Abstract
To extract effective features for the terrain classification of hyperspectral remote-sensing images (HRSIs), a spectral fractional-differentiation (SFD) feature of HRSIs is presented, and a criterion for selecting the fractional-differentiation order is also proposed based on maximizing data separability. The minimum distance (MD) classifier, support vector machine (SVM) classifier, K-nearest neighbor (K-NN) classifier, and logistic regression (LR) classifier are used to verify the effectiveness of the proposed SFD feature, respectively. The obtained SFD feature is sent to the full connected network (FCN) and 1-dimensionality convolutional neural network (1DCNN) for deep-feature extraction and classification, and the SFD-Spa feature cube containing spatial information is sent to the 3-dimensionality convolutional neural network (3DCNN) for deep-feature extraction and classification. The SFD-Spa feature after performing the principal component analysis (PCA) on spectral pixels is directly connected with the first principal component of the original data and sent to 3DCNNPCA and hybrid spectral net (HybridSN) models to extract deep features. Experiments on four real HRSIs using four traditional classifiers and five network models have shown that the extracted SFD feature can effectively improve the accuracy of terrain classification, and sending SFD feature to deep-learning environments can further improve the accuracy of terrain classification for HRSIs, especially in the case of small-size training samples.
1. Introduction
Hyperspectral remote-sensing images (HRSIs) contain abundant spatial and spectral information simultaneously. The spectral dimension reveals the spectral curve characteristics of each pixel, while the spatial dimension reveals the spatial characteristics of the ground surface, and the organic fusion of spatial and spectral information is realized by HRSIs [1,2,3]. However, HRSIs have the characteristics of information redundancy and high dimensionality that bring difficulties and challenges to feature extraction and terrain classification [4,5].
For the feature extraction of HRSIs, the dimensionality reduction methods are usually utilized to project the HRSIs’ spectral pixels to a low-dimensionality feature subspace [6,7]. Principal component analysis (PCA) and linear discriminant analysis (LDA) are representative approaches [8,9]. PCA calculates the covariance matrix of the original data, then, the eigenvectors corresponding to the first several largest eigenvalues of the covariance matrix are selected, and the original spectral pixels are projected to the orthogonal subspace supported by these eigenvectors to achieve the feature extraction and dimensionality reduction. LDA projects the original spectral pixels into a low-dimensional subspace, which has the largest between-class scatters and the smallest within-class scatters so that the data have the best separability in the subspace.
In addition to reducing the dimensionality of HRSIs by feature extraction, discriminant features that can enhance the spectral differences of different terrains can also be achieved by other data analysis methods. Bao et al. have demonstrated that the derivatives of the spectral feature of HRSIs can capture the salient features of different land-cover categories, and have shown that in the case of small samples or poor data quality, combining the spectral first-order differentiation rather than second-order differentiation with the original spectral pixel can avoid the curse of dimensionality and improve the recognition rate [10]. Ye et al. extracted the spectral first-order differentiation in HRSIs and then used locality preserving nonnegative matrix factorization (LPNMF) and locality Fisher discrimination analysis (LFDA) to reduce the dimensionality of the original spectral pixel and spectral derivative, respectively, and, finally, performed feature fusion, which can effectively improve the classification performance [11].
At present, fractional differentiation is usually used in spectral analysis to estimate the contents of some elements or ions in soil or vegetation and is rarely used in spectral classification [12]. Lao et al. calculated the fractional differentiation of the soil spectral pixel in visible near-infrared spectroscopy to estimate the soil contents of salt and soluble ions [13]. Hong et al. used fractional differentiation to estimate soil organic carbon (SOC), wherein the spectral parameters derived from different spectral indices based on spectral fractional differentiation are combined to obtain the best estimation accuracy of SOC [14].
In recent years, convolutional neural networks have achieved remarkable results in the terrain classification of HRSIs [15]. Hu et al. applied a 1-dimensionality convolutional neural network (1DCNN) to HRSIs, which only used spectral information without considering spatial information [16]. Zhang et al. used PCA to reduce the dimensionality of spectral pixels and then used a 2-dimensionality convolutional neural network (2DCNN) for feature extraction and classification, which considered the spatial information of HRSIs [17]. To achieve full use of both the spectral and spatial information of HRSIs, Chen et al. used PCA to reduce the dimensionality of spectral pixels and sent the dimensionality-reduced data into a 3-dimensionality convolutional neural network (3DCNN), and, simultaneously, extracted the spatial and spectral deep features of HRSIs [18].
This paper uses fractional differentiation to perform feature extraction on the pixel spectral curves of HRSIs from the aspect of data analysis, because fractional differentiation can retain part of the original characteristics of the data while obtaining the characteristics that express the differences in the data, and the order of the fractional differentiation can change with the different data. In this paper, a spectral fractional-differentiation (SFD) feature of HRSIs is presented, and a criterion for selecting the fractional-differentiation order is also proposed based on maximizing data separability. The minimum distance (MD) classifier, support vector machine (SVM) classifier, K-nearest neighbor (K-NN) classifier, and logistic regression (LR) classifier are used to verify the effectiveness of the proposed SFD feature, respectively. The obtained SFD feature is sent to the full connected network (FCN) [19] and 1DCNN for deep-feature extraction and classification, and the SFD-Spa feature cube containing spatial information is sent to 3DCNN for deep-feature extraction and classification. The SFD-Spa feature after performing PCA on spectral pixels is directly connected with the first principal component of the original data and sent to 3DCNNPCA and hybrid spectral net (HybridSN) [20] models to extract deep features. Compared with integer-order differentiation, the advantage of fractional-order differentiation is that it has memory and globality. When the order of the integer differentiation is just larger than that of fractional differentiation, fractional-order differentiation can preserve more low-frequency components of the signal, while the high- and middle-frequency components are also obviously enhanced [21]. The advantages of the presented HRSIs SFD feature are as follows:
- (1)
- The presented SFD feature preserves both the overall curve shape and local burrs characteristics of the pixel spectral curves of HRSIs, which is very suitable for terrain classification. The overall curve shapes of spectral curves correspond to the low-frequency components and the local burrs correspond to the high-frequency components of the pixel spectral curve. For HRSIs terrain classification, the shape characteristics of spectral curves contribute most to the discriminant of quite different terrains, such as water, soil, and plants; while the local burr characteristics contribute most to the identification of the different terrains which have similar spectral curves, such as wheat and soybean. These two characteristics are both important, however, the integer differentiation invariably enhanced the high-frequency components, i.e., local burrs while losing most of the low-frequency components, i.e., the shape characteristics of spectral curves. Fractional differentiation preserves the low-frequency components sufficiently while amplifying the high-frequency components remarkably, thus, the presented SFD feature contains both the overall curve shape and local burr characteristics of the spectral curves;
- (2)
- The order of the fractional differentiation of the presented SFD feature can be selected by achieving the best separability. With the increase in the differentiation order, the shape characteristics of the original spectral curve are less preserved, while the local burr characteristics are enhanced more significantly. In view of such character, a criterion for selecting the appropriate fractional-differentiation order is presented based on achieving the best data separability, which guarantees that the overall curve shape characteristics and the local burr characteristics are properly preserved in the resulting SFD feature, such that the quite different terrains and the similar terrains are all easy to identify.
Experimental results on four real HRSIs using four traditional classifiers and five network models have shown that the extracted SFD feature can effectively improve the terrain classification accuracy, and sending the SFD feature to deep-learning environments can further improve the terrain classification accuracy, especially in the case of small-size training samples [22,23].
2. Spectral Fractional-Differentiation (SFD) Feature
2.1. Fractional Differentiation
Among the many definitions of fractional differentiation, the commonly used three forms are Riemann–Liouville, Grümwald–Letnikvo, and Caputo [24]. In this paper, the Grümwald–Letnikvo definition is used to generalize the differentiation of continuous functions from integer order to fractional order, and the fractional-order differential expression is deduced by using the difference equation of integer-order differentiation.
According to the definition of integer-order differentiation, for a differentiable function f(x), its g-th integer-order differentiation is
where , the binomial coefficient , is Gamma function, , and h represents the differential step size. Extending the order g to any real number v, the Grümwald–Letnikvo differentiation of f(x) is defined as
where a represents the lower limit of f(x), and [(x − a)/h] represents taking the integer part of (x − a)/h [25].
Fractional differentiation defined in Equation (2) is a generalization of integer differentiation. When the order v is a positive integer, Equation (2) still holds, thus, the integer-order differentiation can be regarded as a special case of the fractional-order differentiation. Fractional differentiation is different from integer differentiation in numerical computing. During the calculation of the integer-order differentiation, the differential result of a point is only related to the information of the nearby points and unrelated to the information of other points; when the fractional differentiation is calculated, the differential result of a point is related to the information of all points before that point, and the points closer to it have greater weights in the calculation, thus, results in that fractional differentiation have memory and globality [25].
2.2. Spectral Fractional-Differentiation (SFD) Feature
The classical integer-order differentiation is a tool to describe the characteristics of the Euclidean space samples and is often utilized for signal extraction and singularity detection in signal analysis and processing. Fractional differentiation is a generalization of integer differentiation. Pu has pointed out that when the fractional-differentiation operation of a signal is performed, the high-frequency and middle-frequency components of the signal will be greatly improved, while the low-frequency components are retained nonlinearly [26]; and with the increase in the differentiation order, the improvement of the high-frequency and middle-frequency components will be enhanced, but fewer low-frequency components will be preserved [27]. In this paper, fractional differentiation is performed on the spectral pixel of HRSIs, and the resulting spectral fractional-differentiation (SFD) feature is used for terrain classification. Since the definition of Grümwald–Letnikvo fractional differentiation is generalized from the definition of integer differentiation and is expressed in discrete form, which is convenient for numerical calculation. Therefore, the presented SFD feature is defined according to the Grümwald–Letnikvo formula.
For a unary function f(x), let the differential step h = 1, then the expression of the v-th order fractional differentiation of f(x) is
which has (t + 1) terms.
For HRSIs, a spectral pixel can be regarded as a discrete form of a unary function. Assuming that each pixel has N spectral bands, for a spectral pixel , the v-th order fractional-differentiation vector of x, i.e., the presented SFD feature, is
where are the first coefficients on the right side of Equation (3) and
The dimensionality of the SFD feature x(v) is , and the components of x(v) correspond to the v-th order fractional differentiation of bands . In particular, when the order v equals 1, the expression of spectral fractional differentiation is the same as that of the first-order differentiation.
2.3. Criterion for Selecting Optimal Fractional-Differentiation Order
In the terrain classification of HRSIs based on the spectral pixel, when there only exist quite different terrains, such as water, soil, and plants, the overall curve shape characteristics of spectral curves, which correspond to the low-frequency components, contribute most to the discriminant. However, the phenomenon of different subjects with similar spectra commonly exists in HRSIs scenes [28,29]; in this case, the local burrs characteristics, which correspond to the high-frequency components, contribute most to the identification. In real HRSIs scenes, the phenomena of different objects with quite different spectra and different subjects with similar spectra both exist. This required that the feature extracted from the spectral curve should properly contain the low-frequency and high-frequency components simultaneously.
Shown in Figure 1 is the amplitude spectrum of the SFD feature of the corn-no-till class in the Indian Pines dataset, where the fractional-differentiation order v varies from 0 to 1.6 with step 0.4, the amplitude spectrum is taken logarithm for observation and the bases of the logarithm is 2. Figure 1 shows that as the fractional-differentiation order increases, the low-frequency components of the amplitude spectra decrease, while the mid-frequency and high-frequency components significantly increase. It can be concluded that the low-order SFD feature can enhance the high-frequency components while sufficiently retaining the low-frequency components of the spectral pixel, which is beneficial for preserving both the overall curve shape characteristics and the local burrs characteristics. However, how to select an appropriate differentiation order is a problem worth considering.
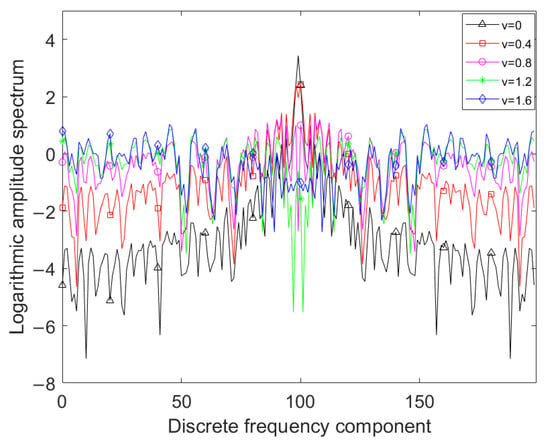
Figure 1.
Amplitude spectra of SFDs with different fractional-differentiation orders.
To study how the presented SFD feature is influenced by the fractional-differentiation order and to select the appropriate SFD order, the spectral curve of the corn-no-till class in the Indian Pines dataset is selected to extract the SFD feature with the fractional-differentiation order varies from 0 to 1.9 at step 0.1, thus, a total of 20 SFD curves are obtained, as shown in Figure 2.

Figure 2.
SFD curves of corn-no-till with fractional-differentiation order varying from 0 to 1.9: (a) = 0~0.4; (b) = 0.5~0.9; (c) = 1~1.4; (d) = 1.5~1.9.
It can be seen intuitively from Figure 2 that, as the differentiation order increases, the SFD values corresponding to the slowly changing parts of the original spectral curve gradually approach 0, and the SFD values corresponding to the local sharply changing parts dramatically increase. When the differentiation order increases from 0 to 1, the SFD curves still retain lots of shape characteristics of the original spectral curve, and the local sharp characteristics are enhanced. When the differentiation order increases from 1 to 1.9, the SFD curves lost most of the shape characteristics of the original spectral curve, and the local sharp characteristics are further enhanced. Therefore, for HRSIs terrain classification, when the differentiation order 0 < v < 1, the presented SFD feature contains the discriminant information benefit for classifying the different objects with quite different spectra and different subjects with similar spectra simultaneously and is very suitable for real HRSIs scenes. However, how to achieve more precise ranges of appropriate differentiation orders for different HRSIs is a problem worth further considering. In this paper, a criterion for selecting the SFD order is proposed based on maximizing the separability.
Assuming that the number of classes is C, let v denote the order of SFD, and the dimensionality of the SFD feature is , the within-class scatter matrix and the between-class scatter matrix in the -dimensionality SFD feature space are
and
, respectively, where ni represents the number of samples of class i, represents the v-th order fractional differentiation of the k-th sample of class i, Pi represents the prior probability of class i, represents the mean of the v-th order fractional differentiations of class i, and represents the overall mean of the v-th order fractional differentiations.
The presented criterion for optimizing SFD order is
where “Tr()” represents the trace of a matrix. The principle of the SFD order selecting criterion is that the data separability should be maximized in the SFD feature space. measures the variance of the class means in the v-th order SFD feature space, the larger is, the greater the between-class separability is. measures the within-class divergence in the v-th order SFD feature space, the smaller the is, the smaller the within-class divergence is. Therefore, J(v) evaluates the data separability in the v-th order SFD feature space, by maximizing J, the data separability in the SFD feature space is maximized, thus, the optimal SFD order is
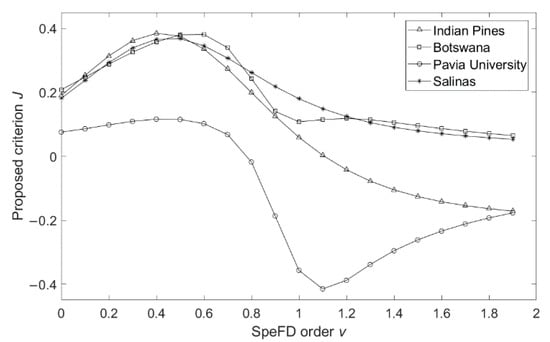
Figure 3.
Comparison of variations of J with SFD order v.
Figure 3 shows that, when the SFD order 0 < v < 1, Botswana, Indian Pines, and Salinas datasets have the same variation trend, they all have obvious peaks as , as the SFD order v increases, the criterion J becomes smaller, which means smaller data separability, this is consistent with the analysis of Figure 1. For the Pavia University dataset, criterion J has an obvious peak as and then decreases with the increase in v, and an inflection point occurs at v = 1.1, but the general trend is still the same as the other three datasets. Therefore, it is confirmed again that the SFD order v ranges between 0 and 1 is more conducive to improving the classification accuracy of HRSIs, and the precise appropriate SFD order range for each dataset is given.
3. Networks Structure and Parameter Settings
To further extract deep features, five network models are used for deep-feature extraction and terrain classification. The five network models used are fully connected network (FCN), one-dimensional convolutional neural network (1DCNN), three-dimensional convolutional neural network (3DCNN), three-dimensional convolutional neural network after spectral PCA dimensionality reduction (3DCNNPCA), and hybrid spectral net (HybridSN). Table 1 and Table 2 show the parameters and the number of output feature maps for each layer of the networks, respectively. N represents the dimension of the input dataset. C represents the number of classes. I, Conv, Po, and FC represent the input layer, convolutional layer, pooling layer, and fully connected layer, respectively. For example, Conv6 indicates that this layer is a convolutional layer located in the sixth layer of the network structure. ”√” means there exists an FC layer. <*> represents rounding up the calculation result.

Table 1.
Parameter settings for five network models.
Table 2.
Number of output feature maps for five network models.
4. Experimental Results
Firstly, using the proposed criterion J to select the appropriate SFD order for each dataset, the selected SFD order for Indian Pines, Botswana, Pavia University, and Salinas are 0.6, 0.3, 0.6, and 0.4, respectively. Additionally, then perform fractional differentiation on the pixel spectral curves with the selected order and achieve the SFD feature. Four traditional classifiers and five networks are used to verify the effectiveness of the resulting SFD feature. Among the five network models, the inputs of FCN and 1DCNN models are SFD feature vectors without spatial information, while the inputs of 3DCNN, 3DCNNPCA, and HybridSN contain spatial information. The input of 3DCNN is the SFD-Spa feature cube, and the input of 3DCNNPCA and HybridSN is the data cube by connecting the SFD-Spa feature after PCA with the first principal component of the original data. To unify the forms, the experimental results on five network models are all represented by “SFD”.
4.1. Experimental Datasets
Four real HRSIs, namely, Indian Pines, Botswana, Pavia University, and Salinas, are used for the experiments. The Indian Pines dataset includes 16 classes, and the image size is 145 145, and a total of 10,249 pixels can be used to classify. After removing the bands 104–108, 150–163, and 220 affected by noise factors, 200 bands were finally left for the experiment. The Botswana dataset was obtained by NASA’s EO-1 satellite in the Botswana area. 14 terrain classes are included, and the image size is 1476 256, and 3248 of them are terrain pixels. After removing the bands affected by noise and water vapor, the bands 10–55, 82–97, 102–119, 134–164, and 187–220 were retained, i.e., a total of 145 bands were finally selected. Pavia University dataset contains 9 classes, the image size is 610 340, including 42,776 terrain pixels, and 103 bands were finally selected. The Salinas dataset has 16 classes, and the image size is 512 217. Bands 108–112, 154–167, and 220 were affected by noise and water vapor and were removed. 204 bands are reserved for research, and a total of 54,129 pixels can be used for terrain classification. Table 3 shows the specific sampling results of the experimental data. Figure 4 and Figure 5 show the false-color image and ground truth of these datasets.
Table 3.
Category number, name, and sample number of each dataset.

Figure 4.
The false-color image of four HRSIs datasets: (a) Indian Pines; (b) Botswana; (c) Pavia University; (d) Salinas.


Figure 5.
The ground truth of four HRSIs datasets: (a) Indian Pines; (b) Botswana; (c) Pavia University; (d) Salinas.
4.2. Classification Results of Traditional Shallow Classifiers
The presented SFD feature will be compared with the spectral (Spe) feature, spectral first-order differential (Spe-1st) feature, and spectral second-order differential (Spe-2nd) feature. The above four features will be further compared through LDA dimensionality reduction to form SFDLDA, SpeLDA, Spe-1stLDA, and Spe-2ndLDA features. The comparison process will be validated using four traditional classifiers, namely, the MD classifier, the SVM classifier, the K-NN classifier, and the LR classifier. For each dataset, 20% of each class data are randomly selected as training samples and the rest as testing samples. Considering the randomness of the experiment, the average overall accuracy (AOA) and standard deviation (SD), average Kappa coefficient of 10 runs are used to describe the classification results. The experimental results on four real HRSIs datasets are shown in Table 4, Table 5, Table 6 and Table 7, “Average Kappa” is the abbreviation of “Average Kappa coefficient”, the optimal classification results are shown in bold in each column.
Table 4.
Classification results of the Indian Pines dataset on traditional shallow classifiers.
Table 5.
Classification results of the Botswana dataset on traditional shallow classifiers.
Table 6.
Classification results of the Pavia University dataset on traditional shallow classifiers.
Table 7.
Classification results of the Salinas dataset on traditional shallow classifiers.
From Table 4, it can be seen that under 20% of the training samples in the Indian Pines dataset, compared to the original spectral feature Spe, the AOA of the extracted SFD features on SVM, MD, K-NN, and LR classifiers increased by 0.62%, 2.80%, 0.44%, and 6.59%, respectively; additionally, compared to the Spe-1st and Spe-2nd features, the AOA and average Kappa coefficient obtained by classification has significantly improved, indicating that the extracted SFD feature can achieve better accuracy in terrain classification. In addition, compared to the SpeLDA feature by performing LDA on the original spectral feature Spe, the SFDLDA feature has an AOA increase of 0.14%, 0.30%, 0.21%, and 0.12% on SVM, MD, K-NN, and LR classifiers; and compared to Spe-1stLDA feature and Spe-2ndLDA feature, the AOA and average Kappa coefficient have been improved to a certain extent, indicating that the extracted SFD feature can still retain their high separability after dimensionality reduction processing, enhancing the classification effect. In terms of the classification time, using the MD classifier as an example, the classification time for the Spe feature, Spe-1st feature, Spe-2nd feature, and SFD feature are 0.371 s, 0.361 s, 0.360 s, and 0.356 s, respectively. The result indicates that the extracted SFD feature can improve the accuracy of terrain classification while ensuring an almost constant classification rate.
Table 5 shows the classification results of the Botswana dataset under 20% of training samples. Compared to the original spectral feature Spe, the extracted SFD feature has significantly improved AOA and average Kappa coefficient on SVM, MD, K-NN, and LR classifiers compared to other features. Compared to the Spe feature, AOA has increased by 0.76%, 1.25%, 0.98%, and 2.48%, respectively, proving that the SFD feature can achieve better terrain classification accuracy. Meanwhile, compared to the SpeLDA feature, the AOA of the SFDLDA feature on SVM, MD, K-NN, and LR classifiers also increased by 0.10%, 0.16%, 0.11%, and 0.28%, respectively, indicating that the extracted SFD feature can still retain their high separability after dimensionality reduction processing, enhancing classification performance. In addition, the SD values of SFD and SFDLDA features are smaller than those of other features, further proving that the extracted features have a more stable classification effect. In terms of the classification time, using the MD classifier as an example, the classification time for the Spe feature, Spe-1st feature, Spe-2nd feature, and SFD feature are 0.132 s, 0.125 s, 0.136 s, and 0.126 s, respectively. The result indicates that the extracted SFD feature can effectively improve accuracy while maintaining runtime.
According to Table 6, it can be found that under 20% of training samples, the SFD feature extracted from the Pavia University dataset showed an increase in AOA on SVM, MD, K-NN, and LR classifiers by 1.47%, 2.80%, 0.69%, and 6.06%, respectively, compared to the original Spe feature. Moreover, compared to the Spe-1st and Spe-2nd features, the AOA and average Kappa coefficient of the SFD features were significantly improved, indicating that the extracted SFD feature can achieve better terrain classification accuracy. In addition, compared to the SpeLDA feature, the AOA of the SFDLDA feature on SVM, MD, K-NN, and LR classifiers increased by 0.87%, 6.02%, 1.09%, and 0.06%, respectively, and was also much greater than the AOA obtained from Spe-1stLDA and Spe-2ndLDA feature classification. Meanwhile, the SD values of the SFD feature and SFDLDA feature have decreased to varying degrees compared to most other features, indicating that the SFD feature has a certain degree of stability in terrain classification compared to other features. In terms of the classification time, using the MD classifier as an example, the classification time for the Spe feature, Spe-1st feature, Spe-2nd feature, and SFD feature are 0.748 s, 0.778 s, 0.721 s, and 0.755 s, respectively. The result indicates that the extracted SFD feature can improve the accuracy of terrain classification while ensuring an almost constant classification rate.
From Table 7, it can be observed that when selecting 20% of the training samples in the Salinas dataset, the extracted SFD feature showed an increase in AOA on SVM, MD, K-NN, and LR classifiers by 0.14%, 1.23%, 0.17%, and 2.41%, respectively, compared to the Spe feature. Moreover, the AOA was significantly improved compared to the Spe-1st feature and Spe-2nd feature. In addition, the AOA of the SFDLDA feature on SVM, MD, K-NN, and LR classifiers increased by 0.13%, 0.02%, 0.02%, and 0.03%, respectively, compared to the SpeLDA feature. The AOA and average Kappa coefficient obtained by the SFDLDA feature were also improved to some extent compared to the Spe-1stLDA feature and Spe-2ndLDA feature, indicating that the extracted SFD feature can still enhance the classification effect to some extent compared to other features. In addition, in terms of the classification time, using the MD classifier as an example, the classification time for the Spe feature, Spe-1st feature, Spe-2nd feature, and SFD feature are 1.680 s, 1.638 s, 1.666 s, and 1.642 s, respectively. The result indicates that the extracted SFD feature can effectively improve accuracy while maintaining runtime.
4.3. Classification Results of Networks
To extract deep features and verify the effectiveness of the SFD feature on different network structures, this paper sends the original spectral feature Spe, spectral first-order differential (Spe-1st) feature, spectral second-order differential (Spe-2nd) feature, spectral and frequency spectrum mixed feature (SFMF) [30], and extracted SFD feature into five different network structures for deep-feature extraction and classification, and compares the classification results. The experiments are conducted on a server with the RTX3080 graphical processing unit and 128 GB RAM, and the networks are implemented in Python. For each HRSIs dataset, 3%, 5%, and 10% samples of each class are randomly selected as training samples, and the rest are testing samples. Considering the randomness of the experimental results, the AOA and average Kappa coefficient of 10 runs were recorded to evaluate the classification effect. Table 8, Table 9, Table 10 and Table 11 show the experimental results on four real HRSIs datasets, where “Avg. Kap.” is the abbreviation of “Average Kappa coefficient”, the optimal classification results are shown in bold.
Table 8.
Classification results of the Indian Pines dataset on network models.
Table 9.
Classification results of the Botswana dataset on network models.
Table 10.
Classification results of the Pavia University dataset on network models.
Table 11.
Classification results of the Salinas dataset on network models.
According to Table 8, it can be found that on the Indian Pines dataset, the AOA and average Kappa coefficient of the deep SFD feature are significantly higher than those of the deep Spe feature, deep Spe-1st feature, deep Spe-2nd feature, and SFMF on the five network models under 3%, 5%, and 10% training samples, and the deep Spe-1st and deep Spe-2nd features, generally, have lower AOA and average Kappa coefficient compared to the deep Spe feature. This indicates that the SFD feature extracted using fractional-order differentiation can enhance recognition performance compared to features extracted using first-order differentiation and second-order differentiation. In addition, when the proportion of training samples is small, the deep SFD feature performs relatively better in terrain classification accuracy compared to other features, such as the results of 3DCNNPCA and HybridSN models. Under the condition of 3% training samples, the number of training samples in each class is lower than 30 (except for classes 2, 11, and 14, the number of 3% samples per class is 42, 73, and 37, respectively), this indicates that even under the condition of small-size training samples, the SFD feature is superior to other features. Meanwhile, through comparison, it can be seen that the SD value of the deep SFD feature is also smaller compared to the deep Spe feature, indicating that the classification effect of the deep SFD feature has a better stability. In terms of running time, using the 3DCNNPCA model with 5% training samples as an example, the testing times for the Spe feature, Spe-1st feature, Spe-2nd feature, SFMF, and SFD feature are 0.475 s, 0.476 s, 0.475 s, 0.531 s, and 0.476 s, respectively. The result indicates that the extracted SFD feature can effectively improve accuracy while maintaining runtime.
Figure 6 shows the classification maps of the Indian Pines dataset of deep Spe feature and deep SFD feature on five network models under 5% training samples. Through comparison, it can be found that the classification results of the deep SFD feature are, generally, better than those of the deep Spe feature on the five network models, with fewer misclassified pixels.

Figure 6.
Indian Pines dataset classification map: (a) Spe feature in FCN model with 69.36% AOA; (b) Spe feature in 1DCNN model with 77.12% AOA; (c) Spe feature in 3DCNN model with 81.53% AOA; (d) Spe feature in 3DCNNPCA model with 90.77% AOA; (e) Spe feature in HybridSN model with 93.81% AOA; (f) SFD feature in FCN model with 73.88% AOA; (g) SFD feature in 1DCNN model with 79.77% AOA; (h) SFD feature in 3DCNN model with 85.39% AOA; (i) SFD feature in 3DCNNPCA model with 91.44% AOA; (j) SFD feature in HybridSN model with 95.47% AOA.
Table 9 shows the classification results of the presented SFD feature compared to the Spe feature, Spe-1st feature, Spe-2nd feature, and SFMF on five network models for the Botswana dataset with 3%, 5%, and 10% training samples. It can be found that the AOA of the SFD feature proposed in this paper has improved compared to the other three features on all five models, making it more effective for terrain classification. Additionally, when the proportion of training samples is smaller, the AOA and average Kappa coefficient of the SFD feature are significantly improved compared to other features. Under the condition of 3% training samples, the number of training samples in each class is far lower than 30, indicating that in the case of small-size training samples, the SFD feature can better exert its advantages compared to other features. At the same time, it can be found that the SD values of the SFD feature are, generally, smaller than those of other features, indicating that the SFD feature is more stable in the classification. In terms of running time, using the 3DCNNPCA model with 5% training samples as an example, the testing times for the Spe feature, Spe-1st feature, Spe-2nd feature, SFMF, and SFD feature are 0.349 s, 0.349 s, 0.348 s, 0.481 s, and 0.312 s, respectively. The result indicates that the extracted SFD feature not only improves the accuracy of terrain classification but also has a more efficient running rate compared to other features.
Figure 7 shows the classification results of the Spe and the presented SFD features of the Botswana dataset on five network models under 5% training samples. Through comparison, it can be seen that the classification results of the SFD feature are, generally, better than those of the Spe feature on the five network models, further demonstrating the effectiveness of the SFD feature in terrain classification.

Figure 7.
Botswana dataset classification map: (a) Spe feature in FCN model with 82.48% AOA; (b) Spe feature in 1DCNN model with 82.76% AOA; (c) Spe feature in 3DCNN model with 89.02% AOA; (d) Spe feature in 3DCNNPCA model with 98.57% AOA; (e) Spe feature in HybridSN model with 96.45% AOA; (f) SFD feature in FCN model with 87.37% AOA; (g) SFD feature in 1DCNN model with 84.58% AOA; (h) SFD feature in 3DCNN model with 91.92% AOA; (i) SFD feature in 3DCNNPCA model with 99.16% AOA; (j) SFD feature in HybridSN model with 97.93% AOA.
From Table 10, it can be seen that on the Pavia University dataset, the presented SFD feature has higher AOA and average Kappa coefficient compared to the Spe feature, Spe-1st feature, Spe-2nd feature, and SFMF on the five network models at 3%, 5%, and 10% of the training samples. Additionally, the smaller the proportion of training samples, the more significant the improvement in the AOA of the SFD feature on certain models. For example, on 3DCNN, the AOA of the SFD feature increased by 2.98%, 0.95%, and 0.49% compared to Spe feature under 3%, 5%, and 10% training samples, respectively. Meanwhile, the SD values of the SFD feature are also smaller than those of other features, indicating that the presented SFD feature is more stable in the classification compared to other features. In terms of running time, using the 3DCNNPCA model with 5% training samples as an example, the testing times for the Spe feature, Spe-1st feature, Spe-2nd feature, SFMF, and SFD feature are 1.648 s, 1.646 s, 1.647 s, 2.068 s, and 1.634 s, respectively. The result indicates that the extracted SFD feature can effectively improve accuracy while maintaining runtime.
Figure 8 shows the classification maps of the Spe feature and the presented SFD feature on five network models for the Pavia University dataset under 5% training samples. Through comparison, it can be found that the classification results of the SFD feature are, generally, better than those of the Spe feature, which further proves the effectiveness of the extracted SFD feature in terrain classification.

Figure 8.
Pavia University dataset classification map: (a) Spe feature in FCN model with 85.36% AOA; (b) Spe feature in 1DCNN model with 81.66% AOA; (c) Spe feature in 3DCNN model with 93.03% AOA; (d) Spe feature in 3DCNNPCA model with 98.89% AOA; (e) Spe feature in HybridSN model with 99.29% AOA; (f) SFD feature in FCN model with 87.73% AOA; (g) SFD feature in 1DCNN model with 83.39% AOA; (h) SFD feature in 3DCNN model with 94.34% AOA; (i) SFD feature in 3DCNNPCA model with 99.12% AOA; (j) SFD feature in HybridSN model with 99.79% AOA.
Figure 9 shows the classification maps of the Spe feature and SFD feature of the Salinas dataset on five network models under 5% training samples. It can be found that the classification results of the presented SFD feature are, generally, better than those of the Spe feature on five network models, and the misclassification rate of the SFD feature is lower compared to the Spe feature, indicating that the extracted SFD feature can effectively improve the classification accuracy.
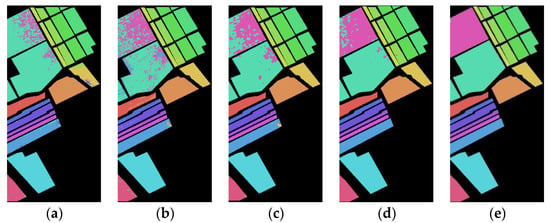
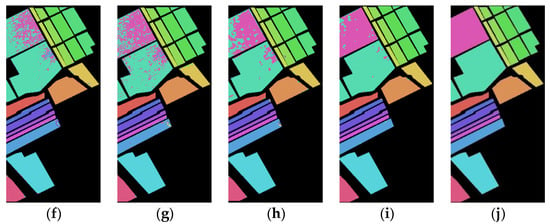
Figure 9.
Salinas dataset classification map: (a) Spe feature in FCN model with 88.77% AOA; (b) Spe feature in 1DCNN model with 87.14% AOA; (c) Spe feature in 3DCNN model with 91.02% AOA; (d) Spe feature in 3DCNNPCA model with 97.89% AOA; (e) Spe feature in HybridSN model with 99.78% AOA; (f) SFD feature in FCN model with 90.95% AOA; (g) SFD feature in 1DCNN model with 89.35% AOA; (h) SFD feature in 3DCNN model with 92.98% AOA; (i) SFD feature in 3DCNNPCA model with 98.86% AOA; (j) SFD feature in HybridSN model with 99.94% AOA.
From Table 11, it can be seen that at 3%, 5%, and 10% of the training samples, the SFD feature extracted from the Salinas dataset has a certain improvement in AOA and average Kappa coefficient compared to the Spe feature, Spe-1st feature, Spe-2nd feature, and SFMF on the five network models. Moreover, when the proportion of training samples is small, the AOA of the presented SFD feature is more significantly improved. For example, on the 3DCNN model, when the proportion of training samples is 3%, 5%, and 10%, the AOA of the SFD feature increased by 0.75%, 0.62%, and 0.25% compared to the Spe feature, respectively. In addition, the SD values of the SFD feature are, generally, smaller compared to other features, further indicating that the SFD feature has higher stability in the classification. In terms of running time, using the 3DCNNPCA model with 5% training samples as an example, the testing times for the Spe feature, Spe-1st feature, Spe-2nd feature, SFMF, and SFD feature are 2.021 s, 2.136 s, 2.056 s, 2.499 s, and 2.093 s, respectively. The result indicates that the extracted SFD feature can effectively improve accuracy while maintaining runtime.
Table 12 shows the small-size training samples experiments on the Pavia University and Salinas datasets under the condition of 30 training samples per class, the optimal classification results are shown in bold. From Table 12, it can be concluded that, in the case of small-size training samples, the SFD feature has greater advantages compared to other features on the Pavia University and Salinas datasets.
Table 12.
Classification results of Pavia University and Salinas datasets on network models under 30 training samples per class.
4.4. Discussion of Classification Results
From the above experimental results, it can be seen that the proposed SFD feature can effectively improve the classification accuracy of HRSIs. In the four HRSI datasets, the SFD feature has improved the accuracy of terrain classification to varying degrees. To demonstrate the effectiveness of the proposed criteria, Table 13 takes the MD classifier as an example and shows the AOA and SD vary with the SFD order v in the range of 0.1 to 0.9 at step 0.1 on four HRSIs datasets. For each dataset, 20% of each class data is randomly selected as a training sample and the rest are testing samples. The best result of each column is shown in bold.
Table 13.
Classification results of MD classifier with SFD order in the range of 0~0.9.
Table 13 shows that the SFD order v corresponding to the highest AOA of each dataset is mainly within the range of the peaks of criterion J in Figure 3. Additionally, the variation trend of classification accuracy with SFD order is also similar to that of criterion J with SFD order, which proves the feasibility of the presented SFD order selection criterion. It can be concluded that the presented criterion J is an effective method to select appropriate SFD order v, and performing fractional differentiation on the pixel spectral curves with the selected order v will achieve the efficient SFD feature that can improve the classification accuracy.
For two classes that are easily misclassified, the SFD feature shows its advantage and can enhance the separability between these two classes. Taking the Salinas dataset as an example, Table 14 shows the classification accuracy of each class and the overall accuracy, the significantly improved class at order 0.5 is shown in bold. It is shown in Table 14 that for most classes, the results of the SFD feature are better or equal to the original spectral feature. Because most classes in the Salinas dataset are vegetation and crops, which leads to different subjects with similar spectra, in this case, the local burrs characteristics of the pixel spectral curves, which correspond to the high-frequency components, contribute most to the identification. The extracted SFD feature can enhance the high-frequency components while sufficiently retaining the low-frequency components of the spectral pixel, thus, the separability of these similar classes will increase and the classification accuracy will be improved, which confirms the results discussed in Section 2.3.
Table 14.
Classification accuracy of each class and overall accuracy of Salinas dataset by MD classifier with SFD order in the range of 0~0.9.
The experimental results have verified the validity of the proposed SFD feature-extraction method. The reason behind the experimental phenomenon is that the presented SFD feature-extraction method uses fractional differentiation to extract both the low-frequency components characteristics and high-frequency components characteristics of the pixel spectral curves of HRSIs, which can preserve both the overall curve shape and local burrs characteristics of the pixel spectral curves of HRSIs. On the other hand, the experimental results also show the effectiveness of the presented criterion for selecting the fractional-differentiation order. The network models perform deep-feature extraction based on importing the SFD feature and, thus, achieve efficient deep features that can further improve terrain classification accuracy. Especially under the condition of small-size training samples, the terrain classification accuracy is improved more significantly.
5. Conclusions
In this paper, a spectral fractional-differentiation (SFD) feature of HRSIs is presented, and a fractional-differentiation order selection criterion is proposed. The MD classifier, SVM classifier, K-NN classifier, and LR classifier are used to evaluate the performance of the presented SFD feature. The obtained SFD feature is sent to the FCN and 1DCNN for deep-feature extraction and classification, and the SFD-Spa feature cube containing spatial information is sent to 3DCNN for deep-feature extraction and classification. The SFD-Spa feature after performing PCA on spectral pixels is directly connected with the first principal component of the original data and sent to 3DCNNPCA and HybridSN models to extract deep features. The experimental results on four real HRSIs show that the extracted SFD feature can effectively improve the accuracy of terrain classification, and sending SFD feature to deep-learning environments can further improve the accuracy of terrain classification for HRSIs, especially in the case of small-size training samples. The presented SFD feature-extraction method has limitations, such as the fact that the fractional-differentiation order needs to be selected, the SFD feature-extraction method cannot reduce the dimensionality of data, and the presented method should be performed on the datum one by one because there is no projection matrix that suits LDA or PCA.
Author Contributions
Conceptualization, Y.L. (Yang Li); formal analysis, Y.L. (Yang Li); funding acquisition, F.Z., Y.L. (Yi Liu), and J.L.; investigation, J.L. and Y.L. (Yang Li); methodology, J.L. and Y.L. (Yang Li); project administration, J.L., Y.L. (Yi Liu), and F.Z.; software, Y.L. (Yang Li); supervision, J.L.; validation, J.L.; visualization, Y.L. (Yang Li); writing—original draft, Y.L. (Yang Li); writing—review and editing, J.L. and Y.L. (Yi Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (no. 62176140, no. 62077038, and no. 61672405) and the Natural Science Foundation of Shaanxi Province of China (no. 2021JM-459).
Acknowledgments
The authors would like to thank the editors and anonymous reviewers who handled our paper.
Conflicts of Interest
The authors declare that there are no conflict of interest regarding the publication of this paper.
References
- Alcolea, A.; Paoletti, M.E.; Haut, J.M.; Resano, J.; Plaza, A. Inference in Supervised Spectral Classifiers for On-Board Hyperspectral Imaging: An Overview. Remote Sens. 2020, 12, 534. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-Branch Multi-Attention Mechanism Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef]
- Renard, N.; Bourennane, S.; Blanc-Talon, J. Denoising and Dimensionality Reduction Using Multilinear Tools for Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 138–142. [Google Scholar] [CrossRef]
- Dong, Y.; Du, B.; Zhang, L.; Zhang, L. Dimensionality Reduction and Classification of Hyperspectral Images Using Ensemble Discriminative Local Metric Learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2509–2524. [Google Scholar] [CrossRef]
- Li, N.; Zhou, D.; Shi, J.; Wu, T.; Gong, M. Spectral-Locational-Spatial Manifold Learning for Hyperspectral Images Dimensionality Reduction. Remote Sens. 2021, 13, 2752. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear Versus Nonlinear PCA for the Classification of Hyperspectral Data Based on the Extended Morphological Profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of Hyperspectral Images with Regularized Linear Discriminant Analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Bao, J.; Chi, M.; Benediktsson, J.A. Spectral Derivative Features for Classification of Hyperspectral Remote Sensing Images: Experimental Evaluation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2013, 6, 594–601. [Google Scholar] [CrossRef]
- Ye, Z.; He, M.; Fowler, J.E.; Du, Q. Hyperspectral Image Classification Based on Spectra Derivative Features and Locality Preserving Analysis. In Proceedings of the 2014 IEEE China Summit and International Conference on Signal and Information Processing, Xi’an, China, 4 September 2014; pp. 138–142. [Google Scholar]
- Tian, A.; Zhao, J.; Tang, B.; Zhu, D.; Fu, C.; Xiong, H. Hyperspectral Prediction of Soil Total Salt Content by Different Disturbance Degree under a Fractional-Order Differential Model with Differing Spectral Transformations. Remote Sens. 2021, 13, 4283. [Google Scholar] [CrossRef]
- Lao, C.; Chen, J.; Zhang, Z.; Chen, Y.; Ma, Y.; Chen, H.; Gu, X.; Ning, J.; Jin, J.; Li, X. Predicting the Contents of Soil Salt and Major Water-soluble Ions with Fractional-order Derivative Spectral Indices and Variable Selection. Comput. Electron. Agric. 2021, 182, 106031. [Google Scholar] [CrossRef]
- Hong, Y.; Guo, L.; Chen, S.; Linderman, M.; Mouazen, A.M.; Yu, L.; Chen, Y.; Liu, Y.; Liu, Y.; Chen, H.; et al. Exploring the Potential of Airborne Hyperspectral Image for Estimating Topsoil Organic Carbon: Effects of Fractional-order Derivative and Optimal Band Combination Algorithm. Geoderma 2020, 365, 114228. [Google Scholar] [CrossRef]
- Gao, Q.; Lim, S.; Jia, X. Hyperspectral Image Classification Using Convolutional Neural Networks and Multiple Feature Learning. Remote Sens. 2018, 10, 299. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, F.; Zhang, L. Hyperspectral Image Classification Via a Random Patches Network. ISPRS J. Photogramm. Remote Sens. 2018, 142, 344–357. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefevre, S. Deep Learning for Classification of Hyperspectral Data: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Chen, W.; Jia, Z.; Yang, J.; Kasabov, N.K. Multispectral Image Enhancement Based on the Dark Channel Prior and Bilateral Fractional Differential Model. Remote Sens. 2022, 14, 233. [Google Scholar] [CrossRef]
- Dong, S.; Quan, Y.; Feng, W.; Dauphin, G.; Gao, L.; Xing, M. A Pixel Cluster CNN and Spectral-Spatial Fusion Algorithm for Hyperspectral Image Classification with Small-Size Training Samples. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 4101–4114. [Google Scholar] [CrossRef]
- Aydemir, M.S.; Bilgin, G. Semisupervised Hyperspectral Image Classification Using Small Sample Sizes. IEEE Geosci. Remote Sens. Lett. 2017, 14, 621–625. [Google Scholar] [CrossRef]
- Sun, H.; Chang, A.; Zhang, Y.; Chen, W. A Review on Variable-order Fractional Differential Equations: Mathematical Foundations, Physical Models, Numerical Methods and Applications. Fract. Calc. Appl. Anal. 2019, 22, 27–59. [Google Scholar] [CrossRef]
- Podlubny, I. Fractional Differential Equations; Academic Press: San Diego, CA, USA, 1999; pp. 43–48, 203. [Google Scholar]
- Pu, Y. Fractional Calculus Approach to Texture of Digital Image. In Proceedings of the 8th International Conference on Signal Processing, Guilin, China, 16 November 2006; pp. 1002–1006. [Google Scholar]
- Pu, Y.; Yuan, X.; Liao, K.; Chen, Z.; Zhou, J. Five Numerical Algorithms of Fractional Calculus Applied in Modern Signal Analyzing and Processing. J. Sichuan Univ. Eng. Sci. Ed. 2005, 37, 118–124. [Google Scholar]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in Spectral-spatial Classification of Hyperspectral Images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Liu, J.; Yang, Z.; Liu, Y.; Mu, C. Hyperspectral Remote Sensing Images Deep Feature Extraction Based on Mixed Feature and Convolutional Neural Networks. Remote Sens. 2021, 13, 2599. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s), and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).