
MASA-SegNet: A Semantic Segmentation Network for PolSAR Images
 and
and
Abstract
:
1. Introduction
- -
- We propose two methods for pseudo-color synthesis of PolSAR images; these are used as pre-processing methods for single-polarization and multi-polarization SAR images. The aim is to reduce the interference of noise and increase the readability of images as much as possible prior to executing segmentation tasks.
- -
- We design a feature extractor for PolSAR images. The feature map is serialized along two axes to calculate both global and local attention, thereby extracting important spatial feature information and reducing noise interference.
- -
- We propose MASA-SegNet, which is a novel multi-axis sequence attention semantic segmentation network that deploys an encoder–decoder structure to achieve effective semantic segmentation. The encoder of MASA-SegNet consists of multi-level feature extraction, and the decoder is constructed with convolution and linear interpolation upsampling. This network architecture demonstrates excellent performance with PolSAR datasets.
2. Materials and Methods
2.1. Datasets
2.1.1. Single-Polarization SAR Data
2.1.2. Multi-Polarization SAR data
2.2. Methodology
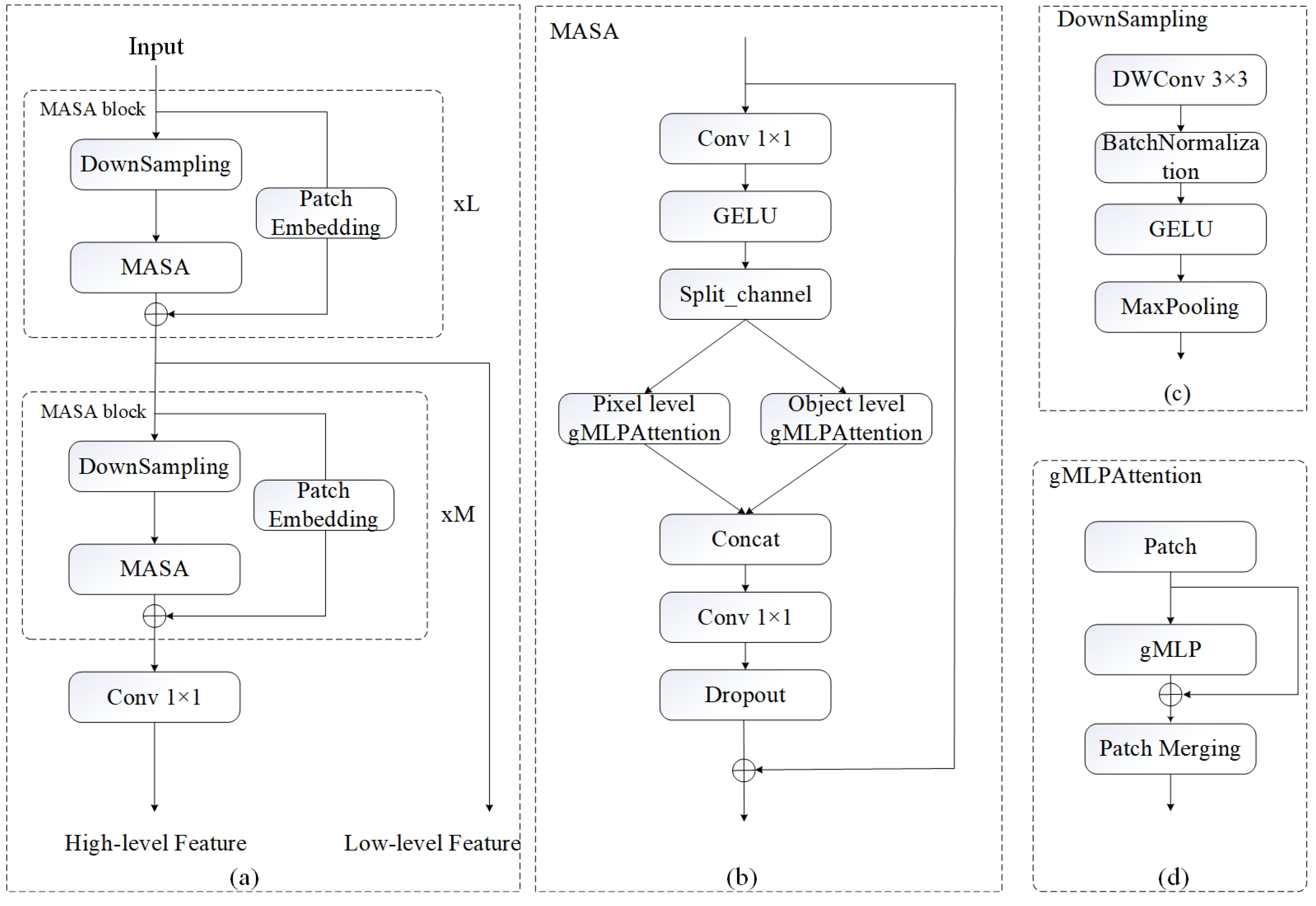
2.2.1. Framework of MASA-SegNet
2.2.2. PolSAR Image Feature Extraction
- Pixel-level sequence attention: In the pixel-level attention axis, the feature with a size of is serialized into a sequence of tensors with a shape of , and the pixel of each block is , as shown in Figure 5a.
- Region-level sequence attention: In the region-level attention axis, the entire feature map is divided into sequence windows with a shape of , and the size of each window is , as shown in Figure 5b.
2.3. Network Details
2.3.1. Encoder
2.3.2. Decoder
3. Experiments and Results
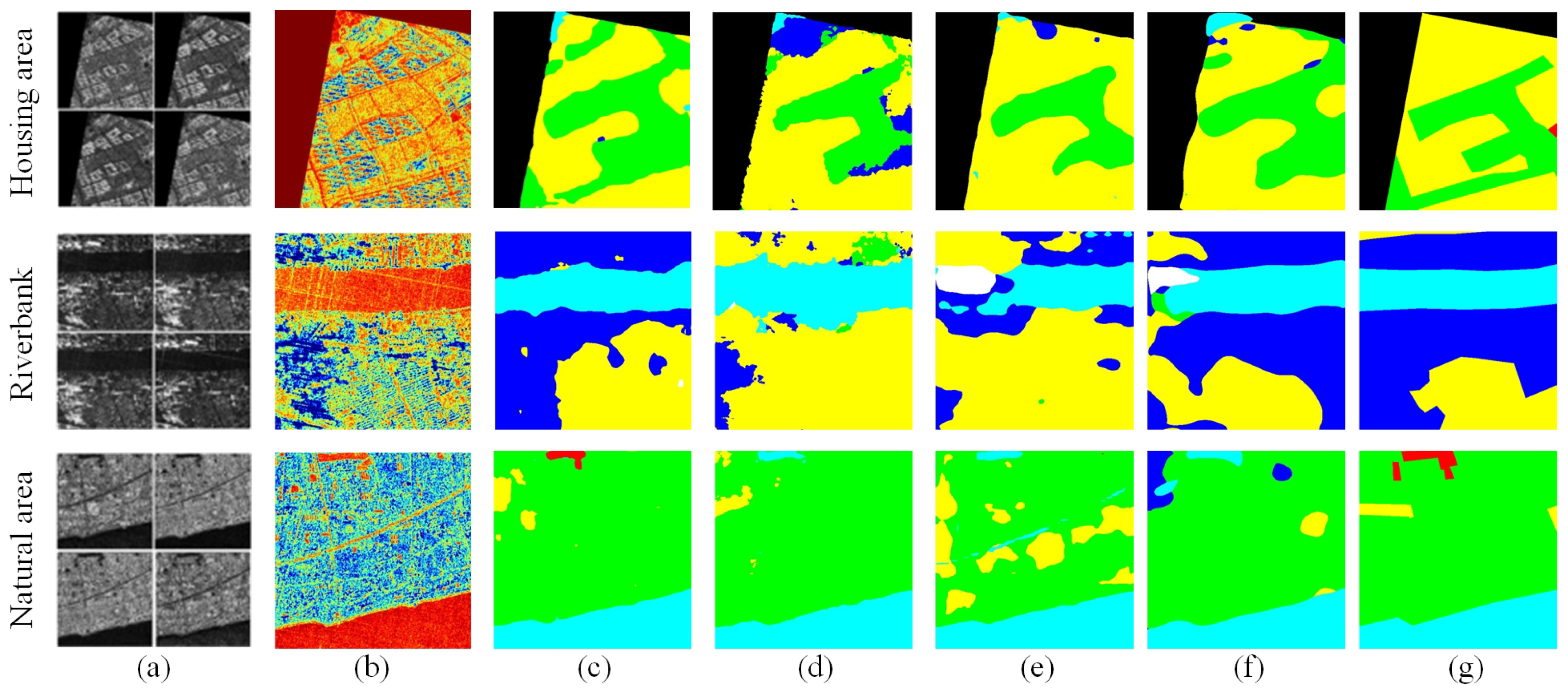
3.1. Experiments on FUSAR-MAP Dataset
3.2. Experiments on AIR-PolSAR-Seg Dataset
3.3. Ablation Study
4. Discussion
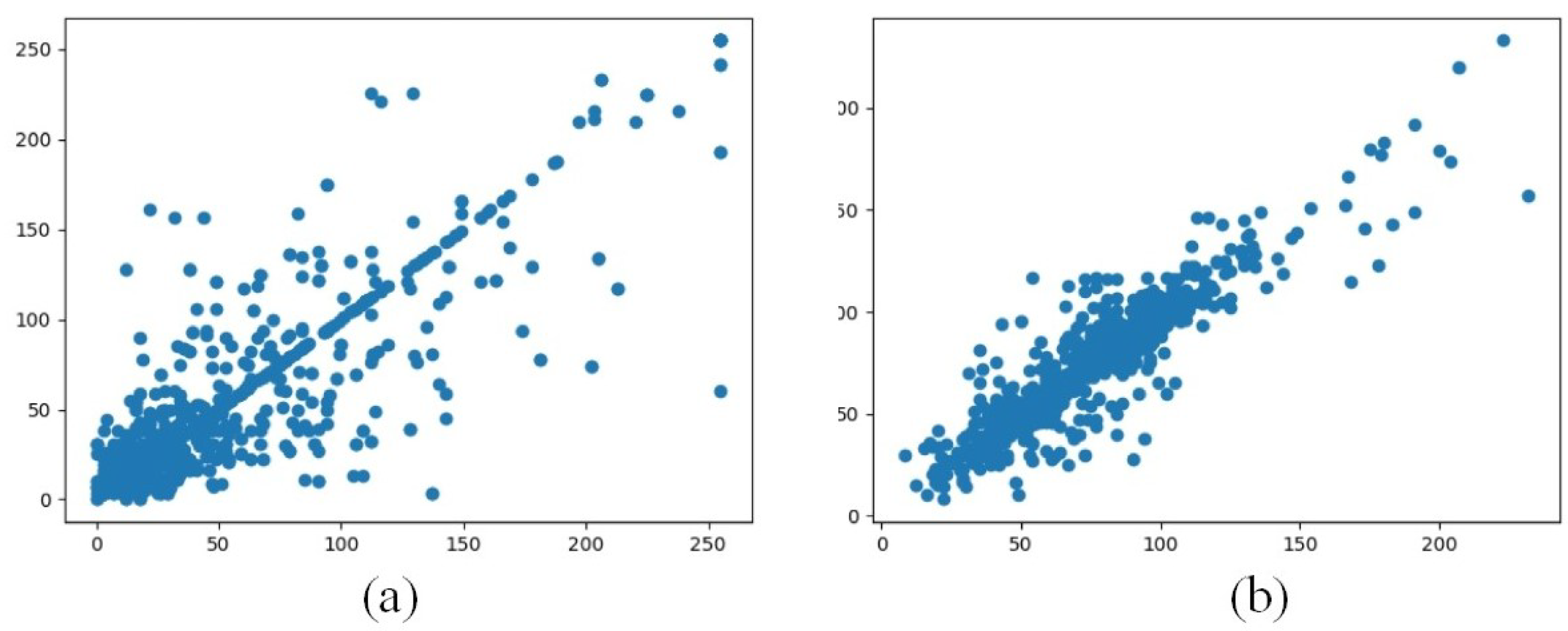
4.1. Analysis of Data Preprocessing Effects
4.2. Effect of Feature Extractor on PolSAR
4.3. Advantages of Framework
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| SAR | Synthetic Aperture Radar |
| PolSAR | Polarimetric Synthetic Aperture Radar |
| MASA-SegNet | Multi-axis Sequence Attention Segmentation Network |
| MASA | Multi-axis Sequence Attention |
| SVM | Support Vector Machine |
| CNNs | Convolutional Neural Networks |
| ViT | Vision Transformer |
| gMLP | Multilayer Perceptron with gate |
| IoU | Intersection over Union |
| mIoU | Mean Intersection over Union |
| FWIoU | Frequency Weighted Intersection over Union |
| RLF | Refined Lee Filter |
| OA | Overall Accuracy |
| QPSI | Quad-Polarization Strip Map |
| DW-Conv | Depthwise Separable Convolution |
| GLUE | Gaussian Error Linear Units |
| SGD | Stochastic Gradient Descent |
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.-S.; Jurkevich, L.; Dewaele, P.; Wambacq, P.; Oosterlinck, A. Speckle filtering of synthetic aperture radar images: A review. Remote Sens. Rev. 1994, 8, 313–340. [Google Scholar] [CrossRef]
- Ayed, I.B.; Mitiche, A.; Belhadj, Z. Multiregion level-set partitioning of synthetic aperture radar images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 793–800. [Google Scholar] [CrossRef] [PubMed]
- Parihar, N.; Das, A.; Rathore, V.S.; Nathawat, M.S.; Mohan, S. Analysis of l-band sar backscatter and coherence for delineation of land-use/land-cover. Int. J. Remote Sens. 2014, 35, 6781–6798. [Google Scholar] [CrossRef]
- Haldar, D.; Das, A.; Mohan, S.; Pal, O.; Hooda, R.S.; Chakraborty, B. Assessment of l-band sar data at different polarization combinations for crop and other landuse classification. Prog. Electromagn. Res. B 2012, 36, 303–321. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, S. Decision fusion of sparse representation and support vector machine for sar image target recognition. Neurocomputing 2013, 113, 97–104. [Google Scholar] [CrossRef]
- Beijma, S.V.; Comber, A.; Lamb, A. Random forest classification of salt marsh vegetation habitats using quad-polarimetric airborne sar, elevation and optical rs data. Remote Sens. Environ. 2014, 149, 118–129. [Google Scholar] [CrossRef]
- Luo, S.; Tong, L.; Chen, Y. A multi-region segmentation method for sar images based on the multi-texture model with level sets. IEEE Trans. Image Process. 2018, 27, 2560–2574. [Google Scholar] [CrossRef]
- Bi, H.; Xu, L.; Cao, X.; Xue, Y.; Xu, Z. Polarimetric sar image semantic segmentation with 3d discrete wavelet transform and markov random field. IEEE Trans. Image Process. 2020, 29, 6601–6614. [Google Scholar] [CrossRef]
- Bianchi, F.M.; Espeseth, M.M.; Borch, N. Large-scale detection and categorization of oil spills from sar images with deep learning. Remote Sens. 2020, 12, 2260. [Google Scholar] [CrossRef]
- Jaturapitpornchai, R.; Matsuoka, M.; Kanemoto, N.; Kuzuoka, S.; Ito, R.; Nakamura, R. Newly built construction detection in sar images using deep learning. Remote Sens. 2019, 11, 1444. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for sar ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Cao, H.; Zhang, H.; Wang, C.; Zhang, B. Operational flood detection using sentinel-1 sar data over large areas. Water 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric sar imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. A deep neural network for oil spill semantic segmentation in sar images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3773–3777. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Zou, B.; Xu, X.; Zhang, L. Object-based classification of polsar images based on spatial and semantic features. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 609–619. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 12 October 2021; pp. 10012–10022. [Google Scholar]
- Sun, J.; Zhang, J.; Gao, X.; Wang, M.; Ou, D.; Wu, X.; Zhang, D. Fusing spatial attention with spectral-channel attention mechanism for hyperspectral image classification via encoder–decoder networks. Remote Sens. 2022, 14, 1968. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, L.; Zou, B. Exploring vision transformers for polarimetric sar image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5219715. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Bhattacharya, A.; Ghamisi, P. Local window attention transformer for polarimetric sar image classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4004205. [Google Scholar] [CrossRef]
- Liu, X.; Wu, Y.; Liang, W.; Cao, Y.; Li, M. High resolution sar image classification using global-local network structure based on vision transformer and cnn. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4505405. [Google Scholar] [CrossRef]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. Crtranssar: A visual transformer based on contextual joint representation learning for sar ship detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Zhao, S.; Luo, Y.; Zhang, T.; Guo, W.; Zhang, Z. A domain specific knowledge extraction transformer method for multisource satellite-borne sar images ship detection. ISPRS J. Photogramm. Remote Sens. 2023, 198, 16–29. [Google Scholar] [CrossRef]
- Liu, H.; Dai, Z.; So, D.; Le, Q.V. Pay attention to mlps. Adv. Neural Inf. Process. Syst. 2021, 34, 9204–9215. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxim: Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Istanbul, Turkey, 28–29 January 2022; pp. 5769–5780. [Google Scholar]
- Wang, Z.; Zeng, X.; Yan, Z.; Kang, J.; Sun, X. Air-polsar-seg: A large-scale data set for terrain segmentation in complex-scene polsar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3830–3841. [Google Scholar] [CrossRef]
- Shi, X.; Fu, S.; Chen, J.; Wang, F.; Xu, F. Object-level semantic segmentation on the high-resolution gaofen-3 fusar-map dataset. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3107–3119. [Google Scholar] [CrossRef]
- Yommy, A.S.; Liu, R.; Wu, S. Sar image despeckling using refined lee filter. In Proceedings of the 2015 7th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2015; Volume 2, pp. 260–265. [Google Scholar]
- Toet, A.; Walraven, J. New false color mapping for image fusion. Opt. Eng. 1996, 35, 650–658. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Computer Vision–ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018, Proceedings, Part VII 15; Springer: Berlin/Heidelberg, Germany, 2018; pp. 833–851. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, T.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D.B. How much position information do convolutional neural networks encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Terrain Category/IOU(%) | mIoU | FWIoU | OA | |||
|---|---|---|---|---|---|---|---|
| Water | Road | Building | Vegetation and Others | ||||
| U-Net [37] | 81.93 | 13.02 | 22.06 | 56.70 | 43.43 | 57.34 | 66.92 |
| SegNet [38] | 79.40 | 6.44 | 11.79 | 56.46 | 38.52 | 54.76 | 64.78 |
| VGG-SegNet [38] | 82.22 | 7.85 | 28.55 | 57.49 | 44.03 | 59.21 | 68.26 |
| DeepLabv3+ [36] | 85.87 | 13.72 | 32.60 | 58.30 | 47.62 | 62.23 | 72.02 |
| FUSAR-Map [30] | 88.28 | 25.26 | 35.15 | 60.55 | 52.31 | 66.59 | 75.80 |
| MASA-SegNet | 88.68 | 25.56 | 27.28 | 61.27 | 50.70 | 75.94 | 79.67 |
| Methods | Terrain Category/IOU (%) | mIoU | FWIoU | OA | |||||
|---|---|---|---|---|---|---|---|---|---|
| Industrial Area | Natural Area | Land Use | Water | Housing | Other | ||||
| FCN [39] | 37.78 | 71.58 | 1.24 | 72.76 | 67.69 | 39.05 | 48.35 | 53.21 | 76.28 |
| ANN [40] | 41.23 | 72.92 | 0.97 | 75.95 | 68.40 | 56.01 | 52.58 | 61.54 | 77.46 |
| U-Net [37] | 42.17 | 73.83 | 0.96 | 75.52 | 67.19 | 53.28 | 52.12 | 62.12 | 77.29 |
| DeepLabv3+ [36] | 40.62 | 70.67 | 0.55 | 72.93 | 69.96 | 34.53 | 48.21 | 56.24 | 76.81 |
| DANet [41] | 39.56 | 72.00 | 1.00 | 74.95 | 67.79 | 56.28 | 51.93 | 58.73 | 76.91 |
| PSPNet [42] | 40.70 | 69.46 | 1.33 | 69.46 | 68.75 | 32.68 | 47.14 | 56.95 | 76.21 |
| EncNet [43] | 32.95 | 71.59 | 1.89 | 75.66 | 67.16 | 37.24 | 47.75 | 57.68 | 75.67 |
| NonLocal [44] | 35.51 | 71.12 | 2.47 | 70.60 | 68.39 | 16.31 | 44.23 | 53.43 | 76.05 |
| FUSAR-Map [30] | 38.52 | 74.09 | 1.94 | 68.17 | 62.88 | 47.63 | 55.45 | 60.61 | 74.42 |
| MASA-SegNet | 45.00 | 74.79 | 7.91 | 74.36 | 66.87 | 56.58 | 54.25 | 65.54 | 77.60 |
| Method | mIoU | FWIoU | OA |
|---|---|---|---|
| None-MASA | 47.955 | 60.22 | 73.78 |
| MASA-SegNet | 54.25 | 65.54 | 77.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Yang, S.; Gao, X.; Ou, D.; Tian, Z.; Wu, J.; Wang, M. MASA-SegNet: A Semantic Segmentation Network for PolSAR Images. Remote Sens. 2023, 15, 3662. https://doi.org/10.3390/rs15143662
Sun J, Yang S, Gao X, Ou D, Tian Z, Wu J, Wang M. MASA-SegNet: A Semantic Segmentation Network for PolSAR Images. Remote Sensing. 2023; 15(14):3662. https://doi.org/10.3390/rs15143662
Chicago/Turabian StyleSun, Jun, Shiqi Yang, Xuesong Gao, Dinghua Ou, Zhaonan Tian, Jing Wu, and Mantao Wang. 2023. "MASA-SegNet: A Semantic Segmentation Network for PolSAR Images" Remote Sensing 15, no. 14: 3662. https://doi.org/10.3390/rs15143662