1. Introduction
Agriculture forms the foundation for human survival and development. The classification of crops on large-scale agricultural land holds immense significance in various aspects, including crop monitoring, yield estimation, and post-disaster compensation statistics. In recent years, advanced scientific and technological approaches have been extensively employed in agriculture to reduce agricultural expenditure and advance scientific, precise, and intelligent farming methods [
1]. Remote sensing technology, specifically hyperspectral remote sensing, has played a pivotal role in this regard. Hyperspectral images, known for containing a wealth of spectral features, have found widespread applications in agriculture and forestry, such as crop classification, geological exploration, forestry delineation, and environmental monitoring [
2].
Crop classification methods using hyperspectral images involve the processing of hyperspectral data. In the realm of hyperspectral image classification, traditional methods typically follow a data processing sequence composed of image data preprocessing, feature extraction, and classification based on the extracted features. Multinomial logistic regression (MLR) and the support vector machine (SVM) are recognized as the most prominent feature extraction and classification methods in this context [
3].
The advancement of deep learning technologies has led to the widespread adoption of recurrent neural networks (RNNs) for sequential tasks. Likewise, convolutional neural networks (CNNs) have demonstrated their applicability across a range of computer vision tasks. When compared to traditional machine learning approaches, CNNs offer notable advantages in terms of prediction accuracy. Moreover, traditional methods often entail stringent image acquisition requirements, resulting in considerably higher overall time costs as compared to CNN-based approaches [
4].
Hyperspectral image classification shares similarities with image classification methods in computer vision. In this study, we refer to this specific approach as the hyperspectral image classification method based on image classification. This method entails partitioning the hyperspectral image data into image blocks, each with a predetermined size of , during both model training and prediction. In this context, and represent the dimensions of the hyperspectral image being classified, while denotes the predefined block size determined by the model input. Subsequently, all blocks undergo feature extraction utilizing an image classification model.
In contrast to traditional methods, this approach comprehensively leverages spatial features by predicting the class assignment of each pixel based on its neighboring blocks. However, this model exhibits high computational complexity due to repeated calculations for pixels in the same position during inference. Furthermore, methods based on image classification solely concentrate on the fixed data within the divided image blocks, overlooking the global spatial context information.
The primary objective of hyperspectral image classification is to assign a label to each pixel within the hyperspectral image, a task akin to semantic segmentation in computer vision. Consequently, certain researchers have tackled the challenge of hyperspectral image classification by enhancing traditional semantic segmentation models such as U-Net and the fully convolutional network (FCN). These improvements aim to enhance computational efficiency and achieve higher accuracy [
5].
However, the majority of studies focusing on hyperspectral image classification have predominantly employed CNN and RNN approaches [
6,
7,
8]. CNN-based methods primarily emphasize local features within the hyperspectral images themselves, overlooking the distinctive spectral features unique to hyperspectral data [
9]. On the other hand, RNN approaches solely attend to the distinct spectral sequence features, lacking the ability to effectively process global sequence information due to their unidirectional nature. Furthermore, hyperspectral image data often exhibit imbalanced samples, with certain categories having significantly more instances, sometimes even tens of times more, compared to other categories [
10]. In terms of sampling strategies, many methods only consider positive samples that are annotated with corresponding crop classes within the dataset. This results in a high misclassification rate for unlabeled negative samples that do not belong to any crop class. Consequently, the visualization of prediction results tends to have low quality, with unclear classification boundaries.
This paper revisits the structural characteristics of hyperspectral images, recognizing their abundant sequence features and the need to capture both local and global spatial context information. In light of this, we turn to the transformer architecture, which has gained popularity in computer vision. The main contributions of this paper are as follows:
- (1)
We propose an end-to-end hyperspectral image classification method called HyperSFormer, which combines a transformer and semantic segmentation. HyperSFormer enhances the SegFormer architecture by replacing its encoder with an improved Swin Transformer while retaining the SegFormer decoder. By leveraging the powerful image and sequence processing capabilities of the transformer, we address the limitations of the traditional CNN and RNN frameworks in expressing global information entropy due to insufficient contextual information [
11].
- (2)
To extract detailed spectral and spatial context information more effectively from hyperspectral images, we introduce an adaptive hyperspectral image embedding method called hyper patch embedding (HPE). Prior to the input encoder, the HPE module encodes hyperspectral images into fixed-dimensional embedding vectors, which are then fed into the model’s encoder. The encoder leverages multiple levels of self-attention operations to capture image feature information at different levels. Additionally, a transpose padding upsample (TPU) module is integrated at the output of the decoder to preserve the width and height information of the image during the encoding and decoding process, ensuring end-to-end hyperspectral image classification.
- (3)
To ensure the effectiveness of training, this study proposes an adaptive min log sampling (AMLS) strategy. This strategy determines the number of samples used for training by setting sampling coefficients based on the distribution of the different datasets. Additionally, during training, random flips are applied to the images in both vertical and horizontal directions, and samples are randomly selected from the training set for parameter updating, allowing for different gradients and effective training. Moreover, a novel loss function is designed that combines focal loss and dice loss, considering the distinctions between positive and negative samples, as well as between difficult and easy samples. This loss function aims to achieve efficient training and accurate classification outcomes.
The rest of the paper is organized as follows.
Section 2 introduces the methods in hyperspectral image classification and describes the details of the proposed HyperSFormer, and
Section 3 details the comparative results obtained on the three datasets. Next,
Section 4 presents the ablation experiments and a discussion on the model design. Finally,
Section 5 concludes the paper.
2. Background
In recent years, deep learning approaches have demonstrated remarkable achievements in the field of hyperspectral remote sensing. Particularly, methods based on image classification and semantic segmentation have proven successful for hyperspectral image classification. Traditional CNN-based methods have encountered limitations, prompting researchers to explore alternative approaches using the transformer architecture. Moreover, the persisting challenges of limited and unbalanced sample sizes remain significant considerations in hyperspectral image classification.
2.1. Hyperspectral Image Classification Methods Based on Image Classification
Image classification methods are widely used in computer vision analysis and offer significant advantages in terms of accuracy. Each pixel and its surrounding pixels need to be divided into a hyperspectral image block based on the block size set by the model before classification to enable feature extraction and model training. Zhong et al. [
12] proposed the spectral–spatial residual network (SSRN) that directly uses original three-dimensional (3D) cubes as input to learn discriminative features from spectral features and spatial contexts in hyperspectral images. Ma et al. [
13] introduced a double-branch multi-attention mechanism (DBMA) network, which applies two types of attention mechanisms to extract spectral and spatial features separately, ensuring the extraction of more discriminative features. Song et al. [
14] developed a deep feature fusion network (DFFN) that incorporates residual learning to optimize multiple convolutional layers as identity maps, simplifying the training of deeper networks. The long short-term memory (LSTM), as a special deep learning architecture, is highly capable of modeling in the spectral dimension. Hu et al. [
9] introduced the spatial–spectral convolutional LSTM 3D neural network (SSCL3DNN), which utilizes data blocks within a local sliding window as input for each storage unit, leveraging the capabilities of long short-term memory (LSTM) in modeling the spectral dimension.
Despite the remarkable classification accuracy achieved by these image classification methods, computational redundancy and the lack of global information learning in overlapping parts of adjacent blocks are inevitable. This is due to the requirement of dividing hyperspectral images into image blocks for model training.
2.2. Hyperspectral Image Classification Methods Based on Semantic Segmentation
Semantic segmentation is a fundamental task in computer vision, sharing similarities with hyperspectral image classification by assigning a classification label to each pixel in an image. Long et al. [
15] introduced the FCN, the first deep learning model utilized for semantic segmentation, which achieved remarkable success in the field by replacing the final fully connected layer of the image classification model with a 1 × 1 convolutional kernel and upsampling the image to the original size for segmentation output. Ronneberger et al. [
16] extended semantic segmentation to the medical domain and proposed U-Net, which integrates feature maps from different layers to capture varying sizes of information within an image. With the increasing popularity of the transformer architecture in computer vision, it has also been applied to semantic segmentation. Xie et al. [
17] put forward SegFormer, a semantic segmentation network consisting of a transformer-based encoder and a multilayer perceptron (MLP)-based decoder. It adopts the architecture of the transformer block in the vision transformer (ViT), improves the downsampling method to generate feature maps of different levels, and designs a more suitable lightweight decoder of transformer architecture designed to obtain a good segmentation effect with only a four-MLP architecture.
Although the goal of hyperspectral image classification is the same as semantic segmentation, it is infeasible to transfer the semantic segmentation model directly to hyperspectral image classification. Because of the difficulty of hyperspectral image acquisition, the dataset often has only one image, and the training samples are selected based on the whole image, resulting in highly sparse training samples. The irregularity of the spectral bands of each hyperspectral image dataset also leads to model input uncertainty.
To solve the above problem, Xu et al. [
18] suggested a spectral–spatial fully convolutional network (SSFCN) and a new mask matrix to assist in training for the sparse training samples of hyperspectral images. Zheng et al. [
19] proposed a fast patch-free global learning (FPGA) framework for hyperspectral image classification. The sampling strategy global stochastic stratified (GS2) transforms all training samples into stratified samples to solve the problem of the failure to converge during training. Moreover, in the design of the network, FPGA applies a spectral attention encoder based on the FCN with the addition of a lateral connection module to maximize the exploitation of the global spatial context information and can effectively improve model performance.
The sampling strategy of FPGA only focuses on the stratified samples during each training instance and does not balance the relationship between difficult and easy samples. When the sample data are unbalanced, it is challenging for FPGA to extract the most discriminative features. Addressing the problem of insufficient and imbalanced hyperspectral image samples, Zhu [
5] designed the spectral–spatial-dependent global learning framework (SSDGL). The framework uses a hierarchically balanced (H-B) sampling strategy and weighted softmax loss to solve the sample imbalance problem while introducing the global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) modules to extract the long short-term dependency of spectral features and feature representations in attention regions.
Niu et al. [
20] propose a novel semantic segmentation model (HSI-TransUNet) for crop mapping, which could make full use of the abundant spatial and spectral information of UAV HSI data simultaneously. The proposed HSI-TransUNet designed a spectral-feature attention module for spectral features aggregation in the encoder, and sub-pixel convolutions are adopted to avoid the chess-board effect in the segmentation results in the decoder. The proposed HSI-TransUNet has achieved good performance in crop classification. The 3D-CSAM-2DCNN proposed by Meng et al. [
21] automatically learned the spectral and spatial features of 14 rice varieties and deeply extracted them by u hybrid convolutional neural network structure. The 3D-CSAM-2DCNN attempts to optimize the model with the end-to-end trainable attention module and performed the best on the fine classification of rice varieties.
2.3. Current Research on the CNN and Transformer
The CNN, as a current mainstream deep learning architecture, has the powerful ability to extract local spatial information from hyperspectral images. However, CNNs encounter performance bottlenecks due to the difficulty of the CNN architecture to capture the spectral sequence information in hyperspectral images well, especially the global spectral similarity information. The CNN can focus too much on the spatial context information in the data, distorting the order of spectral feature learning and increasing the difficulty of mining complete spectral information.
Vaswani et al. [
11] found that the transformer architecture demonstrates powerful performance in natural language processing (NLP) tasks. Dosovitskiy et al. [
22] reflected on the use of the transformer architecture in NLP tasks and proposed the ViT, the first computer vision model based on the transformer architecture, which performed well in vision tasks.
In the application of hyperspectral image classification, Hong et al. [
23] observed the impressive capability of the transformer architecture in processing sequence information. To leverage this, they introduced a novel network for image classification known as SpectralFormer, which utilizes the transformer’s ability to learn local spectral sequence information from adjacent bands and generate group-wise spectral embeddings. Additionally, they designed a cross-layer skip connection to enable the transfer of memory-like components from shallow to deep layers through adaptive learning, effectively integrating the “soft” residuals across layers.
Nevertheless, the transformer architecture has the following drawbacks in the hyperspectral image classification methods based on semantic segmentation:
- (1)
The transformer architecture performs well in processing global sequence context information. However, it is inferior to the CNN in processing local spatial information, and each encoder in the ViT model outputs a feature map of the same size, which does not consider the multiscale features of the image and cannot be used directly as an encoder in semantic segmentation [
24].
- (2)
The model based on the transformer architecture has strong generalization after training. However, training the model with the transformer architecture often requires numerous training samples for good generalization. The small number of training samples and the unbalanced distribution of samples in hyperspectral image classification datasets make it difficult to train the model. A sampling strategy and training scheme must be fully adapted to the transformer architecture to obtain better results [
25].
2.4. Current Research on Insufficient and Imbalanced Samples
Hyperspectral image datasets are often limited to a single image, posing significant challenges to achieving high accuracy in hyperspectral image classification due to the scarcity of training samples. Pretrained deep learning networks offer a potential solution by leveraging knowledge from related domains. Yang et al. [
26] pretrained a CNN network with a two-channel architecture, preserving the trained bottom and middle layers while initializing the top layer randomly for specific data training. Pan et al. [
27] introduced the multi-grained network (MugNet) to address the spectral relationships between different bands using multi-grain scanning. They employed a semi-supervised approach in the convolution kernel generation process to maximize the utilization of finite samples. To exploit both spatial and spectral information effectively, Mei et al. [
10] devised a 3D convolutional autoencoder (3D-CAE) along with an auxiliary 3D convolutional decoder network. Their approach involved unsupervised training for the 3D convolutional decoder and used it to guide the training of the 3D-CAE.
For the hyperspectral image classification method used for crop classification, the following questions arise:
How should the model based on semantic segmentation consider the relationship between spectral bands?
How can we fully use the global and local information in the transformer-based model?
How can we solve the problem of insufficient and imbalanced samples in a hyperspectral image dataset?
To overcome the above problems, we propose HyperSFormer, a transformer-based end-to-end hyperspectral image classification method for crop classification.
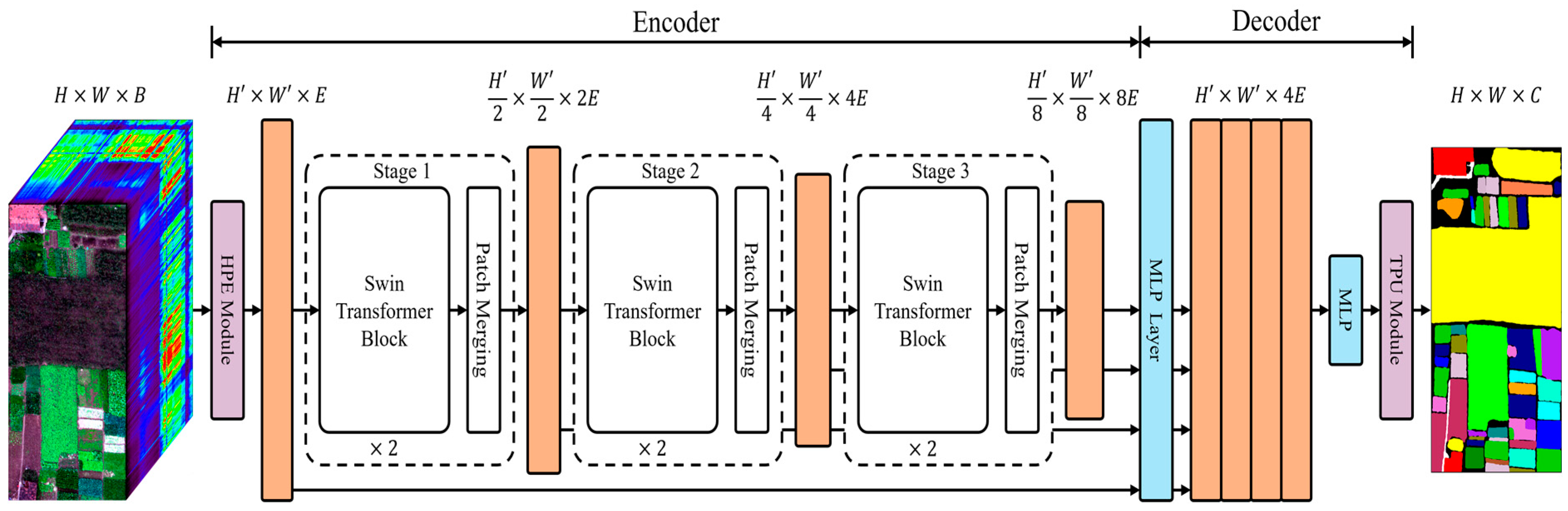
3. HyperSFormer
This section reviews knowledge of the classical transformer architecture and proposes the HyperSFormer method. The model is a complete end-to-end hyperspectral image classification model, which implements end-to-end image segmentation by learning the mapping
. As illustrated in
Figure 1, the model converts hyperspectral images into embedding vectors that are suitable for the Swin Transformer architecture through the HPE module. It initially extracts both local spatial and global spectral context information from the images. The uniquely designed Swin Transformer encoder extracts feature maps of various sizes and levels, which are then fused by the decoder using the improved SegFormer. This fusion allows for thorough learning of the spatial context information within different sample ranges. The inclusion of the TPU module preserves the original image size information during decoding, which is crucial for achieving end-to-end hyperspectral image classification. Additionally, the AMLS sampling strategy addresses the issue of insufficient and imbalanced training samples in the hyperspectral image classification dataset. To ensure fast model convergence, a loss function specifically tailored for hyperspectral image classification is designed.
3.1. Swin Transformer
The transformer architecture is a deep learning architecture utterly unlike the CNN and RNN and was first used in NLP. Due to its good results in dealing with sequence-to-sequence problems (e.g., machine translation and text summary generation), researchers have stopped using the RNN, which is a one-way-only sequence processing architecture, and enabled the model to capture global information at any position in the sequence through the powerful self-attention mechanism in the transformer [
28]. Beyond NLP, the computer vision field has also begun to re-evaluate the limitations of CNNs and explore the potential of the transformer architecture in improving model performance [
29].
The ViT pioneered using the transformer architecture for better results in computer vision [
24]. The model divides an image into blocks and encodes the position so that the image is transformed into the embedding vector that can be input into the transformer encoder while adding the cls embedding to the input to achieve the effect of image classification. The Swin Transformer proposed by Liu et al. [
30] is another great success of the transformer architecture in computer vision. After re-evaluating the limitations of the ViT model, the Swin Transformer employs shifted windows and a multi-level feature map design similar to that of the CNN model, achieving better results than the CNN-based model in tasks in computer vision (image classification, object detection, semantic segmentation, etc.). Because it is more suitable for extracting sequence information features, it has attracted increasing attention in video understanding, multimodal, and other fields. The transformer architecture provides a new solution and creative thinking for computer vision-related tasks.
The success of the transformer architecture heavily relies on the self-attention module for extracting internal information from the sequence. In contrast to CNN, the transformer encoder decreases its reliance on external information by stacking and integrating multiple self-attention modules, resulting in the formation of multihead self-attention (MSA). The specific pseudocode for the MSA module is provided in Algorithm 1.
| Algorithm 1 multi-head self-attention |
1: Input: : a sequence data, where has m length
2: : three transformation matrices of
3: : the number of multi-head
4: Output: Z: a sequence data
5:
6:
7:
8:
9: |
10: return |
However, the self-attentive module only operates on the encoded vector of the image and does not preserve the location information. This module has specific restrictions on the information extraction of image data containing local information; therefore, the ViT conducts position coding to retain image position information when patch embedding. The Swin Transformer improves based on the ViT and retains position information through relative position encoding for each pixel during MSA. Additionally, the Swin Transformer adopts a patch merging module to achieve a hierarchical architecture similar to that of a CNN, thereby allowing the model to effectively handle images of varying scales. This approach involves creating a new image by selecting elements at regular intervals in the row and column directions, resulting in a reduced length and width. Subsequently, all merged images pass through a fully connected layer to alter the channel size from four times the original to twice the original dimensions. For a visual representation of this specific implementation, refer to
Figure 2.
The Swin Transformer divides the input image into non-overlapping windows of a fixed size and performs MSA calculations on various windows to achieve the window MSA (W-MSA) operation to reduce the computational effort. The W-MSA makes the complexity of the model in computation linear only for the height and width of the image. The computational complexity of the W-MSA operation and MSA operation on an image with a size of
and number of channels
is as follows:
Although W-MSA can reduce the computational complexity of the transformer architecture, the lack of information communication between non-overlapping windows loses the ability to extract global information using MSA. Thus, the shifted window MSA (SW-MSA) operation is introduced to realize the information between windows. As depicted in
Figure 3, SW-MSA shifts the original division by half the window size in two adjacent Swin Transformer blocks to obtain the new division.
However, this operation presents an additional challenge in terms of computational complexity, as depicted in
Figure 3. This change results in an increase in the utilization of the MSA module from four to nine times. To address this issue, the cyclic shift operation is employed. It concatenates the windows that would otherwise have been divided prior to conducting the SW-MSA process. By doing so, the computational complexity remains unchanged while effectively facilitating information interaction across different windows.
3.2. SegFormer
In previous research on semantic segmentation models, most of the work investigates how to design better decoders (e.g., adding more feature map fusion patterns), which leads to increasingly larger decoders for the models. With the growing utilization of the Transformer architecture in computer vision, its application of serialized feature vectors allows for a reduction in decoder architecture complexity. SegFormer presents a straightforward, efficient, and resilient semantic segmentation model. It employs an encoder based on the transformer architecture and a decoder comprising only a few MLPs. This model achieves state-of-the-art (SOTA) performance on well-established semantic segmentation datasets such as ADE20K and Cityscapes, all while considering segmentation speed. Similarly, SegFormer delivers remarkable results, showcasing improved robustness, on datasets contaminated with various forms of noise, such as Cityscapes-C.
In SegFormer, the encoder generates a sequence of feature vectors as its output. To handle feature sequences of different scales, the feature sequence is expanded into a feature map, which is only one-fourth the size of the original image, using the MLP architecture. The transformed feature maps from each level are then merged, followed by channel reduction through an MLP, resulting in segmented categories for obtaining the prediction results. The decoder architecture in SegFormer solely comprises the MLP, avoiding the introduction of complex operations such as dilated convolution or bidirectional feature pyramid network (Bi-FPN). This design choice ensures the efficiency and effectiveness of the decoder operation.
3.3. Hyper Patch Embedding and Transpose Padding Upsample Module
In the Swin Transformer, the RGB image of size is transformed into tokens of size through patch embedding. These tokens are then inputted into the Swin Transformer block. Specifically, the image is first divided into square patches using two-dimensional convolution, with each patch having a patch size of 4 × 4. These patches are then concatenated as individual tokens and fed into the model.
Unlike the Swin Transformer, which processes dissimilar discrete sequences as input features, hyperspectral images contain data obtained from densely sampled spectral channels across the electromagnetic spectrum. It is common for neighboring channels in hyperspectral images to exhibit similarities due to the tiny sampling intervals. The crucial aspect for accurate classification of hyperspectral images lies in capturing the most expressive features from the nearly continuous spectral information.
Therefore, the hyper patch embedding (HPE) module is added before the input Swin Transformer block in this paper. The implementation process of the entire HPE is illustrated in
Figure 4. Given a hyperspectral image, as shown in the “Patch” operation of
Figure 4, we initially apply a two-dimensional convolution to extract local spatial features with a patch size of
. This process simultaneously extracts spectral features while reducing the channel dimension to the size of
. To ensure the model’s generalizability across different datasets, we perform a “Pad” operation on the hyperspectral image, resulting in
and
and satisfying the following equation:
Here, refers to the sliding window size designed in the Swin Transformer block, and is determined by the three downsampling operations performed by the model. Finally, the padded hyperspectral image is passed through a simple multilayer perceptron (MLP) to capture the global spatial context at the initial stage of the model. Subsequently, the image is unfolded and normalized before being fed as input to the encoder.
Given all of the features in a hyperspectral image, the local spatial features are extracted according to a predefined , and each patch is considered a token. The number of channels of spectral features is reduced from the original number of channels to the to extract spectral features. Furthermore, to ensure model adaptability to arbitrary datasets, the height and width of the extracted hyperspectral image must be padded to satisfy certain conditions.
Finally, the filled hyperspectral image is completed once with MLP operation, and the images in each extracted spectral feature are expanded and normalized as the encoder input. The details are provided in
Figure 4.
After the lightweight encoder in SegFormer, bilinear interpolation restores the fused feature map of the decoder to its original size. This method can significantly improve the efficiency of model segmentation for the semantic segmentation task of RGB images, but it is not applicable to the hyperspectral image classification task. In hyperspectral image classification, because the images are taken using remote sensing techniques, one pixel often represents a large piece of the actual area, and the prediction results must be accurate to the pixel level.
In this paper, we designed the transpose padding upsample (TPU) module based on the output of the decoder in SegFormer. The fused feature map can be restored to the original size of the image using the TPU module.
Figure 5 illustrates the details of the TPU module. In this module, we first extract features between pixels surrounding the original pixels in different channels through the “Transpose” operation. Specifically, the feature maps are enlarged by
times, and the channel dimension is halved, which can be achieved using two-dimensional convolution. Subsequently, the enlarged image is cropped back to its original size using the “Cut” operation. Finally, a simple MLP is employed to map the channel dimension to the number of classes,
, enabling end-to-end prediction.
3.4. Adaptive Min Log Sampling Strategy and Loss Function
The problem of insufficient and imbalanced training samples in hyperspectral image classification has been a critical problem to be solved in this field. The number of labeled samples in each category varies widely. When the traditional sampling strategy is used, where a fixed number of samples are randomly selected from all samples in each category as training samples, it leads to a significant limitation in the average and overall model accuracy due to the imbalance between the number of training samples. To make the model learn more discriminative features and enhance the robustness of model classification, the sampling strategy of adaptive min log sampling (AMLS) is used, formally described in Algorithm 2.
| Algorithm 2 adaptive min log sampling |
: a set of labels for training
: the number of class where not included negative classes
: the Sampling magnification
: mini-batch per class
: a list of sets of stratified labels
: an empty list
7: for k = 0 to N do
the number of
10: end for
the minimum of
12: for k = 0 to N do
|
Randomly sample samples from
16: end for
17: repeat
18: for k = 0 to N do
21: end for |
In the AMLS strategy, the training samples are taken from the whole image rather than the divided image blocks. Discrete training sample sequences are extracted from the entire hyperspectral image according to the above algorithm, and other samples that are not selected as training samples are used as testing samples. The training samples are randomly selected from the training sample sequence during training to reduce the training time and improve the model robustness. Most current models only consider the positive samples in the image during training. However, they do not consider the unlabeled negative samples in the image, leading to the possibility of misclassifying some negative samples as positive samples during classification and making the final generated prediction images less accurate. In the strategy proposed in this paper, negative samples are uniformly labeled as Class 0. Before sampling, one must iterate over the sample count of each class and store the indices of each class’s samples in the corresponding list. Then, based on the class with the minimum sample count and the sampling factor , the number of training samples for each sample is determined as . Using the training sample count for each sample, training samples are randomly selected from the list of each class to obtain the training sample sequence for the hyperspectral image. In each subsequent epoch of training, samples are randomly selected from for training, based on and the hyperparameter . Here, the aforementioned sampling factor is determined by the class with the minimum sample count and the dataset. By using the formula, it can be observed that when calculating the training sample count for the class with the minimum sample count, is equal to 1, resulting in being . By referring to relevant literature on the dataset, the commonly used sample count for the class with the minimum sample count during training is obtained, and the sampling factor is determined accordingly. The hyperparameter mentioned above is determined per training epoch. In this study, the hyperparameter is set to 0.2.
Similarly, in hyperspectral image classification, the selected training sample size is logarithmically calculated to dilute the gap between the original sample sizes. However, due to the massive gap between the number of original samples in some datasets, the problem of slow convergence caused by the gap between the number of samples in different categories must still be considered during training. A loss function more suitable for hyperspectral image classification is designed in this paper to address the above problems. The specific formula is as follows:
In hyperspectral image classification, the architecture between pixel points is strongly regionally correlated, and the same categories tend to be clustered together, with clear demarcations between categories. Thus, the pixel loss and gradient update are related to the predicted and actual values of that point and other points around that point. Milletari et al. [
31] proposed dice loss to calculate this strong correlation loss, and dice loss is very effective in balancing positive and negative samples to identify the foreground and background regions of an image effectively. The specific formula is as follows:
where
is the probability that all training samples predict category
,
is the actual value of all training samples (i.e., those not for category
have a value of
and those for category
have a value of
).
An improved binary cross entropy (BCE) loss called focal loss [
32] was used for the sample gap between classes of hyperspectral images. By adding sample size weights before the BCE loss, the model reduces the weight of easily classifiable samples and focuses more on the difficult-to-classify samples during training.
Specifically, we define
as the weight for balancing difficult samples, calculated as follows:
where
represents the point in the training sample when the actual value of the point is category
and
takes the value of the predicted probability of the point; otherwise, it is
minus the predicted probability of the point. In general, the formula can be written as follows when calculating
for that category:
Therefore, the specific formula of focal loss is given as follows:
where
is an adjustable parameter to adjust the ratio of the difficult and easy weights, and in this paper,
is set to 2. In the formula for the total loss function,
is used to adjust the weights between the two loss functions, and
is set to 0.7.
With the above loss function, the AMLS strategy ensures a balanced distribution of categories in the training samples while obtaining stable and diverse gradients by sampling small batches. The designed loss function can consider both positive and negative samples while distinguishing between difficult and easy samples, ensuring the stability and randomness of the gradient and accelerating the training speed.
5. Discussion
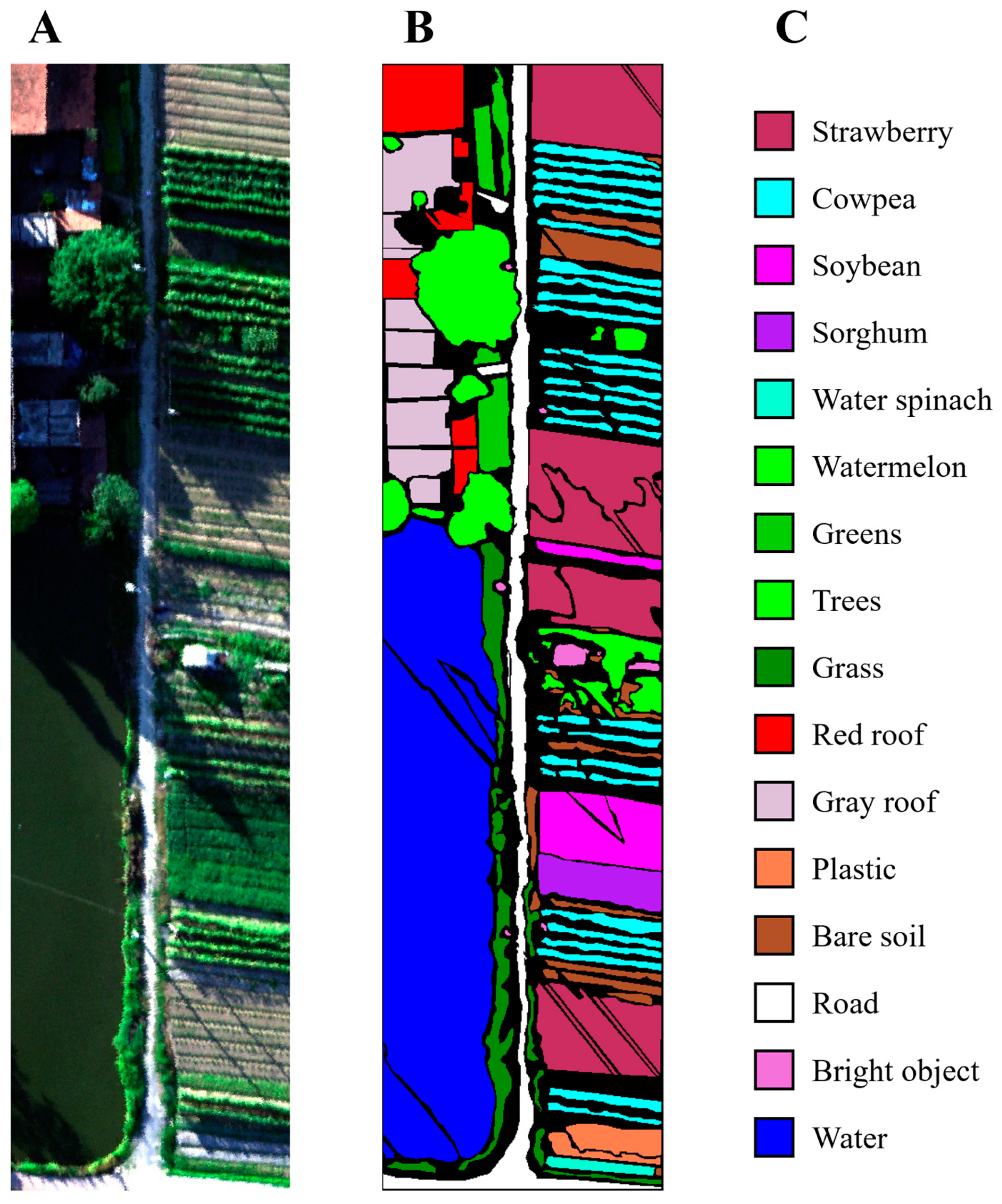
We conducted extensive analytical experiments on each parameter setting to understand the effectiveness of the HyperSFormer model parameter settings better. All analytical experiments were performed on the Indian Pines dataset with low spatial resolution and unbalanced sample data.
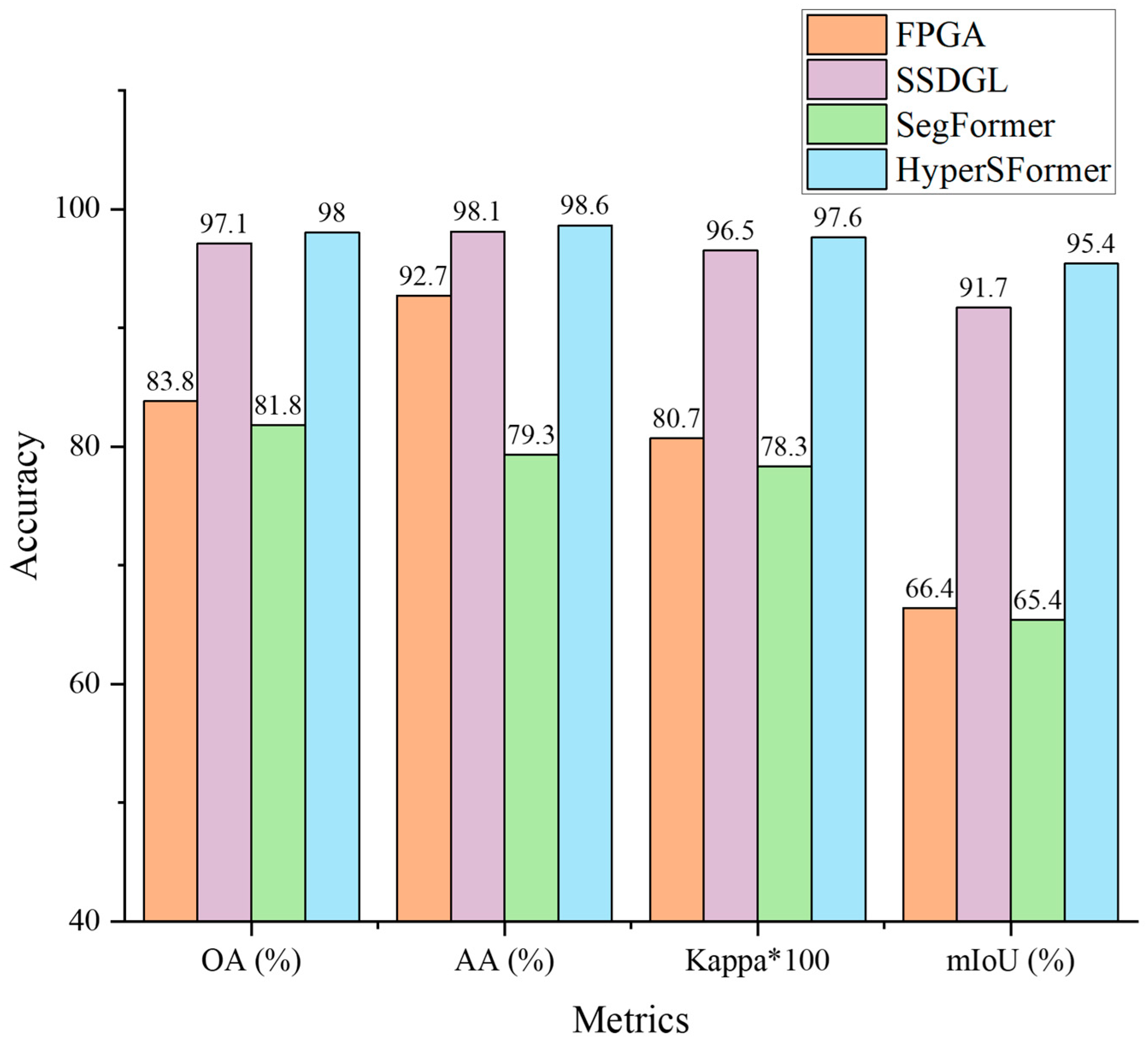
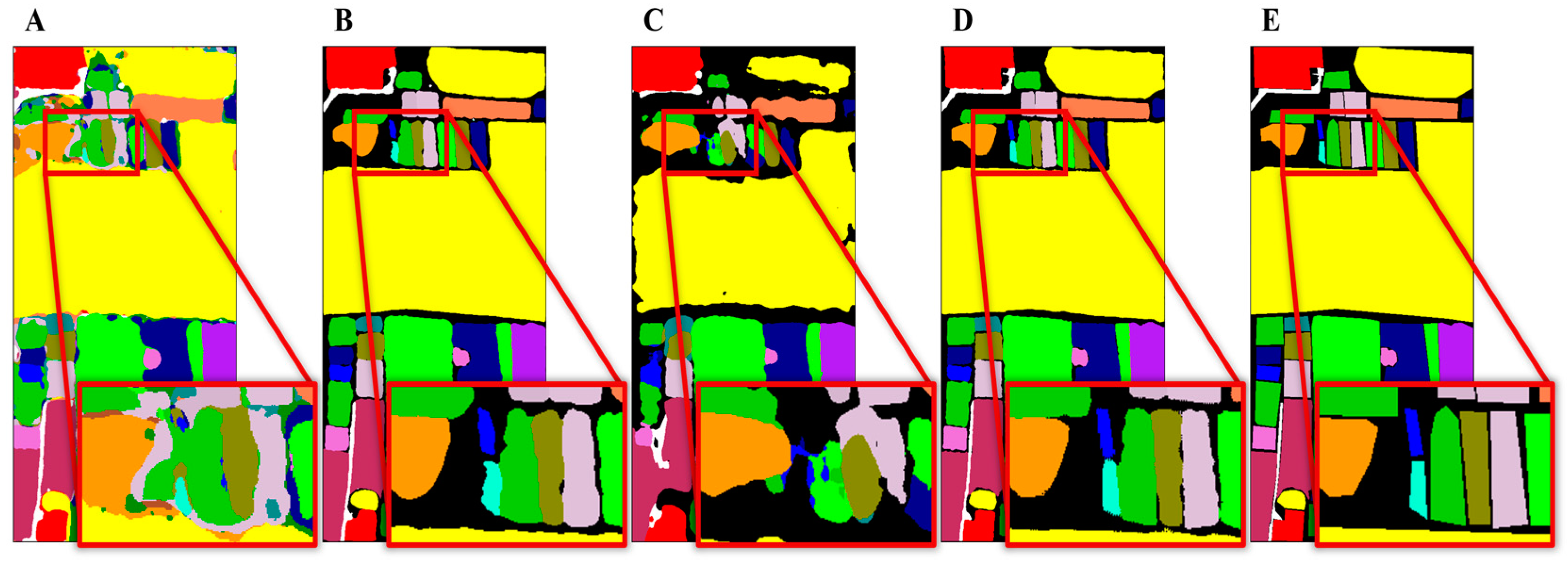
5.1. Discussion of Different Models
Table 2 displays a comparative analysis of our model against several semantic segmentation models. Evidently, the computational complexity associated with transformer-based architectures is predominantly lower in comparison to their CNN-based counterparts. HyperSFormer manages to maintain reduced computational complexity while simultaneously minimizing the number of parameters involved.
5.2. Discussion of the HPE Parameters
Table 3 delineates the classification performance of the model using various combinations of hyperparameters. The benchmark method encompasses the model parameter configurations utilized in the preceding section. In contrast to the model devoid of the HPE module, the model incorporating the HPE module exhibits superior classification capacity for both positive and negative instances, culminating in a higher AA compared to its counterpart without the HPE module.
The hyperparameter
is the unit for chunking images in the HPE module.
Table 3 reveals that the model works best when the
is set to 2 because the model initially extracts the neighboring spatial features in the hyperspectral images in the HPE. If the
is too large, the model focuses too much on the surrounding features instead of those that should be extracted, degrading classification accuracy. If the
is set to 1, the model only learns its own channel information and not the neighboring spatial features, which also decreases classification accuracy.
The hyperparameter
is introduced in the HPE module to determine the number of compressed channels in the spectral space and is also the basic unit of vector dimensionality in the Swin Transformer block.
Table 3 indicates that when
is lower or higher, the model does not perform as well as when it is set to 64 because when set low, the limited number of channels is too small to learn all spatial and spectral features. When
is set high, the model becomes too redundant, making the model too scattered in feature learning, focusing on features that should not be focused on, and causing the training time to increase significantly.
5.3. Discussion of the Loss
Table 4 presents the effect of training HyperSFormer using various loss functions to demonstrate the reasonableness of the loss function settings. The hyperparameter
is used to set the ratio between the dice loss and focal loss.
Table 4 reveals that training the model with cross-entropy loss and focal loss results in higher AA metrics than OA metrics in the final results of the model, indicating that the two loss functions are good at classifying each class. The model focuses on both difficult- and easy-to-classify samples but not enough for the overall classification effect, and it cannot effectively balance the gap between positive and negative samples. Moreover, the model is better trained using the focal loss than cross-entropy loss, which is consistent with the setting, where it is a cross-entropy loss improvement algorithm. In addition,
Table 4 reveals that the OA with only dice loss is much higher than AA because the dice loss focuses on the background information in the sample in addition to the foreground information and determines the most discriminative features from the positive and negative samples.
In the fused loss function of dice loss and focal loss proposed in this paper, the overall classification performance using the fused loss function is better than that of the single loss function. Adding focal loss compensates for the lack of discriminative power of using the dice loss for difficult-to-classify samples. The value of does not have a substantial influence on the classification performance but still plays a key role, and the model is best trained when is 0.7.
5.4. Discussion of the Sampling Strategy
Table 5 presents the comparison of sample counts and validation results using the HyperSFormer architecture combined with different sampling strategies. Among them, global stochastic stratified (GS
2) is the sampling strategy used in FPGA, where it simply selects 100 samples for each class for training. If there are fewer than 100 samples, all samples of that class are used for training. The hierarchically balanced (H-B) sampling strategy is used in SSDGL, where it randomly selects 5% of the sample count for each class as training samples. For classes with fewer than five samples after computation, five samples are randomly selected for training. From the data in
Table 5, it can be observed that the AMLS sampling strategy selects significantly fewer training samples compared to GS
2 and H-B. In terms of the distribution of training samples, GS
2 does not consider the imbalance between different classes, while H-B only selects training samples based on the sample count of each class. This can result in inconsistent convergence speeds and larger loss weights for certain classes due to the imbalance in training samples. AMLS takes both factors into consideration by not only selecting training samples based on sample counts but also balancing the sample disparities between different classes using the class with the minimum sample count as the reference. Experimental results demonstrate that the AMLS sampling strategy achieves higher mIoU with fewer training samples.
5.5. Discussion of the HyperSFormer
The HyperSFormer proposed in this study demonstrates the effective utilization of hyperspectral images for end-to-end crop classification. This model, based on the transformer, fully incorporates both global and local spatial context as well as spectral information. The AMLS sampling strategy and fusion loss function are designed to ensure the consideration of positive and negative samples, as well as difficult and easy samples.
Although the learning-rate decay method of cosine annealing is employed in this approach, the model training still suffers from instability, and the convergence rate is marginally slower than that of the CNN-based method. Additionally, the model parameters are not yet generalized across datasets in terms of their application. To address these limitations, a future investigation will focus on developing a generalized hyperspectral image classification method, enabling the reuse of model parameters across datasets. Furthermore, training strategies will be explored to enhance the speed of model convergence.
6. Conclusions
The present study introduces HyperSFormer, a crop classification method utilizing the Transformer and semantic segmentation in hyperspectral image analysis. In HyperSFormer, we replace the encoder of SegFormer with an enhanced Swin Transformer while preserving the SegFormer decoder. The entire model is characterized by a streamlined and unified transformer structure. Additionally, an HPE module and TPU module are incorporated into the model to enhance its capacity to capture global spatial context and spectral information. To address the issues of inadequate and imbalanced samples in hyperspectral image classification, we devise the AMLS strategy and a loss function that combines dice loss and focal loss, facilitating model training. Experimental findings demonstrate that HyperSFormer outperforms existing methods in terms of hyperspectral image classification, particularly when dealing with complex negative samples and mixed sample classes. Ablation experiments confirm the soundness of the model parameter design, showing that the selected parameters lead to optimal performance. Notably, the fusion loss in the designed loss function contributes significantly to the improvement. The proposed method, compared to CNN-based approaches, aligns better with the characteristics of hyperspectral images, enabling accurate hyperspectral image classification and widening the application prospects of hyperspectral image analysis in agricultural production.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}