
DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement


Abstract
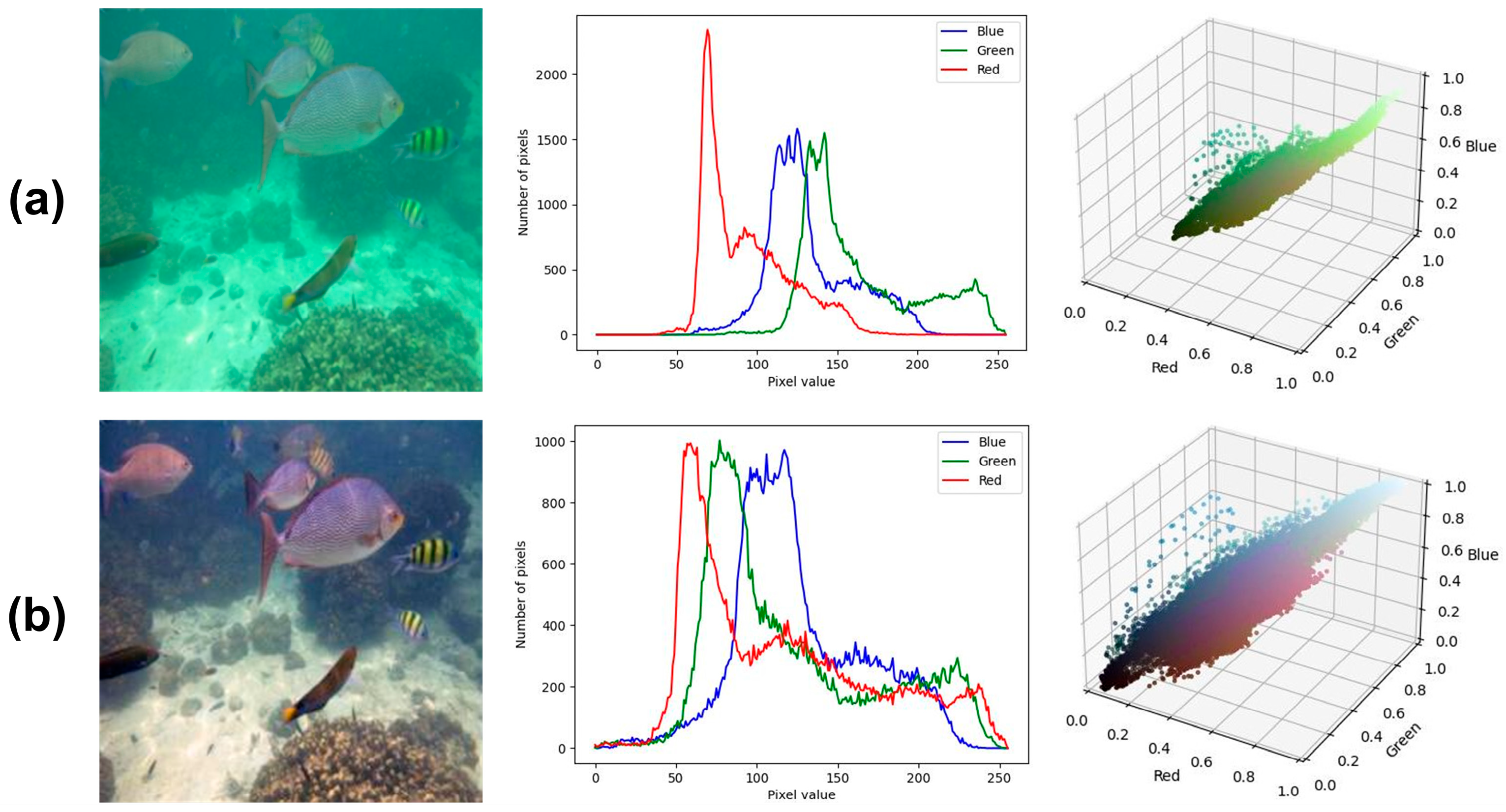
1. Introduction
- ∙
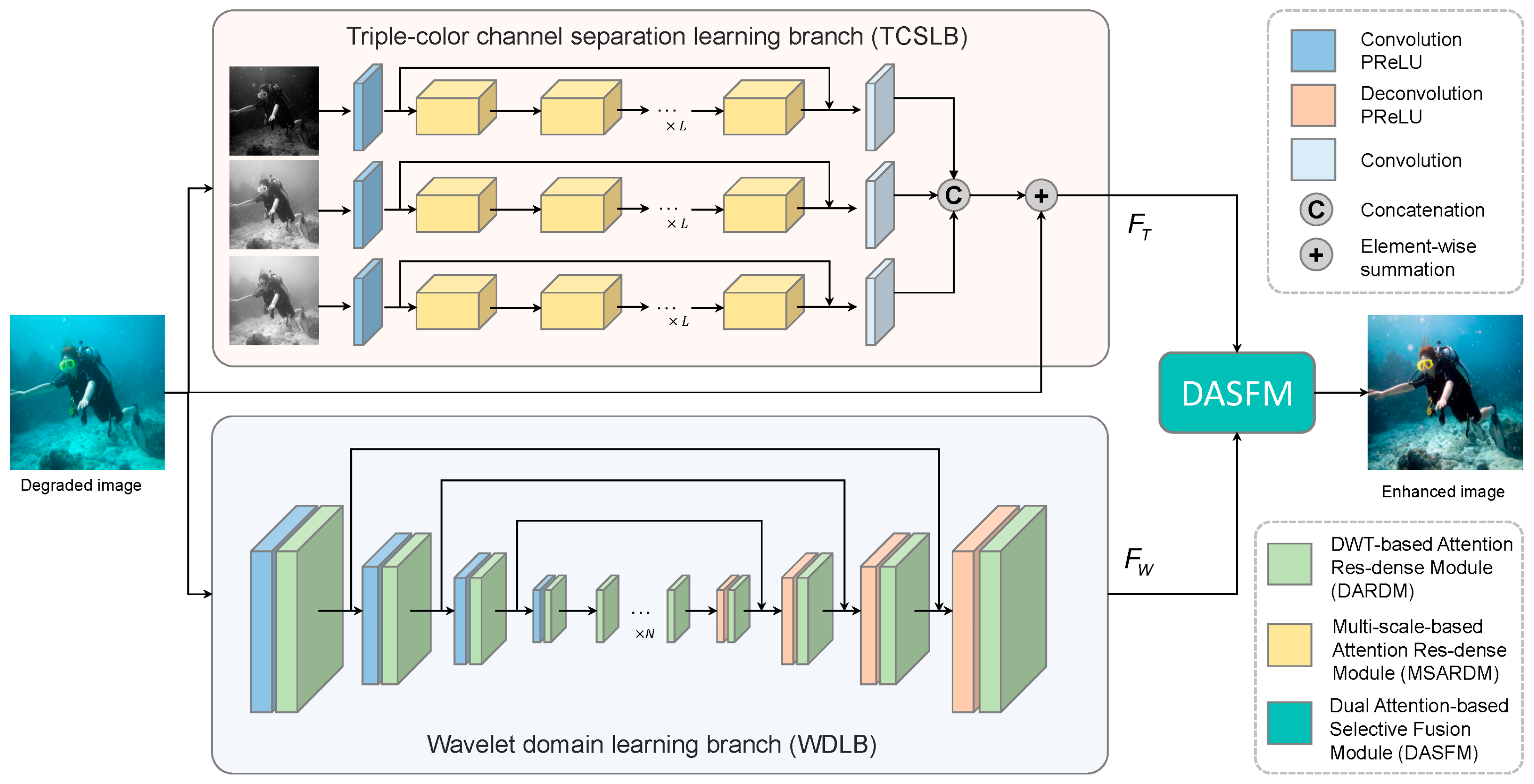
- We propose a dual-branch network termed the DBFNet for UIE. Our method is more effective for color correction and detail restoration, thanks to the use of the triple-color channel separation learning branch and wavelet domain learning branch;
- ∙
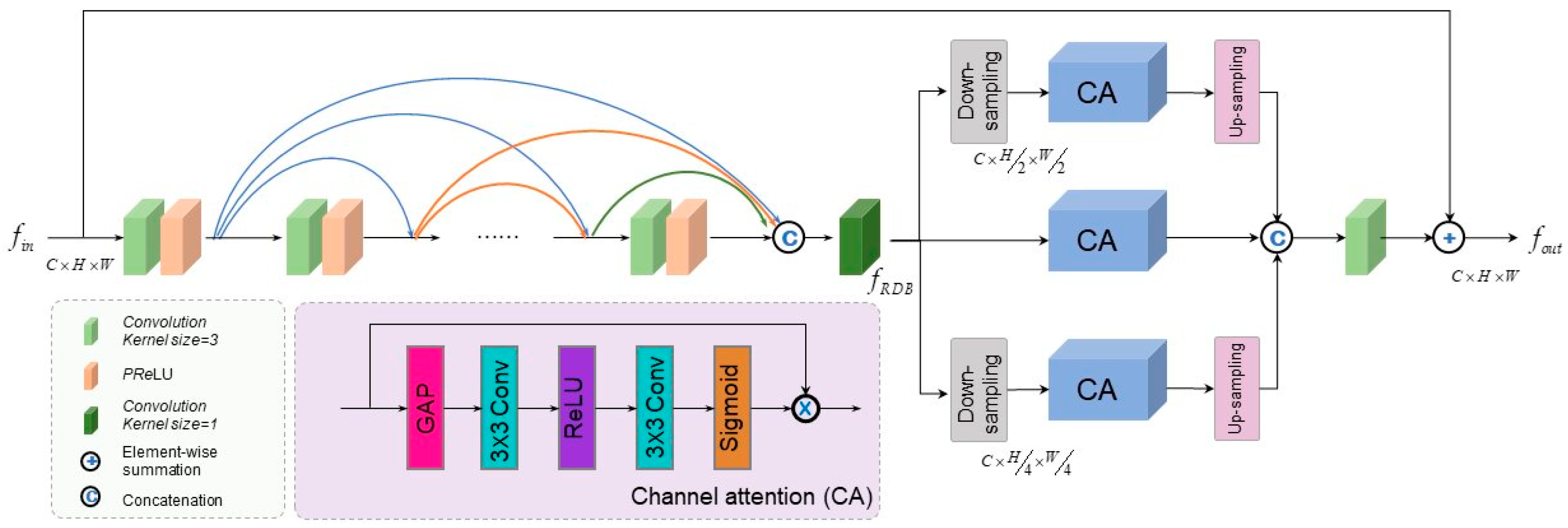
- In the TCSLB, we design an effective MSARDM consisting of dense residual blocks and a multi-scale channel attention sub-module, which can improve the color mapping performance;
- ∙
- In the WDLB, we design an effective DARDM consisting of dense residual blocks and a DWT-based attention module, which can provide more detailed features in the wavelet domain;
- ∙
- We design the dual attention-based selective fusion module to achieve the feasible fusion of TCSLB and WDLB output features, which can adaptively emphasize the information parts of different latent results;
- ∙
- We validate the effectiveness of the DBFNet by comparing it with recent DL-based and model-based methods on different datasets. Moreover, we provide detailed ablation experiments and visual and quantitative evaluations.
2. Related Work
3. Proposed Method
3.1. Overall Architecture
3.2. Triple-Color Channel Separation Learning Branch (TCSLB)
3.3. Wavelet Domain Learning Branch (WDLB)
3.4. Dual Attention-Based Selective Fusion Module (DASFM)
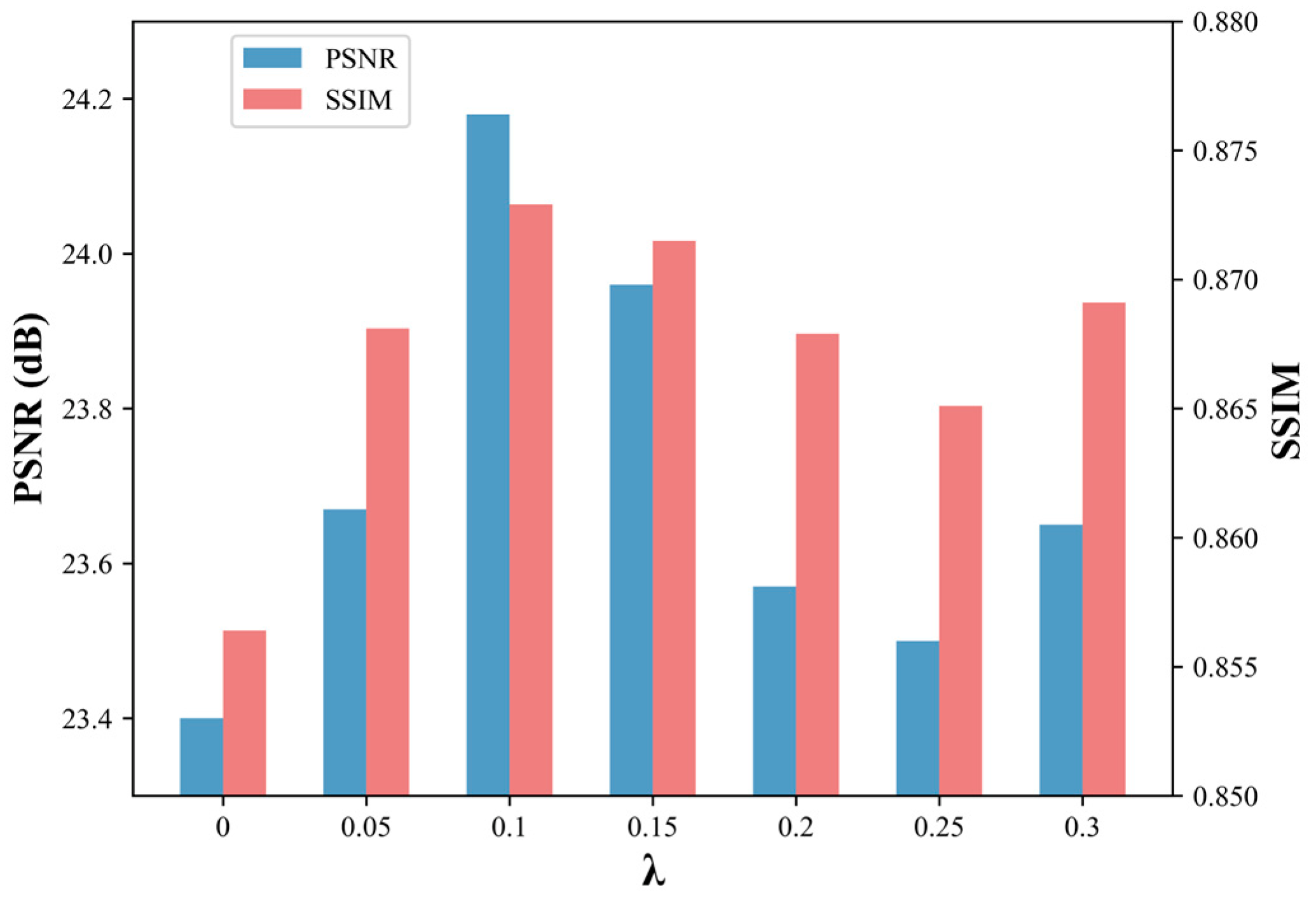
3.5. Hybrid Loss Function
4. Experiments
4.1. Experimental Implementation Details
4.2. Comparisons on Synthetic Datasets
4.3. Comparisons on Real-World Datasets
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission Estimation in Underwater Single Images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 825–830. [Google Scholar]
- Peng, Y.-T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Liu, D.; Xie, X.; Zhang, W. Underwater image restoration by red channel compensation and underwater median dark channel prior. Appl. Optics 2022, 61, 2915–2922. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Fan, H.; Lin, S.; Wang, Q.; Ding, N.; Tang, Y. Adaptive Learning Attention Network for Underwater Image Enhancement. IEEE Robot. Autom. Lett. 2022, 7, 5326–5333. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R. UDA-Net: Densely Attention Network for Underwater Image Enhancement. IET Image Process. 2021, 15, 774–785. [Google Scholar] [CrossRef]
- Liu, P.; Wang, G.; Qi, H.; Zhang, C.; Zheng, H.; Yu, Z. Underwater image enhancement with a deep residual framework. IEEE Access 2019, 7, 94614–94629. [Google Scholar] [CrossRef]
- Gangisetty, S.; Rai, R.R. FloodNet: Underwater image restoration based on residual dense learning. Signal Process. Image Commun. 2022, 104, 116647. [Google Scholar] [CrossRef]
- Yang, H.H.; Huang, K.C.; Chen, W.T. LAFFNet: A lightweight adaptive feature fusion network for underwater image enhancement. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 685–692. [Google Scholar]
- Qi, Q.; Zhang, Y.; Tian, F.; Wu, Q.M.J.; Li, K.; Luan, X.; Song, D. Underwater image co-enhancement with correlation feature matching and joint learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1133–1147. [Google Scholar] [CrossRef]
- Guo, Y.; Li, H.; Zhuang, P. Underwater image enhancement using a multiscale dense generative adversarial network. IEEE J. Oceanic Eng. 2019, 45, 862–870. [Google Scholar] [CrossRef]
- Yang, M.; Hu, K.; Du, Y.; Wei, Z.; Sheng, Z.; Hu, J. Underwater image enhancement based on conditional generative adversarial network. Signal Process. Image Commun. 2020, 81, 115723. [Google Scholar] [CrossRef]
- Zhang, D.; Shen, J.; Zhou, J.; Chen, E.; Zhang, W. Dual-path joint correction network for underwater image enhancement. Opt. Express 2022, 30, 33412–33432. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, P.; Quan, L.; Yi, C.; Lu, C. Underwater image enhancement based on deep learning and image formation model. arXiv 2021, arXiv:2101.00991. [Google Scholar]
- Peng, L.; Zhu, C.; Bian, L. U-shape Transformer for Underwater Image Enhancement. arXiv 2021, arXiv:2111.11843. [Google Scholar]
- Xue, X.; Hao, Z.; Ma, L.; Wang, Y.; Liu, R. Joint luminance and chrominance learning for underwater image enhancement. IEEE Signal Process. Lett. 2021, 28, 818–822. [Google Scholar] [CrossRef]
- Xue, X.; Li, Z.; Ma, L.; Jia, Q.; Liu, R.; Fan, X. Investigating intrinsic degradation factors by multi-branch aggregation for real-world underwater image enhancement. Pattern Recognit. 2023, 133, 109041. [Google Scholar] [CrossRef]
- Yan, X.; Qin, W.; Wang, Y.; Wang, G.; Fu, X. Attention-guided dynamic multi-branch neural network for underwater image enhancement. Knowl.-Based Syst. 2022, 258, 110041. [Google Scholar] [CrossRef]
- Hu, J.; Jiang, Q.; Cong, R.; Gao, W.; Shao, F. Two-branch deep neural network for underwater image enhancement in HSV color space. IEEE Signal Process. Lett. 2021, 28, 2152–2156. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, Z.; Yang, S.; Gao, W.; Shao, F. Target Oriented Perceptual Adversarial Fusion Network for Underwater Image Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6584–6598. [Google Scholar] [CrossRef]
- Jamadandi, A.; Mudenagudi, U. Exemplar-based underwater image enhancement augmented by wavelet corrected transforms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–21 June 2019; pp. 11–17. [Google Scholar]
- Aytekin, C.; Alenius, S.; Paliy, D.; Gren, J. A Sub-band Approach to Deep Denoising Wavelet Networks and a Frequency-adaptive Loss for Perceptual Quality. In Proceedings of the IEEE International Workshop on Multimedia Signal Processing, Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Huo, F.; Li, B.; Zhu, X. Efficient Wavelet Boost Learning-Based Multi-stage Progressive Refinement Network for Underwater Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1944–1952. [Google Scholar]
- Ma, Z.; Oh, C. A Wavelet-Based Dual-Stream Network for Underwater Image Enhancement. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2769–2773. [Google Scholar]
- Zou, W.; Jiang, M.; Zhang, Y.; Chen, L.; Lu, Z.; Wu, Y. SDWnet: A straight dilated network with wavelet transformation for image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1895–1904. [Google Scholar]
- Fan, C.M.; Liu, T.J.; Liu, K.H. Half Wavelet Attention on M-Net+ for Low-Light Image Enhancement. arXiv 2022, arXiv:2203.01296. [Google Scholar]
- Peng, Y.; Cao, Y.; Liu, S.; Yang, J.; Zuo, W. Progressive training of multi-level wavelet residual networks for image denoising. arXiv 2020, arXiv:2010.12422. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Sun, K.; Meng, F.; Tian, Y. Underwater image enhancement based on noise residual and color correction aggregation network. Digit. Signal Process. 2022, 129, 103684. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Yang, H.; Zhou, D.; Cao, J.; Zhao, Q. DPNet: Detail-preserving image deraining via learning frequency domain knowledge. Digit. Signal Process. 2022, 130, 103740. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Anwar, S.; Li, C.; Porikli, F. Deep underwater image enhancement. arXiv 2018, arXiv:1807.03528. [Google Scholar]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Hore, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Hunt, B.R. The Application of Constrained Least Squares Estimation to Image Restoration by Digital Computer. IEEE Trans. Comput. 1973, 100, 805–812. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired Underwater Image Quality Measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An Underwater Color Image Quality Evaluation Metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-UWnet: Compressed Model for Underwater Image Enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 15853–15854. [Google Scholar]
- Sharma, P.K.; Bisht, I.; Sur, A. Wavelength-based Attributed Deep Neural Network for Underwater Image Restoration. arXiv 2021, arXiv:2106.07910. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Wang, Y.; Guo, J.; Gao, H.; Yue, H. UIEC2Net: CNN-based Underwater Image Enhancement Using Two Color Space. Signal Process. Image Commun. 2021, 96, 116250. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, Z.; Tong, L.; Liu, Z.; Zhao, A.; Zhang, Q.; Dong, J.; Zhou, H. Perceptual underwater image enhancement with deep learning and physical priors. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3078–3092. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Metrics | UDCP | IBLA | Shallow-UWnet | UResnet | Chen et al. | WaterNet | Deep-WaveNet | UGAN | Ma et al. | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PSNR | 13.68 | 14.70 | 18.85 | 19.50 | 20.07 | 20.67 | 23.08 | 25.45 | 27.82 | 31.93 |
| SSIM | 0.6547 | 0.6881 | 0.7789 | 0.7158 | 0.7518 | 0.8361 | 0.8651 | 0.8874 | 0.8873 | 0.9165 | |
| MSE | 3.3332 | 2.8291 | 1.3059 | 0.9665 | 0.8480 | 0.7702 | 0.4172 | 0.1914 | 0.1279 | 0.0464 | |
| 3 | PSNR | 11.84 | 13.03 | 15.04 | 16.71 | 17.43 | 17.97 | 19.76 | 24.74 | 24.58 | 29.68 |
| SSIM | 0.5444 | 0.0639 | 0.6863 | 0.6492 | 0.6908 | 0.7825 | 0.7972 | 0.8616 | 0.8434 | 0.8962 | |
| MSE | 4.9485 | 3.6553 | 2.2795 | 1.7687 | 1.4022 | 1.3724 | 0.9074 | 0.2353 | 0.3010 | 0.0895 | |
| 5 | PSNR | 10.00 | 11.16 | 13.80 | 13.34 | 15.40 | 15.13 | 16.52 | 22.61 | 20.91 | 24.95 |
| SSIM | 0.3992 | 0.4531 | 0.6118 | 0.5079 | 0.6059 | 0.6955 | 0.6997 | 0.7863 | 0.7671 | 0.8356 | |
| MSE | 7.4906 | 5.7544 | 3.0015 | 3.3493 | 2.1646 | 2.4177 | 1.7984 | 0.4646 | 0.7468 | 0.3420 | |
| 7 | PSNR | 8.99 | 9.73 | 13.05 | 11.33 | 13.97 | 13.44 | 14.43 | 19.11 | 17.43 | 20.01 |
| SSIM | 0.2775 | 0.3197 | 0.5285 | 0.3884 | 0.5272 | 0.6025 | 0.5920 | 0.6322 | 0.6590 | 0.7185 | |
| MSE | 9.7561 | 8.5102 | 3.5799 | 5.1834 | 3.0144 | 3.4888 | 2.8472 | 1.1833 | 1.6848 | 1.1682 | |
| I | PSNR | 16.53 | 14.13 | 21.98 | 20.70 | 23.67 | 24.06 | 25.95 | 25.57 | 29.72 | 33.00 |
| SSIM | 0.7640 | 0.5591 | 0.8495 | 0.7374 | 0.8339 | 0.8847 | 0.9149 | 0.8934 | 0.9069 | 0.9247 | |
| MSE | 1.6850 | 2.9865 | 0.5588 | 0.7715 | 0.3316 | 0.3295 | 0.1998 | 0.1856 | 0.0769 | 0.0353 | |
| IA | PSNR | 16.72 | 14.37 | 22.14 | 21.22 | 23.74 | 24.16 | 26.03 | 25.63 | 29.90 | 32.89 |
| SSIM | 0.7747 | 0.5804 | 0.8554 | 0.7532 | 0.8405 | 0.8884 | 0.9197 | 0.8964 | 0.9106 | 0.9257 | |
| MSE | 1.6099 | 2.9442 | 0.4847 | 0.6348 | 0.3161 | 0.3140 | 0.1940 | 0.1836 | 0.0740 | 0.0360 | |
| IB | PSNR | 16.44 | 14.53 | 21.95 | 21.10 | 23.29 | 23.41 | 25.75 | 25.59 | 29.78 | 32.76 |
| SSIM | 0.7661 | 0.5998 | 0.8448 | 0.7479 | 0.8260 | 0.8770 | 0.9109 | 0.8951 | 0.9060 | 0.9231 | |
| MSE | 1.7255 | 2.8851 | 0.5305 | 0.6578 | 0.3587 | 0.3832 | 0.2074 | 0.1842 | 0.0768 | 0.0372 | |
| II | PSNR | 15.55 | 15.29 | 21.01 | 21.06 | 21.81 | 22.78 | 24.90 | 25.58 | 29.29 | 32.70 |
| SSIM | 0.7384 | 0.6763 | 0.8216 | 0.7494 | 0.7978 | 0.8657 | 0.8992 | 0.8957 | 0.9015 | 0.9227 | |
| MSE | 2.1428 | 2.5699 | 0.7549 | 0.6544 | 0.5353 | 0.4471 | 0.2567 | 0.1843 | 0.0888 | 0.0380 | |
| III | PSNR | 13.67 | 14.92 | 18.2 | 19.43 | 19.84 | 20.13 | 22.64 | 25.46 | 27.44 | 31.91 |
| SSIM | 0.6639 | 0.7035 | 0.776 | 0.7220 | 0.7578 | 0.8345 | 0.8681 | 0.8906 | 0.8869 | 0.9186 | |
| MSE | 3.3143 | 2.5748 | 1.4835 | 1.0180 | 0.9028 | 0.8556 | 0.4515 | 0.1908 | 0.1392 | 0.0461 |
| Methods | |||
|---|---|---|---|
| UDCP | 11.51 | 0.5212 | 5.1332 |
| IBLA | 15.81 | 0.6651 | 2.8412 |
| Shallow-UWnet | 17.79 | 0.7403 | 1.6002 |
| UResnet | 18.32 | 0.7175 | 1.1126 |
| Chen et al. | 21.32 | 0.8260 | 0.6588 |
| WaterNet | 20.88 | 0.8418 | 0.7840 |
| Deep-WaveNet | 22.34 | 0.8656 | 0.7030 |
| UGAN | 20.43 | 0.8255 | 0.6836 |
| Ma et al. | 20.04 | 0.8305 | 0.8495 |
| Ours | 24.18 | 0.8729 | 0.4054 |
| Methods | |||||
|---|---|---|---|---|---|
| UDCP | 5.3511 | 3.8881 | 0.0472 | 1.4679 | 0.5364 |
| IBLA | 5.8522 | 4.3957 | 0.1627 | 2.0448 | 0.5685 |
| Shallow-UWnet | 2.0769 | 4.2078 | 0.2842 | 2.3172 | 0.4677 |
| UResnet | 6.7992 | 6.4352 | 0.1976 | 2.7986 | 0.5974 |
| Chen et al. | 4.5519 | 5.3269 | 0.2821 | 2.7099 | 0.5466 |
| WaterNet | 4.1166 | 5.2974 | 0.2620 | 2.6172 | 0.5698 |
| Deep-WaveNet | 4.2254 | 5.1885 | 0.2499 | 2.5450 | 0.5729 |
| UGAN | 5.4232 | 6.0859 | 0.2591 | 2.8766 | 0.6037 |
| Ma et al. | 3.8633 | 5.2574 | 0.2851 | 2.6809 | 0.5473 |
| Ours | 5.1320 | 5.5205 | 0.2678 | 2.7326 | 0.5827 |
| Methods | w/o WDLB | w/o TCSLB | w/o DARDM | Full Model |
|---|---|---|---|---|
| PSNR | 21.39 | 23.40 | 22.89 | 24.18 |
| SSIM | 0.8434 | 0.8573 | 0.8584 | 0.8729 |
| MSE | 0.6466 | 0.4501 | 0.5006 | 0.4054 |
| Methods | Summation | Concatenate | DASFM |
|---|---|---|---|
| PSNR | 23.25 | 23.95 | 24.18 |
| SSIM | 0.8688 | 0.8710 | 0.8729 |
| MSE | 0.4446 | 0.3934 | 0.4054 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, K.; Tian, Y. DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement. Remote Sens. 2023, 15, 1195. https://doi.org/10.3390/rs15051195
Sun K, Tian Y. DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement. Remote Sensing. 2023; 15(5):1195. https://doi.org/10.3390/rs15051195
Chicago/Turabian StyleSun, Kaichuan, and Yubo Tian. 2023. "DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement" Remote Sensing 15, no. 5: 1195. https://doi.org/10.3390/rs15051195
APA StyleSun, K., & Tian, Y. (2023). DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement. Remote Sensing, 15(5), 1195. https://doi.org/10.3390/rs15051195