
CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection
 , , , and
, , , and
Abstract
:1. Introduction
2. Related Works
2.1. Infrared Small Target Datasets
2.2. Infrared Small Target Detection Methods
2.3. Evaluation Metrics
3. SLR-IRST Dataset
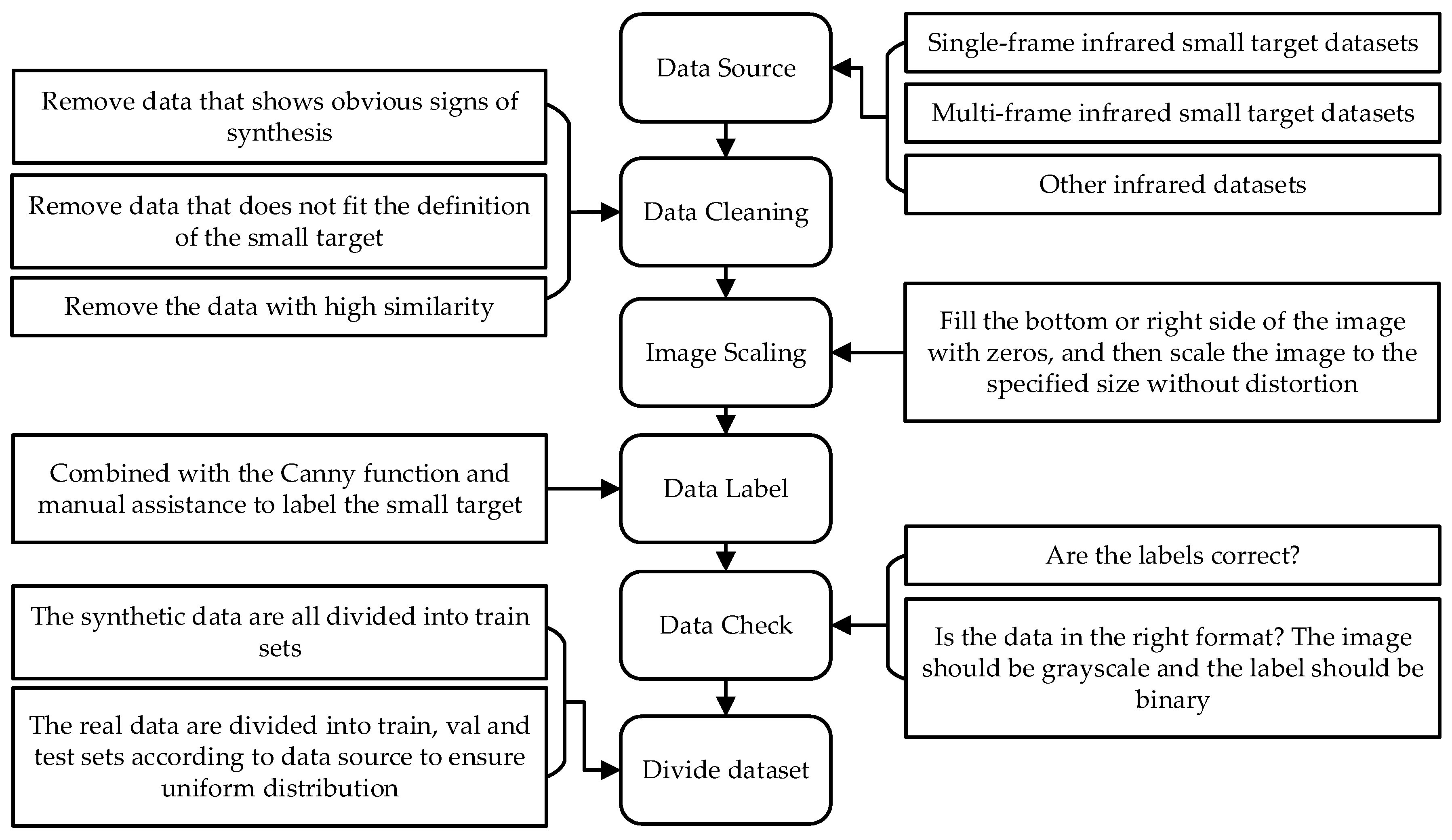
3.1. Construction of the SLR-IRST Dataset
- 1.
- Data Source: The data in the SLR-IRST dataset are from a single-frame infrared small target dataset (SIRST, IRSTD-1k, IRST640, SIRST-v2 [36]) and a multi-frame infrared small target dataset (IRDST [25]). There is a serious shortage of maritime target data in the existing dataset (see Table 3), so some waterborne target images were extended in the SLR-IRST dataset from this infrared dataset (http://iray.iraytek.com:7813/apply/Sea_shipping.html/ (accessed on 10 December 2021)).
- 2.
- Data Cleaning: The collected images were first data cleaned. The images that did not meet the small target definition [30] or had obvious synthetic traces were removed. The frequency of image extraction in the multi-frame dataset, IRDST, is 1 for every 50 images. In order to ensure the diversity and balance of the data in the dataset, the structure similarity index measure (SSIM) value [37] was used to evaluate the similarity between the images. Highly similar images with SSIM values greater than 0.85 (for simple backgrounds) and 0.90 (for complex backgrounds) were discarded.
- 3.
- Image Scaling: The resolution of the images in the existing infrared small target dataset is inconsistent. Under normal circumstances, the images in the dataset would be directly resized to the specified resolution before training and testing [19]. However, the direct resize operation causes the target to deform and the label to no longer be binarized, which introduces additional errors when network testing. Therefore, the resolution of images in SLR-IRST was unified by an undistorted method [38]. Zero was filled below or to the right of the original image to make it match the aspect ratio of the specified resolution, and then resized to the specified resolution. By referring to the common resolution of infrared detection equipment and parameters of other datasets [32], the unified resolution of images in SLR-IRST was 256 × 256.
- 4.
- Data Label: The images, after the unified resolution, were re-labeled. The small target in the infrared image was fuzzy and the edge was difficult to define. The Canny function [39] helps to define the boundaries of small targets and reduce manual labeling errors. The SLR-IRST dataset has pixel-level labels, bounding box labels, and center point labels. The boundary box label and center point label are determined by calculating the boundary and center point of the pixel-level label.
- 5.
- Data Check: Finally, all the marked data was checked again to ensure that the labels are correct and the data format is correct.
- 6.
- Divide Dataset: When dividing the dataset, all the synthesized data was divided in the training set. All real data was evenly divided into training, validation, and test sets depending on the source of the data.
3.2. Construction and Characterization of the SLR-IRST Dataset
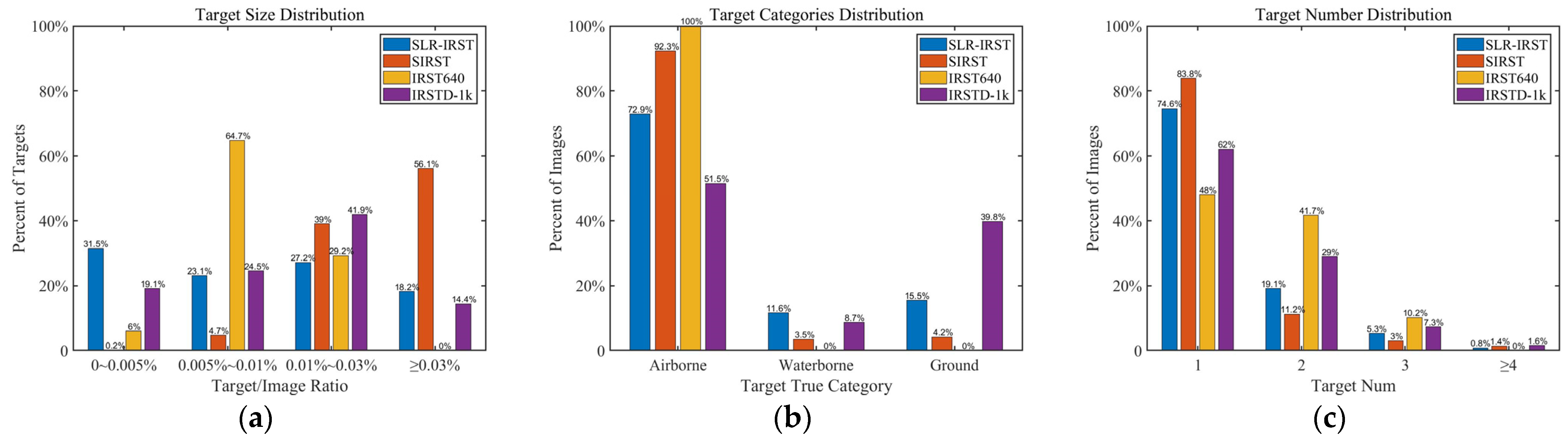
- Smaller target: As can be seen in Table 4, targets in the SLR-IRST dataset are smaller, occupying only 15.48 pixels on average and sized 3.33 × 4.58 on average. As can be seen in Figure 2a, compared with other datasets, more targets in the SLR-IRST dataset accounted for less than 0.005% of the total image.
- More balanced distribution of data categories: Figure 2b shows the statistical distribution of targets in different datasets against the real categories. The distribution of target categories in the SLR-IRST dataset is more balanced. The sample size of the waterborne targets was expanded from 87 (8.7%) in IRSTD-1k to 313 (11.3%) in SLR-IRST, which is a nearly three-fold increase. This greatly alleviates the problem of sample scarcity in the waterborne target category.
4. Methodology
4.1. Overall Architecture
4.2. Center Point-Guided Circular Region of Interest Suggestion Module
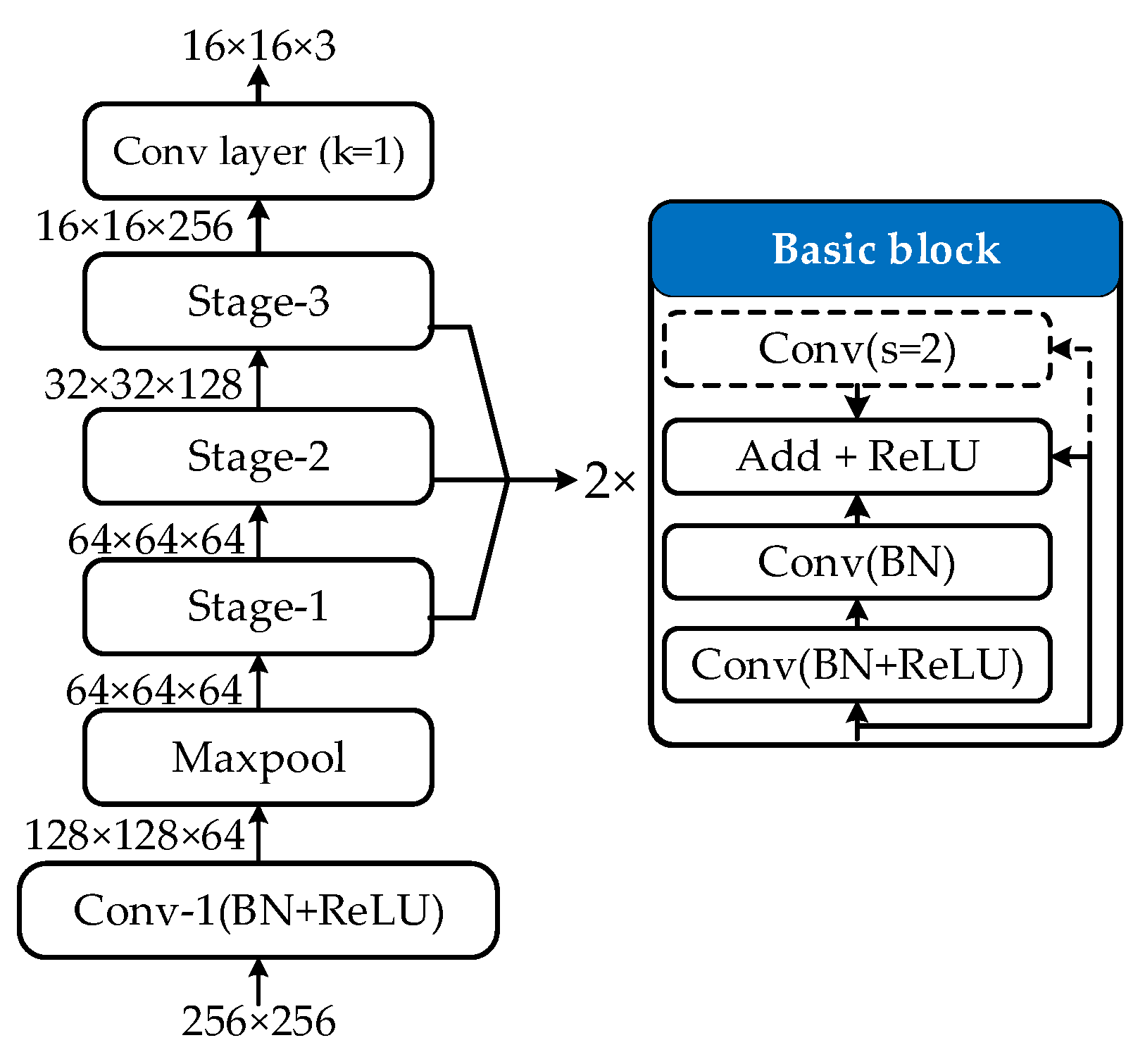
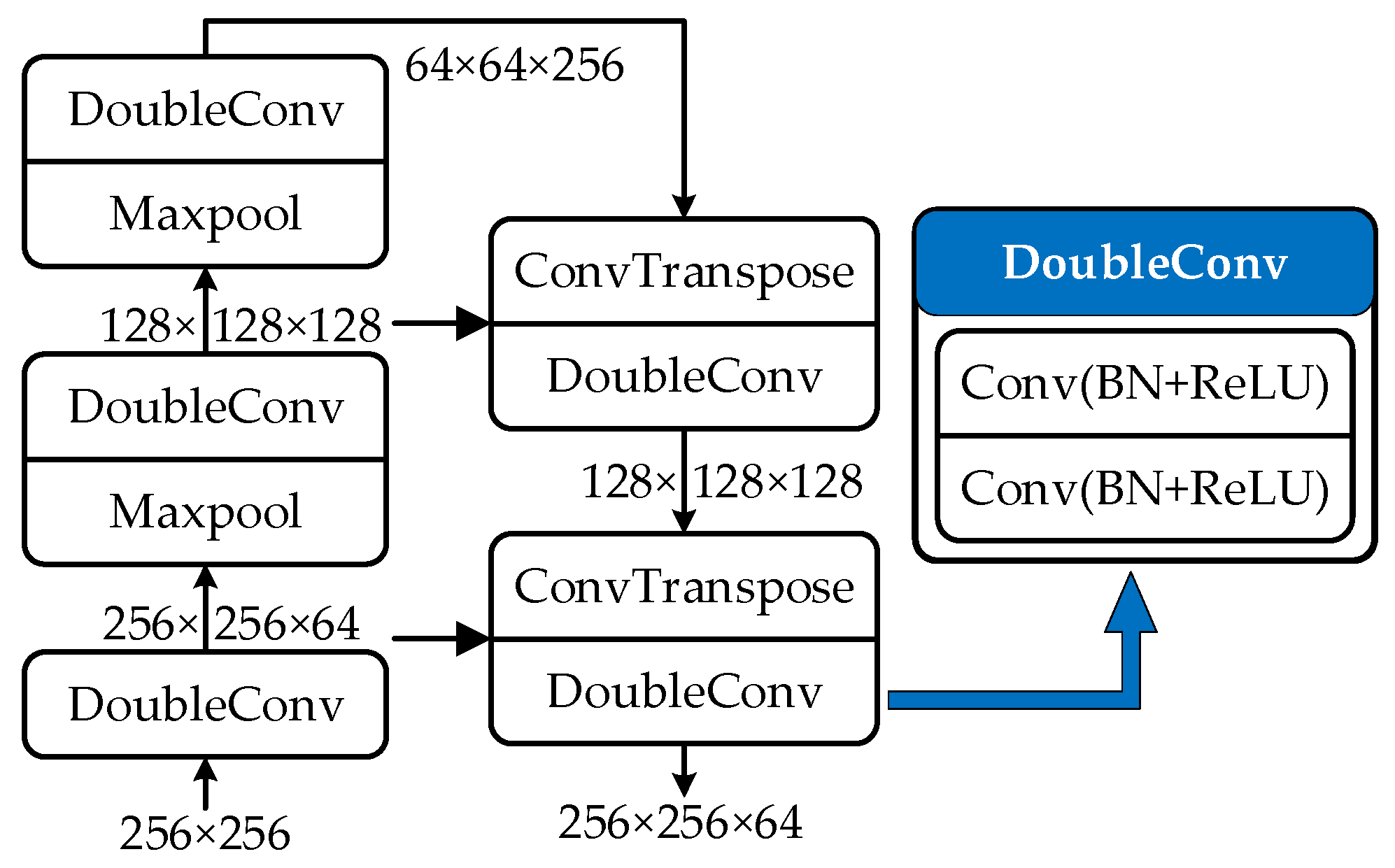
4.3. U-Shape Feature Extraction Module
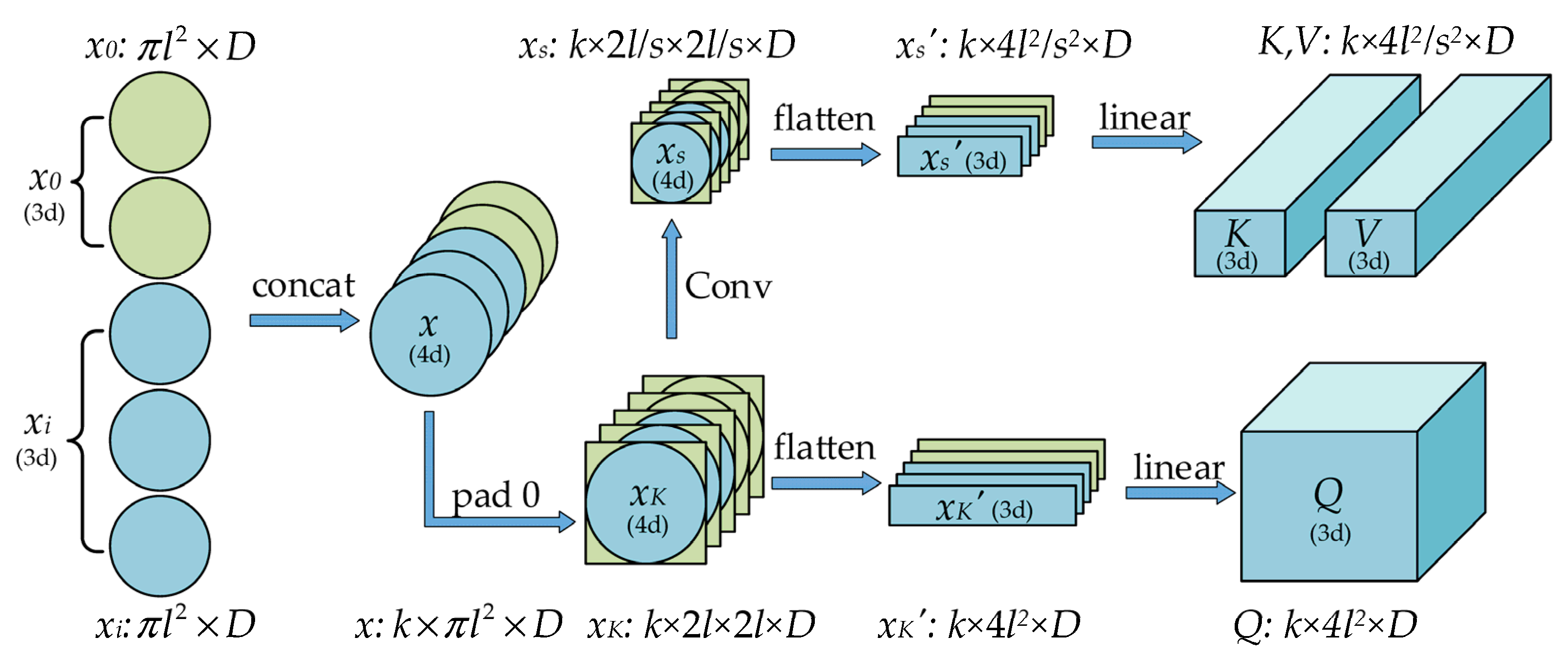
4.4. Share Params Local Self-Attention Module
5. Experiments
5.1. Experimental Setting
5.1.1. Implementation Details
5.1.2. Evaluation Metrics
5.2. Loss Function Experiments
5.3. Hyperparameter Experiments
5.4. Ablation Study
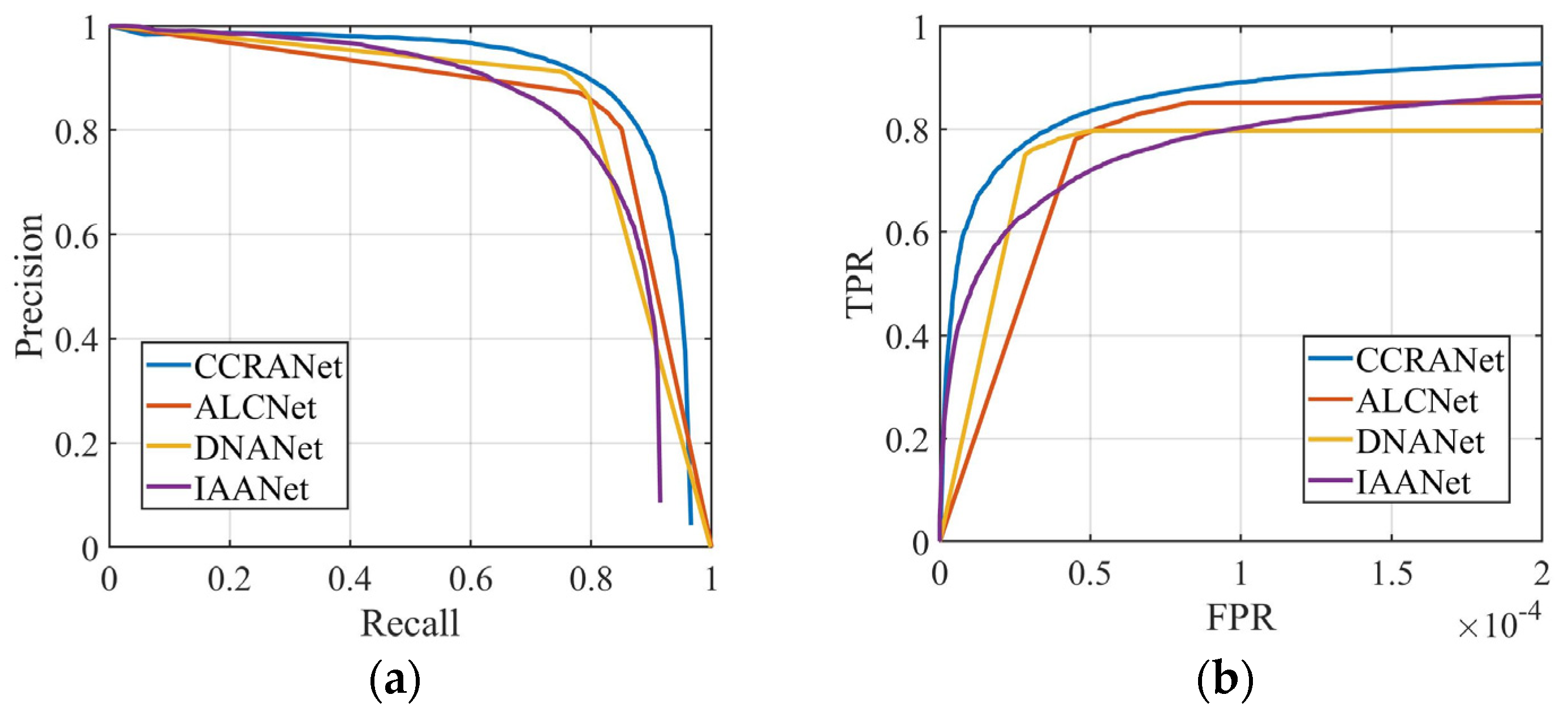
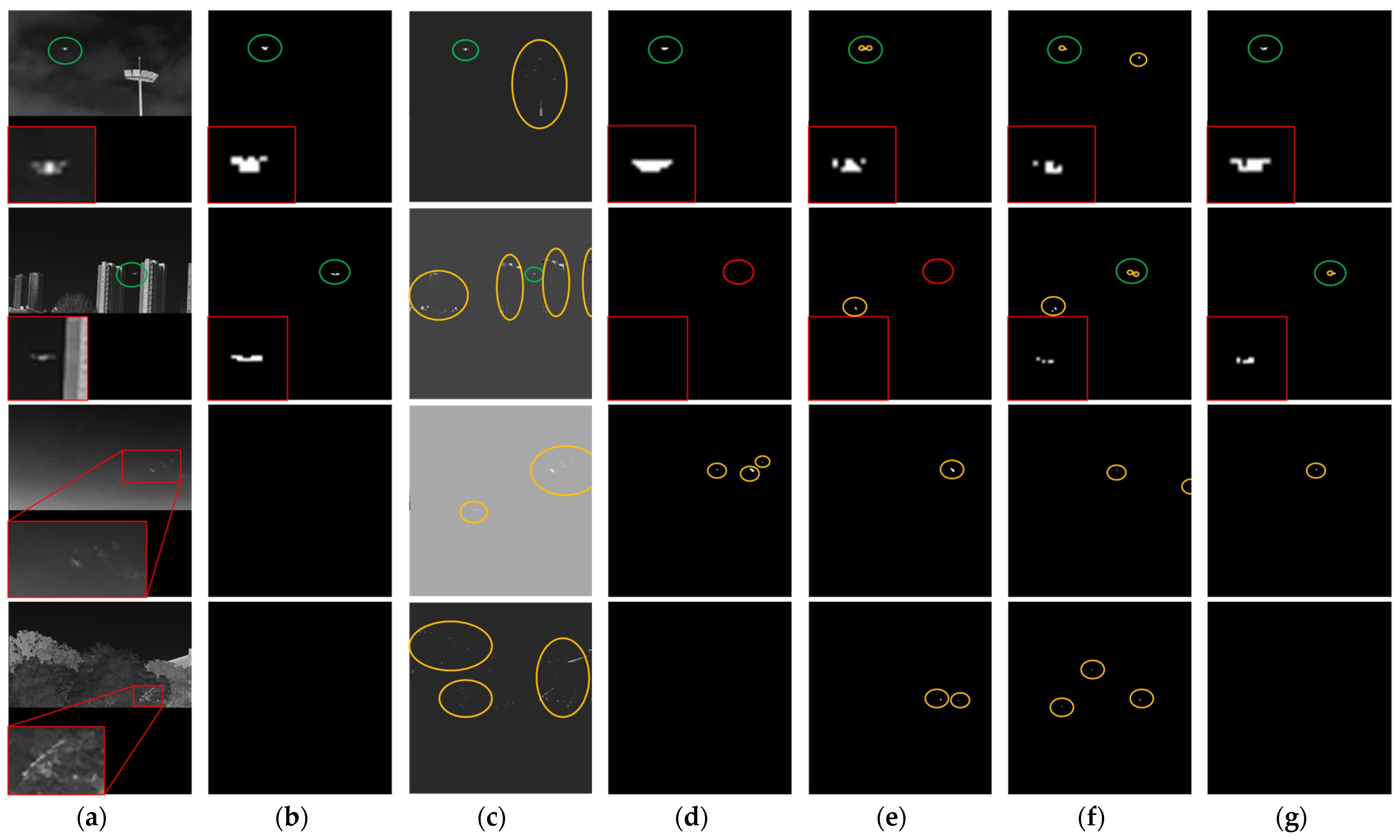
5.5. Comparison with SOTA Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Levenson, E.; Lerch, P.; Martin, M.C. Infrared imaging: Synchrotrons vs. arrays, resolution vs. speed. Infrared Phys. Technol. 2006, 49, 45–52. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-frame infrared small-target detection: A survey. IEEE Trans. Geosci. Remote Sens. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Sun, X.; Guo, L.; Zhang, W.; Wang, Z.; Yu, Q. Small aerial target detection for airborne infrared detection systems using LightGBM and trajectory constraints. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9959–9973. [Google Scholar] [CrossRef]
- Yang, P.; Dong, L.; Xu, W. Infrared small maritime target detection based on integrated target saliency measure. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2369–2386. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Tao, C.; Yang, C.; Tian, J. A robust directional saliency-based method for infrared small-target detection under various complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2012, 10, 495–499. [Google Scholar]
- Rogalski, A.; Martyniuk, P.; Kopytko, M. Challenges of small-pixel infrared detectors: A review. Rep. Prog. Phys. 2016, 79, 046501. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef]
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Comaniciu, D. An algorithm for data-driven bandwidth selection. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 281–288. [Google Scholar] [CrossRef]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A local contrast method for small infrared target detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Qin, Y.; Li, B. Effective infrared small target detection utilizing a novel local contrast method. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1890–1894. [Google Scholar] [CrossRef]
- Wei, Y.; You, X.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Infrared small-target detection using multiscale gray difference weighted image entropy. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 60–72. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Zhu, H.; Ni, H.; Liu, S.; Xu, G.; Deng, L. Tnlrs: Target-aware non-local low-rank modeling with saliency filtering regularization for infrared small target detection. IEEE Trans. Image Process. 2020, 29, 9546–9558. [Google Scholar] [CrossRef]
- Pang, D.; Shan, T.; Li, W.; Ma, P.; Tao, R.; Ma, Y. Facet derivative-based multidirectional edge awareness and spatial–temporal tensor model for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Guan, X.; Zhang, L.; Huang, S.; Peng, Z. Infrared small target detection via non-convex tensor rank surrogate joint local contrast energy. Remote Sens. 2020, 12, 1520. [Google Scholar] [CrossRef]
- Pang, D.; Ma, P.; Shan, T.; Li, W.; Tao, R.; Ma, Y.; Wang, T. STTM-SFR: Spatial–temporal tensor modeling with saliency filter regularization for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape Matters for Infrared Small Target Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar]
- Chen, G.; Wang, W.; Tan, S. IRSTFormer: A Hierarchical Vision Transformer for Infrared Small Target Detection. Remote Sens. 2022, 14, 3258. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 950–959. [Google Scholar]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Chen, F.; Gao, C.; Liu, F.; Zhao, Y.; Zhou, Y.; Meng, D.; Zuo, W. Local patch network with global attention for infrared small target detection. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3979–3991. [Google Scholar] [CrossRef]
- Tong, X.; Su, S.; Wu, P.; Guo, R.; Wei, J.; Zuo, Z.; Sun, B. MSAFFNet: A multi-scale label-supervised attention feature fusion network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef]
- Chen, Y.; Li, L.; Liu, X.; Su, X. A multi-task framework for infrared small target detection and segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–9. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Luo, Y.; Wang, Y.; Xiao, C.; Liu, T.; Yang, J.; An, W.; Guo, Y. MTU-Net: Multilevel TransUNet for Space-Based Infrared Tiny Ship Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Zhang, W.; Cong, M.; Wang, L. Algorithms for optical weak small targets detection and tracking. In Proceedings of the International Conference on Neural Networks and Signal Processing (ICNNSP), Nanjing, China, 14–17 December 2003; pp. 643–647. [Google Scholar]
- Pang, D.; Ma, P.; Feng, Y.; Shan, T.; Tao, R.; Jin, Q. Tensor Spectral k-support Norm Minimization for Detecting Infrared Dim and Small Target against Urban Backgrounds. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Hui, B.; Song, Z.; Fan, H.; Zhong, P.; Hu, W.; Zhang, X.; Ling, J.; Su, H.; Jin, W.; Zhang, Y. A dataset for infrared detection and tracking of dim-small aircraft targets under ground/air background. China Sci. Data 2020, 5, 291–302. [Google Scholar]
- Sun, H.; Bai, J.; Yang, F.; Bai, X. Receptive-field and Direction Induced Attention Network for Infrared Dim Small Target Detection with a Large-scale Dataset IRDST. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Dai, Y.; Li, X.; Zhou, F.; Qian, Y.; Chen, Y.; Yang, J. One-Stage Cascade Refinement Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Zhang, Q.; Yang, Y.B. Rest: An efficient transformer for visual recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 15475–15485. [Google Scholar]
- Duchi, J.C.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (ICAIS), Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Chintala, S.; et al. PyTorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 318–327. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Dataset | Image Num | Image Size | Provided Label | Target True Class | Background Type |
|---|---|---|---|---|---|---|
| Real | SIRST [19] | 427 | 96 × 135 to 388 × 418 | Pixel/Box | Aircraft/Drone/Ship/Vehicle | Cloud/Grass/River |
| IRSTD-1k [20] | 1001 | 512 × 512 | Pixel | Drone/Bird/Animal | Cloud/Building/Grass/River/Lake | |
| Synthetic | MFIRST [21] | 10,000 | 128 × 128 | Pixel | - | Cloud/Road |
| NUDT-SIRST [7] | 1327 | 256 × 256 | Pixel | - | Cloud/Building/Vegetation | |
| IRST640 [22] | 1024 | 640 × 512 | Pixel | - | Cloud/Building | |
| real/synthetic | SLR-IRST (our) | 2689 | 256 × 256 | Pixel/Box/Center | Aircraft/Drone/Ship/Vehicle/Bird/Animal | Cloud/Building/Grass/River/Lake/Vegetation |
| Data Type | Dataset | Sequence Num | Image Num | Image Size | Target True Class | Background Type |
|---|---|---|---|---|---|---|
| real | Dataset in [31] | 6 | 342 | 318 × 256 to 540 × 398 | Drone | City/Building/Tower Hanger |
| ISATD [32] | 22 | 16177 | 256 × 256 | Drone | Sky/Field/Building | |
| real/synthetic | IRDST [33] | 401 | 142727 | 720 × 480/934 × 696 | Aircraft/Drone | Clouds/Trees/Lakes/Buildings |
| Dataset | Airborne Target | Waterborne Target | Ground Target |
|---|---|---|---|
| SIRST | 394 | 15 | 18 |
| IRST640 | 1024 | 0 | 0 |
| IRSTD-1K | 516 | 87 | 398 |
| SLR-IRST | 1960 | 312 | 417 |
| Dataset | SLR-IRST | SIRST | IRST640 | IRSTD-1K |
|---|---|---|---|---|
| image size | 256 × 256 | 96 × 135 to 388 × 418 | 640 × 512 | 512 × 512 |
| image num | 2689 | 427 | 1024 | 1001 |
| target num | 3586 | 533 | 1662 | 1495 |
| target pixel range (average) | 1~367 (15.48) | 4~330 (32.86) | 1~51 (27.73) | 1~1065 (50.11) |
| target size range (average) | 1 × 1~14 × 34 (3.33 × 4.58) | 2 × 2~14 × 34 (5.62 × 6.94) | 1 × 1~9 × 8 (6.11 × 6.33) | 1 × 1~56 × 53 (7.69 × 8.74) |
| target SCR range (average) | 0.004~70.35 (7.46) | 0.17~42.81 (9.20) | 0.04~70.34 (4.93) | 0.004~68.76 (7.13) |
| Method | SIRST | SLR-IRST |
|---|---|---|
| ALCNet | 0.7570 | 0.7077 |
| DNANet | 0.7757 | 0.7076 |
| Seg Loss | Center Loss | nIoU (↑) | IoU (↑) | R (↑) | P (↑) | F1 − P (↑) |
|---|---|---|---|---|---|---|
| BCE | L1+BCE | 0.7340 | 0.7286 | 0.8562 | 0.8275 | 0.8416 |
| Focal | L1+BCE | 0.7398 | 0.7216 | 0.7988 | 0.8703 | 0.8330 |
| Soft-IoU | L1+BCE | 0.7359 | 0.7178 | 0.8069 | 0.8366 | 0.8215 |
| Mixed | L1+BCE | 0.7579 | 0.7398 | 0.8324 | 0.8694 | 0.8505 |
| k | l | Pixel-Level Metric | Target-Level Metric | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| nIoU (↑) | IoU (↑) | R (↑) | P (↑) | F1 − P (↑) | Pd (↑) | Md (↓) | Pa (↑) | Fa (↓) | F1 − T (↑) | ||
| 3 | 10 | 0.7348 | 0.7271 | 0.8682 | 0.8119 | 0.8391 | 0.9587 | 0.0413 | 0.8256 | 0.1744 | 0.8872 |
| 10 | 10 | 0.6764 | 0.6941 | 0.8853 | 0.7498 | 0.8119 | 0.9516 | 0.0484 | 0.7286 | 0.2714 | 0.8253 |
| 5 | 10 | 0.7579 | 0.7398 | 0.8324 | 0.8694 | 0.8505 | 0.9659 | 0.0341 | 0.8773 | 0.1227 | 0.9194 |
| 5 | 5 | 0.7216 | 0.6658 | 0.7681 | 0.8287 | 0.7973 | 0.9516 | 0.0484 | 0.8253 | 0.1747 | 0.8840 |
| 5 | 20 | 0.7395 | 0.7287 | 0.8234 | 0.8296 | 0.8265 | 0.9559 | 0.0441 | 0.7936 | 0.2064 | 0.8672 |
| CCRS | U-FE | FPN | FCN | SPSA | TSA | CONV | Name |
|---|---|---|---|---|---|---|---|
| √ | √ | √ | A (CCRANet) | ||||
| √ | √ | √ | B1 | ||||
| √ | √ | √ | B2 | ||||
| √ | √ | √ | C1 | ||||
| √ | √ | √ | C2 |
| Method | Pixel-Level Metric | Target-Level Metric | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| nIoU (↑) | IoU (↑) | R (↑) | P (↑) | F1 − P (↑) | Pd (↑) | Md (↓) | Pa (↑) | Fa (↓) | F1 − T (↑) | |
| A | 0.7579 | 0.7398 | 0.8324 | 0.8694 | 0.8505 | 0.9659 | 0.0341 | 0.8773 | 0.1227 | 0.9194 |
| B1 | 0.6795 | 0.6932 | 0.8015 | 0.8117 | 0.8066 | 0.9388 | 0.0612 | 0.9394 | 0.0616 | 0.9391 |
| B2 | 0.7243 | 0.6902 | 0.8317 | 0.7889 | 0.8097 | 0.9516 | 0.0484 | 0.7597 | 0.2413 | 0.8449 |
| C1 | 0.7348 | 0.7278 | 0.8684 | 0.8149 | 0.8408 | 0.9431 | 0.0569 | 0.8328 | 0.1672 | 0.8845 |
| C2 | 0.6691 | 0.6725 | 0.8026 | 0.7935 | 0.7980 | 0.9459 | 0.0541 | 0.6081 | 0.3919 | 0.7403 |
| Method | Pixel-Level Metric | Target-Level Metric | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| nIoU (↑) | IoU (↑) | R (↑) | P (↑) | F1 − P (↑) | Pd (↑) | Md (↓) | Pa (↑) | Fa (↓) | F1 − T (↑) | |
| IPI | 0.1986 | 0.1536 | 0.1689 | 0.6301 | 0.2663 | 0.5846 | 0.4154 | 0.4014 | 0.5986 | 0.4760 |
| ALCNet | 0.6621 | 0.7077 | 0.8150 | 0.8432 | 0.8288 | 0.8990 | 0.1010 | 0.8393 | 0.1607 | 0.8681 |
| DNANet | 0.6916 | 0.7076 | 0.7751 | 0.8905 | 0.8288 | 0.9047 | 0.0953 | 0.8583 | 0.1417 | 0.8809 |
| IAANet | 0.6724 | 0.6451 | 0.7763 | 0.7925 | 0.7843 | 0.7696 | 0.2304 | 0.6051 | 0.3949 | 0.6775 |
| CCRANet | 0.7579 | 0.7398 | 0.8324 | 0.8694 | 0.8505 | 0.9659 | 0.0341 | 0.8773 | 0.1227 | 0.9194 |
| Method | ALCNet | DNANet | IAANet | CCRANet |
|---|---|---|---|---|
| Fps (↑) | 111.09 | 45.68 | 24.43 | 66.52 |
| Method | Pixel-Level Metric | Target-Level Metric | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| nIoU (↑) | IoU (↑) | R (↑) | P (↑) | F1 − P (↑) | Pd (↑) | Md (↓) | Pa (↑) | Fa (↓) | F1 − T (↑) | |
| IPI | 0.1907 | 0.1439 | 0.2165 | 0.3003 | 0.2516 | 0.8043 | 0.1957 | 0.2681 | 0.7319 | 0.4022 |
| ALCNet | 0.5178 | 0.4886 | 0.5584 | 0.7963 | 0.6565 | 0.8478 | 0.1522 | 0.7800 | 0.2200 | 0.8125 |
| DNANet | 0.5331 | 0.5398 | 0.5866 | 0.8714 | 0.7012 | 0.9348 | 0.0652 | 0.8600 | 0.1400 | 0.8958 |
| IAANet | 0.5350 | 0.4673 | 0.5108 | 0.8459 | 0.6370 | 0.9348 | 0.0652 | 0.7818 | 0.2182 | 0.8515 |
| CCRANet | 0.5555 | 0.5832 | 0.6450 | 0.8588 | 0.7367 | 0.9565 | 0.0435 | 0.8800 | 0.1200 | 0.9167 |
| Method | IPI | ALCNet | DNANet | IAANet | CCRANet |
|---|---|---|---|---|---|
| Fa Num(↓) | 256 | 16 | 14 | 62 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Xiao, C.; Dou, H.; Liang, R.; Yuan, H.; Zhao, G.; Chen, Z.; Huang, Y. CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection. Remote Sens. 2023, 15, 5539. https://doi.org/10.3390/rs15235539
Wang W, Xiao C, Dou H, Liang R, Yuan H, Zhao G, Chen Z, Huang Y. CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection. Remote Sensing. 2023; 15(23):5539. https://doi.org/10.3390/rs15235539
Chicago/Turabian StyleWang, Wenjing, Chengwang Xiao, Haofeng Dou, Ruixiang Liang, Huaibin Yuan, Guanghui Zhao, Zhiwei Chen, and Yuhang Huang. 2023. "CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection" Remote Sensing 15, no. 23: 5539. https://doi.org/10.3390/rs15235539
APA StyleWang, W., Xiao, C., Dou, H., Liang, R., Yuan, H., Zhao, G., Chen, Z., & Huang, Y. (2023). CCRANet: A Two-Stage Local Attention Network for Single-Frame Low-Resolution Infrared Small Target Detection. Remote Sensing, 15(23), 5539. https://doi.org/10.3390/rs15235539