The GRU is an improvement on LSTM and is one of the variants of the RNN (recurrent neural network). The RNN is a type of neural network that can handle sequential data. In the traditional RNN model, the current input and the previous time step’s state are combined through a recurrent unit to generate a new state. However, this structure is prone to the issues of vanishing and exploding gradients, which limits the long-term dependency capability of RNNs. LSTM, on the other hand, addresses these problems by introducing memory cells and gate mechanisms, enabling a better handling of long sequential data. In comparison to the LSTM model, the GRU removes one gate unit, resulting in fewer model parameters and a lighter model overall. This makes the GRU more practical in certain application scenarios, such as autonomous driving. The main idea of the GRU is the introduction of the gating mechanism, which controls the flow of information and selectively forgets past information while updating the information at the current time. The GRU model includes two key parts, which are the reset gate and the update gate. The reset gate controls the degree of influence for the information in the past to the present moment. Additionally, the update gate controls the degree of update for the new information in the present moment and the information in the past moment. In addition, the GRU also introduces a hidden state to save information from previous moments, which can be reused in future moments. The traditional GRU typically uses the sigmoid and tanh functions as the activation functions for the gating mechanism, and their parameters are fixed. However, when dealing with point cloud data with complex distributions, these fixed-parameter activation functions may not fully adapt to the data’s characteristics. To address this issue, this article proposes the Ada-GRU. In the Ada-GRU, the activation function’s parameters are learned through training, enabling the model to adaptively adjust the gating mechanism based on the input data’s characteristics. This adaptability allows the model to better capture the temporal and geometric information within the point cloud data.
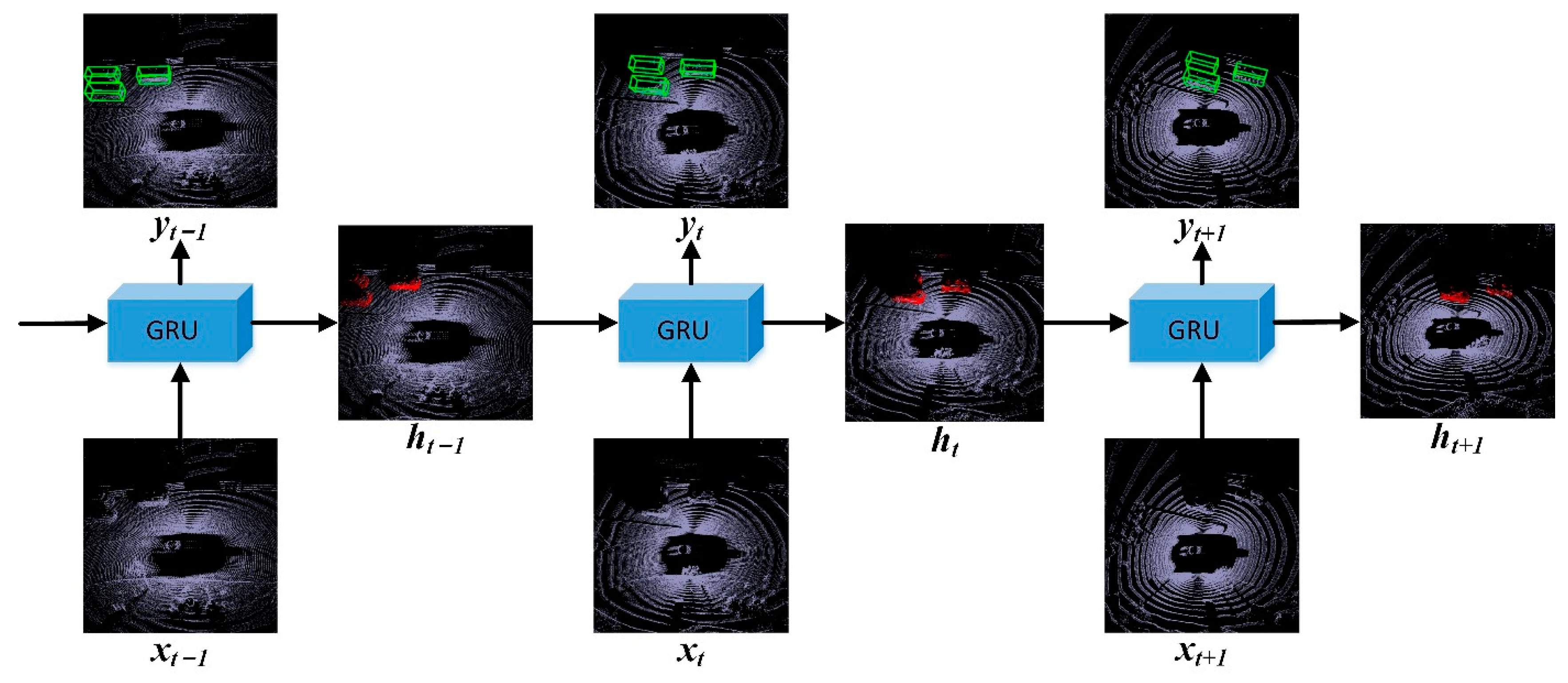
Ada-GRU: The Ada-GRU model is used to fuse the characteristics of the temporal sequence of the LiDAR point cloud frames, and the model structure and basic notation are shown in
Figure 4. In the figure,
represents the hidden features of the previous frames, accumulating the historical information over the temporal sequence. By utilizing the historical information,
can provide a more comprehensive understanding of the point cloud frame at the current moment, enabling the model to better capture the dynamic changes and motion characteristics of the object.
is the parameter of the reset gate, which has a value in the range of
and serves as a scaling factor that controls how much information is retained by the hidden feature
of the previous frames. The calculation method is as follows:
where
represents the weight matrix of the reset gate,
represents the concatenation of the hidden feature
of the previous frames and the feature
of the current frame based on the feature dimension, “
” represents the matrix multiplication operation, and
represents the bias vector of the reset gate.
represents the following adaptive sigmoid function:
which restricts the reset gate parameter
within the range of
. In comparison to the traditional sigmoid function, the adaptive sigmoid function introduces a trainable parameter
, which can learn to adjust the slope of the sigmoid function.
Figure 5 (left) shows the variations in the slope when different values of
are used. When
is larger, the sigmoid function exhibits a steeper change curve, making the gating unit easier to “open” or “close”. Conversely, when
is small, the change curve of the sigmoid function becomes gentler, resulting in smoother responses of the gated units to the sequence features. By introducing the adaptive sigmoid function, the model can automatically adjust the gating mechanism according to the characteristics of the data, thereby enhancing the fusion performance of the temporal sequence information in the point cloud data. After obtaining the reset gate parameter
, it is multiplied with the previous frames’ hidden feature
to retain the relevant information for the current frame. Then, it is concatenated with
based on the feature dimension, and the candidate hidden feature
is calculated as follows:
where
is the weight matrix of the candidate hidden feature, “
” represents the element-wise multiplication operation,
represents the bias vector, and
represents the following adaptive hyperbolic tangent function:
of which its effect is to perform a nonlinear transformation and restrict the candidate hidden feature
within the range of
. Similar to the adaptive sigmoid function, the slope of the hyperbolic tangent function is adjusted by introducing the trainable parameter
.
Figure 5 (right) shows the variations in the slope when different values of
are used. The main purpose of the hidden feature
is to incorporate both the feature
of the current frame and the hidden feature
of the previous frames into the current frame. The candidate hidden feature
can be seen as a way to remember the “state” of the point cloud feature in the current frame.
Finally, during the “update memory” phase of the Ada-GRU, the update gate parameter
is calculated as follows:
where
represents the weight matrix of the update gate, and
represents the bias vector. The update gate parameter
is used to control the influence of the previous frames’ hiding feature
and the current frame’s candidate hidden feature
on the current frame’s hidden feature
. The hidden feature
of the current frame is the output of the Ada-GRU model, and its calculation method is as follows:
where
represents the influence of the previous frames’ hidden features on the current frame, and
represents the influence of the current frame’s candidate hidden features on the current frame. By using the update gate parameter
to control the weighted sum of the previous frames’ hidden features and the current frame’s hidden features, the Ada-GRU model can flexibly regulate the influence of the previous frames’ hidden features on the current frame. This enables the model to effectively capture the temporal feature information of the point cloud.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}