
MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification




Abstract
:1. Introduction
2. Methodology
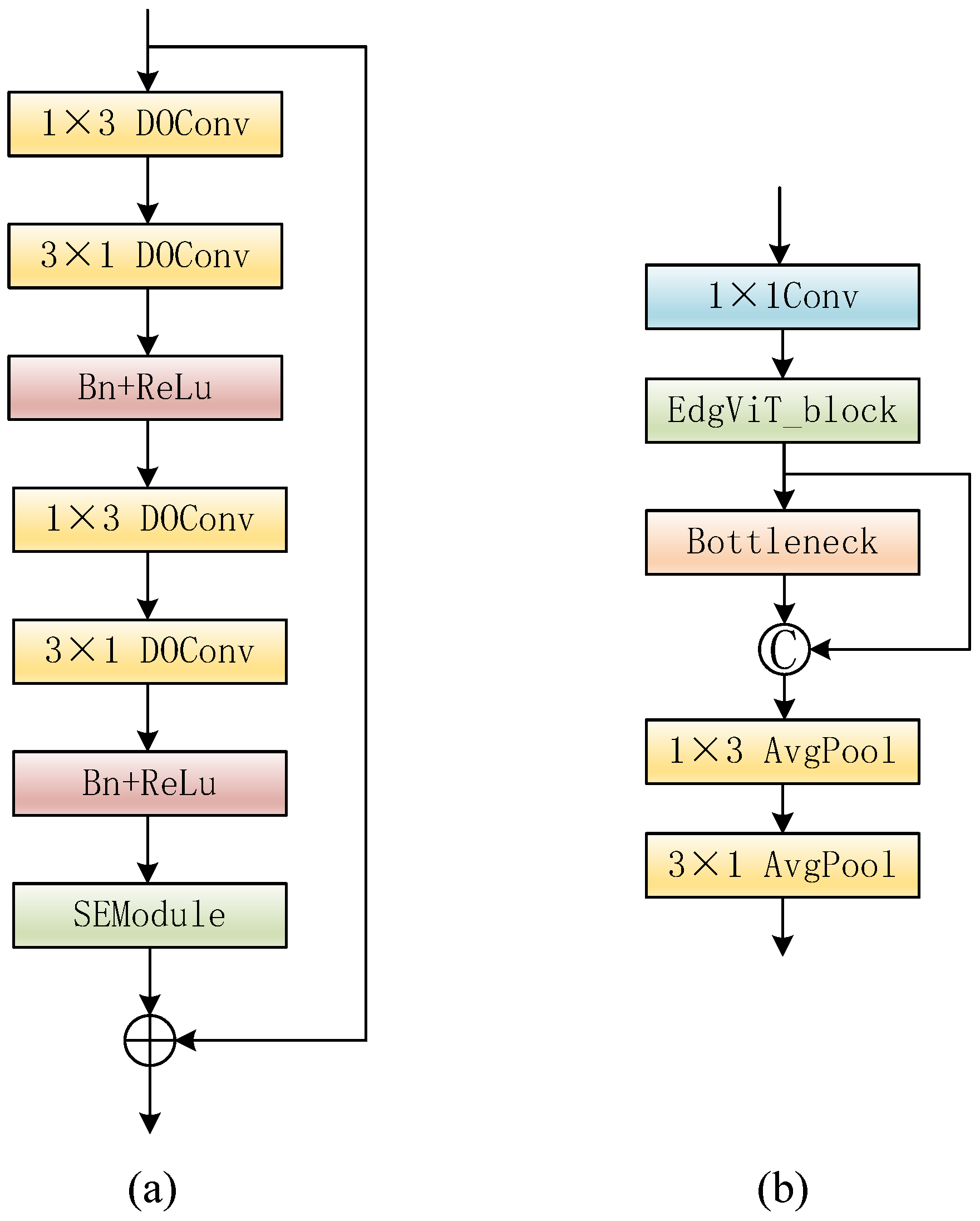
2.1. Network Architecture
2.2. Backbone
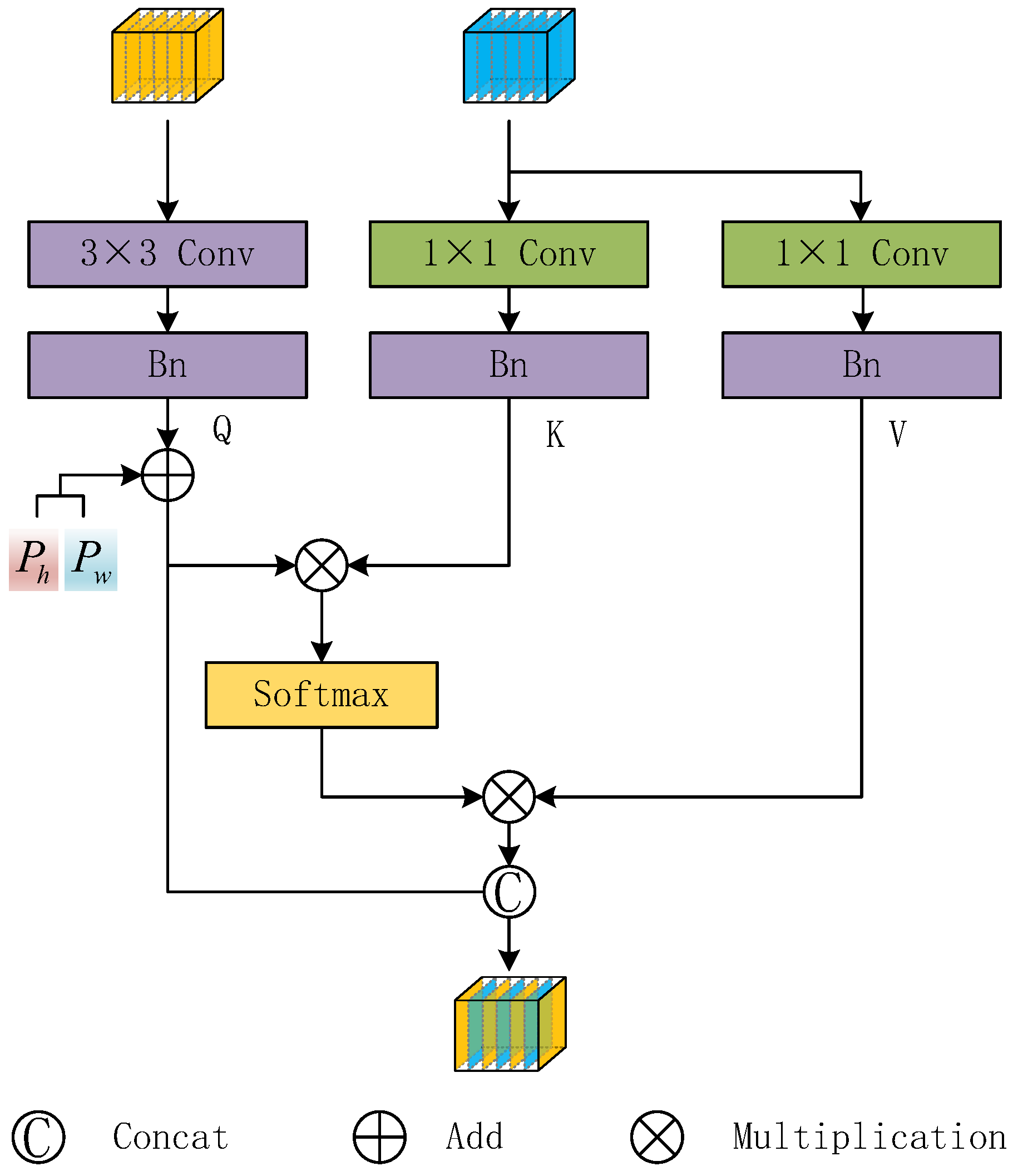
2.3. Semantic Information Guidance Module
2.4. Multi-Scale Fusion Module
2.5. Experimental Details and Evaluation Metrics
3. Experiment
3.1. Datasets
3.1.1. LandCover Dataset
3.1.2. Wuhan Dense Labeling Dataset (WHDLD)
3.2. Ablation Study
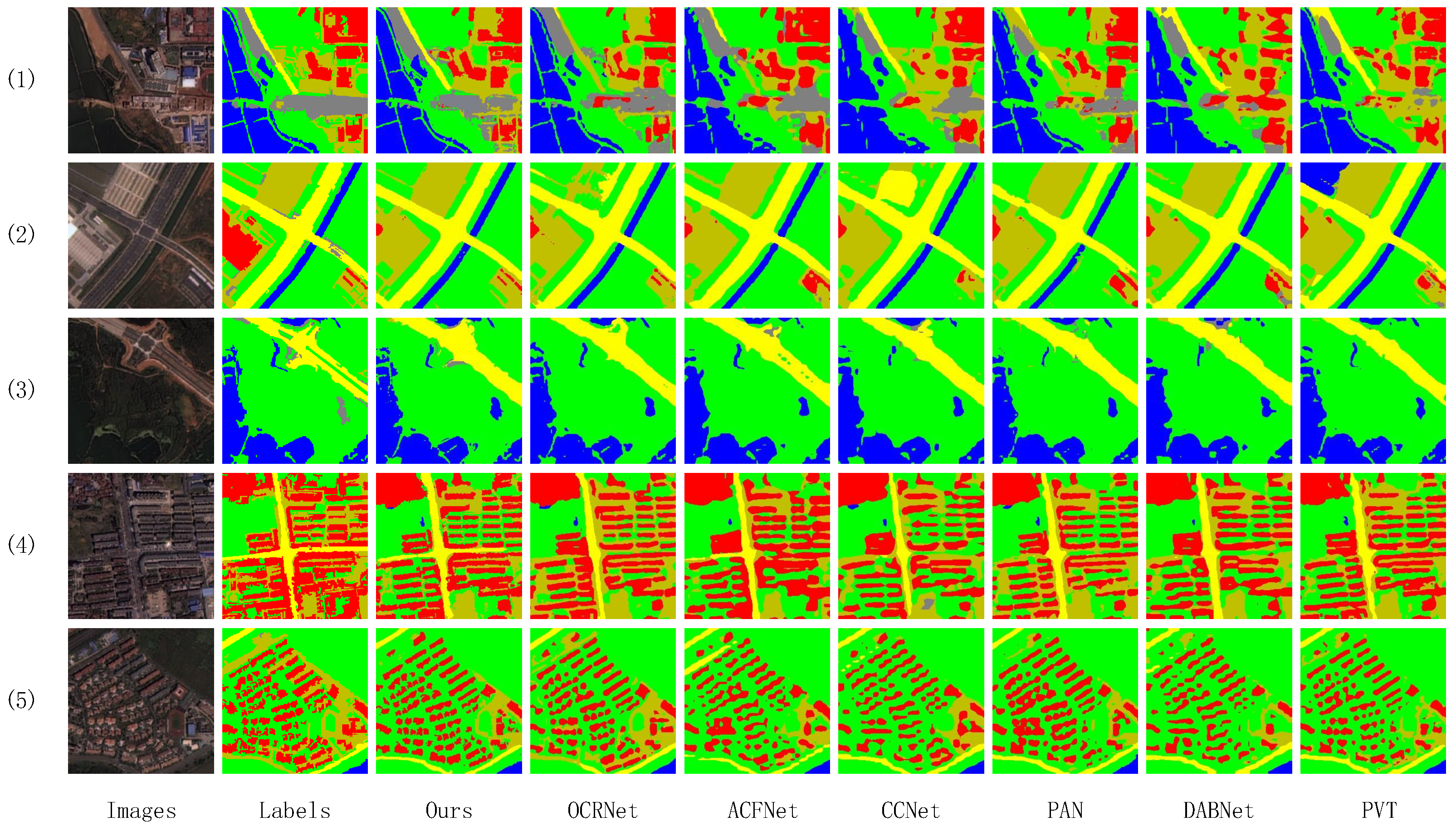
3.3. Comparison Test on the LandCover Dataset
3.4. Comparison Test on the WHDLD Dataset
4. Discussion
4.1. About the Model
4.2. About the Experiments
4.3. Limitations and Future Research Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. FENet: Feature enhancement network for land cover classification. Int. J. Remote Sens. 2023, 44, 1702–1725. [Google Scholar] [CrossRef]
- Chu, S.; Li, P.; Xia, M. MFGAN: Multi feature guided aggregation network for remote sensing image. Neural Comput. Appl. 2022, 34, 10157–10173. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Hu, K.; Li, M.; Xia, M.; Lin, H. Multi-Scale Feature Aggregation Network for Water Area Segmentation. Remote Sens. 2022, 14, 206. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Wang, D.; Weng, L.; Xia, M.; Lin, H. MBCNet: Multi-Branch Collaborative Change-Detection Network Based on Siamese Structure. Remote Sens. 2023, 15, 2237. [Google Scholar] [CrossRef]
- Toll, D.L. Analysis of digital LANDSAT MSS and SEASAT SAR data for use in discriminating land cover at the urban fringe of Denver, Colorado. Int. J. Remote Sens. 1985, 6, 1209–1229. [Google Scholar] [CrossRef]
- Jewell, N. An evaluation of multi-date SPOT data for agriculture and land use mapping in the United Kingdom. Int. J. Remote Sens. 1989, 10, 939–951. [Google Scholar] [CrossRef]
- Zhang, F.; Yang, X. Improving land cover classification in an urbanized coastal area by random forests: The role of variable selection. Remote Sens. Environ. 2020, 251, 112105. [Google Scholar] [CrossRef]
- Paneque-Gálvez, J.; Mas, J.F.; Moré, G.; Cristóbal, J.; Orta-Martínez, M.; Luz, A.C.; Guèze, M.; Macía, M.J.; Reyes-García, V. Enhanced land use/cover classification of heterogeneous tropical landscapes using support vector machines and textural homogeneity. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 372–383. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, D.; Li, R. Remote sensing image segmentation by combining spectral and texture features. IEEE Trans. Geosci. Remote Sens. 2013, 52, 16–24. [Google Scholar] [CrossRef]
- Xu, J.; Li, J.; Peng, H.; He, Y.; Wu, B. Information Extraction from High-Resolution Remote Sensing Images Based on Multi-Scale Segmentation and Case-Based Reasoning. Photogramm. Eng. Remote Sens. 2022, 88, 199–205. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, Q.; Xu, J. Coastline extraction using support vector machine from remote sensing image. J. Multimed. 2013, 8, 175–182. [Google Scholar]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover. ai: Dataset for automatic mapping of buildings, woodlands, water and roads from aerial imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1102–1110. [Google Scholar]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Qian, M. Multi-Scale Location Attention Network for Building and Water Segmentation of Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2023. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Zhang, S.; Weng, L. STPGTN—A Multi-Branch Parameters Identification Method Considering Spatial Constraints and Transient Measurement Data. Comput. Model. Eng. Sci. 2023, 136, 2635–2654. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Yin, M.; Wang, P.; Ni, C.; Hao, W. Cloud and snow detection of remote sensing images based on improved Unet3+. Sci. Rep. 2022, 12, 14415. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Xia, M.; Weng, L.; Lin, H. Local Feature Search Network for Building and Water Segmentation of Remote Sensing Image. Sustainability 2023, 15, 3034. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-Branch Network for Cloud and Cloud Shadow Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Pang, K.; Weng, L.; Zhang, Y.; Liu, J.; Lin, H.; Xia, M. SGBNet: An ultra light-weight network for real-time semantic segmentation of land cover. Int. J. Remote Sens. 2022, 43, 5917–5939. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, J.; Li, Y.; Sun, M.; Chen, Y.; Lischinski, D.; Cohen-Or, D.; Chen, B.; Tu, C. Do-conv: Depthwise over-parameterized convolutional layer. arXiv 2020, arXiv:2006.12030. [Google Scholar] [CrossRef]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martinez, B. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XI. Springer: Cham, Switzerland, 2022; pp. 294–311. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Cui, Z.; Kerekes, J.P. Potential of red edge spectral bands in future landsat satellites on agroecosystem canopy green leaf area index retrieval. Remote Sens. 2018, 10, 1458. [Google Scholar] [CrossRef]
- Cui, Z.; Kerekes, J. Potential of Red Edge Spectral Bands in Future Landsat Satellites on Agroecosystem Canopy Chlorophyll Content Retrieval. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7168–7171. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6798–6807. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Xia, X.; Li, J.; Wu, J.; Wang, X.; Wang, M.; Xiao, X.; Zheng, M.; Wang, R. TRT-ViT: TensorRT-oriented vision transformer. arXiv 2022, arXiv:2205.09579. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Levels | Modules | Repeated Times | Output Bands | Output Size |
|---|---|---|---|---|
| L1 | 7 × 7 Conv2d | 1 | 64 | 1/2 |
| L2 | RCA | 2 | 128 | 1/4 |
| L3 | RCA | 2 | 256 | 1/8 |
| L4 | CAII | 3 | 512 | 1/16 |
| L5 | CAII | 3 | 512 | 1/32 |
| Methods | MIOU (%) |
|---|---|
| ResNet-18 | 84.462 |
| Backbone | 85.500 |
| Backbone + SIG | 86.122 |
| Backbone + SIG + MSF | 87.432 |
| Methods | MPA (%) | MIOU (%) | FWIOU (%) |
|---|---|---|---|
| CVT [50] | 88.279 | 78.824 | 86.761 |
| DeepLabV3Plus [35] | 87.713 | 79.260 | 84.421 |
| PAN [57] | 90.665 | 81.210 | 87.399 |
| ACFNet [55] | 91.689 | 83.081 | 88.263 |
| OCRNet [52] | 92.739 | 83.240 | 88.565 |
| PVT [51] | 91.998 | 83.520 | 87.965 |
| CCNet [56] | 93.162 | 84.194 | 89.235 |
| DABNet [53] | 93.316 | 84.444 | 89.112 |
| CGNet [54] | 93.692 | 85.546 | 89.838 |
| Ours | 94.563 | 87.432 | 91.103 |
| Methods | MPA (%) | MIOU (%) | FWIOU (%) |
|---|---|---|---|
| CVT | 69.219 | 55.062 | 76.267 |
| CGNet | 74.161 | 62.003 | 80.748 |
| PVT | 74.105 | 62.056 | 81.055 |
| DABNet | 75.049 | 62.155 | 81.012 |
| PAN | 75.796 | 62.267 | 81.354 |
| CCNet | 75.324 | 62.455 | 81.182 |
| ACFNet | 76.268 | 62.864 | 81.650 |
| DeepLabV3Plus | 76.060 | 63.441 | 81.982 |
| OCRNet | 75.802 | 63.569 | 82.291 |
| Ours | 76.122 | 64.243 | 83.121 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Zhang, E.; Dai, X.; Xia, M.; Zhou, F.; Weng, L.; Lin, H. MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification. Remote Sens. 2023, 15, 2810. https://doi.org/10.3390/rs15112810
Hu K, Zhang E, Dai X, Xia M, Zhou F, Weng L, Lin H. MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification. Remote Sensing. 2023; 15(11):2810. https://doi.org/10.3390/rs15112810
Chicago/Turabian StyleHu, Kai, Enwei Zhang, Xin Dai, Min Xia, Fenghua Zhou, Liguo Weng, and Haifeng Lin. 2023. "MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification" Remote Sensing 15, no. 11: 2810. https://doi.org/10.3390/rs15112810
APA StyleHu, K., Zhang, E., Dai, X., Xia, M., Zhou, F., Weng, L., & Lin, H. (2023). MCSGNet: A Encoder–Decoder Architecture Network for Land Cover Classification. Remote Sensing, 15(11), 2810. https://doi.org/10.3390/rs15112810