1. Introduction
Forest investment planning requires accurate inventories describing a given stand’s size and product distribution. To achieve this, attributes such as breast height diameter (DBH), tree heights, merchantability, and volume of standing trees are regularly sampled to describe the value of a given stand. However, traditional methods of field-based inventories are often time-consuming and expensive due to the cost of establishing adequate samples capturing the existing variability [
1,
2,
3]. Moreover, the variables collected through field-based inventories are limited within the instrumental range and accessibility of a field crew, and their credibility highly depends on the quality and quantity of the field samples [
4]. Furthermore, studies demanding more comprehensive variables, such as biomass or tree taper studies, require the destructive sampling of a subsequent number of trees. The feasibility of such sampling is extremely limited by capital, organization, labor, and protected areas [
5,
6]. Therefore, over the last two decades, researchers have focused on improving the use of remotely sensed information as auxiliary variables in forest inventories. The advent of inexpensive multispectral satellite data [
7] or the use of hyperspectral imagining, radar, and laser scanning has opened the door to new developments [
8,
9,
10], not only allowing fast and repetitive data collection over a large spatial area but also allowing for a reduction in the inventory cost.
Airborne laser scanning (ALS) is a type of active remote sensing system with its own source of electromagnetic energy that has revolutionized remote sensing technology over the last three decades [
11,
12]. The major highlight of this revolution is its capability to measure the three-dimensional structure of imaged areas directly and to extract bio-spatial data, such as aboveground vegetation-related data, from geospatial information, such as the terrain surface, using laser pulses [
13]. In ALS, a laser scanner is attached to the aerial platform, such as crewed or uncrewed aircraft, which distributes the transmitted pulses across the flight direction, measuring the 3D position of points at the surface with an accuracy of a few decimeters in vegetation canopies [
14]. Lidar (Light Detecting and Ranging) is one of the ALS systems that presents a remarkable performance by offering a high density of points, intensity measurements for the returning signal, multiple echoes per laser pulse, and centimeter accuracy for horizontal and vertical positioning [
15]. Because of such features, a lidar is a valuable tool for forest characterization and monitoring across the landscape [
11,
15,
16,
17,
18].
Two approaches commonly used for forest attribute estimation using three-dimensional lidar point clouds are the Individual tree-based approach [
19,
20] and the area-based approach [
21,
22]. Individual tree-based approaches are applied when single-tree level attributes are required, and high-density lidar data is available. For single-tree level attribute extraction, several automated and semi-automated algorithms, such as the local maximum-based methods [
23,
24], local curvature methods [
25], the watershed methods [
26,
27], and many other methods have been proposed and applied by several researchers in past few years. However, these algorithms are difficult to implement due to the generation of omission and inclusion errors when individualizing trees [
28,
29]. Moreover, joining and overlapping tree crowns can be problematic when identifying individual trees [
30]. Therefore, applying an individual tree-based approach in complex stands such as uneven-aged natural forests and plantations with high stem density is difficult. Area-based approaches (ABA) is another method that is more commonly used in diverse forest biomes for forest attribute estimation and mapping [
31,
32,
33]. In this approach, various plots or grids, level metrics such as mean height, dominant height, the density of 3D point clouds in different height percentiles, skewness, kurtosis, canopy cover, etc., are generated using the echo heights (backscattering of laser beam towards the sensor each time the laser beam is totally or partially intercepted by an object) and intensities (the strength of the laser beam that returned to the sensor) of lidar point cloud data [
18]. Those metrics extracted from point cloud data are then compared with the plot-level data to estimate stand level attributes.
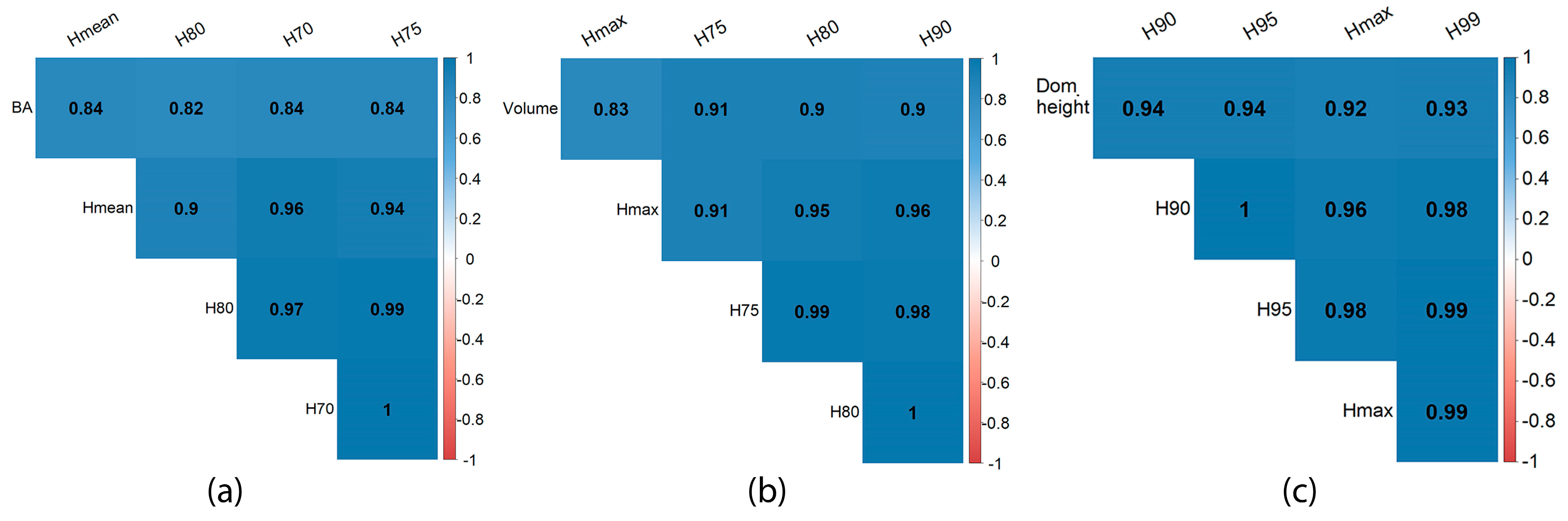
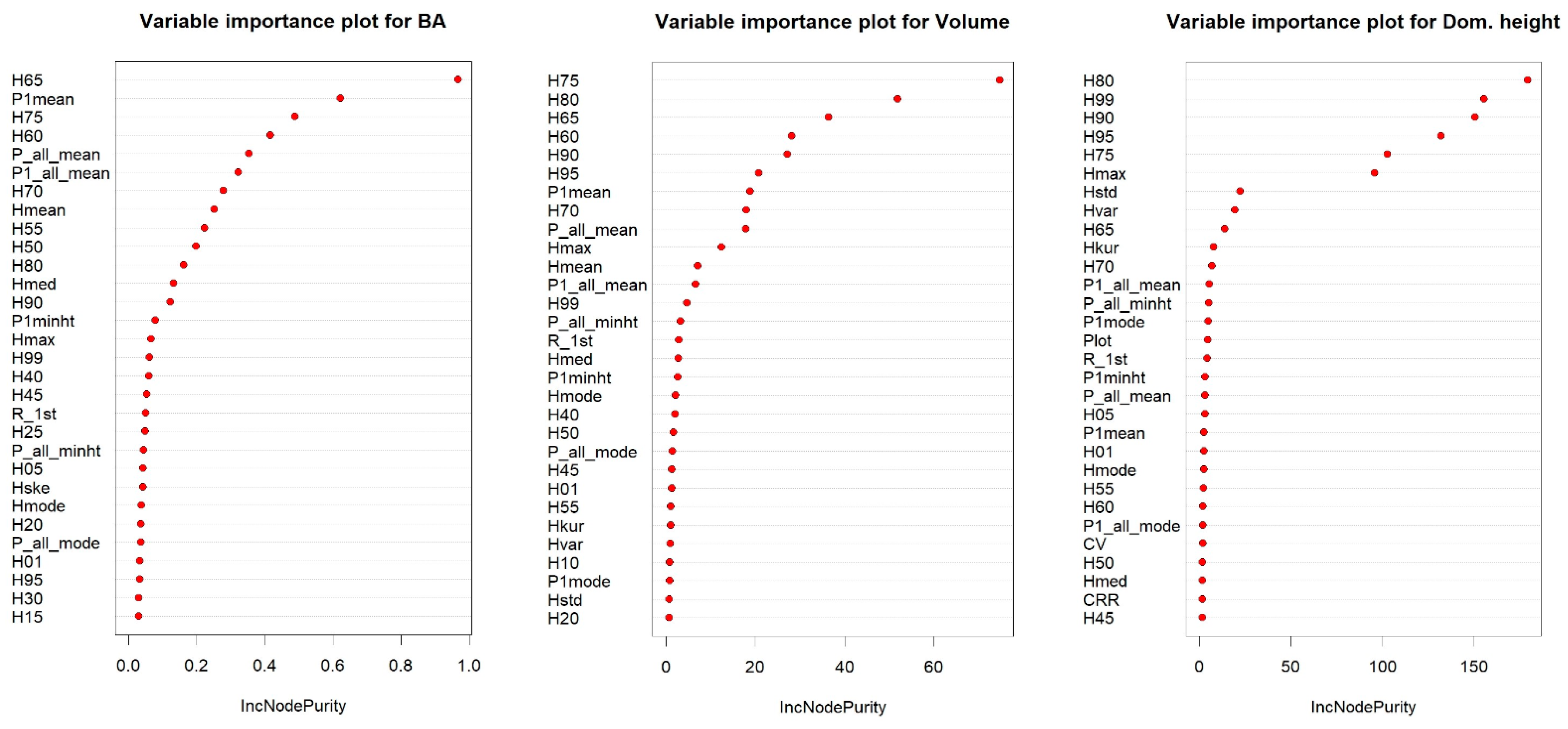
However, some serious challenges exist in estimating stand-level attributes using lidar metrics. Among the major challenges are the high data dimensionality and redundancy in some of them [
34]. For instance, Shi et al. (2018) evaluated the correlation among 37 frequently used lidar metrics. Their result indicated that about 60 percent of lidar metrics correlate above 70 percent to each other [
35]. Thus, such high dimensional and highly correlating metrics obtained from 3D lidar data require a robust statistical modeling approach to obtain meaningful information and accurate inventory parameter estimation. To produce reliable models relating ground attributes with lidar metrics, several studies have proposed various parametric, semiparametric, and nonparametric modeling methods, such as the Ordinary Least Squares (OLS) regression [
7,
17,
36], nonlinear least squares regression [
37], randomforest (RF)-based imputation [
35,
38,
39], Geographically Weighted Regression (GWR) [
40,
41] Artificial Neural Networks (ANN) [
42], Support Vector Regression (SVR) [
43], and others.
The linear regression model (LM) is one of the most used regression methods for modeling remote sensing data with field-measured data. The key advantage of using this method is the simplicity and easy interoperability of the resulting model. However, when applying this method to develop a model predicting forest attributes using lidar-derived metrics, multicollinearity between different metrics is one of the major problems limiting its applicability. Multicollinearity, also called collinearity, refers to a phenomenon in which explanatory variables in a multiple regression model are highly linearly related. This implies that two or more variables provide the same information in more than one way [
44]. Moreover, traditional linear model-fitting methods, such as the Ordinary Least Squares (OLS) regression, require a large sample size, which also increases the regression variances in the case of multicollinearity. Such substantial variances of regression coefficients make it challenging to test the hypothesis concerning the effects of the predictors [
45].
To overcome the issue of multicollinearity and the high dimension of predictor variables, nonparametric machine learning techniques, such as the Support Vector Regression (SVR), Random Forest (RF), k-nearest neighbor imputation (kNN), etc., have been introduced as alternatives to the traditional regression analysis. For example, Shi et al. (2018) used the random forest to classify tree species using lidar metrics and demonstrated its usefulness for highly correlated variables [
35]. Furthermore, Pascual et al. (2019) applied a kNN imputation based on a random forest approach to estimate the forest attributes [
46]. However, the usual pitfall of the random forest method is that the models are complex, not easily interpretable, and tend to overfit, given the large number of predictors used [
47]. Moreover, some research found a higher bias with random forests while predicting out of the range covered by the training data. [
46,
47].
Another approach to deal with multicollinearity is using semi-parametric methods such as the adaptive least absolute shrinkage and selection operator (ALASSO) regularization in a regression analysis [
48,
49] and Generalized Additive Modeling Selection (GAMSEL) [
50]. Unlike OLS, these regression methods can accommodate nonlinear relations and have more flexibility in terms of statistical assumptions. Moreover, they are known for their variable selection and regularization ability and for enhancing a model’s prediction accuracy and interpretability, especially for high-dimension data [
50,
51]. In the case of selecting variables to predict forest attributes with highly correlated lidar metrics, such ability can help select the most suitable predictors to develop a robust model. However, the applicability of these semi-parametric methods has not been explicitly explored for the forest attribute estimation utilizing lidar data.
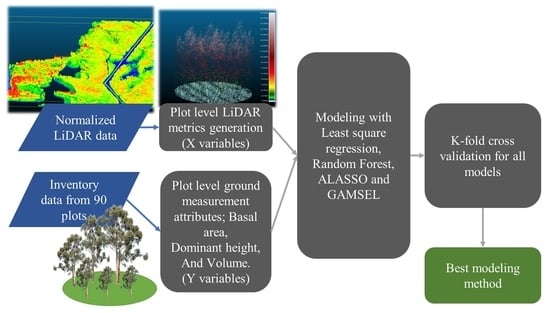
This research aims at developing equations to estimate forest attributes using two different modeling approaches—parametric and nonparametric regression for forest attribute prediction using lidar metrics. We evaluated four modeling methods: (1) Least squares regression (LSR), (2) adaptive least absolute shrinkage and selection operator (ALASSO), (3) random forest (RF), and (4) Generalized Additive Modeling Selection (GAMSEL). The last three methods aim to directly address the multicollinearity problem in ABA methodology while providing flexible model forms that might improve the relationship between lidar metrics and ground information.
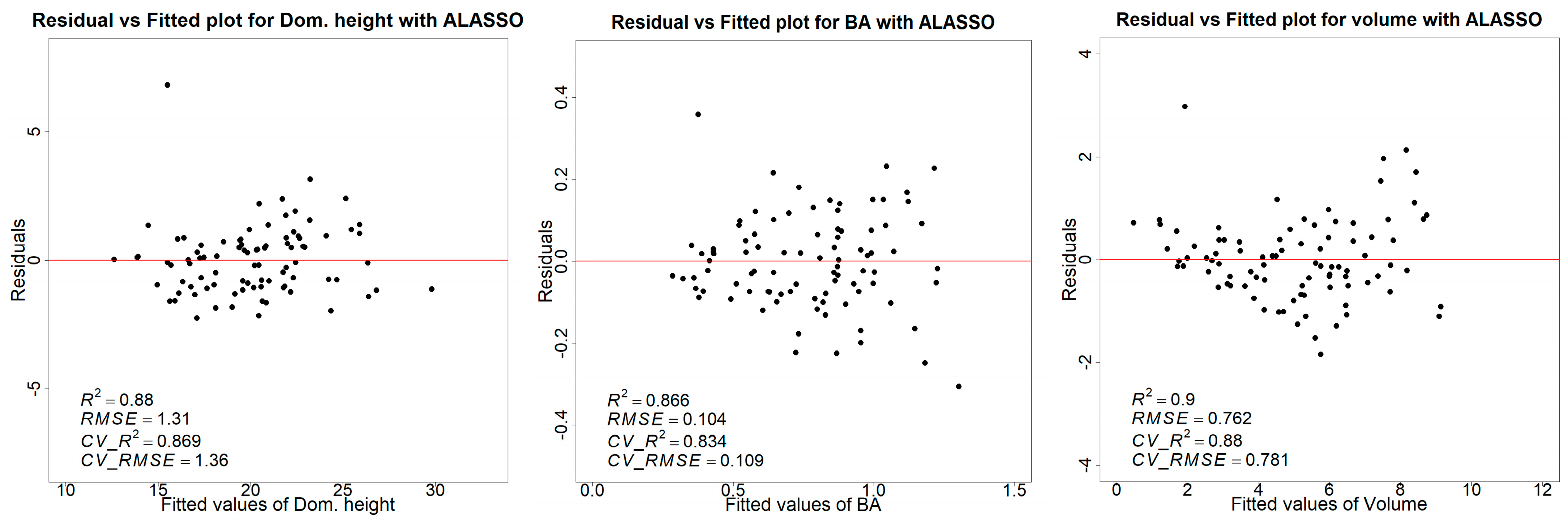
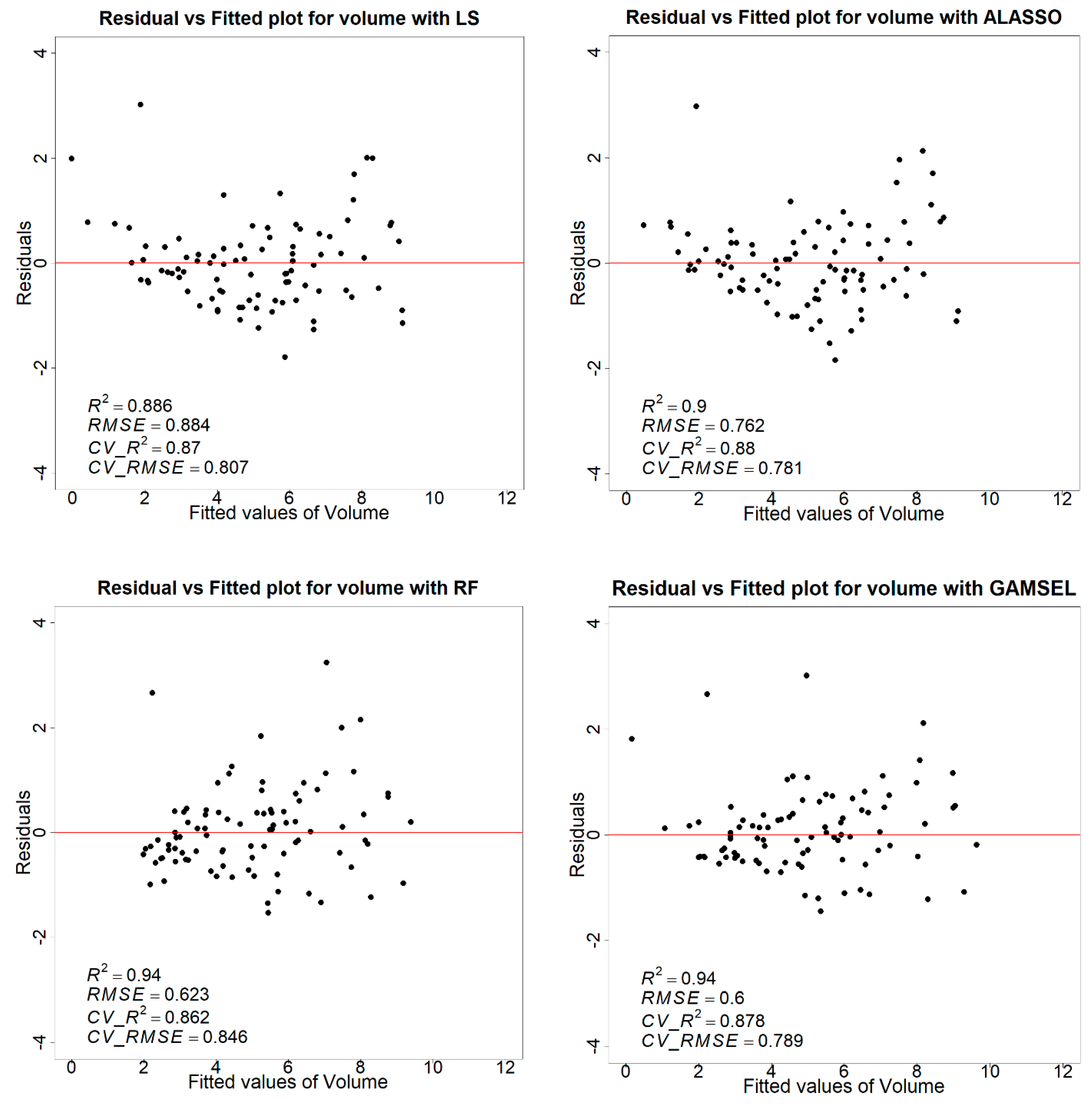
4. Discussion
In recent decades, several forest-related industries around the globe have adopted laser scanning as auxiliary information to complement forest inventories. However, the modeling methods in use for the forest parameter estimation are still not adequately exploiting the information in the point clouds [
73]. In this study, we compared the performance of four different modeling methods to predict various forest attributes using aerial lidar data. When comparing those four methods for volume estimation, adaptive lasso performed better than the other three. Although the overall coefficient of determination (adj. R
2) of 0.88 and the lowest RMSE of 19.53 m
3/ha was achieved in this study with adaptive lasso regression, the difference compared to other methods is very nominal, i.e., 19.73 m
3/ha, 20.18 m
3/ha, and 21.15 m
3/ha with respect to the GAMSEL, LS (least squares), and random forest, respectively. The RMSE of 19.53 m
3/ha is low compared to other studies in similar forest conditions. A possible reason for this might be lidar data with better point cloud density (44 points/m
2) and a relatively smaller study area than other studies. Leite et al. (2020) compared a few parametric and nonparametric regression methods for the area-based volume estimation of a eucalyptus plantation using low-lidar data (5 points/m
2) and concluded the best result of adj. R
2 0.83 and RMSE 40.71 m
3/ha using the artificial neural network (ANN) and the lowest of adj. R
2 0.79 and RMSE 46.76 m
3/ha with the linear regression method [
74]. Likewise, Silva et al. (2016) applied the principal component approach for predicting the stem volume in eucalyptus plantations using a lidar metric generated from medium-density (10/points/m
2) lidar point clouds. They achieved an adj R
2 of 0.87 and RMSE of 27.60 m
3/ha [
56].
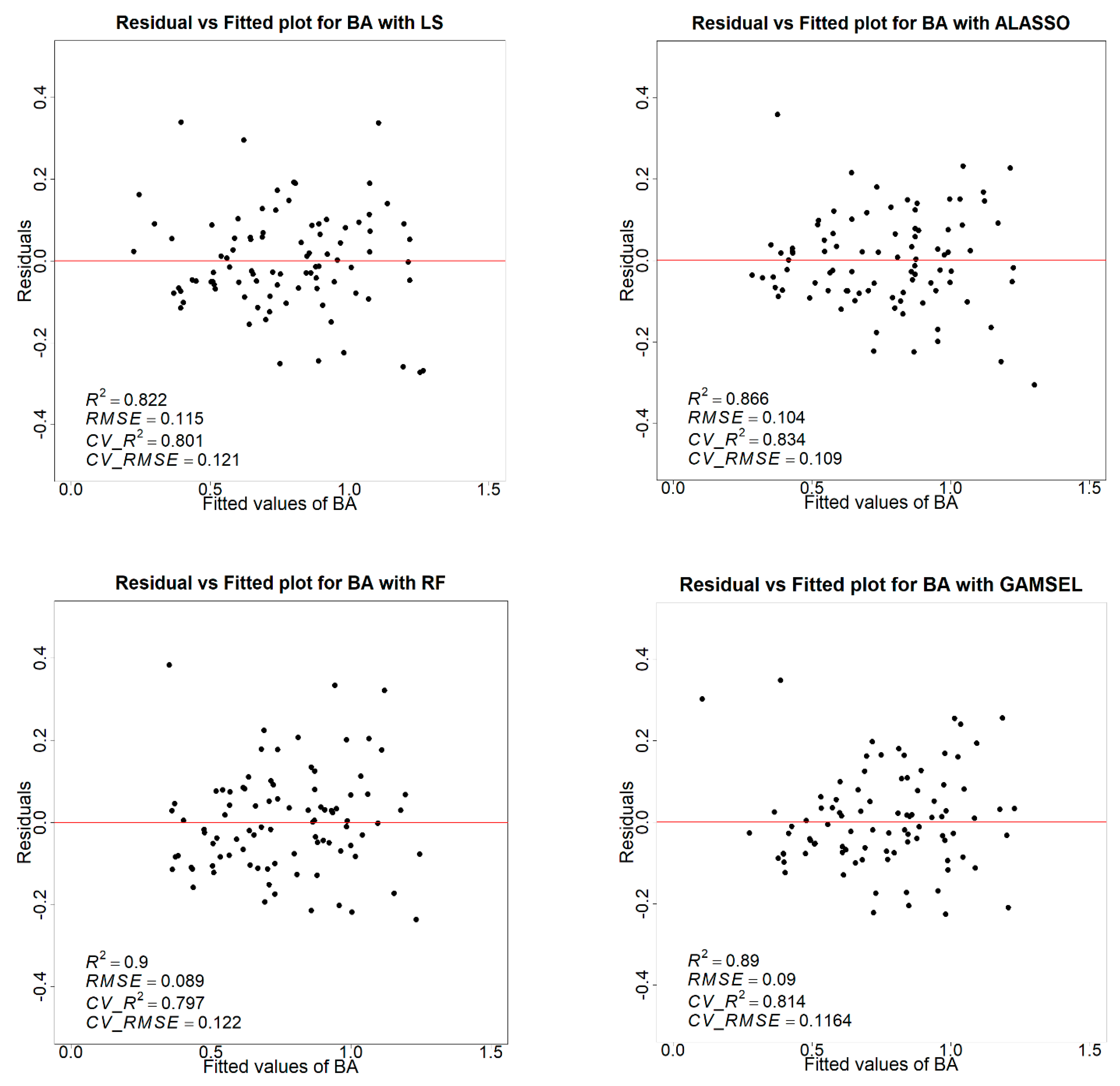
In this study, the 75th percentile of height was included in all four models as a vital metric for estimating the volume. After the 75th percentile, the 90th percentile, canopy relief ratio, and percentage of the first return above the mean are primary metrics predicting the volume. Consistent with the outcome obtained for the volume model, the optimal model for the basal area was determined using the adaptive lasso regression method. The adaptive lasso regression slightly improved the prediction for the basal area with an overall adj. R
2 of 0.83 and RMSE 2.73 m
2/ha compared to the adj. R
2 of 0.81, 0.80, and 0.80 and RMSE of 2.90 m
2/ha, 3.03 m
2/ha, and 3.05 m
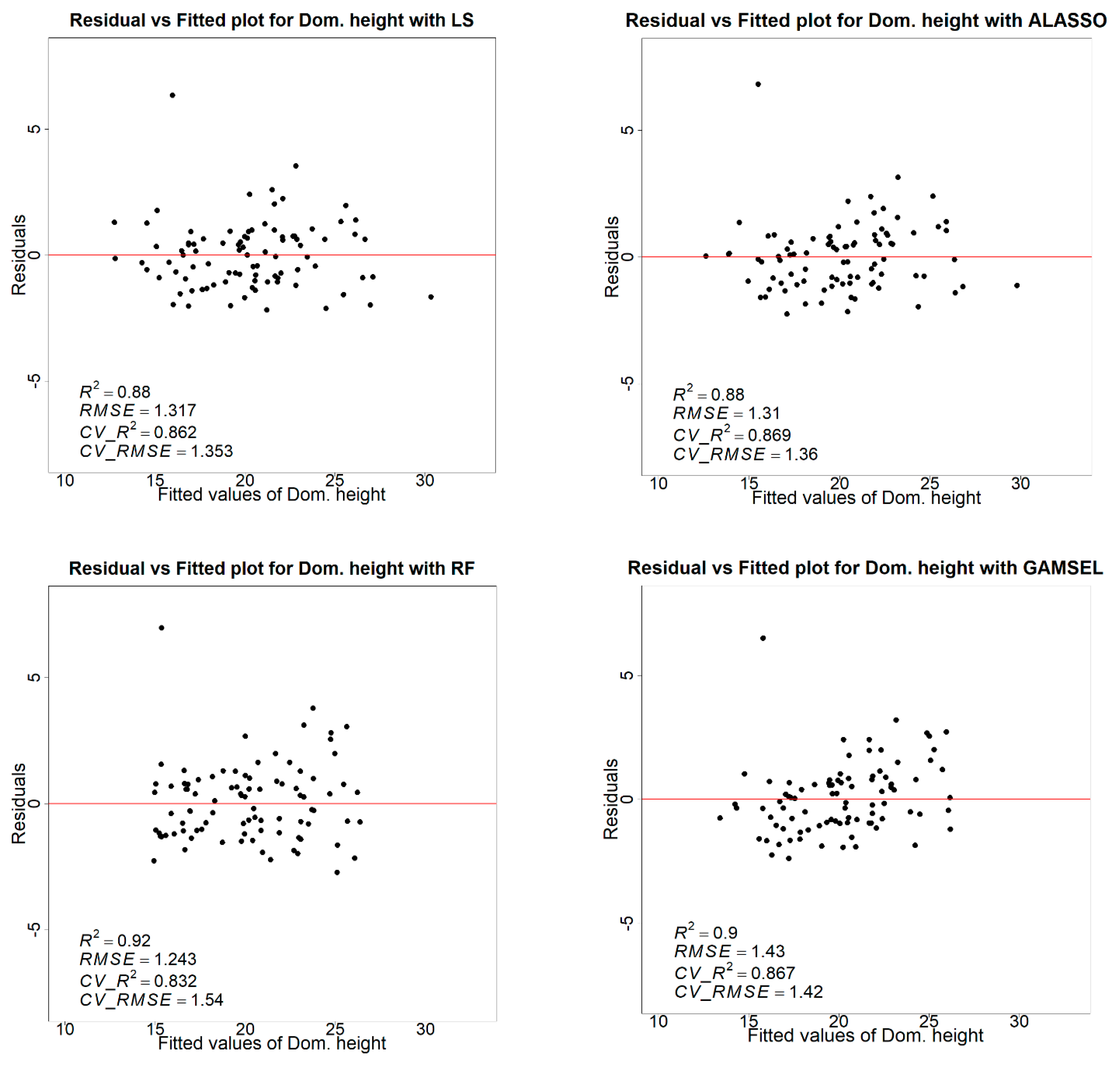
2/ha with GAMSEL, LS, and random forest, respectively. Likewise, for the dominant height, both the adaptive lasso and GAMSEL model achieved the highest adj. R
2 of 0.87 followed by LS and random forest regression methods with an adj. R
2 of 0.86 and 0.83, respectively. However, in terms of better RMSE for dominant height, the least square method resulted in a slightly better RMSE of 33.83 m/ha, followed by the adaptive lasso, GAMSEL, and the random forest with an RMSE of 33.98 m/ha, 33.53 m/ha, and 38.82 m/ha, respectively. Other researchers, such as Brown et al. (2022), compared linear and random forest methods for the basal area estimation using variables from the low-density lidar and multispectral imageries. In that study, they achieved a slightly better result with the random forest method (R
2 of 0.39 and 0.36, and RMSE of 5.662 m
2/ha and 5.731 m
2/ha with the random forest and LS, respectively) but an overall low accuracy compared to our study [
57]. In another study by Li et al. (2022), they proposed a model with a good generalization capability for the basal area using lidar-derived metrics for eucalyptus plantation forests achieving an R
2 of 0.71 and rRMSE of 18.22% [
75] using the least square method.
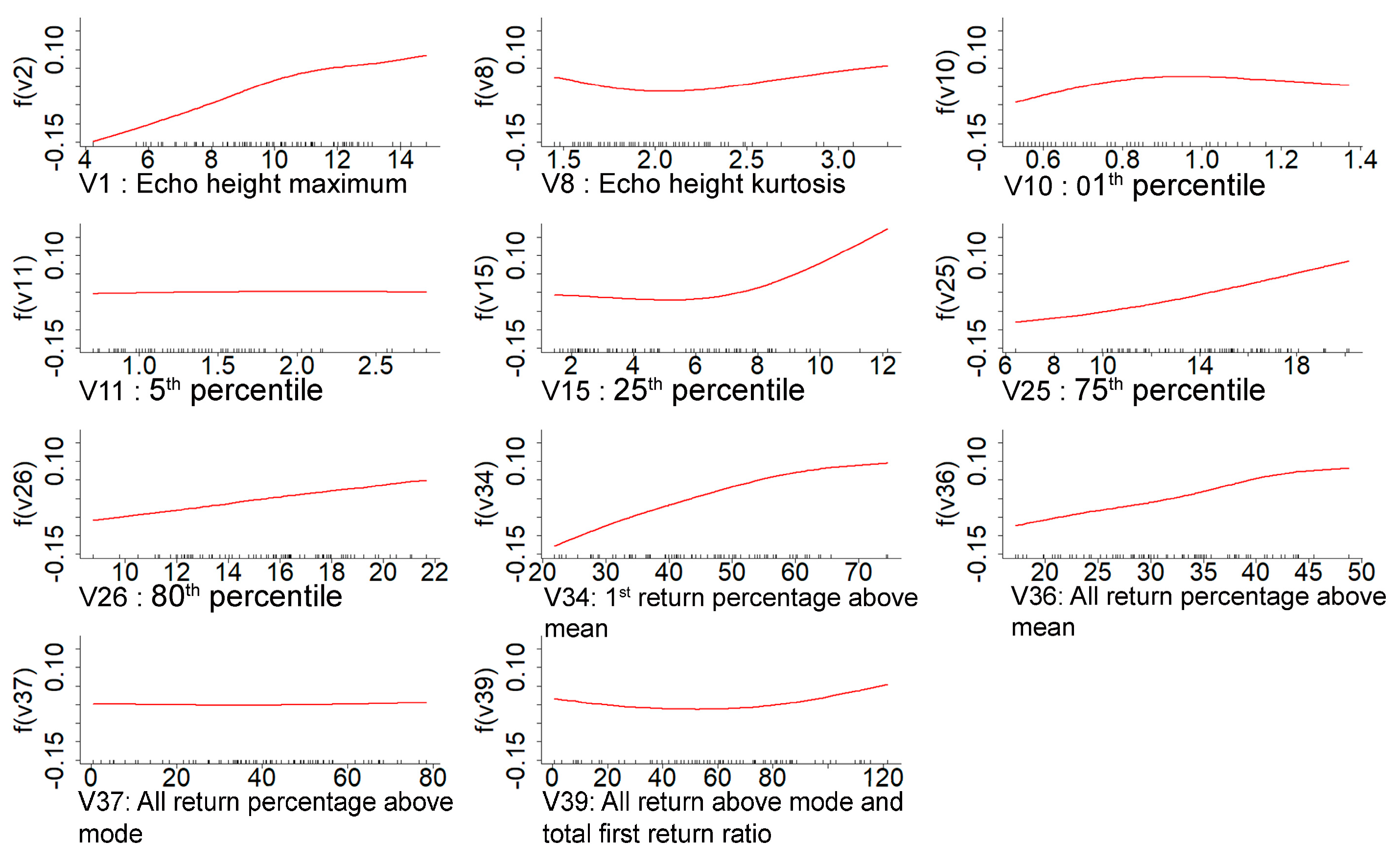
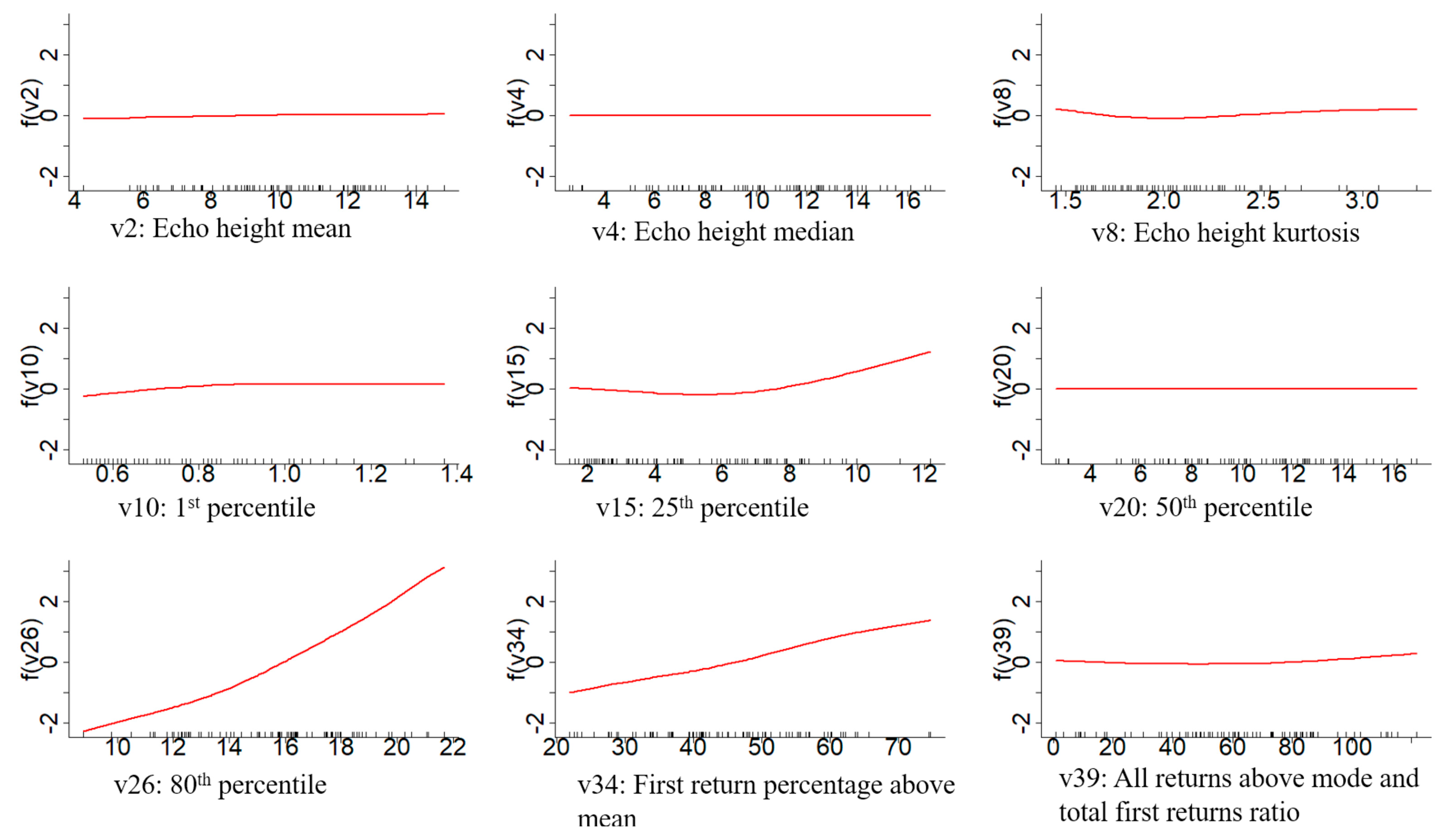
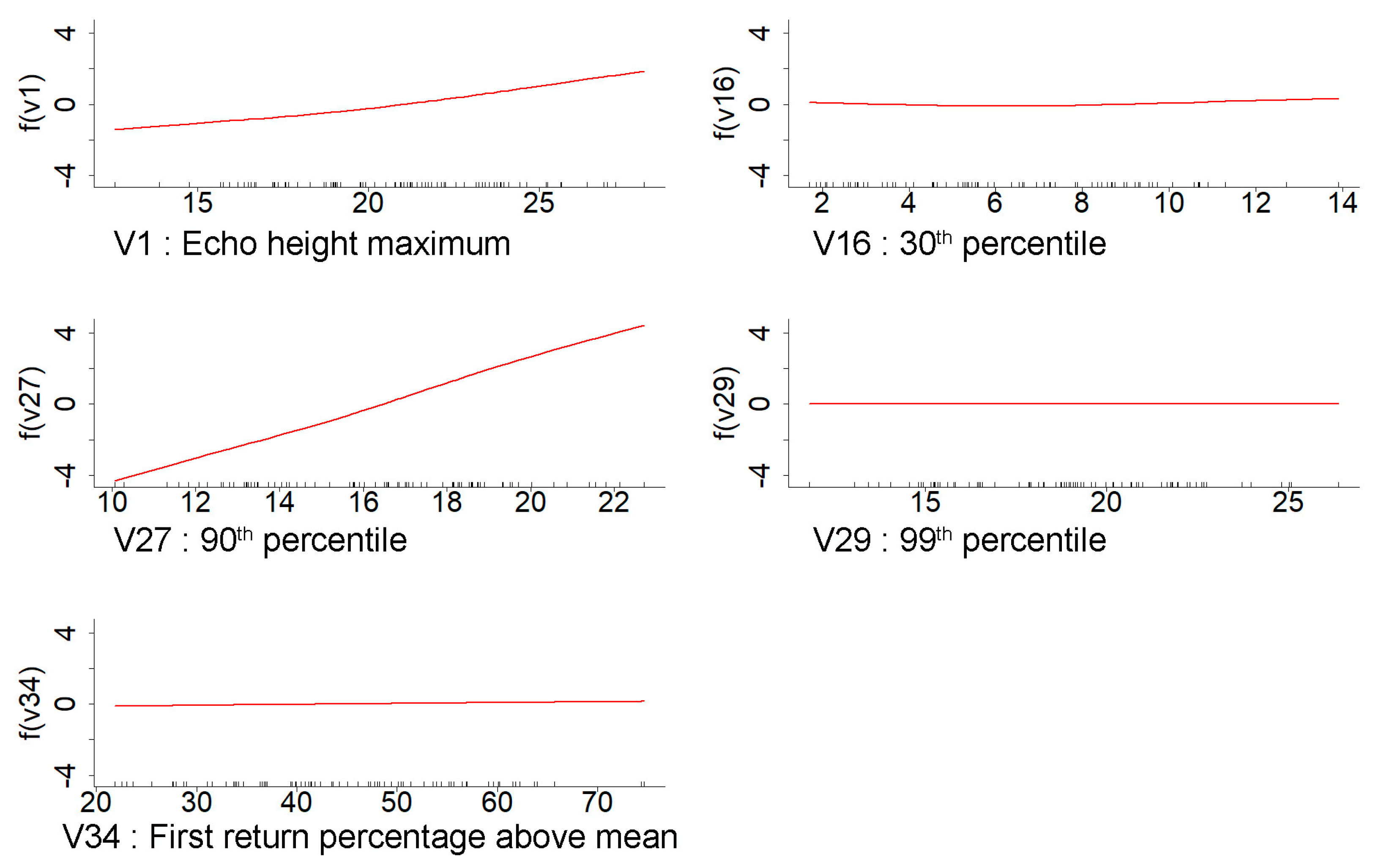
Furthermore, Li et al. (2022) used an exhaustive combination of lidar metrics with a clear meaning in forest mensuration. They formulated 86 tree type-specific and region-generalized models and sorted the most meaningful variables for estimating the stand volume and basal area. In that study, they found the 75th and 95th percentile, the percentage of the first returns above the minimum height, and the standard height deviation as important variables for the basal area estimation. Similarly to this is the 95th percentile, first return ratio above the mean height, and the coefficient of a height variance for the volume estimation in the eucalyptus forest [
75]. The 50th to 75th percentile represents the middle and upper part of the stand canopy; likewise, the 80th to 99th percentile characterizes the upper part of the canopy [
29,
76]. Therefore, including these mid and upper-canopy percentiles and density metrics representing the crown structure and cover makes the model more generalizable and significant. This result corresponds with the variables selected in our models. In our study, the 75th percentile of the echo height and the percentage of the first returns above the mean are the two significant variables in the LS model for the basal area and volume. Comparably, the foremost contributing variables in the random forest model are the height percentiles representing the canopy’s middle and upper parts, and the minimal contributing variables are below the 40th percentile. Corresponding to the LS and random forest, the most significant variables in the GAMSEL model are also from the middle and upper percentiles and density ratio variables representing the canopy structure and cover. However, the variables included in the adaptive lasso are distinct from the other three since the most contributing variable for the basal area is the canopy relief ratio, and for volume and dominant height, it is the first percentile of echo height. Although these selected variables are not among the topmost variables in the other three models, they have similar properties to those selected variables in the other three models. The canopy relief ratio is the ratio of the mean and maximum value of all echo heights in a given area, signifying the canopy structure like other density metrics. Similarly, the first percentile represents the bottom portion of the stem and tends to fluctuate evenly according to the stem density.
We tested the performance of popular parametric, semiparametric, and nonparametric modeling methods for the forest attribute estimation. In our test, the semiparametric models, i.e., the adaptive lasso and GAMSEL, slightly improved the estimates; however, none performed significantly differently from the others. Kangas et al. (2016), in their study of the aboveground biomass (AGB) estimation, tested the parametric, semiparametric, and nonparametric models using real-world and simulated lidar-based variables. In that comparison, although they achieved a better accuracy with the nonparametric model, i.e., local constant kernel, they found it leading to the underestimation of the variance; thus, they recommended using the semiparametric, i.e., GAM, which they found more consistent and suitable for the internal model [
77]. On the other hand, even though parametric models such as the least squares regression are a more straightforward method, applications at a practical scale are scarcer. One primary reason is that when the number of dependent variables is very high, evaluating each variable to obtain a meaningful model conforming to all assumptions is not practical [
78]. Hence, even though our results demonstrate the nominal difference in accuracies between the evaluated models, the semiparametric model seems more fitting to apply in a practical scenario.
In our study, the individual tree detection method failed to estimate the total number of trees in the plot correctly. One probable reason for such low correlations can be the small sample plot size of just 400 m
2, resulting in the insufficient number of trees to adjust the error due to the trees in the plot boundary. Moreover, in the field inventory, a standard GNSS receiver was used to establish the plot center, which might also have contributed to the low accuracy of ITD. Some studies have suggested that using a higher-density lidar point cloud will improve the ITD accuracy. However, a study was conducted in a similar eucalyptus plantation forest by Corte et al. (2022), and applying a similar ITD approach in high-density lidar data (>1400 pts/m
2) did not noticeably contribute to improving the accuracy (average R
2 = 0.24). They mentioned a complex stand structure and irregular branching forms of the eucalyptus causing omission and commission when outlining trees, in addition to the error associated with the GPS positioning as the major limitation [
55]. Those mentioned limitations are also the case in our study. In addition, half of the sample plots are from regrowth forests with complex branching and multiple stems; it was challenging to delineate the crown of every branch.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}