5.4. Performance Evaluation
In this section, the effectiveness of the proposed method is evaluated by comparing it with classical image classification networks on the CIFAR-10 and FGSCR-10 datasets. The validation results are shown in
Table 2 and
Table 3. The bold typeface represents the best results, while underlining represents the second-best results.
In
Table 2 and
Table 3, two metrics were used to evaluate the classification performance, as well as to compare the four classical classification networks and two fine-grained image classification networks with the E-FPN. The proposed method was evaluated on the CIFAR-10 dataset using two metrics—OA and Kappa. The results indicate that the E-FPN achieved excellent performance in both metrics, with an OA of 94.78% and a Kappa value of 0.945, thereby obtaining the second-best and best scores, respectively. This demonstrates the effectiveness of the E-FPN with respect to the traditional natural image dataset.
In the FGSCR-10 dataset, the proposed method achieved an OA of 98.04% and a Kappa value of 0.9776. Compared to the other four classical methods, the E-FPN showed an improvement in the OA that ranged from 1.15% to 3.95% and an improvement in the Kappa metric that ranged from 0.0095 to 0.044. When compared with the other two fine-grained image classification algorithms, the E-FPN also achieved excellent results with the highest OA and Kappa values.
Through the experiments on the two datasets, it can be observed that all algorithms showed similar performance on the CIFAR-10 dataset, and in some cases, the B-CNN even exhibited lower accuracy compared to the baseline model. This could be attributed to the low resolution of the images in this dataset, as certain algorithmic improvements may not perform as effectively under such conditions.
In the FGSCR-10 dataset, the performance of the proposed method surpassed that of the other four baseline models. This may be due to the fact that the FGSCR-10 dataset involves fine-grained classification targets. After feature extraction by the backbone network, the E-FPN utilizes the FPN method to fuse features at different scales, which allows for complementary details among the three-dimensional feature maps. Finally, the classification results of the different feature maps are fused using the evidence-theory-based decision-level fusion method, thus further correcting the classification results. For example, when an image is misclassified, its correct classification has a probability value that is close to the probability value of the current misclassification. When another set of probability distributions is fused, the probability value corresponding to the correct classification is also large. After fusion, the probability value of the correct classification may become the largest, thus resulting in the final correct result. As a result, the proposed method demonstrates an advantage over the other methods in the FGSCR-10 dataset. Compared to the other two fine-grained image classification algorithms, our proposed E-FPN outperformed the B-CNN and DCL. This may be attributed to the effective extraction of the objects’ fine-grained features using our multiscale approach, and the decision-level fusion enables a comprehensive analysis of the classification results from different perspectives.
In terms of the Kappa metric, all classification methods achieved a performance exceeding 90% on both datasets, thus indicating a level of consistency that is considered “almost perfect”. Compared to the other four baseline models, the E-FPN exhibited further improvement in this metric, thus signifying enhanced classification accuracy for each class and its general applicability. Additionally, when compared to the fine-grained image recognition algorithms (B-CNN and DCL), the E-FPN also showed improvement in terms of the Kappa value. Furthermore,
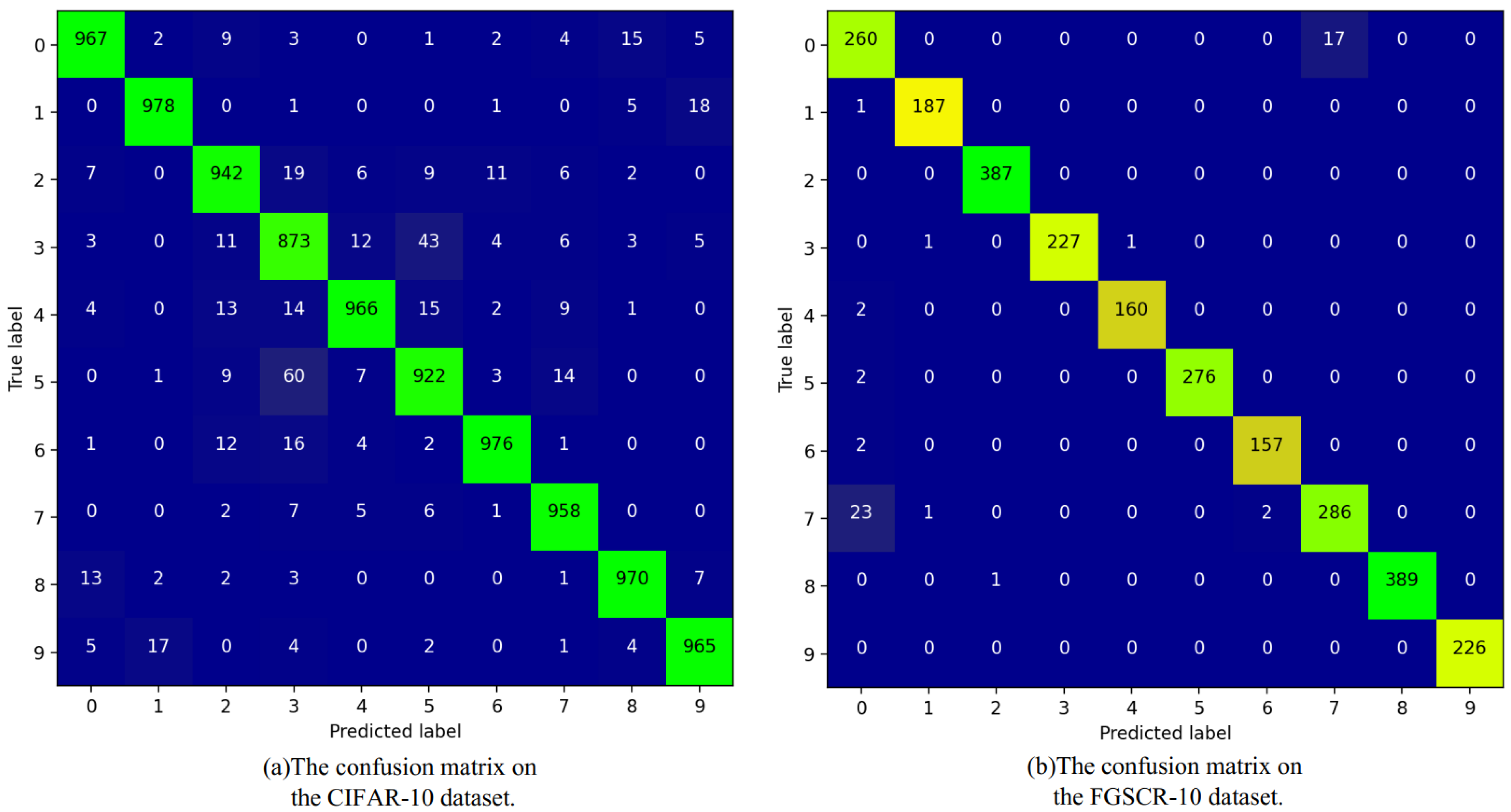
Figure 6 provides a detailed visualization of the classification results for each class, which demonstrates the proposed method’s performance in terms of confusion matrices for both the CIFAR-10 and FGSCR-10 datasets. There are very few dark areas outside of the diagonal, thus indicating a reduced number of misclassifications. This visual representation intuitively demonstrates the effectiveness of the E-FPN.
Table 4 presents the number of parameters, FLOPs (floating-point operations), and inference times for the seven models. It can be observed that the VGG16 and VGG19 had significantly higher numbers of parameters and FLOPs compared to the other baseline models. This is likely due to their deeper network architectures and the utilization of numerous convolutional layers. On the other hand, the ResNet50 and ResNeXt50 had smaller numbers of parameters and FLOPs. This reduction can be attributed to the utilization of residual structures, which help reduce network depth and complexity. Among the five methods, the E-FPN had a higher number of parameters compared to the ResNet50 and ResNeXt50, but it was lower than the VGG16 and VGG19. However, its FLOPs were the lowest among the five methods, thus indicating a relatively low computational cost when performing the classification task. This is because the proposed method introduces an additional FPN network, while the backbone network adopts the residual approach to reduce its depth. When comparing the fine-grained image classification models, the E-FPN had the highest number of parameters, thus suggesting higher storage requirements. However, its FLOPs remained the lowest, which indicates that, compared to the other six models, the E-FPN requires fewer computational resources during the inference phase, thereby making it suitable for deployment on mobile and edge devices. This observation is evident from the inference speed, where all three fine-grained image recognition models, including the E-FPN, required higher inference times than the four baseline models. However, in the fine-grained image recognition models, the inference time of the E-FPN model was lower than the other two (B-CNN and DCL). This demonstrates the advantage of the E-FPN in terms of the inference speed.
Additionally, the DS fusion method used in the E-FPN incurred minimal additional computational costs for the network. As a result, the increase in network parameters was relatively small, and the FLOPs were the lowest among the all models.
By comparing the experimental results from the two aforementioned tables, it can be concluded that the E-FPN is effective with respect to both traditional natural image datasets and fine-grained remote sensing image datasets. In the description of the FPN network structure, it was mentioned that three feature maps of different dimensions were utilized, but during the final decision-level fusion, only the results from the deeper two scales of the feature maps were selected for fusion. In the following, we will discuss the impact of choosing different dimension feature maps for decision-level fusion on the final results. The results of these experiments are presented in
Table 5 and
Table 6.
In this experiment, different combinations of feature maps were fused for each dataset, and the impact of the pairwise fusion of different feature maps on the final results was compared. The last line represents the results obtained by fusing all three feature maps together. Dark3–Dark5 represent the probability distributions of the classification results from the FPN fused outputs of the backbone network. In
Table 5, the CIFAR-10 dataset was used. It can be observed that, before decision-level fusion, the OA gradually improved as the network layers deepened. However, after fusion, the OA was lower than the OA of the Dark5 output result. Among the fused results, the fusion of Dark4 and Dark5 achieved the highest OA of 94.92%. Furthermore, its Kappa value was superior to the other three results, which came out to 0.945. Preliminary analysis suggests that this may be due to significant conflicts in the probability values among certain categories before fusion, thereby resulting in an unreasonable probability distribution after fusion, thus leading to incorrect fusion results. Further investigation of this issue will be discussed in subsequent sections.
Table 6 displays the results obtained from the FGSCR-10 dataset: Dark3–Dark5 had the same classification OA of 97.73%. However, the OA improved after fusion. The fusion of the Dark3 and Dark4 achieved an OA of 97.8%, while the fusions of the Dark4 and Dark5, Dark3 and Dark5, and all three (Dark3–Dark5) had an OA of 98.04%. The performance of the Kappa index was consistent with the OA, with the fusion of the Dark3 and Dark4 resulting in a Kappa value of 0.975, while the other three fusions all had Kappa values of 0.978. By comparing the results before and after fusion, it can be observed that the samples correctly classified by the Dark3–Dark5 were not entirely the same, and, in the probability distributions of misclassified samples, the probability values for the correct class were close to those of the misclassified class. Therefore, after fusion, some misclassified samples were corrected, thereby resulting in an improvement in the final OA of the results.
According to the above table, it can be observed that the highest OA resulted after fusions were obtained by combining Dark5 with other parts, and these results were superior to the results obtained by fusing the Dark3 and Dark4. It can be seen that the results obtained from the deeper parts of the network had a more reliable probability distribution. However, the results obtained by fusing all three parts together showed a slight decrease compared to the fusion of the Dark4 and Dark5. This may be due to the fact that, during fusion, the probability values of the correct class and the misclassified class for all three inputs were very close, and since the Dark3 had classification errors, the final result was not corrected to the correct class during fusion, thereby resulting in a decrease in the OA. Therefore, in the experiment, this study chose to fuse the Dark4 and Dark5 for the fusion process.
The E-FPN in this paper consists of three parts: the feature extraction network, the FPN network, and the decision fusion part. During the training process, the crossentropy loss values of the three outputs from the FPN were summed to calculate the overall loss value. Specifically, the obtained loss values in the network are referred to as loss_0, loss_1, and loss_2. However, for the final decision, only the output results from the Dark4 and Dark5 were selected for fusion. Therefore, the next step was to explore the impact of the loss_0 value obtained from Dark2 on the classification performance and the effect of using the FPN for fusion at the feature level.
According to the experimental results in
Table 7, for the CIFAR-10 dataset, the removal of the loss_0 slightly improved the OA to 95.13%. This may be because the FPN has multiple output classification results, and adding the loss_0 during the training process may have led to oscillation and decision risk. Additionally, the OA gap between the Dark4 and Dark5 was very small, and their Kappa values were similar. Without using the FPN for feature-level fusion, the OA was lower in both cases, and the fused OA and Kappa values were also lower compared to the two cases with theFPN. This indicates that the classification results of the shallow layers may have had a negative impact on the decision-making and fusion in the datasets with clear image features. However, the positive impact of the shallow layers in the feature-level fusion should not be ignored, as shown in
Table 8.
When conducting experiments on the FGSCR-10 dataset, it was found that adding the loss_0 and using the FPN for feature-level fusion resulted in a higher OA and Kappa values compared to not using the FPN or not adding the loss_0, wherein 98.04% and 0.978 were achieved, respectively. This indicates that the classification performance for each class object in the dataset was excellent. Under the conditions of removing the FPN and removing the loss_0, the OA gap between the Dark4, Dark5, and the fused result was small. However, it can be observed that the OA of the fused result was better than the individual results. As mentioned earlier, although the outputs of the shallow network can have a negative impact on the final decision-level fusion, the features learned by the shallow network still have a positive influence on the classification results in the feature-level fusion process.
Based on the experiments and discussions, it can be concluded that using the FPN structure and training the shallow network for classification improved the classification performance on the fine-grained remote-sensing image dataset. The FPN structure complemented the detailed features that were lost in the deep network. Since the FPN structure used in the paper involved the fusion of the information from the three layers, adding the loss_0 for classification training in the top layer of the network could facilitate the learning of more useful feature information, thereby further enhancing the feature fusion effect. The results in
Table 8 indicate that employing the feature-level fusion method helped improve the classification performance of fine-grained remote-sensing image classification and further enhanced the classification performance after decision-level fusion.
The experimental parameter section in this paper mentions that, unlike the four other classification methods used in the comparative experiments, the image input size for the E-FPN in this paper was 320 × 320, while the four classical classification methods used an image input size of 224 × 224. The purpose of this choice was to preserve more image feature information. However, it should be noted that a larger input image size does not necessarily guarantee better performance.
Table 9 and
Table 10 present a comparison of the impact of different input image sizes on the classification performance.
In the experiments comparing the impact of different input image sizes on the classification performance, the image size of 224 × 224, which is the same as the other four classical algorithms, was selected. Additionally, scaled versions of the 640 × 640 and 160 × 160 were used. Based on the data in
Table 9 and
Table 10, it was found that the input image size of 320 × 320 achieved the best performance in terms of the classification OA and Kappa value. Furthermore, in both tables, as the input image size decreased from large to small, the classification the OA initially increased and then decreased. Therefore, it is not necessarily true that a larger input image size leads to better performance, and the appropriate size should be chosen based on the specific circumstances.
Table 9 presents the influence of different input image sizes on classification performance, which reveals that the classification OA for each size increased with the depth of the network. Except for the 320 × 320 size group, all other size groups exhibited an increase in the classification OA after decision-level fusion. However, the final accuracy remained lower than that of the 320 × 320 size group. Regarding the Kappa index, the 320 × 320 size group still performed the best. These data indicate that, for traditional natural image datasets, which have easily discernible image features, adequate feature extraction enabled effective classification, thereby only necessitating the selection of an appropriate input image size.
Table 10 demonstrates the impact of different input image sizes on the classification performance in the FGSCR-10 dataset. In contrast to
Table 9,
Table 10 does not observe an increase in the classification OA with the network depth. In the 640 × 640 and 160 × 160 size groups, a decline in the classification OA was observed as the network depth increased. This may have been due to excessively large or small feature maps that failed to effectively propagate relevant features in the FPN feature fusion. For the 160 × 160 size group, the small image size may have led to the loss of crucial detail features, thereby resulting in a reduced classification OA. This could also result in significant conflicts between the generated probability distributions, thereby making it difficult to correct misclassifications during the decision-level fusion and ultimately decreasing the OA of the fused results. In the 320 × 320 size group, the Dark3–Dark5 exhibited a higher classification OA than the other groups. Although these three groups had the same classification accuracy, the decision-level fusion further enhances their OA values. These data demonstrate that the proposed classification method, when applied to fine-grained remote sensing image datasets, benefits from using appropriately sized input images. This enabled the extraction of abstract features while retaining some detailed features, thereby facilitating subsequent image classification operations.
In the previous sections, we discussed the network architecture and input image data. In
Section 2, the limitations of the DS fusion method were mentioned; specifically, the issue of unreasonable fusion results when significant conflicts exist between two input evidence factors were discussed. To overcome this problem, this paper adopted the PCR5 fusion method and utilized the Shafer discounting method to weigh the evidence, thereby reducing the conflicts between input evidence. The obtained results were compared with those of the DS fusion method.
Table 11 and
Table 12 present the OA and Kappa values obtained using three different fusion rules for the CIFAR-10 dataset. The DS fusion rule was the fusion rule adopted in this paper, the PCR5 was the proportional conflict redistribution method mentioned in
Section 2 of this paper, and wPCR5 refers to the addition of weights to the probability distributions before using the PCR5 fusion rule by applying the Shafer discounting method to discount the evidence and reduce conflicts between input data. From
Table 11, it can be observed that the OA values of the Dark3 × Dark4, Dark3 × Dark5, and Dark4 × Dark5 combinations under the DS fusion rule and PCR5 fusion rule were almost indistinguishable. However, for the Dark4 × Dark5 combination, the OA decreased when using the PCR5 rule compared to using the DS rule. After applying the wPCR5 fusion rule, the OA improved compared to both the DS rule and the PCR5 rule for all three combinations. This improvement may have been attributed to the already high classification OA before fusion, thereby indicating a relatively small conflict between the probability distributions of the two input data. The PCR5 fusion rule primarily aims to mitigate the impact of the conflicts on the fusion results and to prevent the generation of unreasonable output values. By adding weights and employing the PCR5 rule, the conflicts between the two inputs can be further effectively reduced, thereby leading to better results. The Kappa values generally exhibited a similar pattern to the OA results. The wPCR5 rule yielded slightly better results compared to the DS and PCR5 rules, but the improvement was marginal, while there was little difference between the DS rule and the PCR5 rule.
Table 13 and
Table 14 compare the OA and Kappa values for the FGSCR-10 dataset. Similar to the results obtained on the CIFAR-10 dataset, the DS fusion rule and the PCR5 fusion rule yielded nearly identical results. However, for the Dark3 × Dark5 combination with higher conflicts, the PCR5 rule slightly outperformed the DS rule. When using the wPCR5 rule, the performance was slightly worse than when using the previous two rules. The same trend was observed in the Kappa values. However, in the case of the fine-grained remote-sensing image datasets, the probability values of each class in the classification distributions were close, thereby making it difficult to compute favorable weights, as was mentioned in
Section 2. Consequently, the weighting approach weakened the confidence of certain correctly classified classes during the discounting operations, thereby resulting in suboptimal final results. Regarding the Kappa values, there was little difference among the three fusion methods.
Based on the above analysis, it can be observed that the DS fusion rule and the PCR5 fusion rule yielded almost identical results on both datasets. The wPCR5 method performed slightly better than the previous two methods with respect to the traditional natural image datasets but slightly worse with respect to the fine-grained remote-sensing image datasets. Additionally, the computation complexities of the PCR5 and wPCR5 were higher than that of the DS rule, and the complexities increased more noticeably with a larger number of classes to be classified. Therefore, when there was no significant conflict between the two probability distributions, the DS fusion rule was chosen in this paper.
In the previous experiments, it was mentioned that, in the fine-grained remote-sensing image dataset, the method of adding weights to reduce the conflicts between the evidence actually weakened the credibility of some correctly classified results. In the process of calculating the weights, a threshold was set for the ratio between the mass values of each class and the maximum mass value to preserve the differences between the two classification results.
In the previous experiments, a threshold of 0.5 was set. The impact of the threshold value on the OA and Kappa value after fusion can be seen in
Table 15 and
Table 16.
The above table demonstrates the influence of the threshold values ranging from 0.1 to 0.9 for the classification OA and consistency with respect to the two datasets. In the CIFAR-10 dataset, as the threshold value increased from 0.1 to 0.9, the classification OA gradually rose to 95.17%. Compared to the threshold value of 0.1, there was an improvement of 0.24%. The Kappa value increased from 0.9436 to 0.9463. In this dataset, when the threshold value increased, it filtered out categories with lower probability values in the probability distributions, thereby retaining other potential options for correct classification. This preserved some differences between the classifiers as complementary information, which benefitted subsequent fusion operations.
In the FGSCR-10 dataset, changing the threshold value from 0.1 to 0.9 had almost no impact on the classification OA and Kappa values. This indicates that the threshold value had little effect on the fusion results in this dataset.
Table 17 displays the partial probability distributions generated by Dark5. It can be observed that the reason for this phenomenon is that one class in the probability distribution—before fusion—had a significantly high probability value, and the ratios of other probabilities to it were lower than 0.1. Consequently, the variation in the threshold value did not affect the final result.
Based on the experiments, it can be concluded that the threshold value has almost no impact on the classification of OA in the FGSCR-10 dataset. In the CIFAR-10 dataset used in this experiment, setting a higher threshold value allows for the rational utilization of the differences between different classifiers, thereby obtaining complementary information and improving the OA of the classification results.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}