
Weakly Supervised Semantic Segmentation in Aerial Imagery via Cross-Image Semantic Mining

 , ,
, ,
Abstract
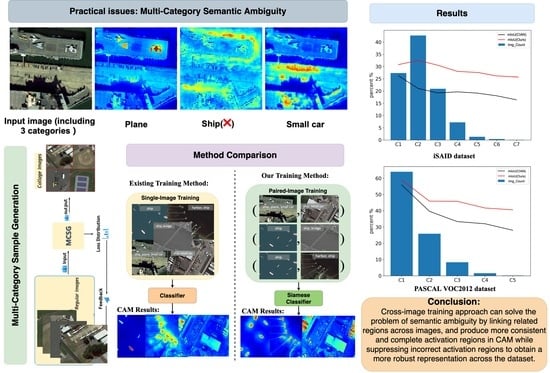
1. Introduction
- We propose CISM as the first RS cross-image semantic mining WSSS framework to explore more object regions and complete semantics in multi-category RS scenes with two novel loss functions: the common semantic mining loss and the non-common semantic contrastive loss, obtaining cutting-edge state-of-the-art results on the iSAID dataset by only using image-level labels.
- To capture cross-image semantic similarities and differences between categories, including the background, the prototype vectors based on class-specific feature maps and the PIE module are proposed, which are beneficial to enhance the feature representation and improve the target localization performance by 4.5% and 2.1% on the mIoU and OA, respectively.
- To avoid class confusion and the unnecessary activation of closely related backgrounds, we propose integrating the SLSC task and its corresponding novel loss into our framework, which forces the network to acquire knowledge from additional object parts while suppressing false activation regions. Ultimately, SLSC improved the model performance by 1.3% and 1.5% on the mIoU and OA, respectively.
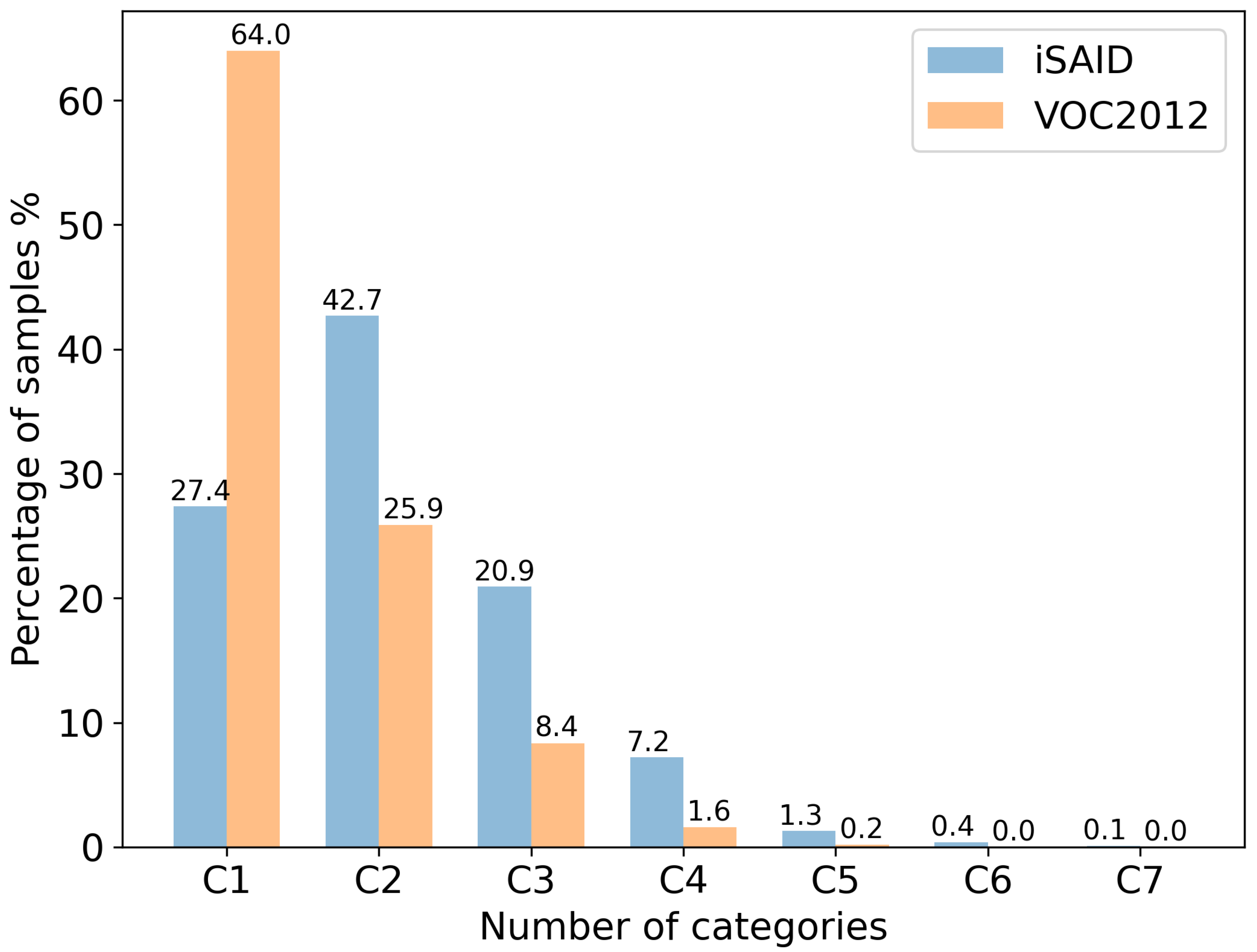
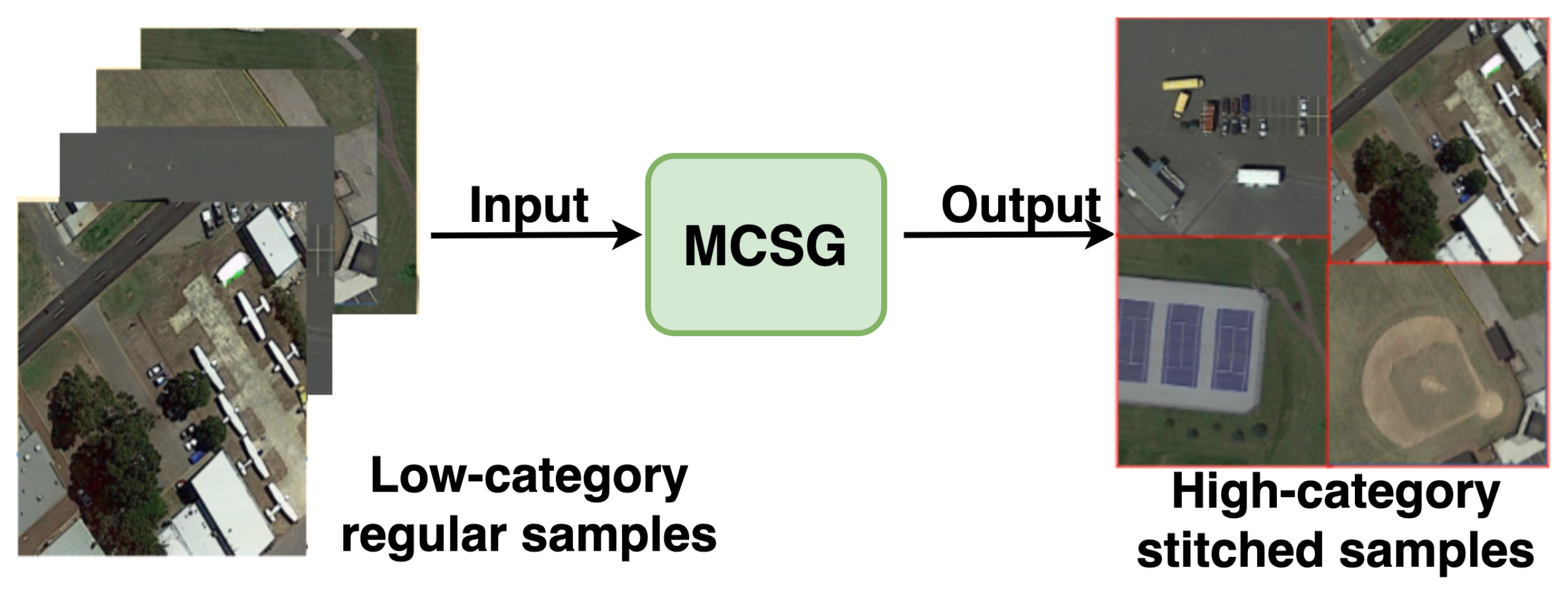
- The multi-category sample generation strategy is proposed to obtain a large number of multi-category samples by randomly stitching most of the low-category samples, which balances the distribution of samples across different categories and improved the model performance by 1.9% and 2.5% on the mIoU and OA, respectively.
2. Related Works
2.1. Semantic Segmentation in Remote Sensing Scenes
2.2. Weakly Supervised Semantic Segmentation
3. Methodology
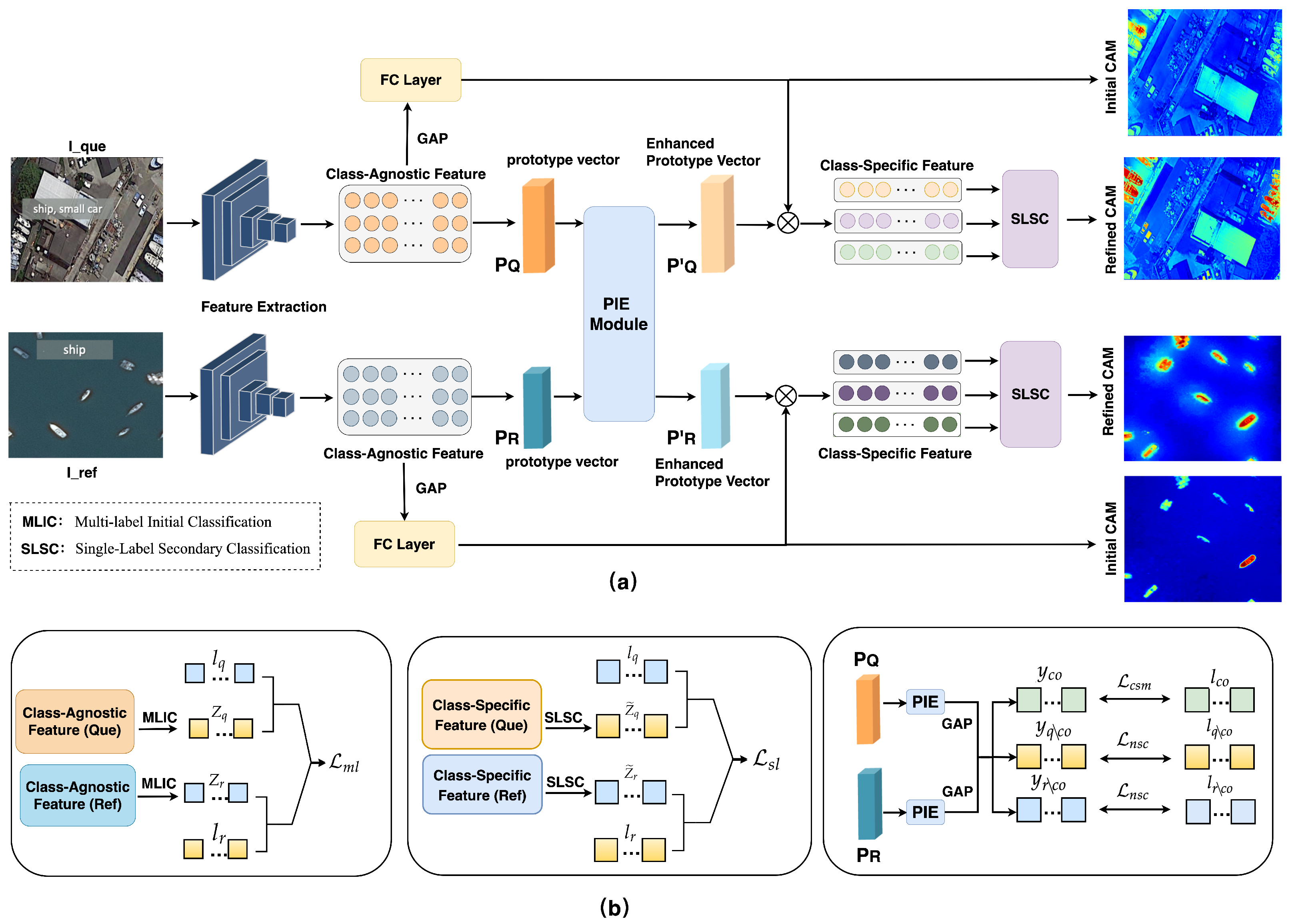
3.1. Cross-Image Semantic Mining Network
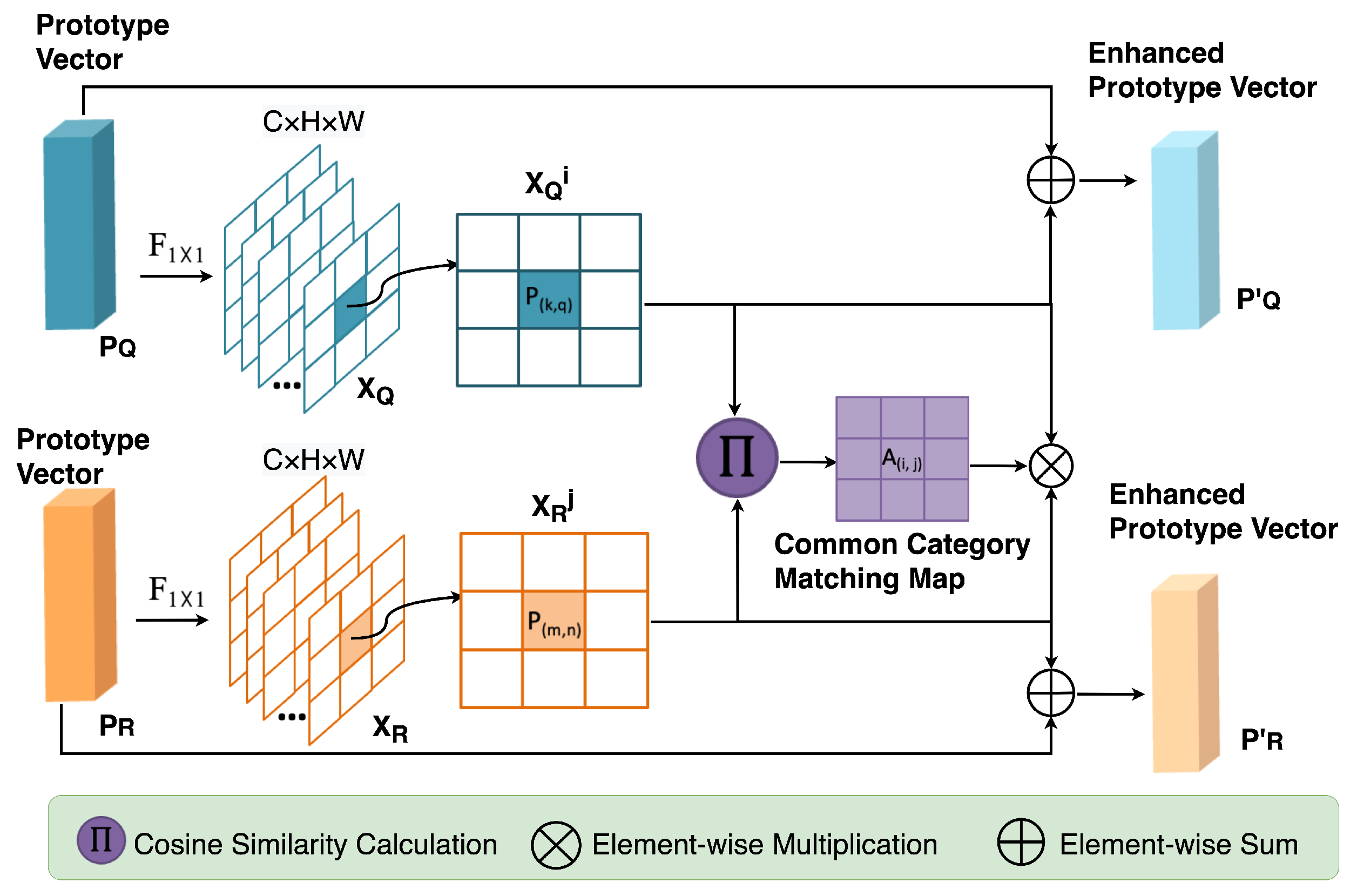
3.1.1. Prototype Vector Generation
3.1.2. Prototype Interactive Enhancement
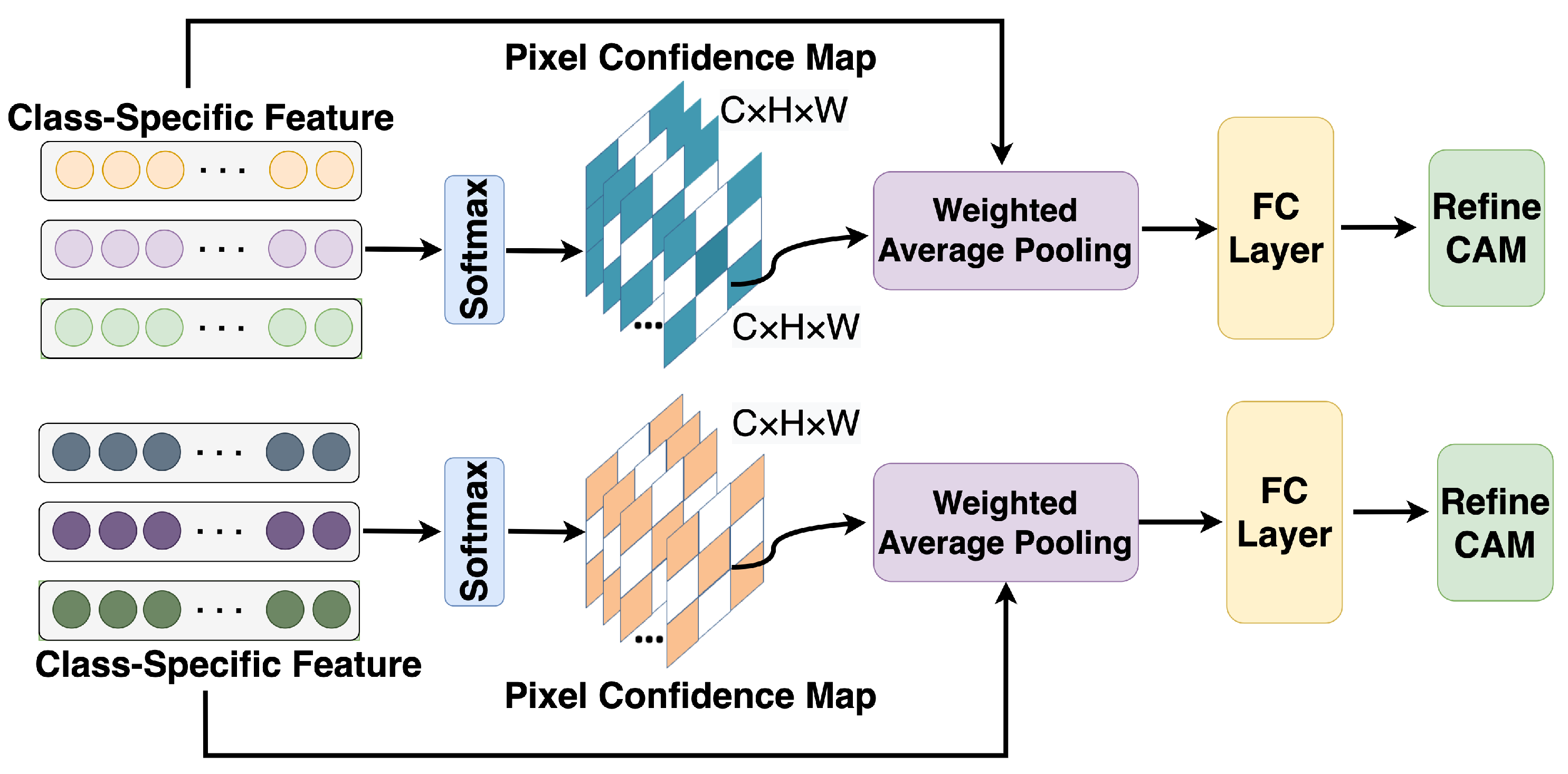
3.2. Revisiting the CAM Generation
3.2.1. Multi-Label Initial Classification
3.2.2. Single-Label Secondary Classification
3.3. Multi-Category Sample Generation
- -
- First, we randomly selected images from the and groups to form a batch denoted as according to the ratio , where b is the size of the batch size (), and the ratio .
- -
- Second, four images were randomly selected from the . denotes the randomly selected operation.
- -
- Third, the selected images were stitched into a new image according to random scaling, cropping, and random arrangement. In particular, the new image was the same size as the maximum size of the selected images.
3.4. Network Training Loss
3.4.1. Multi-Label Initial Classification
3.4.2. Single-Label Secondary Classification
3.4.3. Common Semantic Mining Loss
3.4.4. Non-Common Semantic Contrastive Loss
4. Experimental Results and Discussion
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Results
4.3.1. iSAID Dataset
- Comparison with weak supervision methods: For the purposes of comparing the performance with other WSSS methods, we selected several recent competitive NS methods to participate in this comparison. According to Table 1, for the performance comparison, we achieved state-of-the-art performances on the iSAID dataset without any additional training information. In comparison with the baseline method [39], our method improved the mIoU by 10.2%, which is a promising development in the field of WSSS. Notice that there are some very low values in Table 1, such as for SVs, HAs, HCs, etc. They have in common that they belong to hard samples, where the distribution of SVs is dense and the target scale is small, the target scale of HAs is highly variable, and the sample size of HCs is sparse. These hard samples are not conducive to network learning and are difficult to find in complex remote sensing scenes. The above experimental results demonstrated the advantage of leveraging cross-image relationships, which enables the implementation of image-level WSSS in the RS field.
- Comparison with other supervised methods: To more intuitively compare the performance of the models under different supervision types, we compared four types of supervision methods and list their differences in Table 2, where indicates full supervision, denotes semi-supervision, and denote the bounding box supervision and image-level supervision, respectively. Our CISM with ResNet50 achieved an mIoU of 34.1% on the iSAID dataset, outperforming all previous results only with image-level labels. However, compared to fully supervised and semi-supervised methods, our method had a large performance gap. The main reason is that the image-level supervision only provides information on target categories, while information on the number and location of targets is completely absent. Therefore, the bounding box supervision methods are proposed, which provide information on the categories and locations of all objects in the form of bounding boxes. Notably, our model was comparable to some bounding box works, such as [6,55,56], which were equal to 66.5% of the performance of the weakly supervised method [55] based on the bounding boxes. All the above experimental results demonstrated the advantage of leveraging cross-image relationships, which enables the implementation of image-level WSSS in the RS field.
- Analyses of the visualization:Figure 7 illustrates the comparison between our method and the baseline method in terms of qualitative segmentation results on iSAID. From the first two rows, the CISM model can produce segmentation results with more explicit boundaries and more regular shapes, as well as significantly reducing misclassified pixels. The results in the middle two rows show that our method is able to reduce false positive predictions in the background to some extent, as they are never matched in any of the reference images. From the last two rows, we show that our CISM model can accurately recognize and locate objects in multi-category RS scenes. This is because our CISM builds a more robust representation across the dataset with the help of cross-image semantic information, and the related representations can be strengthened by each other, thus achieving more accurate semantic localization and segmentation. This is because our CISM constructs a more robust representation across the dataset using cross-image semantic information, and the related representations can be strengthened by each other, resulting in more accurate semantic localization and segmentation.
4.3.2. PASCAL VOC2012 Dataset
- Comparison with SOTA methods: According to Table 3, our method produces better results than the baseline (CIAN) in both validation and testing and outperforms all of the previous results without any additional supervision. Based on the PASCAL VOC2012 validation set, our CISM achieved a 67.3% mIoU with ResNet-101. Furthermore, on the test set, we achieved a 68.5% mIoU and generated high-quality pseudo-masks. To be fair, the CISM model was also evaluated on various backbone networks and is marked with different combinations of the symbols * and †. Excluding the method that employs additional supervision, as a result of our model, all types of backbones achieved new state-of-the-art performance, with specific types including ResNet-38, ResNet-50, and ResNet-101, which demonstrates the effectiveness of cross-image semantic mining.
4.4. Ablation Experiments
4.4.1. Effectiveness of Prototype Vector
- Analyses of the visualization: In order to illustrate the impact of the prototype vector and PIE module in an intuitive manner, the CAM visualization results are presented in Figure 8. Given a picture that includes some targets, the baseline can only have a rough estimate of the local discriminatory regions of the targets at first. Following the addition of the prototype vector and PIE module, there was a substantial improvement in the accuracy of target positioning and a strengthening of the CAM activation area, and the pseudo-masks became more complete and clearer. This is because that the prototype vector and PIE module suppress the further propagation of the background and interference information, ensuring that the classifier can learn more useful semantic information and achieve reasonable optimization.
- Selection of hyperparameters: In the process of prototype vector generation, we developed an adjustable variable to assist in discarding certain regions from the CAMs during training, and then, the corresponding location of the initial prototype vector will be masked. Table 5 presents the effect of different hyperparameter settings on CAM quality as measured by the mIoU (%) and OA (%). With the increase of the parameter , the evaluation metrics gradually increased and then decreased, achieving the maximum value at .
4.4.2. Effects of Single-Label Secondary Classification
- Analyses of the visualization: In Figure 9, the CAM visualization results on the iSAID dataset are presented. The baseline network still has limited localization capability in multi-category RS scenes and is prone to produce incomplete activation areas. Compared to the baseline, the RPNet [39] found more activated regions by correlations between prototype vectors. However, the granularity of the CAM generated by the RPNet was still insufficient, hence limiting the quality of subsequent pseudo-label generation. Our CISM extracts prototype vectors from high-confidence regions while filtering out interference regions in the background and confusion regions between different categories, hence enhancing the representation of features. As can be seen in the last column of Figure 9, the addition of the SLSC improved the fine-grainedness of the CAMs and further refined the activation area in the CAMs.
4.4.3. Effects of Multi-Category Sample Generation
4.4.4. Impact of Loss Functions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| WSSS | Weakly Supervised Semantic Segmentation |
| FSSS | Fully Supervised Semantic Segmentation |
| SLSC | Single-Label Secondary Classification |
| CISM | Cross-Image Semantic Mining |
| CAM | Class Activation Maps |
| CSM | Common Semantic Mining |
| NSC | Non-common Semantic Contrastive |
| PIE | Prototype Interactive Enhancement |
| MCSG | Multi-Category Sample Generation |
| RS | Remote Sensing |
| NS | Natural Scene |
References
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Pu, M.; Huang, Y.; Guan, Q.; Qi, Z. Graphnet: Learning image pseudo annotations for weakly supervised semantic segmentation. In Proceedings of the 2018 ACM Multimedia Conference, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2953–2961. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3136–3145. [Google Scholar]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly and semi-supervised learning of a deep convolutional network for semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016. [Google Scholar]
- Hsu, C.-C.; Hsu, K.-J.; Tsai, C.-C.; Lin, Y.-Y.; Chuang, Y.-Y. Weakly supervised instance segmentation using the bounding box tightness prior. Adv. Neural Inf. Process. Syst. 2019, 32, 6586–6597. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, expand and constrain: Three principles for weakly supervised image segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 695–711. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Jie, Z.; Xiao, Y.; Zhao, Y.; Yan, S. Learning to segment with image-level annotations. Pattern Recognit. 2016, 59, 234–244. [Google Scholar] [CrossRef]
- Jiang, P.-T.; Hou, Q.; Cao, Y.; Cheng, M.-M.; Wei, Y.; Xiong, H.-K. Integral object mining via online attention accumulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2070–2079. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2921–2929. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Shen, X.; Cheng, M.-M.; Feng, J.; Zhao, Y.; Yan, S. Stc: A simple to complex framework for weakly supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2314–2320. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation with Inter-Pixel Relations; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, J.; Zhang, J.; Hong, Y.; Barnes, N. Learning structure-aware semantic segmentation with image-level supervision. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.-S.; Bai, X. Isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 28–37. [Google Scholar]
- Everingham, M. The PASCAL Visual Object Classes Challenge. 2007. Available online: http://www.PASCAL-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 7 June 2007).
- Souly, N.; Spampinato, C.; Shah, M. Semi supervised semantic segmentation using generative adversarial network. In Proceedings of the IEEE International Conference On Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5688–5696. [Google Scholar]
- Hung, W.-C.; Tsai, Y.-H.; Liou, Y.-T.; Lin, Y.-Y.; Yang, M.-H. Adversarial learning for semi-supervised semantic segmentation. arXiv 2018, arXiv:1802.07934. [Google Scholar]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. Bas4net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Liao, C.; Shan, B.; Zhou, X. Classhyper: Classmix-based hybrid perturbations for deep semi-supervised semantic segmentation of remote sensing imagery. Remote. Sens. 2022, 14, 879. [Google Scholar] [CrossRef]
- Grozavu, N.; Rogovschi, N.; Cabanes, G.; Troya-Galvis, A.; Gançarski, P. Vhr satellite image segmentation based on topological unsupervised learning. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; IEEE: New York, NY, USA, 2015; pp. 543–546. [Google Scholar]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-supervised vision transformers for land-cover segmentation and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1422–1431. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 549–565. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Amsterdam, The Netherlands, 11–14 October 2016; pp. 3159–3167. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, S.T. Revisiting dilated convolution: A simple approach for weakly and semi-supervised semantic segmentation. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA; 2018; pp. 7268–7277. [Google Scholar]
- Chang, Y.T.; Wang, Q.; Hung, W.C.; Piramuthu, R.; Tsai, Y.H.; Yang, M.H. Weakly supervised semantic segmentation via sub-category exploration. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8988–8997. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5267–5276. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3917–3926. [Google Scholar]
- Hou, Q.; Cheng, M.-M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Hong, S.; Yeo, D.; Kwak, S.; Lee, H.; Han, B. Weakly supervised semantic segmentation using web-crawled videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7322–7330. [Google Scholar]
- Shen, T.; Lin, G.; Shen, C.; Reid, I. Bootstrapping the performance of webly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1363–1371. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Frame-to-frame aggregation of active regions in web videos for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6808–6818. [Google Scholar]
- Tokmakov, P.; Alahari, K.; Schmid, C. Weakly supervised semantic segmentation using motion cues. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 388–404. [Google Scholar]
- Fan, J.; Zhang, Z.; Tan, T.; Song, C.; Xiao, J. Cian: Cross-image affinity net for weakly supervised semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10762–10769. [Google Scholar]
- Sun, G.; Wang, W.; Dai, J.; Gool, L.V. Mining cross-image semantics for weakly supervised semantic segmentation. In Proceedings of the 16th European Conference on Computer Visione CCV, Online, 23–28 August 2020; pp. 347–365. [Google Scholar]
- Liu, W.; Kong, X.; Hung, T.-Y.; Lin, G. Cross-image region mining with region prototypical network for weakly supervised segmentation. IEEE Trans. Multimed. 2021, 1. [Google Scholar] [CrossRef]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. Wsf-net: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote. Sens. 2018, 10, 1970. [Google Scholar] [CrossRef]
- Chen, J.; He, F.; Zhang, Y.; Sun, G.; Deng, M. Spmf-net: Weakly supervised building segmentation by combining superpixel pooling and multi-scale feature fusion. Remote. Sens. 2020, 12, 1049. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Zhang, X.; Wei, Y.; Yang, Y.; Huang, T.S. Sg-one: Similarity guidance network for one-shot semantic segmentation. IEEE Trans. Cybern. 2020, 50, 3855–3865. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, T.; Wu, X.; Hua, X.-S.; Zhang, H.; Sun, Q. Class re-activation maps for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 969–978. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Yuan, Z.; Zhang, W.; Tian, C.; Mao, Y.; Zhou, R.; Wang, H.; Fu, K.; Sun, X. Mcrn: A multi-source cross-modal retrieval network for remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103071. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Li, C.; Pan, Z.; Mao, Y.; Chen, J.; Li, S.; Wang, H.; Sun, X. Learning to evaluate performance of multi-modal semantic localization. arXiv 2022, arXiv:2209.06515. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; Computer Vision Foundation: New York, NY, USA, 2016. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21-26 July 2017; pp. 876–885. [Google Scholar]
- Guo, R.; Sun, X.; Chen, K.; Zhou, X.; Yan, Z.; Diao, W.; Yan, M. Jmlnet: Joint multi-label learning network for weakly supervised semantic segmentation in aerial images. Remote. Sens. 2020, 12, 3169. [Google Scholar] [CrossRef]
- Zhang, B.; Xiao, J.; Jiao, J.; Wei, Y.; Zhao, Y. Affinity attention graph neural network for weakly supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8082–8096. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.; Huang, J.; Gao, G.; Wei, X.; Wei, X.; Luo, X.; Liu, C.H. Embedded discriminative attention mechanism for weakly supervised semantic segmentation. In Proceedings of the 2021 Conference on Computer Vision and Pattern Recognition CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 16765–16774. [Google Scholar]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In Proceedings of the 2021 Conference on Computer Vision and Pattern Recognition CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 5495–5505. [Google Scholar]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1354–1362. [Google Scholar]
- Chaudhry, A.; Dokania, P.K.; Torr, P.H. Discovering class-specific pixels for weakly supervised semantic segmentation. arXiv 2017, arXiv:1707.05821. [Google Scholar]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly supervised semantic segmentation network with deep seeded region growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7014–7023. [Google Scholar]
- Hou, Q.; Jiang, P.-T.; Wei, Y.; Cheng, M.-M. Self-erasing network for integral object attention. arXiv 2018, arXiv:1810.09821. [Google Scholar]
- Fan, R.; Hou, Q.; Cheng, M.-M.; Yu, G.; Martin, R.R.; Hu, S.-M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BG | GTF | SBF | SV | SH | BR | BC | BD | RA | PL | TC | LV | ST | HA | SP | HC | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AffinityNet [17] | 77.8 | 14.7 | 43.7 | 3.7 | 5.8 | 6.3 | 18.8 | 20.4 | 9.8 | 7.5 | 54.3 | 23.8 | 42.4 | 3.9 | 1.8 | 1.0 | 20.9 |
| IRNet [16] | 78.6 | 18.9 | 39.8 | 6.7 | 16.6 | 7.5 | 24.5 | 16.4 | 5.7 | 15.7 | 54.9 | 29.0 | 29.6 | 9.8 | 2.7 | 3.1 | 22.5 |
| CIAN [39] | 78.3 | 21.9 | 40.8 | 8.9 | 17.5 | 8.3 | 28.4 | 22.7 | 13.5 | 18.1 | 47.5 | 27.6 | 30.2 | 8.5 | 4.2 | 5.3 | 23.9 |
| SEAM [18] | 73.2 | 28.4 | 37.8 | 4.7 | 15.3 | 6.9 | 43.1 | 31.4 | 16.7 | 19.6 | 44.3 | 31.1 | 24.4 | 7.8 | 9.8 | 8.3 | 24.5 |
| SC-CAM [31] | 76.2 | 28.6 | 36.1 | 11.1 | 20.0 | 5.7 | 23.1 | 36.9 | 23.2 | 24.8 | 54.3 | 30.1 | 29.8 | 10.3 | 17.3 | 11.9 | 26.6 |
| RPNet [41] | 80.2 | 33.6 | 42.1 | 9.8 | 16.9 | 7.2 | 45.2 | 32.6 | 26.1 | 27.6 | 51.5 | 29.4 | 42.7 | 9.3 | 16.8 | 13.7 | 30.3 |
| CISM (ours) | 83.1 | 35.5 | 44.6 | 11.8 | 19.5 | 8.4 | 48.3 | 34.4 | 29.2 | 30.5 | 52.6 | 31.9 | 44.1 | 10.8 | 17.6 | 14.3 | 32.2 |
| Supervision Type | Model | Backbone | mIoU (%) |
|---|---|---|---|
| DeepLab v3 [54] | ResNet50 | 59.1 | |
| SDI [55] | VGG16 | 54.9 | |
| Song [6] | VGG16 | 55.2 | |
| JMLNet [56] | ResNet50 | 56.8 | |
| (B) | SDI [55] | VGG16 | 53.8 |
| Song [6] | VGG16 | 54.2 | |
| JMLNet [56] | ResNet50 | 55.3 | |
| (I) | CIAN [39] | ResNet50 | 23.9 |
| SC-CAM [31] | ResNet50 | 26.6 | |
| RPNet [41] | ResNet50 | 30.3 | |
| CISM (ours) | ResNet50 | 35.8 |
| Methods | Backbone | Sup. | Val | Test |
|---|---|---|---|---|
| AFFNet [17] | R-38 | L | 61.7 | 63.7 |
| SEAM [18] | R-38 | L | 64.5 | 65.7 |
| A2GNN [57] | R-38 | L | 66.8 | 67.4 |
| EDAM [58] | R-38 | L + S | 70.9 | 70.6 |
| EPS [59] | R-38 | L + S | 70.9 | 70.8 |
| CIAN [39] | R-50 | L | 62.4 | 63.8 |
| IRNet [16] | R-50 | L | 63.5 | 64.8 |
| RPNet [41] | R-50 | L | 66.4 | 67.2 |
| MCOF [60] | R-101 | L | 60.3 | 61.2 |
| DCSP [61] | R-101 | L | 60.8 | 61.9 |
| DSRG [62] | R-101 | L | 61.4 | 63.2 |
| SeeNet [63] | R-101 | L + S | 63.1 | 62.8 |
| AISI [64] | R-101 | L + S | 63.6 | 64.5 |
| CIAN [39] | R-101 | L | 64.1 | 64.7 |
| FickleNet [32] | R-101 | L + S | 64.9 | 65.3 |
| SC-CAM [31] | R-101 | L | 66.1 | 65.9 |
| RPNet [39] | R-101 | L | 66.9 | 68.0 |
| Ours: | ||||
| CISM (†) | R-38 | L | 64.4 | 66.8 |
| CISM († *) | R-50 | L | 66.8 | 67.6 |
| CISM († **) | R-101 | L | 67.3 | 68.5 |
| Baseline | +PV | +PIE | mIoU (%) | OA (%) |
|---|---|---|---|---|
| ✓ | 23.9 | 77.2 | ||
| ✓ | ✓ | 24.6 | 73.5 | |
| ✓ | ✓ | ✓ | 28.4 | 79.3 |
| mIoU (%) | OA (%) | |
|---|---|---|
| 0.1 | 28.9 | 80.6 |
| 0.3 | 32.2 | 82.4 |
| 0.5 | 27.4 | 80.1 |
| 0.7 | 25.8 | 79.2 |
| Baseline | +SLSC | mIoU (%) | OA (%) |
|---|---|---|---|
| ✓ | 23.9 | 77.2 | |
| ✓ | ✓ | 27.7 | 80.5 |
| RPNet | +SLSC | mIoU(%) | OA(%) |
| ✓ | 30.3 | 80.8 | |
| ✓ | ✓ | 32.6 | 82.7 |
| CISM (ours) | +SLSC | mIoU (%) | OA (%) |
| ✓ | 32.2 | 82.4 | |
| ✓ | ✓ | 33.5 | 83.9 |
| Method | mIoU (%) | OA (%) |
|---|---|---|
| Baseline | 23.9 | 77.2 |
| Baseline + MCSG | 25.3 | 79.5 |
| CISM | 32.2 | 82.4 |
| CISM + MCSG | 34.1 | 84.9 |
| mIoU (%) | ||||
|---|---|---|---|---|
| ✓ | 23.9 | |||
| ✓ | ✓ | 26.7 | ||
| ✓ | ✓ | ✓ | 20.3 | |
| ✓ | ✓ | ✓ | 29.8 | |
| ✓ | ✓ | ✓ | ✓ | 34.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, R.; Yuan, Z.; Rong, X.; Ma, W.; Sun, X.; Fu, K.; Zhang, W. Weakly Supervised Semantic Segmentation in Aerial Imagery via Cross-Image Semantic Mining. Remote Sens. 2023, 15, 986. https://doi.org/10.3390/rs15040986
Zhou R, Yuan Z, Rong X, Ma W, Sun X, Fu K, Zhang W. Weakly Supervised Semantic Segmentation in Aerial Imagery via Cross-Image Semantic Mining. Remote Sensing. 2023; 15(4):986. https://doi.org/10.3390/rs15040986
Chicago/Turabian StyleZhou, Ruixue, Zhiqiang Yuan, Xuee Rong, Weicong Ma, Xian Sun, Kun Fu, and Wenkai Zhang. 2023. "Weakly Supervised Semantic Segmentation in Aerial Imagery via Cross-Image Semantic Mining" Remote Sensing 15, no. 4: 986. https://doi.org/10.3390/rs15040986
APA StyleZhou, R., Yuan, Z., Rong, X., Ma, W., Sun, X., Fu, K., & Zhang, W. (2023). Weakly Supervised Semantic Segmentation in Aerial Imagery via Cross-Image Semantic Mining. Remote Sensing, 15(4), 986. https://doi.org/10.3390/rs15040986