
Improving Out-of-Distribution Generalization in SAR Image Scene Classification with Limited Training Samples



Abstract
:
1. Introduction
- (1)
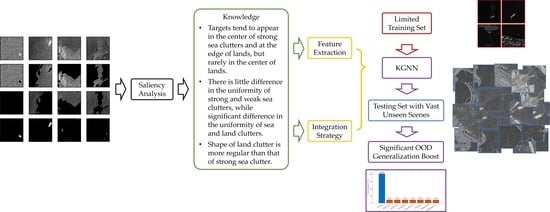
- We define knowledge as task-specific information about relations between entities in a maritime SAR image scene and extract the knowledge in descriptive sentence form through saliency analysis from the perspective of frequency and amplitude.
- (2)
- We design a feature integration strategy to reflect the inherent information of objects (knowledge) in maritime scene classification tasks, and thus propose a new KGNN network.
2. Related Works
2.1. Unsupervised Representation Learning
2.2. Supervised Model Learning
2.3. Few-Shot Learning
2.4. Integrating Knowledge into Deep Learning
3. Materials and Methods
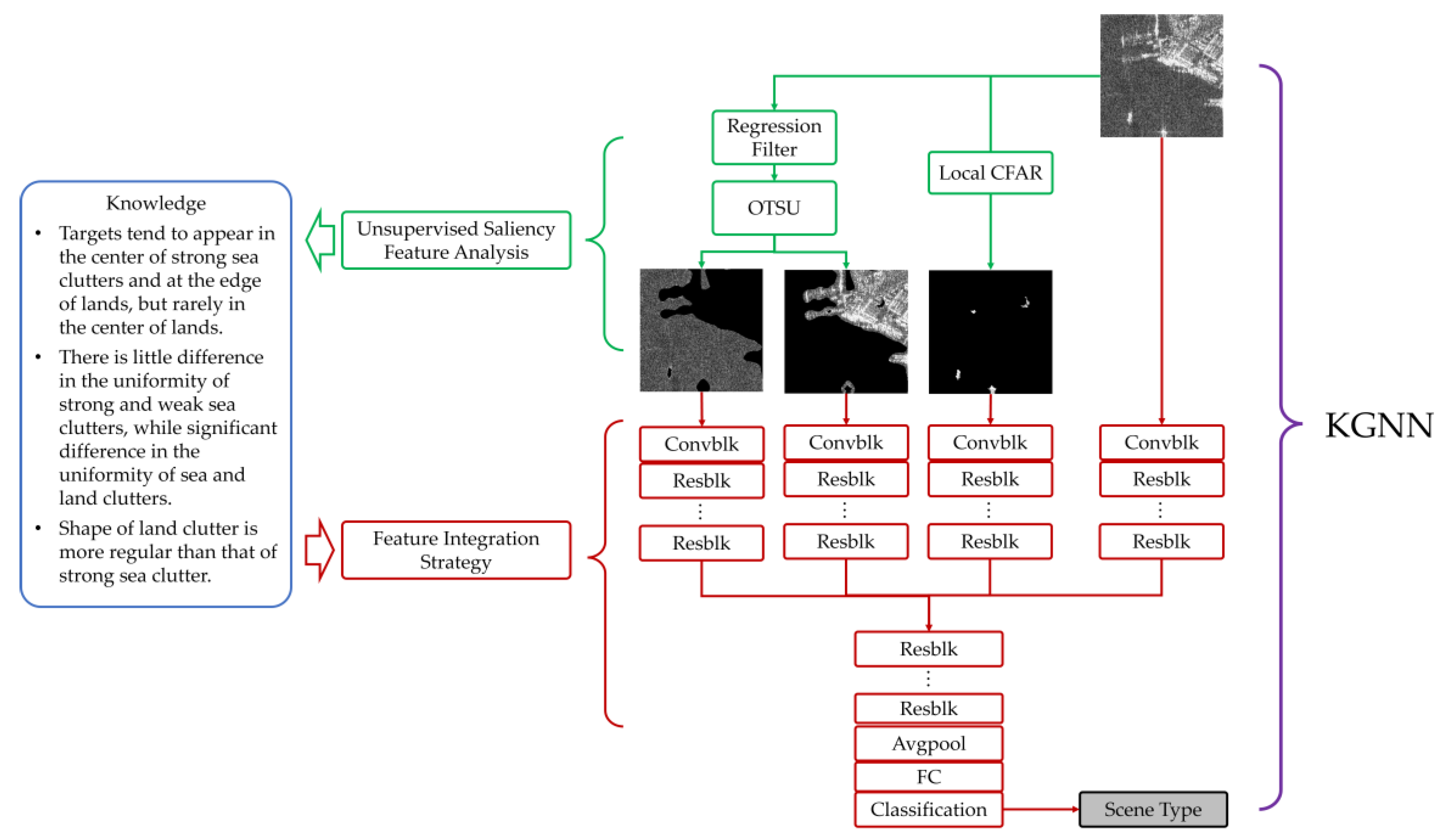
3.1. Knowledge Extraction via Saliency Analysis
- (1)
- Ship targets tend to appear in the center of strong sea clutter and at the edge of land, but rarely in the center of land.
- (2)
- There is little difference in the uniformity of strong and weak sea clutter, while a significant difference is observed in the uniformity of sea and land clutter.
- (3)
- The layout of land regions is more regular compared to strong sea clutter.
3.2. Knowledge-Guided Neural Network (KGNN)
- (1)
- We feed the three saliency maps along with the original SAR image into separate branches of a ResNet-18 [48] backbone to generate feature embeddings. We apply the convolutional block and the first four residual blocks of ResNet-18 as the data-driven feature extractor branch. The purpose is to extract features with semantic discrimination beneficial to the classification of each saliency map. The original SAR image feature extractor branch is designed to address the neighboring information in the edge between saliency maps. In practice, we implement the four feature extractor branches using grouped convolutional layers [49] and grouped batch normalization layers [50].
- (2)
- The feature embeddings generated from the four branches are concatenated and propagate together into the remaining four residual blocks of ResNet-18. The transformed semantic features of the saliency maps correlate with each other and evolute in the mid-level and high-level layers of the conventional classification network successively.
4. Results and Discussion
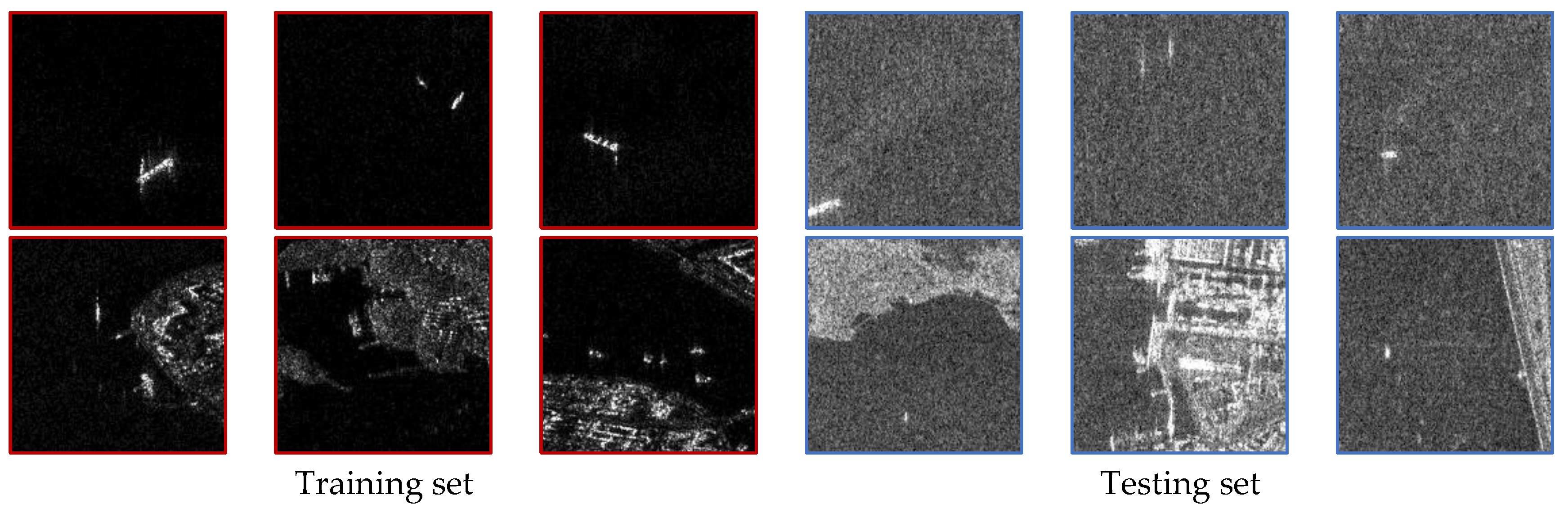
4.1. Data Description
- (1)
- How the scaling of the training data affects the OOD generalization and the performance improvement of KGNN under different training sample sizes.
- (2)
- How robust is the KGNN to independent factors concerning SAR data variation such as weather conditions, terrain type, and sensor characteristics.
4.2. Experimental Setup
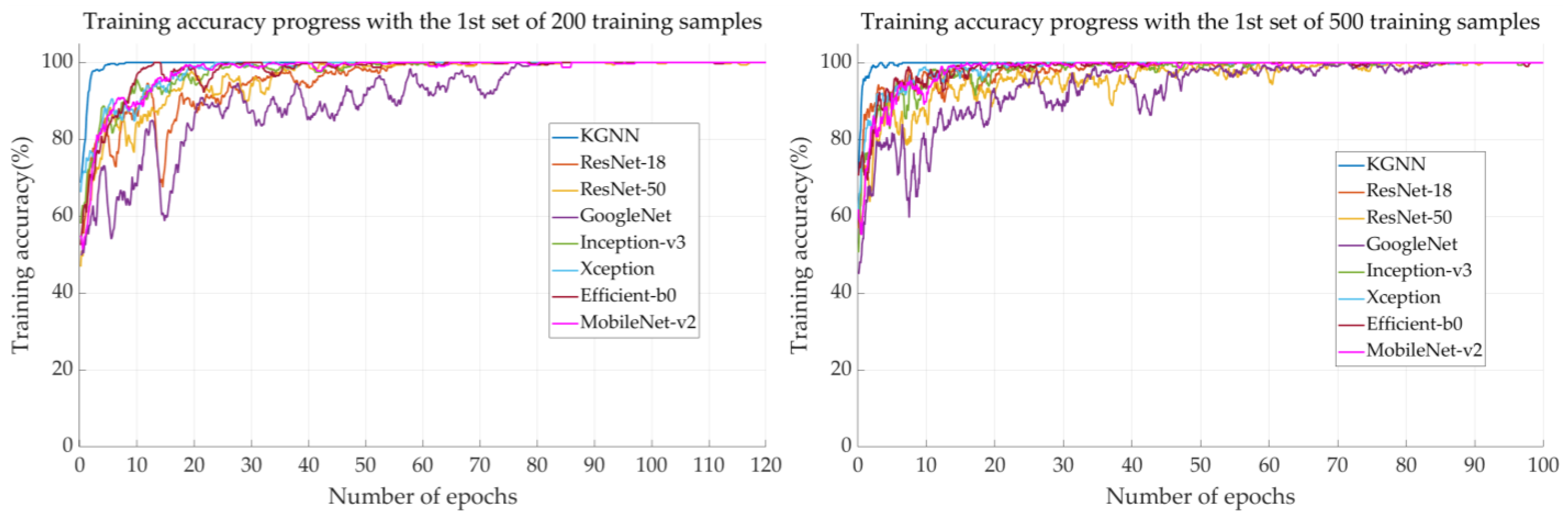
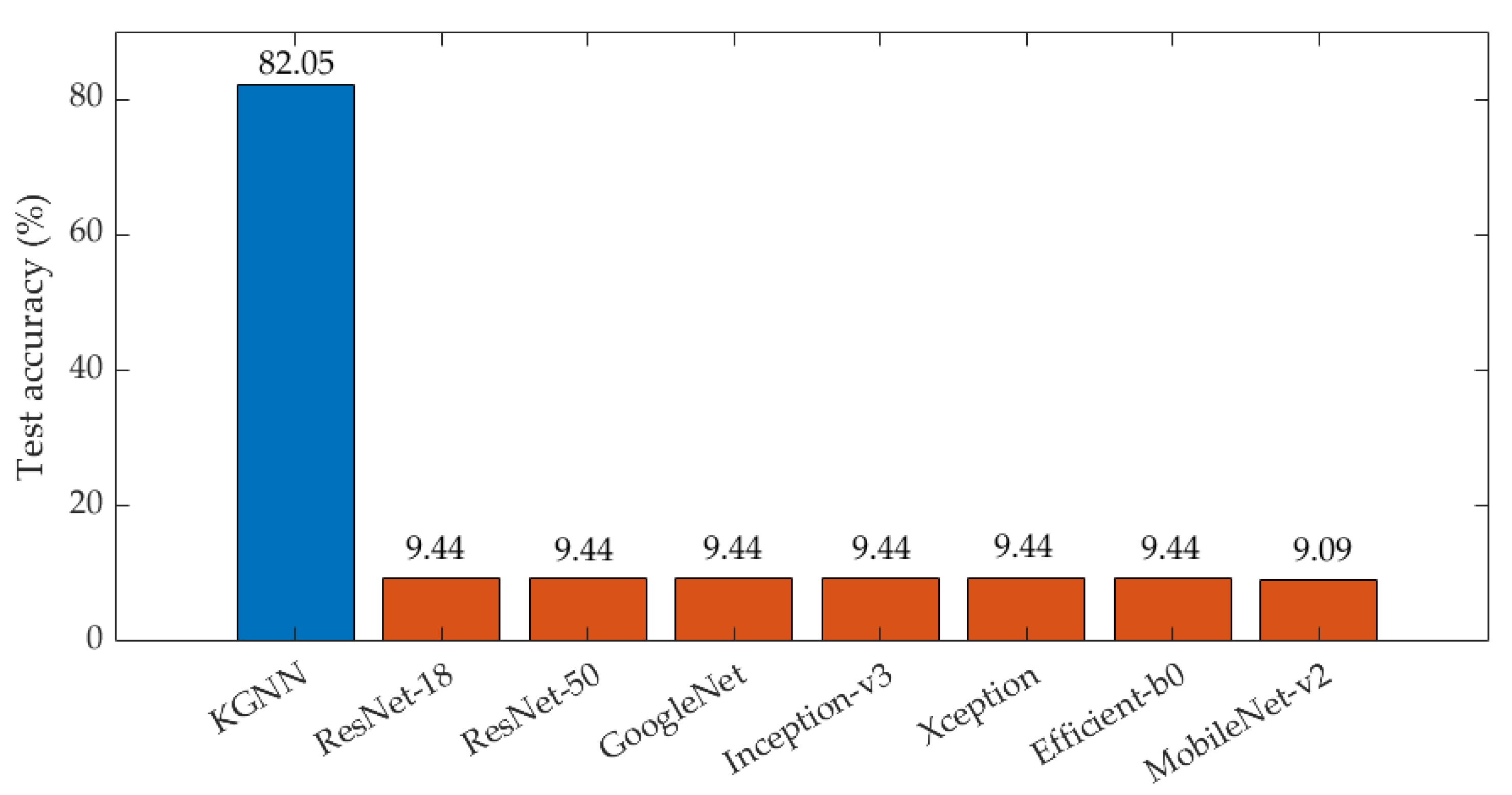
4.3. Results under Multiple-Factor Influence
4.4. Results under Single-Factor Influence
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Ren, Z.; Hou, B.; Wu, Q.; Wen, Z.; Jiao, L. A distribution and structure match generative adversarial network for SAR image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3864–3880. [Google Scholar] [CrossRef]
- Qian, X.; Liu, F.; Jiao, L.; Zhang, X.; Guo, Y.; Liu, X.; Cui, Y. Ridgelet-nets with speckle reduction regularization for SAR image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9290–9306. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Cao, Y.; Ren, J.; Su, C.; Liang, J. Scene classification from POLSAR image using medium-level features. In Proceedings of the Conference Proceedings of 2013 Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Tsukuba, Japan, 23–27 September 2013; pp. 342–345. [Google Scholar]
- Hou, B.; Ren, B.; Ju, G.; Li, H.; Jiao, L.; Zhao, J. SAR image classification via hierarchical sparse representation and multisize patch features. IEEE Geosci. Remote Sens. Lett. 2016, 13, 33–37. [Google Scholar] [CrossRef]
- Parikh, H.; Patel, S.; Patel, V. Classification of SAR and PolSAR images using deep learning: A review. Int. J. Image Data Fusion 2020, 11, 1–32. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Liang, J.; Deng, Y.; Zeng, D. A deep neural network combined CNN and GCN for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards out-of-distribution generalization: A survey. arXiv 2021, arXiv:2108.13624. [Google Scholar]
- Duchi, J.; Namkoong, H. Learning models with uniform performance via distributionally robust optimization. arXiv 2018, arXiv:1810.08750. [Google Scholar] [CrossRef]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant risk minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Creager, E.; Jacobsen, J.H.; Zemel, R. Environment inference for invariant learning. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 18–24 July 2021; pp. 2189–2200. [Google Scholar]
- Arjovsky, M. Out of Distribution Generalization in Machine Learning. Ph.D. Dissertation, New York University, New York, NY, USA, 2020. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Locatello, F.; Bauer, S.; Lucic, M.; Raetsch, G.; Gelly, S.; Schölkopf, B.; Bachem, O. Challenging common assumptions in the unsupervised learning of disentangled representations. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4114–4124. [Google Scholar]
- Yang, M.; Liu, F.; Chen, Z.; Shen, X.; Hao, J.; Wang, J. Causalvae: Disentangled representation learning via neural structural causal models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9593–9602. [Google Scholar]
- Shen, X.; Liu, F.; Dong, H.; Lian, Q.; Chen, Z.; Zhang, T. Disentangled generative causal representation learning. arXiv 2020, arXiv:2010.02637. [Google Scholar]
- Dittadi, A.; Träuble, F.; Locatello, F.; Wüthrich, M.; Agrawal, V.; Winther, O.; Bauer, S.; Schölkopf, B. On the transfer of disentangled representations in realistic settings. arXiv 2020, arXiv:2010.14407. [Google Scholar]
- Träuble, F.; Creager, E.; Kilbertus, N.; Locatello, F.; Dittadi, A.; Goyal, A.; Schölkopf, B.; Bauer, S. On disentangled representations learned from correlated data. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10401–10412. [Google Scholar]
- Leeb, F.; Lanzillotta, G.; Annadani, Y.; Besserve, M.; Bauer, S.; Schölkopf, B. Structure by architecture: Disentangled representations without regularization. arXiv 2020, arXiv:2006.07796. [Google Scholar]
- Li, Y.; Tian, X.; Gong, M.; Liu, Y.; Liu, T.; Zhang, K.; Tao, D. Deep domain generalization via conditional invariant adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 624–639. [Google Scholar]
- Shao, R.; Lan, X.; Li, J.; Yuen, P.C. Multi-adversarial discriminative deep domain generalization for face presentation attack detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10023–10031. [Google Scholar]
- Wang, J.; Feng, W.; Chen, Y.; Yu, H.; Huang, M.; Yu, P.S. Visual domain adaptation with manifold embedded distribution alignment. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 402–410. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5715–5725. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Gwon, K.; Yoo, J. Out-of-distribution (OOD) detection and generalization improved by augmenting adversarial mixup samples. Electronics 2023, 12, 1421. [Google Scholar] [CrossRef]
- Li, H.; Pan, S.J.; Wang, S.; Kot, A.C. Domain generalization with adversarial feature learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5400–5409. [Google Scholar]
- He, J.; Wang, Y.; Liu, H. Ship classification in medium-resolution SAR images via densely connected triplet CNNs integrating fisher discrimination regularized metric learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3022–3039. [Google Scholar] [CrossRef]
- Raj, J.A.; Idicula, S.M.; Paul, B. One-shot learning-based SAR ship classification using new hybrid Siamese network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Stewart, R.; Ermon, S. Label-free supervision of neural networks with physics and domain knowledge. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Von Rueden, L.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Pfrommer, J.; Pick, A.; Ramamurthy, R.; et al. Informed machine learning—A taxonomy and survey of integrating prior knowledge into learning systems. IEEE Trans. Knowl. Data Eng. 2021, 35, 614–633. [Google Scholar] [CrossRef]
- Diligenti, M.; Roychowdhury, S.; Gori, M. Integrating prior knowledge into deep learning. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 920–923. [Google Scholar]
- Huang, Z.; Yao, X.; Liu, Y.; Dumitru, C.O.; Datcu, M.; Han, J. Physically explainable CNN for SAR image classification. ISPRS J. Photogramm. Remote Sens. 2022, 190, 25–37. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Injection of traditional hand-crafted features into modern CNN-based models for SAR ship classification: What, why, where, and how. Remote Sens. 2021, 13, 2091. [Google Scholar] [CrossRef]
- Chen, Z.; Ding, Z.; Zhang, X.; Wang, X.; Zhou, Y. Inshore ship detection based on multi-modality saliency for synthetic aperture radar images. Remote Sens. 2023, 15, 3868. [Google Scholar] [CrossRef]
- Blaschke, T.; Feizizadeh, B.; Hölbling, D. Object-based image analysis and digital terrain analysis for locating landslides in the Urmia Lake Basin, Iran. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4806–4817. [Google Scholar] [CrossRef]
- ISO 11562; Geometrical Product Specification (GPS)—Surface Texture: Profile Method—Metrological Characteristics of Phase Correct Filters. ISO: Geneva, Switzerland, 1996.
- Zeng, W.; Jiang, X.; Scott, P.J. Fast algorithm of the robust Gaussian regression filter for areal surface analysis. Meas. Sci. Technol. 2010, 21, 055108. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Lagarias, J.C.; Reeds, J.A.; Wright, M.H.; Wright, P.E. Convergence properties of the Nelder—Mead simplex method in low dimensions. SIAM J. Optim. 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Wang, R.; Xu, F.; Pei, J.; Zhang, Q.; Huang, Y.; Zhang, Y.; Yang, J. Context semantic perception based on superpixel segmentation for inshore ship detection in SAR image. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Evans, M.; Hastings, N.; Peacock, B. Statistical Distributions, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1993. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 249–256. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A visual transformer based on contextual joint representation learning for SAR ship detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Xue, S.; Geng, X.; Meng, L.; Xie, T.; Huang, L.; Yan, X.-H. HISEA-1: The first C-Band SAR miniaturized satellite for ocean and coastal observation. Remote Sens. 2021, 13, 2076. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Cruz, H.; Véstias, M.; Monteiro, J.; Neto, H.; Duarte, R.P. A Review of Synthetic-Aperture Radar Image Formation Algorithms and Implementations: A Computational Perspective. Remote Sens. 2022, 14, 1258. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Series | Image Index | Time | Location | Satellite | Imaging Mode |
|---|---|---|---|---|---|
| 1 | 1~496 | 24 Mar. 2021 | - | HISEA-1 | SM |
| 2 | 613~5251 | 15 Jan. 2017 | E122.0, N30.3 | Gaofen-3 | FSI |
| 3 | 5252~5351 | 24 Oct. 2017 | E120.8, N36.1 | Gaofen-3 | FSI |
| 5352~5745 | 24 Oct. 2017 | E120.9, N35.7 | Gaofen-3 | FSI | |
| 5746~5884 | 24 Oct. 2017 | E121.0, N35.2 | Gaofen-3 | FSI | |
| 5885~5936 | 24 Oct. 2017 | E121.1, N34.7 | Gaofen-3 | FSI | |
| 5937~8229 | 24 Oct. 2017 | E122.0, N30.1 | Gaofen-3 | FSI | |
| 4 | 8230~8243 | 16 Nov. 2017 | E110.5, N18.1 | Gaofen-3 | NSC |
| 5 | 8244~8804 | 5 Jul. 2017 | E120.1, N35.8 | Gaofen-3 | QPSI |
| 6 | 8805~8913 | 12 Aug. 2017 | E109.7, N18.4 | Gaofen-3 | UFS |
| 7 | 8914~10,119 | 15 Jul. 2017 | E120.4, N35.4 | Gaofen-3 | FSII |
| 8 | 10,120~12,972 | 3 Nov. 2017 | E121.9, N30.1 | Gaofen-3 | QPSI |
| 9 | 12,973~12,974 | 20 Feb. 2017 | E120.7, N35.0 | Gaofen-3 | FSI |
| 12,975~13,273 | 20 Feb. 2017 | E120.9, N36.0 | Gaofen-3 | FSI | |
| 10 | 13,274~13,635 | 6 Jul. 2017 | E129.6, N33.0 | Gaofen-3 | QPSI |
| 13,636~14,145 | 6 Jul. 2017 | E129.7, N33.5 | Gaofen-3 | QPSI | |
| 11 | 14,146~14,314 | 2 Sept. 2017 | E129.6, N33.1 | Gaofen-3 | QPSI |
| 14,315~14,387 | 2 Sept. 2017 | E129.7, N33.4 | Gaofen-3 | QPSI | |
| 14,388~14,411 | 2 Sept. 2017 | E129.7, N33.6 | Gaofen-3 | QPSI | |
| 12 | 14,412~15,432 | 30 Sept. 2017 | E120.5, N36.3 | Gaofen-3 | FSII |
| 15,433~17,588 | 30 Sept. 2017 | E121.9, N30.3 | Gaofen-3 | FSII | |
| 13 | 17,589~19,121 | 15 Feb. 2017 | E122.3, N29.9 | Gaofen-3 | FSI |
| 14 | 19,122~21,147 | 10 Jul. 2017 | E122.5, N30.2 | Gaofen-3 | NSC |
| 15 | 21,148~22,875 | 29 Jul. 2017 | E121.1, N30.5 | Gaofen-3 | NSC |
| 16 | 22,876~23,202 | 5 Oct. 2017 | E120.4, N36.2 | Gaofen-3 | QPSI |
| 23,203~23,264 | 5 Oct. 2017 | E121.0, N33.5 | Gaofen-3 | QPSI | |
| 23,265~24,122 | 5 Oct. 2017 | E121.9, N30.1 | Gaofen-3 | QPSI | |
| 24,123~24,147 | 5 Oct. 2017 | E121.5, N34.2 | Gaofen-3 | QPSI | |
| 24,148~24,157 | 5 Oct. 2017 | E121.6, N34.7 | Gaofen-3 | QPSI | |
| 24,158~24,168 | 5 Oct. 2017 | E121.7, N35.0 | Gaofen-3 | QPSI | |
| 24,169~24,187 | 5 Oct. 2017 | E121.8, N35.6 | Gaofen-3 | QPSI | |
| 24,188~24,217 | 5 Oct. 2017 | E122.1, N36.7 | Gaofen-3 | QPSI | |
| 17 | 24,218~24,229 | 15 Oct. 2017 | E124.6, N34.7 | Gaofen-3 | QPSI |
| 24,230~24,248 | 15 Oct. 2017 | E124.7, N35.2 | Gaofen-3 | QPSI | |
| 18 | 24,249~24,263 | 3 Nov. 2017 | E121.0, N35.0 | Gaofen-3 | QPSI |
| 24,264~24,327 | 3 Nov. 2017 | E121.1, N35.4 | Gaofen-3 | QPSI | |
| 24,328~24,378 | 3 Nov. 2017 | E121.1, N35.6 | Gaofen-3 | QPSI | |
| 24,379~24,396 | 3 Nov. 2017 | E121.2, N35.8 | Gaofen-3 | QPSI | |
| 24,397~24,429 | 3 Nov. 2017 | E121.3, N36.2 | Gaofen-3 | QPSI | |
| 24,430~24,435 | 3 Nov. 2017 | E121.4, N36.6 | Gaofen-3 | QPSI | |
| 19 | 24,436~25,080 | 15 Nov. 2017 | E122.7, N36.5 | Gaofen-3 | UFS |
| 25,081~25,461 | 15 Nov. 2017 | E123.0, N34.8 | Gaofen-3 | UFS | |
| 25,462~25,623 | 15 Nov. 2017 | E123.0, N35.0 | Gaofen-3 | UFS | |
| 25,624~25,675 | 15 Nov. 2017 | E123.1, N34.5 | Gaofen-3 | UFS | |
| 20 | 25,676~26,892 | 6 Jan. 2017 | E132.5, N32.5 | Gaofen-3 | WSC |
| 21 | 26,893~28,449 | 4 Aug. 2017 | E128.9, N32.2 | Gaofen-3 | WSC |
| Series | Image Index | Time | Location | Satellite | Imaging Mode |
|---|---|---|---|---|---|
| 7 | 8914~10,119 | 15 Jul. 2017 | E120.4, N35.4 | Gaofen-3 | FSII |
| 12 | 14,412~15,432 | 30 Sept. 2017 | E120.5, N36.3 | Gaofen-3 | FSII |
| Series | Image Index | Time | Location | Satellite | Imaging Mode |
|---|---|---|---|---|---|
| 3 | 5252~5351 | 24 Oct. 2017 | E120.8, N36.1 | Gaofen-3 | FSI |
| 5352~5745 | 24 Oct. 2017 | E120.9, N35.7 | Gaofen-3 | FSI | |
| 5937~8229 | 24 Oct. 2017 | E122.0, N30.1 | Gaofen-3 | FSI |
| Series | Image Index | Time | Location | Satellite | Imaging Mode |
|---|---|---|---|---|---|
| 2 | 613~5251 | 15 Jan. 2017 | E122.0, N30.3 | Gaofen-3 | FSI |
| 5 | 8244~8804 | 5 Jul. 2017 | E120.1, N35.8 | Gaofen-3 | QPSI |
| 8 | 10,120~12,972 | 3 Nov. 2017 | E121.9, N30.1 | Gaofen-3 | QPSI |
| 13 | 17,589~19,121 | 15 Feb. 2017 | E122.3, N29.9 | Gaofen-3 | FSI |
| 16 | 22,876~23,202 | 5 Oct. 2017 | E120.4, N36.2 | Gaofen-3 | QPSI |
| 23,203~23,264 | 5 Oct. 2017 | E121.0, N33.5 | Gaofen-3 | QPSI | |
| 23,265~24,122 | 5 Oct. 2017 | E121.9, N30.1 | Gaofen-3 | QPSI | |
| 24,123~24,147 | 5 Oct. 2017 | E121.5, N34.2 | Gaofen-3 | QPSI | |
| 24,148~24,157 | 5 Oct. 2017 | E121.6, N34.7 | Gaofen-3 | QPSI | |
| 24,158~24,168 | 5 Oct. 2017 | E121.7, N35.0 | Gaofen-3 | QPSI | |
| 24,169~24,187 | 5 Oct. 2017 | E121.8, N35.6 | Gaofen-3 | QPSI | |
| 24,188~24,217 | 5 Oct. 2017 | E122.1, N36.7 | Gaofen-3 | QPSI |
| Model Name | Trainable Variables (Millions) | Running Time per Image (s) |
|---|---|---|
| KGNN | 14.4 | 0.0511 |
| ResNet-18 | 11.1 | 0.0013 |
| ResNet-50 | 23.5 | 0.0020 |
| GoogleNet | 5.9 | 0.0005 |
| Inception-v3 | 21.8 | 0.0013 |
| Xception | 20.8 | 0.0026 |
| Efficient-b0 | 4.0 | 0.0033 |
| MobileNet-v2 | 2.2 | 0.0018 |
| Test Accuracy (%) | Number of Samples in Training Set | |||||
|---|---|---|---|---|---|---|
| 10 | 20 | 50 | 100 | 200 | 500 | |
| KGNN | 79.23 ± 3.29 | 87.07 ± 6.17 | 96.33 ± 0.91 | 97.41 ± 1.66 | 98.43 ± 0.27 | 98.75 ± 0.37 |
| ResNet-18 | 68.85 ± 7.53 | 70.12 ± 7.51 | 85.94 ± 2.04 | 89.60 ± 2.81 | 90.93 ± 1.52 | 91.61 ± 0.62 |
| ResNet-50 | 63.33 ± 5.58 | 72.99 ± 4.94 | 85.83± 2.07 | 88.29 ± 3.70 | 89.27 ± 1.39 | 91.22 ± 1.44 |
| GoogleNet | 65.31 ± 14.16 | 77.62 ± 4.04 | 84.67 ± 3.26 | 88.82 ± 2.76 | 88.95 ± 2.31 | 93.99 ± 0.96 |
| Inception-v3 | 57.50 ± 7.90 | 64.52 ± 11.10 | 84.13 ± 1.74 | 89.38 ± 2.04 | 92.67 ± 1.26 | 94.86 ± 2.25 |
| Xception | 62.41 ± 4.10 | 67.40 ± 6.01 | 83.39 ± 2.44 | 89.88 ± 2.12 | 90.79 ± 1.53 | 94.29 ± 1.19 |
| Efficient-b0 | 64.98 ± 2.12 | 65.72 ± 5.30 | 77.62 ± 3.82 | 83.58 ± 4.48 | 88.23 ± 2.72 | 91.26 ± 0.84 |
| MobileNet-v2 | 62.75 ± 5.24 | 70.67± 7.87 | 84.43 ± 1.46 | 84.72 ± 1.75 | 87.03 ± 1.61 | 89.48 ± 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Ding, Z.; Zhang, X.; Zhang, X.; Qin, T. Improving Out-of-Distribution Generalization in SAR Image Scene Classification with Limited Training Samples. Remote Sens. 2023, 15, 5761. https://doi.org/10.3390/rs15245761
Chen Z, Ding Z, Zhang X, Zhang X, Qin T. Improving Out-of-Distribution Generalization in SAR Image Scene Classification with Limited Training Samples. Remote Sensing. 2023; 15(24):5761. https://doi.org/10.3390/rs15245761
Chicago/Turabian StyleChen, Zhe, Zhiquan Ding, Xiaoling Zhang, Xin Zhang, and Tianqi Qin. 2023. "Improving Out-of-Distribution Generalization in SAR Image Scene Classification with Limited Training Samples" Remote Sensing 15, no. 24: 5761. https://doi.org/10.3390/rs15245761
APA StyleChen, Z., Ding, Z., Zhang, X., Zhang, X., & Qin, T. (2023). Improving Out-of-Distribution Generalization in SAR Image Scene Classification with Limited Training Samples. Remote Sensing, 15(24), 5761. https://doi.org/10.3390/rs15245761