
MV-CDN: Multi-Visual Collaborative Deep Network for Change Detection of Double-Temporal Hyperspectral Images



Abstract
:
1. Introduction
2. Related Work
3. Materials and Methods
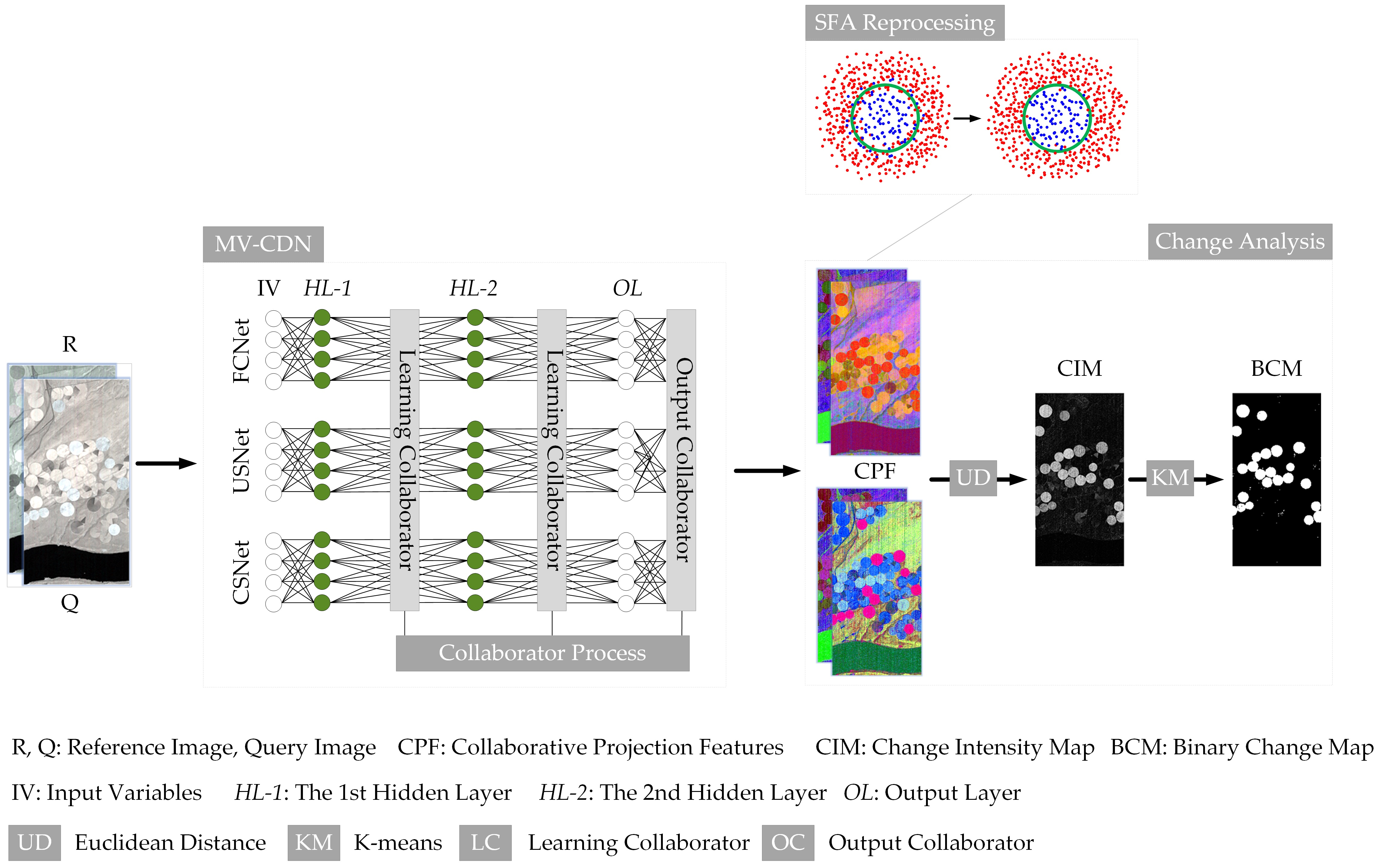
- This section describes the procedure of the proposed schema, which is composed of four modules: the MV-CDN module, the collaborator module, the SFA reprocessing module, and the change analysis model.
- The MV-CDN consists of three subdivision approaches: CDN-C, CDN-2C, and CDN-3C, with CDN-C denoting the CDN with one collaborator on the OL, CDN-2C denoting the CDN with two collaborators on the OL and HL-2, and CDN-3C denoting the CDN with three collaborators on the OL, HL-2, and HL-1.
- We first feed the double-channel MV-CDN with symmetric training pixels X and Y, which are selected from specific areas of the pre-detected binary change map (BCM) obtained from DSFA [25] with SFA reprocessing omitted, and the specific areas are detailed in the experiment section. The MV-CDN model could be well-trained following Section 3.1 and Section 3.2 under the hyperparameter settings in the experimental section. In the deep learning process, three light-weight collaborative network members, FCNet [25], USNet [26], and CSNet [26], are employed to serve the MV-CDN; the SFA algorithm is applied to construct the loss function for extracting invariance features. As the central idea of this paper, collaborators are utilized to translate the group-thinking of the collaborative network members into a more robust field of vision.
- The collaborators carried by different network layers of the three subdivision approaches are shown in Table 1, where OC denotes the output collaborator and LC denotes the learning collaborator.
- Figure 1 shows the procedure of the proposed schema for detecting the changes of double-temporal hyperspectral images. Given the reference image denoted by R and query image denoted by Q, we reshape both into N × 1 × B-dimensional data, with N and B respectively denoting the number of pixels and the band number of an image. Note that N is equivalent to H × W, with H and W respectively representing the height and width of the image. All paired pixels will pass the well-trained model to obtain the CPF with a spatial dimension of H × W × b, with b denoting the number of feature bands. Next, the SFA reprocessing module is employed to further inhibit the unchanged features and enhance the changed features of the spatial data model of N × 1 × b. Finally, in the change-analysis module, the Euclidean distance [34] and K-means [28] algorithms are successively applied to compute the change-intensity map and the final binary change map.

3.1. Architecture and Training Process of Proposed MV-CDN
3.2. Collaborator Process
3.3. SFA Reprocessing
3.4. Change Analysis
| Algorithm 1 Pseudocode of proposed schema for change detection of double-temporal hyperspectral images |
| Input: Double-temporal scene images R and Q; |
| Output: Detected binary change map (BCM); |
| 1: Select training samples X and Y based on BCM of pre-detection; |
| 2: Initialize parameters of MV-CDN as ; |
| 3: Configuration of epoch number, learning rate, sample size, etc.; |
| 4: Case CDN-C: |
| 5: Apply OC on OL; |
| 6: Go to line 13; |
| 7: Case CDN-2C: |
| 8: Apply OC on OL, and LC on HL-2; |
| 9: Go to line 13; |
| 10: Case CDN-3C: |
| 11: Apply OC on OL, and LC on HL-2& HL-1; |
| 12: Go to line 13; |
| 13: while i < epochs do |
| 14: Compute the double-temporal projection features of pair-wise samples X and Y: = f (X, ) and = f (Y, ); |
| 15: Compute the gradient of loss function ( ) = with L )/ and L ( )/; |
| 16: Update parameters; |
| 17: i++; |
| 18: end |
| 19: Generate the double-temporal projection features and of images R and Q; |
| 20: SFA reprocessing is applied to the CPF to generate the pair-wise data with: , ; |
| 21: Euclidean distance is used for the calculation of CIM; |
| 22: K-means is applied to obtain the BCM; |
| 23: return BCM; |
4. Results
4.1. Measurement Coefficients
4.2. Comparison with State-of-the-Art Work
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Z.; Wu, Z.; Chen, Y.; Yang, Z.; Marinello, F. Exploration of eco-environment and urbanization changes in coastal zones: A case study in China over the past 20 years. Ecol. Indic. 2020, 119, 106847. [Google Scholar] [CrossRef]
- Yao, K.; Halike, A.; Chen, L.; Wei, Q. Spatiotemporal changes of eco-environmental quality based on remote sensing-based ecological index in the Hotan Oasis, Xinjiang. J. Arid. LandIssue 2022, 14, 262–283. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: An UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. SPRS J. Photogramm. Remote Sens. 2021, 190, 196–214. [Google Scholar] [CrossRef]
- Rahman, A.; Aggarwal, S.P.; Netzband, M.; Fazal, S. Monitoring urban sprawl using remote sensing and GIS techniques of a fast growing urban centre, India. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 4, 56–64. [Google Scholar] [CrossRef]
- Cao, C.; Dragićević, S.; Li, S. Land-use change detection with convolutional neural network methods. Environments 2019, 6, 25. [Google Scholar] [CrossRef]
- Alhassan, V.; Henry, C.; Ramanna, S.; Storie, C. A deep learning framework for land-use/land-cover mapping and analysis using multispectral satellite imagery. Neural Comput. Appl. 2020, 32, 8529–8544. [Google Scholar] [CrossRef]
- Wei, Z.; Gu, X.; Sun, Q.; Hu, X.; Gao, Y. Analysis of the Spatial and Temporal Pattern of Changes in Abandoned Farmland Based on Long Time Series of Remote Sensing Data. Remote Sens. 2021, 13, 2549. [Google Scholar] [CrossRef]
- Sofia, G.; Bailly, J.-S.; Chehata, N.; Tarolli, P.; Levavasseur, F. Comparison of pleiades and LiDAR digital elevation models for terraces detection in farmlands. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1567–1576. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, C.; Meng, Y.; Chen, J.; Yue, A. Landslide Monitoring Using Change Detection in Multitemporal Optical Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 312–316. [Google Scholar] [CrossRef]
- Lê, T.T.; Froger, J.-L.; Minh, D.H.T. Multiscale framework for rapid change analysis from SAR image time series: Case study of flood monitoring in the central coast regions of Vietnam. Remote Sens. Environ. 2022, 269, 112837. [Google Scholar] [CrossRef]
- Liu, D.; Chen, W.; Menz, G.; Dubovyk, O. Development of integrated wetland change detection approach: In case of Erdos Larus Relictus National Nature Reserve, China. Sci. Total Environ. 2020, 731, 139166. [Google Scholar] [CrossRef]
- Li, Y.; Dong, H.; Li, H.; Zhang, X.; Zhang, B. Multi-block SSD based on small object detection for UAV railway scene surveillance. Chin. J. Aeronaut. 2020, 33, 1747–1755. [Google Scholar] [CrossRef]
- Zhu, Y.; Jia, Z.; Yang, J.; Kasabov, N.K. Change detection in multitemporal monitoring images under low illumination. IEEE Access 2020, 8, 126700–126712. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, H.; Wu, M.; Wu, C. Extended Motion Diffusion-Based Change Detection for Airport Ground Surveillance. IEEE Trans. Image Process. 2020, 29, 5677–5686. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral Change Detection Based on Multiple Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5507312. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, D.; Sha, J.; Gao, L.; Liu, L.; Zhang, Y.; Rong, X. Spectral–spatial–temporal transformers for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536814. [Google Scholar] [CrossRef]
- Afaq, Y.; Manocha, A. Analysis on change detection techniques for remote sensing applications: A review. Ecol. Inform. 2021, 63, 101310. [Google Scholar] [CrossRef]
- Zhou, S.Q.; Schoellig, A.P. An Analysis of the Expressiveness of Deep Neural Network Architectures Based on Their Lipschitz Constants. arXiv 2019, arXiv:1912.11511. [Google Scholar]
- Jeong, Y.S.; Byon, Y.J.; Castro-Neto, M.M.; Easa, S.M. Supervised Weighting-Online Learning Algorithm for Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1700–1707. [Google Scholar] [CrossRef]
- Blanchart, P.; Datcu, M. A Semi-Supervised Algorithm for Auto-Annotation and Unknown Structures Discovery in Satellite Image Databases. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 3, 698–717. [Google Scholar] [CrossRef]
- Xu, J.; Zhao, R.; Yu, Y.; Zhang, Q.; Bian, X.; Wang, J.; Ge, Z.; Qian, D. Real-time automatic polyp detection in colonoscopy using feature enhancement module and spatiotemporal similarity correlation unit. Biomed. Signal Process. Control. 2022, 66, 102503. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Li, L.; Zhao, T.; Zhang, N.; Tian, J. SEFEPNet: Scale Expansion and Feature Enhancement Pyramid Network for SAR Aircraft Detection with Small Sample Dataset. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3365–3375. [Google Scholar] [CrossRef]
- Qu, L.; Huang, S.; Jia, Y.; Li, X. Improved Loss Function-Based Prediction Method of Extreme Temperatures in Greenhouses. arXiv 2021, arXiv:2111.01366. [Google Scholar]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef]
- Li, J.; Yuan, X.; Li, J.; Huang, G.; Li, P.; Feng, L. CD-SDN: Unsupervised Sensitivity Disparity Networks for Hyper-Spectral Image Change Detection. Remote Sens. 2022, 14, 4806. [Google Scholar] [CrossRef]
- Li, J.; Yuan, X.; Feng, L. Alteration Detection of Multispectral/Hyperspectral Images Using Dual-Path Partial Recurrent Networks. Remote Sens. 2021, 13, 4802. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Feng, S.; Fan, Y.; Tang, Y.; Cheng, H.; Zhao, C.; Zhu, Y.; Cheng, C. A Change Detection Method Based on Multi-Scale Adaptive Convolution Kernel Network and Multimodal Conditional Random Field for Multi-Temporal Multispectral Images. Remote Sens. 2022, 14, 5368. [Google Scholar] [CrossRef]
- Yuan, Y.; Lv, H.; Lu, X. Semi-supervised change detection method for multi-temporal hyperspectral images. Neurocomputing 2015, 148, 363–375. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604816. [Google Scholar] [CrossRef]
- Lei, J.; Li, M.; Xie, W.; Li, Y.; Jia, X. Spectral mapping with adversarial learning for unsupervised hyperspectral change detection. Neurocomputing 2021, 465, 71–83. [Google Scholar] [CrossRef]
- Li, Q.; Gong, H.; Dai, H.; Li, C.; Mu, T. Unsupervised Hyperspectral Image Change Detection via Deep Learning Self-generated Credible Labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9012–9024. [Google Scholar] [CrossRef]
- Danielsson, P.-E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Emran, S.M.; Ye, N. Robustness of Chi-square and Canberra distance metrics for computer intrusion detection. Qual. Reliab. Eng. Int. 2002, 18, 19–28. [Google Scholar] [CrossRef]
- Maesschalck, R.D.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Hyperspectral Change Detection Dataset. Available online: https://citius.usc.es/investigacion/datasets/hyperspectral-change-detection-dataset (accessed on 26 February 2023).
- Wang, D.; Gao, T.; Zhang, Y. Image Sharpening Detection Based on Difference Sets. IEEE Access 2020, 8, 51431–51445. [Google Scholar] [CrossRef]
- De Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change detection of deforestation in the Brazilian Amazon using landsat data and convolutional neural networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Collaborator | CDN-C | CDN-2C | CDN-3C |
|---|---|---|---|
| HL-1 | × | × | LC |
| HL-2 | × | LC | LC |
| OL | OC | OC | OC |
| Settings | Activation Function | Nodes | Double-Cycle | Dropout | |
|---|---|---|---|---|---|
| FCNet | IV | N/A | B | N/A | N/A |
| HL-1 | 128 | × | 0 | ||
| HL-2 | 128 | × | |||
| OL | 6 | × | |||
| USNet | IV | N/A | B | N/A | N/A |
| HL-1 | 128 | × | 0.2 | ||
| HL-2 | 128 | √ | |||
| OL | 10 | × | |||
| CSNet | IV | N/A | B | N/A | N/A |
| HL-1 | 128 | √ | 0.2 | ||
| HL-2 | 128 | × | |||
| OL | 10 | × | |||
| Results | TP | TN | FP | FN | OA_CHG | OA_UN | OA | Kappa | F1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| DSFA [25] | 9299 | 67,467 | 547 | 687 | 0.9312 | 0.9920 | 0.9842 | 0.9287 | 0.9378 | |
| CD-USNet [26] | 9206 | 67,650 | 364 | 780 | 0.9219 | 0.9946 | 0.9853 | 0.9331 | 0.9415 | |
| CD-CSNet [26] | 9314 | 67,535 | 479 | 672 | 0.9327 | 0.9930 | 0.9852 | 0.9334 | 0.9418 | |
| CD-SDN | CD-SDN-AM [26] | 9195 | 67,674 | 340 | 791 | 0.9208 | 0.9950 | 0.9855 | 0.9338 | 0.9421 |
| CD-SDN-AL [26] | 9346 | 67,632 | 382 | 640 | 0.9359 | 0.9944 | 0.9869 | 0.9407 | 0.9482 | |
| MV-CDN | CDN-C (Proposed) | 9420 | 67,578 | 436 | 566 | 0.9433 | 0.9936 | 0.9872 | 0.9421 | 0.9495 |
| CDN-2C (Proposed) | 9414 | 67,597 | 417 | 572 | 0.9427 | 0.9939 | 0.9873 | 0.9428 | 0.9501 | |
| CDN-3C (Proposed) | 9456 | 67,543 | 471 | 530 | 0.9469 | 0.9931 | 0.9872 | 0.9424 | 0.9497 |
| Results | TP | TN | FP | FN | OA_CHG | OA_UN | OA | Kappa | F1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| DSFA [25] | 43,426 | 79,333 | 1085 | 8708 | 0.8330 | 0.9865 | 0.9261 | 0.8411 | 0.8987 | |
| CD-USNet [26] | 43,442 | 79,580 | 838 | 8692 | 0.8333 | 0.9896 | 0.9281 | 0.8452 | 0.9012 | |
| CD-CSNet [26] | 45,497 | 77,087 | 3331 | 6637 | 0.8727 | 0.9586 | 0.9248 | 0.8406 | 0.9013 | |
| CD-SDN | CD-SDN-AM [26] | 46,532 | 76,838 | 3580 | 5602 | 0.8925 | 0.9555 | 0.9307 | 0.8539 | 0.9102 |
| CD-SDN-AL [26] | 45,481 | 78,892 | 1526 | 6653 | 0.8724 | 0.9810 | 0.9383 | 0.8684 | 0.9175 | |
| MV-CDN | CDN-C (Proposed) | 45,547 | 78,855 | 1563 | 6587 | 0.8737 | 0.9806 | 0.9385 | 0.8689 | 0.9179 |
| CDN-2C (Proposed) | 45,537 | 78,912 | 1506 | 6597 | 0.8735 | 0.9813 | 0.9389 | 0.8697 | 0.9183 | |
| CDN-3C (Proposed) | 45,593 | 78,781 | 1637 | 6541 | 0.8745 | 0.9796 | 0.9383 | 0.8685 | 0.9177 |
| Results | TP | TN | FP | FN | OA_CHG | OA_UN | OA | Kappa | F1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| DSFA [25] | 32,972 | 32,961 | 1250 | 6298 | 0.8396 | 0.9635 | 0.8973 | 0.7955 | 0.8973 | |
| CD-USNet [26] | 32,959 | 33,042 | 1169 | 6311 | 0.8393 | 0.9658 | 0.8982 | 0.7974 | 0.8981 | |
| CD-CSNet [26] | 33,738 | 32,603 | 1608 | 5532 | 0.8591 | 0.9530 | 0.9028 | 0.8062 | 0.9043 | |
| CD-SDN | CD-SDN-AM [26] | 35,717 | 31,815 | 2396 | 3553 | 0.9095 | 0.9300 | 0.9190 | 0.8377 | 0.9231 |
| CD-SDN-AL [26] | 35,632 | 32,422 | 1789 | 3638 | 0.9074 | 0.9477 | 0.9261 | 0.8521 | 0.9292 | |
| MV-CDN | CDN-C (Proposed) | 35,654 | 32,618 | 1593 | 3616 | 0.9079 | 0.9534 | 0.9291 | 0.8581 | 0.9319 |
| CDN-2C (Proposed) | 35,645 | 32,681 | 1530 | 3625 | 0.9077 | 0.9553 | 0.9298 | 0.8596 | 0.9326 | |
| CDN-3C (Proposed) | 35,590 | 32,675 | 1536 | 3680 | 0.9063 | 0.9551 | 0.9290 | 0.8579 | 0.9317 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Yuan, X.; Li, J.; Huang, G.; Feng, L.; Zhang, J. MV-CDN: Multi-Visual Collaborative Deep Network for Change Detection of Double-Temporal Hyperspectral Images. Remote Sens. 2023, 15, 2834. https://doi.org/10.3390/rs15112834
Li J, Yuan X, Li J, Huang G, Feng L, Zhang J. MV-CDN: Multi-Visual Collaborative Deep Network for Change Detection of Double-Temporal Hyperspectral Images. Remote Sensing. 2023; 15(11):2834. https://doi.org/10.3390/rs15112834
Chicago/Turabian StyleLi, Jinlong, Xiaochen Yuan, Jinfeng Li, Guoheng Huang, Li Feng, and Jing Zhang. 2023. "MV-CDN: Multi-Visual Collaborative Deep Network for Change Detection of Double-Temporal Hyperspectral Images" Remote Sensing 15, no. 11: 2834. https://doi.org/10.3390/rs15112834
APA StyleLi, J., Yuan, X., Li, J., Huang, G., Feng, L., & Zhang, J. (2023). MV-CDN: Multi-Visual Collaborative Deep Network for Change Detection of Double-Temporal Hyperspectral Images. Remote Sensing, 15(11), 2834. https://doi.org/10.3390/rs15112834