
Supervised versus Semi-Supervised Urban Functional Area Prediction: Uncertainty, Robustness and Sensitivity

 ,
, 
 ,
, (This article belongs to the Section AI Remote Sensing)
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Preprocessing

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functional Land Use Types in This Paper | OSM Land Use Category | Land Utilization in Hong Kong (LUHK) Category |
|---|---|---|
| Commercial | Retail | Commercial/Business and Office |
| Residential | Residential | Private Residential |
| Public Residential | ||
| Rural Settlement | ||
| Public service | University | Government, Institutional and Community Facilities |
| Museum | ||
| Public | ||
| Recreational | Garden | Open Space and Recreation |
| Leisure | ||
| Park | ||
| Recreation Ground | ||
| Transportation | Railway | Roads and Transport Facilities |
| Railways | ||
| Airport | ||
| Port Facilities | ||
| Not available (NA) | Other | Other |
2.2. Feature Extraction
2.2.1. POI Embedding for Functional Area Vectorizing
2.2.2. Similarity Measurement for Functional Area Semantic Linkage
2.3. Urban Functional Area Prediction Models
2.3.1. Supervised Models
2.3.2. Semi-Supervised Model: Graph Convolutional Network
2.4. Accuracy Assessment
3. Results
3.1. Model Comparison
3.1.1. Sensitivity on Training Set Size
- Although models’ accuracies are improved as the amount of training data increases, disparities could be diagnosed from the model comparison. RF, MLP and GCN show an obvious higher accuracy and improving potential (see the tendency of the accuracies to the training sample percentage) as the number of training samples increases;
- Supervised models (e.g., RF and MLP) indicate advantages with large number of training samples in terms of the accuracies. For example, MLP is with the top accuracies when the number of training samples is beyond around 10%. The RF-128 and RF-200 models show slightly improvements compared with MLP with the percentage of training samples equal to 30% and 40%. As the number of training samples keeps rising (greater than 40%), MLP wins again in terms of accuracy;
- Semi-supervised models indicate advantages with a small number of training samples. That is, the GCN model is within the top accuracy, from 0.65 to 0.70, when the number of training samples is less than 10%. However, the potential of the GCN model is of underperformance when the number of training samples increases, compared with supervised models of RF and MLP;
- All models are tested five times with the same amount and combination of training data for monitoring model stability by calculating the standard deviations (Std.) of the result accuracies (see the colored shadows in Figure 3a). SVM and GCN reveal better model stability (smaller Std.), compared with RF and MLP. As the model stability of MLP depends on the number of training data, it shows high instability with a small number of training data, but it improves (and become even better than RF) with a large number of training data.
3.1.2. Training Performances: Small vs. Large Number of Training Data
3.1.3. Robustness to Different Selection of Training Data

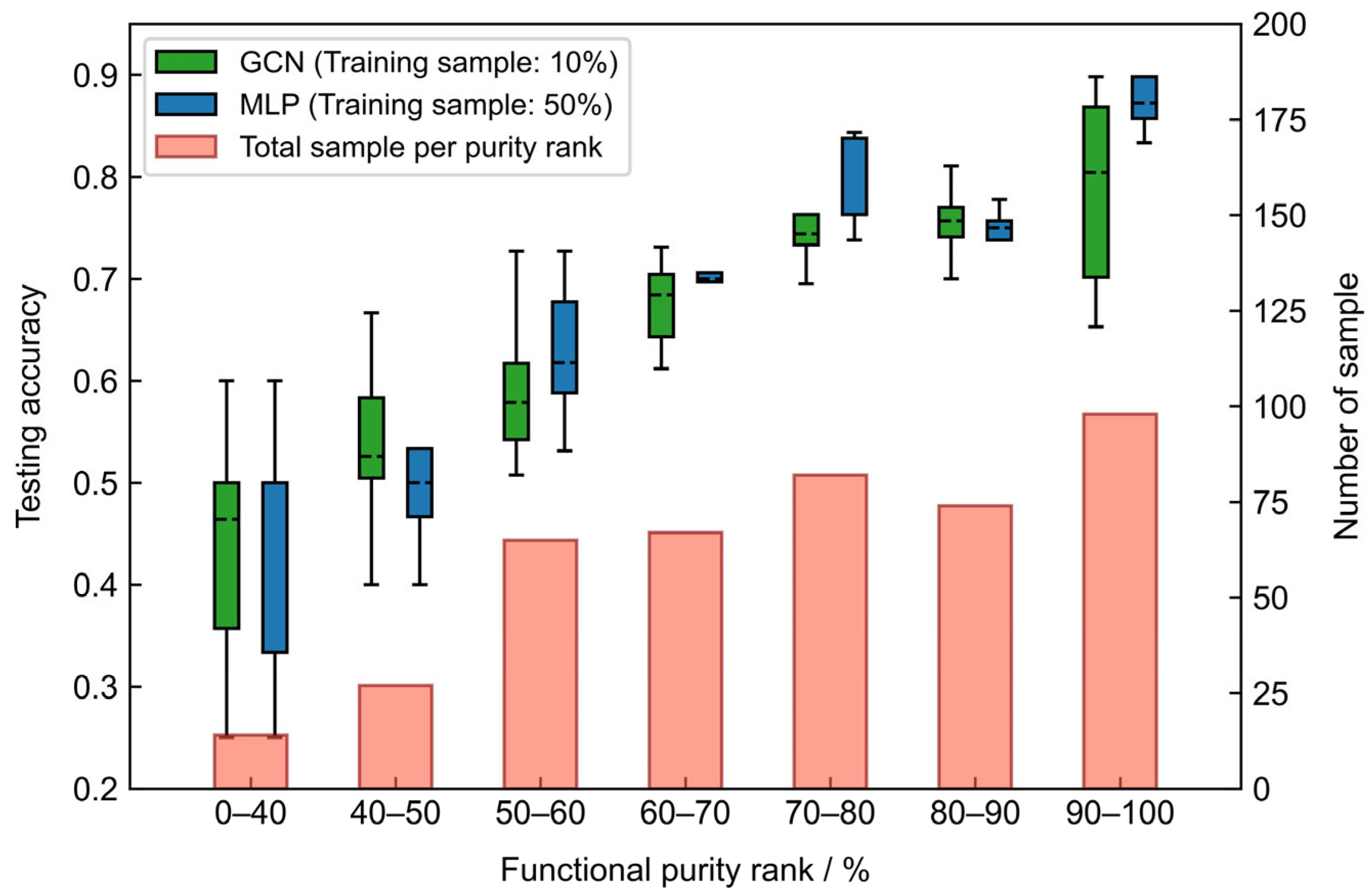
3.1.4. Impact from Different Levels of Functional Heterogeneity
3.1.5. Visual Comparison
3.2. Case Study: Beijing
- 5.
- Inside the 2nd ring, commercial, residential, public service, recreational and transportation areas are 51.0%, 8.1%, 35.6%, 4.7% and 0.7% of the related sub-region. From the 2nd to 4th ring, commercial, residential, public service, recreational and transportation areas are 62.7%, 3.1%, 19.7%, 13.9% and 0.7% of the related sub-region. And outside the 4th ring, commercial, residential, public service, recreational and transportation areas are 60.3%, 6.7%, 15.2%, 11.6% and 6% of the related sub-region;
- 6.
- The classification accuracies for three sub-regions are 0.60, 0.83 and 0.69, respectively, and 0.73 for the whole study area. The belt sub-region between the 2nd and 4th ring roads contains a complex distribution of various functional regions, yet exhibits the highest accuracy among three sub-regions. This is in agreement with the relatively high variability observed in the robustness test in Section 3.1.3;
- 7.
- Confusion matrixes indicate relatively higher user accuracies of residential (and recreational) functional land use from 64% to 88% (67% to 100%). The user accuracy of commercial (and public service) functional land use varies in three subareas from 40% to 80% (and 50% to 83%). Transportation functional land use is with less accuracy, which is probably because its low density;
- 8.
- More specifically, public service is located more in the north of the city, while transportation occurs more on the south. On the east side of the 2nd ring, Beijing Central Business District is clearly displaced (the clustered dark red colors). From the 2nd to 4th ring, the well-identified public service areas show the existence of corresponding institutes and universities, especially in the north. To the northwest part of the third sub-region, recreational areas, such as the Summer Palace and Yuanmingyuan, compose distinctive clusters (see the areas colored with dark green). POI point density is relatively low in this region, indicating a lower density of buildings and commercial activities. Areas in the south part of the city are more irregular in shape (Figure 8a), which may be explained by the fact that this region is relatively less planned and developed compared with other regions.

4. Discussion
4.1. Sensitivity and Accuracy
4.2. When Is Machine Learning Application the Best Choice?
4.3. Limitation and Future Work
5. Conclusions
- As the amount of training sample grows, models’ accuracies are improved, but with different potentials. GCN model is with the top accuracy, from 0.65 to 0.70, when the number of training samples is less than 10%, while MLP and RF show top accuracies when the number of training samples exceeds around 10%;
- With a large amount of training samples, which is normally in the modification of existing urban functional area maps, RF and MLP could be the best selection. However, one should note that MLP is less stable with the same training set, but varies less in cross-validation. For RF, the increasing of the number of decision trees may not increase the final accuracy, but may increase the model’s instability;
- With a small amount of training samples, which is normally the case in the real world, GCN could provide viable results by incorporating the auxiliary information provided by the proposed semantic linkages. For example, with the incorporating of the similarity-based semantic linkage, the model could be trained using only 5% of the total samples and produce an accuracy of 0.68;
- In the perspective of the model overfit problem, which could be ignored in the real application due to lacking enough testing samples, when the training samples is less than 10%, we suggest choosing GCN for the urban functional land use prediction, and one should be cautious using MLP, by testing the optimal epoch for obtaining the best accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| ID | POI Category | ID | POI Category |
|---|---|---|---|
| 0 | Automobile Service Related | 135 | Stationary Store |
| 1 | Filling Station | 136 | Sports Store |
| 2 | Other Energy Station | 137 | Commercial Street |
| 3 | Automobile Maintenance/Decoration | 138 | Clothing Store |
| 4 | Car Wash | 139 | Franchise Store |
| 5 | Automobile Club | 140 | Special Trade House |
| 6 | Automobile Rescue | 141 | Personal Care Items Shop |
| 7 | Automobile Parts Sales | 142 | Daily Life Service Place |
| 8 | Automobile Rental | 143 | Travel Agency |
| 9 | Used Automobile Dealer | 144 | Information Centre |
| 10 | Charging Station | 145 | Ticket Office |
| 11 | Automobile Sales | 146 | Post Office |
| 12 | Volkswagen Franchised Sales | 147 | Post Office |
| 13 | Honda Franchised Sales | 148 | Logistics Service |
| 14 | Audi Franchised Sales | 149 | Telecom Office |
| 15 | General Motors Franchised Sales | 150 | Professional Service Firm |
| 16 | BMW Franchised Sales | 151 | Job Center |
| 17 | Nissan Franchised Sales | 152 | Water Supply Service Office |
| 18 | Renault Franchised Sales | 153 | Electric Supply Service Office |
| 19 | Mercedes-Benz Franchised Sales | 154 | Beauty and Hairdressing Store |
| 20 | Toyota Franchised Sales | 155 | Repair Store |
| 21 | Subaru Franchised Sales | 156 | Photo Finishing |
| 22 | Peugeot Citroen Franchised Sales | 157 | Bath & Massage Center |
| 23 | Peugeot Citroen | 158 | Laundry |
| 24 | Mitsubishi Franchised Sales | 159 | Agency |
| 25 | Fiat Franchised Sales | 160 | Move Service |
| 26 | Ferrari Franchised Sales | 161 | Lottery Store |
| 27 | Hyundai Franchised Sales | 162 | Funeral Facilities |
| 28 | KIA Franchised Sales | 163 | Baby Service Place |
| 29 | Ford Franchised Sales | 164 | Shared Device |
| 30 | JAGUAR Franchised Sales | 165 | Sports & Recreation Places |
| 31 | Land Rover Franchised Sales | 166 | Sports Stadium |
| 32 | Porsche Franchised Sales | 167 | Golf Related |
| 33 | DFM Franchised Sales | 168 | Recreation Center |
| 34 | Geely Franchised Sales | 169 | Holiday & Nursing Resort |
| 35 | Chery Franchised Sales | 170 | Recreation Place |
| 36 | Chrysler Franchised Sales | 171 | Theatre & Cinema |
| 37 | ROEWE Sales | 172 | Medical and Health Care Service Place |
| 38 | MG Sales | 173 | Hospital |
| 39 | JAC Sales | 174 | Special Hospital |
| 40 | Hongqi Sales | 175 | Clinic |
| 41 | Chang’an Sales | 176 | Emergency Center |
| 42 | Haima Sales | 177 | Disease Prevention Institution |
| 43 | BAIC MOTOR Sales | 178 | Pharmacy |
| 44 | Great Wall Sales | 179 | Veterinary Hospital |
| 45 | Luxgen Sales | 180 | Accommodation Service Related |
| 46 | GAC Trumpchi Sales | 181 | Hotel |
| 47 | Truck Sales | 182 | Hostel |
| 48 | Dongfeng Truck Sales | 183 | Tourist Attraction Related |
| 49 | SINOTRUK Sales | 184 | Park & Square |
| 50 | FAW Jiefang Sales | 185 | Park & Plaza |
| 51 | Foton Truck Sales | 186 | Scenery Spot |
| 52 | Shaanxi Heavy-duty Truck Sales | 187 | Commercial House Related |
| 53 | Beiben Trucks Sales | 188 | Industrial Park |
| 54 | JAC Truck Sales | 189 | Building |
| 55 | CAMC Sales | 190 | Residential Area |
| 56 | Chengdu Dayun Automotive Sales | 191 | Governmental & Social Groups Related |
| 57 | Mercedes-Benz Truck Sales | 192 | Governmental Organization |
| 58 | MAN Sales | 193 | Foreign Organization |
| 59 | SCANIA Sales | 194 | Democratic Party |
| 60 | Volvo Truck Sales | 195 | Social Group |
| 61 | Qoros Sales | 196 | Public Security Organization |
| 62 | Automobile Repair | 197 | Traffic Vehicle Management |
| 63 | Automobile Comprehensive Repair | 198 | Industrial and Commercial Taxation Institution |
| 64 | Volkswagen Franchised Repair | 199 | Science & Education Cultural Place |
| 65 | Honda Franchised Repair | 200 | Museum |
| 66 | Audi Franchised Repair | 201 | Exhibition Hall |
| 67 | General Motors Franchised Repair | 202 | Convention & Exhibition Center |
| 68 | BMW Franchised Repair | 203 | Art Gallery |
| 69 | Nissan Franchised Repair | 204 | Library |
| 70 | Renault Franchised Repair | 205 | Science & Technology Museum |
| 71 | Mercedes-Benz Franchised Repair | 206 | Planetarium |
| 72 | Toyota Franchised Repair | 207 | Cultural Palace |
| 73 | Subaru Franchised Repair | 208 | Archives Hall |
| 74 | Peugeot Citroen Franchised Repair | 209 | Arts Organization |
| 75 | Peugeot Citroen | 210 | Media Organization |
| 76 | Mitsubishi Franchised Repair | 211 | School |
| 77 | Fiat Franchised Repair | 212 | Research Institution |
| 78 | Ferrari Franchised Repair | 213 | Training Institution |
| 79 | Hyundai Franchised Repair | 214 | Driving School |
| 80 | KIA Franchised Repair | 215 | Transportation Service Related |
| 81 | Ford Franchised Repair | 216 | Airport Related |
| 82 | JAGUAR Franchised Repair | 217 | Railway Station |
| 83 | Land Rover Franchised Repair | 218 | Port & Marina |
| 84 | Porsche Franchised Repair | 219 | Coach Station |
| 85 | DFM Franchised Repair | 220 | Subway Station |
| 86 | Geely Franchised Repair | 221 | Light Rail Station |
| 87 | Chery Franchised Repair | 222 | Bus Station |
| 88 | Chrysler Franchised Repair | 223 | Commuter Bus Station |
| 89 | ROEWE Repair | 224 | Parking Lot |
| 90 | MG Repair | 225 | Border Crossing |
| 91 | JAC Repair | 226 | Taxi |
| 92 | Hongqi Repair | 227 | Ferry Station |
| 93 | Chang’an Repair | 228 | Ropeway Station |
| 94 | Haima Repair | 229 | Loading & Unloading Area |
| 95 | BAIC MOTOR Repair | 230 | Finance & Insurance Service Institution |
| 96 | Great Wall Repair | 231 | Bank |
| 97 | Luxgen Repair | 232 | Bank Related |
| 98 | GAC Trumpchi Repair | 233 | ATM |
| 99 | Truck Repair | 234 | Insurance Company |
| 100 | Dongfeng Truck Repair | 235 | Securities Company |
| 101 | SINOTRUK Repair | 236 | Finance Company |
| 102 | FAW Jiefang Repair | 237 | Enterprises |
| 103 | Foton Truck Repair | 238 | Famous Enterprise |
| 104 | Shaanxi Heavy-duty Truck Repair | 239 | Company |
| 105 | Beiben Trucks Repair | 240 | Factory |
| 106 | JAC Truck Repair | 241 | Farming, Forestry, Animal Husbandry and Fishery Base |
| 107 | CAMC Repair | 242 | Road Furniture |
| 108 | Chengdu Dayun Automotive Repair | 243 | Warning Sign |
| 109 | Mercedes-Benz Truck Repair | 244 | Toll Gate |
| 110 | MAN Repair | 245 | Service Area |
| 111 | SCANIA Repair | 246 | Traffic Light |
| 112 | Volvo Truck Repair | 247 | Signpost |
| 113 | Qoros Repair | 248 | Place Name & Address |
| 114 | Motorcycle Service Related | 249 | Natural Place Name |
| 115 | Motorcycle Sales | 250 | Transportation Place Name |
| 116 | Motorcycle Repair | 251 | Address Sign |
| 117 | Food & Beverages Related | 252 | City Center |
| 118 | Chinese Food Restaurant | 253 | Landmark Buildings |
| 119 | Foreign Food Restaurant | 254 | The hot names |
| 120 | Fast Food Restaurant | 255 | Public Facility |
| 121 | Leisure Food Restaurant | 256 | Newsstand |
| 122 | Coffee House | 257 | Public Phone |
| 123 | Tea House | 258 | Public Toilet |
| 124 | Icecream Shop | 259 | Emergency Shelter |
| 125 | Bakery | 260 | Incidents and Events |
| 126 | Dessert House | 261 | Public Event |
| 127 | Shopping Related Places | 262 | Emergency |
| 128 | Shopping Plaza | 263 | Indoor facilities |
| 129 | Convenience Store | 264 | Pass Facilities |
| 130 | Home Electronics Hypermarket | 265 | Gate of Buildings |
| 131 | Supermarket | 266 | Gate of Street House |
| 132 | Plants & Pet Market | 267 | Virtual Gate |
| 133 | Home Building Materials Market | 268 | Special corridor |
| 134 | Comprehensive Market |
| Percentage of Raining Sample (%) | Area Type | Number of Samples | Percentage of Raining Sample (%) | Area Type | Number of Samples |
|---|---|---|---|---|---|
| 2 | Commercial | 1 | 40 | Commercial | 34 |
| Residential | 3 | Residential | 97 | ||
| Public service | 3 | Public service | 30 | ||
| Recreational | 2 | Recreational | 23 | ||
| Transportation | 1 | Transportation | 4 | ||
| 4.7 | Commercial | 6 | 50 | Commercial | 42 |
| Residential | 4 | Residential | 123 | ||
| Public service | 4 | Public service | 32 | ||
| Recreational | 4 | Recreational | 32 | ||
| Transportation | 4 | Transportation | 5 | ||
| 10 | Commercial | 8 | 80 | Commercial | 65 |
| Residential | 19 | Residential | 196 | ||
| Public service | 8 | Public service | 62 | ||
| Recreational | 8 | Recreational | 46 | ||
| Transportation | 4 | Transportation | 5 | ||
| 20 | Commercial | 25 | 90 | Commercial | 79 |
| Residential | 42 | Residential | 222 | ||
| Public service | 19 | Public service | 63 | ||
| Recreational | 6 | Recreational | 48 | ||
| Transportation | 2 | Transportation | 9 | ||
| 30 | Commercial | 24 | |||
| Residential | 69 | ||||
| Public service | 25 | ||||
| Recreational | 20 | ||||
| Transportation | 2 |
References
- Duranton, G.; Puga, D. Chapter 8—Urban Land Use. In Handbook of Regional and Urban Economics; Duranton, G., Henderson, J.V., Strange, W.C., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 467–560. [Google Scholar]
- Cai, D.; Fraedrich, K.; Guan, Y.; Guo, S.; Zhang, C. Urbanization and the thermal environment of Chinese and US-American cities. Sci. Total Environ. 2017, 589, 200–211. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xing, Q.; Sun, Z.; Tao, Y.; Shang, J.; Miao, S.; Xiao, C.; Zheng, C. Projections of future temperature-related cardiovascular mortality under climate change, urbanization and population aging in Beijing, China. Environ. Int. 2022, 163, 107231. [Google Scholar] [CrossRef] [PubMed]
- Asabere, S.B.; Acheampong, R.A.; Ashiagbor, G.; Beckers, S.C.; Keck, M.; Erasmi, S.; Schanze, J.; Sauer, D. Urbanization, land use transformation and spatio-environmental impacts: Analyses of trends and implications in major metropolitan regions of Ghana. Land Use Policy 2020, 96, 104707. [Google Scholar] [CrossRef]
- Dadashpoor, H.; Azizi, P.; Moghadasi, M. Land use change, urbanization, and change in landscape pattern in a metropolitan area. Sci. Total Environ. 2019, 655, 707–719. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.; He, Z.; Wu, L.; Yin, L.; Cui, H. A framework for extracting urban functional regions based on multiprototype word. Computers Environ. Urban Syst. 2019, 80, 101442. [Google Scholar] [CrossRef]
- Goldstein, J.H.; Caldarone, G.; Duarte, T.K.; Ennaanay, D.; Hannahs, N.; Mendoza, G.; Polasky, S.; Wolny, S.; Daily, G.C. Integrating ecosystem-service tradeoffs into land-use decisions. Proc. Natl. Acad. Sci. USA 2012, 109, 7565–7570. [Google Scholar] [CrossRef] [Green Version]
- Frias-Martinez, V.; Frias-Martinez, E. Spectral clustering for sensing urban land use using Twitter activity. Eng. Appl. Artif. Intell. 2014, 35, 237–245. [Google Scholar] [CrossRef] [Green Version]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.R.; Gu, C. Beyond Word2vec: An approach for urban functional region extraction and identification by combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Sanchez, T.W.; Shumway, H.; Gordner, T.; Lim, T. The prospects of artificial intelligence in urban planning. Int. J. Urban Sci. 2022, 1–16. [Google Scholar] [CrossRef]
- Zhang, J.; He, X.; Yuan, X.-D. Research on the relationship between Urban economic development level and urban spatial structure—A case study of two Chinese cities. PLoS ONE 2020, 15, e0235858. [Google Scholar] [CrossRef] [PubMed]
- Du, M.; Zhang, X.; Mora, L. Strategic Planning for Smart City Development: Assessing Spatial Inequalities in the Basic Service Provision of Metropolitan Cities. J. Urban Technol. 2021, 28, 115–134. [Google Scholar] [CrossRef]
- Cariolet, J.-M.; Colombert, M.; Vuillet, M.; Diab, Y. Assessing the resilience of urban areas to traffic-related air pollution: Application in Greater Paris. Sci. Total Environ. 2018, 615, 588–596. [Google Scholar] [CrossRef] [PubMed]
- Hao, H.; Wang, Y. Disentangling relations between urban form and urban accessibility for resilience to extreme weather and climate events. Landsc. Urban Plan. 2022, 220, 104352. [Google Scholar] [CrossRef]
- Kim, D.; Song, S.-K. Measuring changes in urban functional capacity for climate resilience: Perspectives from Korea. Futures 2018, 102, 89–103. [Google Scholar] [CrossRef]
- Ouyang, X.; Wei, X.; Li, Y.; Wang, X.-C.; Klemeš, J.J. Impacts of urban land morphology on PM2. 5 concentration in the urban agglomerations of China. J. Environ. Manag. 2021, 283, 112000. [Google Scholar] [CrossRef]
- Yu, Z.; Jing, Y.; Yang, G.; Sun, R. A new urban functional zone-based climate zoning system for urban temperature study. Remote Sens. 2021, 13, 251. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, P.; Hong, Y.; Liang, Z.; Wang, R.; Guan, Q.; Chen, J. Fine-scale intra- and inter-city commercial store site recommendations using knowledge transfer. Trans. GIS 2019, 23, 1029–1047. [Google Scholar] [CrossRef]
- Klapka, P.; Kraft, S.; Halás, M. Network based definition of functional regions: A graph theory approach for spatial distribution of traffic flows. J. Transp. Geogr. 2020, 88, 102855. [Google Scholar] [CrossRef]
- Zhao, P.; Luo, A.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 2512–2524. [Google Scholar] [CrossRef]
- Shen, G.; Zhao, Z.; Kong, X. GCN2CDD: A Commercial District Discovery Framework via Embedding Space Clustering on Graph Convolution Networks. IEEE Trans. Ind. Inform. 2022, 18, 356–364. [Google Scholar] [CrossRef]
- Yang, J.; Wang, Y.; Xiu, C.; Xiao, X.; Xia, J.; Jin, C. Optimizing local climate zones to mitigate urban heat island effect in human settlements. J. Clean. Prod. 2020, 275, 123767. [Google Scholar] [CrossRef]
- Lyu, Y.; Wang, M.; Zou, Y.; Wu, C. Mapping trade-offs among urban fringe land use functions to accurately support spatial planning. Sci. Total Environ. 2022, 802, 149915. [Google Scholar] [CrossRef]
- Guan, Q.; Zhou, J.; Wang, R.; Yao, Y.; Qian, C.; Zhai, Y.; Ren, S. Understanding China’s urban functional patterns at the county scale by using time-series social media data. J. Spat. Sci. 2022, 1–19. [Google Scholar] [CrossRef]
- Cai, M. Natural language processing for urban research: A systematic review. Heliyon 2021, 7, e06322. [Google Scholar] [CrossRef] [PubMed]
- Zhu, D.; Zhang, F.; Wang, S.; Wang, Y.; Cheng, X.; Huang, Z.; Liu, Y. Understanding Place Characteristics in Geographic Contexts through Graph Convolutional Neural Networks. Ann. Am. Assoc. of Geogr. 2020, 110, 408–420. [Google Scholar] [CrossRef]
- Xu, N.; Luo, J.; Wu, T.; Dong, W.; Liu, W.; Zhou, N. Identification and portrait of urban functional zones based on multisource heterogeneous data and ensemble learning. Remote Sens. 2021, 13, 373. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, H.; Liu, Y.; Zhou, J.; Xu, T.; Xiong, H. Semi-Supervised City-Wide Parking Availability Prediction via Hierarchical Recurrent Graph Neural Network. IEEE Trans. Knowl. Data Eng. 2022, 34, 3984–3996. [Google Scholar] [CrossRef]
- Kim, N.; Yoon, Y. Effective Urban Region Representation Learning Using Heterogeneous Urban Graph Attention Network (HUGAT). arXiv preprint 2022, arXiv:2202.09021. [Google Scholar]
- Zhu, D.; Liu, Y.; Yao, X.; Fischer, M.M. Spatial regression graph convolutional neural networks: A deep learning paradigm for spatial multivariate distributions. GeoInformatica 2022, 26, 645–676. [Google Scholar] [CrossRef]
- Geng, X.; Li, Y.; Wang, L.; Zhang, L.; Yang, Q.; Ye, J.; Liu, Y. Spatiotemporal Multi-Graph Convolution Network for Ride-Hailing Demand Forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3656–3663. [Google Scholar] [CrossRef]
- Chi, J.; Jiao, L.; Dong, T.; Gu, Y.; Ma, Y. Quantitative identification and visualization of urban functional area based on POI data. J. Geomat 2016, 41, 68–73. [Google Scholar]
- Miao, R.; Wang, Y.; Li, S. Analyzing urban spatial patterns and functional zones using sina Weibo POI data: A case study of Beijing. Sustainability 2021, 13, 647. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Li, Y. Identification of Urban Functional Areas and Their Mixing Degree Using Point of Interest Analyses. Land 2022, 11, 996. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Zhan, X.; Ukkusuri, S.V.; Zhu, F. Inferring Urban Land Use Using Large-Scale Social Media Check-in Data. Netw. Spat. Econ. 2014, 14, 647–667. [Google Scholar] [CrossRef]
- Wong, K.S.; Tanaka, K. Data embedding for geo-tagging any contents in smart device. In Proceedings of the 2014 IEEE Region 10 Symposium, Kuala Lumpur, Malaysia, 14–16 April 2014. [Google Scholar]
- Hu, Y.; Han, Y. Identification of Urban Functional Areas Based on POI Data: A Case Study of the Guangzhou Economic and Technological Development Zone. Sustainability 2019, 11, 1385. [Google Scholar] [CrossRef] [Green Version]
- Iranmanesh, A.; Cömert, N.Z.; Hoşkara, Ş.Ö. Reading urban land use through spatio-temporal and content analysis of geotagged Twitter data. GeoJournal 2022, 87, 2593–2610. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining 2012, Association for Computing Machinery, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Liu, W.; Lü, L. Link prediction based on local random walk. EPL (Europhys. Lett.) 2010, 89, 58007. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Saravanan, R.; Sujatha, P. A State of Art Techniques on Machine Learning Algorithms: A Perspective of Supervised Learning Approaches in Data Classification. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018. [Google Scholar]
- Aly, M. Survey on multiclass classification methods. Neural Netw 2005, 19, 9. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]
- Woldesemayat, E.M.; Genovese, P.V. Urban Green Space Composition and Configuration in Functional Land Use Areas in Addis Ababa, Ethiopia, and Their Relationship with Urban Form. Land 2021, 10, 85. [Google Scholar] [CrossRef]
- Junker, M.; Hoch, R.; Dengel, A. On the evaluation of document analysis components by recall, precision, and accuracy. In Proceedings of the Fifth International Conference on Document Analysis and Recognition ICDAR’99 (Cat. No. PR00318), Bangalore, India, 22 September 1999. [Google Scholar]
- Dietterich, T. Overfitting and undercomputing in machine learning. ACM Comput. Surv. (CSUR) 1995, 27, 326–327. [Google Scholar] [CrossRef]
- Parsons, V.L. Stratified sampling. Wiley StatsRef Stat. Ref. Online 2014, 1–11. [Google Scholar]
- Stone, M. Cross-validation:a review. Ser. Stat. 1978, 9, 127–139. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? ArXiv 2019, arXiv:1810.00826. [Google Scholar]
- Ganesan, S.; Lau, S.S.Y. Urban challenges in Hong Kong: Future directions for design. Urban Des. Int. 2000, 5, 3–12. [Google Scholar] [CrossRef]
- Liu, G.; Yang, Z.; Chen, B.; Ulgiati, S. Monitoring trends of urban development and environmental impact of Beijing, 1999–2006. Sci. Total Environ. 2011, 409, 3295–3308. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Du, S. A Linear Dirichlet Mixture Model for decomposing scenes: Application to analyzing urban functional zonings. Remote Sens. Environ. 2015, 169, 37–49. [Google Scholar] [CrossRef]
- Wang, J.-F.; Zhang, T.-L.; Fu, B.-J. A measure of spatial stratified heterogeneity. Ecol. Indic. 2016, 67, 250–256. [Google Scholar] [CrossRef]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of Classification Algorithms and Training Sample Sizes in Urban Land Classification with Landsat Thematic Mapper Imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Zhang, K.; Ming, D.; Du, S.; Xu, L.; Ling, X.; Zeng, B.; Lv, X. Distance Weight-Graph Attention Model-Based High-Resolution Remote Sensing Urban Functional Zone Identification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Wu, Y.; Zhuang, D.; Labbe, A.; Sun, L. Inductive Graph Neural Networks for Spatiotemporal Kriging. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4478–4485. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, T.; Tsou, M.-H.; Li, H.; Jiang, W.; Guo, F. Mapping Dynamic Urban Land Use Patterns with Crowdsourced Geo-Tagged Social Media (Sina-Weibo) and Commercial Points of Interest Collections in Beijing, China. Sustainability 2016, 8, 1202. [Google Scholar] [CrossRef]





| Model | Training Sample Quantity | Hyperparameters | Python Library | |
|---|---|---|---|---|
| Supervised | SVM | Large | Value of the slack variable (In Soft Margin term) | Scikit-learn |
| RF-128 | Large | Number of Decision Trees | Scikit-learn | |
| RF-200 | ||||
| MLP | Large | (a) Number of Hidden Layers (b) Corresponding Neurons (c) Weighting and Focusing Factors (In Focal Loss Function) | Pytorch | |
| Semi-supervised | GCN | Relatively Less | Similarity Thresholds (In Semantic Linkage) | Pytorch-Geometric |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, R.; Guan, Y.; Cai, D.; Yang, T.; Fraedrich, K.; Zhang, C.; Tang, J.; Liao, Z.; Wei, Z.; Guo, S. Supervised versus Semi-Supervised Urban Functional Area Prediction: Uncertainty, Robustness and Sensitivity. Remote Sens. 2023, 15, 341. https://doi.org/10.3390/rs15020341
Deng R, Guan Y, Cai D, Yang T, Fraedrich K, Zhang C, Tang J, Liao Z, Wei Z, Guo S. Supervised versus Semi-Supervised Urban Functional Area Prediction: Uncertainty, Robustness and Sensitivity. Remote Sensing. 2023; 15(2):341. https://doi.org/10.3390/rs15020341
Chicago/Turabian StyleDeng, Rui, Yanning Guan, Danlu Cai, Tao Yang, Klaus Fraedrich, Chunyan Zhang, Jiakui Tang, Zhouwei Liao, Zhishou Wei, and Shan Guo. 2023. "Supervised versus Semi-Supervised Urban Functional Area Prediction: Uncertainty, Robustness and Sensitivity" Remote Sensing 15, no. 2: 341. https://doi.org/10.3390/rs15020341