






Multi-Pooling Context Network for Image Semantic Segmentation

Abstract
:1. Introduction
- (1)
- We constructed a Multi-Pooling Context Network (MPCNet), which captures rich semantic context information through the encoder and restores the spatial context information through the decoder formed by the jump connection. The whole network realizes the effective combination of semantic context and spatial context with the encoding and decoding structure, thus completing the semantic segmentation task.
- (2)
- We designed a Spatial Context Module (SCM), which is composed of different types of pooling layers. It transfers the spatial information in the low-level feature map at the encoding stage to each decoding stage through the jump connection, improves the information utilization of the spatial context, and, thus, increases the pixel location of the semantic category.
- (3)
- We designed a Pooling Context Aggregation Module (PCAM) consisting of a combination of different pooling operations and dilation convolution. It cooperates with the encoder to capture different contexts in the high-level feature graph, thereby creating rich semantic contextual information for pixel classification.
2. Related Work
2.1. Semantic Context Information
2.2. Spatial Context Information
3. Methodology
3.1. Overview
3.2. Spatial Context Module
3.3. Pooling Context Aggregation Module
4. Experimental Results
4.1. Datasets and Experimental Settings
4.1.1. PASCAL VOC2012
4.1.2. Cityscapes
4.1.3. ADE20K MIT
4.1.4. Experimental Settings
4.2. Ablation Experiments with MPCNet
4.2.1. Ablation Experiment for PCAM
4.2.2. Ablation Experiment for SCM
4.3. Segmentation Performances and Comparisons
4.3.1. PASCAL VOC2012
4.3.2. Cityscapes
4.3.3. ADE20K
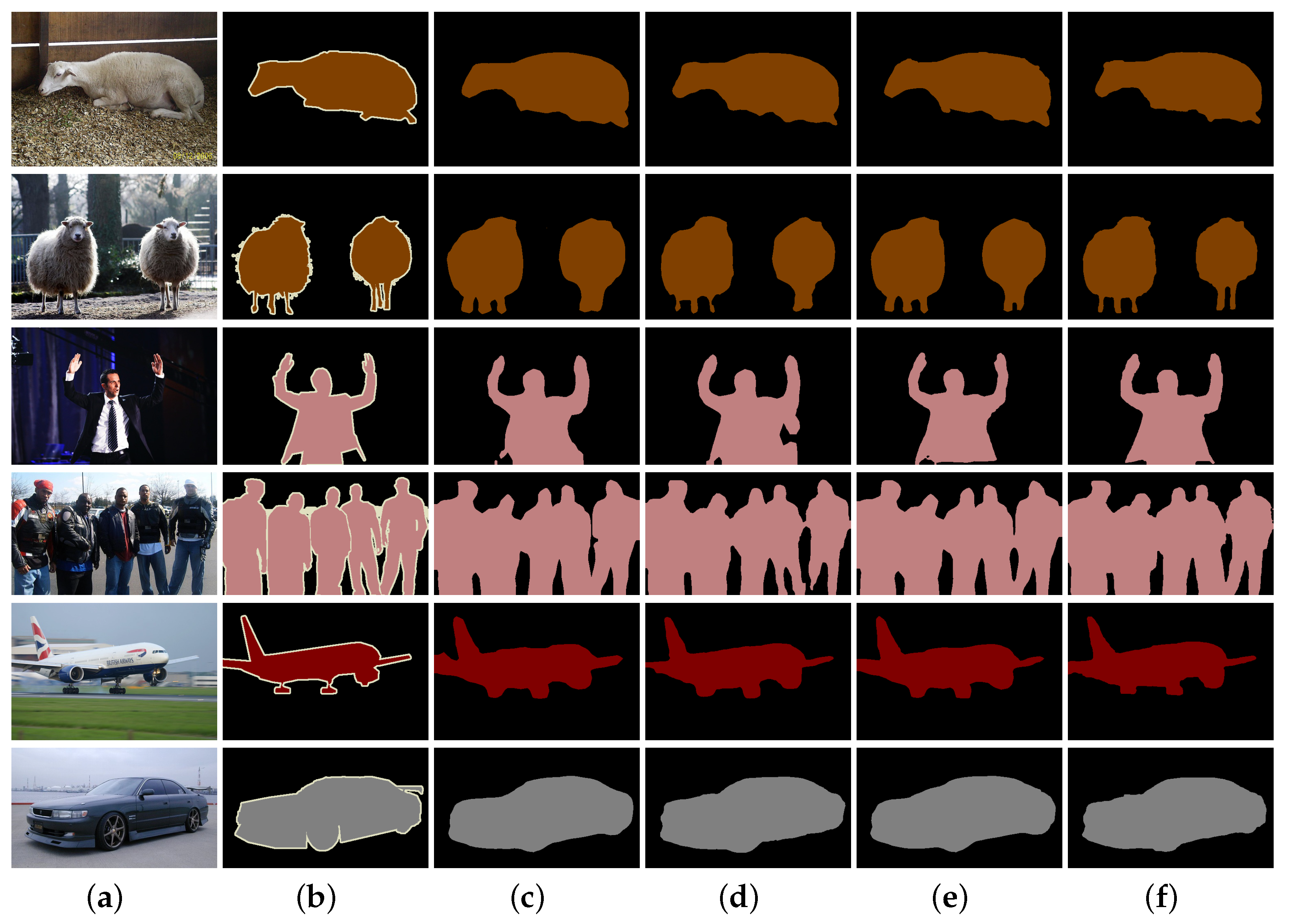
4.4. Visual Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Liu, Y.; Cui, Z.; Yang, F.; Zhao, Y.; Lian, C.; Gao, C. Semantic graph attention with explicit anatomical association modeling for tooth segmentation from CBCT images. IEEE Trans. Med. Imaging 2022, 41, 3116–3127. [Google Scholar] [CrossRef] [PubMed]
- Song, J.; Chen, X.; Zhu, Q.; Shi, F.; Xiang, D.; Chen, Z.; Fan, Y.; Pan, L.; Zhu, W. Global and local feature reconstruction for medical image segmentation. IEEE Trans. Med. Imaging 2022, 41, 2273–2284. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Du, Y.; Fan, H.; Ma, C. Towards collaborative appearance and semantic adaptation for medical image segmentation. Neurocomputing 2022, 491, 633–643. [Google Scholar] [CrossRef]
- Dai, Y.; Zheng, T.; Xue, C.; Zhou, L. SegMarsViT: Lightweight mars terrain segmentation network for autonomous driving in planetary exploration. Remote. Sens. 2022, 14, 6297. [Google Scholar] [CrossRef]
- Li, X.; Zhao, Z.; Wang, Q. ABSSNet: Attention-based spatial segmentation network for traffic scene understanding. IEEE Trans. Cybern. 2021, 52, 9352–9362. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, Y.; Li, X. Multi-stage context refinement network for semantic segmentation. Neurocomputing 2023, 535, 53–63. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Liu, B.; Hu, J.; Bi, X.; Li, W.; Gao, X. PGNet: Positioning guidance network for semantic segmentation of very-high-resolution remote sensing images. Remote. Sens. 2022, 14, 4219. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and transformer network for crop segmentation of remote sensing images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Nie, J.; Zheng, C.; Wang, C.; Zuo, Z.; Lv, X.; Yu, S.; Wei, Z. Scale–Relation joint decoupling network for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Dong, Y.; Jiang, Z.; Tao, F.; Fu, Z. Multiple spatial residual network for object detection. Complex Intell. Syst. 2022, 9, 1–16. [Google Scholar] [CrossRef]
- Dong, Y.; Tan, W.; Tao, D.; Zheng, L.; Li, X. CartoonLossGAN: Learning surface and coloring of images for cartoonization. IEEE Trans. Image Process. 2021, 31, 485–498. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Yang, H.; Pei, Y.; Shen, L.; Zheng, L.; Li, P. Compact interactive dual-branch network for real-time semantic segmentation. Complex Intell. Syst. 2023, 2023, 1–11. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, X.; Zha, Z.J.; Zeng, W. Context-reinforced semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4046–4055. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, H.; Zhang, H.; Wang, C.; Xie, J. Co-occurrent features in semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 548–557. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Fu, J.; Liu, J.; Li, Y.; Bao, Y.; Yan, W.; Fang, Z.; Lu, H. Contextual deconvolution network for semantic segmentation. Pattern Recognit. 2020, 101, 107152. [Google Scholar] [CrossRef]
- Geng, Q.; Zhang, H.; Qi, X.; Huang, G.; Yang, R.; Zhou, Z. Gated path selection network for semantic segmentation. IEEE Trans. Image Process. 2021, 30, 2436–2449. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, W.; Wang, M.; Kang, M.; Weise, T.; Wang, X.; Tan, M.; Xu, L.; Li, X.; Zhang, C. LightFGCNet: A aightweight and focusing on global context information semantic segmentation network for remote sensing imagery. Remote Sens. 2022, 14, 6193. [Google Scholar] [CrossRef]
- Ma, H.; Yang, H.; Huang, D. Boundary guided context aggregation for semantic segmentation. arXiv 2021, arXiv:2110.14587. [Google Scholar]
- Yang, Y.; Dong, J.; Wang, Y.; Yu, B.; Yang, Z. DMAU-Net: An Attention-Based Multiscale Max-Pooling Dense Network for the Semantic Segmentation in VHR Remote-Sensing Images. Remote Sens. 2023, 15, 1328. [Google Scholar] [CrossRef]
- Hang, R.; Yang, P.; Zhou, F.; Liu, Q. Multiscale progressive segmentation network for high-resolution remote sensing imagery. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Lin, Z.; Sun, W.; Tang, B.; Li, J.; Yao, X.; Li, Y. Semantic segmentation network with multi-path structure, attention reweighting and multi-scale encoding. Vis. Comput. 2023, 39, 597–608. [Google Scholar] [CrossRef]
- De Souza Brito, A. Combining max-pooling and wavelet pooling strategies for semantic image segmentation. Expert Syst. Appl. 2021, 183, 115403. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 323–339. [Google Scholar]
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.; Saenko, K.; Sclaroff, S. Real-time semantic segmentation with fast attention. IEEE Robot. Autom. Lett. 2020, 6, 263–270. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Li, Z.; Sun, Y.; Zhang, L.; Tang, J. CTNet: Context-based tandem network for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9904–9917. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 March 2018; pp. 801–818. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Yang, K. Gff: Gated fully fusion for semantic segmentation. arXiv 2019, arXiv:1904.01803. [Google Scholar]
- Kim, T.; Kim, J.; Kim, D. SpaceMeshLab: Spatial context memoization and meshgrid atrous convolution consensus for semantic segmentation. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AL, USA, 19–22 September 2021; pp. 2259–2263. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Semantic segmentation with context encoding and multi-path decoding. IEEE Trans. Image Process. 2020, 29, 3520–3533. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y.; Hong, R.; Cheng, J.; Wang, M. Real-Time semantic segmentation via spatial-detail guided context propagation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 2022, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tan, S.; Tong, Y. Semantic flow for fast and accurate scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 775–793. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Shen, L.; Pei, Y.; Yang, H.; Li, X. Field-matching attention network for object detection. Neurocomputing 2023, 535, 123–133. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 18–20 June 2020; pp. 4003–4012. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Zhou, Z.; Zhou, Y.; Wang, D.; Mu, J.; Zhou, H. Self-attention feature fusion network for semantic segmentation. Neurocomputing 2021, 453, 50–59. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PA (%) | mIOU (%) | |||
|---|---|---|---|---|---|
| ResNet101 | 90.77 | 71.25 | |||
| ResNet101 | ✓ | ✓ | 94.76 | 77.88 | |
| ResNet101 | ✓ | 94.27 | 77.56 | ||
| ResNet101 | ✓ | ✓ | ✓ | 95.81 | 78.05 |
| Method | BaseNet | PPM | ASPP | MPM | PCAM | PA (%) | mIOU (%) |
|---|---|---|---|---|---|---|---|
| MPCNet | ResNet101 | ✓ | 94.56 | 76.43 | |||
| MPCNet | ResNet101 | ✓ | 95.15 | 77.68 | |||
| MPCNet | ResNet101 | ✓ | 95.01 | 77.21 | |||
| MPCNet | ResNet101 | ✓ | 97.92 | 78.24 |
| Method | SPM | SCM | PA (%) | mIOU (%) |
|---|---|---|---|---|
| ResNet101 | 90.77 | 71.25 | ||
| ResNet101 | ✓ | 94.76 | 75.58 | |
| ResNet101 | ✓ | 96.21 | 76.74 |
| Method | BaseNet | PA (%) | mIOU (%) |
|---|---|---|---|
| FCN [15] | ResNet101 | 88.73 | 62.20 |
| DeepLab [50] | ResNet101 | 92.84 | 78.51 |
| PSPNet [31] | ResNet101 | 93.11 | 82.60 |
| DeepLabv3+ [33] | ResNet101 | 93.78 | 80.57 |
| Denseaspp [51] | ResNet101 | 93.68 | 75.27 |
| ANN [54] | ResNet101 | 93.20 | 72.79 |
| DANet [56] | ResNet101 | 93.38 | 80.40 |
| OCRNet [53] | ResNet101 | 93.47 | 74.69 |
| OCNet [52] | ResNet101 | 93.80 | 75.55 |
| SA-FFNet [55] | ResNet101 | 93.84 | 76.42 |
| MPCNet (ours) | ResNet101 | 94.83 | 77.48 |
| Method | BaseNet | PA (%) | mIOU (%) |
|---|---|---|---|
| FCN [15] | ResNet101 | 94.85 | 66.61 |
| DeepLab[50] | ResNet101 | 95.78 | 79.30 |
| PSPNet [31] | ResNet101 | 96.49 | 78.40 |
| DeepLabv3+ [33] | ResNet101 | 96.66 | 79.55 |
| Denseaspp [51] | ResNet101 | 95.85 | 80.60 |
| ANN [54] | ResNet101 | 95.16 | 81.30 |
| DANet [56] | ResNet101 | 95.45 | 81.50 |
| OCRNet [53] | ResNet101 | 95.29 | 81.80 |
| OCNet [52] | ResNet101 | 96.53 | 81.40 |
| SA-FFNet [55] | ResNet101 | 96.25 | 73.13 |
| MPCNet (ours) | ResNet101 | 97.92 | 78.24 |
| Method | BaseNet | PA (%) | mIOU (%) |
|---|---|---|---|
| FCN [15] | ResNet101 | 76.32 | 29.47 |
| SegNet [57] | ResNet101 | 68.59 | 21.63 |
| DeepLab[50] | ResNet101 | 80.26 | 33.87 |
| PSPNet [31] | ResNet101 | 81.56 | 41.68 |
| DeepLabv3+ [33] | ResNet101 | 82.31 | 36.42 |
| Denseaspp [51] | ResNet101 | 81.75 | 34.55 |
| ANN [54] | ResNet101 | 81.37 | 45.24 |
| DANet [56] | ResNet101 | 82.27 | 36.33 |
| OCRNet [53] | ResNet101 | 81.88 | 45.28 |
| OCNet [52] | ResNet101 | 82.10 | 45.04 |
| MPCNet (ours) | ResNet101 | 82.55 | 38.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Dong, Y.; Jiang, Z.; Pei, Y.; Zheng, B.; Zheng, L.; Fu, Z. Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sens. 2023, 15, 2800. https://doi.org/10.3390/rs15112800
Liu Q, Dong Y, Jiang Z, Pei Y, Zheng B, Zheng L, Fu Z. Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sensing. 2023; 15(11):2800. https://doi.org/10.3390/rs15112800
Chicago/Turabian StyleLiu, Qing, Yongsheng Dong, Zhiqiang Jiang, Yuanhua Pei, Boshi Zheng, Lintao Zheng, and Zhumu Fu. 2023. "Multi-Pooling Context Network for Image Semantic Segmentation" Remote Sensing 15, no. 11: 2800. https://doi.org/10.3390/rs15112800
APA StyleLiu, Q., Dong, Y., Jiang, Z., Pei, Y., Zheng, B., Zheng, L., & Fu, Z. (2023). Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sensing, 15(11), 2800. https://doi.org/10.3390/rs15112800