
SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing

Abstract
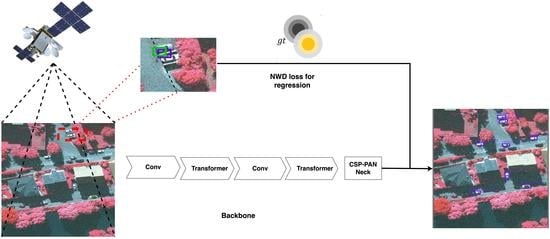
1. Introduction
- We propose Local Lighted Transformer block (2L-Transformer), a new transformer module, and integrate it with EfficientNetV2-S as our backbone for improved feature extraction. On the AI-TOD dataset, an increase of 1.3% in AP is observed when we replace the original backbone with EfficientNetV2-S. When further embedding the proposed Transformer block in EfficientNetV2-S, we achieve an additional 1.8% increase in AP.
- By optimizing the original bottleneck network on the PAN topology utilizing CSP as an internal building block, our experiments demonstrate that the optimized model is more effective in integrating multi-scale features.
- We also evaluate the possibility of using the normalized Wasserstein distance (NWD) as an alternative similarity metric for small targets. Specifically, on the AI-TOD dataset, the proposed model with NWD has a 14.1% increase in AP compared with the standard AP baseline. Moreover, on the VOC 2007 dataset, our proposed multi-level NWD shows better results than the NWD metric.
2. Related Work
2.1. Feature Pyramid
2.2. Transformers/Self-Attention Mechanism
2.3. Similarity Metrics
3. Materials and Methods
3.1. Self-Attention Mechanism
3.2. Feature Fusion Strategy
3.2.1. Spatial Pyramid Pooling-Fast
3.2.2. Path Aggregation Network
3.2.3. Cross Stage Partial-PAN
3.3. Similarity Metric
4. Results
4.1. DataSet
4.2. Experimental Setup
4.3. Evaluation Metric
4.4. Results and Analysis
4.5. Ablation Study
4.5.1. Influence of Local Lighted Transformer Module
4.5.2. Influence of Different Feature Fusion Modules
- Spatial Pyramid Pooling-Fast
- Cross Stage Partial-PAN
4.5.3. Influence of Normalized Wasserstein Distance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tong, K.; Wu, Y.; Zhou, F. Recent Advances in Small Object Detection Based on Deep Learning: A Review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn, J. YOLOv5 Release v6.1. 2022. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.1 (accessed on 10 June 2020).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. Pp-yoloe: An evolved version of yolo. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Leng, J.; Liu, Y. An enhanced SSD with feature fusion and visual reasoning for object detection. Neural Comput. Appl. 2019, 31, 6549–6558. [Google Scholar] [CrossRef]
- Shi, W.; Bao, S.; Tan, D. FFESSD: An Accurate and Efficient Single-Shot Detector for Target Detection. Appl. Sci. 2019, 9, 4276. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhou, D.; Zhai, J. SSD small target detection algorithm based on deconvolution and feature fusion. CAAI Trans. Intell. Syst. 2020, 15, 310–316. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by Concatenating Feature Maps for Object Detection. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. Sci. China (Inf. Sci.) 2020, 63, 94–96. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale 2021. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2022, 190, 79–93. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–20 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7029–7038. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jacob, D.; Ming, C.; Kenton, L.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Alec, R.; Karthik, N.; Tim, S.; Ilya, S. Improving Language Understanding with Unsupervised Learning. Tech. Rep. 2018, 4. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Tom, B.; Benjamin, M.; Nick, R.; Melanie, S.; Jared, K.; Prafulla, D.; Arvind, N.; Pranav, S.; Girish, S.; Amanda, A.; et al. Language models are few-shot learners. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1971–1980. [Google Scholar]
- Bello, I.; Zoph, B.; Le, Q.; Vaswani, A.; Shlens, J. Attention Augmented Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3285–3294. [Google Scholar]
- Yin, M.; Yao, Z.; Cao, Y.; Li, X.; Zhang, Z.; Lin, S.; Hu, H. Disentangled non-local neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Online, 23–28 August 2020. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 3588–3597. [Google Scholar]
- Gu, J.; Hu, H.; Wang, L.; Wei, Y.; Dai, J. Learning Region Features for Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 381–395. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Cheng, C.; Fangyun, W.; Han, H. Relationnet++: Bridging visual representations for object detection via transformer decoder. In Proceedings of the Thirty-Fourth Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable {detr}: Deformable transformers for end-to-end object detection. In Proceedings of the 2021 International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 14449–14458. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the 2020 AAAI Conference on Artifificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian Wasserstein distance loss. In Proceedings of the 2021 International Conference on Machine Learning (ICML), Online, 18–24 July 2021. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 2021 International Conference on Machine Learning (ICML), Online, 18–24 July 2021. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks 2019. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7132–7141. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (CVPR), Online, 19–25 June 2021; pp. 10012–10022. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. arXiv 2022, arXiv:2110.02178. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.-S. Tiny Object Detection in Aerial Images. In Proceedings of the 2021 26th International Conference on Pattern Recognition (ICPR), Taichung, Taiwan, 18–21 July 2021; pp. 3791–3798. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 5–12 September 2014; pp. 740–755. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 3974–3983. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A one-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- YOLO by Ultralytics (Version 8.0.0). Available online: https://github.com/ultralytics/ultralytics (accessed on 17 April 2023).
- Liu, K.; Huang, J.; Li, X. Eagle-Eye-Inspired Attention for Object Detection in Remote Sensing. Remote Sens. 2022, 14, 1743. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z.-X. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9656–9665. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9756–9765. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Qiao, S.; Chen, L.-C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 10208–10219. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Input Size | mAP |
|---|---|---|---|
| SSD300 | VGG-16 | 300 × 300 | 77.2 |
| SSD512 | VGG-16 | 512 × 512 | 79.8 |
| ESSD [14] | VGG-16 | 300 × 300 | 78.7 |
| ESSD [14] | VGG-16 | 512 × 512 | 81.7 |
| RSSD [17] | VGG-16 | 300 × 300 | 78.5 |
| RSSD [17] | VGG-16 | 512 × 512 | 80.8 |
| FFESSD [15] | VGG-16 | 300 × 300 | 79.1 |
| FFESSD [15] | VGG-16 | 512 × 512 | 80.9 |
| MDSSD [18] | VGG-16 | 300 × 300 | 78.6 |
| MDSSD [18] | VGG-16 | 512 × 512 | 81.0 |
| YOLOv6-M [57] | EfficientRep | 640 × 640 | 86.0 |
| YOLOv8n [59] | Darknet | 640 × 640 | 80.2 |
| DETR [39] | Transformer Encoder | 640 × 640 | 82.6 |
| Ours300 | VGG-16 | 300 × 300 | 79.9 |
| Ours512 | VGG-16 | 512 × 512 | 82.4 |
| Ours300 | 2L-Transformer+EfficientNetV2-S | 300 × 300 | 82.2 |
| Ours512 | 2L-Transformer+EfficientNetV2-S | 512 × 512 | 84.9 |
| Method | Backbone | AP | AP0.5 | AP0.75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|
| HRCNN-regression [52] | AlexNet | / | 51.4 | / | / | / | / |
| YOLO-v4 | CSPDarknet-53 | 59.9 | 89.7 | 68.3 | 11.2 | 50.1 | 58.2 |
| YOLOv3-608 | Darknet-53 | 59.4 | 89.0 | 66.8 | 10.6 | 48.3 | 55.6 |
| RetinaNet | ResNet-50 | 59.6 | 89.3 | 67.7 | 10.9 | 49.2 | 57.4 |
| EFNet [60] | ResNet-50 | 62.2 | 90.7 | 71.7 | 12.4 | 53.5 | 60.2 |
| SSD512 | VGG-16 | 52.7 | 87.3 | 57.4 | 9.5 | 42.1 | 51.7 |
| FoveaBox | Resnet-50 | 61.8 | 90.4 | 70.6 | 18.4 | 51.8 | 58.7 |
| SSD512 | EfficientNetV2-S | 53.4 | 88.0 | 62.1 | 9.6 | 43.5 | 53.8 |
| YOLOv6-M [57] | EfficientRep | 62.9 | 91.4 | 71.2 | 18.3 | 54.0 | 61.2 |
| YOLOv8n [59] | Darknet | 61.3 | 90.4 | 70.7 | 18.0 | 53.1 | 59.3 |
| DETR [39] | Transformer Encoder | 58.8 | 88.5 | 69.5 | 14.5 | 53.5 | 61.8 |
| Ours512 | 2L-Transformer+ EfficientNetV2-S | 63.2 | 91.1 | 72.2 | 20.4 | 53.8 | 60.6 |
| Method | Backbone | AP | AP0.5 | AP0.75 | APvt | APt | APs | APm |
|---|---|---|---|---|---|---|---|---|
| SSD512 [13] | ResNet-50 | 7.0 | 21.7 | 2.8 | 1.0 | 4.7 | 11.5 | 13.5 |
| TridentNet [61] | ResNet-50 | 7.5 | 20.9 | 3.6 | 1.0 | 5.8 | 12.6 | 14.0 |
| FoveaBox [58] | ResNet-50 | 8.1 | 19.8 | 5.1 | 0.9 | 5.8 | 13.4 | 15.9 |
| RepPoints [62] | ResNet-50 | 9.2 | 23.6 | 5.3 | 2.5 | 9.2 | 12.9 | 14.4 |
| FCOS [63] | ResNet-50 | 9.8 | 24.1 | 5.9 | 1.4 | 8.0 | 15.1 | 17.4 |
| M-CenterNet [53] | DLA-34 | 14.5 | 40.7 | 6.4 | 6.1 | 15.0 | 19.4 | 20.4 |
| RetinaNet | ResNet-50 | 4.7 | 13.6 | 2.1 | 2.0 | 5.4 | 6.3 | 7.6 |
| ATSS [64] | ResNet-50 | 12.8 | 30.6 | 8.5 | 1.9 | 11.6 | 19.5 | 29.2 |
| Faster R-CNN | ResNet-50 | 11.1 | 26.3 | 7.6 | 0.0 | 7.2 | 23.3 | 33.6 |
| Cascade R-CNN [65] | ResNet-50 | 13.8 | 30.8 | 10.5 | 0.0 | 10.6 | 25.5 | 36.6 |
| DetectorRS [66] | ResNet-50 | 14.8 | 32.8 | 11.4 | 0.0 | 10.8 | 28.3 | 38.0 |
| SSD512 | EfficientNetV2-S | 6.9 | 21.4 | 2.7 | 0.8 | 4.7 | 11.0 | 13.5 |
| YOLOv6-M [57] | EfficientRep | 16.3 | 37.9 | 12.1 | 2.6 | 10.2 | 30.5 | 40.2 |
| YOLOv8n [59] | Darknet | 14.9 | 32.8 | 11.6 | 2.0 | 9.8 | 26.4 | 33.6 |
| DETR [39] | Transformer Encoder | 10.6 | 26.4 | 7.4 | 0.0 | 6.7 | 20.5 | 35.2 |
| Ours | 2L-Transformer+ EfficientNetV2-S | 21.1 | 49.9 | 14.9 | 7.0 | 20.8 | 30.1 | 38.8 |
| Backbone | AP | AP0.5 | |
|---|---|---|---|
| AI-TOD | VGG-16 | 7.0 | 21.7 |
| ResNet-50 | 9.1 | 26.2 | |
| EfficientNetV2-S | 8.3 | 24.4 | |
| 2L-Transformer + EfficientNetV2-S | 10.1 | 27.5 | |
| VOC-07 | VGG-16 | 60.7 | 79.8 |
| ResNet-50 | 62.1 | 81.6 | |
| EfficientNetV2-S | 61.5 | 80.3 | |
| 2L-Transformer + EfficientNetV2-S | 62.5 | 82.8 | |
| TGRS-HRRSD | VGG-16 | 52.7 | 87.3 |
| ResNet-50 | 58.8 | 88.9 | |
| EfficientNetV2-S | 58.7 | 88.4 | |
| 2L-Transformer + EfficientNetV2-S | 59.6 | 89.3 |
| Dataset/Component | SSD_Neck (AP0.5) | FPN (AP0.5) | PAN (AP0.5) | CSP-PAN (AP0.5) |
|---|---|---|---|---|
| AI-TOD | 27.5 | 29.8 | 31.8 | 32.4 |
| VOC-07 | 82.8 | 83.5 | 84.3 | 84.9 |
| TGRS-HRRSD | 89.3 | 90.2 | 90.5 | 90.6 |
| Dataset/Component | SPP-Fast | CSP-PAN | AP0.5 |
|---|---|---|---|
| AI-TOD | 27.5 | ||
| √ | 27.3 | ||
| √ | 32.2 | ||
| √ | √ | 32.4 | |
| VOC-07 | 82.8 | ||
| √ | 82.4 | ||
| √ | 84.1 | ||
| √ | √ | 84.9 | |
| TGRS-HRRSD | 89.3 | ||
| √ | 89.4 | ||
| √ | 90.4 | ||
| √ | √ | 90.6 |
| Dataset | Method | Assigning | Loss | AP | AP0.5 |
|---|---|---|---|---|---|
| AI-TOD | Baseline | 12.8 | 32.4 | ||
| NMD | √ | 18.9 | 46.2 | ||
| √ | 13.4 | 36.4 | |||
| √ | √ | 21.1 | 49.9 | ||
| VOC-07 | Baseline | 64.8 | 84.9 | ||
| NMD | √ | 62.2 | 80.2 | ||
| √ | 60.7 | 78.8 | |||
| √ | √ | 60.5 | 78.6 | ||
| TGRS-HRRSD | Baseline | 62.5 | 90.6 | ||
| NMD | √ | 62.4 | 90.4 | ||
| √ | 63.0 | 91.1 | |||
| √ | √ | 62.4 | 90.5 |
| Method | AP | AP0.5 |
|---|---|---|
| IoU | 64.8 | 84.9 |
| NWD | 60.7 | 78.8 |
| Multi-level NWD | 62.6 | 84.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Remote Sens. 2023, 15, 3027. https://doi.org/10.3390/rs15123027
Huo B, Li C, Zhang J, Xue Y, Lin Z. SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Remote Sensing. 2023; 15(12):3027. https://doi.org/10.3390/rs15123027
Chicago/Turabian StyleHuo, Bihan, Chenglong Li, Jianwei Zhang, Yingjian Xue, and Zhoujin Lin. 2023. "SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing" Remote Sensing 15, no. 12: 3027. https://doi.org/10.3390/rs15123027
APA StyleHuo, B., Li, C., Zhang, J., Xue, Y., & Lin, Z. (2023). SAFF-SSD: Self-Attention Combined Feature Fusion-Based SSD for Small Object Detection in Remote Sensing. Remote Sensing, 15(12), 3027. https://doi.org/10.3390/rs15123027