
A Texture Feature Removal Network for Sonar Image Classification and Detection




Abstract
:1. Introduction
2. Materials and Methods
2.1. Problem Definition
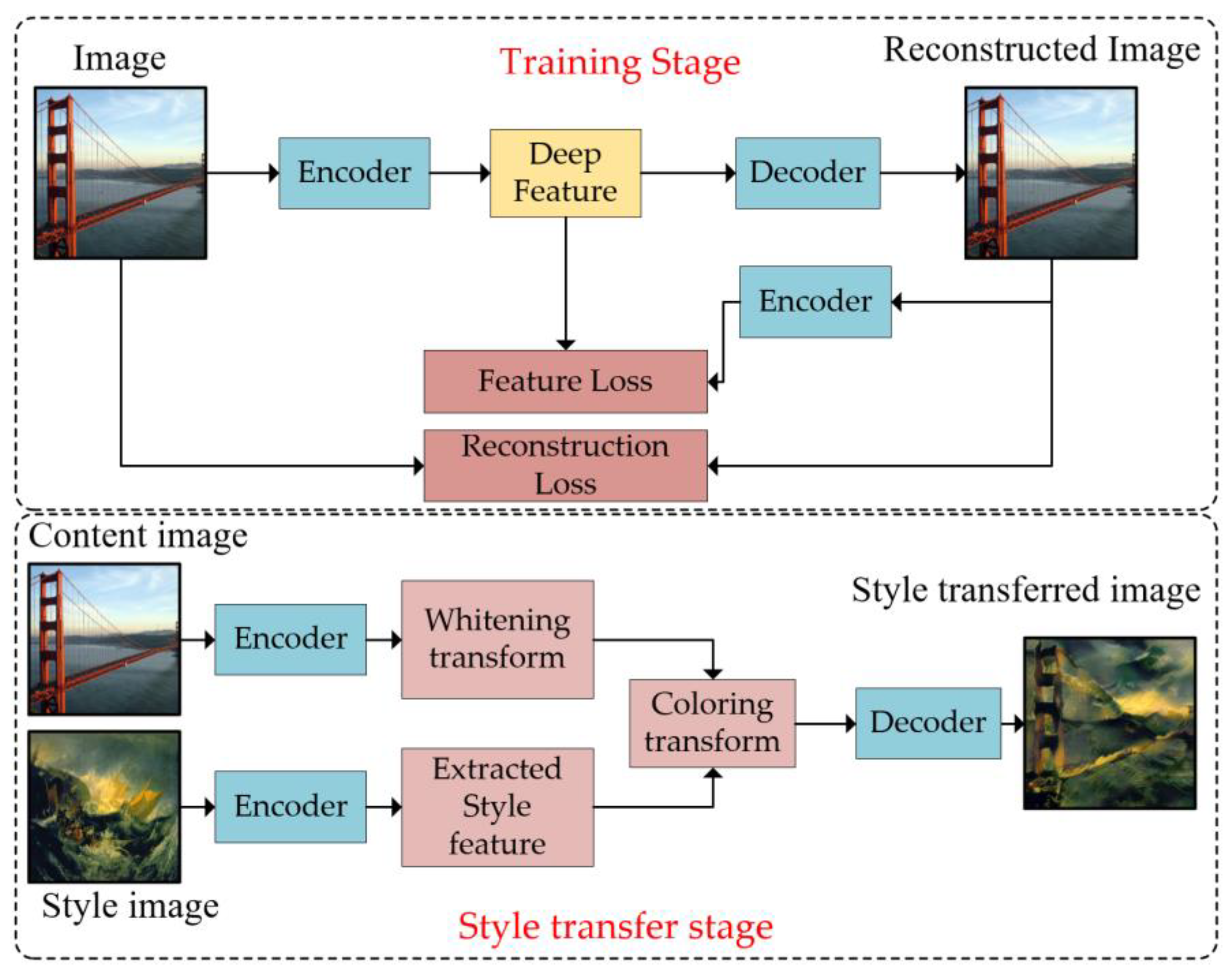
2.2. Texture Feature Removal Network
3. Results
3.1. Supervised Transfer Learning Experiments of the Side-Scan Sonar Image Classification Task
3.1.1. Source Domain Dataset
3.1.2. Side-Scan Sonar Image Dataset
3.1.3. Supervised Transfer Learning Experiments
3.2. Unsupervised Transfer Learning Experiment on the Side-Scan Sonar Image Classification Task
3.3. Imaging Sonar Object Detection Experiments and Results
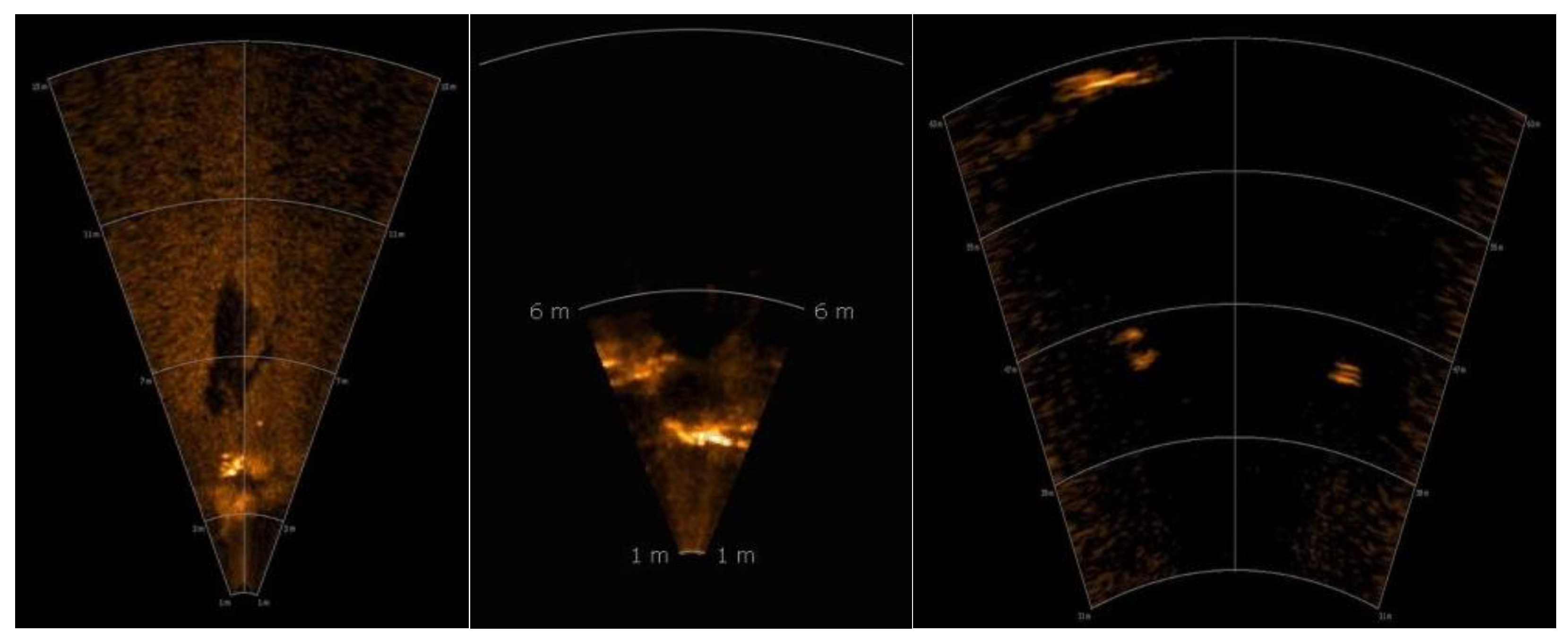
3.3.1. Dataset
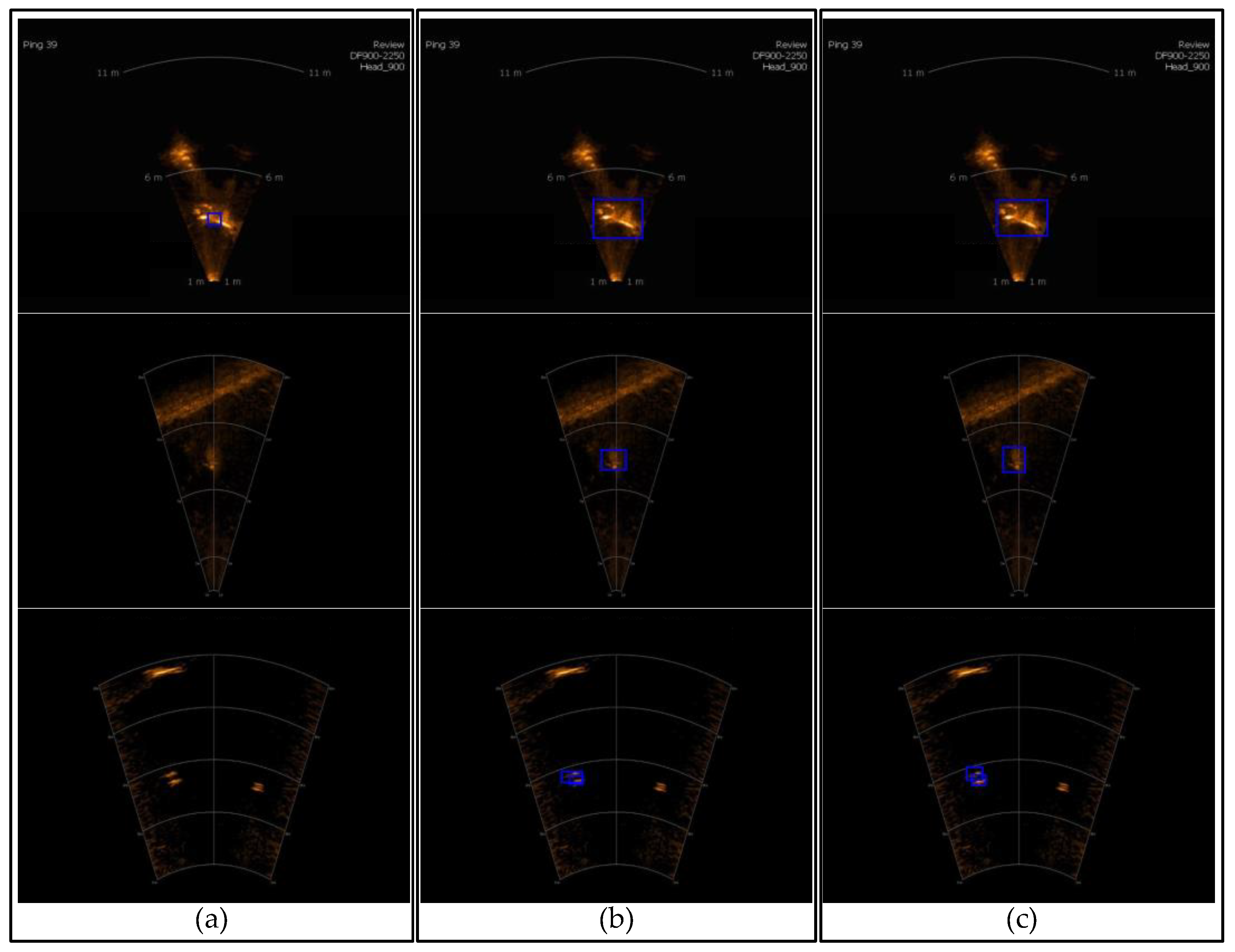
3.3.2. Forward-Looking Sonar Image Detection Experiments
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huo, G.; Wu, Z.; Li, J. Underwater Object Classification in Sidescan Sonar Images Using Deep Transfer Learning and Semisynthetic Training Data. IEEE Access 2020, 8, 47407–47418. [Google Scholar] [CrossRef]
- Ye, X.; Yang, H.; Li, C.; Jia, Y.; Li, P. A gray scale correction method for side-scan sonar images based on retinex. Remote Sens. 2019, 11, 1281. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; He, B.; Liu, P. Real-Time Object Detection for AUVs Using Self-Cascaded Convolutional Neural Networks. IEEE J. Ocean. Eng. 2021, 46, 56–67. [Google Scholar] [CrossRef]
- Cho, H.; Gu, J.; Yu, S. Robust Sonar-Based Underwater Object Recognition Against Angle-of-View Variation. IEEE Sens. J. 2016, 16, 1013–1025. [Google Scholar] [CrossRef]
- Li, C.; Ye, X.; Cao, D.; Hou, J.; Yang, H. Zero shot objects classification method of side scan sonar image based on synthesis of pseudo samples. Appl. Acoust. 2021, 173, 107691. [Google Scholar] [CrossRef]
- Xu, H.; Yuan, H. An svm-based adaboost cascade classifier for sonar image. IEEE Access 2020, 8, 115857–115864. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Talo, M.; Baloglu, U.B.; Yildrm, Ö.; Rajendra Acharya, U. Application of deep transfer learning for automated brain abnormality classification using mr images. Cogn. Syst. Res. 2019, 54, 176–188. [Google Scholar] [CrossRef]
- Swati, Z.N.K.; Zhao, Q.; Kabir, M.; Ali, F.; Ali, Z.; Ahmed, S.; Lu, J. Brain tumor classification for mr images using transfer learning and fine-tuning. Comput. Med. Imaging Graph. 2019, 75, 34–46. [Google Scholar] [CrossRef]
- Rahman, T.; Chowdhury, M.E.H.; Khandakar, A.; Islam, K.R.; Islam, K.F.; Mahbub, Z.B.; Kadir, M.A.; Kashem, S. Transfer learning with deep convolutional neural network (cnn) for pneumonia detection using chest X-ray. Appl. Sci. 2020, 10, 3233. [Google Scholar] [CrossRef]
- Lu, S.; Lu, Z.; Zhang, Y. Pathological brain detection based on alexnet and transfer learning. J. Comput. Sci. 2019, 30, 41–47. [Google Scholar] [CrossRef]
- Liang, G.; Zheng, L. A transfer learning method with deep residual network for pediatric pneumonia diagnosis. Comput. Methods Programs Biomed. 2020, 187, 104964. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- Chouhan, V.; Singh, S.K.; Khamparia, A.; Gupta, D.; Tiwari, P.; Moreira, C.; Damaeviius, R.; De Albuquerque, V.H.C. A novel transfer learning based approach for pneumonia detection in chest X-ray images. Appl. Sci. 2020, 10, 559. [Google Scholar] [CrossRef] [Green Version]
- Lumini, A.; Nanni, L. Deep learning and transfer learning features for plankton classification. Ecol. Inform. 2019, 51, 33–43. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep neural networks with transfer learning in millet crop images. Comput. Ind. 2019, 108, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J.; Zhang, D.; Sun, Y.; Nanehkaran, Y. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Qin, X.; Luo, X.; Wu, Z.; Shang, J. Optimizing the sediment classification of small side-scan sonar images based on deep learning. IEEE Access 2021, 9, 29416–29428. [Google Scholar] [CrossRef]
- Pires de Lima, R.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2019, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- You, K.; Liu, Y.; Wang, J.; Long, M. Logme: Practical assessment of pre-trained models for transfer learning. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Volume 139, pp. 12133–12143. [Google Scholar]
- You, K.; Kou, Z.; Long, M.; Wang, J. Co-tuning for transfer learning. Adv. Neural Inf. Process. Syst. 2020, 33, 17236–17246. [Google Scholar]
- Guo, Y.; Shi, H.; Kumar, A.; Grauman, K.; Rosing, T.; Feris, R. Spottune: Transfer learning through adaptive fine-tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4805–4814. [Google Scholar]
- Shafahi, A.; Saadatpanah, P.; Zhu, C.; Ghiasi, A.; Studer, C.; Jacobs, D.; Goldstein, T. Adversarially robust transfer learning. arXiv 2019, arXiv:1905.08232. [Google Scholar]
- Chen, W.; Liu, Z.; Zhang, H.; Chen, M.; Zhang, Y. A submarine pipeline segmentation method for noisy forward-looking sonar images using global information and coarse segmentation. Appl. Ocean Res. 2021, 112, 102691. [Google Scholar] [CrossRef]
- Yulin, T.; Shaohua, J.; Gang, B.; Yonzhou, Z.; Fan, L. Wreckage target recognition in side-scan sonar images based on an improved faster r-cnn model. In Proceedings of the 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Bangkok, Thailand, 30 October–1 November 2020; pp. 348–354. [Google Scholar]
- Zhou, Y.; Chen, S. Research on lightweight improvement of sonar image classification network. In Proceedings of the Journal of Physics: Conference Series, Dali, China, 18–20 June 2021; p. 012140. [Google Scholar]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-time underwater maritime object detection in side-scan sonar images based on transformer-yolov5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Raaza, A.; Rajendran, V.; Ravikumar, D. Side scan sonar image augmentation for sediment classification using deep learning based transfer learning approach. Mater. Today Proc. 2021, 1, 1. [Google Scholar] [CrossRef]
- Ochal, M.; Vazquez, J.; Petillot, Y.; Wang, S. A comparison of few-shot learning methods for underwater optical and sonar image classification. In Proceedings of the Global Oceans 2020, Singapore U.S., Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–10. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain adaptive neural networks for object recognition. In Proceedings of Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2014; pp. 898–904. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2208–2217. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning with double encoding-layer autoencoder for transfer learning. ACM Trans. Intell. Syst. Technol. 2017, 9, 1–17. [Google Scholar] [CrossRef]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T.; Lu, W.; Chen, Y.; Zeng, W.; Yu, P. Generalizing to unseen domains: A survey on domain Generalization. IEEE Trans. Knowl. Data Eng. 2022, 1, 1. [Google Scholar] [CrossRef]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. Adv. Neural Inf. Process. Syst. 2015, 28, 262–270. [Google Scholar]
- Cui, S.; Wang, S.; Zhuo, J.; Li, L.; Huang, Q.; Tian, Q. Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 14–19 June 2020; pp. 3941–3950. [Google Scholar]
- Xu, T.; Chen, W.; Wang, P.; Wang, F.; Li, H.; Jin, R. Cdtrans: Cross-domain transformer for unsupervised domain adaptation. arXiv 2021, arXiv:2109.06165. [Google Scholar]
- Venkateswara, H.; Eusebio, J.; Chakraborty, S.; Panchanathan, S. Deep hashing network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5018–5027. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 1. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 97–105. [Google Scholar]
- Li, Y.; Liu, M.; Li, X.; Yang, M.; Kautz, J. A closed-form solution to photorealistic image stylization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 453–468. [Google Scholar]
- Alexey, D.; Thomas, B. Generating images with perceptual similarity metrics based on deep networks. Adv. Neural Inf. Process. Syst. 2016, 29, 658–666. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. Isprs J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Gong, C.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar]
- Yin, X.; Chen, W.; Wu, X.; Yue, H. Fine-tuning and visualization of convolutional neural networks. In Proceedings of the 12th IEEE Conference on Industrial Electronics and Applications (ICIEA), Siem Reap, Cambodia, 18–20 June 2017; pp. 1310–1315. [Google Scholar]
- Karen, S.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NY, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhao, S.; Yue, X.; Zhang, S.; Li, B.; Zhao, H.; Wu, B.; Krishna, R.; Gonzalez, J.E.; Sangiovanni-Vincentelli, A.; Seshia, S.A.; et al. A review of single-source deep unsupervised visual domain adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 473–493. [Google Scholar] [CrossRef] [PubMed]
- Wilson, G.; Cook, D.J. A survey of unsupervised deep domain adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–46. [Google Scholar] [CrossRef]
- Gani, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2015, 17, 2030–2096. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision 2014 (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
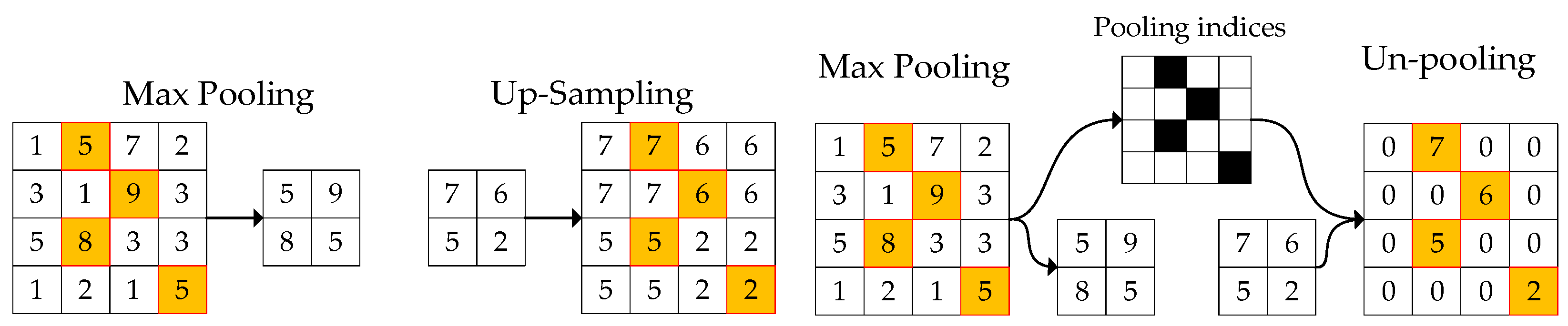{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
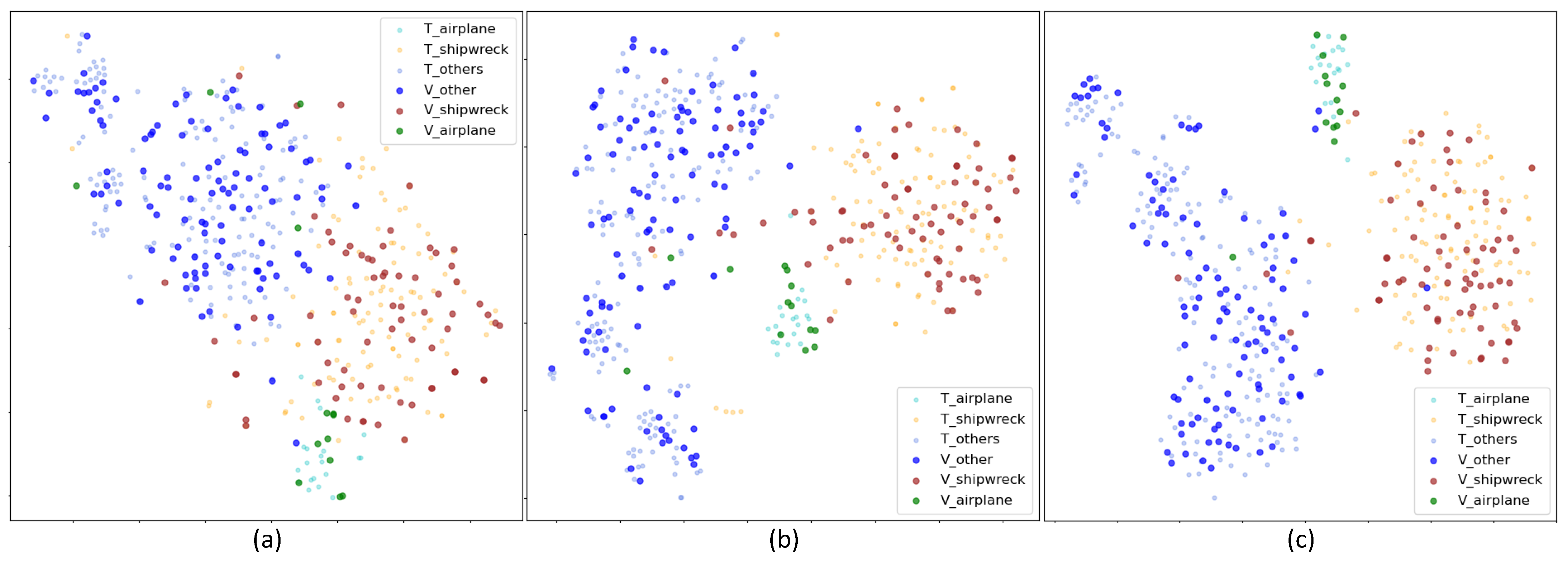{kind=link}
| Airplane 13 Samples | Shipwreck 71 Samples | Other 106 Samples | Global Accuracy | Mean Accuracy | |
|---|---|---|---|---|---|
| 6 | 45 | 100 | 0.7947 | 0.6796 | |
| 9 | 67 | 100 | 0.9316 | 0.8645 | |
| Our method | 11 | 66 | 101 | 0.9368 | 0.9095 |
| Airplane 33 Samples | Shipwreck 179 Samples | Other 265 Samples | Global Accuracy | Mean Accuracy | |
|---|---|---|---|---|---|
| DaNN | 19 | 103 | 251 | 0.782 | 0.6995 |
| Our method | 22 | 122 | 244 | 0.8134 | 0.7563 |
| Missing Detections | Incorrect Detections | |||
|---|---|---|---|---|
| 0.039 | 0.231 | 9 | 1 | |
| 0.246 | 0.632 | 2 | 1 | |
| Our method | 0.356 | 0.711 | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Ye, X.; Xi, J.; Jia, Y. A Texture Feature Removal Network for Sonar Image Classification and Detection. Remote Sens. 2023, 15, 616. https://doi.org/10.3390/rs15030616
Li C, Ye X, Xi J, Jia Y. A Texture Feature Removal Network for Sonar Image Classification and Detection. Remote Sensing. 2023; 15(3):616. https://doi.org/10.3390/rs15030616
Chicago/Turabian StyleLi, Chuanlong, Xiufen Ye, Jier Xi, and Yunpeng Jia. 2023. "A Texture Feature Removal Network for Sonar Image Classification and Detection" Remote Sensing 15, no. 3: 616. https://doi.org/10.3390/rs15030616
APA StyleLi, C., Ye, X., Xi, J., & Jia, Y. (2023). A Texture Feature Removal Network for Sonar Image Classification and Detection. Remote Sensing, 15(3), 616. https://doi.org/10.3390/rs15030616