1. Introduction
Hyperspectral images (HSIs) can give comprehensive spectral and geographical information, which are commonly employed in astronomy, the military, and agriculture [
1,
2,
3,
4,
5]. HSI classification is the critical and common technique in these applications. It is designed to use the spectral and spatial information of HSIs to identify surface objects on earth [
6,
7]. Luo et al. [
8] realized the complementation of different features by taking into account the neighborhood, tangential, and statistical distribution of each sample under different features. In addition, an embedded objective function was constructed to effectively complete feature reduction and HSI classification. Classical machine learning [
9,
10,
11] is used for HSI classification. The impressive classification performance of supervised learning methods generally requires the support of abundant labeled samples [
12]. However, it is difficult for researchers to obtain accurate HSI labels [
13]. Thus, how to accurately classify HSIs using a few labels is a hot topic in remote sensing [
14]. Active learning and semi-supervised learning provide a viable solution. Active learning can actively select samples with the largest amount of information from unlabeled samples, and manually label them to increase the amount of training samples [
15]. Semi-supervised learning can complete HSI classification with limited labeled samples and a large amount of unlabeled samples [
16]. Luo et al. [
17] proposed a novel sparse adaptive hypergraph discriminant analysis method, which reveals the structure relationship of HSIs using sparse representation to obtain the discriminative embedded features of HSIs. Zhang et al. [
18] proposed a semisupervised classification method based on simple linear iterative cluster segmentation, which effectively explored the spectral features of HSIs and achieved good classification accuracy.
The above techniques can deal with the issue of insufficient training samples due to labeling difficulty to some extent. However, when the distributions of training and testing sample sets are quite different, it is difficult to achieve satisfactory results with the above methods. Domain adaptation (DA) transfers knowledge from a labeled domain (source domain) to a comparable but not identical domain (target domain) by exploring domain-invariant features [
19,
20]. When the target domain labels are missing or insufficient, DA can exploit similar labeled samples in the source domain to solve the problem of the target domain [
21]. According to whether there is a discrepancy between two domains, DA methods can be mainly summarized to fall into two categories: homogeneous and heterogeneous. For the homogeneous DA methods, the feature spaces of both domains are consistent. Kumar et al. [
22] developed a theory for gradual domain adaptation and reliably adapted the different distributions between domains with the gradual shift structure. Unlike with homogeneous DA, the main difficulty with heterogeneous DA is that the source and target domain data are located in different feature spaces. To address multi-source heterogeneous unsupervised DA problems, Liu et al. [
23] presented a shared-fuzzy-equivalence-relation neural network containing multiple source branches and one target branch.
According to the type of learning model, DA methods can be classified as shallow-learning-based or deep-learning-based. At present, there are a large number of domain adaptation methods based on shallow learning. Since the shallow-learning model cannot fit the data distribution well, it will lead to under-fitting and under-matching problems. The deep neural network has a powerful non-linear representation capability, and thus can extract discriminative and compact features of the input [
24,
25]. Given the above advantages, DA methods based on deep neural networks have been extensively studied by researchers [
26]. Long et al. [
27] proposed a deep adaptation network (DAN) to reduce the marginal distribution discrepancy between domains by embedding multiple-kernel maximum mean discrepancy (MK-MMD) into CNNs, which generalized CNNs to the domain adaptation scenario. MMD is one of the most commonly used nonparametric methods to measure the distribution discrepancy across domains. For MMD, kernel selection is very important for ensuring effectiveness. In view of this, Liu et al. [
28] proposed a class of non-parametric two-sample tests for learning deep kernels. To detect the discrepancy between natural and adversarial data, Gao et al. [
29] further designed a simple and effective semantic-aware MMD based on the two-sample tests. Ganin and Lempitsky [
30] applied the adversarial idea to domain adaptation and proposed a domain-adversarial neural network (DANN). Ma et al. [
31] proposed a deep domain adaptation network containing three modules: domain alignment module, task allocation module, and domain adaptation module, which successfully achieved the cross-domain classification of HSIs. Wang et al. [
32] added a weighted maximum mean-discrepancy-based term and a manifold regularization term into the objective function of the deep neural network, simultaneously achieving domain adaptation. Deng et al. [
33] introduced metric learning into a deep embedding network, and achieved same-scene and different-scene HSI classifications.
Recently, the novel broad learning system (BLS) [
34] was proposed, which can be viewed as an alternative way of learning in a deep structure. The structure of BLS mainly consists of three parts: the mapped feature (MF) layer for feature mapping of input data, the enhancement node (EN) layer for breadth expansion of the mapping features, and the output layer for solving the weight through ridge regression. Compared with deep learning networks, BLS has the following advantages [
35,
36]: (1) The structure of the BLS is simple and flexible, and it is easy to integrate with other models; (2) because of EN, BLS is able to achieve feature breadth expansion to enhance the capability of feature representation. Wang et al. [
37] fused graph convolution operation and BLS as a unified framework, fully utilizing the flexibility and feature breadth expansion ability of BLS to achieve efficient HSI classification. Guo et al. [
38] made full use of the fast training-speed of BLS to pre-train multiple groups of classification models, and then built a dynamic integration structure with multiple classifier groups to determine the class of vehicles. Kong et al. [
39] extended the multi-level depth feature using BLS to obtain multi-level features, and introduced block diagonal constraints to enhance the independence between multi-level features. The above model has achieved good results in HSI classification. Feng and Chen [
40] achieved good performance in regression and classification tasks by organically combining a Takagi–Sugeno fuzzy system with BLS.
Due to the high label cost of HSIs, HSIs (target domain) are often lacking or even without labels in actual scenes. In order to classify the HSIs of the target domain in this scenario, transfer learning can use the source domain with rich labels to help the target domain complete the classification task. However, due to the differences in equipment, environment and spatial area during the acquisition of different HSIs, there are often large differences in the distribution of the two domains, which causes susceptibility to the phenomenon of difficult knowledge transfer between the two domains. The above problems are difficult to solve with common transfer-learning-based methods because they have the following limitations:
- (1)
Common transfer learning methods often only consider aligning the two domain distributions by minimizing the difference between the first or second order statistics of the two domains, with which it is difficult to achieve comprehensive adaptation to the two domain distributions;
- (2)
Common transfer learning methods often ignore the difference in conditional distribution between the two domains, which easily leads to confusion of the two domains’ discriminant features, and hinders the improvement of the model’s classification performance;
- (3)
Due to the difference between the two HSIs in spatial areas during acquisition, the distribution of their class prior may not be consistent. This phenomenon may lead to insufficient alignment of class distribution. When the two-domain classes are unbalanced, this phenomenon often causes serious performance damage to the model.
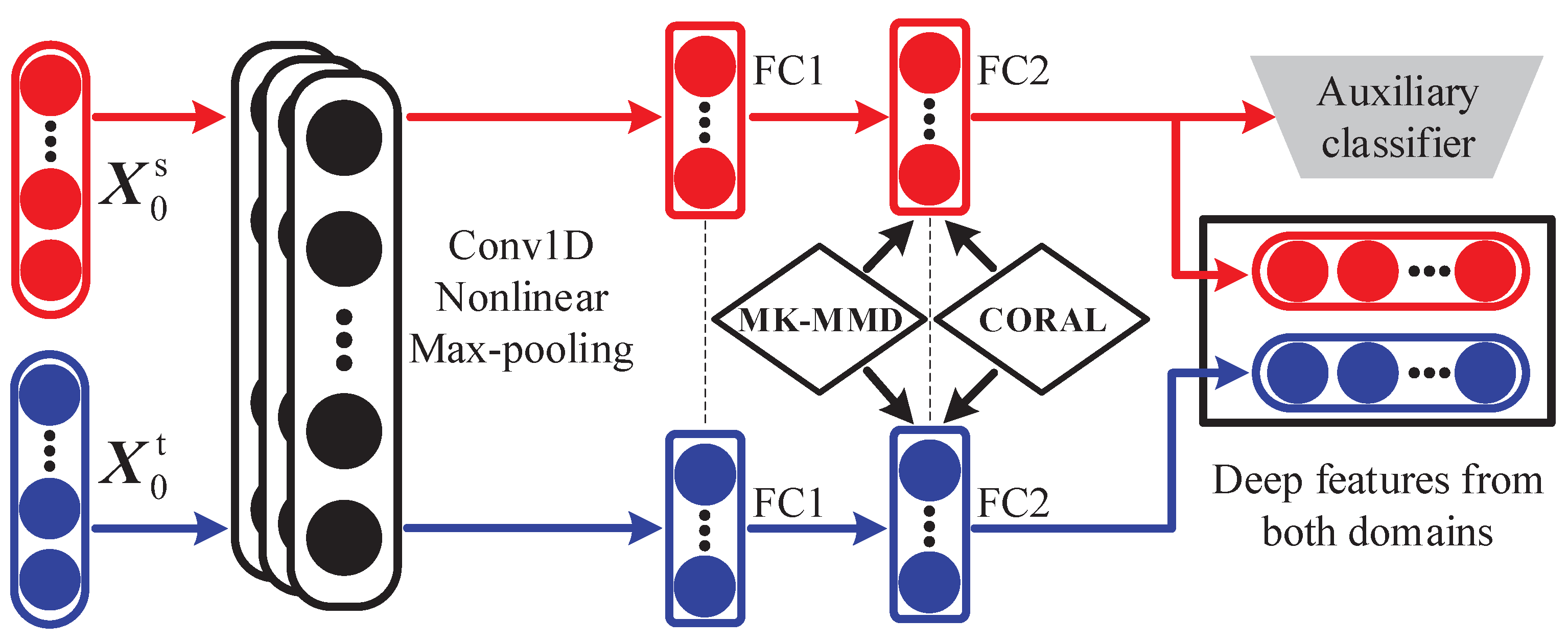
To solve the above problems, we propose CWDAN, which considers the marginal distribution, conditional distribution and class prior distribution of the two domains. Specifically, when aligning the marginal distribution of the two domains, the difference between the first-order statistics and the second-order statistics is minimized through the MMD and CORAL, so as to achieve full alignment of the marginal distribution of the two domains. Then, BLS is used to expand the width of the domain-adaptation features extracted by the ConDAN to further enhance the feature representation ability. In addition, the CWMMD-based domain adaptation term is added to BLS, which reduces the difference between the conditional distributions and class weight bias, so that the model pays more attention to the classes that occupy a higher proportion in the target domain, and thus improves its classification performance in the target domain. The main novel aspects of our work are summarized below:
- (1)
We propose a convolutional domain adaptation network (ConDAN); by simultaneously reducing the two-domain difference between the first- and second-order statistics, sufficient and fast marginal distribution alignment was achieved;
- (2)
We defined a novel class-weighted maximum mean discrepancy (CWMMD) and further imposed the CWMMD-based domain adaptation term in classical BLS. The weight of each class in the domain adaptation is adjusted based on the class prior distribution, and the training is focused on the important classes in the target domain, which solves the problem of class being unbalanced during conditional distribution alignment;
- (3)
Deep learning and broad learning are embedded in a unified framework, and the strong feature extraction ability of deep learning as well as the feature breadth expansion ability of broad learning are fully utilized to achieve the extraction and enhancement of domain-invariant features.
The rest of this paper is organized as follows. The flowchart of CWDAN for HSI classification is presented in
Section 2. The experimental results on eight real HSI data pairs are presented and analyzed, followed by a conclusion in
Section 4.
4. Discussion
The HSI dimension reduction method usually consists of two categories: feature-learning-based and band-selection-based. The feature-learning-based method maps the original data to a low-dimensional subspace for dimension reduction. Common techniques include maximum noise fraction [
49] and principal component analysis [
50]. The band-selection-based method selects bands with large amounts of information according to a certain standard. Common techniques include equal interval band selection [
42] and progressive band selection [
51]. However, the operation of image transformation with the feature-learning-based method makes the transformed data no longer have the original physical attributes, which is not conducive to understanding the original data. Compared with the above method, the advantages of band selection include [
52,
53]: (1) the selected band not only contains useful detailed data information, but also maintains the integrity of its physical attributes; (2) the operation of band selection is relatively simple.
The common methods for alleviating the class distribution misalignment caused by class unbalance are divided into two categories: data-resampling-based [
54,
55] and sample-reweighting-based [
56,
57]. The first method alleviates the class distribution misalignment by oversampling the minority classes or undersampling the majority classes. However, the oversampling of minority classes may easily lead to over-fitting, while the undersampling of majority classes may lead to information loss. The other method alleviates the class distribution misalignment by assigning the corresponding weight to each class in the process of domain adaptation. However, most of the sample reweighting-based methods tend to pay the same attention to each class when designing the weight factor, without considering the relationship between the weight factor and the class prior distribution in the target domain. Considering that the classification task is targeted at the target domain, the proposed method designs the weight factor based on the prior distribution of the target class, and focuses the training of the model on the important classes of the target domain during domain adaptation, which improves the accuracy of the model in the task of cross-domain HSI classification.
The OA of CWDAN in all data pairs is the highest, with a little sacrifice in terms of running time and number of parameters, which is due to the advantages of the proposed method. The advantages of CWDAN are summarized as follows: (1) By simultaneously reducing the two-domain difference between the first and second order statistics, sufficient and fast marginal distribution alignment is achieved; (2) the weight of each class in the domain adaptation is adjusted based on the class prior distribution of the two domains, and the training is focused on the important classes in the target domain, which solves the problem of class unbalanced during the conditional distribution alignment; (3) deep learning and broad learning are embedded in a unified framework, and the strong feature extraction ability of deep learning and the feature breadth expansion ability of broad learning are fully utilized to achieve the extraction and enhancement of domain-invariant features.
The disadvantages of CWDAN are summarized as follows: the model cannot adaptively adjust and , which makes it difficult to adapt to the marginal distribution differences according to importance, thus hindering the further improvement of domain adaptation performance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}