
A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments


Abstract
:1. Introduction
- (1)
- Complex background, including near-shore environment and noise interference. Due to SAR imaging characteristics [32], there is a presence of speckle noise. Additionally, ship detection is affected by sea clutter, islands, and shore, which could lead to false alarms.
- (2)
- Multiscale and small-ship detection. Due to various ship shapes and multiresolution imaging modes, there are ships of different sizes present in a single image, especially densely distributed small ships. When small ships are mapped into the final feature map, little information is available for fine-tuning the location and classification, resulting in a high rate of false negatives.
- (3)
- Capacity for generalization. Most algorithms exhibit limited robustness across different datasets and scenarios.
- (1)
- Considering the complex background, we propose an integrated feature extractor, Swin-T-YOLOv5l, which combines YOLOv5l and Swin Transformer encoders. The extractor significantly improves detection accuracy by encoding both local and global information, effectively distinguishing between targets from complex backgrounds.
- (2)
- For multiscale and small-ship detection, a feature pyramid IEFR-FPN, including IEM and FRM, is proposed in the feature fusion layer. IEM injects the multiscale features generated by dilated convolution into the feature pyramid network from top to bottom, therefore supplementing contextual information. The FRM introduces a feature refinement mechanism both in the spatial and channel dimensions to prevent small targets from being submerged in conflicting information with an attention mechanism.
- (3)
- We introduce g3Conv prediction heads (GCPH) and one more prediction head to locate small ships accurately and improve robustness. To verify the robustness of our model, we conduct experiments on the datasets of SSDD [41], and SAR-Ship-Dataset [42], and our method achieves the accuracy of 96.7% and 96.5% separately.
2. Related Work
2.1. SAR Ship Detection
2.2. Structure of YOLOv5l
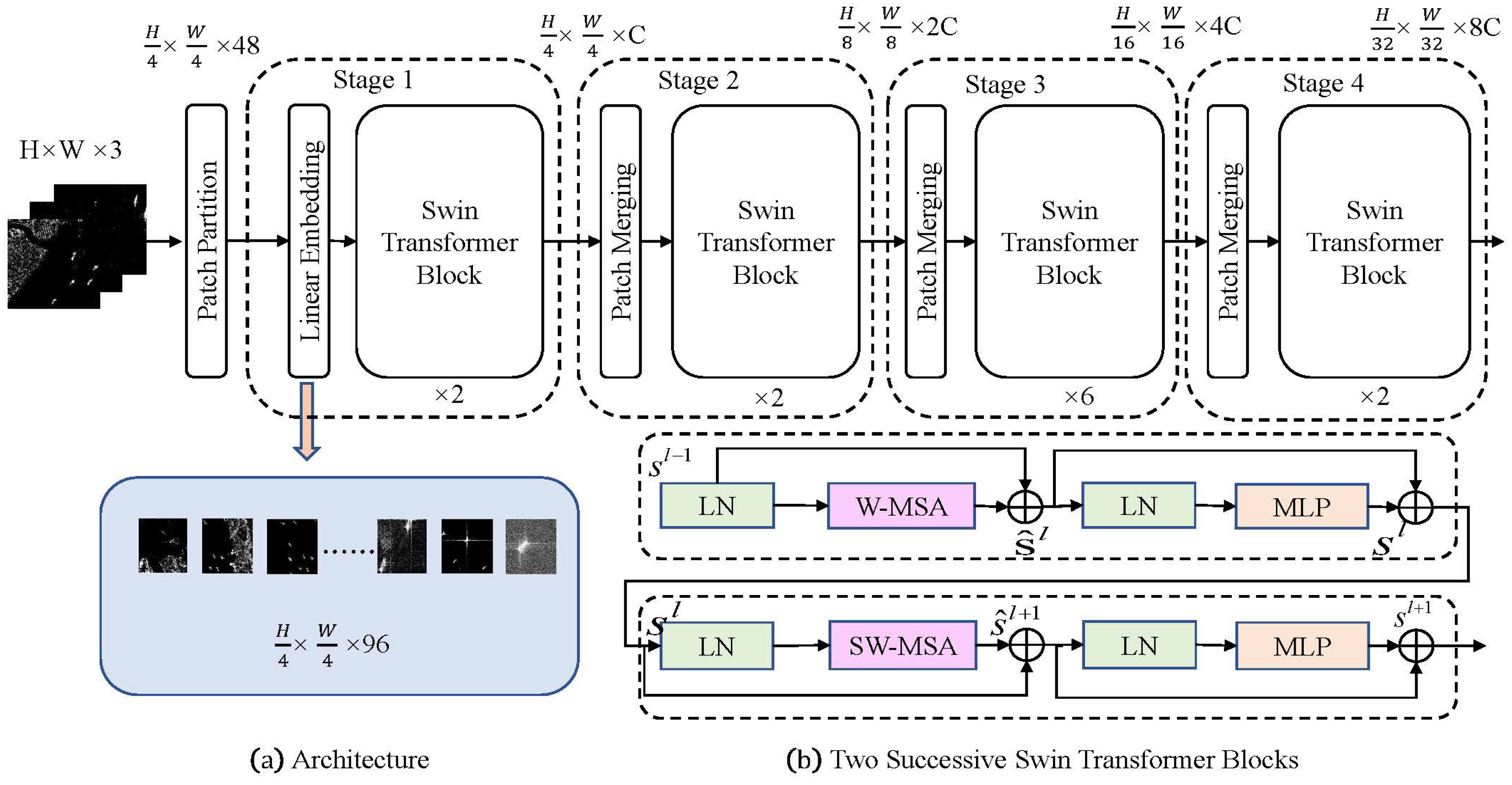
2.3. Swin Transformer
3. Materials and Methods
3.1. SwinT-FRM-ShipNet Network
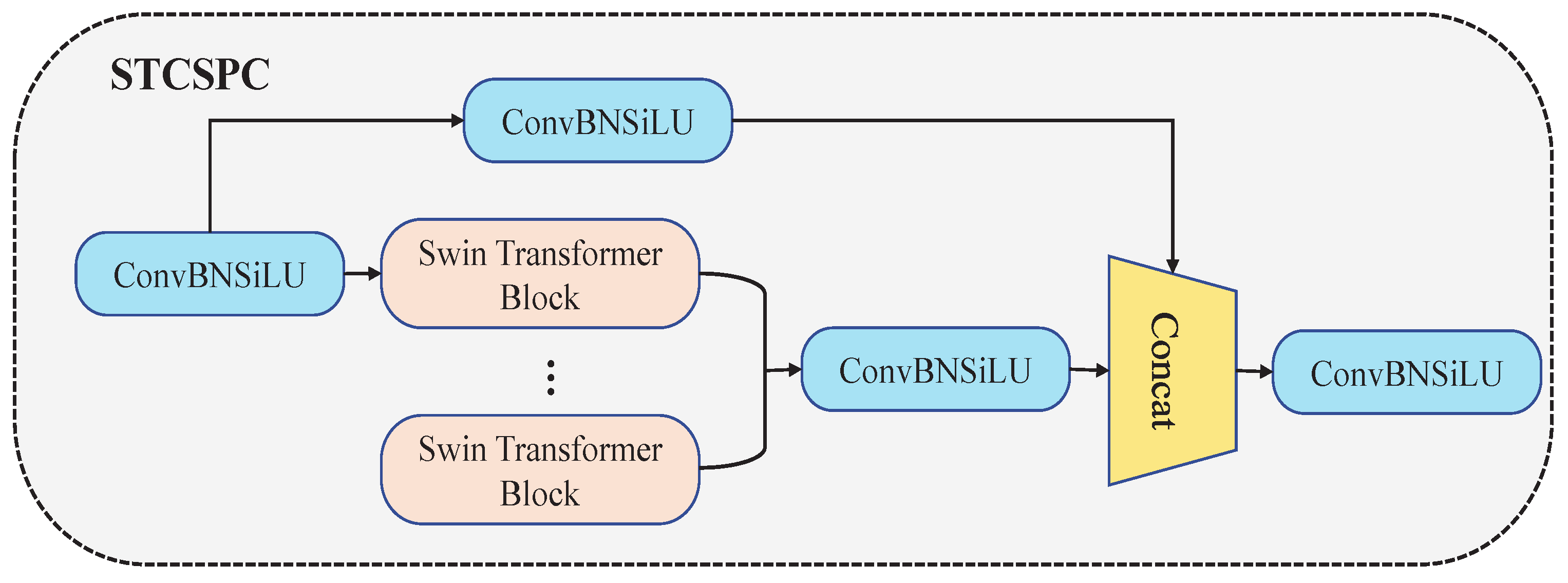
3.2. Integration of Swin Transformer and YOLOv5l
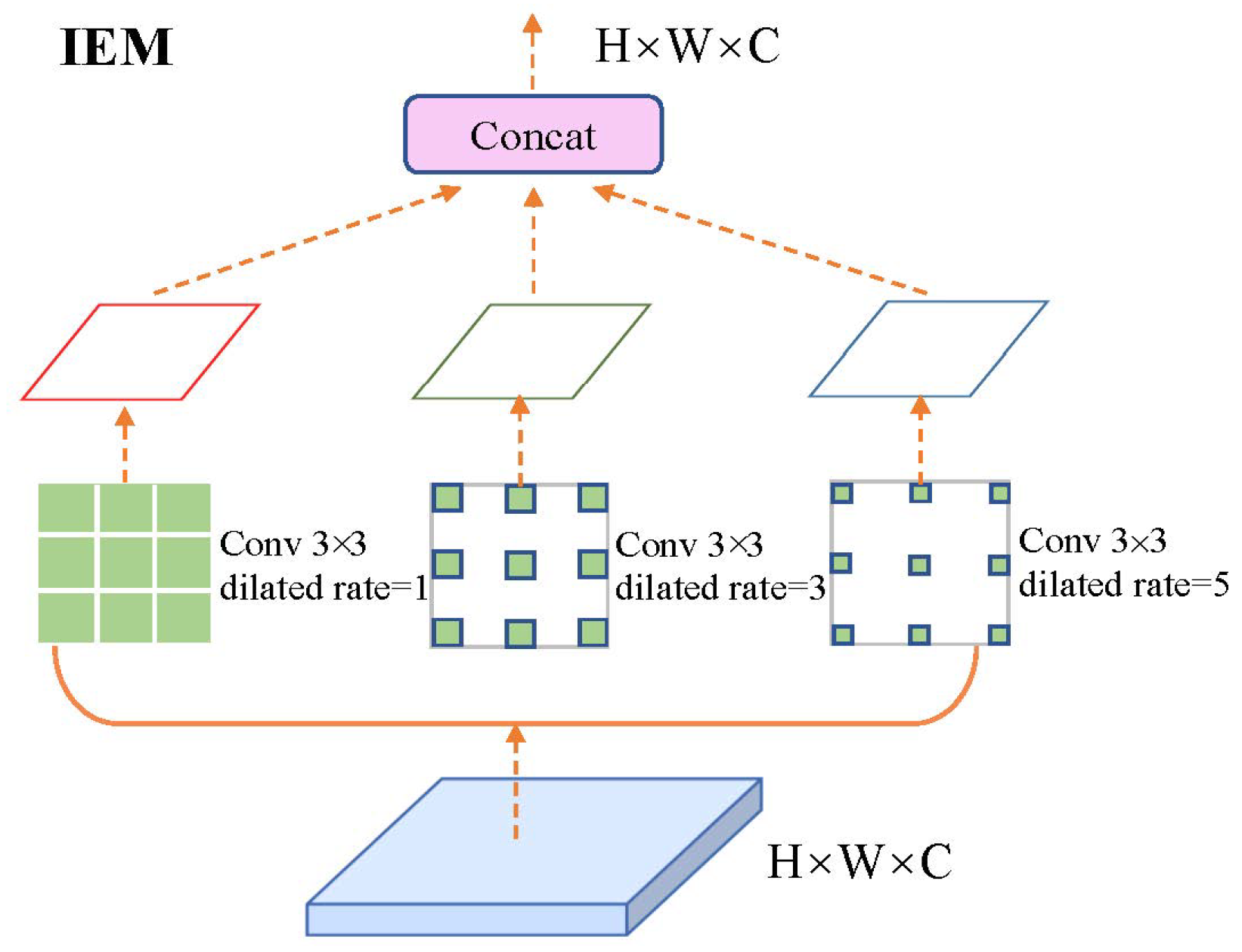
3.3. Information Enhancement Module
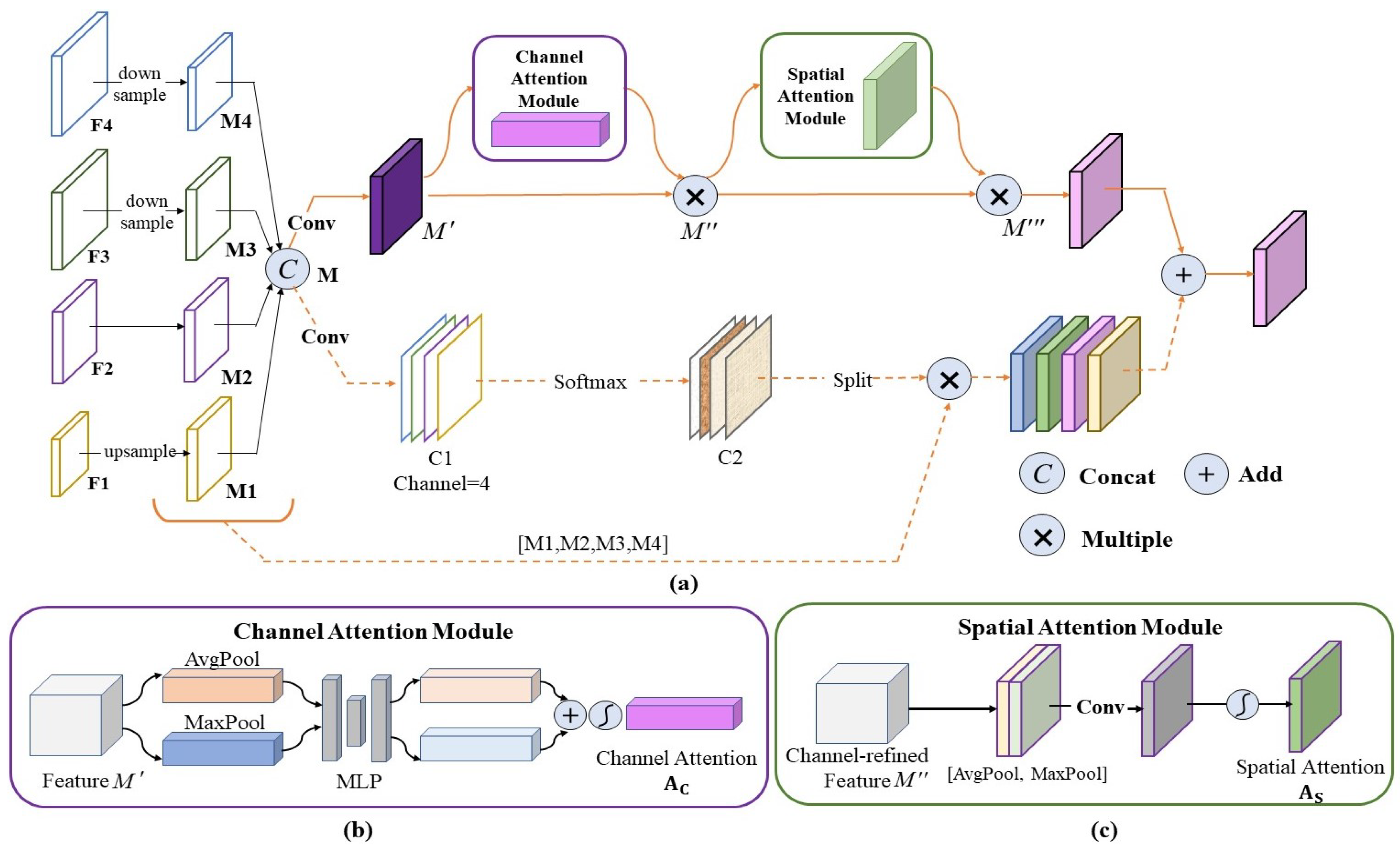
3.4. Feature Refinement Module
3.4.1. Convolutional Block Attention Module
3.4.2. Spatial Purification Module
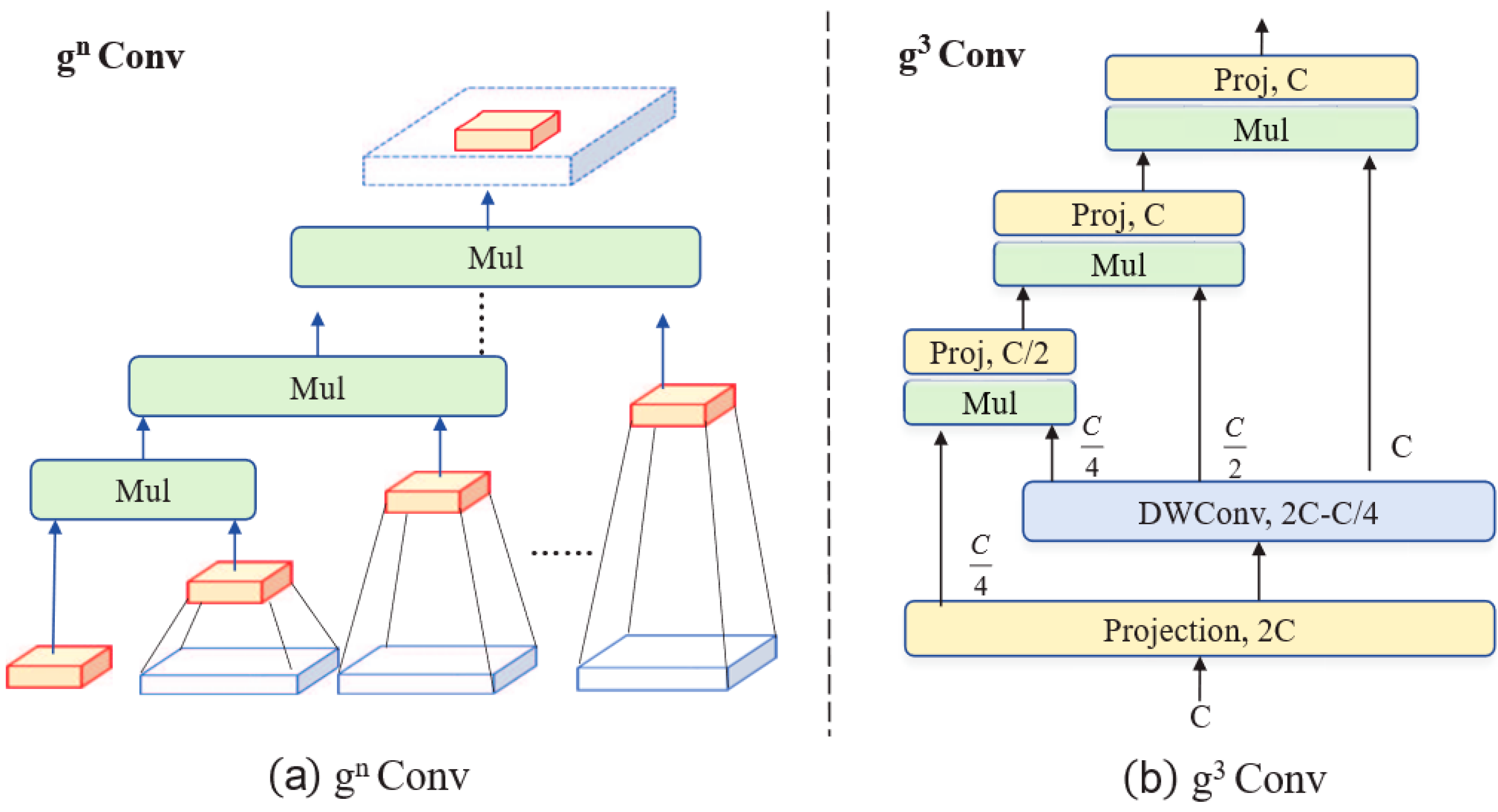
3.5. g3Conv Prediction Head
4. Experiment and Results
4.1. Datasets and Evaluation Metric
4.2. Experiment Settings
4.3. Comparison with the Mainstream Methods
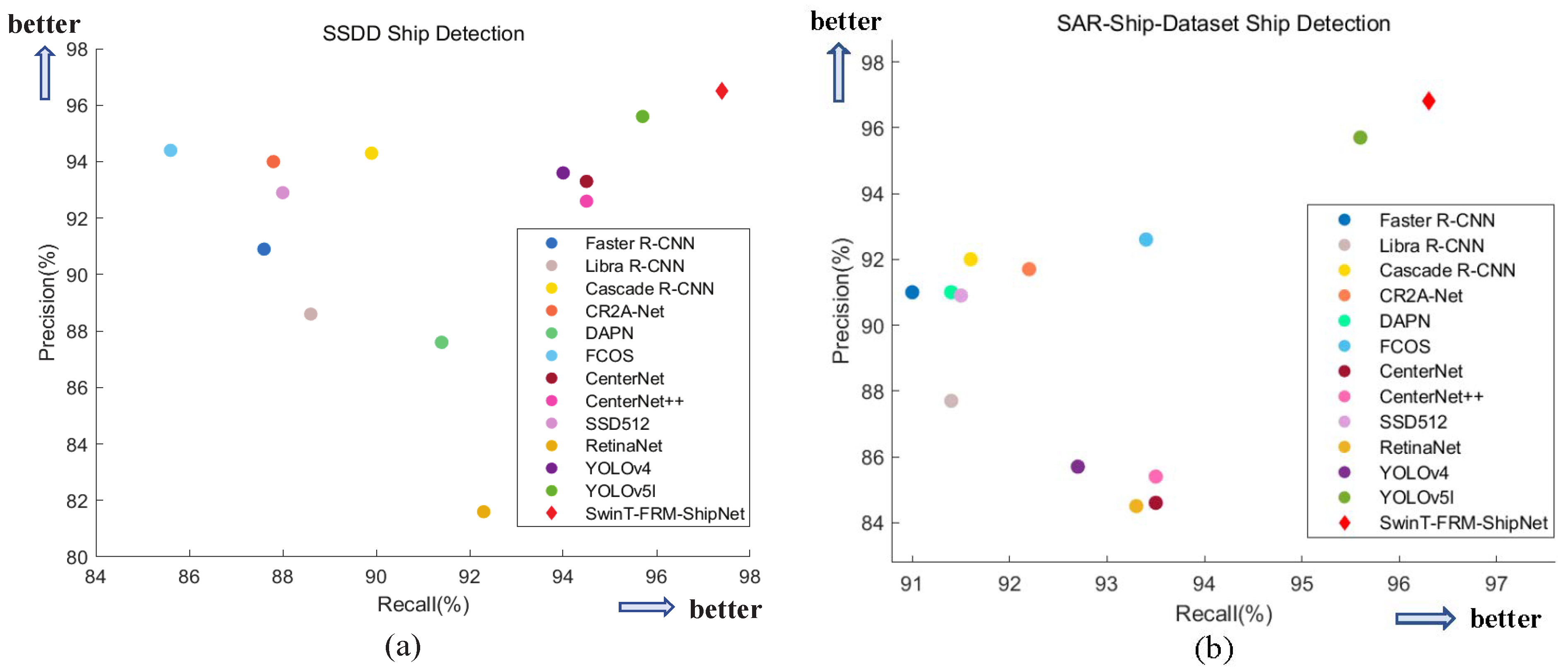
4.3.1. Experiments Based on the SSDD
4.3.2. Experiments Based on the SAR-Ship-Dataset
4.3.3. Discussion
4.4. Visual Results of Near-Shore and Offshore Areas
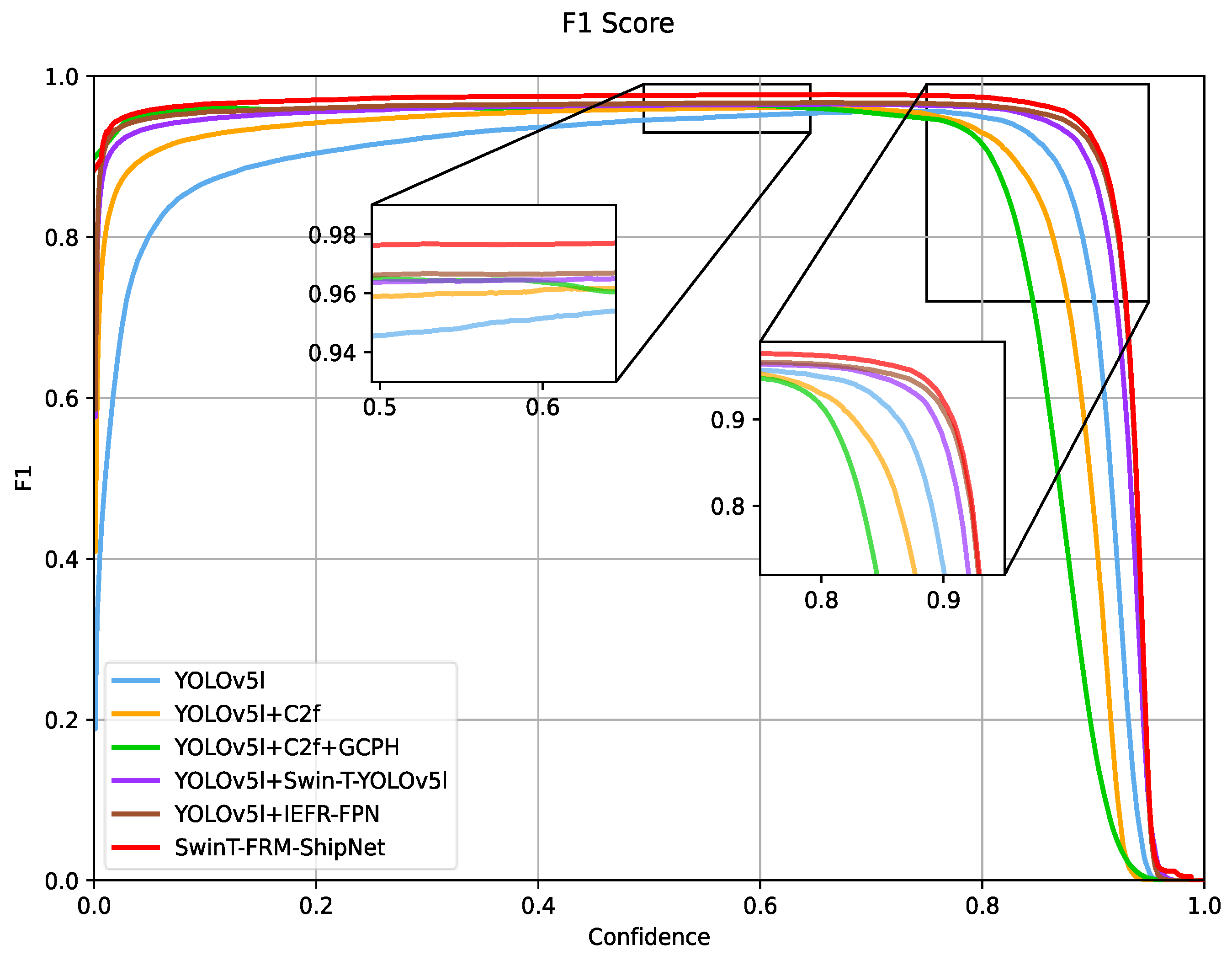
4.5. Ablation Experiment
4.5.1. C2f and GCPH
4.5.2. Swin-T-YOLOv5l
4.5.3. IEFR-FPN
4.5.4. SwinT-FRM-ShipNet
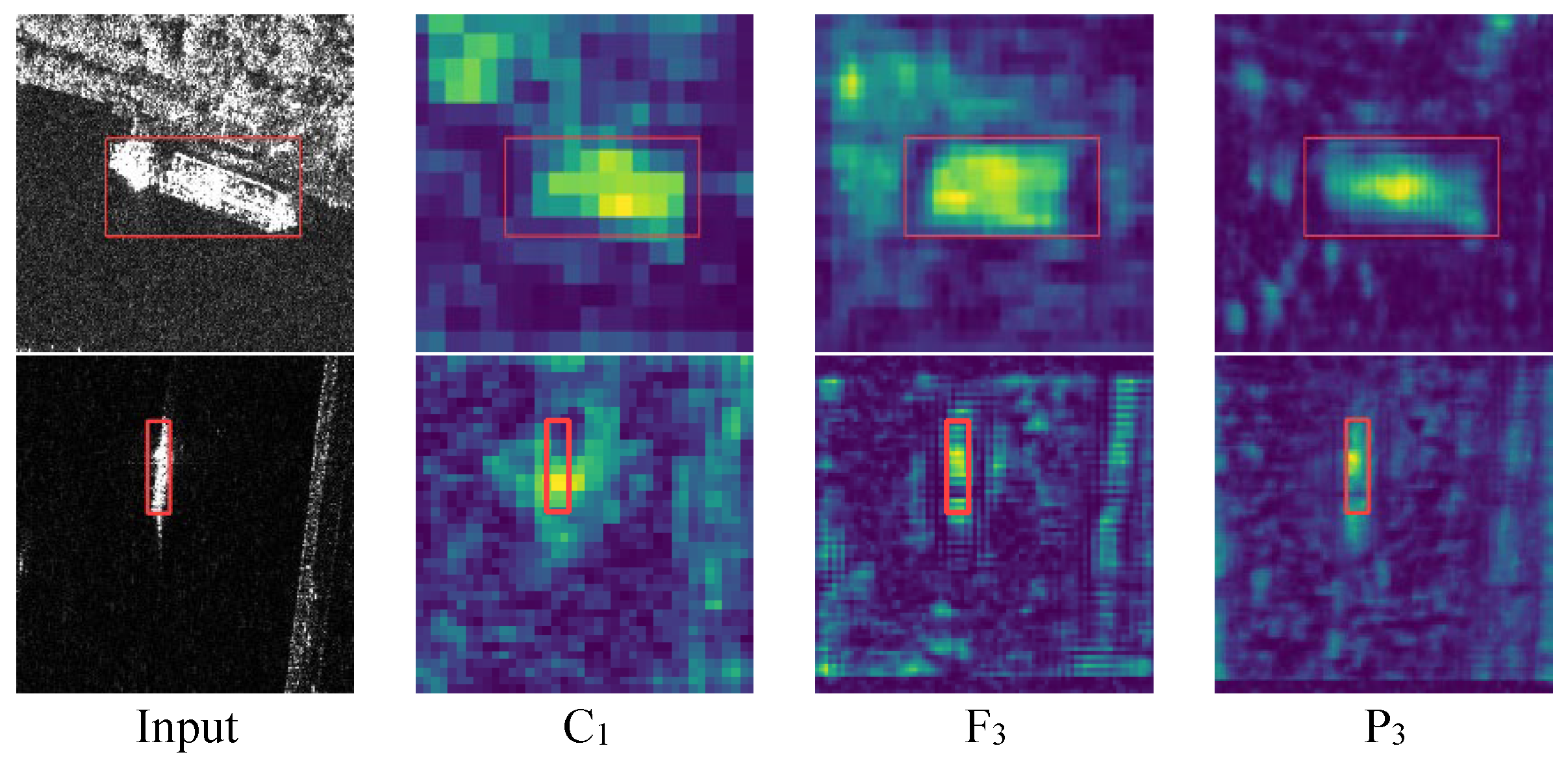
4.6. Feature Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Reigber, A.; Scheiber, R.; Jager, M.; Prats-Iraola, P.; Hajnsek, I.; Jagdhuber, T.; Papathanassiou, K.P.; Nannini, M.; Aguilera, E.; Baumgartner, S.; et al. Very-High-Resolution Airborne Synthetic Aperture Radar Imaging: Signal Processing and Applications. Proc. IEEE 2013, 101, 759–783. [Google Scholar] [CrossRef]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Wackerman, C.C.; Friedman, K.S.; Pichel, W.; Clemente-Colón, P.; Li, X. Automatic Detection of Ships in RADARSAT-1 SAR Imagery. Can. J. Remote Sens. 2001, 27, 568–577. [Google Scholar] [CrossRef]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; Van Schie, B. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 49, 1092–1103. [Google Scholar] [CrossRef]
- Martorella, M.; Pastina, D.; Berizzi, F.; Lombardo, P. Spaceborne radar imaging of maritime moving targets with the Cosmo-SkyMed SAR system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2797–2810. [Google Scholar] [CrossRef]
- Crisp, D.J. A Ship Detection System for RADARSAT-2 Dual-Pol Multi-Look Imagery Implemented in the ADSS. In Proceedings of the 2013 International Conference on Radar, Adelaide, Australia, 9–12 September 2013; pp. 318–323. [Google Scholar] [CrossRef]
- Zhang, T.; Ji, J.; Li, X.; Yu, W.; Xiong, H. Ship Detection from PolSAR Imagery Using the Complete Polarimetric Covariance Difference Matrix. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2824–2839. [Google Scholar] [CrossRef]
- Zhang, T.; Jiang, L.; Xiang, D.; Ban, Y.; Pei, L.; Xiong, H. Ship detection from PolSAR imagery using the ambiguity removal polarimetric notch filter. ISPRS J. Photogramm. Remote Sens. 2019, 157, 41–58. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, H. A CFAR Algorithm Based on Monte Carlo Method for Millimeter-Wave Radar Road Traffic Target Detection. Remote Sens. 2022, 14, 1779. [Google Scholar] [CrossRef]
- Gao, G.; Shi, G. CFAR Ship Detection in Nonhomogeneous Sea Clutter Using Polarimetric SAR Data Based on the Notch Filter. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4811–4824. [Google Scholar] [CrossRef]
- Frery, A.C.; Muller, H.J.; Yanasse, C.D.C.F.; Sant’Anna, S.J.S. A model for extremely heterogeneous clutter. IEEE Trans. Geosci. Remote Sens. 1997, 35, 648–659. [Google Scholar] [CrossRef]
- Wang, C.; Bi, F.; Zhang, W.; Chen, L. An Intensity-Space Domain CFAR Method for Ship Detection in HR SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 529–533. [Google Scholar] [CrossRef]
- Ye, Z.; Liu, Y.; Zhang, S. A CFAR algorithm for non-Gaussian clutter based on mixture of K distributions. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1531–1535. [Google Scholar]
- Drenkow, N.; Sani, N.; Shpitser, I.; Unberath, M. A systematic review of robustness in deep learning for computer vision: Mind the gap? arXiv 2021, arXiv:2112.00639. [Google Scholar]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey. Mach. Learn. Knowl. Extr. 2021, 3, 966–989. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Carotenuto, V.; De Maio, A. On Multiple Covariance Equality Testing with Application to SAR Change Detection. IEEE Trans. Signal Process. 2017, 65, 5078–5091. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2015, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the European Conference on Computer Vision 2022, Tel Aviv, Israel, 24–28 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Freeman, A. SAR calibration: An overview. IEEE Trans. Geosci. Remote Sens. 1992, 30, 1107–1121. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Song, B.; Gao, X. A Rotational Libra R-CNN Method for Ship Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A CenterNet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2020, 59, 379–391. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A Novel Multidimensional Domain Deep Learning Network for SAR Ship Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5203213. [Google Scholar] [CrossRef]
- Dai, W.; Mao, Y.; Yuan, R.; Liu, Y.; Pu, X.; Li, C. A Novel Detector Based on Convolution Neural Networks for Multiscale SAR Ship Detection in Complex Background. Sensors 2020, 20, 2547. [Google Scholar] [CrossRef] [PubMed]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.N.; Lu, J. Hornet: Efficient high-order spatial interactions with recursive gated convolutions. Adv. Neural Inf. Process. Syst. 2022, 35, 10353–10366. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; IEEE; New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European conference on computer vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Keskar, N.S.; Socher, R. Improving generalization performance by switching from adam to sgd. arXiv 2017, arXiv:1712.07628. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Precision (%) | Recall (%) | F1 (%) | mAP0.5 (%) | Runtime (ms) | Params (M) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-101-FPN | 90.9 | 87.6 | 89.2 | 88.3 | 30.2 | 60.1 |
| Libra R-CNN | ResNet-101-FPN | 88.6 | 88.6 | 88.6 | 89.9 | 30.2 | 60.4 |
| Cascade R-CNN | ResNet-101-FPN | 94.3 | 89.9 | 92.0 | 89.5 | 38.8 | 87.9 |
| CR2A-Net | ResNet-101-FPN | 94.0 | 87.8 | 90.8 | 89.8 | 67.2 | 88.6 |
| DAPN | ResNet-101-FPN | 87.6 | 91.4 | 89.4 | 90.1 | 34.5 | 63.8 |
| FCOS | ResNet-101-FPN | 94.4 | 85.6 | 89.8 | 88.7 | 25.9 | 50.8 |
| CenterNet | DAL-34 | 93.3 | 94.5 | 93.9 | 93.5 | 21.5 | 20.2 |
| CenterNet++ | DAL-34 | 92.6 | 94.5 | 93.6 | 92.7 | 21.5 | 20.3 |
| SSD512 | SSDVGG | 92.9 | 88.0 | 90.4 | 94.0 | 30.2 | 24.4 |
| RetinaNet | ResNet-101-FPN | 81.6 | 92.3 | 86.6 | 89.6 | 30.2 | 55.1 |
| YOLOv4 | CSPDarknet-53 | 93.6 | 94.0 | 93.8 | 96.1 | 14.9 | 64.3 |
| YOLOv5l | YOLOv5l | 95.6 | 95.7 | 95.6 | 97.2 | 14.2 | 48.5 |
| SwinT-FRM-ShipNet | Swin-T-YOLOv5l | 96.2 | 97.4 | 96.7 | 98.1 | 21.2 | 64.2 |
| Method | Backbone | Precision (%) | Recall (%) | F1 (%) | mAP0.5 (%) | Runtime (ms) | Params (M) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-101-FPN | 91.0 | 91.0 | 91.0 | 91.0 | 25.1 | 60.1 |
| Libra R-CNN | ResNet-101-FPN | 87.7 | 91.4 | 89.6 | 91.5 | 25.5 | 60.4 |
| Cascade R-CNN | ResNet-101-FPN | 92.0 | 91.6 | 91.8 | 92.0 | 34.0 | 87.9 |
| CR2A-Net | ResNet-101-FPN | 91.7 | 92.2 | 91.9 | 90.1 | 41.7 | 88.6 |
| DAPN | ResNet-101-FPN | 91.0 | 91.4 | 91.2 | 91.9 | 27.8 | 63.8 |
| FCOS | ResNet-101-FPN | 92.6 | 93.4 | 93.0 | 94.9 | 22.8 | 50.8 |
| CenterNet | DAL-34 | 84.6 | 93.5 | 88.8 | 95.0 | 14.3 | 20.2 |
| CenterNet++ | DAL-34 | 85.4 | 93.5 | 89.3 | 94.9 | 15.2 | 20.3 |
| SSD512 | SSDVGG | 90.9 | 91.5 | 91.2 | 94.2 | 23.7 | 24.4 |
| RetinaNet | ResNet-101-FPN | 84.5 | 93.3 | 88.7 | 93.8 | 25.8 | 55.1 |
| YOLOv4 | CSPDarknet-53 | 85.7 | 92.7 | 89.1 | 94.4 | 14.2 | 64.3 |
| YOLOv5l | YOLOv5l | 95.7 | 95.6 | 95.6 | 97.2 | 15.6 | 48.5 |
| SwinT-FRM-ShipNet | Swin-T-YOLOv5l | 96.8 | 96.3 | 96.5 | 98.2 | 24.5 | 64.2 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|---|---|---|
| YOLOv5l | 95.7 | 95.6 | 95.6 | 97.2 | 72.1 |
| YOLOv5l + C2f | 96.4 (+0.7) | 95.6 (+0.0) | 95.9 (+0.3) | 97.7 (+0.5) | 72.4 (+0.3) |
| YOLOv5l + C2f + GCPH | 96.2 (+0.7) | 95.9 (+0.3) | 96.0 (+0.4) | 97.8 (+0.6) | 74.8 (+0.7) |
| YOLOv5l + Swin-T-YOLOv5l (Swin Transformer) | 96.3( +0.6) | 96.2 (+0.6) | 96.2 (+0.6) | 98.1 (+0.9) | 74.2 (+2.1) |
| YOLOv5l + IEFR-FPN (IEM + FRM) | 96.1 (+0.4) | 96.1 (+0.5) | 96.1 (+0.5) | 98.1 (+0.9) | 74.4 (+2.3) |
| SwinT-FRM-ShipNet (C2f + GCPH + Swin-T-YOLOv5l + IEFR-FPN) | 96.8 (+1.1) | 96.3 (+0.7) | 96.5 (+0.9) | 98.2 (+1.0) | 75.4 (+3.3) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Z.; Wang, P.; Li, Y.; Ding, B. A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments. Remote Sens. 2023, 15, 5780. https://doi.org/10.3390/rs15245780
Lu Z, Wang P, Li Y, Ding B. A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments. Remote Sensing. 2023; 15(24):5780. https://doi.org/10.3390/rs15245780
Chicago/Turabian StyleLu, Zhuhao, Pengfei Wang, Yajun Li, and Baogang Ding. 2023. "A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments" Remote Sensing 15, no. 24: 5780. https://doi.org/10.3390/rs15245780
APA StyleLu, Z., Wang, P., Li, Y., & Ding, B. (2023). A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments. Remote Sensing, 15(24), 5780. https://doi.org/10.3390/rs15245780