
DVST: Deformable Voxel Set Transformer for 3D Object Detection from Point Clouds




Abstract
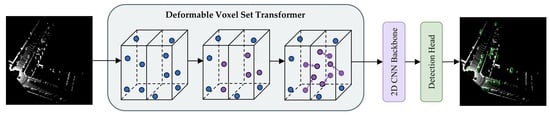
:
1. Introduction
- (1)
- The DVST deformable backbone was developed to detect objects in 3D point clouds. It combines the flexibility of deformable mechanisms, the powerful long-range modeling capability of transformers, and the linear computational complexity of set attention in a cohesive manner. By solely focusing on learning the offsets of foreground queries, the target semantic information is strengthened, the background features are weakened, and the detection performance is improved.
- (2)
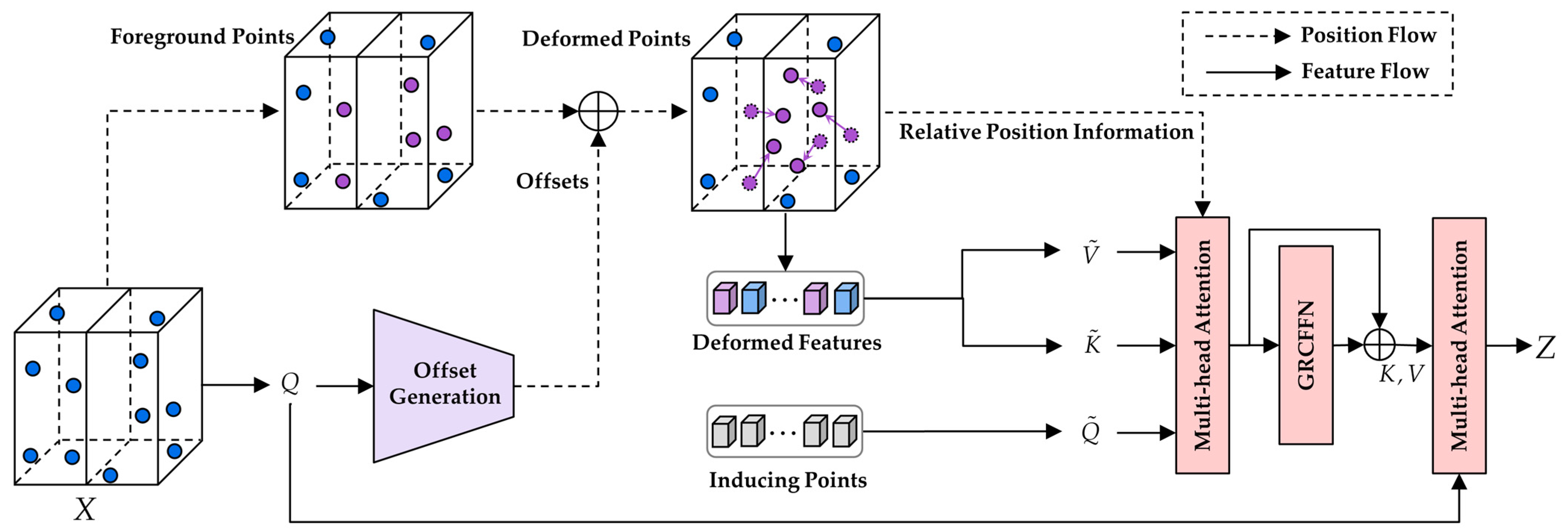
- DVSA, a deformable attention module for 3D point cloud learning, was designed for the first time. It utilizes deformable mechanisms to transfer the candidate keys and values of foreground queries to important regions. This enhancement provides the original self-attention with increased flexibility to capture target-related feature information.
- (3)
- A novel offset generation module (OGM) was constructed for learning the offsets of foreground queries in the DVSA module. This data-dependent method of generating offsets enhances the model’s robustness in detecting diverse scenarios. Moreover, a GRCFFN with a residual connection is proposed to facilitate global interaction and feature learning within the hidden space.
- (4)
- One-stage and two-stage detection models were developed based on the DVST, and experiments were performed on the KITTI and Waymo open datasets, widely used benchmarks for 3D object detection. The findings indicate that the proposed backbone enhances the performance of 3D detection while ensuring computational efficiency.
2. Related Work
2.1. Three-Dimensional Object Detection from Point Clouds
2.2. Transformers in 3D Object Detection
2.3. Deformable Mechanisms in 3D Object Detection
3. Deformable Voxel Set Transformer
3.1. Overall Architecture
3.2. Deformable Voxel Set Attention
3.2.1. Positional Embedding
3.2.2. Offset Generation Module
3.2.3. Encoding Cross-Attention
3.2.4. Globally Responsive Convolutional Feed-Forward Network
3.2.5. Decoding Cross-Attention
3.3. BEV Feature Encoding and Detection Head
3.4. Training Losses
4. Experiments and Results
4.1. Dataset and Implementation Details
4.2. Three-Dimensional Detection Results on KITTI Dataset
4.2.1. KITTI Test Set
4.2.2. KITTI Validation Set
4.2.3. Performance on Pedestrian and Cyclist Classes
4.2.4. Qualitative Analysis
4.3. Three-Dimensional Detection Results on Waymo Open Dataset
4.4. Ablation Studies
4.4.1. Effect of the DVST Components
4.4.2. Effect of the Number of Inducing Points
4.5. Efficiency Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, J.; Shi, S.; Wang, Z.; Li, H.; Qi, X. ST3D++: Denoised Self-Training for Unsupervised Domain Adaptation on 3D Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6354–6371. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Chen, Q.; Fu, Z. LSNet: Learned Sampling Network for 3D Object Detection from Point Clouds. Remote Sens. 2022, 14, 1539. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4 December 2017; pp. 5105–5114. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not All Points Are Equal: Learning Highly Efficient Point-Based Detectors for 3D LiDAR Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18931–18940. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 1201–1209. [Google Scholar]
- Wu, H.; Wen, C.; Li, W.; Li, X.; Yang, R.; Wang, C. Transformation-Equivariant 3D Object Detection for Autonomous Driving. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; pp. 2795–2802. [Google Scholar]
- Ren, S.; Pan, X.; Zhao, W.; Nie, B.; Han, B. Dynamic Graph Transformer for 3D Object Detection. Knowl.-Based Syst. 2023, 259, 110085. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel Transformer for 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3144–3153. [Google Scholar]
- He, C.; Li, R.; Li, S.; Zhang, L. Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8407–8417. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4784–4793. [Google Scholar]
- Bhattacharyya, P.; Czarnecki, K. Deformable PV-RCNN: Improving 3D Object Detection with Learned Deformations. arXiv 2020, arXiv:2008.08766. [Google Scholar]
- Bhattacharyya, P.; Huang, C.; Czarnecki, K. SA-Det3D: Self-Attention Based Context-Aware 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3022–3031. [Google Scholar]
- Chen, Z.; Li, Z.; Zhang, S.; Fang, L.; Jiang, Q.; Zhao, F. Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 628–644. [Google Scholar]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.R.; Choi, S.; Teh, Y.W. Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks. arXiv 2019, arXiv:1810.00825. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Paigwar, A.; Erkent, O.; Wolf, C.; Laugier, C. Attentional PointNet for 3D-Object Detection in Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1297–1306. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1708–1716. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-Based 3D Object Detection and Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11779–11788. [Google Scholar]
- Yang, S.; Lu, H.; Li, J. Multifeature Fusion-Based Object Detection for Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1126–1133. [Google Scholar] [CrossRef]
- He, C.; Zeng, H.; Huang, J.; Hua, X.-S.; Zhang, L. Structure Aware Single-Stage 3D Object Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11870–11879. [Google Scholar]
- Noh, J.; Lee, S.; Ham, B. HVPR: Hybrid Voxel-Point Representation for Single-Stage 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14600–14609. [Google Scholar]
- Shuang, F.; Huang, H.; Li, Y.; Qu, R.; Li, P. AFE-RCNN: Adaptive Feature Enhancement RCNN for 3D Object Detection. Remote Sens. 2022, 14, 1176. [Google Scholar] [CrossRef]
- Sheng, H.; Cai, S.; Liu, Y.; Deng, B.; Huang, J.; Hua, X.-S.; Zhao, M.-J. Improving 3D Object Detection with Channel-Wise Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2723–2732. [Google Scholar]
- Guan, T.; Wang, J.; Lan, S.; Chandra, R.; Wu, Z.; Davis, L.; Manocha, D. M3DETR: Multi-Representation, Multi-Scale, Mutual-Relation 3D Object Detection with Transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2293–2303. [Google Scholar]
- Sun, P.; Tan, M.; Wang, W.; Liu, C.; Xia, F.; Leng, Z.; Anguelov, D. SWFormer: Sparse Window Transformer for 3D Object Detection in Point Clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 426–442. [Google Scholar]
- Tang, Z.; Sun, B.; Ma, T.; Li, D.; Xu, Z. Weakly Supervised Point Clouds Transformer for 3D Object Detection. In Proceedings of the IEEE 25th International Conference on Intelligent Transportation Systems, Macau, China, 8 October 2022; pp. 3948–3955. [Google Scholar]
- Zhou, Z.; Zhao, X.; Wang, Y.; Wang, P.; Foroosh, H. CenterFormer: Center-Based Transformer for 3D Object Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 496–513. [Google Scholar]
- Liu, H.; Ma, Y.; Wang, H.; Zhang, C.; Guo, Y. AnchorPoint: Query Design for Transformer-Based 3D Object Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10988–11000. [Google Scholar] [CrossRef]
- Ning, K.; Liu, Y.; Su, Y.; Jiang, K. Point-Voxel and Bird-Eye-View Representation Aggregation Network for Single Stage 3D Object Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3223–3235. [Google Scholar] [CrossRef]
- Tang, Q.; Bai, X.; Guo, J.; Pan, B.; Jiang, W. DFAF3D: A Dual-Feature-Aware Anchor-Free Single-Stage 3D Detector for Point Clouds. Image Vis. Comput. 2023, 129, 104594. [Google Scholar] [CrossRef]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D Object Detection with Pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7459–7468. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. ConvNeXt V2: Co-Designing and Scaling ConvNets with Masked Autoencoders. arXiv 2023, arXiv:2301.00808. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. STD: Sparse-to-Dense 3D Object Detector for Point Cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019; pp. 1951–1960. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2443–2451. [Google Scholar]
- OpenPCDet Development Team. OpenPCDet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. 2020. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 17 October 2023).
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- He, Y.; Xia, G.; Luo, Y.; Su, L.; Zhang, Z.; Li, W.; Wang, P. DVFENet: Dual-Branch Voxel Feature Extraction Network for 3D Object Detection. Neurocomputing 2021, 459, 201–211. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, D.; Li, Y.; Zhao, L.; Su, R. FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion. Remote Sens. 2023, 15, 2692. [Google Scholar] [CrossRef]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection from Point Cloud with Part-Aware and Part-Aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. TANet: Robust 3D Object Detection from Point Clouds with Triple Attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11677–11684. [Google Scholar]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.-W. CIA-SSD: Confident IoU-Aware Single-Stage Object Detector from Point Cloud. arXiv 2020, arXiv:2012.03015. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Car-3D Detection (%) | Car-BEV Detection (%) | ||||
|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| PointRCNN [25] (CVPR 2019) | Point-based | 86.96 | 75.64 | 70.70 | 92.13 | 87.39 | 82.72 |
| EPNet [47] (ECCV 2020) | 89.81 | 79.28 | 74.59 | 94.22 | 88.47 | 83.69 | |
| 3DSSD [5] (CVPR 2020) | 88.36 | 79.57 | 74.55 | 92.66 | 89.02 | 85.86 | |
| Point-GNN [26] (CVPR 2020) | 88.33 | 79.47 | 72.29 | 93.11 | 89.17 | 83.90 | |
| IA-SSD [6] (CVPR 2022) | 88.34 | 80.13 | 75.04 | 92.79 | 89.33 | 84.35 | |
| AnchorPoint [37] (IEEE T-ITS 2023) | - | 80.16 | - | - | 87.39 | - | |
| DGT-Det3D [10] (KBS 2023) | 87.89 | 80.68 | 76.02 | - | - | - | |
| SA-SSD [29] (CVPR 2020) | Point–voxel | 88.75 | 79.79 | 74.16 | 95.03 | 91.03 | 85.96 |
| PV-RCNN [11] (CVPR 2020) | 90.25 | 81.43 | 76.82 | 94.98 | 90.65 | 86.14 | |
| DVFENet [48] (Neurocomputing 2021) | 86.20 | 79.18 | 74.58 | 90.93 | 87.68 | 84.60 | |
| HVPR [30] (CVPR 2021) | 86.38 | 77.92 | 73.04 | - | - | - | |
| DSA-PV-RCNN [20] (ICCV 2021) | 88.25 | 81.46 | 76.96 | 92.42 | 90.13 | 85.93 | |
| AFE-RCNN [31] (Remote Sensing 2022) | 88.41 | 81.53 | 77.03 | ||||
| FusionPillars [49] (Remote Sensing 2023) | 86.96 | 75.74 | 73.03 | 92.15 | 88.00 | 85.53 | |
| SECOND [12] (Sensors 2018) | Voxel-based | 83.13 | 73.66 | 66.20 | 88.07 | 79.37 | 77.95 |
| PointPillars [7] (CVPR 2019) | 82.58 | 74.31 | 68.99 | 90.07 | 86.56 | 82.81 | |
| Part-A2 [50] (IEEE TPAMI 2020) | 87.81 | 78.49 | 73.51 | 91.70 | 87.79 | 84.61 | |
| TANeT [51] (AAAI 2020) | 84.39 | 75.94 | 68.82 | 91.58 | 86.54 | 81.19 | |
| CIA-SSD [52] (AAAI 2021) | 89.59 | 80.28 | 72.87 | 93.74 | 89.84 | 82.39 | |
| DFAF3D [39] (IMAVIS 2023) | 88.59 | 79.37 | 72.21 | 93.14 | 89.45 | 84.22 | |
| CT3D [32] (ICCV 2021) | 87.83 | 81.77 | 77.16 | 92.36 | 88.83 | 84.07 | |
| VoxSeT [14] (CVPR 2022) | 88.53 | 82.06 | 77.46 | 92.70 | 89.07 | 86.29 | |
| DVST-TSD (Ours) | 88.70 | 81.66 | 77.18 | 92.72 | 88.71 | 85.97 | |
| Method | Type | Car-Orientation (%) | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| PointRCNN [25] (CVPR 2019) | Point-based | 95.90 | 91.77 | 86.92 |
| EPNet [47] (ECCV 2020) | 96.13 | 94.22 | 89.68 | |
| Point-GNN [26] (CVPR 2020) | 38.66 | 37.20 | 36.29 | |
| IA-SSD [6] (CVPR 2022) | 96.07 | 93.47 | 90.51 | |
| SA-SSD [29] (CVPR 2020) | Point–voxel | 39.40 | 38.30 | 37.07 |
| DVFENet [48] (Neurocomputing 2021) | 95.33 | 94.44 | 91.55 | |
| PV-RCNN [11] (CVPR 2020) | 98.15 | 94.57 | 91.85 | |
| DSA-PV-RCNN [20] (ICCV 2021) | 95.84 | 94.52 | 91.93 | |
| AFE-RCNN [31] (Remote Sensing 2022) | 95.84 | 94.63 | 92.07 | |
| PointPillars [7] (CVPR 2019) | Voxel-based | 93.84 | 90.70 | 87.47 |
| Part-A2 [50] (IEEE TPAMI 2020) | 95.00 | 91.73 | 88.86 | |
| TANeT [51] (AAAI 2020) | 93.52 | 90.11 | 84.61 | |
| CIA-SSD [52] (AAAI2021) | 96.65 | 93.34 | 85.76 | |
| DFAF3D [39] (IMAVIS 2023) | 96.54 | 93.20 | 90.03 | |
| CT3D [32] (ICCV 2021) | 96.26 | 93.20 | 90.44 | |
| VoxSeT [14] (CVPR 2022) | 96.15 | 95.13 | 90.38 | |
| DVST-TSD(Ours) | 96.02 | 94.67 | 92.03 | |
| Method | Type | Car-3D Detection (%) | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| PointRCNN [25] (CVPR 2019) | Point-based | 88.88 | 78.63 | 77.38 |
| 3DSSD [5] (CVPR 2020) | 89.71 | 79.45 | 78.67 | |
| Point-GNN [26] (CVPR 2020) | 87.89 | 78.34 | 77.38 | |
| AnchorPoint [37] (IEEE T-ITS 2023) | 89.70 | 83.21 | 78.79 | |
| DGT-Det3D [10] (KBS 2023) | 89.65 | 84.82 | 78.76 | |
| SA-SSD [29] (CVPR 2020) | Point–voxel | 90.15 | 79.91 | 78.78 |
| PV-RCNN [11] (CVPR 2020) | 89.35 | 83.69 | 78.70 | |
| Deformable PV-RCNN [19] (ECCV 2020) | - | 83.30 | - | |
| DVFENet [48] (Neurocomputing 2021) | 89.81 | 79.52 | 78.35 | |
| HVPR [30] (CVPR 2021) | 90.24 | 82.05 | 79.49 | |
| AFE-RCNN [31] (Remote Sensing 2022) | 89.61 | 83.99 | 79.18 | |
| SECOND [12] (Sensors 2018) | Voxel-based | 88.61 | 78.62 | 77.22 |
| PointPillars [7] (CVPR 2019) | 86.46 | 77.28 | 74.65 | |
| Part-A2 [50] (IEEE TPAMI 2020) | 89.55 | 79.40 | 77.84 | |
| TANeT [51] (AAAI 2020) | 87.52 | 76.64 | 73.86 | |
| CIA-SSD [52] (AAAI2021) | 90.04 | 79.81 | 78.80 | |
| VoTr-TSD [13] (ICCV 2021) | 89.04 | 84.04 | 78.68 | |
| CT3D [32] (ICCV 2021) | 89.54 | 86.06 | 78.99 | |
| VoxSeT [14] (CVPR 2022) | 89.24 | 84.58 | 78.87 | |
| DVST-TSD(Ours) | 89.30 | 85.05 | 78.99 | |
| Method | Car (%) | Pedestrian (%) | Cyclist (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| SECOND [12] | 88.61 | 78.62 | 77.22 | 56.55 | 52.98 | 47.73 | 80.58 | 67.15 | 63.10 |
| PointPillars [7] | 86.46 | 77.28 | 74.65 | 57.75 | 52.29 | 47.90 | 80.04 | 62.61 | 59.52 |
| VoxSeT [14] | 88.45 | 78.48 | 77.07 | 60.62 | 54.74 | 50.39 | 84.07 | 68.11 | 65.14 |
| DVST-SSD (Ours) | 88.98 | 78.95 | 77.76 | 60.79 | 57.34 | 52.44 | 84.63 | 70.65 | 65.53 |
| Improvements | +0.37 | +0.33 | +0.54 | +0.17 | +2.60 | +2.05 | +0.56 | +2.54 | +0.39 |
| Method | Vehicle-L1 | Vehicle-L2 | Pedestrian-L1 | Pedestrian-L2 | Cyclist-L1 | Cyclist-L2 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mAP | mAPH | mAP | mAPH | mAP | mAPH | mAP | mAPH | mAP | mAPH | mAP | mAPH | |
| SECOND [12] | 68.03 | 67.44 | 59.57 | 59.04 | 61.14 | 50.33 | 53.00 | 43.56 | 54.66 | 53.31 | 52.67 | 51.37 |
| CenterPoint [27] | 70.50 | 69.96 | 62.18 | 61.69 | 73.11 | 61.97 | 65.06 | 55.00 | 65.44 | 63.85 | 62.98 | 61.46 |
| Part-A2 [50] | 74.66 | 74.12 | 65.82 | 65.32 | 71.71 | 62.24 | 62.46 | 54.06 | 66.53 | 65.18 | 64.05 | 62.75 |
| AnchorPoint [37] | 73.91 | 73.40 | 65.10 | 64.64 | 70.37 | 61.76 | 61.77 | 54.08 | 70.18 | 68.65 | 67.76 | 66.28 |
| IA-SSD [6] | 70.53 | 69.67 | 61.55 | 60.80 | 69.38 | 58.47 | 60.30 | 50.73 | 67.67 | 65.30 | 64.98 | 62.71 |
| AFE-RCNN [31] | 71.23 | 70.53 | 62.62 | 61.99 | - | - | - | - | 59.69 | 43.14 | 57.44 | 41.51 |
| PV-RCNN [11] | 75.41 | 74.74 | 67.44 | 66.80 | 71.98 | 61.24 | 63.70 | 53.95 | 65.88 | 64.25 | 63.39 | 61.82 |
| PointPillars [7] | 69.37 | 68.73 | 61.22 | 60.65 | 64.29 | 44.64 | 56.03 | 38.84 | 54.14 | 51.19 | 52.11 | 49.26 |
| DVST-SSD | 69.93 | 69.39 | 61.62 | 61.14 | 69.73 | 56.08 | 61.40 | 49.26 | 60.66 | 59.04 | 58.39 | 56.83 |
| Improvements | +0.56 | +0.66 | +0.40 | +0.49 | +5.44 | +11.44 | +5.37 | +10.42 | +6.52 | +7.85 | +6.28 | +7.57 |
| VoxSeT [14] | 70.09 | 69.59 | 61.63 | 61.18 | 74.04 | 65.56 | 65.78 | 58.13 | 68.72 | 67.42 | 66.18 | 64.93 |
| DVST-TSD | 71.29 | 70.79 | 62.79 | 62.34 | 75.43 | 67.04 | 67.33 | 59.72 | 70.65 | 69.34 | 68.03 | 66.76 |
| Improvements | +1.20 | +1.20 | +1.16 | +1.16 | +1.39 | +1.48 | +1.55 | +1.59 | +1.93 | +1.92 | +1.85 | +1.83 |
| Methods | OGM | GRCFFN | RC | Easy (%) | Moderate (%) | Hard (%) |
|---|---|---|---|---|---|---|
| VoxSeT | - | - | - | 89.24 | 84.58 | 78.87 |
| DVST-TSD | √ | - | - | 89.10 | 84.71 | 78.88 |
| √ | √ | - | 89.19 | 84.80 | 78.84 | |
| √ | - | √ | 89.34 | 84.89 | 78.90 | |
| √ | √ | √ | 89.30 | 85.05 | 78.99 |
| Number of Inducing Points | Car (%) | Pedestrian (%) | Cyclist (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| 2 | 88.34 | 78.33 | 77.04 | 59.08 | 55.17 | 50.32 | 85.69 | 67.16 | 63.79 |
| 4 | 88.46 | 78.49 | 77.37 | 61.25 | 56.80 | 52.27 | 83.78 | 68.22 | 63.39 |
| 8 | 88.98 | 78.95 | 77.76 | 60.79 | 57.34 | 52.44 | 84.63 | 70.65 | 65.53 |
| Method | Car (%) | Pedestrian (%) | Cyclist (%) | Parameters (M) | FLOPs (G) | Inference_Time (ms) |
|---|---|---|---|---|---|---|
| SECOND | 78.62 | 52.98 | 67.15 | 4.61 | 76.86 | 53.10 |
| PointPillars | 77.28 | 52.29 | 62.61 | 4.83 | 63.69 | 28.73 |
| VoxSeT | 78.48 | 54.74 | 68.11 | 2.93 | 53.01 | 48.85 |
| DVST-SSD | 78.95 | 57.34 | 70.65 | 4.42 | 57.94 | 52.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, Y.; Cao, J.; Bao, C.; Hao, Q. DVST: Deformable Voxel Set Transformer for 3D Object Detection from Point Clouds. Remote Sens. 2023, 15, 5612. https://doi.org/10.3390/rs15235612
Ning Y, Cao J, Bao C, Hao Q. DVST: Deformable Voxel Set Transformer for 3D Object Detection from Point Clouds. Remote Sensing. 2023; 15(23):5612. https://doi.org/10.3390/rs15235612
Chicago/Turabian StyleNing, Yaqian, Jie Cao, Chun Bao, and Qun Hao. 2023. "DVST: Deformable Voxel Set Transformer for 3D Object Detection from Point Clouds" Remote Sensing 15, no. 23: 5612. https://doi.org/10.3390/rs15235612
APA StyleNing, Y., Cao, J., Bao, C., & Hao, Q. (2023). DVST: Deformable Voxel Set Transformer for 3D Object Detection from Point Clouds. Remote Sensing, 15(23), 5612. https://doi.org/10.3390/rs15235612