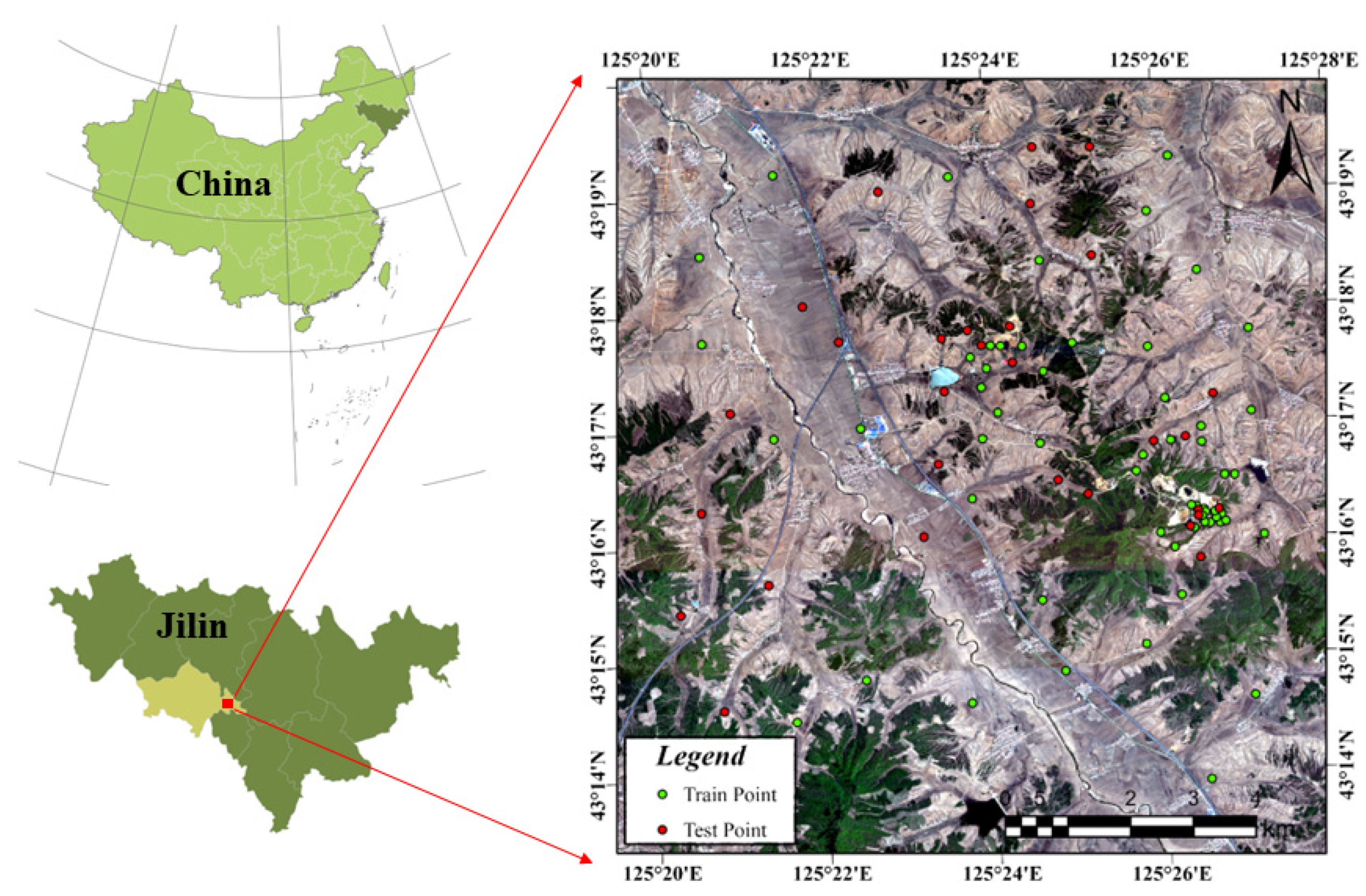
3.1. Datasets and Preprocessing
3.1.1. Preprocessing of the Hyperspectral Data Cube
3.1.2. Processing of the Soil Samples
- (1)
- Calculate the absorption depth after continuum removal processing:
- (2)
- Calculate the first-order differentiation of the spectrum:where and respectively represent the reflectance of the former and latter bands, and respectively represent the wavelength of the former and latter bands, and is the first-order differential value at that band.
- (3)
- Calculate the band ratio: Since there were 101 bands in the dataset, calculating all the band ratios would result in a large amount of feature redundancy. Therefore, for each band, its ratio to the other bands was calculated, and the ratio with the highest correlation with SOM in all band ratios was selected as the optimal ratio of that band.
- (4)
- Combine all the above features (raw spectrum, absorption depth of the continuum removal, first-order differentiation, and optimal band ratios).
- (5)
- Sample expansion based on the spatial distance: Considering Tobler’s first law of geography and the stability of the SOM at the meter level, to improve the model stability, the training set was expanded according to the spatial distance and spectral angle distance from the labeled samples. Unlabeled samples that were spatially neighboring and spectrally close to the training set were added to the new training set.
3.2. Experiment in RLFSR
- (1)
- PCA: principal component analysis, which extracts features to a cumulative contribution rate of 0.99.
- (2)
- ICA: independent component analysis with 10 components.
- (3)
- Pearson: the Pearson product-moment correlation coefficient, which selects the 30 characteristics that are most relevant to the dependent variable.
- (4)
- VIP: variable importance projection, which selects the 30 features of the highest importance for the inversion modeling.
- (5)
- SOS: symbiotic organisms search.
- (6)
- IRF: interval random frog.
- (7)
- CARS: competitive adaptive reweighted sampling.
- (1)
- PLS: partial least squares regression with 20 latent variables.
- (2)
- RF: random forest regression, which is a supervised learning algorithm that uses an ensemble learning method for the regression.
- (3)
- SVM: support vector machine regression equipped with a radial basis function (RBF) kernel. Parameters and were determined by 10-fold cross-validation.
- (4)
- XGBoost: extreme gradient boosting, which is an implementation of gradient-boosted decision trees designed for speed and performance. The main parameters were determined by 10-fold cross-validation.
- (1)
- R2: the coefficient of determination is the proportion of the variation in the dependent variable that is predictable from the independent variable.
- (2)
- MSE: the mean squared error of an estimator measures the average of the squares of the errors, i.e., the average squared difference between the estimated value and the true value.
- (3)
- MAE: the mean absolute error is the arithmetic average of the absolute errors.
3.3. Results of Different Dimensionality Reduction Methods
4. Discussion
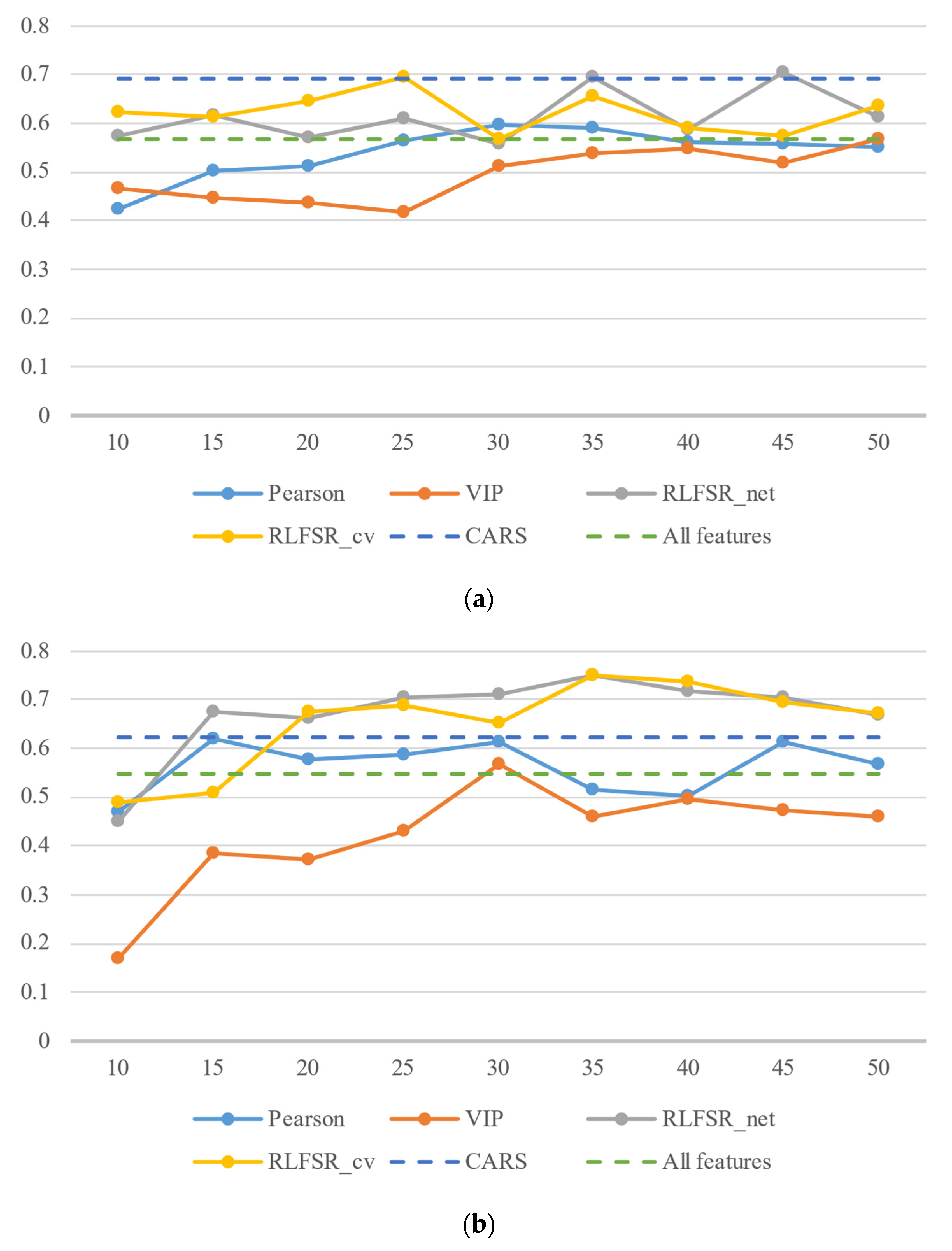
4.1. Performance with Different Numbers of Selected Features
4.2. Analysis of the Spectral Features
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bünemann, E.K.; Bongiorno, G.; Bai, Z.; Creamer, R.E.; De Deyn, G.; de Goede, R.; Fleskens, L.; Geissen, V.; Kuyper, T.W.; Mäder, P. Soil quality–A critical review. Soil Biol. Biochem. 2018, 120, 105–125. [Google Scholar] [CrossRef]
- Tan, K.; Ma, W.; Chen, L.; Wang, H.; Du, Q.; Du, P.; Yan, B.; Liu, R.; Li, H. Estimating the distribution trend of soil heavy metals in mining area from HyMap airborne hyperspectral imagery based on ensemble learning. J. Hazard. Mater. 2021, 401, 123288. [Google Scholar] [CrossRef] [PubMed]
- Tan, K.; Wang, H.; Chen, L.; Du, Q.; Du, P.; Pan, C. Estimation of the spatial distribution of heavy metal in agricultural soils using airborne hyperspectral imaging and random forest. J. Hazard. Mater. 2020, 382, 120987. [Google Scholar] [CrossRef] [PubMed]
- Meng, X.; Bao, Y.; Ye, Q.; Liu, H.; Zhang, X.; Tang, H.; Zhang, X. Soil organic matter prediction model with satellite hyperspectral image based on optimized denoising method. Remote Sens. 2021, 13, 2273. [Google Scholar] [CrossRef]
- Nanni, M.R.; Demattê, J.A.M.; Rodrigues, M.; Santos, G.L.A.A.d.; Reis, A.S.; Oliveira, K.M.d.; Cezar, E.; Furlanetto, R.H.; Crusiol, L.G.T.; Sun, L. Mapping particle size and soil organic matter in tropical soil based on hyperspectral imaging and non-imaging sensors. Remote Sens. 2021, 13, 1782. [Google Scholar] [CrossRef]
- Ou, D.; Tan, K.; Lai, J.; Jia, X.; Wang, X.; Chen, Y.; Li, J. Semi-supervised DNN regression on airborne hyperspectral imagery for improved spatial soil properties prediction. Geoderma 2021, 385, 114875. [Google Scholar] [CrossRef]
- Kumar, V.; Minz, S. Feature selection: A literature review. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Lee, J.; Park, D.; Lee, C. Feature selection algorithm for intrusions detection system using sequential forward search and random forest classifier. KSII Trans. Internet Inf. Syst. (TIIS) 2017, 11, 5132–5148. [Google Scholar]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Cortina-Januchs, M.; Andina, D. Feature selection using sequential forward selection and classification applying artificial metaplasticity neural network. In Proceedings of the IECON 2010-36th Annual Conference on IEEE Industrial Electronics Society, Glendale, AZ, USA, 7–10 November 2010; pp. 2845–2850. [Google Scholar]
- Ververidis, D.; Kotropoulos, C. Sequential forward feature selection with low computational cost. In Proceedings of the 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Mao, K.Z. Orthogonal forward selection and backward elimination algorithms for feature subset selection. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 629–634. [Google Scholar] [CrossRef]
- Cotter, S.F.; Kreutz-Delgado, K.; Rao, B.D. Backward sequential elimination for sparse vector subset selection. Signal Process. 2001, 81, 1849–1864. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Shafiee, S.; Lied, L.M.; Burud, I.; Dieseth, J.A.; Alsheikh, M.; Lillemo, M. Sequential forward selection and support vector regression in comparison to LASSO regression for spring wheat yield prediction based on UAV imagery. Comput. Electron. Agric. 2021, 183, 106036. [Google Scholar] [CrossRef]
- Meiri, R.; Zahavi, J. Using simulated annealing to optimize the feature selection problem in marketing applications. Eur. J. Oper. Res. 2006, 171, 842–858. [Google Scholar] [CrossRef]
- Huang, C.-L.; Wang, C.-J. A GA-based feature selection and parameters optimizationfor support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- De La Iglesia, B. Evolutionary computation for feature selection in classification problems. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 381–407. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimization for feature selection in classification: A multi-objective approach. IEEE Trans. Cybern. 2012, 43, 1656–1671. [Google Scholar] [CrossRef]
- Wang, X.; Yang, J.; Teng, X.; Xia, W.; Jensen, R. Feature selection based on rough sets and particle swarm optimization. Pattern Recognit. Lett. 2007, 28, 459–471. [Google Scholar] [CrossRef]
- Zabinsky, Z.B. Random Search Algorithms; Department of Industrial and Systems Engineering, University of Washington: Washinton, DC, USA, 2009. [Google Scholar]
- Almuallim, H.; Dietterich, T.G. Learning boolean concepts in the presence of many irrelevant features. Artif. Intell. 1994, 69, 279–305. [Google Scholar] [CrossRef]
- Ben-Bassat, M. Pattern recognition and reduction of dimensionality. Handb. Stat. 1982, 2, 773–910. [Google Scholar]
- Devijver, P.A.; Kittler, J. Pattern Recognition: A Statistical Approach; Prentice Hall: Hoboken, NJ, USA, 1982. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection of Discrete and Numeric Class Machine Learning; University of Waikato: Hamilton, New Zealand, 2000. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Piramuthu, S. Evaluating feature selection methods for learning in data mining applications. Eur. J. Oper. Res. 2004, 156, 483–494. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 454. [Google Scholar]
- John, G.H.; Kohavi, R.; Pfleger, K. Irrelevant features and the subset selection problem. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 121–129. [Google Scholar]
- Bangelesa, F.; Adam, E.; Knight, J.; Dhau, I.; Ramudzuli, M.; Mokotjomela, T.M. Predicting soil organic carbon content using hyperspectral remote sensing in a degraded mountain landscape in lesotho. Appl. Environ. Soil Sci. 2020, 2020, 2158573. [Google Scholar] [CrossRef]
- Song, Y.-Q.; Zhao, X.; Su, H.-Y.; Li, B.; Hu, Y.-M.; Cui, X.-S. Predicting spatial variations in soil nutrients with hyperspectral remote sensing at regional scale. Sensors 2018, 18, 3086. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Yuan, Z.; Zhong, Y.; Yang, L.; Hu, X.; Zhang, Y. An improved gradient boosting regression tree estimation model for soil heavy metal (Arsenic) pollution monitoring using hyperspectral remote sensing. Appl. Sci. 2019, 9, 1943. [Google Scholar] [CrossRef]
- Kawamura, K.; Tsujimoto, Y.; Nishigaki, T.; Andriamananjara, A.; Rabenarivo, M.; Asai, H.; Rakotoson, T.; Razafimbelo, T. Laboratory visible and near-infrared spectroscopy with genetic algorithm-based partial least squares regression for assessing the soil phosphorus content of upland and lowland rice fields in Madagascar. Remote Sens. 2019, 11, 506. [Google Scholar] [CrossRef]
- Feng, J.; Li, D.; Chen, J.; Zhang, X.; Tang, X.; Wu, X. Hyperspectral band selection based on ternary weight convolutional neural network. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3804–3807. [Google Scholar]
- Lorenzo, P.R.; Tulczyjew, L.; Marcinkiewicz, M.; Nalepa, J. Hyperspectral band selection using attention-based convolutional neural networks. IEEE Access 2020, 8, 42384–42403. [Google Scholar] [CrossRef]
- Ortiz, A.; Granados, A.; Fuentes, O.; Kiekintveld, C.; Rosario, D.; Bell, Z. Integrated learning and feature selection for deep neural networks in multispectral images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1196–1205. [Google Scholar]
- Bernal, E.A. Surrogate Contrastive Network for Supervised Band Selection in Multispectral Computer Vision Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Mou, L.; Saha, S.; Hua, Y.; Bovolo, F.; Bruzzone, L.; Zhu, X.X. Deep reinforcement learning for band selection in hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5504414. [Google Scholar] [CrossRef]
- Feng, J.; Li, D.; Gu, J.; Cao, X.; Shang, R.; Zhang, X.; Jiao, L. Deep reinforcement learning for semisupervised hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5501719. [Google Scholar] [CrossRef]
- Berk, A.; Anderson, G.P.; Bernstein, L.S.; Acharya, P.K.; Dothe, H.; Matthew, M.W.; Adler-Golden, S.M.; Chetwynd, J.H., Jr.; Richtsmeier, S.C.; Pukall, B. MODTRAN4 radiative transfer modeling for atmospheric correction. In Proceedings of the Optical Spectroscopic Techniques and Instrumentation for Atmospheric and Space Research III, Denver, CO, USA, 19–21 July 1999; pp. 348–353. [Google Scholar]
- Yu, J.; Yan, B.; Liu, W.; Li, Y.; He, P. Seamless Mosaicking of Multi-strip Airborne Hyperspectral Images Based on Hapke Model. In Proceedings of the International Conference on Sensing and Imaging, Chengdu, China, 5–7 June 2017; pp. 285–292. [Google Scholar]
- Wang, X.; Zhang, F.; Johnson, V.C. New methods for improving the remote sensing estimation of soil organic matter content (SOMC) in the Ebinur Lake Wetland National Nature Reserve (ELWNNR) in northwest China. Remote Sens. Environ. 2018, 218, 104–118. [Google Scholar] [CrossRef]
- Mutanga, O.; Skidmore, A.K.; Prins, H. Predicting in situ pasture quality in the Kruger National Park, South Africa, using continuum-removed absorption features. Remote Sens. Environ. 2004, 89, 393–408. [Google Scholar] [CrossRef]
- Dou, X.; Wang, X.; Liu, H.; Zhang, X.; Meng, L.; Pan, Y.; Yu, Z.; Cui, Y. Prediction of soil organic matter using multi-temporal satellite images in the Songnen Plain, China. Geoderma 2019, 356, 113896. [Google Scholar] [CrossRef]
- Jaffel, Z.; Farah, M. A symbiotic organisms search algorithm for feature selection in satellite image classification. In Proceedings of the 2018 4th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 21–24 March 2018; pp. 1–5. [Google Scholar]
- Liu, H.; Zhang, Y.; Zhang, B. Novel hyperspectral reflectance models for estimating black-soil organic matter in Northeast China. Environ. Monit. Assess. 2009, 154, 147–154. [Google Scholar] [CrossRef] [PubMed]
- Weidong, L.; Baret, F.; Xingfa, G.; Qingxi, T.; Lanfen, Z.; Bing, Z. Relating soil surface moisture to reflectance. Remote Sens. Environ. 2002, 81, 238–246. [Google Scholar] [CrossRef]
- Shen, L.; Gao, M.; Yan, J.; Li, Z.-L.; Leng, P.; Yang, Q.; Duan, S.-B. Hyperspectral estimation of soil organic matter content using different spectral preprocessing techniques and PLSR method. Remote Sens. 2020, 12, 1206. [Google Scholar] [CrossRef]
- Ou, D.; Tan, K.; Wang, X.; Wu, Z.; Li, J.; Ding, J. Modified soil scattering coefficients for organic matter inversion based on Kubelka-Munk theory. Geoderma 2022, 418, 115845. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Regression Model | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|---|
| R2 | MAE | MSE | R2 | MAE | MSE | ||
| PCA | PLS | 0.5968 | 3.2967 | 16.9878 | 0.3386 | 3.9512 | 25.6450 |
| SVM-RBF | 0.9998 | 0.0989 | 0.0098 | 0.0636 | 4.6384 | 36.3075 | |
| RF | 0.5580 | 3.3086 | 18.6191 | 0.5488 | 3.3328 | 17.4946 | |
| XGBoost | 0.9729 | 0.7786 | 1.1435 | 0.5332 | 3.5420 | 18.0982 | |
| ICA | PLS | 0.4182 | 3.9287 | 24.5114 | 0.5788 | 3.2597 | 16.3295 |
| SVM-RBF | 0.9998 | 0.0991 | 0.0099 | 0.0791 | 4.6205 | 35.7049 | |
| RF | 0.6942 | 2.6750 | 12.8822 | 0.3452 | 4.0807 | 25.3871 | |
| XGBoost | 0.8526 | 1.8588 | 6.2109 | 0.3386 | 3.8821 | 25.6452 | |
| Pearson | PLS | 0.4609 | 3.7721 | 22.7120 | 0.4209 | 3.7285 | 22.4544 |
| SVM-RBF | 0.6623 | 2.2414 | 14.2281 | 0.5977 | 3.3790 | 15.5993 | |
| RF | 0.6763 | 2.8541 | 13.6371 | 0.5891 | 3.1342 | 15.9333 | |
| XGBoost | 0.7929 | 2.2260 | 8.7256 | 0.6122 | 2.8507 | 15.0379 | |
| VIP | PLS | 0.5880 | 3.3063 | 17.3584 | 0.2480 | 4.0115 | 29.1573 |
| SVM-RBF | 0.5636 | 2.9460 | 18.3826 | 0.5134 | 3.3498 | 18.8654 | |
| RF | 0.5861 | 3.2546 | 17.4362 | 0.5579 | 3.5180 | 17.1430 | |
| XGBoost | 0.9960 | 0.3060 | 0.1696 | 0.5686 | 3.2672 | 16.7250 | |
| SOS | PLS | 0.6217 | 3.1355 | 15.9358 | 0.3224 | 3.8480 | 26.2733 |
| SVM-RBF | 0.8166 | 1.5208 | 7.7243 | 0.4664 | 3.7999 | 20.6903 | |
| RF | 0.7841 | 2.3960 | 9.0969 | 0.5541 | 3.5191 | 17.2875 | |
| XGBoost | 0.9999 | 0.0472 | 0.0043 | 0.5024 | 3.6873 | 19.2929 | |
| IRF | PLS | 0.7738 | 2.4291 | 9.5302 | 0.0012 | 5.4822 | 57.2887 |
| SVM-RBF | 0.9211 | 0.7375 | 3.3228 | 0.5682 | 3.1987 | 16.7439 | |
| RF | 0.7910 | 2.3532 | 8.8043 | 0.6649 | 3.0512 | 12.9923 | |
| XGBoost | 0.9999 | 0.0470 | 0.0041 | 0.6514 | 2.9768 | 13.5181 | |
| CARS | PLS | 0.7418 | 2.6394 | 10.8791 | 0.0018 | 4.9548 | 44.3211 |
| SVM-RBF | 0.8302 | 1.4981 | 7.1515 | 0.6902 | 2.8810 | 12.0125 | |
| RF | 0.6943 | 2.8585 | 12.8799 | 0.6541 | 2.9864 | 13.4113 | |
| XGBoost | 0.9750 | 0.7535 | 1.0512 | 0.6228 | 2.9414 | 14.6253 | |
| RLFSR-Net | PLS | 0.5211 | 3.4638 | 20.1745 | 0.4080 | 3.6995 | 22.9549 |
| SVM-RBF | 0.7514 | 1.8932 | 10.4742 | 0.6955 | 2.7447 | 11.8063 | |
| RF | 0.7320 | 2.5578 | 11.2919 | 0.7312 | 2.6398 | 10.4218 | |
| XGBoost | 0.9999 | 0.0006 | 0.0001 | 0.7506 | 2.7276 | 9.6700 | |
| RLFSR-Cv | PLS | 0.5390 | 3.4213 | 19.4200 | 0.3960 | 3.3683 | 23.4192 |
| SVM-RBF | 0.7227 | 2.0551 | 11.6808 | 0.6549 | 2.9157 | 13.3790 | |
| RF | 0.7739 | 2.3723 | 9.5260 | 0.6800 | 2.8373 | 12.4054 | |
| XGBoost | 0.9997 | 0.0735 | 0.0108 | 0.7518 | 2.4512 | 9.6215 | |
| Method | Inference Time (s) |
|---|---|
| PCA | 0.04 |
| ICA | 0.10 |
| Pearson | 0.01 |
| VIP | 0.12 |
| CARS | 22.96 |
| SOS | 353.46 |
| IRF | 397.84 |
| RLFSR-Cv | 177.51 |
| RLFSR-Net | 92.97 |
| Method | Number of Features | Training Set | Test Set | ||||
|---|---|---|---|---|---|---|---|
| R2 | MAE | MSE | R2 | MAE | MSE | ||
| RLFSR-Net | 10 | 0.9977 | 0.2144 | 0.0959 | 0.4514 | 3.7140 | 21.2701 |
| 15 | 0.9991 | 0.1346 | 0.0364 | 0.6758 | 2.6654 | 12.5721 | |
| 20 | 0.9989 | 0.1518 | 0.0457 | 0.6609 | 3.0678 | 13.1479 | |
| 25 | 0.9995 | 0.1097 | 0.0223 | 0.7055 | 2.9341 | 11.4206 | |
| 30 | 0.9995 | 0.1003 | 0.0205 | 0.7103 | 2.8101 | 11.2323 | |
| 35 | 0.9999 | 0.0006 | 0.0001 | 0.7506 | 2.7276 | 9.6700 | |
| 40 | 0.9997 | 0.0742 | 0.0111 | 0.7171 | 2.3913 | 10.9676 | |
| 45 | 0.9998 | 0.0685 | 0.0097 | 0.7044 | 2.9024 | 11.4620 | |
| 50 | 0.9999 | 0.0556 | 0.0058 | 0.6690 | 3.0277 | 12.8336 | |
| RLFSR-Cv | 10 | 0.9985 | 0.1862 | 0.0624 | 0.4876 | 3.6880 | 19.8690 |
| 15 | 0.9996 | 0.0848 | 0.0154 | 0.5100 | 3.7000 | 18.9994 | |
| 20 | 0.9994 | 0.1113 | 0.0254 | 0.6744 | 2.6709 | 12.6227 | |
| 25 | 0.9997 | 0.0764 | 0.0122 | 0.6886 | 2.9802 | 12.0740 | |
| 30 | 0.9997 | 0.0825 | 0.0125 | 0.6529 | 2.9904 | 13.4596 | |
| 35 | 0.9997 | 0.0735 | 0.0108 | 0.7518 | 2.4512 | 9.6215 | |
| 40 | 0.9999 | 0.0480 | 0.0052 | 0.7362 | 2.3955 | 10.2286 | |
| 45 | 0.9999 | 0.0563 | 0.0060 | 0.6949 | 2.8559 | 11.8290 | |
| 50 | 0.9999 | 0.0473 | 0.0042 | 0.6710 | 2.9491 | 12.7550 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Tan, K.; Wang, X.; Ding, J.; Liu, Z.; Ma, H.; Han, B. Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies. Remote Sens. 2023, 15, 127. https://doi.org/10.3390/rs15010127
Zhao L, Tan K, Wang X, Ding J, Liu Z, Ma H, Han B. Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies. Remote Sensing. 2023; 15(1):127. https://doi.org/10.3390/rs15010127
Chicago/Turabian StyleZhao, Linya, Kun Tan, Xue Wang, Jianwei Ding, Zhaoxian Liu, Huilin Ma, and Bo Han. 2023. "Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies" Remote Sensing 15, no. 1: 127. https://doi.org/10.3390/rs15010127
APA StyleZhao, L., Tan, K., Wang, X., Ding, J., Liu, Z., Ma, H., & Han, B. (2023). Hyperspectral Feature Selection for SOM Prediction Using Deep Reinforcement Learning and Multiple Subset Evaluation Strategies. Remote Sensing, 15(1), 127. https://doi.org/10.3390/rs15010127