
Convolutional Neural Network-Driven Improvements in Global Cloud Detection for Landsat 8 and Transfer Learning on Sentinel-2 Imagery



Abstract
:1. Introduction
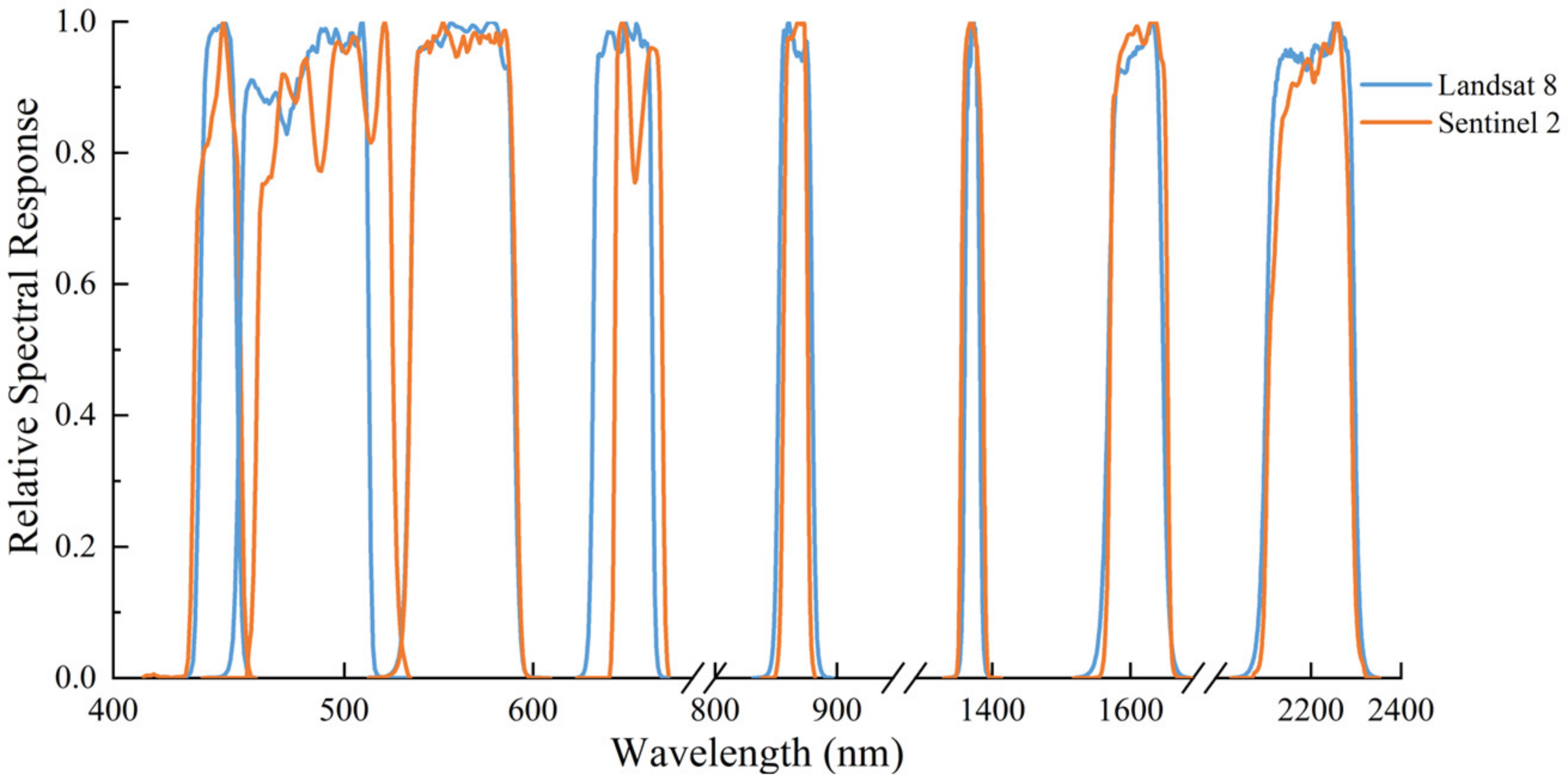
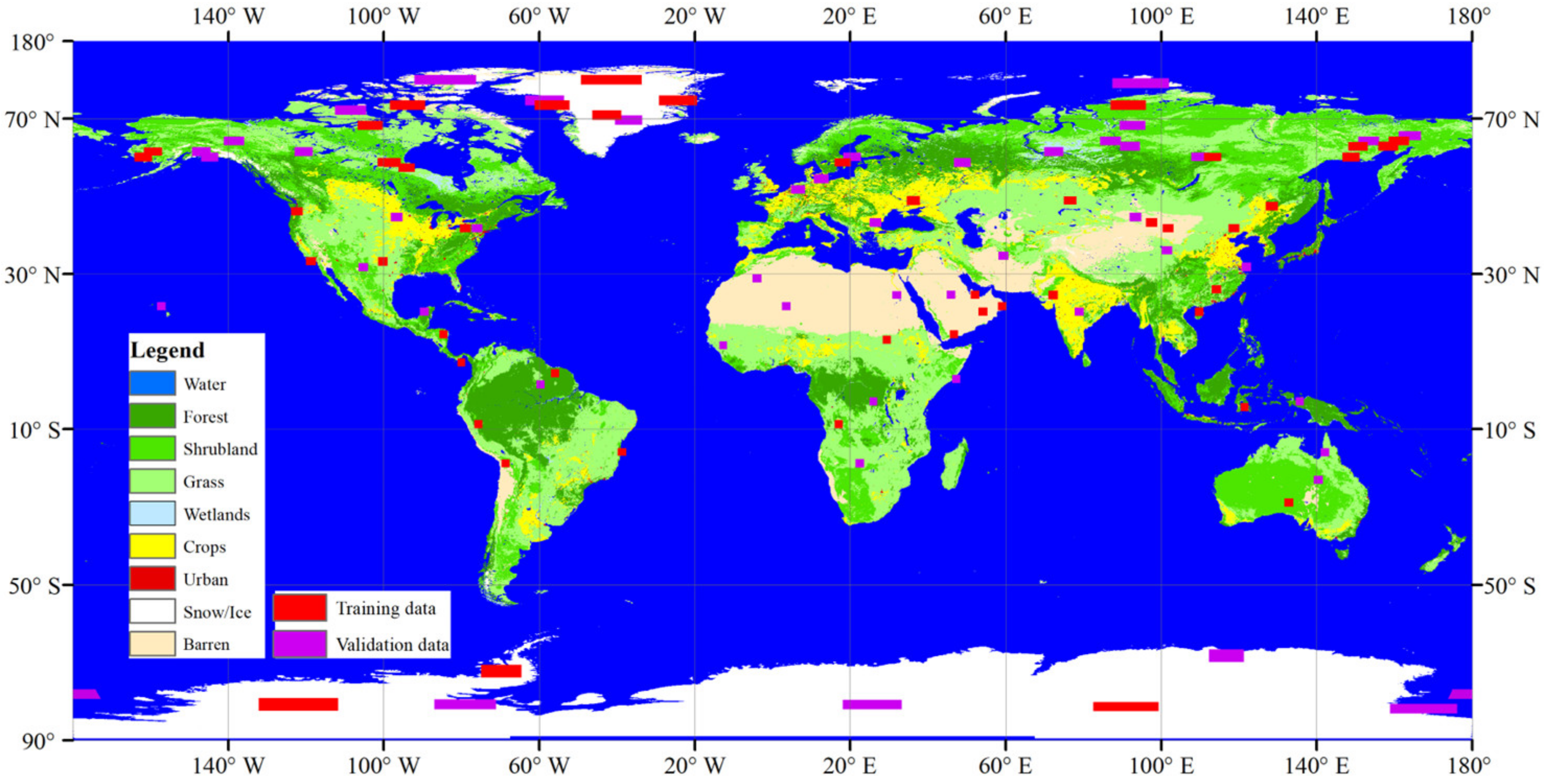
2. Data Materials
3. Models and Methods
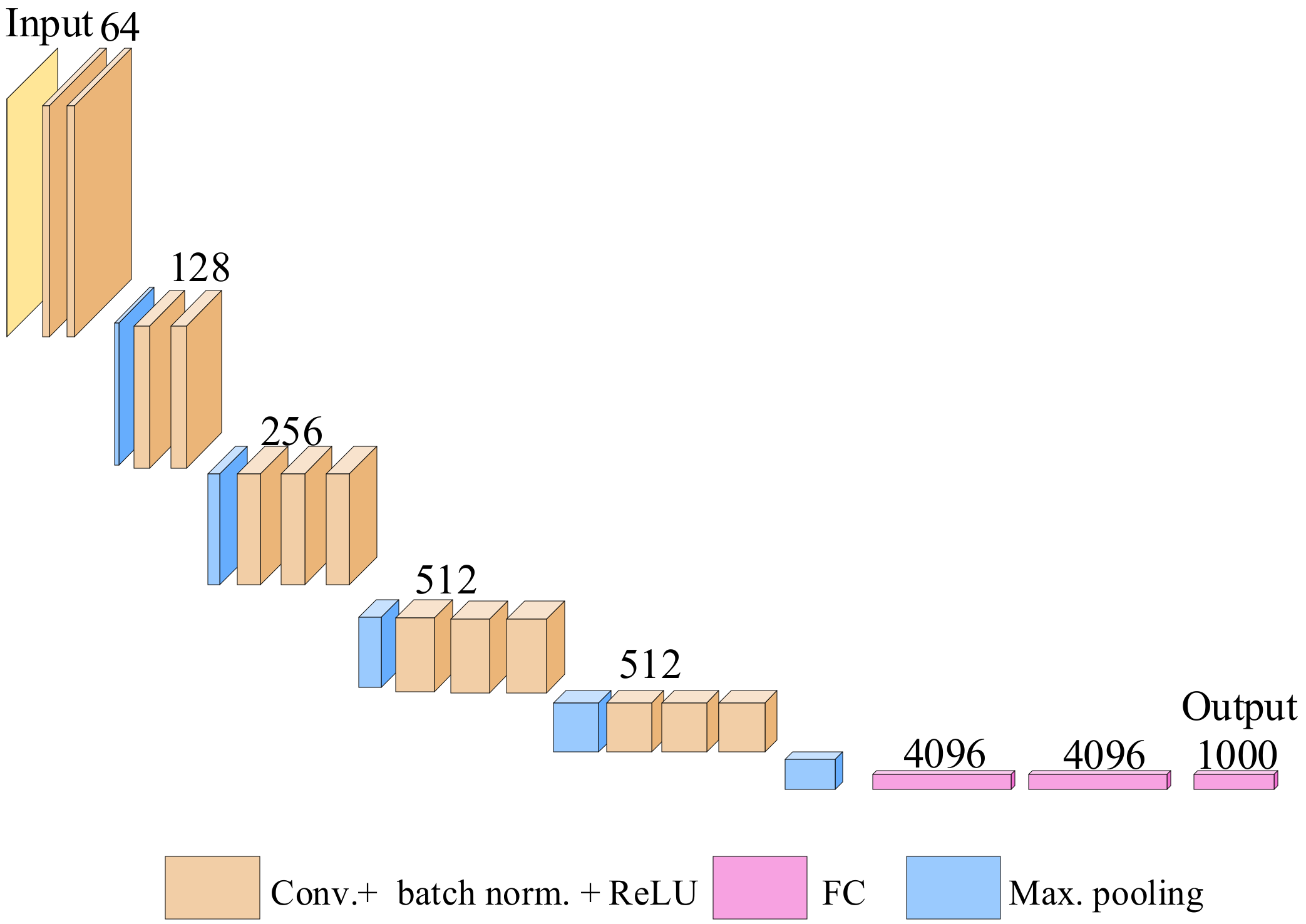
3.1. Convolutional Neural Network
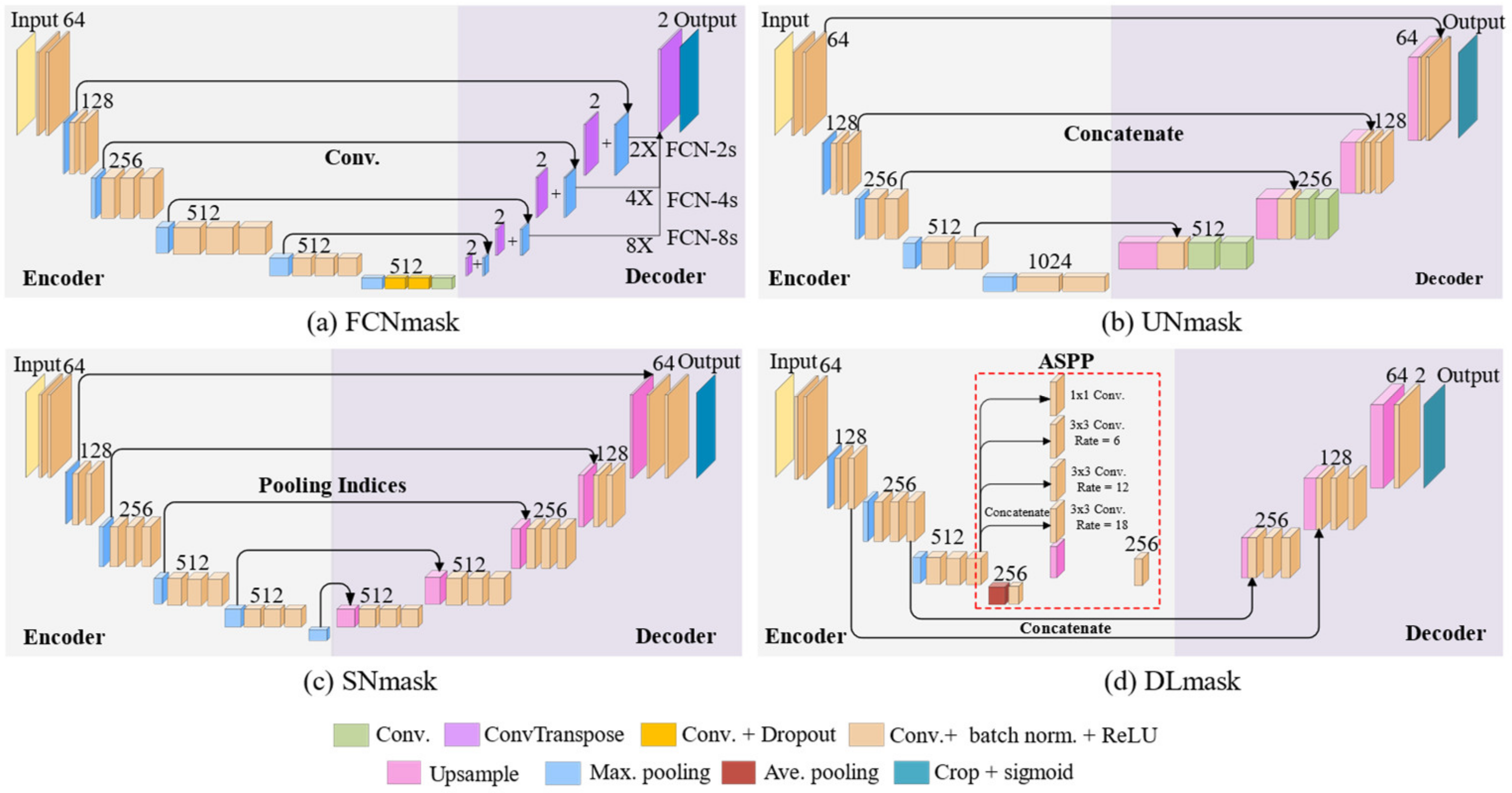
3.1.1. FCN
3.1.2. U-Net
3.1.3. SegNet
3.1.4. DeepLab
3.2. Model Training and Validation
3.2.1. Model Training
3.2.2. Model Validation
3.2.3. Transfer Learning
4. Results and Discussion
4.1. Landsat 8 Cloud Detection Results
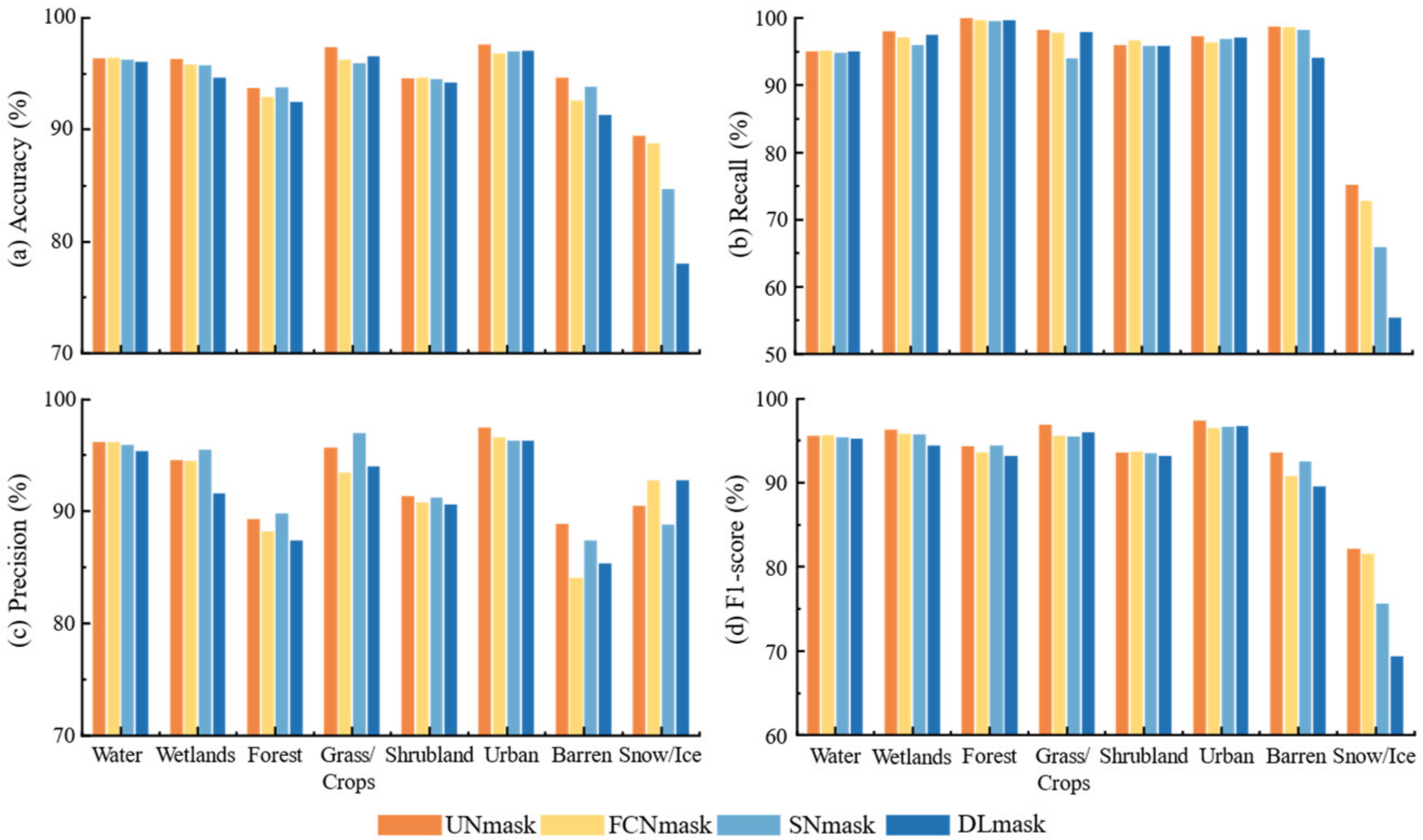
4.2. Quantitative Accuracy Evaluation
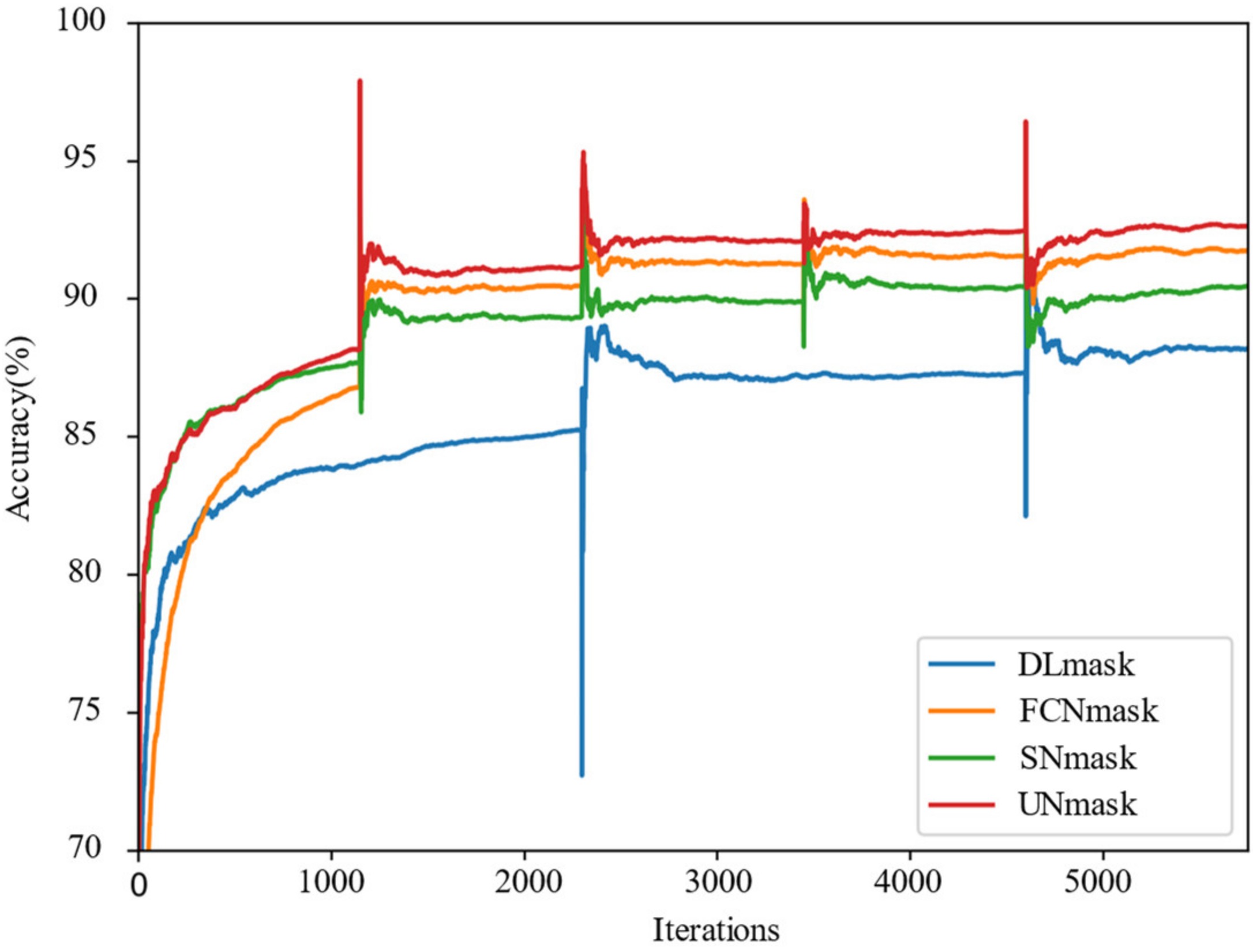
4.2.1. Overall Performance and Operating Efficiency
4.2.2. Model Comparison and Efficiency Analysis
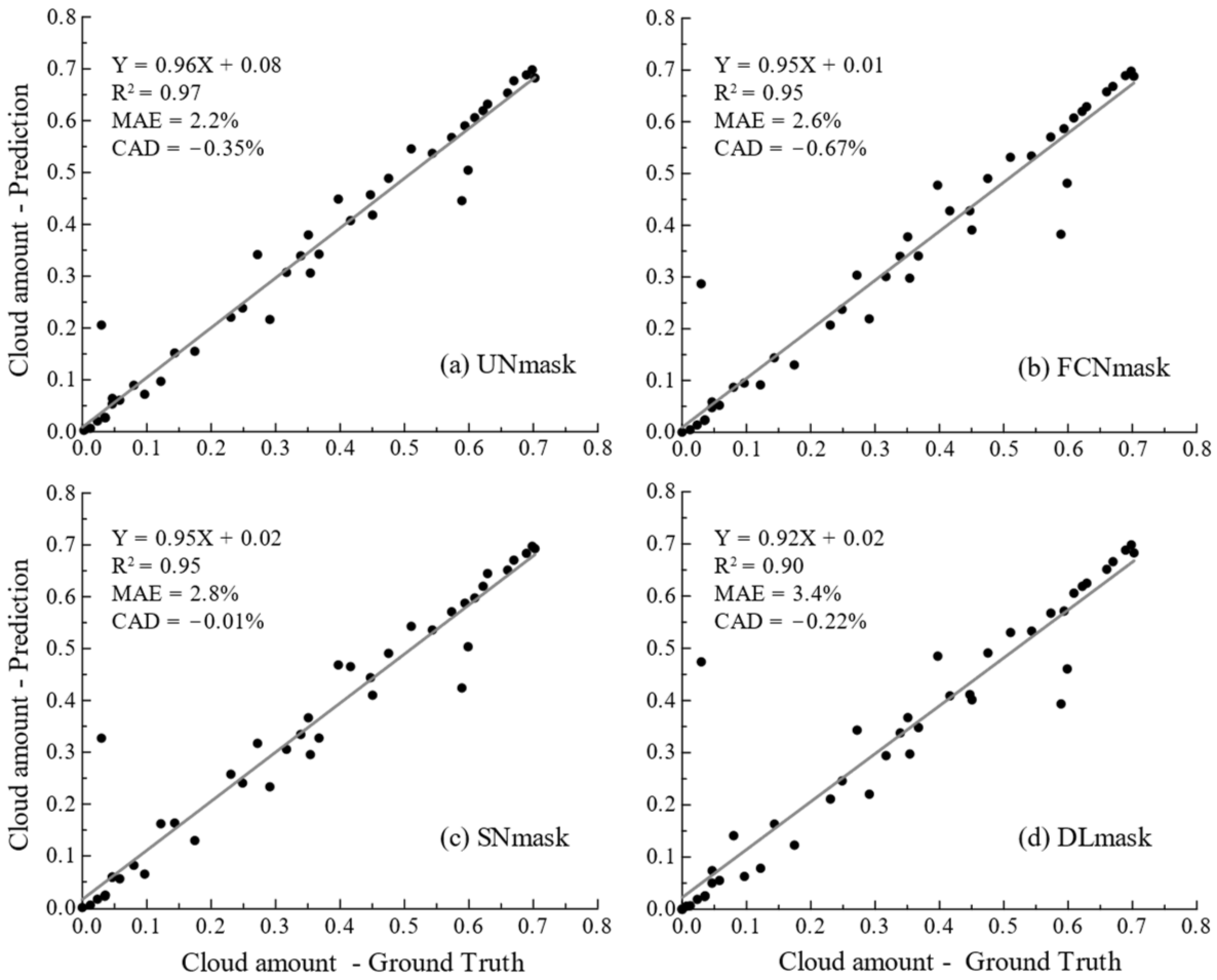
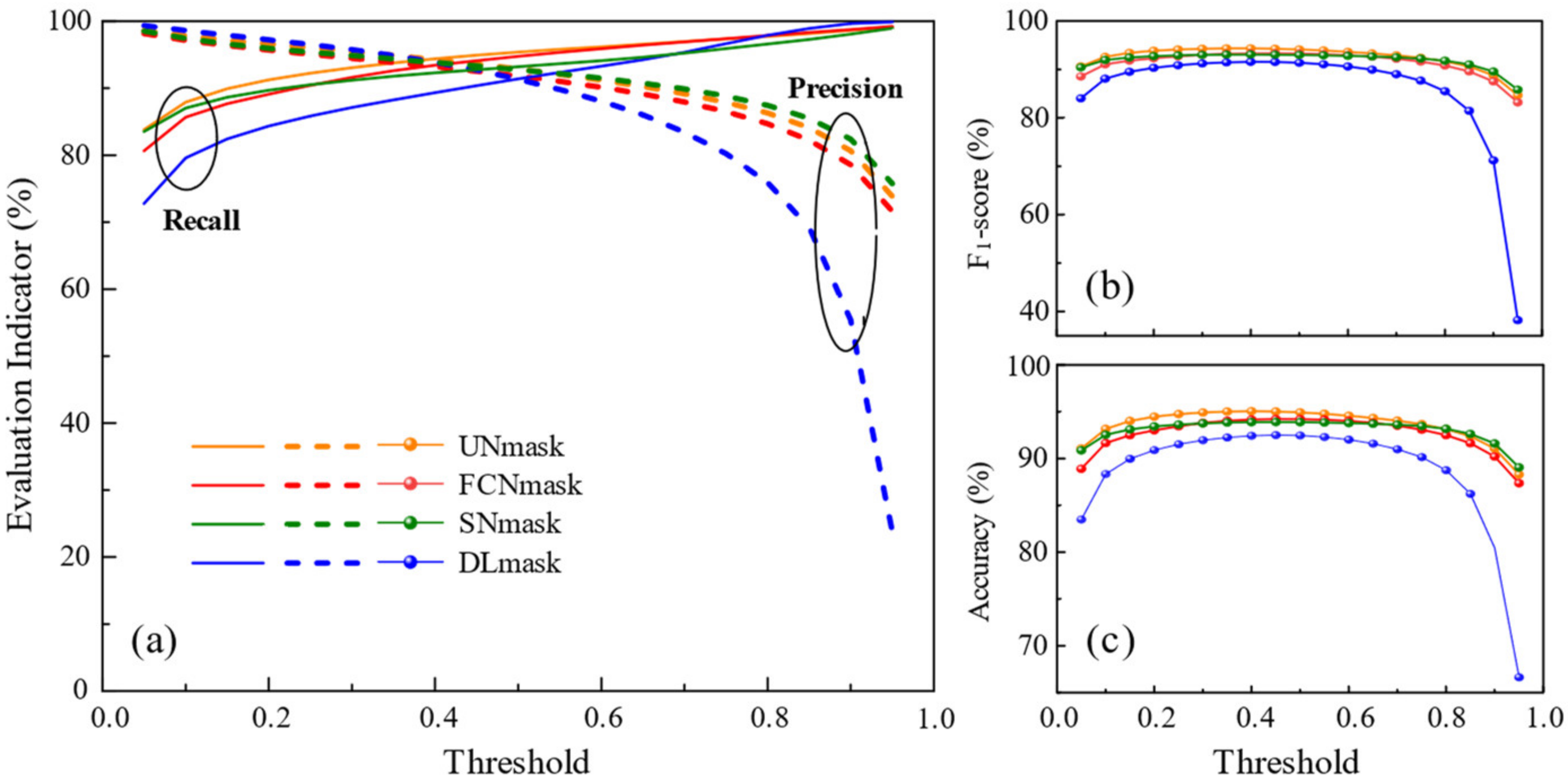
4.2.3. Impacts of Threshold Setting on Cloud Detection
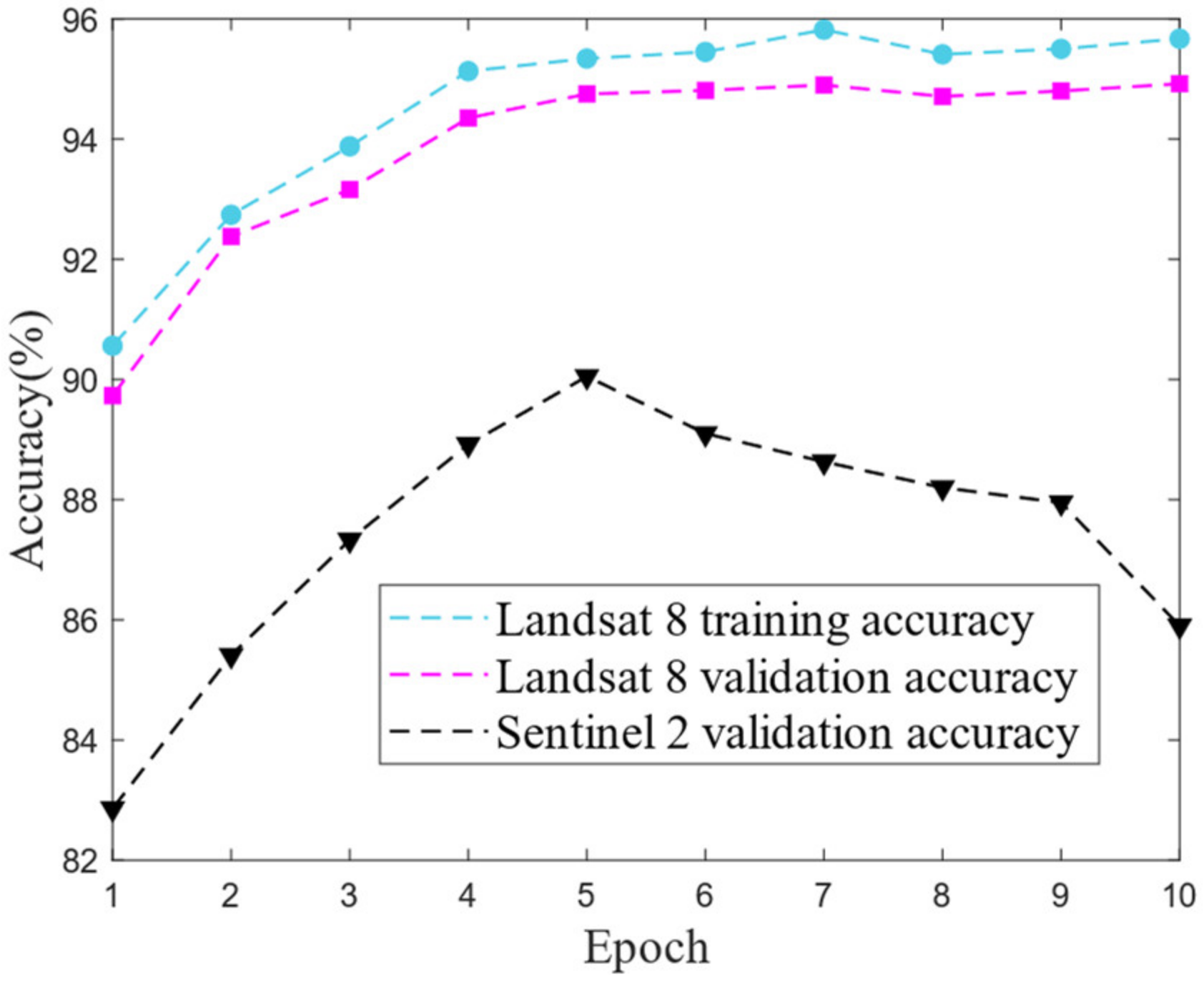
4.3. Transfer Learning Cloud Detection for Sentinel 2 Imagery
4.3.1. Overall Performance and Operating Efficiency
4.3.2. Model Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Harshvardhan; Randall, D.A.; Corsetti, T.G. Earth Radiation Budget and Cloudiness Simulations with a General Circulation Model. J. Atmos. Sci. 1989, 46, 1922–1942. [Google Scholar] [CrossRef]
- Ramanathan, V.; Cess, R.D.; Harrison, E.F.; Minnis, P.; Barkstrom, B.R.; Ahmad, E.; Hartmann, D. Cloud-Radiative Forcing and Climate: Results from the Earth Radiation Budget Experiment. Science 1989, 243, 57–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, L.; Wei, J.; Wang, J.; Mi, X.T.; Guo, Y.M.; Lv, Y.; Yang, Y.K.; Gan, P.; Zhou, X.Y.; Jia, C.; et al. A Universal Dynamic Threshold Cloud Detection Algorithm (UDTCDA) supported by a prior surface reflectance database. J. Geophys. Res. Atmos. 2016, 121, 7172–7196. [Google Scholar] [CrossRef]
- Wei, J.; Huang, B.; Sun, L.; Zhang, Z.; Wang, L.; Bilal, M. A simple and universal aerosol retrieval algorithm for Landsat series images over complex surfaces. J. Geophys. Res. -Atmos. 2017, 122, 13338–13355. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Li, Z.; Wang, J.; Li, C.; Gupta, P.; Cribb, M. Ground-level gaseous pollutants (NO2, SO2, and CO) in China: Daily seamless mapping and spatiotemporal variations. Atmos. Chem. Phys. 2023, 23, 1511–1532. [Google Scholar] [CrossRef]
- Asner, G.P. Cloud cover in Landsat observations of the Brazilian Amazon. Int. J. Remote Sens. 2001, 22, 3855–3862. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and Temporal Distribution of Clouds Observed by MODIS Onboard the Terra and Aqua Satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. -Atmos. 2004, 109, D19105. [Google Scholar] [CrossRef] [Green Version]
- Rossow, W.B.; Mosher, F.; Kinsella, E.; Arking, A.; Desbois, M.; Harrison, E.; Minnis, P.; Ruprecht, E.; Sèze, G.; Smith, E. ISCCP cloud analysis algorithm intercomparison. Adv. Space Res. 1985, 5, 185. [Google Scholar] [CrossRef]
- Rossow, W.B.; Schiffer, R.A. ISCCP Cloud Data Products. Bull. Am. Meteorol. Soc. 1991, 72, 2–20. [Google Scholar] [CrossRef]
- Rossow, W.B.; Garder, L.C. Cloud Detection Using Satellite Measurements of Infrared and Visible Radiances for ISCCP. J. Clim. 1993, 6, 2341–2369. [Google Scholar] [CrossRef]
- Stowe, L.L.; McClain, E.P.; Carey, R.; Pellegrino, P.; Gutman, G.G.; Davis, P.; Long, C.; Hart, S. Global distribution of cloud cover derived from NOAA/AVHRR operational satellite data. Adv. Space Res. 1991, 11, 51–54. [Google Scholar] [CrossRef]
- Saunders, R.W.; Kriebel, K.T. An improved method for detecting clear sky and cloudy radiances from AVHRR data. Int. J. Remote Sens. 1988, 9, 123–150. [Google Scholar] [CrossRef]
- Kriebel, K.T.; Saunders, R.W.; Gesell, G. Optical Properties of Clouds Derived from Fully Cloudy AVHRR Pixels. Bcitr. Phys. Atmosph. 1989, 62, 165–171. [Google Scholar]
- Irish, R. Landsat 7 automatic cloud cover assessment. Proc. SPIE Int. Soc. Opt. Eng. 2000, 4049, 348–355. [Google Scholar] [CrossRef]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Guindon, B. Quantitative assessment of a haze suppression methodology for satellite imagery: Effect on land cover classification performance. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1082–1089. [Google Scholar] [CrossRef]
- Zhang, Y.; Guindon, B.; Cihlar, J. An image transform to characterize and compensate for spatial variations in thin cloud contamination of Landsat images. Remote Sens. Environ. 2002, 82, 173–187. [Google Scholar] [CrossRef]
- Gomez-Chova, L.; Camps-Valls, G.; Calpe-Maravilla, J.; Guanter, L.; Moreno, J. Cloud-screening algorithm for ENVISAT/MERIS multispectral images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4105–4118. [Google Scholar] [CrossRef]
- Le Hegarat-Mascle, S.; Andre, C. Use of Markov Random Fields for automatic cloud/shadow detection on high resolution optical images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 351–366. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.Y.; Zhang, L.P.; Li, P.X. Cloud/shadow detection based on spectral indices for multi/hyperspectral optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Frantz, D.; Hass, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Oishi, Y.; Ishida, H.; Nakamura, R. A new Landsat 8 cloud discrimination algorithm using thresholding tests. Int. J. Remote Sens. 2018, 39, 1–21. [Google Scholar] [CrossRef]
- Chen, N.; Li, W.; Gatebe, C.; Tanikawa, T.; Hori, M.; Shimada, R.; Aoki, T.; Stamnes, K. New neural network cloud mask algorithm based on radiative transfer simulations. Remote Sens. Environ. 2018, 219, 62–71. [Google Scholar] [CrossRef] [Green Version]
- Ackerman, S.A.; Strabala, K.I.; Menzel, W.P.; Frey, R.A.; Moeller, C.C.; Gumley, L.E. Discriminating clear sky from clouds with MODIS. J. Geophys. Res. Atmos. 1998, 103, 32141–32157. [Google Scholar] [CrossRef]
- Wang, X.; Xie, H.; Liang, T. Evaluation of MODIS snow cover and cloud mask and its application in Northern Xinjiang, China. Remote Sens. Environ. 2008, 112, 1497–1513. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Lyapustin, A.; Sun, L.; Peng, Y.; Xue, W.; Su, T.; Cribb, M. Reconstructing 1-km-resolution high-quality PM2.5 data records from 2000 to 2018 in China: Spatiotemporal variations and policy implications. Remote Sens. Environ. 2021, 252, 112136. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Sui, Y.; He, B.; Fu, T. Energy-based cloud detection in multispectral images based on the SVM technique. Int. J. Remote Sens. 2019, 40, 5530–5543. [Google Scholar] [CrossRef]
- Hughes, M.; Hayes, D. Automated Detection of Cloud and Cloud Shadow in Single-Date Landsat Imagery Using Neural Networks and Spatial Post-Processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Ghasemian, N.; Akhoondzadeh, M. Introducing two Random Forest based methods for cloud detection in remote sensing images. Adv. Space Res. 2018, 62, 288–303. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Deep Facial Diagnosis: Deep Transfer Learning From Face Recognition to Facial Diagnosis. IEEE Access 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Pseudo RGB-D Face Recognition. IEEE Sens. J. 2022, 22, 21780–21794. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.; Millis, B.; Huo, Y. VoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding Based Deep Learning. Mach. Learn. Med. Imaging 2021, 12966, 437–446. [Google Scholar]
- Yao, T.; Qu, C.; Liu, Q.; Deng, R.; Tian, Y.; Xu, J.; Jha, A.; Bao, S.; Zhao, M.; Fogo, A.; et al. Compound Figure Separation of Biomedical Images with Side Loss. Deep. Gener. Model. Data Augment. Label. Imperfections 2021, 13003, 173–183. [Google Scholar]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Goff, M.L.; Tourneret, J.-Y.; Wendt, H.; Ortner, M.; Spigai, M. Deep Learning for Cloud Detection; International Conference of Pattern Recognition Systems (ICPRS): Madrid, Spain, 2017; pp. 1–6. [Google Scholar]
- Zi, Y.; Xie, F.; Jiang, Z. A Cloud Detection Method for Landsat 8 Images Based on PCANet. Remote Sens. 2018, 10, 877. [Google Scholar] [CrossRef] [Green Version]
- Ozkan, S.; Efendioglu, M.; Demirpolat, C. Cloud detection from RGB color remote sensing images with deep pyramid networks. In Proceedings of the 38th IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 6939–6942. [Google Scholar]
- Chai, D.; Newsam, S.; Zhang, H.K.K.; Qiu, Y.; Huang, J.F. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Li, Z.W.; Shen, H.F.; Cheng, Q.; Liu, Y.H.; You, S.C.; He, Z.Y. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Shao, X.; Zhang, W. SPatchGAN: A Statistical Feature Based Discriminator for Unsupervised Image-to-Image Translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6526–6535. [Google Scholar]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised Representation Learning for Remote Sensing Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef] [Green Version]
- Castro, J.; Nigri Happ, P.; Feitosa, R.; Oliveira, D. Synthesis of Multispectral Optical Images From SAR/Optical Multitemporal Data Using Conditional Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1220–1224. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Hu, Z.; Zhang, J.; Li, M.; Mo, L.; Molinier, M. Thin cloud removal in optical remote sensing images based on generative adversarial networks and physical model of cloud distortion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 373–389. [Google Scholar] [CrossRef]
- Nyborg, J.; Assent, I. Weakly-Supervised Cloud Detection with Fixed-Point GANs. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 4191–4198. [Google Scholar]
- Wu, Z.; Li, J.; Wang, Y.; Hu, Z.; Molinier, M. Self-Attentive Generative Adversarial Network for Cloud Detection in High Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1792–1796. [Google Scholar] [CrossRef]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative Adversarial Networks. Stat 2017, 1050. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021; pp. 1–21. [Google Scholar]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An Empirical Study of Remote Sensing Pretraining. IEEE Trans. Geosci. Remote Sens. 2022. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model. IEEE Trans. Geosci. Remote Sens. 2022. [Google Scholar] [CrossRef]
- Mateo-Garcia, G.; Laparra, V.; Lopez-Puigdollers, D.; Gomez-Chova, L. Transferring deep learning models for cloud detection between Landsat-8 and Proba-V. ISPRS J. Photogramm. Remote Sens. 2020, 160, 1–17. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Sheng, Q.; Wang, B.; Hu, Z.; Zheng, S.; Camps-Valls, G.; Molinier, M. A hybrid generative adversarial network for weakly-supervised cloud detection in multispectral images. Remote Sens. Environ. 2022, 280, 113197. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI); Medical Image Computing and Computer-Assisted Intervention (MICCAI): Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Fernández-Manso, A.; Fernández-Manso, O.; Quintano, C. SENTINEL-2A red-edge spectral indices suitability for discriminating burn severity. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 170–175. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Francis, A.; Mrziglod, J.; Sidiropoulos, P.; Muller, J.-P. Sentinel-2 Cloud Mask Catalogue. Zenodo 2020. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Edwards, A.L. Note on the “correction for continuity” in testing the significance of the difference between correlated proportions. Psychometrika 1948, 13, 185–187. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Steven, M.D.; Malthus, T.J.; Baret, F.; Xu, H.; Chopping, M.J. Intercalibration of vegetation indices from different sensor systems. Remote Sens. Environ. 2003, 88, 412–422. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Zhu, Z.; Wang, S.X.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landsat 8 OLI/TIRS | Sentinel 2A MSI | Band Type | ||||
|---|---|---|---|---|---|---|
| Band Index | Wavelength (μm) | Spatial Resolution | Band Index | Wavelength (μm) | Spatial Resolution | |
| 1 | 0.435–0.451 | 30 m | 1 | 0.433–0.453 | 60 m | Coastal |
| 2 | 0.452–0.512 | 30 m | 2 | 0.458–0.523 | 10 m | Blue |
| 3 | 0.533–0.590 | 30 m | 3 | 0.543–0.578 | 10 m | Green |
| 4 | 0.636–0.673 | 30 m | 4 | 0.650–0.680 | 10 m | Red |
| 5 | 0.851–0.879 | 30 m | 8 | 0.785–0.900 | 10 m | NIR |
| 6 | 1.566–1.651 | 30 m | 11 | 1.565–1.655 | 20 m | SWIR-1 |
| 10 | 10.60–11.19 | 100 m | _ | _ | _ | TIR-1 |
| 7 | 2.107–2.294 | 30 m | 12 | 2.100–2.280 | 20 m | SWIR-2 |
| 8 | 0.503–0.676 | 15 m | _ | _ | _ | Panchromatic |
| 9 | 1.363–1.384 | 30 m | 10 | 1.360–1.390 | 60 m | Cirrus |
| 11 | 11.50–12.51 | 100 m | _ | _ | _ | TIR-2 |
| _ | _ | _ | 5 | 0.698–0.713 | 20 m | Red edge |
| _ | _ | _ | 6 | 0.733–0.748 | 20 m | Red edge |
| _ | _ | _ | 7 | 0.773–0.793 | 20 m | Red edge |
| _ | _ | _ | 8a | 0.854–0.875 | 20 m | Red edge |
| 9 | 0.935–0.955 | 60 m | Water vapor | |||
| Model | Params | FLOPs |
|---|---|---|
| UNmask | 7.85 M | 28.11 G |
| SNmask | 4.47 M | 56.35 G |
| DLmask | 13.09 M | 42.22 G |
| FCNmask | 27.84 M | 57.72 G |
| Model | Accuracy (%) | F1 (%) | Recall (%) | Precision (%) |
|---|---|---|---|---|
| UNmask | 94.9 | 94.1 | 95.4 | 92.9 |
| FCNmask | 94.2 | 93.3 | 94.7 | 91.8 |
| SNmask | 93.9 | 93.0 | 93.2 | 92.8 |
| DLmask | 92.5 | 91.4 | 91.4 | 91.3 |
| Model | UNmask | FCNmask | SNmask | DLmask |
|---|---|---|---|---|
| UNmask | - | 222 | 3982 | 1,230,033 |
| FCNmask | - | - | 6434 | 2,085,938 |
| SNmask | - | - | - | 743,929 |
| DLmask | - | - | - | - |
| Algorithm | Accuracy (%) | Recall (%) | Precision (%) | Literature |
|---|---|---|---|---|
| LaSRC | 73.1 | - | - | Foga et al., 2017 [68] |
| FT-ACCA | 74.2 | - | - | |
| ACCA | 83.8 | - | - | |
| See5 | 85.8 | - | - | |
| AT-ACCA | 87.5 | - | - | |
| CFmask | 89.3 | - | - | |
| CDAL8 | 88.8 | - | - | Oishi et al., 2018 [24] |
| RS-Net | 93.1 | 91.8 | 94.1 | Jeppesen et al., 2019 [29] |
| Fmask | 93.3 | 95.0 | 97.0 | Zhu et al., 2015 [79] |
| RFmask | 93.7 | 87.6 | 89.0 | Wei et al., 2020 [33] |
| SegNet | 94.0 | 93.1 | 94.5 | Chai et al., 2019 [45] |
| MSCFF | 95.0 | 95.1 | 93.9 | Li et al., 2019 [47] |
| UNmask | 94.9 | 95.4 | 92.9 | This study |
| Model | Accuracy (%) | F1 (%) | Recall (%) | Precision (%) | FLOPs | Iterations |
|---|---|---|---|---|---|---|
| Fmask 4.0 | 86.1 | 85.2 | 85.6 | 84.9 | - | - |
| UNmask | 90.1 | 90.2 | 89.1 | 91.4 | 28.11 G | ~6000 |
| GAN-CDM-6 | 92.5 | 92.9 | 92.8 | 92.9 | 201.66 G | ~1,000,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, S.; Sun, L.; Tian, Y.; Ma, Y.; Wei, J. Convolutional Neural Network-Driven Improvements in Global Cloud Detection for Landsat 8 and Transfer Learning on Sentinel-2 Imagery. Remote Sens. 2023, 15, 1706. https://doi.org/10.3390/rs15061706
Pang S, Sun L, Tian Y, Ma Y, Wei J. Convolutional Neural Network-Driven Improvements in Global Cloud Detection for Landsat 8 and Transfer Learning on Sentinel-2 Imagery. Remote Sensing. 2023; 15(6):1706. https://doi.org/10.3390/rs15061706
Chicago/Turabian StylePang, Shulin, Lin Sun, Yanan Tian, Yutiao Ma, and Jing Wei. 2023. "Convolutional Neural Network-Driven Improvements in Global Cloud Detection for Landsat 8 and Transfer Learning on Sentinel-2 Imagery" Remote Sensing 15, no. 6: 1706. https://doi.org/10.3390/rs15061706
APA StylePang, S., Sun, L., Tian, Y., Ma, Y., & Wei, J. (2023). Convolutional Neural Network-Driven Improvements in Global Cloud Detection for Landsat 8 and Transfer Learning on Sentinel-2 Imagery. Remote Sensing, 15(6), 1706. https://doi.org/10.3390/rs15061706