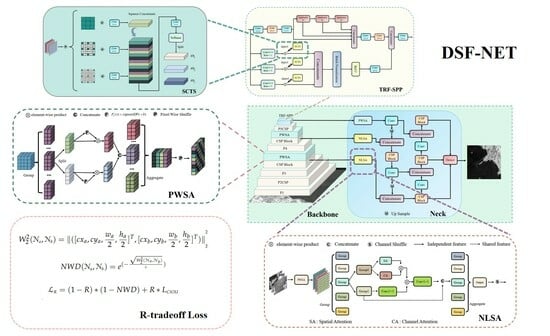
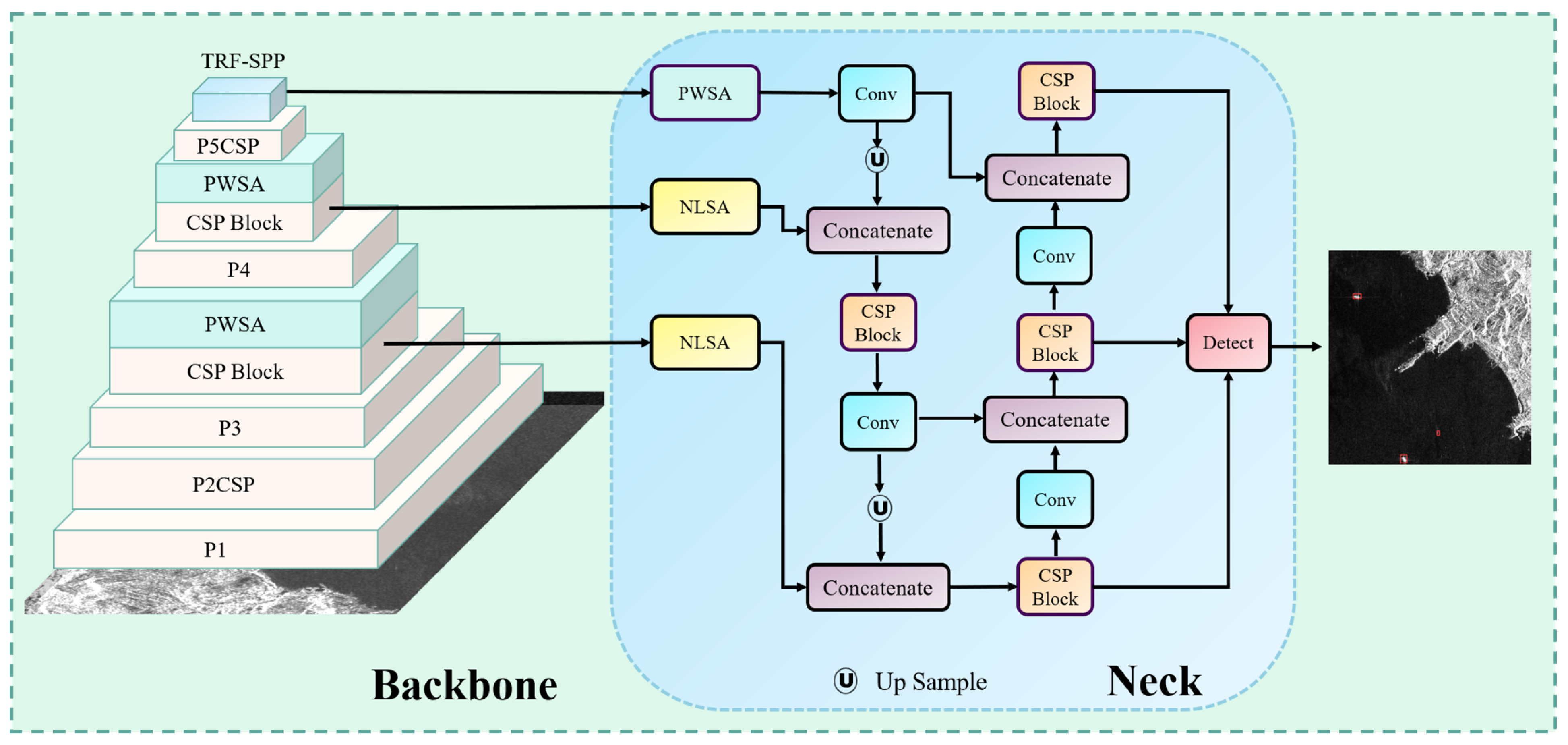
4.4.1. Comparison with the Existing Methods
We compare the DSF-Net proposed in this study with other object detection methods. These methods include state-of-the-art object detection methods, two-stage object detection methods, one-stage object detection methods, anchor-free methods, and the latest methods in the field of SAR small ship target detection. The results are given in
Table 2 at length. The results of visualization are presented in
Figure 10,
Figure 11,
Figure 12 and
Figure 13.
Table 2.
Comparison with other detection Methods in LS-SSDD-v1 [
52] of entire scenes. Where the superscript with * indicates that the results are from [
27], and the superscript with † indicates that the results are from [
53].
Table 2.
Comparison with other detection Methods in LS-SSDD-v1 [
52] of entire scenes. Where the superscript with * indicates that the results are from [
27], and the superscript with † indicates that the results are from [
53].
|
Method
|
P (%)
|
R (%)
|
mAP (%)
|
mAP (%)
|
F (%)
|
GFLOPs
|
|---|
| Faster R-CNN [14] | 58 | 61.6 | 57.7 | – | 59.75 | – |
| Cascade R-CNN [54] | 54.1 | 66.2 | 59.0 | – | 59.54 | – |
| YOLO V5 [39] | 84 | 63.6 | 73.3 | 27.1 | 72 | 15.9 |
| YOLO V8 [55] | 82.4 | 67 | 74.4 | 29 | 74 | 28.4 |
| Filtered Convolution [56] | – | – | 73 | – | – | – |
| Guided Anchoring * [57] | 80.1 | 63.8 | 59.8 | – | 71.0 | – |
| FoveaBox * [58] | 77.5 | 59.9 | 52.2 | – | 67.6 | – |
| FCOS * [59] | 50.5 | 66.7 | 63.2 | – | 57.48 | – |
| MTL-Det * [60] | – | – | 71.7 | – | – | – |
| ATSS * [61] | 74.2 | 71.5 | 68.1 | – | 72.8 | – |
| YOLO X † [19] | 66.78 | 75.44 | – | – | 70.85 | – |
| RefineDet † [62] | 66.72 | 70.23 | – | – | 68.43 | – |
| SII-Net [27] | 68.2 | 79.3 | 76.1 | – | 73.3 | – |
| DSF-Net(ours) | 86.4 | 68.7 | 76.9 | 29.4 | 77 | 33.5 |
We selected the typical scenes to demonstrate the detection effect. The scenes consist of densely arranged ship areas and inshore scenes. The detection results are shown in
Figure 11 and
Figure 12. At the same time, we also performed Grad-CAM visualization tests. In the visualization tests, we compared the results between the baseline and the proposed method, which are shown in
Figure 13.
Combining the data in
Table 2 with the results in
Figure 11,
Figure 12 and
Figure 13 for analysis, the detection results and the data results can corroborate each other in theory. In
Table 2, YOLO X and Cascade R-CNN have a relatively high recall. According to Equation (
11), we believe that higher Recall means that fewer missed detections occur, so there are fewer missed detections in the detection results of YOLO X. However, the Precision value is lower in comparison to the proposed method. According to Equation (
12), the lower Precision is reflected in the detection results as more false detection.
Figure 11 and
Figure 12 can well confirm this view: YOLO X is able to detect all the Ground truth but simultaneously generates a large number of false detections. In comparison with the state-of-the-art method, YOLO V8 detected the target correctly in some scenes as well as the proposed method, but the confidence score of the proposed method was much higher than that of YOLO V8. In
Figure 11g,h, DSF-Net exhibits a confidence level approximately 2.7 times higher than YOLO V8 in the top right corner of the first image and the top left corner of the last image. This phenomenon is particularly notable in scenarios featuring densely distributed small SAR ship targets. Therefore, the proposed method in this paper effectively reduces the cases of false detection and missed detection and performs favorably in detecting small SAR ship targets.
4.4.2. Ablation Experiments
To demonstrate that each module of DSF-Net plays an active role in the detection of the small SAR ship targets, we carried out ablation experiments on the LS-SSDDv1.0 dataset. The experimental results are shown in
Table 3.
By analyzing the experimental results in
Table 3, we can mutually corroborate with the theory. The placement of PWSA in the Backbone and NLSA in the Bridge Node expands the extraction capability of the Backbone for small target features and increases the capture of long-range dependencies. Hence, there is a certain degree of improvement in both precision and recall. The role of the TRF-SPP module is to enhance the network’s capability to capture contextual information and reduce the likelihood of missed detections, so the recall will be improved in theory. From the experimental data, the recall is improved by 6.3% compared to the baseline model after adding TRF-SPP to PWSA&NLSA. R-tradeoff Loss makes a tradeoff between CIOU loss and NWD loss without increasing the computational effort. The ability of CIOU loss to prevent false detection is retained as much as possible; concurrently, the R-tradeoff loss improves the anti-missed detection ability for small targets. From the experimental results, it can be seen that the precision is improved by 2.8%, the recall is improved by 8%, and the F1 score is improved by 6.9% compared to the baseline model. Additionally, there is no change in GFLOPs before and after replacing the loss with R-tradeoff Loss. To further verify that the proposed method can extract features more effectively, we represent the features captured in the inference as the heat maps. The results of the heat maps are shown in
Figure 10. The color closer to red indicates that the network pays more attention to these features, and the color closer to blue indicates that the network pays less attention to these features.
Figure 10.
The results of feature map visualization. (a,d,g) are the original images; (b,e,h) are Ground Truth; (c,f,i) are the feature maps in the form of heat maps.
Figure 10.
The results of feature map visualization. (a,d,g) are the original images; (b,e,h) are Ground Truth; (c,f,i) are the feature maps in the form of heat maps.
Some of the common scenes in small SAR ship target detection are shown in
Figure 10. Among
Figure 10,
Figure 10a is the densely arranged ship scenes,
Figure 10d is the small ship target scenes with coherent bright spots, and
Figure 10g is the small ship target detection scenes with the imaging clutter and black edge. As can be seen from the figures, the proposed DSF-Net can better focus on the small ship targets for all the above scenes, and the features of different dimensions have excellent extraction effects.
To verify our assumptions about the network structure and our assertions about the Bridge Node and loss function, we conducted a series of contrast experiments. First, to demonstrate the importance of PWSA and NLSA modules, we replace PWSA and NLSA in the same position with mainstream attention modules and conduct comparative experiments. The results are shown in
Table 4.
Figure 11.
Dense scene of small SAR ship target detection results comparison, where (
a) are the original images, (
b) are the Ground truth, (
c) are the results of Cascade R-CNN [
54], (
d) are the results of RetinaNet [
63], (
e) are the results of YOLO X [
19], (
f) are the results of YOLO V5 [
39], (
g) are the results of YOLO V8 [
55] and (
h) are the results of DSF-Net(ours).
Figure 11.
Dense scene of small SAR ship target detection results comparison, where (
a) are the original images, (
b) are the Ground truth, (
c) are the results of Cascade R-CNN [
54], (
d) are the results of RetinaNet [
63], (
e) are the results of YOLO X [
19], (
f) are the results of YOLO V5 [
39], (
g) are the results of YOLO V8 [
55] and (
h) are the results of DSF-Net(ours).
Figure 12.
Comparison of small SAR ship target detection results for inshore scenes, where (
a) are the original images, (
b) are the Ground truth, (
c) are the results of Cascade R-CNN [
54], (
d) are the results of RetinaNet [
63], (
e) are the results of YOLO X [
19], (
f) are the results of YOLO V5 [
39], (
g) are the results of YOLO V8 [
55] and (
h) are the results of DSF-Net(ours).
Figure 12.
Comparison of small SAR ship target detection results for inshore scenes, where (
a) are the original images, (
b) are the Ground truth, (
c) are the results of Cascade R-CNN [
54], (
d) are the results of RetinaNet [
63], (
e) are the results of YOLO X [
19], (
f) are the results of YOLO V5 [
39], (
g) are the results of YOLO V8 [
55] and (
h) are the results of DSF-Net(ours).
Figure 13.
The results of Grad-CAM between the baseline and our DSF-Net, where (
a) are the original images, (
b) are the Ground truth, (
c) are the Grad-CAM of YOLO V5(baseline) [
39], (
d) are the Grad-CAM of DSF-Net(ours).
Figure 13.
The results of Grad-CAM between the baseline and our DSF-Net, where (
a) are the original images, (
b) are the Ground truth, (
c) are the Grad-CAM of YOLO V5(baseline) [
39], (
d) are the Grad-CAM of DSF-Net(ours).
Based on the data presented in
Table 4, it is evident that the networks incorporating the attention module exhibit a certain degree of enhancement in recall. The result indicates that attention is indeed effective in solving the missed detection of small targets and can enhance the Backbone’s ability to extract features of small targets. However, in terms of precision, the networks with other attention modules decreased the precision to different degrees, which is consistent with our view on the stability of the Bridge Node. We believe that the instability in the feature fusion process is responsible for the loss of certain features, resulting in a decrease in precision. In addition, the F1 scores for SE Attention and Shuffle Attention have demonstrated improvements compared to the baseline model. Conversely, the F1 scores of other attention mechanisms have declined, further affirming the efficacy of the Squeeze operation and Channel shuffle operation in enhancing the extraction of features related to small targets.
Table 4.
The results of the experiment comparing different attention modules.
Table 4.
The results of the experiment comparing different attention modules.
|
Method
|
P (%)
|
R (%)
|
mAP (%)
|
mAP (%)
|
F (%)
|
GFLOPs
|
|---|
| YOLO v5 | 84 | 63.6 | 73.3 | 27.1 | 72 | 15.9 |
| PWSA&NLSA | 85.1 | 66.5 | 75.5 | 28.9 | 75 | 22.1 |
| SE Attention [26] | 81.9 | 65.6 | 72.5 | 26.3 | 73 | 15.8 |
| Shuffle Attention [35] | 83.7 | 64.5 | 72.1 | 26.9 | 73 | 15.8 |
| CBAM Attention [31] | 79.9 | 65.8 | 72.4 | 27 | 72 | 15.9 |
| ECA Attention [64] | 80.7 | 65.1 | 72 | 26.5 | 72 | 15.8 |
| Coord Attention [65] | 79.5 | 64.9 | 71.6 | 26.9 | 71 | 15.8 |
To further investigate the effectiveness of our designed R-tradeoff Loss, we conducted controlled experiments for different R values based on DSF-Net. According to the experimental results, We selected the most suitable R-value. The experimental results are shown in
Table 5.
From the data in
Table 5, it can be concluded that when the value of R is small, the recall will be higher. The NWD loss dominates the loss function at this time, which is consistent with our view that NWD will decrease the missed detection of small ship targets. Additionally, it can be seen from Equation (
11) that a decrease in FP will result in an improvement in Recall. With the increase of R, the advantage of CIOU gradually appears, FN starts to fall, and Precision starts to rise. Moreover, the relationship between R, Recall, and Precision is not linear. After considering multiple metrics, we chose R = 0.5 as the result after adding R-tradeoff Loss. Both ablation experiments and R-factor control experiments demonstrate the superior performance of the R-tradeoff loss for small-scale SAR ship target detection. The original intention behind the design of the R-tradeoff loss is to strike a balance between detection accuracy and the ability to resist missed detections in small-scale ship targets. These aspects are reflected in the metrics P and R, respectively. The F1 score, as a comprehensive metric combining both P and R, is highly suitable for evaluating the performance of the R-tradeoff loss. Based on the data presented in
Table 5, it is evident that F1 scores exhibit varying degrees of improvement when R values are within the smaller range. The highest improvement, amounting to 6 percentage points compared to the baseline model, is consistent with our initial design intent.
To comprehensively evaluate the algorithm proposed in this paper, we conducted an analysis of its complexity from two perspectives: GFLOPs and Params, following the findings presented in reference [
53,
66].
Low complexity and high performance are often difficult to achieve simultaneously in algorithms. Significant performance improvements typically come with a substantial increase in algorithm complexity. However, DSF-Net, proposed in this paper, achieves a notable improvement in performance with only a slight increase in complexity. Compared to the baseline model, with an increase of 17.6 GFLOPs, the growth in the F1 score is 6.9 times the original. Compared to YOLO V8, various metrics show different degrees of improvement, with GFLOPs increasing by only 5.1. At the same time, we compared the change in single-layer GFLOPs after adding PWSA and NLSA. The shallowest PWSA module has a time of 0.5ms and GFLOPs of 2.11; the shallowest NLSA module has a time of 0.5 ms and GFLOPs of 0.02; while the corresponding layer’s CSP module has a time of 0.9 ms and GFLOPs of 2.01. This indicates that the introduction of PWSA and NLSA in this paper adds complexity similar to that of a single CSP module yet delivers performance surpassing that of the CSP module.
The comparison of Parameters is shown in
Table 6. It can be observed from this table that DSF-Net, proposed in this paper, achieves comparable or even superior results when compared to other methods with similar parameter counts. The F1 score is improved by up to 29.67% compared to previous methods, and the parameters are in a similar range.
Table 7 presents a comparison of model sizes between the proposed method and common two-stage and one-stage methods. In this comparison, when compared to the advanced YOLO-SD, our method exhibits a slightly lower mAP
by 0.3%, a notably higher mAP
by 2.5%, and requires 10.1 MB fewer parameters. It is worth noting that YOLO-SD has undergone pretraining. In summary, the DSF-Net proposed in this paper achieves a good balance between model performance and algorithm complexity.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















