Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis


Abstract
:
1. Introduction
- A new method is proposed for remote sensing synthesis based on Neural Radiance Fields with an attention mechanism;
- A point attention module is added to increase the nonlinear capabilities of the network and the ability of implicit 3D representation;
- A batch attention module is introduced to enhance the relationship between different rays and sampled points to improve the constraint inside the spatial points;
- A frequency-weighted position encoding is proposed to make the network focus on the most significant feature in different frequencies.
2. Related Work
2.1. NeRF and NeRF Variants
2.2. Remote Sensing Novel View Synthesis and 3D Reconstruction
3. Materials and Methods
3.1. Preliminaries on NeRF
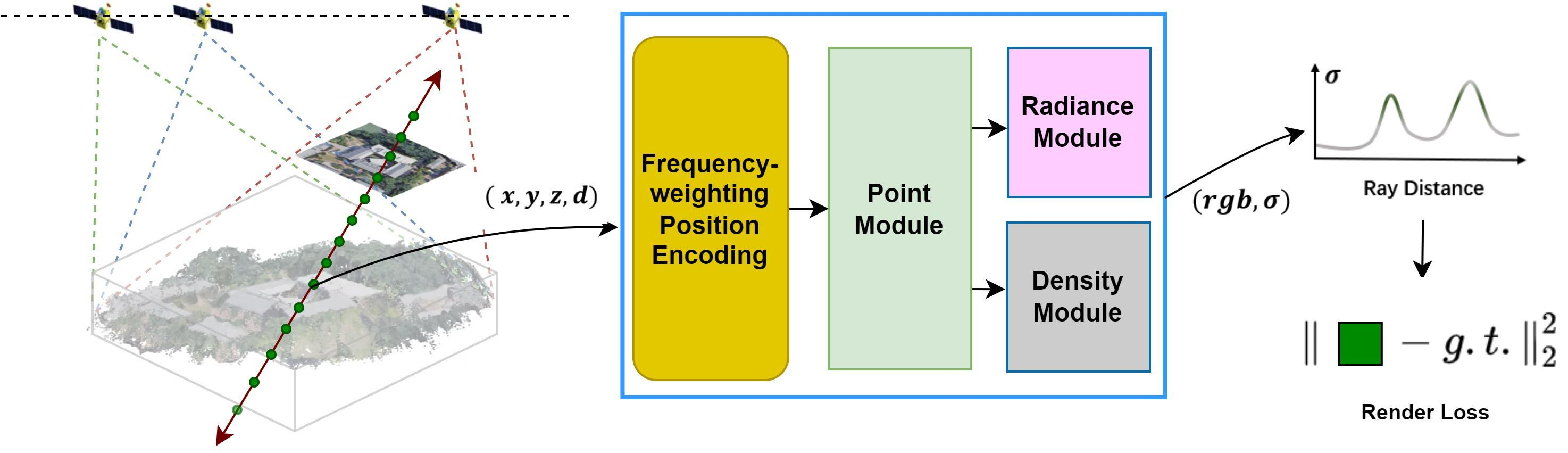
3.2. Overall Architecture
3.3. 3D Scene Representation Network with Attention Mechanism
3.3.1. Network Design
3.3.2. Frequency-Weighted Position Encoding
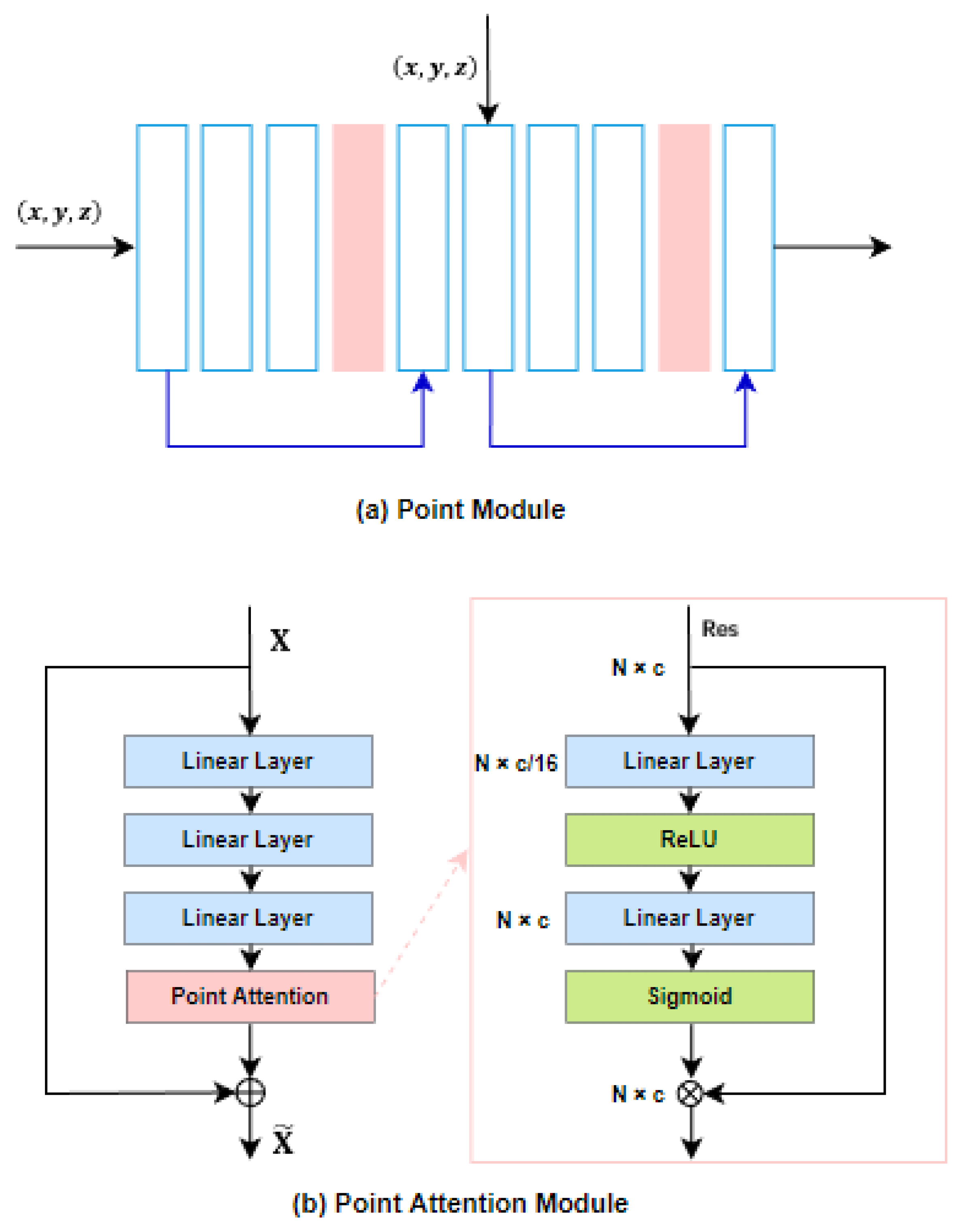
3.3.3. Point Module with Point Attention
3.3.4. Radiance Module with Batch Attention
3.3.5. Density Module
3.4. Sampling and Volume Rendering
4. Experiments and Results
4.1. Dataset
4.2. Quality Assessment Metrics
4.3. Implementation Details
4.4. Results
4.4.1. Quantitative and Qualitative Evaluation Compared with Other Methods
4.4.2. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Remondino, F. Heritage Recording and 3D Modeling with Photogrammetry and 3D Scanning. Remote Sens. 2011, 3, 1104–1138. [Google Scholar] [CrossRef] [Green Version]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Kanazawa, A.; Tulsiani, S.; Efros, A.A.; Malik, J. Learning category-specific mesh reconstruction from image collections. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 371–386. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3D mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–67. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3D surface generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 216–224. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Generative and discriminative voxel modeling with convolutional neural networks. arXiv 2016, arXiv:1608.04236. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Flynn, J.; Broxton, M.; Debevec, P.; DuVall, M.; Fyffe, G.; Overbeck, R.; Snavely, N.; Tucker, R. Deepview: View synthesis with learned gradient descent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2367–2376. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Liu, S.; Chen, W.; Li, T.; Li, H. Soft rasterizer: Differentiable rendering for unsupervised single-view mesh reconstruction. arXiv 2019, arXiv:1901.05567. [Google Scholar]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3D mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Genova, K.; Cole, F.; Sud, A.; Sarna, A.; Funkhouser, T. Local Deep Implicit Functions for 3D Shape. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3D reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Jiang, C.; Sud, A.; Makadia, A.; Huang, J.; Nießner, M.; Funkhouser, T. Local implicit grid representations for 3D scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6001–6010. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- Neff, T.; Stadlbauer, P.; Parger, M.; Kurz, A.; Mueller, J.H.; Chaitanya, C.R.A.; Kaplanyan, A.; Steinberger, M. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. Comput. Graph. Forum 2021, 40, 45–59. [Google Scholar] [CrossRef]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4578–4587. [Google Scholar]
- Wu, Y.; Zou, Z.; Shi, Z. Remote Sensing Novel View Synthesis with Implicit Multiplane Representations. arXiv 2022, arXiv:2205.08908. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Zhang, J.; Zhang, Y.; Fu, H.; Zhou, X.; Cai, B.; Huang, J.; Jia, R.; Zhao, B.; Tang, X. Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18376–18386. [Google Scholar]
- Park, K.; Sinha, U.; Barron, J.T.; Bouaziz, S.; Goldman, D.B.; Seitz, S.M.; Martin-Brualla, R. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5865–5874. [Google Scholar]
- Deng, K.; Liu, A.; Zhu, J.Y.; Ramanan, D. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12882–12891. [Google Scholar]
- Wei, Y.; Liu, S.; Rao, Y.; Zhao, W.; Lu, J.; Zhou, J. Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5610–5619. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. Fastnerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14346–14355. [Google Scholar]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14335–14345. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1311–1321. [Google Scholar]
- Zhao, C.; Zhang, C.; Su, N.; Yan, Y.; Huang, B. A Novel Building Reconstruction Framework using Single-View Remote Sensing Images Based on Convolutional Neural Networks. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4211–4214. [Google Scholar] [CrossRef]
- Matsunaga, R.; Hashimoto, M.; Kanazawa, Y.; Sonoda, J. Accurate 3-D reconstruction of sands from UAV image sequence. In Proceedings of the 2016 International Conference On Advanced Informatics: Concepts, Theory And Application (ICAICTA), Penang, Malaysia, 16–19 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Fraundorfer, F. Building and site reconstruction from small scale unmanned aerial vehicles (UAV’s). In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Wu, S.; Liebel, L.; Körner, M. Derivation of Geometrically and Semantically Annotated UAV Datasets at Large Scales from 3D City Models. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4712–4719. [Google Scholar] [CrossRef]
- Chen, H.; Chen, W.; Gao, T. Ground 3D Object Reconstruction Based on Multi-View 3D Occupancy Network using Satellite Remote Sensing Image. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4826–4829. [Google Scholar] [CrossRef]
- Kajiya, J.T.; Von Herzen, B.P. Ray tracing volume densities. ACM SIGGRAPH Comput. Graph. 1984, 18, 165–174. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; pp. 770–778. [Google Scholar]
- Rahaman, N.; Baratin, A.; Arpit, D.; Draxler, F.; Lin, M.; Hamprecht, F.; Bengio, Y.; Courville, A. On the spectral bias of neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Beach, CA, USA, 10–15 June 2019; pp. 5301–5310. [Google Scholar]
- Sitzmann, V.; Thies, J.; Heide, F.; Nießner, M.; Wetzstein, G.; Zollhofer, M. Deepvoxels: Learning persistent 3D feature embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2437–2446. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Name | NeRF | ImMPI | Ours | NeRF | ImMPI | Ours | NeRF | ImMPI | Ours |
| Building1 | 23.14/21.79 | 24.92/24.77 | 29.12/24.64 | 0.725/0.706 | 0.867/0.865 | 0.933/0.906 | 0.385/0.393 | 0.105/0.151 | 0.169/0.189 |
| Building2 | 23.08/22.20 | 23.31/22.73 | 29.36/26.25 | 0.655/0.638 | 0.783/0.776 | 0.885/0.855 | 0.420/0.423 | 0.217/0.218 | 0.195/0.213 |
| College | 25.20/24.06 | 26.17/25.71 | 35.01/28.55 | 0.713/0.696 | 0.820/0.817 | 0.954/0.917 | 0.381/0.393 | 0.201/0.203 | 0.104/0.131 |
| Mountain1 | 28.65/28.05 | 30.23/29.88 | 34.38/32.02 | 0.737/0.727 | 0.854/0.854 | 0.922/0.902 | 0.375/0.379 | 0.187/0.185 | 0.145/0.158 |
| Mountain2 | 27.42/26.89 | 29.56/29.37 | 33.14/30.64 | 0.679/0.666 | 0.844/0.843 | 0.911/0.888 | 0.430/0.437 | 0.172/0.173 | 0.174/0.188 |
| Mountain3 | 29.92/29.41 | 33.02/32.81 | 34.68/33.56 | 0.735/0.726 | 0.880/0.878 | 0.914/0.901 | 0.411/0.414 | 0.156/0.157 | 0.149/0.160 |
| Observation | 23.25/22.57 | 23.04/22.54 | 29.64/26.22 | 0.671/0.654 | 0.728/0.718 | 0.906/0.865 | 0.404/0.408 | 0.267/0.272 | 0.176/0.196 |
| Church | 22.71/21.65 | 21.60/21.04 | 28.72/25.43 | 0.679/0.658 | 0.729/0.720 | 0.891/0.858 | 0.405/0.413 | 0.254/0.258 | 0.183/0.205 |
| Town1 | 25.49/25.00 | 26.34/25.88 | 32.01/29.56 | 0.759/0.752 | 0.849/0.844 | 0.938/0.922 | 0.343/0.349 | 0.163/0.167 | 0.118/0.134 |
| Town2 | 23.37/22.41 | 25.89/25.31 | 32.95/25.09 | 0.691/0.667 | 0.855/0.850 | 0.942/0.874 | 0.385/0.402 | 0.156/0.158 | 0.127/0.168 |
| Town3 | 24.64/23.77 | 26.23/25.68 | 32.19/27.89 | 0.733/0.717 | 0.840/0.834 | 0.924/0.893 | 0.361/0.367 | 0.187/0.190 | 0.148/0.168 |
| Stadium | 25.64/24.96 | 26.69/26.50 | 32.97/30.44 | 0.735/0.727 | 0.878/0.876 | 0.936/0.923 | 0.362/0.364 | 0.123/0.125 | 0.115/0.124 |
| Factory | 25.34/24.67 | 28.15/28.08 | 31.85/28.16 | 0.777/0.762 | 0.908/0.907 | 0.929/0.890 | 0.338/0.342 | 0.109/0.109 | 0.135/0.153 |
| Park | 25.90/25.55 | 27.87/27.81 | 32.18/29.85 | 0.796/0.788 | 0.896/0.896 | 0.941/0.921 | 0.352/0.358 | 0.123/0.124 | 0.137/0.149 |
| School | 24.28/24.83 | 25.74/25.33 | 30.48/27.44 | 0.666/0.654 | 0.830/0.825 | 0.869/0.837 | 0.422/0.426 | 0.163/0.165 | 0.187/0.202 |
| Downtown | 23.42/22.52 | 24.99/24.24 | 28.46/25.03 | 0.685/0.668 | 0.825/0.816 | 0.872/0.838 | 0.444/0.449 | 0.201/0.205 | 0.204/0.211 |
| Average | 25.09/24.39 | 26.34/25.95 | 31.63/28.45 | 0.714/0.700 | 0.835/0.831 | 0.915/0.885 | 0.388/0.394 | 0.172/0.173 | 0.154/0.171 |
| Scene | NoFWPE,PA,BA | NoFWPE | NoPA | NoBA | CompleteModel | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| Building1 | 21.79 | 0.706 | 0.393 | 23.62 | 0.829 | 0.255 | 23.56 | 0.822 | 0.270 | 23.64 | 0.826 | 0.260 | 24.64 | 0.876 | 0.189 |
| Building2 | 22.20 | 0.638 | 0.423 | 24.48 | 0.790 | 0.291 | 24.31 | 0.772 | 0.317 | 24.79 | 0.803 | 0.273 | 26.25 | 0.855 | 0.213 |
| College | 24.06 | 0.696 | 0.393 | 27.54 | 0.879 | 0.183 | 27.16 | 0.877 | 0.192 | 27.37 | 0.889 | 0.172 | 28.55 | 0.917 | 0.131 |
| Mountain1 | 28.05 | 0.727 | 0.379 | 30.46 | 0.852 | 0.229 | 30.48 | 0.853 | 0.234 | 30.68 | 0.860 | 0.225 | 32.02 | 0.902 | 0.158 |
| Mountain2 | 26.89 | 0.666 | 0.437 | 29.39 | 0.831 | 0.261 | 28.90 | 0.817 | 0.287 | 29.51 | 0.830 | 0.264 | 33.14 | 0.911 | 0.174 |
| Mountain3 | 29.41 | 0.726 | 0.414 | 31.88 | 0.856 | 0.229 | 31.87 | 0.848 | 0.246 | 31.71 | 0.851 | 0.235 | 33.56 | 0.901 | 0.160 |
| Observation | 22.57 | 0.654 | 0.408 | 25.17 | 0.813 | 0.258 | 25.04 | 0.799 | 0.284 | 25.02 | 0.809 | 0.261 | 26.22 | 0.865 | 0.196 |
| Church | 21.65 | 0.658 | 0.413 | 23.99 | 0.798 | 0.271 | 23.99 | 0.795 | 0.282 | 24.02 | 0.800 | 0.270 | 25.43 | 0.858 | 0.205 |
| Town1 | 25.00 | 0.752 | 0.349 | 27.82 | 0.874 | 0.198 | 27.65 | 0.865 | 0.217 | 27.66 | 0.873 | 0.198 | 29.56 | 0.922 | 0.134 |
| Town2 | 22.41 | 0.667 | 0.402 | 23.65 | 0.765 | 0.304 | 23.80 | 0.765 | 0.317 | 23.48 | 0.767 | 0.303 | 29.56 | 0.874 | 0.168 |
| Town3 | 23.77 | 0.717 | 0.367 | 25.01 | 0.809 | 0.270 | 25.09 | 0.809 | 0.270 | 24.98 | 0.807 | 0.297 | 27.89 | 0.893 | 0.168 |
| Stadium | 24.96 | 0.727 | 0.364 | 28.45 | 0.872 | 0.201 | 28.19 | 0.865 | 0.217 | 28.56 | 0.873 | 0.202 | 30.44 | 0.923 | 0.124 |
| Factory | 24.67 | 0.762 | 0.342 | 26.88 | 0.853 | 0.227 | 26.79 | 0.845 | 0.257 | 26.86 | 0.852 | 0.227 | 28.16 | 0.890 | 0.153 |
| Park | 25.55 | 0.788 | 0.358 | 27.94 | 0.881 | 0.221 | 28.16 | 0.881 | 0.223 | 28.13 | 0.882 | 0.220 | 29.85 | 0.921 | 0.140 |
| School | 24.83 | 0.654 | 0.426 | 26.04 | 0.764 | 0.301 | 25.86 | 0.754 | 0.321 | 26.18 | 0.765 | 0.296 | 27.44 | 0.837 | 0.202 |
| Downtown | 22.52 | 0.668 | 0.449 | 23.98 | 0.772 | 0.347 | 23.70 | 0.757 | 0.372 | 24.19 | 0.779 | 0.340 | 25.03 | 0.838 | 0.211 |
| Average | 24.39 | 0.700 | 0.394 | 26.64 | 0.827 | 0.253 | 26.53 | 0.820 | 0.271 | 26.67 | 0.829 | 0.253 | 28.45 | 0.885 | 0.171 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, J.; Guo, J.; Zhang, Y.; Zhao, X.; Lei, B. Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sens. 2023, 15, 3920. https://doi.org/10.3390/rs15163920
Lv J, Guo J, Zhang Y, Zhao X, Lei B. Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sensing. 2023; 15(16):3920. https://doi.org/10.3390/rs15163920
Chicago/Turabian StyleLv, Junwei, Jiayi Guo, Yueting Zhang, Xin Zhao, and Bin Lei. 2023. "Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis" Remote Sensing 15, no. 16: 3920. https://doi.org/10.3390/rs15163920
APA StyleLv, J., Guo, J., Zhang, Y., Zhao, X., & Lei, B. (2023). Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sensing, 15(16), 3920. https://doi.org/10.3390/rs15163920